Load WildMe Conservation Data into FiftyOne¶
This notebook walks you through how to load data from the WildMe Collection in the Labeled Information Library of Alexandria: Biology and Conservation LILA BC dataset!
First, we'll download the data. Then, we'll load the data into FiftyOne. Finally, we'll add some visualization and similarity indexes to the data, as a bonus.
Note: You can also browse this dataset for free at try.fiftyone.ai!

Setup¶
To run this code, you will need to install the FiftyOne open source library for dataset curation.
!pip install fiftyone
We will import all of the necessary modules:
from datetime import datetime
import json
import numpy as np
import os
import fiftyone as fo
import fiftyone.brain as fob
from fiftyone import ViewField as F
Downloading Data¶
All of the raw data is hosted in Google Cloud buckets. We will be creating one combined dataset out of three collections:
Run the following cell to batch download the zip files containing the X-ray images:
## 3 collections of images and annotations from WildMe
subsets = ["beluga", "hyena", "leopard"]
for s in subsets:
## Download the data
!wget https://storage.googleapis.com/public-datasets-lila/wild-me/{s}.coco.tar.gz
## Unzip the data
!gunzip {s}.coco.tar.gz
## Untar the data
!tar -xvf {s}.coco.tar
## Move the data to the correct location for COCO Import
!mkdir {s}/data
!mv {s}/images/train2022* {s}/data/
!mv {s}/annotations/instances_train2022.json labels.json
Loading the data¶
Now that we have the data downloaded, we can create a FiftyOne dataset for all of it. First, let's create an empty dataset:
dataset = fo.Dataset("WildMe")
Then, we can loop over the subdatasets, import each of them in COCO format, and add them to the main dataset. We also delete the segmentations sample field from the annotations, as it is not used.
DATASET_TYPE = fo.types.COCODetectionDataset
for subset in subsets:
dataset_dir = f"{subset}.coco/"
subset = fo.Dataset.from_dir(
dataset_dir=dataset_dir,
dataset_type=DATASET_TYPE,
)
## delete unused segmentations field
subset.delete_sample_field("segmentations")
dataset.add_samples(subset)
Now, we can make the dataset persistent so it can be used in the future without having to re-download the data.
dataset.persistent=True
Additionally, we can use the add_dynamic_sample_Fields() method to make all of the non-standard attributes on the dataset visible and filterable in the FiftyOne App:
dataset.add_dynamic_sample_fields()
In order to easily differentiate between the sub-collections in the dataset, we will save them each as their own view, and also tag samples with the sub-collection name. This will allow us to easily filter the dataset by sub-collection.
beluga_view = dataset.match_labels(filter = F("label") == "beluga_whale")
dataset.save_view("beluga_view", beluga_view)
beluga_view.tag_samples("beluga")
hyena_view = dataset.match_labels(filter = F("label") == "hyena")
dataset.save_view("hyena_view", hyena_view)
hyena_view.tag_samples("hyena")
leopard_view = dataset.match_labels(filter = F("label") == "leopard")
dataset.save_view("leopard_view", leopard_view)
leopard_view.tag_samples("leopard")
Add Embeddings, Similarity, and Visualization¶
In order to capture visual and conceptual similarity, we will use DreamSim. We will compute embeddings once so that we can use them for the rest of the notebook. If you would like, you can swap out DreamSim for another embedding model, such as ResNet50.
