- 1 Historical high water levels of the river Ahr
- 1.1 Pegel Altenahr
- 1.2 Precipitation data
- 1.3 High water level events of the Ahr
- 1.4 Main tributaries of the Ahr
- 1.4.1 Water levels of tributaries
- 1.4.2 Discharge levels of tributaries
- 1.4.3 The total sum of discharge of 4 principal tributaries.
- 1.4.4 Discharge - waterlevel curve for Kirmutscheid
- 1.4.5 Estimation of the volume of water/sec for a water level of 9.5 meter.
- 1.4.6 Measurement stations of the Ahr and its tributaries.
- 1.5 "Highest measurements" since 1946 vs. the catastrophic flood 14-07-2021
- 1.6 Conclusions
- 1.7 Flood Analysis with Log-Pearson Type III Distribution
- 1.8 Fit several distributions
Historical high water levels of the river Ahr¶
Topic: The purpose of this document is to provide some info about what was the situation that led to the "100-year" flood event of the river Ahr in Germany.
In a follow up document we'll try to answer: "Why was the "100-year" flood event of the river Ahr in Germany on 14-15th July 2021 so catastrophic?"
Author: Van Oproy Kurt
Preliminary notes¶
- The discharge values are the calculated daily or hourly averages, based on the water level measurement.
- The datasets with hourly averages contain only data of the last 31 days.
- The data and descriptions in historical records of similar floods had not been included in the top 10 high water dataset for making predictions.
- The data which the RLP administration for environment used, had only a timespan going back 75 years. Or much less.
- The rainfall amounts of 150-180 mm per day, which in some places occured in a few hours time, were predicted in time.
- Some of the hydrometers broke down before the peak flow. One measurestation was completely washed away.
- Some stations had direct communication links, but they broke down with the collapse of the telecom and electricity infrastructure.
- So, the early warning system was partly cut down before the peak flow.
- Nonetheless, I found 1 station that had all the values of the peak wave, so I'll try to construct a discharge curve of the composite water mass.
References¶
- Reconstructing peak discharges of historic floods of the river Ahr, Germany, 2014-01-05, Thomas Roggenkamp and Jürgen Herget
- Ahr-Hochwasser am 12. 13. Juni 1910 forderte 52 Menschenleben, Leonhard Janta, Helmut Poppelreuter, Heimatjahrbuch Kreis Ahrweiler 2010
- Ahrserie_Katastrophen_28_Juni_2014.pdf, NR. 139. MITTWOCH 18 JUNI 2014, Rhein-Zeitung Epaper - Mittelrhein-Verlag, Koblenz,Germany, Petra Ochs
- Die Ahr und ihre Hochwässer in alten Quellen. Karl August Seel, Heimatjahrbuch des Kreises Ahrweiler 40, 1983
- Das Hochwasser von 1804 im Kreise Ahrweiler, Dr. Hans FRICK, hjb1955
- This was an update of his original publication from 1929.
- Das Naturschutzgebiet Ahrschleife bei Altenahr, Teil 2, Büchs, W.
- Floods in Germany - Analyses of Trends, T. Petrow: Dr. diss.
- Characteristics and process controls of statistical flood moments in Europe – a data based analysis, 2020, David Lun, Alberto Viglione, Miriam Bertola, Jürgen Komma, Juraj Parajka1, Peter Valent, Günter Blöschl, https://doi.org/10.5194/hess-2020-600
- RLP administration for environment
Post-flood event references¶
- Hochwasser Mitteleuropa, Juli 2021 (Deutschland), CEDIM Forensic Disaster Analysis (FDA) Group, 21. Juli 2021 – Bericht Nr. 1 "Nordrhein-Westfalen & Rheinland-Pfalz"
- Déjà-vu der Katastrophe, OLIVER SCHLÖMER, JENS GIESEL und MANFRED LINDINGER · 5. August 2021
- Katastrophale Hochwasser im Ahrtal 2021, 1910, 1804, 1719 und 1601, reitschuster.de
Slope of the steep hill at Dernau¶
(300-160)/518
0.2702702702702703
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
sns.set()
sns.set_context('notebook')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 57
pd.options.display.max_columns = 38
pd.set_option('precision', 2)
from IPython.display import Image, display
%config InlineBackend.figure_format = 'retina'
from IPython.core.display import display, HTML
display(HTML("<style>.container {width:72% !important;}</style>"))
%autosave 400
Ahr =pd.read_csv(r"Ahr Aktuelle Wasserstände.csv",sep="\t", skiprows=2,usecols=[1,2],index_col=0,na_values= "-"); # header=0,sep=\";\",\n",
Ahr.index = pd.to_datetime(Ahr.index, format="%d.%m.%Y %H:%M") # parse_dates=["Datum"]
Abfluss =pd.read_csv(r"Ahr Abfluss.csv",sep="\t", index_col=1,na_values= "-",decimal=","); #parse_dates=["Datum"],
Abfluss.index = pd.to_datetime(Abfluss.index, format="%d.%m.%Y %H:%M")
Ahr.head(10)
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-24 17:15:00 | 59.0 |
| 2021-06-24 17:30:00 | 60.0 |
| 2021-06-24 17:45:00 | 60.0 |
| 2021-06-24 18:00:00 | 60.0 |
