Guided Project - Clean And Analyze Employee Exit Surveys
This guided project is to supplement practice for data cleaning, transforming and data combining skills.
The project involves two datasets: Exit surveys from employees of - the Department of Education, Training and Employment (DETE) and - the Technical and Further Education (TAFE) institute in Queensland, Australia.
The objective of the project is, to answer the following assumed questions:
- Are employees who only worked for the institutes for a short period of time resigning due to some kind of dissatisfaction? What about employees who have been there longer?
- Are younger employees resigning due to some kind of dissatisfaction? What about older employees?
Due to lack of a proper data dictionary about the datasets, general info based on the columns present has been considered.
Section 1 - Read data files
- Import python libraries
- Read datafiles into dataframes
- Explore the columns and the datatypes
- Use heatmaps to glance at the raw dataframes
# magic line to get plots in the jupyter file itself
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dete_survey = pd.read_csv("dete_survey.csv", encoding="latin_1")
tafe_survey = pd.read_csv("tafe_survey.csv", encoding="Windows-1252")
# DETE info
dete_survey.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 822 entries, 0 to 821 Data columns (total 56 columns): ID 822 non-null int64 SeparationType 822 non-null object Cease Date 822 non-null object DETE Start Date 822 non-null object Role Start Date 822 non-null object Position 817 non-null object Classification 455 non-null object Region 822 non-null object Business Unit 126 non-null object Employment Status 817 non-null object Career move to public sector 822 non-null bool Career move to private sector 822 non-null bool Interpersonal conflicts 822 non-null bool Job dissatisfaction 822 non-null bool Dissatisfaction with the department 822 non-null bool Physical work environment 822 non-null bool Lack of recognition 822 non-null bool Lack of job security 822 non-null bool Work location 822 non-null bool Employment conditions 822 non-null bool Maternity/family 822 non-null bool Relocation 822 non-null bool Study/Travel 822 non-null bool Ill Health 822 non-null bool Traumatic incident 822 non-null bool Work life balance 822 non-null bool Workload 822 non-null bool None of the above 822 non-null bool Professional Development 808 non-null object Opportunities for promotion 735 non-null object Staff morale 816 non-null object Workplace issue 788 non-null object Physical environment 817 non-null object Worklife balance 815 non-null object Stress and pressure support 810 non-null object Performance of supervisor 813 non-null object Peer support 812 non-null object Initiative 813 non-null object Skills 811 non-null object Coach 767 non-null object Career Aspirations 746 non-null object Feedback 792 non-null object Further PD 768 non-null object Communication 814 non-null object My say 812 non-null object Information 816 non-null object Kept informed 813 non-null object Wellness programs 766 non-null object Health & Safety 793 non-null object Gender 798 non-null object Age 811 non-null object Aboriginal 16 non-null object Torres Strait 3 non-null object South Sea 7 non-null object Disability 23 non-null object NESB 32 non-null object dtypes: bool(18), int64(1), object(37) memory usage: 258.6+ KB
# TAFE info
tafe_survey.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 702 entries, 0 to 701 Data columns (total 72 columns): Record ID 702 non-null float64 Institute 702 non-null object WorkArea 702 non-null object CESSATION YEAR 695 non-null float64 Reason for ceasing employment 701 non-null object Contributing Factors. Career Move - Public Sector 437 non-null object Contributing Factors. Career Move - Private Sector 437 non-null object Contributing Factors. Career Move - Self-employment 437 non-null object Contributing Factors. Ill Health 437 non-null object Contributing Factors. Maternity/Family 437 non-null object Contributing Factors. Dissatisfaction 437 non-null object Contributing Factors. Job Dissatisfaction 437 non-null object Contributing Factors. Interpersonal Conflict 437 non-null object Contributing Factors. Study 437 non-null object Contributing Factors. Travel 437 non-null object Contributing Factors. Other 437 non-null object Contributing Factors. NONE 437 non-null object Main Factor. Which of these was the main factor for leaving? 113 non-null object InstituteViews. Topic:1. I feel the senior leadership had a clear vision and direction 608 non-null object InstituteViews. Topic:2. I was given access to skills training to help me do my job better 613 non-null object InstituteViews. Topic:3. I was given adequate opportunities for personal development 610 non-null object InstituteViews. Topic:4. I was given adequate opportunities for promotion within %Institute]Q25LBL% 608 non-null object InstituteViews. Topic:5. I felt the salary for the job was right for the responsibilities I had 615 non-null object InstituteViews. Topic:6. The organisation recognised when staff did good work 607 non-null object InstituteViews. Topic:7. Management was generally supportive of me 614 non-null object InstituteViews. Topic:8. Management was generally supportive of my team 608 non-null object InstituteViews. Topic:9. I was kept informed of the changes in the organisation which would affect me 610 non-null object InstituteViews. Topic:10. Staff morale was positive within the Institute 602 non-null object InstituteViews. Topic:11. If I had a workplace issue it was dealt with quickly 601 non-null object InstituteViews. Topic:12. If I had a workplace issue it was dealt with efficiently 597 non-null object InstituteViews. Topic:13. If I had a workplace issue it was dealt with discreetly 601 non-null object WorkUnitViews. Topic:14. I was satisfied with the quality of the management and supervision within my work unit 609 non-null object WorkUnitViews. Topic:15. I worked well with my colleagues 605 non-null object WorkUnitViews. Topic:16. My job was challenging and interesting 607 non-null object WorkUnitViews. Topic:17. I was encouraged to use my initiative in the course of my work 610 non-null object WorkUnitViews. Topic:18. I had sufficient contact with other people in my job 613 non-null object WorkUnitViews. Topic:19. I was given adequate support and co-operation by my peers to enable me to do my job 609 non-null object WorkUnitViews. Topic:20. I was able to use the full range of my skills in my job 609 non-null object WorkUnitViews. Topic:21. I was able to use the full range of my abilities in my job. ; Category:Level of Agreement; Question:YOUR VIEWS ABOUT YOUR WORK UNIT] 608 non-null object WorkUnitViews. Topic:22. I was able to use the full range of my knowledge in my job 608 non-null object WorkUnitViews. Topic:23. My job provided sufficient variety 611 non-null object WorkUnitViews. Topic:24. I was able to cope with the level of stress and pressure in my job 610 non-null object WorkUnitViews. Topic:25. My job allowed me to balance the demands of work and family to my satisfaction 611 non-null object WorkUnitViews. Topic:26. My supervisor gave me adequate personal recognition and feedback on my performance 606 non-null object WorkUnitViews. Topic:27. My working environment was satisfactory e.g. sufficient space, good lighting, suitable seating and working area 610 non-null object WorkUnitViews. Topic:28. I was given the opportunity to mentor and coach others in order for me to pass on my skills and knowledge prior to my cessation date 609 non-null object WorkUnitViews. Topic:29. There was adequate communication between staff in my unit 603 non-null object WorkUnitViews. Topic:30. Staff morale was positive within my work unit 606 non-null object Induction. Did you undertake Workplace Induction? 619 non-null object InductionInfo. Topic:Did you undertake a Corporate Induction? 432 non-null object InductionInfo. Topic:Did you undertake a Institute Induction? 483 non-null object InductionInfo. Topic: Did you undertake Team Induction? 440 non-null object InductionInfo. Face to Face Topic:Did you undertake a Corporate Induction; Category:How it was conducted? 555 non-null object InductionInfo. On-line Topic:Did you undertake a Corporate Induction; Category:How it was conducted? 555 non-null object InductionInfo. Induction Manual Topic:Did you undertake a Corporate Induction? 555 non-null object InductionInfo. Face to Face Topic:Did you undertake a Institute Induction? 530 non-null object InductionInfo. On-line Topic:Did you undertake a Institute Induction? 555 non-null object InductionInfo. Induction Manual Topic:Did you undertake a Institute Induction? 553 non-null object InductionInfo. Face to Face Topic: Did you undertake Team Induction; Category? 555 non-null object InductionInfo. On-line Topic: Did you undertake Team Induction?process you undertook and how it was conducted.] 555 non-null object InductionInfo. Induction Manual Topic: Did you undertake Team Induction? 555 non-null object Workplace. Topic:Did you and your Manager develop a Performance and Professional Development Plan (PPDP)? 608 non-null object Workplace. Topic:Does your workplace promote a work culture free from all forms of unlawful discrimination? 594 non-null object Workplace. Topic:Does your workplace promote and practice the principles of employment equity? 587 non-null object Workplace. Topic:Does your workplace value the diversity of its employees? 586 non-null object Workplace. Topic:Would you recommend the Institute as an employer to others? 581 non-null object Gender. What is your Gender? 596 non-null object CurrentAge. Current Age 596 non-null object Employment Type. Employment Type 596 non-null object Classification. Classification 596 non-null object LengthofServiceOverall. Overall Length of Service at Institute (in years) 596 non-null object LengthofServiceCurrent. Length of Service at current workplace (in years) 596 non-null object dtypes: float64(2), object(70) memory usage: 395.0+ KB
Factor the presence of null values in DETE and TAFE dataframes - Visualize missing data with heatmaps - List the observations based on heatmaps
dete_survey.set_index("ID")
fig, ax = plt.subplots(figsize=(17,8))
ax = sns.heatmap(dete_survey.isnull(), cbar=False)
ax.set_yticks([])
ax.set_title("Data Presence and Abscence in DETE", fontsize=14)
plt.show()