!pip install dreamsim
from dreamsim import dreamsim
from PIL import Image
model, preprocess = dreamsim(pretrained=True)
Iterate through samples in the dataset, adding dreamsim embedding to each:
dataset.add_sample_field("dreamsim_embedding", fo.ArrayField)
for sample in dataset.iter_samples(autosave=True, progress=True):
img1 = preprocess(Image.open(sample.filepath)).to("cuda")
sample["dreamsim_embedding"] = np.array(model.embed(img1).cpu())[0]
Now we can use these embeddings to compute an image similarity index on the dataset:
fob.compute_similarity(
dataset,
embeddings = "dreamsim_embedding",
brain_key = "dreamsim_sim",
)
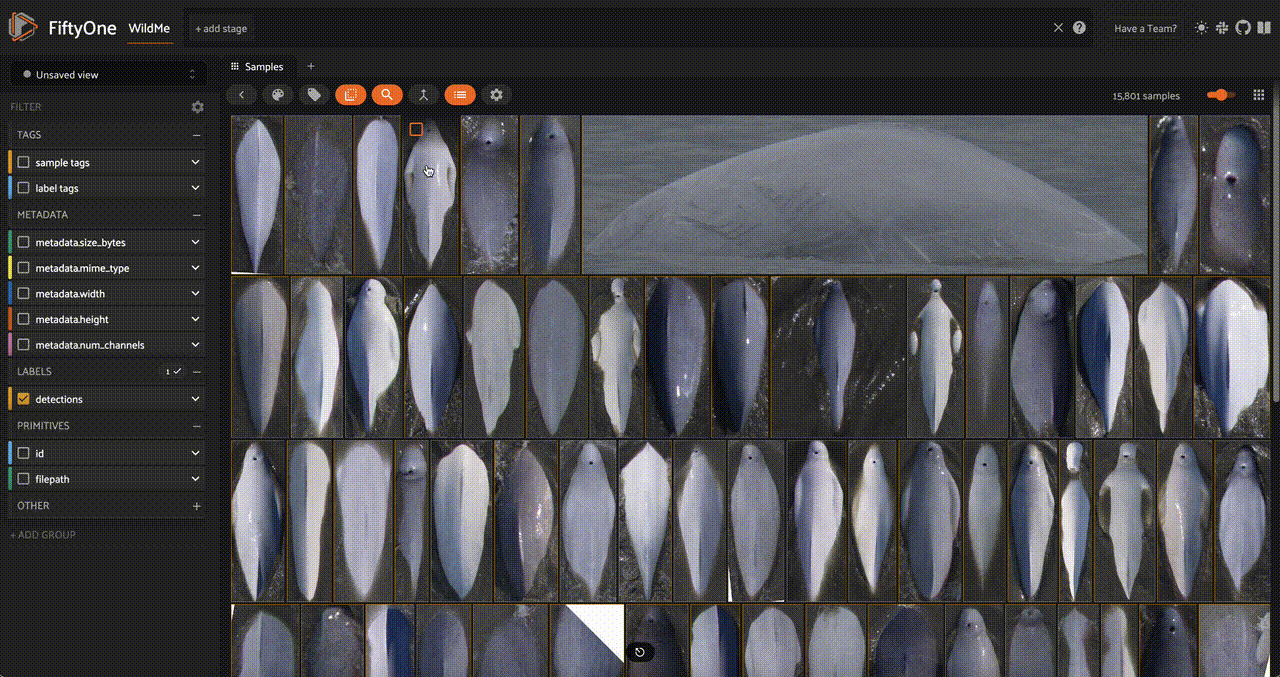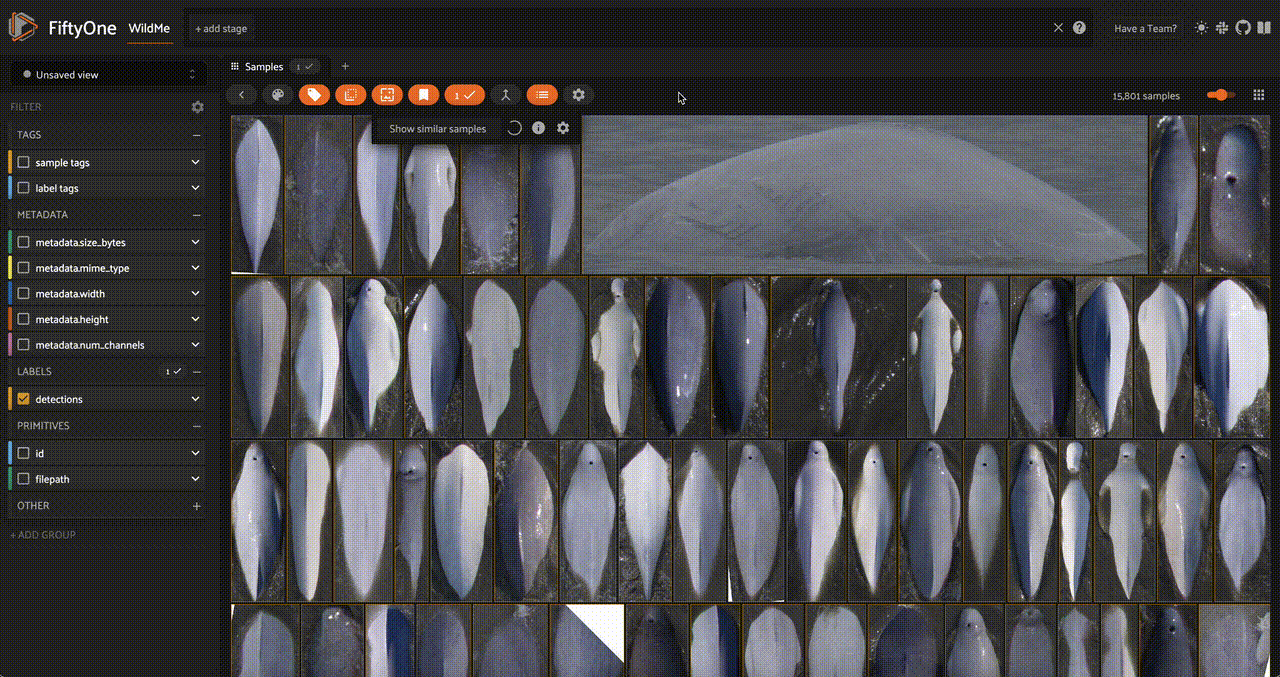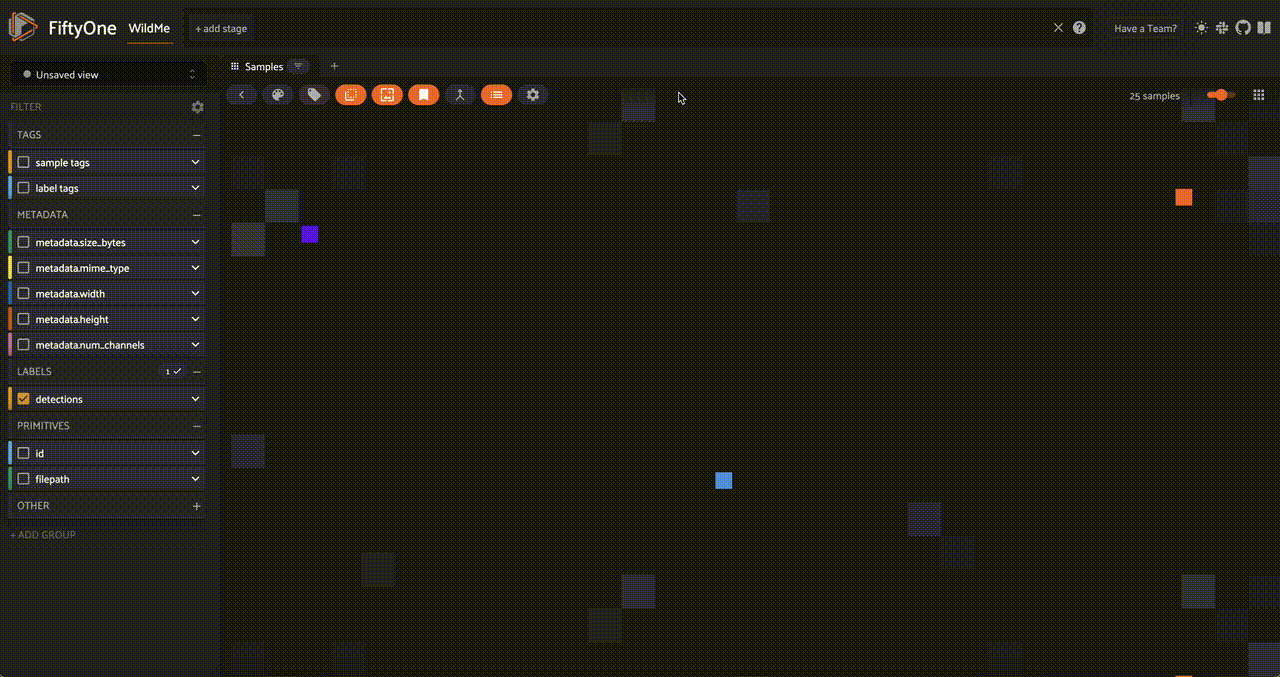