| 2021-06-24 18:15:00 | 60.0 |
| 2021-06-24 18:30:00 | 60.0 |
| 2021-06-24 18:45:00 | 61.0 |
| 2021-06-24 19:00:00 | 62.0 |
| 2021-06-24 19:15:00 | 62.0 |
| 2021-06-24 19:30:00 | 62.0 |
Pegel Altenahr¶
Ahr.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 2204 entries, 2021-06-24 17:15:00 to 2021-07-25 16:00:00 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Wasserstand in cm 2059 non-null float64 dtypes: float64(1) memory usage: 34.4 KB
Ahrstats =pd.read_csv(r"Ahr.csv", skiprows=2,sep="\t",index_col=0,decimal="," ,);
Hochwasser =pd.read_csv(r"AhrHochwasserereignisse19462019.csv",parse_dates=["Datum"],skiprows=2,sep="\t",index_col=1,decimal=",",
engine='python'); #skipfooter=1
#floods[\"Date\"] = pd.to_datetime( River_Arno.Date, format='%d/%m/%Y' ) # euro dates\n",
#floods.set_index(\"Date\", inplace=True)\n",
Ahrstats.head(10)
| Abfluss [m³/s] | Abflussspende [l/s km²] | |
|---|---|---|
| Jährlichkeiten | ||
| 2 | 93.5 | 125 |
| 5 | 125.0 | 168 |
| 10 | 149.0 | 200 |
| 20 | 176.0 | 236 |
| 25 | 185.0 | 248 |
| 50 | 212.0 | 284 |
| 100 | 241.0 | 323 |
Since the calibration curve for the high water levels to estimate the interval of a "100 year flood" is actually based on a shorter period, in fact 1946-2019, we have to correct the timespan accordingly...
Ahrstats["days"]=Ahrstats.index*365
#Ahrstats["year"]= Ahrstats.Jährlichkeiten
Ahrstats["years"]= Ahrstats.index*((2021.5 -1946)/100)
Ahrstats.head(11)
| Abfluss [m³/s] | Abflussspende [l/s km²] | days | years | |
|---|---|---|---|---|
| Jährlichkeiten | ||||
| 2 | 93.5 | 125 | 730 | 1.51 |
| 5 | 125.0 | 168 | 1825 | 3.77 |
| 10 | 149.0 | 200 | 3650 | 7.55 |
| 20 | 176.0 | 236 | 7300 | 15.10 |
| 25 | 185.0 | 248 | 9125 | 18.88 |
| 50 | 212.0 | 284 | 18250 | 37.75 |
| 100 | 241.0 | 323 | 36500 | 75.50 |
Barweiler =pd.read_csv(r"stundenwerte_RR_03660_akt\produkt_rr_stunde_20200130_20210801_03660.txt",sep=";",index_col=1,
na_values= "-999",); # header=0,sep=\";\",\n", ,usecols=[2,3], parse_dates=["MESS_DATUM"]
Barweiler.index = pd.to_datetime(Barweiler.index, format="%Y%m%d%H") # -%M-
Barweiler.head(10)
| STATIONS_ID | QN_8 | R1 | RS_IND | WRTR | eor | |
|---|---|---|---|---|---|---|
| MESS_DATUM | ||||||
| 2020-01-30 00:00:00 | 3660 | 3 | 0.0 | 0.0 | NaN | eor |
| 2020-01-30 01:00:00 | 3660 | 3 | 0.0 | 0.0 | 0.0 | eor |
| 2020-01-30 02:00:00 | 3660 | 3 | 0.0 | 1.0 | 6.0 | eor |
| 2020-01-30 03:00:00 | 3660 | 3 | 0.0 | 0.0 | NaN | eor |
| 2020-01-30 04:00:00 | 3660 | 3 | 0.0 | 0.0 | 0.0 | eor |
| 2020-01-30 05:00:00 | 3660 | 3 | 0.0 | 0.0 | 0.0 | eor |
| 2020-01-30 06:00:00 | 3660 | 3 | 0.0 | 0.0 | NaN | eor |
| 2020-01-30 07:00:00 | 3660 | 3 | 0.0 | 0.0 | 0.0 | eor |
| 2020-01-30 08:00:00 | 3660 | 3 | 0.0 | 0.0 | 0.0 | eor |
| 2020-01-30 09:00:00 | 3660 | 3 | 0.0 | 0.0 | NaN | eor |
Barweiler.tail(3)
| STATIONS_ID | QN_8 | R1 | RS_IND | WRTR | eor | |
|---|---|---|---|---|---|---|
| MESS_DATUM | ||||||
| 2021-07-31 18:00:00 | 3660 | 1 | 0.0 | 1.0 | NaN | eor |
| 2021-07-31 19:00:00 | 3660 | 1 | 0.0 | 1.0 | 6.0 | eor |
| 2021-07-31 20:00:00 | 3660 | 1 | 0.0 | 1.0 | 6.0 | eor |
| 2021-07-31 21:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-07-31 22:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-07-31 23:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 00:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 01:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 02:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 03:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 04:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 05:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 06:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 07:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 08:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 09:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 10:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 11:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 12:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 13:00:00 | 3660 | 1 | 0.0 | 1.0 | 6.0 | eor |
| 2021-08-01 14:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 15:00:00 | 3660 | 1 | 0.0 | 1.0 | NaN | eor |
| 2021-08-01 16:00:00 | 3660 | 1 | 1.4 | 1.0 | 6.0 | eor |
| 2021-08-01 17:00:00 | 3660 | 1 | 0.0 | 1.0 | 6.0 | eor |
| 2021-08-01 18:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 19:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 20:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 21:00:00 | 3660 | 1 | 0.0 | 0.0 | NaN | eor |
| 2021-08-01 22:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
| 2021-08-01 23:00:00 | 3660 | 1 | 0.0 | 0.0 | 0.0 | eor |
Barweiler[" R1"].plot();