As observed from the DETE heatmap, following columns have least amount of data and are right candidates to be dropped from the dataframe: - Classification - Business Unit - Aborginal - Torress Strait - South Sea - Disability - NESB
Following columns show similar distribution of data present and missing, and also are not required for analysis. Hence these columns can also be dropped: - Oppurtunities for pormotion - Coach - Career Aspirations - Further PD - Wellness Programs - Health and Safety
Several other columns may have more data than missing values, however are not required to derive answers for the above questions.
tafe_survey.set_index("Record ID")
fig, ax = plt.subplots(figsize=(18,10))
ax = sns.heatmap(tafe_survey.isnull(), cbar=False)
ax.set_yticks([])
ax.set_title("Data Presence and Absence in TAFE", fontsize=14)
plt.show()

TAFE dataframe has a different show for missing data. Several chunks of rows have almost no data for all the columns provided.
Review unique values in each column of dataframe, to have a glimpse of data captured - Print unique values in each column to get a glimpse of uniformity and difference in formats of data
dete_cols = dete_survey.columns
# exlude "ID" column from column list
dete_cols = dete_cols[1:]
# for each column in the list, print the unique values
for each_col in dete_cols:
print("\033[1m"+each_col+"\033[0m")
print(dete_survey[each_col].unique(),"\n")
SeparationType ['Ill Health Retirement' 'Voluntary Early Retirement (VER)' 'Resignation-Other reasons' 'Age Retirement' 'Resignation-Other employer' 'Resignation-Move overseas/interstate' 'Other' 'Contract Expired' 'Termination'] Cease Date ['08/2012' '05/2012' '07/2012' '2012' '2013' '2014' '2010' '09/2013' '07/2013' '08/2013' '06/2013' '04/2013' '05/2013' '09/2010' '01/2014' '11/2012' '04/2014' '12/2013' '07/2014' '10/2013' '11/2013' 'Not Stated' '09/2014' '07/2006' '02/2014'] DETE Start Date ['1984' 'Not Stated' '2011' '2005' '1970' '1994' '1972' '1988' '2009' '1997' '1999' '1998' '1967' '2007' '1995' '1996' '2006' '1989' '1982' '1980' '1973' '1981' '1974' '1975' '1978' '2003' '2000' '1977' '1976' '1985' '2008' '1963' '1993' '1979' '1990' '1969' '1966' '2010' '1968' '1991' '1971' '2002' '1986' '2004' '2012' '1983' '2001' '1987' '1992' '2013' '1965'] Role Start Date ['2004' 'Not Stated' '2011' '2006' '1989' '1997' '2007' '1990' '2009' '2008' '1999' '1998' '2000' '2010' '1996' '1982' '2012' '1981' '2002' '1977' '2003' '1978' '1992' '1980' '1994' '1976' '1991' '2001' '1993' '1983' '1987' '1985' '1975' '1986' '1979' '1988' '2005' '1995' '1970' '1984' '200' '1974' '2013' '1971' '1973' '1972'] Position ['Public Servant' 'Schools Officer' 'Teacher' 'Head of Curriculum/Head of Special Education' 'Guidance Officer' 'Teacher Aide' 'Cleaner' 'School Administrative Staff' 'Technical Officer' 'Deputy Principal' 'School Principal' nan 'Business Service Manager' 'Professional Officer' 'Other' 'School Based Professional Staff (Therapist, nurse, etc)'] Classification ['A01-A04' 'AO5-AO7' nan 'Primary' 'Secondary' 'Special Education' 'PO1-PO4' 'AO8 and Above' 'Middle'] Region ['Central Office' 'Central Queensland' 'South East' 'Darling Downs South West' 'North Coast' 'North Queensland' 'Not Stated' 'Far North Queensland' 'Metropolitan'] Business Unit ['Corporate Strategy and Peformance' 'Education Queensland' nan 'Information and Technologies' 'Other' 'Training and Tertiary Education Queensland' 'Human Resources' 'Corporate Procurement' 'Finance' 'Early Childhood Education and Care' 'Pacific Pines SHS' 'Calliope State School' 'Policy, Research, Legislation' 'Infrastructure' 'Indigenous Education and Training Futures'] Employment Status ['Permanent Full-time' 'Permanent Part-time' 'Temporary Part-time' 'Temporary Full-time' 'Casual' nan] Career move to public sector [ True False] Career move to private sector [False True] Interpersonal conflicts [False True] Job dissatisfaction [ True False] Dissatisfaction with the department [False True] Physical work environment [False True] Lack of recognition [ True False] Lack of job security [False True] Work location [False True] Employment conditions [False True] Maternity/family [False True] Relocation [False True] Study/Travel [False True] Ill Health [False True] Traumatic incident [False True] Work life balance [False True] Workload [False True] None of the above [ True False] Professional Development ['A' 'N' 'SD' 'D' 'SA' 'M' nan] Opportunities for promotion ['A' 'N' 'SD' nan 'M' 'SA' 'D'] Staff morale ['N' 'SD' 'A' 'D' 'SA' 'M' nan] Workplace issue ['N' 'D' 'A' 'SD' 'SA' nan 'M'] Physical environment ['N' 'A' 'D' 'SD' 'SA' 'M' nan] Worklife balance ['A' 'N' 'D' 'SA' 'SD' 'M' nan] Stress and pressure support ['A' 'N' 'D' 'SA' 'SD' 'M' nan] Performance of supervisor ['A' 'N' 'D' 'SA' 'SD' 'M' nan] Peer support ['A' 'N' nan 'SA' 'D' 'SD' 'M'] Initiative ['N' 'A' 'SA' 'D' 'SD' 'M' nan] Skills ['N' 'A' 'SA' 'SD' 'D' 'M' nan] Coach ['N' 'A' nan 'SD' 'SA' 'M' 'D'] Career Aspirations ['A' 'N' 'D' nan 'SD' 'M' 'SA'] Feedback ['A' 'N' 'SA' 'D' 'SD' 'M' nan] Further PD ['A' 'N' 'SA' 'D' 'SD' 'M' nan] Communication ['N' 'A' 'D' 'SD' 'SA' 'M' nan] My say ['A' 'D' 'SA' 'SD' 'N' 'M' nan] Information ['A' 'N' 'D' 'SD' 'SA' 'M' nan] Kept informed ['N' 'A' 'D' 'SA' 'SD' 'M' nan] Wellness programs ['N' 'A' 'D' nan 'SD' 'M' 'SA'] Health & Safety ['N' 'A' 'M' nan 'SD' 'SA' 'D'] Gender ['Male' 'Female' nan] Age ['56-60' '61 or older' '36-40' '41-45' '31-35' '46-50' '51-55' '21-25' '26-30' nan '20 or younger'] Aboriginal [nan 'Yes'] Torres Strait [nan 'Yes'] South Sea [nan 'Yes'] Disability [nan 'Yes'] NESB ['Yes' nan]
tafe_cols = tafe_survey.columns
# exclude the "Record Id" column
tafe_cols = tafe_cols[1:]
# for each column in the list, print the unique values
for each_col in tafe_cols:
print("\033[1m"+each_col+"\033[0m")
print(tafe_survey[each_col].unique(),"\n")