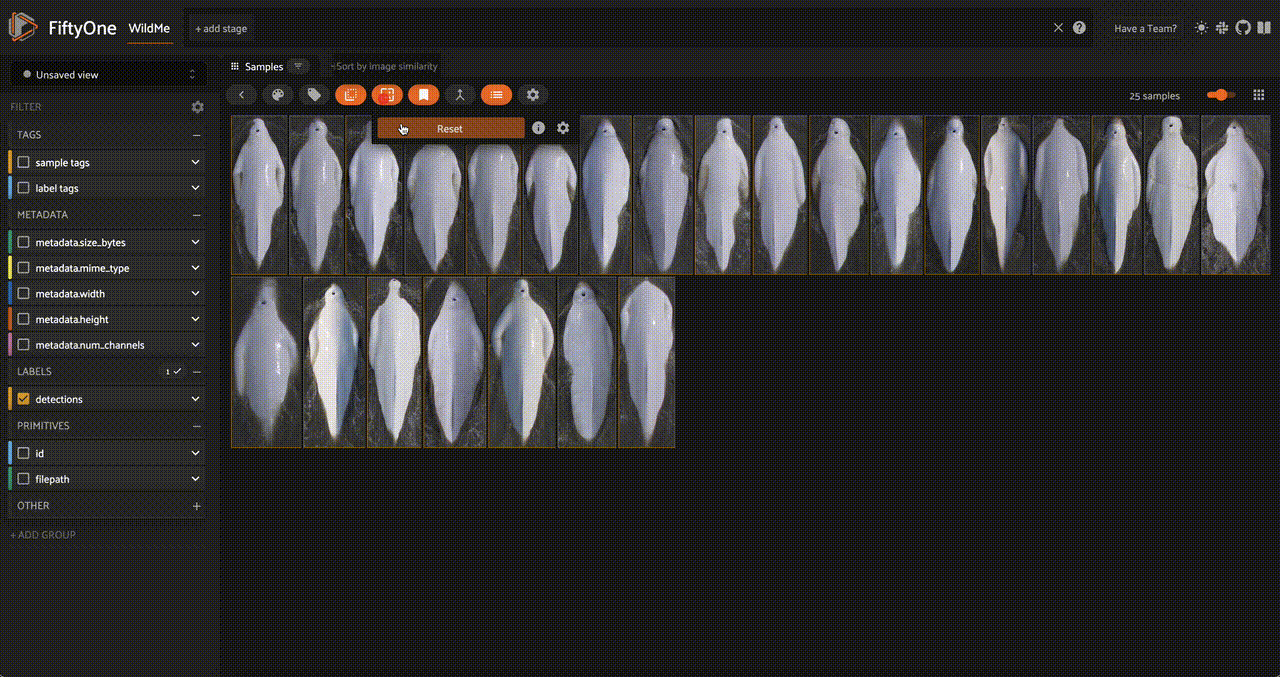
As well as an embedding visualization, which we can generate by running UMAP on the embeddings to reduce them to 2 dimensions:
fob.compute_visualization(
dataset,
embeddings = "dreamsim_embedding",
brain_key = "dreamsim_vis",