Barweiler["2021-07-07":"2021-07-16"][" R1"].plot();

Barweiler.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 13055 entries, 2020-01-30 00:00:00 to 2021-08-01 23:00:00 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 STATIONS_ID 13055 non-null int64 1 QN_8 13055 non-null int64 2 R1 13039 non-null float64 3 RS_IND 13039 non-null float64 4 WRTR 8709 non-null float64 5 eor 13055 non-null object dtypes: float64(3), int64(2), object(1) memory usage: 713.9+ KB
Barweiler[" R1"].resample("D").sum().plot();

BarweilerD= Barweiler[" R1"].resample("D").sum()
BarweilerD.rolling(7).sum().plot();

BarweilerD.rolling(14).sum().plot();

Daily Adenauer¶
Adenauer =pd.read_csv(r"stundenwerte_RR_03490_akt\produkt_rr_stunde_20200130_20210715_03490.txt",sep=";",index_col=1,
na_values= "-999",); # header=0,sep=\";\",\n", ,usecols=[2,3], parse_dates=["MESS_DATUM"]
Adenauer.index = pd.to_datetime(Adenauer.index, format="%Y%m%d%H") # -%M-
Adenauer.head(10)
| STATIONS_ID | QN_8 | R1 | RS_IND | WRTR | eor | |
|---|---|---|---|---|---|---|
| MESS_DATUM | ||||||
| 2020-01-30 00:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 01:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 02:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 03:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 04:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 05:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 06:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 07:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 08:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
| 2020-01-30 09:00:00 | 3490 | 3 | 0.0 | 0 | NaN | eor |
Adenauer.tail(10)
| STATIONS_ID | QN_8 | R1 | RS_IND | WRTR | eor | |
|---|---|---|---|---|---|---|
| MESS_DATUM | ||||||
| 2021-07-14 21:00:00 | 3490 | 1 | 0.0 | 1 | NaN | eor |
| 2021-07-14 22:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-14 23:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 00:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 01:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 02:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 03:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 04:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 05:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
| 2021-07-15 06:00:00 | 3490 | 1 | 0.0 | 0 | NaN | eor |
Adenauer["2021-07-07":"2021-07-16"][" R1"].plot();

Adenauer.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 11795 entries, 2020-01-30 00:00:00 to 2021-07-15 06:00:00 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 STATIONS_ID 11795 non-null int64 1 QN_8 11795 non-null int64 2 R1 11795 non-null float64 3 RS_IND 11795 non-null int64 4 WRTR 0 non-null float64 5 eor 11795 non-null object dtypes: float64(2), int64(3), object(1) memory usage: 645.0+ KB
AdenauerD= Adenauer.iloc[:,2].resample("D").sum()
BarweilerD= Barweiler.iloc[:,2].resample("D").sum()
BarweilerD["2021-07-01":"2021-07-16"].plot();

AdenauerD["2021-07-01":"2021-07-16"].plot();

AhrD= Ahr.iloc[:,0].resample("D").sum()/24
AhrD.loc["2021-07-01":"2021-07-16"].plot();