Institute ['Southern Queensland Institute of TAFE' 'Mount Isa Institute of TAFE' 'Barrier Reef Institute of TAFE' 'Central Queensland Institute of TAFE' 'Brisbane North Institute of TAFE' 'Southbank Institute of Technology' 'Tropical North Institute of TAFE' 'Sunshine Coast Institute of TAFE' 'The Bremer Institute of TAFE' 'Wide Bay Institute of TAFE' 'Metropolitan South Institute of TAFE' 'SkillsTech Australia'] WorkArea ['Non-Delivery (corporate)' 'Delivery (teaching)'] CESSATION YEAR [2010. 2009. nan 2011. 2012. 2013.] Reason for ceasing employment ['Contract Expired' 'Retirement' 'Resignation' 'Retrenchment/ Redundancy' 'Termination' 'Transfer' nan] Contributing Factors. Career Move - Public Sector [nan '-' 'Career Move - Public Sector'] Contributing Factors. Career Move - Private Sector [nan '-' 'Career Move - Private Sector'] Contributing Factors. Career Move - Self-employment [nan '-' 'Career Move - Self-employment'] Contributing Factors. Ill Health [nan '-' 'Ill Health'] Contributing Factors. Maternity/Family [nan '-' 'Maternity/Family'] Contributing Factors. Dissatisfaction [nan '-' 'Contributing Factors. Dissatisfaction '] Contributing Factors. Job Dissatisfaction [nan '-' 'Job Dissatisfaction'] Contributing Factors. Interpersonal Conflict [nan '-' 'Interpersonal Conflict'] Contributing Factors. Study [nan '-' 'Study'] Contributing Factors. Travel [nan 'Travel' '-'] Contributing Factors. Other [nan '-' 'Other'] Contributing Factors. NONE [nan '-' 'NONE'] Main Factor. Which of these was the main factor for leaving? [nan 'Career Move - Private Sector' 'Career Move - Public Sector' 'Job Dissatisfaction' 'Other' 'Dissatisfaction with %[Institute]Q25LBL%' 'Maternity/Family' 'Interpersonal Conflict' 'Study' 'Ill Health' 'Career Move - Self-employment' 'Travel'] InstituteViews. Topic:1. I feel the senior leadership had a clear vision and direction ['Agree' 'Neutral' 'Strongly Agree' 'Disagree' 'Strongly Disagree' nan 'Not Applicable'] InstituteViews. Topic:2. I was given access to skills training to help me do my job better ['Agree' 'Neutral' 'Strongly Agree' nan 'Strongly Disagree' 'Not Applicable' 'Disagree'] InstituteViews. Topic:3. I was given adequate opportunities for personal development ['Agree' 'Strongly Agree' 'Neutral' nan 'Strongly Disagree' 'Disagree' 'Not Applicable'] InstituteViews. Topic:4. I was given adequate opportunities for promotion within %Institute]Q25LBL% ['Neutral' 'Agree' 'Strongly Agree' 'Disagree' 'Not Applicable' nan 'Strongly Disagree'] InstituteViews. Topic:5. I felt the salary for the job was right for the responsibilities I had ['Agree' 'Strongly Agree' 'Strongly Disagree' 'Neutral' nan 'Disagree' 'Not Applicable'] InstituteViews. Topic:6. The organisation recognised when staff did good work ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' nan 'Disagree' 'Not Applicable'] InstituteViews. Topic:7. Management was generally supportive of me ['Agree' 'Strongly Agree' 'Neutral' nan 'Strongly Disagree' 'Not Applicable' 'Disagree'] InstituteViews. Topic:8. Management was generally supportive of my team ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' 'Strongly Disagree' nan 'Not Applicable'] InstituteViews. Topic:9. I was kept informed of the changes in the organisation which would affect me ['Agree' 'Strongly Agree' 'Neutral' nan 'Disagree' 'Not Applicable' 'Strongly Disagree'] InstituteViews. Topic:10. Staff morale was positive within the Institute ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' 'Disagree' nan 'Not Applicable'] InstituteViews. Topic:11. If I had a workplace issue it was dealt with quickly ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' nan 'Strongly Disagree' 'Not Applicable'] InstituteViews. Topic:12. If I had a workplace issue it was dealt with efficiently ['Agree' 'Neutral' 'Strongly Agree' 'Disagree' nan 'Strongly Disagree' 'Not Applicable'] InstituteViews. Topic:13. If I had a workplace issue it was dealt with discreetly ['Agree' 'Disagree' 'Neutral' 'Strongly Agree' nan 'Strongly Disagree' 'Not Applicable'] WorkUnitViews. Topic:14. I was satisfied with the quality of the management and supervision within my work unit ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' nan 'Strongly Disagree' 'Not Applicable'] WorkUnitViews. Topic:15. I worked well with my colleagues ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' nan 'Not Applicable' 'Strongly Disagree'] WorkUnitViews. Topic:16. My job was challenging and interesting ['Agree' 'Strongly Agree' nan 'Neutral' 'Disagree' 'Not Applicable' 'Strongly Disagree'] WorkUnitViews. Topic:17. I was encouraged to use my initiative in the course of my work ['Strongly Agree' 'Agree' 'Neutral' 'Disagree' nan 'Strongly Disagree' 'Not Applicable'] WorkUnitViews. Topic:18. I had sufficient contact with other people in my job ['Agree' 'Strongly Agree' 'Neutral' nan 'Disagree' 'Strongly Disagree' 'Not Applicable'] WorkUnitViews. Topic:19. I was given adequate support and co-operation by my peers to enable me to do my job ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' nan 'Not Applicable' 'Strongly Disagree'] WorkUnitViews. Topic:20. I was able to use the full range of my skills in my job ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' 'Strongly Disagree' nan 'Not Applicable'] WorkUnitViews. Topic:21. I was able to use the full range of my abilities in my job. ; Category:Level of Agreement; Question:YOUR VIEWS ABOUT YOUR WORK UNIT] ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' 'Strongly Disagree' nan 'Not Applicable'] WorkUnitViews. Topic:22. I was able to use the full range of my knowledge in my job ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' 'Strongly Disagree' nan 'Not Applicable'] WorkUnitViews. Topic:23. My job provided sufficient variety ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' nan 'Disagree' 'Not Applicable'] WorkUnitViews. Topic:24. I was able to cope with the level of stress and pressure in my job ['Agree' 'Strongly Agree' 'Neutral' 'Disagree' nan 'Not Applicable' 'Strongly Disagree'] WorkUnitViews. Topic:25. My job allowed me to balance the demands of work and family to my satisfaction ['Agree' 'Strongly Agree' 'Disagree' nan 'Neutral' 'Not Applicable' 'Strongly Disagree'] WorkUnitViews. Topic:26. My supervisor gave me adequate personal recognition and feedback on my performance ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' nan 'Disagree' 'Not Applicable'] WorkUnitViews. Topic:27. My working environment was satisfactory e.g. sufficient space, good lighting, suitable seating and working area ['Agree' 'Strongly Agree' 'Disagree' 'Neutral' nan 'Strongly Disagree' 'Not Applicable'] WorkUnitViews. Topic:28. I was given the opportunity to mentor and coach others in order for me to pass on my skills and knowledge prior to my cessation date ['Neutral' 'Agree' 'Strongly Agree' 'Strongly Disagree' nan 'Not Applicable' 'Disagree'] WorkUnitViews. Topic:29. There was adequate communication between staff in my unit ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' nan 'Not Applicable' 'Disagree'] WorkUnitViews. Topic:30. Staff morale was positive within my work unit ['Agree' 'Strongly Agree' 'Neutral' 'Strongly Disagree' nan 'Disagree' 'Not Applicable'] Induction. Did you undertake Workplace Induction? ['Yes' 'No' nan] InductionInfo. Topic:Did you undertake a Corporate Induction? ['Yes' nan 'No'] InductionInfo. Topic:Did you undertake a Institute Induction? ['Yes' nan 'No'] InductionInfo. Topic: Did you undertake Team Induction? ['Yes' nan 'No'] InductionInfo. Face to Face Topic:Did you undertake a Corporate Induction; Category:How it was conducted? ['Face to Face' nan '-'] InductionInfo. On-line Topic:Did you undertake a Corporate Induction; Category:How it was conducted? ['-' nan 'On-line'] InductionInfo. Induction Manual Topic:Did you undertake a Corporate Induction? ['-' nan 'Induction Manual'] InductionInfo. Face to Face Topic:Did you undertake a Institute Induction? ['Face to Face' nan '-'] InductionInfo. On-line Topic:Did you undertake a Institute Induction? ['-' nan 'On-line'] InductionInfo. Induction Manual Topic:Did you undertake a Institute Induction? ['-' nan 'Induction Manual'] InductionInfo. Face to Face Topic: Did you undertake Team Induction; Category? ['Face to Face' nan '-'] InductionInfo. On-line Topic: Did you undertake Team Induction?process you undertook and how it was conducted.] ['-' nan] InductionInfo. Induction Manual Topic: Did you undertake Team Induction? ['-' nan 'Induction Manual'] Workplace. Topic:Did you and your Manager develop a Performance and Professional Development Plan (PPDP)? ['Yes' 'No' nan] Workplace. Topic:Does your workplace promote a work culture free from all forms of unlawful discrimination? ['Yes' nan 'No'] Workplace. Topic:Does your workplace promote and practice the principles of employment equity? ['Yes' nan 'No'] Workplace. Topic:Does your workplace value the diversity of its employees? ['Yes' nan 'No'] Workplace. Topic:Would you recommend the Institute as an employer to others? ['Yes' nan 'No'] Gender. What is your Gender? ['Female' nan 'Male'] CurrentAge. Current Age ['26 – 30' nan '41 – 45' '56 or older' '20 or younger' '46 – 50' '36 – 40' '21 – 25' '51-55' '31 – 35'] Employment Type. Employment Type ['Temporary Full-time' nan 'Permanent Full-time' 'Contract/casual' 'Temporary Part-time' 'Permanent Part-time'] Classification. Classification ['Administration (AO)' nan 'Teacher (including LVT)' 'Tutor' 'Technical Officer (TO)' 'Professional Officer (PO)' 'Operational (OO)' 'Executive (SES/SO)' 'Workplace Training Officer' 'Apprentice'] LengthofServiceOverall. Overall Length of Service at Institute (in years) ['01-02' nan '03-Apr' '07-Oct' '01-Feb' 'Less than 1 year' 'Nov-20' '05-Jun' 'More than 20 years'] LengthofServiceCurrent. Length of Service at current workplace (in years) ['01-Feb' nan '03-Apr' '07-Oct' 'Less than 1 year' 'Nov-20' '05-Jun' 'More than 20 years']
Preliminary Observations
- Some of the column names in both dataframes are common or similar.
- Some of the column names are too long with repeating headings/classifiers.
- There are many columns with more than half the rows with missing values.
- Certain columns have missing values represented by fillers/literals such as "Not stated", "-"(hypen) etc.
- Columns such as "Cease Date", "Cessation Year" and "Current Age" have values in different formats or with extra literals.
- The survey response columns in DETE and TAFE have different values for the same response types. For example: DETE >> sa and TAFE >> "Strongly Agree"
*Conclusion* : Based on the assumed questions, columns which provide info about tenure of employment, factors leading to dissatisfaction and age of employees are most relevant from the dataframes and rest of columns can be dropped or ignored from analysis.
*Observations given as guided project worklow*
- The dete_survey dataframe contains 'Not Stated' values that indicate values are missing, but they aren't represented as NaN.
- Both the dete_survey and tafe_survey dataframes contain many columns that we don't need to complete our analysis.
- Each dataframe contains many of the same columns, but the column names are different.
- There are multiple columns/answers that indicate an employee resigned because they were dissatisfied.
Section 2 - Recreate dataframes with substitution for missing values
- Replace "Not Stated" in DETE dataframe with NaN
# read missing values as NaN-values into dataframe
dete_survey = pd.read_csv("dete_survey.csv", encoding="ascii", na_values="Not Stated")
# last 5 rows of DETE datset
dete_survey.tail()
| ID | SeparationType | Cease Date | DETE Start Date | Role Start Date | Position | Classification | Region | Business Unit | Employment Status | ... | Kept informed | Wellness programs | Health & Safety | Gender | Age | Aboriginal | Torres Strait | South Sea | Disability | NESB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 817 | 819 | Age Retirement | 02/2014 | 1977.0 | 1999.0 | Teacher | Primary | Central Queensland | NaN | Permanent Part-time | ... | A | A | SA | Female | 56-60 | NaN | NaN | NaN | NaN | NaN |
| 818 | 820 | Age Retirement | 01/2014 | 1980.0 | 1980.0 | Teacher | Secondary | North Coast | NaN | Permanent Full-time | ... | N | N | N | Male | 51-55 | NaN | NaN | NaN | NaN | NaN |
| 819 | 821 | Resignation-Move overseas/interstate | 01/2014 | 2009.0 | 2009.0 | Public Servant | A01-A04 | Central Office | Education Queensland | Permanent Full-time | ... | A | N | A | Female | 31-35 | NaN | NaN | NaN | NaN | NaN |
| 820 | 822 | Ill Health Retirement | 12/2013 | 2001.0 | 2009.0 | Teacher | Secondary | Darling Downs South West | NaN | Permanent Full-time | ... | A | N | A | Female | 41-45 | NaN | NaN | NaN | NaN | NaN |
| 821 | 823 | Resignation-Move overseas/interstate | 12/2013 | NaN | NaN | Teacher Aide | NaN | Metropolitan | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 56 columns
Drop columns that are not required as part of analysis
print("Shape of Dataframes before dropping columns:")
print("DETE: Rows ",dete_survey.shape[0]," | Columns ",dete_survey.shape[1])
print("TAFE: Rows ",tafe_survey.shape[0]," | Columns ",tafe_survey.shape[1],"\n")
# drop columns that are not required for analysis of exit survey
dete_survey_updated = dete_survey.drop(columns = dete_survey.columns[28:49], axis=1)
tafe_survey_updated = tafe_survey.drop(columns = tafe_survey.columns[17:66], axis=1)
print("Shape of Dataframes after dropping columns:")
print("DETE: Rows ",dete_survey_updated.shape[0]," | Columns ",dete_survey_updated.shape[1])
print("TAFE: Rows ",tafe_survey_updated.shape[0]," | Columns ",tafe_survey_updated.shape[1])
Shape of Dataframes before dropping columns: DETE: Rows 822 | Columns 56 TAFE: Rows 702 | Columns 72 Shape of Dataframes after dropping columns: DETE: Rows 822 | Columns 35 TAFE: Rows 702 | Columns 23
The columns which captured the survey responses, i.e. questionnaire answered by the employees, have been dropped from both the dataframes. This has been done as the analysis needs to be based on age, employment duration, and factors responsible for dissatisfaction.
Review updated dataframes using heatmaps
dete_survey_updated.set_index("ID")
fig, ax = plt.subplots(figsize=(17,10))
ax = sns.heatmap(dete_survey_updated.isnull(), cbar=False)
ax.set_yticks([])
ax.set_title("Data Presence and Abscence in DETE updated", fontsize=14)
plt.show()