)
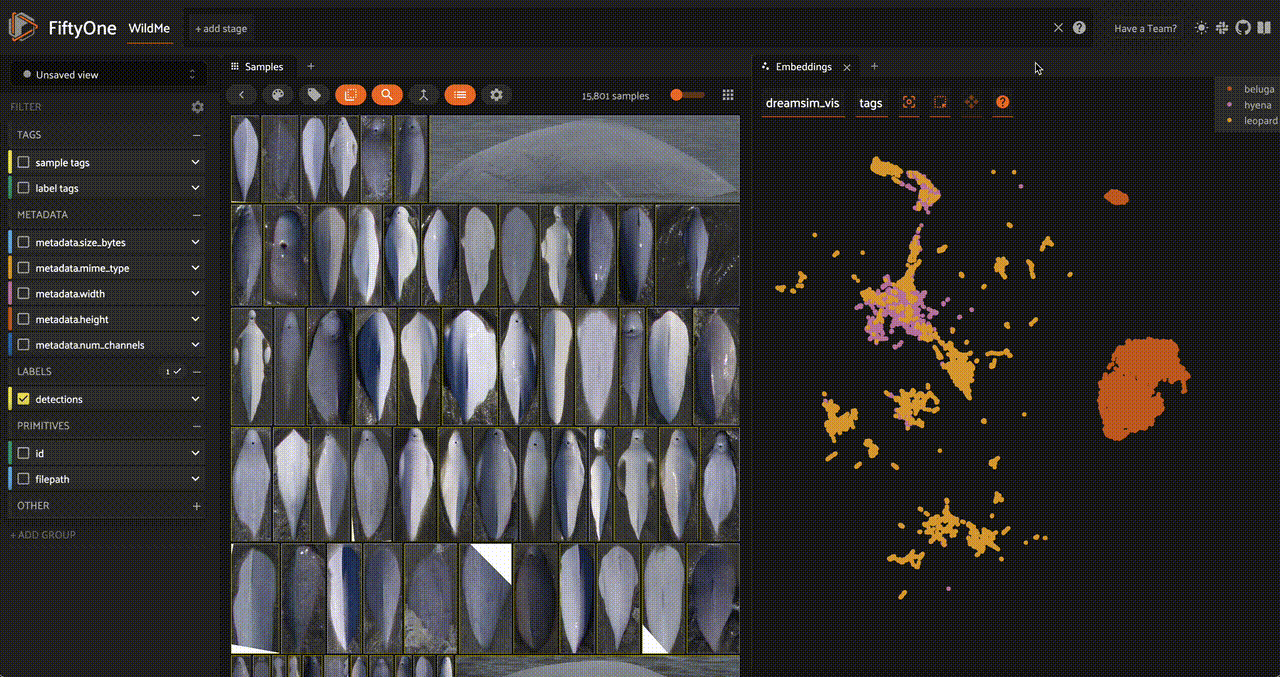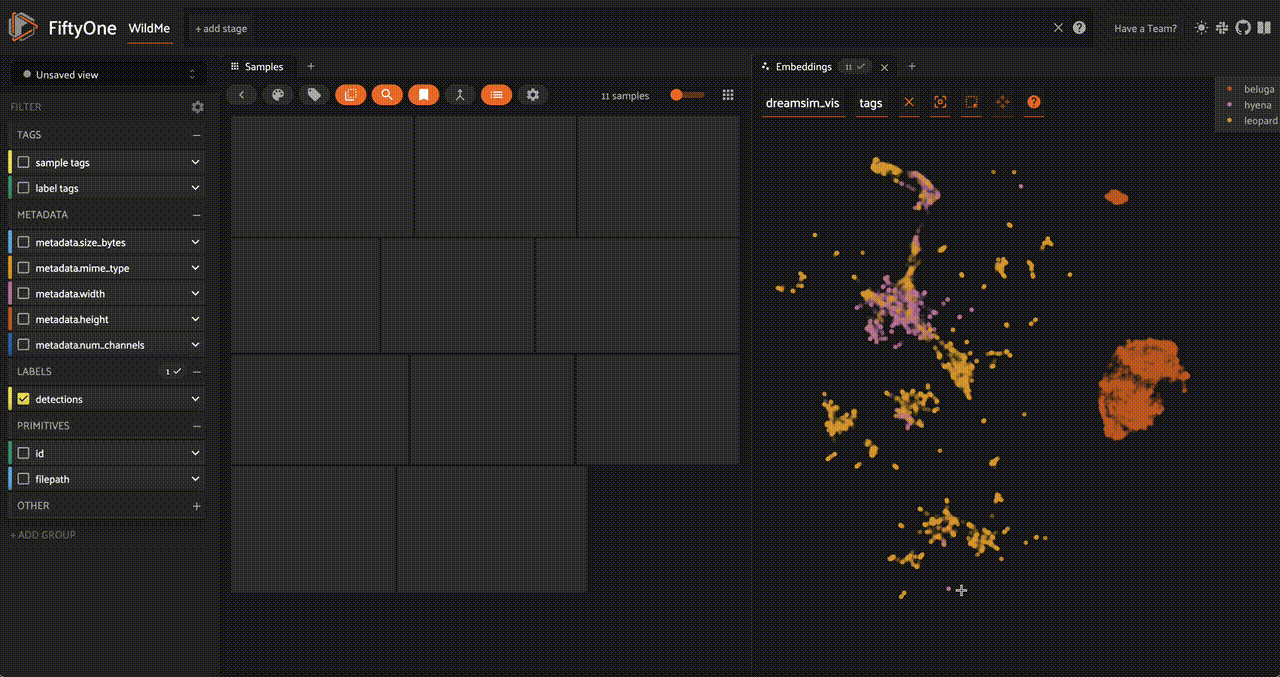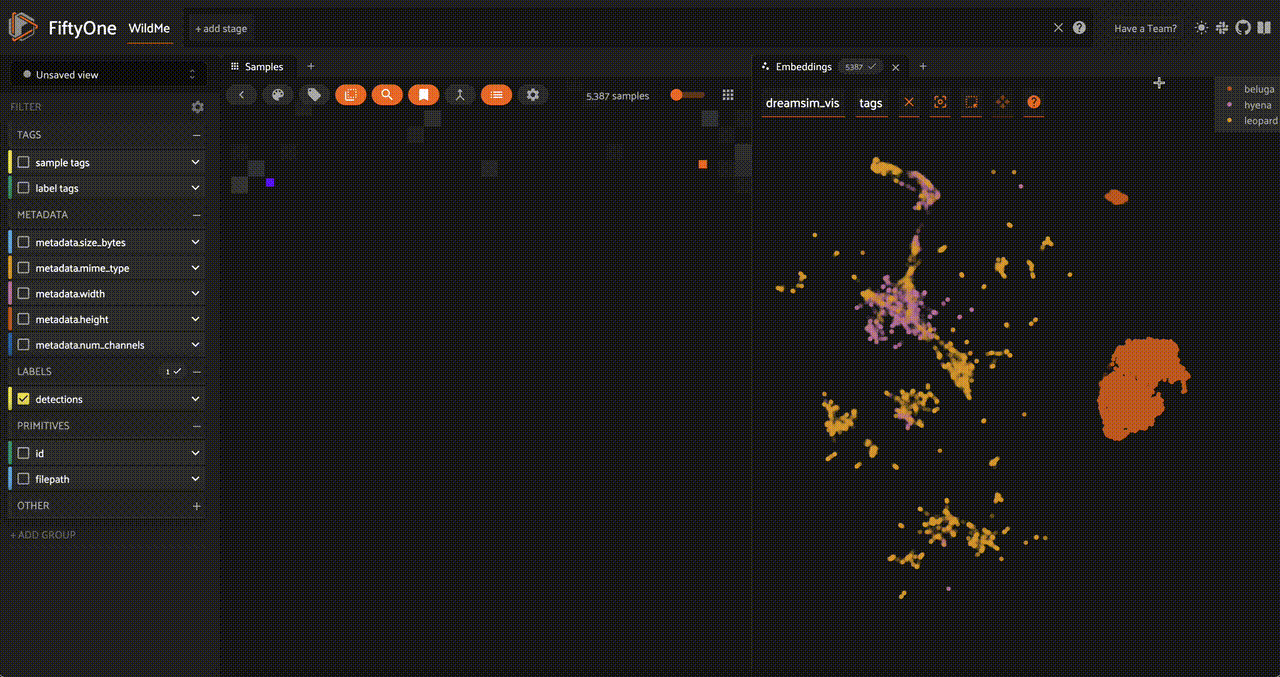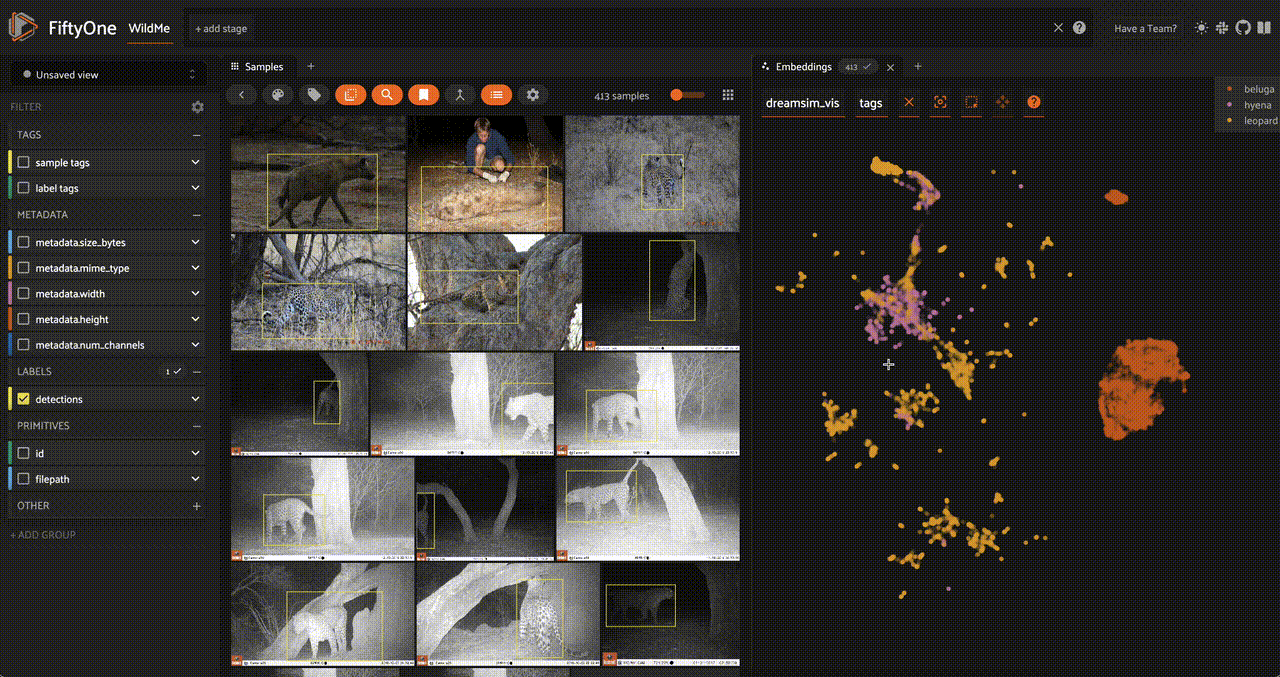
We can also add a similarity index to the detection patches, making them searchable as well. Let's use a CLIP model so that we can search through the object detection patches with natural language queries:
fob.compute_similarity(
dataset,
patches_field = "detections",
model = "clip-vit-base32-torch",
brain_key = "clip_sim"
)