AhrD.loc["2021-07-01":"2021-07-16"]
Datum 2021-07-01 285.12 2021-07-02 252.54 2021-07-03 231.12 2021-07-04 227.54 2021-07-05 245.21 2021-07-06 232.71 2021-07-07 228.25 2021-07-08 232.08 2021-07-09 320.54 2021-07-10 302.58 2021-07-11 295.33 2021-07-12 273.54 2021-07-13 299.62 2021-07-14 601.38 2021-07-15 0.00 2021-07-16 0.00 Freq: D, Name: Wasserstand in cm, dtype: float64
AhrH= Ahr.iloc[:,0]#.resample("H").mean()
AhrH.loc["2021-07-01":"2021-07-16"].plot();

Ahr.loc["2021-07-01":"2021-07-16"].plot();
<AxesSubplot:xlabel='Datum'>

Müsch has 352 km² drainage area, and suppose 100 liter fell in 2 days time:
100*1000*1000/1000*352/(3600*24)
407.4074074074074
3500 m³ on 2days time needs a discharge of 400 cum/sec.
Datum Abfluss in m3/s Abflussspende in L/(s*km2) Wasserstand in cm
02.06.2016 132 374 273
170*1000*1000/1000*352/(3600*24)
692.5925925925926
Soil moisture content¶
Water content in the upper soil layers 10 cm thick, up till 60 cm deep.
soil =pd.read_csv(r"derived_germany_soil_daily_recent_3660.txt\derived_germany__soil__daily__recent__3660.txt",sep=";",index_col=1,
na_values= "-999",); # header=0,sep=\";\",\n", ,usecols=[2,3], parse_dates=["MESS_DATUM"]
soil.index = pd.to_datetime(soil.index, format="%Y%m%d") # -%M-
soil.loc["July 2021"].head(16)
| Stationsindex | VGSL | VPGB | VPGH | TS05 | TS10 | TS20 | TS50 | TS100 | ZFUMI | BF10 | BF20 | BF30 | BF40 | BF50 | BF60 | BFGSL | BFGLS | TSLS05 | TSSL05 | ZTKMI | ZTUMI | VPGPM | VPMB | VPWB | VPZB | VGLS | VWLS | VWSL | BFWLS | BFWSL | eor | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datum | ||||||||||||||||||||||||||||||||
| 2021-07-01 | 3660 | 1.0 | 1.0 | 1.0 | 14.6 | 15.3 | 16.7 | 18.0 | 16.2 | 0 | 94 | 83 | 73 | 77 | 86 | 92 | 84 | 86 | 14.1 | 14.5 | 0 | 0 | 1.4 | 0.9 | 0.9 | 1.1 | 1.0 | 0.9 | 0.9 | 69 | 77 | eor ... |
| 2021-07-02 | 3660 | 2.5 | 2.8 | 2.5 | 18.3 | 17.7 | 17.0 | 17.2 | 16.2 | 0 | 87 | 81 | 74 | 77 | 86 | 92 | 82 | 83 | 17.6 | 17.3 | 0 | 0 | 3.1 | 2.5 | 2.4 | 3.2 | 2.4 | 2.3 | 2.3 | 66 | 76 | eor ... |
| 2021-07-03 | 3660 | 3.0 | 3.6 | 3.1 | 22.0 | 21.0 | 19.3 | 17.2 | 16.0 | 0 | 78 | 77 | 74 | 77 | 85 | 91 | 80 | 80 | 21.3 | 21.4 | 0 | 0 | 3.7 | 3.4 | 3.3 | 4.0 | 2.9 | 3.0 | 3.1 | 63 | 74 | eor ... |
| 2021-07-04 | 3660 | 1.9 | 1.9 | 0.8 | 20.0 | 20.2 | 19.9 | 17.9 | 15.9 | 0 | 105 | 94 | 76 | 77 | 85 | 91 | 88 | 92 | 19.6 | 19.6 | 0 | 0 | 2.2 | 1.7 | 2.0 | 2.1 | 1.9 | 2.0 | 2.0 | 75 | 80 | eor ... |
| 2021-07-05 | 3660 | 2.1 | 2.1 | 0.6 | 18.2 | 18.3 | 18.4 | 17.8 | 16.0 | 0 | 102 | 91 | 78 | 77 | 85 | 91 | 87 | 91 | 17.8 | 18.1 | 0 | 0 | 2.1 | 1.8 | 2.1 | 2.3 | 2.1 | 2.1 | 2.1 | 74 | 80 | eor ... |
| 2021-07-06 | 3660 | 3.1 | 3.1 | 2.0 | 18.5 | 18.4 | 18.3 | 17.6 | 16.0 | 0 | 103 | 94 | 80 | 78 | 84 | 91 | 88 | 92 | 18.2 | 18.1 | 0 | 0 | 3.0 | 2.8 | 3.1 | 3.8 | 3.2 | 3.1 | 3.1 | 75 | 80 | eor ... |