tafe_survey_updated.set_index("Record ID")
fig, ax = plt.subplots(figsize=(17,10))
ax = sns.heatmap(tafe_survey_updated.isnull(), cbar=False)
ax.set_yticks([])
ax.set_title("Data Presence and Abscence in TAFE updated", fontsize=14)
plt.show()

Section 3 - Rename and Format column names
- Shorten column names that are too long and overworded
- Remove extra spaces/ literals from column names such as " ", "." etc.
- Standardize case for all the column names
- Replace spaces with underscores for better readability of multi-worded column names
# standardize column names for DETE
dete_survey_updated.columns = dete_survey_updated.columns.str.replace('.', ' ').str.replace('\s+', '_').str.strip().str.lower()
print("\33[1m"+"Cleaned column names in DETE:"+"\33[0m")
print(list(dete_survey_updated.columns))
Cleaned column names in DETE:
['id', 'separationtype', 'cease_date', 'dete_start_date', 'role_start_date', 'position', 'classification', 'region', 'business_unit', 'employment_status', 'career_move_to_public_sector', 'career_move_to_private_sector', 'interpersonal_conflicts', 'job_dissatisfaction', 'dissatisfaction_with_the_department', 'physical_work_environment', 'lack_of_recognition', 'lack_of_job_security', 'work_location', 'employment_conditions', 'maternity/family', 'relocation', 'study/travel', 'ill_health', 'traumatic_incident', 'work_life_balance', 'workload', 'none_of_the_above', 'gender', 'age', 'aboriginal', 'torres_strait', 'south_sea', 'disability', 'nesb']
# remove extra spaces from column names for TAFE
tafe_survey_updated.columns = tafe_survey_updated.columns.str.replace("\s+", " ").str.strip()
# rename column names for TAFE
cols_map = {'Record ID': 'id', 'CESSATION YEAR': 'cease_date', 'Reason for ceasing employment': 'separationtype',
'Gender. What is your Gender?': 'gender', 'CurrentAge. Current Age': 'age',
'Employment Type. Employment Type': 'employment_status', 'Classification. Classification': 'position',
'LengthofServiceOverall. Overall Length of Service at Institute (in years)': 'institute_service',
'LengthofServiceCurrent. Length of Service at current workplace (in years)': 'role_service'}
tafe_survey_updated.rename(cols_map, axis=1, inplace=True)
print("\33[1m"+"Cleaned column names in TAFE:"+"\33[0m")
print(list(tafe_survey_updated.columns))
Cleaned column names in TAFE:
['id', 'Institute', 'WorkArea', 'cease_date', 'separationtype', 'Contributing Factors. Career Move - Public Sector', 'Contributing Factors. Career Move - Private Sector', 'Contributing Factors. Career Move - Self-employment', 'Contributing Factors. Ill Health', 'Contributing Factors. Maternity/Family', 'Contributing Factors. Dissatisfaction', 'Contributing Factors. Job Dissatisfaction', 'Contributing Factors. Interpersonal Conflict', 'Contributing Factors. Study', 'Contributing Factors. Travel', 'Contributing Factors. Other', 'Contributing Factors. NONE', 'gender', 'age', 'employment_status', 'position', 'institute_service', 'role_service']
Section 4 - Filter and extract data
- Filter datarows having "Resignations" as value for "separationtype" column in TAFE dataframe
(For TAFE only one type exists >> "Resignations")
- For DETE dataframe, filter and extract, following values from "separationtype" column:
- Resignation-Other reasons
- Resignation-Other employer
- Resignation-Move overseas/interstate
- For DETE dataframe, standardize all resignations types as "Resignation" to have uniform value for "separationtype" column
# value count for values present in separationtype column in dete dataset
print("\33[1m"+"Reasons for Sepration in DETE"+"\33[0m")
print(dete_survey_updated["separationtype"].value_counts(dropna=False))
Reasons for Sepration in DETE
Age Retirement 285
Resignation-Other reasons 150
Resignation-Other employer 91
Resignation-Move overseas/interstate 70
Voluntary Early Retirement (VER) 67
Ill Health Retirement 61
Other 49
Contract Expired 34
Termination 15
Name: separationtype, dtype: int64
# value count for values present in separationtype column in tafe dataset
print("\33[1m"+"Reasons for Sepration in TAFE"+"\33[0m")
print(tafe_survey_updated["separationtype"].value_counts(dropna=False))
Reasons for Sepration in TAFE
Resignation 340
Contract Expired 127
Retrenchment/ Redundancy 104
Retirement 82
Transfer 25
Termination 23
NaN 1
Name: separationtype, dtype: int64
Segregate datarows based on separation type: Non-resignations and Resignations
# to suppress the UserWarning
import warnings
warnings.filterwarnings("ignore", 'This pattern has match groups')
search_pattern = r"([Rr]esignation)"
dete_resignations = dete_survey_updated[dete_survey_updated["separationtype"].str.contains(search_pattern) == True]
dete_non_resignations = dete_survey_updated[dete_survey_updated["separationtype"].str.contains(search_pattern) == False]
tafe_resignations = tafe_survey_updated[tafe_survey_updated["separationtype"].str.contains(search_pattern) == True]
tafe_non_resignations = tafe_survey_updated[tafe_survey_updated["separationtype"].str.contains(search_pattern) == False]
print(dete_resignations["separationtype"].value_counts(dropna=False),"\n")
print(tafe_resignations["separationtype"].value_counts(dropna=False),"\n")
Resignation-Other reasons 150 Resignation-Other employer 91 Resignation-Move overseas/interstate 70 Name: separationtype, dtype: int64 Resignation 340 Name: separationtype, dtype: int64
# to avoide the SettingWithCopyWarning copy() method has been used
dete_resignations = dete_resignations.copy()
# update all the resignation types to one value as "Resignation"
dete_resignations["separationtype"] = dete_resignations["separationtype"].str.split("-").str[0]
print("\33[1m"+"dete resignations total"+"\33[0m")
print(dete_resignations["separationtype"].value_counts())
dete resignations total
Resignation 311
Name: separationtype, dtype: int64
Section 5 - Cleanse data that is present in inconsistent format
- Identify the values in "cease_date" and "dete_start_date" columns that differ from the year values
- Split and format the values to follow a "YYYY" pattern
- Visualize the two columns data using a box plot, to identify major outliers
# value count for all the values in cease_date column in DETE datset including null values
dete_resignations["cease_date"].value_counts(dropna=False).sort_values(ascending=False)
# dete_resignations[dete_resignations["cease_date"].isnull() == True]
2012 126 2013 74 01/2014 22 12/2013 17 06/2013 14 NaN 11 09/2013 11 07/2013 9 11/2013 9 10/2013 6 08/2013 4 05/2013 2 05/2012 2 07/2012 1 2010 1 09/2010 1 07/2006 1 Name: cease_date, dtype: int64
# year pattern to be searched
year_pattern = r"([2][0-9]{3})"
# update cease_date values as year extracted
dete_resignations["cease_date"] = dete_resignations["cease_date"].str.extract(year_pattern, expand = False).astype(float).copy()
# recheck value count of years present in cease_date column
dete_resignations["cease_date"].value_counts(dropna=False)
2013.0 146 2012.0 129 2014.0 22 NaN 11 2010.0 2 2006.0 1 Name: cease_date, dtype: int64
# catch invalid years in dete_start_date column
dete_resignations["dete_start_date"].value_counts(dropna=False).sort_index()
1963.0 1 1971.0 1 1972.0 1 1973.0 1 1974.0 2 1975.0 1 1976.0 2 1977.0 1 1980.0 5 1982.0 1 1983.0 2 1984.0 1 1985.0 3 1986.0 3 1987.0 1 1988.0 4 1989.0 4 1990.0 5 1991.0 4 1992.0 6 1993.0 5 1994.0 6 1995.0 4 1996.0 6 1997.0 5 1998.0 6 1999.0 8 2000.0 9 2001.0 3 2002.0 6 2003.0 6 2004.0 14 2005.0 15 2006.0 13 2007.0 21 2008.0 22 2009.0 13 2010.0 17 2011.0 24 2012.0 21 2013.0 10 NaN 28 Name: dete_start_date, dtype: int64
dete_resignations.boxplot(column=["cease_date"])
plt.show()

dete_resignations.boxplot(column=["dete_start_date"])
plt.show()

print(tafe_resignations["cease_date"].value_counts(dropna=False))
tafe_resignations.boxplot(column="cease_date")
plt.show()
2011.0 116 2012.0 94 2010.0 68 2013.0 55 NaN 5 2009.0 2 Name: cease_date, dtype: int64

Based on the results, following are some observations:
- For DETE dataframe, maximum resignations happend in the year 2013 and the oldest year in "cease_date" column is 2016.
- "dete_start_date" column does not have any years before 1963 in DETE
- Missing value count in "cease_date" and "dete_start_date" column are 11 and 28 respectively.
- For TAFE dataframe, oldest year is 2009 and year 2011 indicates maximum resignations
- 5 values are missing for TAFE.
Conclusion - Since the years are not that far from each other in both the dataframes, all the years have been considered for the analysis.
Section 6 - Calculate number of years of service
- For TAFE dataframe, the column "institute_service" provides information about total service years
- For DETE dataframe, calculate the years served as difference of "cease_date" and "dete_start_date" columns
- Label the new column as "institute_service" for DETE dataframe as well
# new column institute_service in dete_resginations with calculated service years
dete_resignations["institute_service"] = dete_resignations["cease_date"] - dete_resignations["dete_start_date"]
dete_resignations["institute_service"].value_counts(dropna=False).sort_index(ascending=True).head(10)
0.0 20 1.0 22 2.0 14 3.0 20 4.0 16 5.0 23 6.0 17 7.0 13 8.0 8 9.0 14 Name: institute_service, dtype: int64
Section 7 - Segregate employees who have resigned due to dissatisfication with work
- Convert the values present in dissatisfaction columns in each dataset to a bool value "True" or "False"
- Add a new column "dissatisfied" to each of the dataframe to identify the following:
- True: indicates a person resigned because they were dissatisfied with the job
- False: indicates a person resigned because of a reason other than dissatisfaction with the job
- NaN: indicates the value is missing
# Columns selected for the section (as per guided project)
tafe_diss_cols = ["Contributing Factors. Dissatisfaction", "Contributing Factors. Job Dissatisfaction"]
dete_diss_cols = ["job_dissatisfaction", "dissatisfaction_with_the_department", "physical_work_environment", "lack_of_recognition",
"lack_of_job_security", "work_location", "employment_conditions", "work_life_balance", "workload"]
print("\33[1m"+"Initial value count for TAFE dataframe dissatisfaction columns"+"\33[0m")
for each_col in tafe_diss_cols:
print(tafe_resignations[each_col].value_counts(dropna=False),"\n")
# update values present in dissatisfaction columns to True, False and NaN
# define function update_vals to convert dissatisfaction values
def update_vals(vals):
if pd.isnull(vals) == True:
return np.nan
elif vals == "-":
return False
else:
return True
# use applymap method to apply the update_vals function to TAFE dissatisfaction columns
tafe_resignations = tafe_resignations.copy()
tafe_resignations[tafe_diss_cols] = tafe_resignations[tafe_diss_cols].applymap(update_vals)
print("\33[1m"+"Updated value count for TAFE dataframe dissatisfaction columns"+"\33[0m")
for each_col in tafe_diss_cols:
print(tafe_resignations[each_col].value_counts(dropna=False),"\n")
Initial value count for TAFE dataframe dissatisfaction columns - 277 Contributing Factors. Dissatisfaction 55 NaN 8 Name: Contributing Factors. Dissatisfaction, dtype: int64 - 270 Job Dissatisfaction 62 NaN 8 Name: Contributing Factors. Job Dissatisfaction, dtype: int64 Updated value count for TAFE dataframe dissatisfaction columns False 277 True 55 NaN 8 Name: Contributing Factors. Dissatisfaction, dtype: int64 False 270 True 62 NaN 8 Name: Contributing Factors. Job Dissatisfaction, dtype: int64
# create new column from dissatisfaction columns based on value match
tafe_resignations["dissatisfied"] = tafe_resignations[tafe_diss_cols].any(axis=1, skipna=False)
dete_resignations["dissatisfied"] = dete_resignations[dete_diss_cols].any(axis=1, skipna=False)
print("resigned due to dissatisfaction TAFE:")
print(tafe_resignations["dissatisfied"].value_counts(dropna=False),"\n")
print("resigned due to dissatisfaction DETE:")
print(dete_resignations["dissatisfied"].value_counts(dropna=False),"\n")
resigned due to dissatisfaction TAFE: False 241 True 91 NaN 8 Name: dissatisfied, dtype: int64 resigned due to dissatisfaction DETE: False 162 True 149 Name: dissatisfied, dtype: int64
# create copy of both datasets as new dataframes
dete_resignations_up = dete_resignations.copy()
tafe_resignations_up = tafe_resignations.copy()
print("DETE updated dataframe shape:", dete_resignations_up.shape)
print("TAFE updated dataframe shape:", tafe_resignations_up.shape)
DETE updated dataframe shape: (311, 37) TAFE updated dataframe shape: (340, 24)
Section 8 - Combine dataframes DETE and TAFE into one
- Combine both dataframes to one
- Remove the non-essential columns from the combined dataframe
- Apply aggregation on "institute_service" column to perform analysis by years served
# add additional column to each dataset which marks the dataset as values
dete_resignations_up["institute"] = "DETE"
tafe_resignations_up["institute"] = "TAFE"
# combine the datasets DETE and TAFE by row
combined = pd.concat([dete_resignations_up, tafe_resignations_up], axis=0, ignore_index=True, sort=False)
print("combined shape:",combined.shape)
combined shape: (651, 53)
# drop columns which have more than 500 null values
combined_updated = combined.dropna(thresh=500, axis=1)
combined_updated.isnull().sum()
id 0 separationtype 0 cease_date 16 position 53 employment_status 54 gender 59 age 55 institute_service 88 dissatisfied 8 institute 0 dtype: int64
Section 9 - Classify duration of service as Experience categories
- Modify values in "institute_service" column, as categorical employment duration
- Classify employment duration in career stages as below:
- New: Less than 3 years at a company
- Experienced: 3-6 years at a company
- Established: 7-10 years at a company
- Veteran: 11 or more years at a company
#unique values in combined dataset for column institute_service
combined_updated["institute_service"].value_counts().sort_values(ascending=False)
Less than 1 year 73 01-Feb 64 03-Apr 63 05-Jun 33 Nov-20 26 5.0 23 1.0 22 07-Oct 21 3.0 20 0.0 20 6.0 17 4.0 16 9.0 14 2.0 14 7.0 13 More than 20 years 10 13.0 8 8.0 8 20.0 7 15.0 7 10.0 6 14.0 6 17.0 6 12.0 6 22.0 6 18.0 5 16.0 5 24.0 4 23.0 4 11.0 4 32.0 3 39.0 3 19.0 3 21.0 3 30.0 2 28.0 2 26.0 2 25.0 2 36.0 2 38.0 1 27.0 1 29.0 1 33.0 1 41.0 1 34.0 1 49.0 1 35.0 1 42.0 1 31.0 1 Name: institute_service, dtype: int64
# correct the values which have month name instead of number range. For example, 01-Feb should be 1-2, Nov-20 should be 11-20
correct_range = {"01-Feb":"1-2", "03-Apr":"3-4", "05-Jun":"5-6", "07-Oct":"7-8", "Nov-20":"11-20"}
combined_updated = combined_updated.copy()
combined_updated["institute_service"] = combined_updated["institute_service"].replace(correct_range)
combined_updated["institute_service"].value_counts(dropna=False).sort_values(ascending=False)
NaN 88 Less than 1 year 73 1-2 64 3-4 63 5-6 33 11-20 26 5.0 23 1.0 22 7-8 21 0.0 20 3.0 20 6.0 17 4.0 16 2.0 14 9.0 14 7.0 13 More than 20 years 10 8.0 8 13.0 8 15.0 7 20.0 7 14.0 6 10.0 6 12.0 6 17.0 6 22.0 6 18.0 5 16.0 5 24.0 4 11.0 4 23.0 4 19.0 3 21.0 3 32.0 3 39.0 3 30.0 2 36.0 2 25.0 2 28.0 2 26.0 2 33.0 1 29.0 1 34.0 1 35.0 1 27.0 1 41.0 1 42.0 1 49.0 1 38.0 1 31.0 1 Name: institute_service, dtype: int64
# exract numeric value from each of the rows of "institute_service" column
combined_updated["institute_service"] = combined_updated["institute_service"].astype(str).str.split("-").str[0].str.extract(r"(\d+)").astype("float")
combined_updated["institute_service"].value_counts(dropna=False).sort_values(ascending=False)
1.0 159 NaN 88 3.0 83 5.0 56 7.0 34 11.0 30 0.0 20 6.0 17 20.0 17 4.0 16 9.0 14 2.0 14 13.0 8 8.0 8 15.0 7 22.0 6 10.0 6 17.0 6 14.0 6 12.0 6 16.0 5 18.0 5 23.0 4 24.0 4 21.0 3 39.0 3 32.0 3 19.0 3 26.0 2 36.0 2 30.0 2 25.0 2 28.0 2 41.0 1 34.0 1 38.0 1 49.0 1 33.0 1 27.0 1 35.0 1 29.0 1 42.0 1 31.0 1 Name: institute_service, dtype: int64
# replace the year number with catergory definitions
# define function which would take each year and convert to experience category
def year_to_cats(year_val):
if year_val < 3.0:
return "New"
elif 3.0 <= year_val <= 6.0:
return "Experienced"
elif 7.0 <= year_val <= 10.0:
return "Established"
elif pd.isnull(year_val):
return np.nan
else:
return "Veteran"
combined_updated["service_cat"] = combined_updated["institute_service"].apply(year_to_cats)
print("Career Stages:")
print(combined_updated["service_cat"].value_counts())
Career Stages: New 193 Experienced 172 Veteran 136 Established 62 Name: service_cat, dtype: int64
Section 10 - Initial Analysis
- Identify relation between % of dissatisfied employees with the duration served at the company
# confirm values in "dissatisfied" column:
combined_updated["dissatisfied"].value_counts(dropna=False)
False 403 True 240 NaN 8 Name: dissatisfied, dtype: int64
# fill in "dissatisfied" column
combined_updated["dissatisfied"] = combined_updated["dissatisfied"].fillna(False)
combined_updated["dissatisfied"].value_counts(dropna=False)
False 411 True 240 Name: dissatisfied, dtype: int64
combined_pv = combined_updated.pivot_table(index="service_cat", values="dissatisfied", margins=True)
combined_pv = combined_pv.reset_index()
combined_pv
| service_cat | dissatisfied | |
|---|---|---|
| 0 | Established | 0.516129 |
| 1 | Experienced | 0.343023 |
| 2 | New | 0.295337 |
| 3 | Veteran | 0.485294 |
| 4 | All | 0.380107 |
ax = combined_pv.plot(kind="bar", x="service_cat", y="dissatisfied", rot=0, figsize=(8,6), fontsize=10, width=0.5)
ax.set_xlabel("Service Category", fontsize="x-large")
ax.set_ylabel("Mean Percentage (%)", fontsize="x-large")
ax.set_title("Employee Experience vs % of Dissatisfied Employees", fontsize="xx-large")
ax.tick_params(bottom=False, top=False, left=False, right=False)
ax.set_ylim(0,0.6)
ax.set_yticks([])
for each_sp in ax.spines:
ax.spines[each_sp].set_visible(False)
for p in ax.patches:
ax.annotate(str(round(p.get_height(),3)), (p.get_x()+.1, p.get_height()*1.02), fontsize="large", fontweight="demibold")
plt.show()