| 2021-07-07 | 3660 | 3.3 | 3.4 | 2.6 | 20.2 | 19.6 | 18.7 | 17.5 | 16.0 | 0 | 93 | 90 | 81 | 78 | 84 | 91 | 86 | 88 | 19.5 | 19.8 | 0 | 0 | 3.6 | 3.2 | 2.6 | 3.9 | 3.2 | 2.6 | 2.6 | 72 | 79 | eor ... |
| 2021-07-08 | 3660 | 1.1 | 1.1 | 0.2 | 17.8 | 18.2 | 18.6 | 17.7 | 16.0 | 0 | 110 | 114 | 110 | 96 | 84 | 91 | 101 | 114 | 17.3 | 17.5 | 0 | 0 | 1.5 | 1.2 | 1.1 | 1.3 | 1.1 | 1.1 | 1.1 | 97 | 93 | eor ... |
| 2021-07-09 | 3660 | 1.4 | 1.4 | 1.5 | 17.5 | 17.6 | 17.7 | 17.5 | 16.0 | 0 | 105 | 108 | 108 | 102 | 89 | 90 | 101 | 113 | 17.1 | 17.4 | 0 | 0 | 1.7 | 1.4 | 1.4 | 1.6 | 1.4 | 1.4 | 1.4 | 96 | 93 | eor ... |
| 2021-07-10 | 3660 | 3.1 | 3.1 | 3.3 | 20.4 | 19.7 | 18.5 | 17.3 | 16.0 | 0 | 98 | 102 | 104 | 103 | 94 | 91 | 99 | 108 | 20.2 | 19.9 | 0 | 0 | 3.0 | 3.1 | 2.6 | 3.6 | 3.1 | 2.6 | 2.6 | 94 | 92 | eor ... |
| 2021-07-11 | 3660 | 1.8 | 1.9 | 2.0 | 19.7 | 19.6 | 19.2 | 17.5 | 16.0 | 0 | 94 | 100 | 104 | 102 | 95 | 92 | 98 | 104 | 19.2 | 19.2 | 0 | 0 | 2.3 | 1.9 | 1.6 | 2.2 | 1.8 | 1.6 | 1.6 | 92 | 91 | eor ... |
| 2021-07-12 | 3660 | 2.0 | 2.1 | 1.7 | 19.6 | 19.4 | 18.9 | 17.7 | 16.0 | 0 | 91 | 98 | 103 | 101 | 95 | 92 | 97 | 101 | 19.1 | 19.2 | 0 | 0 | 2.3 | 2.0 | 1.6 | 2.5 | 2.0 | 1.6 | 1.6 | 90 | 90 | eor ... |
| 2021-07-13 | 3660 | 0.9 | 0.9 | 0.4 | 18.0 | 18.2 | 18.5 | 17.7 | 16.0 | 0 | 110 | 116 | 116 | 112 | 104 | 97 | 109 | 121 | 17.7 | 17.8 | 0 | 0 | 1.0 | 1.0 | 1.1 | 1.1 | 0.9 | 1.1 | 1.1 | 111 | 102 | eor ... |
| 2021-07-14 | 3660 | 0.5 | 0.5 | 0.1 | 15.9 | 16.4 | 17.1 | 17.5 | 16.1 | 0 | 113 | 119 | 123 | 125 | 125 | 126 | 122 | 183 | 15.7 | 15.9 | 0 | 0 | 0.7 | 0.6 | 0.6 | 0.6 | 0.5 | 0.6 | 0.6 | 183 | 121 | eor ... |
| 2021-07-15 | 3660 | 1.9 | 1.9 | 2.0 | 17.3 | 17.0 | 16.7 | 16.9 | 16.3 | 0 | 109 | 115 | 118 | 121 | 122 | 123 | 118 | 159 | 17.0 | 17.3 | 0 | 0 | 1.8 | 1.9 | 1.8 | 2.2 | 1.8 | 1.8 | 1.8 | 159 | 117 | eor ... |
| 2021-07-16 | 3660 | 1.4 | 1.4 | 0.6 | 17.1 | 17.1 | 17.2 | 16.8 | 16.2 | 0 | 103 | 108 | 113 | 116 | 119 | 121 | 113 | 142 | 16.8 | 17.1 | 0 | 0 | 1.6 | 1.3 | 1.0 | 1.5 | 1.4 | 1.0 | 1.0 | 142 | 113 | eor ... |
soilmoisture= soil[["BF10" ,"BF20","BF30","BF40","BF50","BF60"]]
soilmoisture60= soil[["BF60"]]
soilmoisture["BFSUM"]= soilmoisture["BF10"]+soilmoisture["BF20"]+soilmoisture["BF30"]+soilmoisture["BF40"]+soilmoisture["BF50"]+soilmoisture["BF60"]
<ipython-input-11-83a619884aa6>:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy soilmoisture["BFSUM"]= soilmoisture["BF10"]+soilmoisture["BF20"]+soilmoisture["BF30"]+soilmoisture["BF40"]+soilmoisture["BF50"]+soilmoisture["BF60"]
soilmoisture60.plot( figsize=(16,5), grid=True, title="soil moisture under grass and sandy loam between 0 and 60 cm depth in % plant useable water"); # .loc["28 June 2021":"18 July 2021"]

soilmoisture["BFSUM"].plot( figsize=(16,5), grid=True, title="soil moisture under grass and sandy loam between 0 and 60 cm depth in % plant useable water"); # .loc["28 June 2021":"18 July 2021"]

soilmoisture["BFSUM"].max()
731
The soil was at 13-07-2021 up till 60 cm deep full of water.
soilmoisture.loc["28 June 2021":"18 July 2021"].plot( figsize=(16,5), grid=True, title="soil moisture under \
grass and sandy loam between 0 and 60 cm depth in % plant useable water");

soilhistor =pd.read_csv(r"derived_germany_soil_daily_historical_3660.txt\derived_germany__soil__daily__historical__3660.txt.csv",sep=";",index_col=1,
na_values= "-999",); # header=0,sep=\";\",\n", ,usecols=[2,3], parse_dates=["MESS_DATUM"]
soilhistor.index = pd.to_datetime(soilhistor.index, format="%Y%m%d") # -%M-
soilhistor.head(16)
| Stationsindex | VGSL | VPGB | VPGH | TS05 | TS10 | TS20 | TS50 | TS100 | ZFUMI | BF10 | BF20 | BF30 | BF40 | BF50 | BF60 | BFGSL | BFGLS | TSLS05 | TSSL05 | ZTKMI | ZTUMI | VPGPM | VPMB | VPWB | VPZB | VGLS | VWLS | VWSL | BFWLS | BFWSL | eor | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Datum | ||||||||||||||||||||||||||||||||
| 1995-01-01 | 3660 | 0.0 | 0.0 | 0.2 | 0.8 | 1.6 | 3.1 | 5.4 | 6.2 | -9999 | 106 | 103 | 91 | 90 | 90 | 90 | 95 | 98 | 0.6 | 0.7 | -9999 | -9999 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 99 | 95 | eor ... |
| 1995-01-02 | 3660 | 0.1 | 0.1 | 0.3 | 0.5 | 1.0 | 2.2 | 4.7 | 6.2 | -9999 | 109 | 109 | 103 | 93 | 90 | 90 | 99 | 105 | 0.3 | 0.4 | -9999 | -9999 | 0.5 | 0.0 | 0.1 | 0.0 | 0.1 | 0.1 | 0.1 | 106 | 100 | eor ... |
| 1995-01-03 | 3660 | 0.0 | 0.0 | 0.3 | 0.4 | 0.8 | 1.8 | 4.2 | 6.1 | -9999 | 105 | 106 | 104 | 99 | 91 | 90 | 99 | 105 | 0.3 | 0.4 | -9999 | -9999 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 107 | 100 | eor ... |
| 1995-01-04 | 3660 | 0.0 | 0.0 | 0.0 | 0.3 | 0.7 | 1.6 | 3.8 | 6.0 | -9999 | 102 | 104 | 104 | 103 | 92 | 90 | 99 | 105 | 0.3 | 0.3 | -9999 | -9999 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 106 | 100 | eor ... |
| 1995-01-05 | 3660 | 0.0 | 0.0 | 0.1 | 0.4 | 0.7 | 1.5 | 3.5 | 5.8 | -9999 | 102 | 104 | 104 | 101 | 93 | 90 | 99 | 104 | 0.3 | 0.3 | -9999 | -9999 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 105 | 100 | eor ... |
| 1995-01-06 | 3660 | 0.0 | 0.0 | 0.1 | 0.3 | 0.6 | 1.3 | 3.3 | 5.6 | -9999 | 102 | 103 | 103 | 104 | 94 | 91 | 100 | 105 | 0.2 | 0.2 | -9999 | -9999 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 105 | 101 | eor ... |
| 1995-01-07 | 3660 | 0.0 | 0.0 | 0.1 | 0.3 | 0.6 | 1.2 | 3.2 | 5.5 | -9999 | 103 | 103 | 103 | 103 | 95 | 91 | 100 | 104 | 0.2 | 0.3 | -9999 | -9999 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 105 | 101 | eor ... |
| 1995-01-08 | 3660 | 0.0 | 0.0 | 0.1 | 0.4 | 0.6 | 1.2 | 3.0 | 5.3 | -9999 | 109 | 111 | 108 | 105 | 101 | 92 | 104 | 111 | 0.2 | 0.3 | -9999 | -9999 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 112 | 106 | eor ... |
| 1995-01-09 | 3660 | 0.1 | 0.1 | 0.0 | 0.3 | 0.6 | 1.2 | 2.9 | 5.1 | -9999 | 110 | 113 | 112 | 109 | 104 | 97 | 108 | 115 | 0.2 | 0.3 | -9999 | -9999 | 0.2 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 117 | 109 | eor ... |