Initial analysis compares the percentage of employees who have resigned due to some dissatisfaction with their job, with the service experience they have had at the company.
Based on these results, it appears that the maximum resignations came from employees who have already *been working for more than 7 years.*
The next category with maximum resignations due to dissatisfaction came from employees who had been working with the company for *over a decade.*
Answer to first question of the project - Higher number of established and veteran employees have reasoned "Dissatisfaction" with their job as a cause of leaving employment as compared to new employees.
Additional Exercises
1. Decide how to handle the rest of the missing values. Then, aggregate the data according to the service_cat column again. How many people in each career stage resigned due to some kind of dissatisfaction?
- Copy combined_updated dataframe (from initial analysis) to combined_addex dataframe
(this is to maintain the dataframe with the initial analysis)
- Visualize the gaps created by missing values in the column "institute_service" using appropriate plot
- Identify the proportion of datarows with missing values, in comparison to the whole dataframe
- Apply "Interpolate()" method on "institute_service" column
- Compare the effects on interpolation on "dissatisfied" % vs the service experience categories
# copy combined_updated dataframe to combined_addex
combined_addex = combined_updated.copy()
# percentage of datarows with missing values in "institute_service" column
print("Does the datarow has missing values?")
print(combined_updated["service_cat"].isnull().value_counts(normalize=True).mul(100).round(2))
Does the datarow has missing values? False 86.48 True 13.52 Name: service_cat, dtype: float64
The datarows for which "institute_service" column has no data, constitute 13.52% of total datarows in combined_updated dataframe.
combined_addex["institute_service"].value_counts(dropna=False).sort_values()
sns.set_style("white")
fig, ax = plt.subplots(figsize=(18,3))
ax = combined_addex["institute_service"].plot.line(linewidth=1.5)
ax.set_xlim(-30, 670)
ax.set_title("Years Served as Line Plot", fontsize="xx-large")
for key, each_spine in ax.spines.items():
each_spine.set_visible(False)
plt.show()
fig, ax = plt.subplots(figsize=(18,3))
ax = combined_addex["institute_service"].plot.line(linewidth=1.5)
ax.set_xlim(500, 660)
ax.set_title("Years Served as Line Plot (zoomed for index 500 to 650)", fontsize="xx-large")
for key, each_spine in ax.spines.items():
each_spine.set_visible(False)
plt.show()
# the sns.lineplot gives interpolated graph by default
# fig, ax = plt.subplots(figsize=(18,5))
# ax = sns.lineplot(data=combined_updated["institute_service"], palette="tab10", linewidth=2)
# plt.show()


combined_addex["institute_service"] = combined_addex["institute_service"].interpolate()
fig, ax = plt.subplots(figsize=(18,3))
ax = combined_addex["institute_service"].plot.line(linewidth=1.5)
ax.set_xlim(-30, 670)
ax.set_title("Years Served as Line Plot after Interpolation method is applied", fontsize="xx-large")
for key, each_spine in ax.spines.items():
each_spine.set_visible(False)
plt.show()
fig, ax = plt.subplots(figsize=(18,3))
ax = combined_addex["institute_service"].plot.line(linewidth=1.5)
ax.set_xlim(500, 660)
ax.set_title("Years Served as Line Plot after Interpolation method is applied (zoomed for index 500 to 650)",
fontsize="xx-large")
for key, each_spine in ax.spines.items():
each_spine.set_visible(False)
plt.show()


combined_addex["service_cat"] = combined_addex["institute_service"].apply(year_to_cats)
print("Career Stages:")
print(combined_addex["service_cat"].value_counts(dropna=False))
Career Stages: New 214 Experienced 202 Veteran 163 Established 72 Name: service_cat, dtype: int64
combined_addex.set_index("id")
fig, ax = plt.subplots(figsize=(12,8))
ax = sns.heatmap(combined_addex.isnull(), cbar=False)
ax.set_yticks([])
ax.set_title("Combined DETE and TAFE after Interpolate", fontsize=14)
plt.show()

addex_pv = combined_addex.pivot_table(index="service_cat", values="dissatisfied", margins=True)
addex_pv = addex_pv.reset_index()
combine_addex = pd.concat([combined_pv,addex_pv], keys=("Combined","Add-Ex"), ignore_index=False, sort=False)
combine_addex = combine_addex.reset_index()
combine_addex = combine_addex.drop(columns=["level_1"])
combine_addex = combine_addex.rename(columns={"level_0":"dataset"})
combine_addex
| dataset | service_cat | dissatisfied | |
|---|---|---|---|
| 0 | Combined | Established | 0.516129 |
| 1 | Combined | Experienced | 0.343023 |
| 2 | Combined | New | 0.295337 |
| 3 | Combined | Veteran | 0.485294 |
| 4 | Combined | All | 0.380107 |
| 5 | Add-Ex | Established | 0.472222 |
| 6 | Add-Ex | Experienced | 0.336634 |
| 7 | Add-Ex | New | 0.299065 |
| 8 | Add-Ex | Veteran | 0.453988 |
| 9 | Add-Ex | All | 0.368664 |
sns.catplot(kind="bar", x="service_cat", y="dissatisfied", hue="dataset", data=combine_addex,
margin_titles=True, height=4, aspect=2, saturation=.7, legend=False, legend_out=True)
sns.despine(top=True, left=True, right=True, bottom=True)
plt.title("Implications of Interpolate on Years served by Career stage", fontsize="xx-large")
plt.xlabel("Service Category", fontsize="x-large")
plt.ylabel("% of Dissatisfied Employees", fontsize="x-large")
plt.ylim([0,0.6])
plt.yticks([0,0.6])
plt.legend(loc="center right", bbox_to_anchor=(1.3, 0.5), title="Datafames", fontsize="large")
plt.show()

The comparison chart, shows that interpolation has caused the % of dissatisfied employees to decrease for all the career stages except for "New" employees, although the increase is nominal.
Following table shows, the difference in % of dissatisfied employees for each career stage:

2. Clean the age column. How many people in each age group resgined due to some kind of dissatisfaction?
- Remove spaces/ extra characters from "age" column in combined_addex dataframe
- Replace the "age" column values which do not have proper range format
> For exmple: 56 or older to 56-60 since the last data value is 60 or older
- Calculate count of employees in each age group who have resigned from employment due to dissatisfaction
- Identify the age-group which has the maximum count of resignations
- Visualize the number of resignations for each age-group
- Calculate count of employees in each career stage, for each age group who have resigned from employment due to dissatisfaction
- Visualize number of resignations by career stage for each age-group
combined_addex["age"].value_counts(dropna=False).sort_index()
20 or younger 10 21 – 25 33 21-25 29 26 – 30 32 26-30 35 31 – 35 32 31-35 29 36 – 40 32 36-40 41 41 – 45 45 41-45 48 46 – 50 39 46-50 42 51-55 71 56 or older 29 56-60 26 61 or older 23 NaN 55 Name: age, dtype: int64
combined_addex["age"] = combined_addex["age"].str.replace(" – ","-").str.replace("56 or older","56-60")
combined_addex["age"].value_counts(dropna=False).sort_values(ascending=False)
age_pv = combined_addex.pivot_table(index="age", values="dissatisfied", aggfunc=np.sum)
age_pv = age_pv.reset_index()
age_pv
| age | dissatisfied | |
|---|---|---|
| 0 | 20 or younger | 2.0 |
| 1 | 21-25 | 19.0 |
| 2 | 26-30 | 28.0 |
| 3 | 31-35 | 23.0 |
| 4 | 36-40 | 25.0 |
| 5 | 41-45 | 35.0 |
| 6 | 46-50 | 31.0 |
| 7 | 51-55 | 30.0 |
| 8 | 56-60 | 21.0 |
| 9 | 61 or older | 12.0 |
As evident from the value count, the employess belonging to age-group "41-45" show maximum resignations.
Visualize employee resignations due to dissatisfaction
fig,ax = plt.subplots(figsize=(12,5.5))
sns.barplot(ax=ax, x="age", y="dissatisfied", data=age_pv, palette="Blues_d", order=age_pv["age"])
sns.despine(left=True, bottom=False)
ax.set_yticks([])
ax.set_xlabel("Age Group", fontsize="x-large")
ax.set_ylabel("")
ax.set_title("Age-Group wise Number of Employee Resignations", fontsize="xx-large")
for p in ax.patches:
ax.annotate(str(p.get_height()), (p.get_x()+.3, p.get_height()*1.01), fontsize="large", fontweight="demibold")
plt.show()
# sns.plotting_context()

age_cat_pv = combined_addex.pivot_table(index=["age", "service_cat"], values="dissatisfied", aggfunc=np.sum)
age_cat_pv = age_cat_pv.reset_index()
age_cat_pv = age_cat_pv.pivot(index="age", columns="service_cat", values="dissatisfied")
age_cat_pv = age_cat_pv.reset_index()
age_cat_pv
| service_cat | age | Established | Experienced | New | Veteran |
|---|---|---|---|---|---|
| 0 | 20 or younger | NaN | 1.0 | 1.0 | NaN |
| 1 | 21-25 | 0.0 | 6.0 | 11.0 | 2.0 |
| 2 | 26-30 | 7.0 | 13.0 | 8.0 | 0.0 |
| 3 | 31-35 | 9.0 | 6.0 | 6.0 | 2.0 |
| 4 | 36-40 | 4.0 | 9.0 | 8.0 | 4.0 |
| 5 | 41-45 | 4.0 | 12.0 | 7.0 | 12.0 |
| 6 | 46-50 | 4.0 | 7.0 | 7.0 | 13.0 |
| 7 | 51-55 | 3.0 | 4.0 | 7.0 | 16.0 |
| 8 | 56-60 | 2.0 | 3.0 | 2.0 | 14.0 |
| 9 | 61 or older | 1.0 | 1.0 | NaN | 10.0 |
x = age_cat_pv[["age", "Established", "Experienced", "New", "Veteran"]]
y = x.set_index("age")
z = y.groupby("age").sum()
ax = z.plot(kind="bar", stacked=True, figsize=(14,6), width=0.5, rot=0)
ax.legend(loc="upper right", fontsize="large")
ax.set_title("Resignations due to Dissatifaction by Service Category across Age-Groups", fontsize="xx-large")
ax.set_xlabel("Age Group", fontsize="x-large")
ax.set_ylabel("Resignations", fontsize="x-large")
plt.show()

Although the age-group "41-45" show maximum resignations overall, the higher age-groups show maximum number of resignations from the Veteran employees. In the case of new employees, the maximum resignations were given by employess in the age-group 21-25.
Following chart lists the value projected above (top values have been highlighted):

3. Instead of analyzing the survey results together, analyze each survey separately. Did more employees in the DETE survey or TAFE survey end their employment because they were dissatisfied in some way?
- Visualize share of employee resignations based on dissatisfaction, for each institute
institute_group = combined_addex.groupby("institute")
institute_group = institute_group["dissatisfied"].value_counts(normalize=True).mul(100).unstack()
ax = institute_group.plot(kind='barh', figsize=[10,3], stacked=True, legend=False)
ax.set_ylabel("Institute", fontsize="x-large", rotation=0)
ax.set_xlabel("Resignations due to Dissatisfaction", fontsize="x-large")
ax.legend(loc="center right", bbox_to_anchor=(1.2,0.5), fontsize=12)
ax.set_title("Overall Resignations at Institutes", fontsize="xx-large")
# ax.yaxis.set_tick_params(rotation=0)
for p in ax.patches:
left, bottom, width, height = p.get_bbox().bounds
ax.annotate(str(round(width,2)), xy=(left+width/2, bottom+height/2),
ha='center', va='center', fontsize=12, color="white", fontweight="demibold")
plt.show()

Comparison between number of resignations between the two datasets, reveal that the maximum resignations (proportionately to the data for respective dataset) due to dissatisfactions are in DETE.
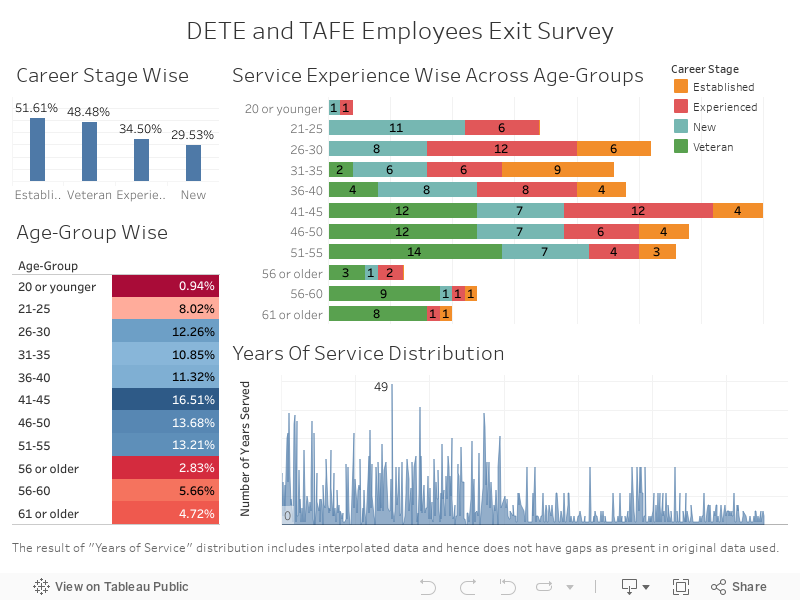
Visualizing Employee Exit Survey Data in Tableau
%%HTML
<div class='tableauPlaceholder' id='viz1584007055090' style='position: relative'><noscript><a href='#'><img alt=' ' src='https://public.tableau.com/static/images/Ex/ExitSurveyDETETAFE/ExitSurvey/1_rss.png' style='border: none' /></a></noscript><object class='tableauViz' style='display:none;'><param name='host_url' value='https%3A%2F%2Fpublic.tableau.com%2F' /> <param name='embed_code_version' value='3' /> <param name='site_root' value='' /><param name='name' value='ExitSurveyDETETAFE/ExitSurvey' /><param name='tabs' value='no' /><param name='toolbar' value='yes' /><param name='static_image' value='https://public.tableau.com/static/images/Ex/ExitSurveyDETETAFE/ExitSurvey/1.png' /> <param name='animate_transition' value='yes' /><param name='display_static_image' value='yes' /><param name='display_spinner' value='yes' /><param name='display_overlay' value='yes' /><param name='display_count' value='yes' /></object></div> <script type='text/javascript'> var divElement = document.getElementById('viz1584007055090'); var vizElement = divElement.getElementsByTagName('object')[0]; if ( divElement.offsetWidth > 800 ) { vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px';} else if ( divElement.offsetWidth > 500 ) { vizElement.style.width='100%';vizElement.style.height=(divElement.offsetWidth*0.75)+'px';} else { vizElement.style.width='100%';vizElement.style.height='1327px';} var scriptElement = document.createElement('script'); scriptElement.src = 'https://public.tableau.com/javascripts/api/viz_v1.js'; vizElement.parentNode.insertBefore(scriptElement, vizElement); </script>