| 1995-01-10 | 3660 | 1.2 | 1.2 | 0.2 | 0.4 | 0.6 | 1.1 | 2.8 | 5.0 | -9999 | 110 | 116 | 116 | 113 | 109 | 103 | 111 | 120 | 0.3 | 0.3 | -9999 | -9999 | 0.6 | 0.5 | 0.8 | 0.5 | 1.2 | 0.8 | 0.8 | 123 | 114 | eor ... |
| 1995-01-11 | 3660 | 0.3 | 0.3 | 0.4 | 0.3 | 0.6 | 1.1 | 2.7 | 4.9 | -9999 | 111 | 116 | 118 | 116 | 113 | 108 | 114 | 123 | 0.3 | 0.3 | -9999 | -9999 | 0.5 | 0.1 | 0.2 | 0.1 | 0.3 | 0.2 | 0.2 | 127 | 116 | eor ... |
| 1995-01-12 | 3660 | 0.0 | 0.0 | 0.4 | 0.3 | 0.6 | 1.1 | 2.6 | 4.7 | -9999 | 111 | 117 | 120 | 120 | 118 | 113 | 117 | 128 | 0.2 | 0.3 | -9999 | -9999 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 132 | 118 | eor ... |
| 1995-01-13 | 3660 | 0.2 | 0.2 | 0.5 | 0.3 | 0.5 | 1.1 | 2.6 | 4.6 | -9999 | 105 | 111 | 115 | 117 | 117 | 116 | 114 | 123 | 0.2 | 0.3 | -9999 | -9999 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 125 | 115 | eor ... |
| 1995-01-14 | 3660 | 0.0 | 0.0 | 0.0 | 0.3 | 0.5 | 1.0 | 2.5 | 4.5 | -9999 | 103 | 107 | 111 | 114 | 115 | 115 | 111 | 118 | 0.2 | 0.3 | -9999 | -9999 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 121 | 112 | eor ... |
| 1995-01-15 | 3660 | 0.1 | 0.1 | 0.0 | 0.3 | 0.5 | 1.0 | 2.4 | 4.4 | -9999 | 104 | 103 | 107 | 110 | 113 | 114 | 108 | 114 | 0.3 | 0.3 | -9999 | -9999 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 116 | 109 | eor ... |
| 1995-01-16 | 3660 | 0.0 | 0.0 | 0.1 | 0.3 | 0.5 | 1.0 | 2.4 | 4.3 | -9999 | 103 | 104 | 103 | 107 | 110 | 111 | 106 | 110 | 0.2 | 0.3 | -9999 | -9999 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 112 | 107 | eor ... |
soilmoisturehistor= soilhistor[["BF10" ,"BF20","BF30","BF40","BF50","BF60"]]
soilmoisturehistor["BFSUM"]= soilhistor["BF10"]+soilhistor["BF20"]+soilhistor["BF30"]+soilhistor["BF40"]+soilhistor["BF50"]+soilhistor["BF60"]
soilmoisturehistor40= soilhistor["BF10"]+soilhistor["BF20"]+soilhistor["BF30"]+soilhistor["BF40"]
soilmoisturehistor30= soilhistor["BF10"]+soilhistor["BF20"]+soilhistor["BF30"]
<ipython-input-13-e73d16716313>:2: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy soilmoisturehistor["BFSUM"]= soilhistor["BF10"]+soilhistor["BF20"]+soilhistor["BF30"]+soilhistor["BF40"]+soilhistor["BF50"]+soilhistor["BF60"]
soilmoisturehistor.plot( figsize=(21,5), grid=True, title="historical soil moisture under \
grass and sandy loam between 0 and 60 cm depth in % plant useable water");

soilmoisturehistor["2015":].plot( figsize=(21,5), grid=True, title="historical soil moisture under \
grass and sandy loam between 0 and 60 cm depth in % plant useable water");

soilmoisturehistor["BFSUM"].plot( figsize=(16,5), grid=True, title="soil moisture under grass and sandy loam between 0 and 60 cm depth in % plant useable water"); # .loc["28 June 2021":"18 July 2021"]

soilmoisturehistor["BFSUM"].max()
721
soilmoisturehistor30["2015":].plot( figsize=(16,5), grid=True, title="historic soil moisture under grass and sandy loam between 0 and 30 cm depth in % plant useable water"); # .loc["28 June 2021":"18 July 2021"]

soilmoisturehistorBFSUM =soilmoisturehistor["BFSUM"] # normalize only bfsum
soilmoistureBFSUM =soilmoisture["BFSUM"]
sns.histplot( data=soilmoisturehistorBFSUM, kde=True, common_norm=True,cumulative=True, stat="probability", )
sns.histplot( data=soilmoistureBFSUM, kde=True, common_norm=True, cumulative=True, stat="probability",color='darkorange');

The moisture content in the soil was throughout 2021 above average.
soilmoistureBFSUM["2021-07-13":"2021-07-16"]
Datum 2021-07-13 655 2021-07-14 731 2021-07-15 708 2021-07-16 680 Name: BFSUM, dtype: int64
For comparison: the situation of the soil moisture content during the flood of 2016-02-06. The total value for 2016 is 663 % for the 6 layers, compared to 732 % for the 2021 flood.
The cause of this great difference were the biblical rainfall amounts of 2021 and slow moving clouds.
Anyway I think this is a good indicator for acuteness of the situation.
soilmoisturehistor.loc["2016-01-01": "2016-02-21"].iloc[:,:6].plot();

soilmoisturehistorBFSUM.loc["2016-01-01": "2016-02-21"].plot(); # .iloc[:,:6]

fig, ax=plt.subplots(figsize=(18,5));
soilmoisturehistorBFSUM.loc["2010-01-01": "2021-02-21"].plot(figsize=(18,5), grid=True,ax=ax, cmap='tab20b'); # .iloc[:,:6]
ax.axhline(y=730,linestyle ='--',color="red");
ax.axhline(y=655,linestyle =':',color="orange");

The soil moisture content vs. water level of river Ahr¶
The higher the soil moisture content of the upper layers is, the sooner rainfall will reach the runoff point, when any rainfall just runs off the slope.
AhrDMax= Ahr.iloc[:,0].resample("D").mean()
soilmoisture_pegel = pd.merge( soilmoistureBFSUM, AhrDMax, left_index=True,right_index=True, )
soilmoisture_pegel
| BFSUM | Wasserstand in cm | |
|---|---|---|
| Datum | ||
| 2021-06-24 | 491 | 62.07 |
| 2021-06-25 | 475 | 60.04 |
| 2021-06-26 | 460 | 55.07 |
| 2021-06-27 | 451 | 52.33 |
| 2021-06-28 | 438 | 51.48 |
| 2021-06-29 | 510 | 52.47 |
| 2021-06-30 | 509 | 92.50 |
| 2021-07-01 | 505 | 71.28 |
| 2021-07-02 | 497 | 63.14 |
| 2021-07-03 | 482 | 57.78 |
| 2021-07-04 | 528 | 56.89 |
| 2021-07-05 | 524 | 61.30 |
| 2021-07-06 | 530 | 58.18 |
| 2021-07-07 | 517 | 57.06 |
| 2021-07-08 | 605 | 58.02 |
| 2021-07-09 | 602 | 80.14 |
| 2021-07-10 | 592 | 75.65 |
| 2021-07-11 | 587 | 73.83 |
| 2021-07-12 | 580 | 68.39 |
| 2021-07-13 | 655 | 74.91 |
| 2021-07-14 | 731 | 176.01 |
| 2021-07-15 | 708 | NaN |
| 2021-07-16 | 680 | NaN |
| 2021-07-17 | 646 | NaN |
| 2021-07-18 | 616 | NaN |
| 2021-07-19 | 594 | NaN |
| 2021-07-20 | 576 | NaN |
| 2021-07-21 | 561 | NaN |
| 2021-07-22 | 553 | NaN |
| 2021-07-23 | 543 | 110.19 |
| 2021-07-24 | 579 | 116.83 |
| 2021-07-25 | 575 | 115.22 |
soilmoisture_pegel.plot(figsize=(14,5), grid=True, kind="bar");

Yearly rainfall maxima¶
klima_jahr_1930 =pd.read_csv(r"jahreswerte_KL_03490_19300101_20191231_hist\produkt_klima_jahr_19300101_20191231_03490.txt",sep=";",index_col=1,
na_values= "-999",); # header=0,sep=\";\",\n", ,usecols=[2,3], parse_dates=["MESS_DATUM"]
klima_jahr_1930.index = pd.to_datetime(klima_jahr_1930.index, format="%Y%m%d") # -%M- MESS_DATUM_BEGINN
klima_jahr_1930.head()
| STATIONS_ID | MESS_DATUM_ENDE | QN_4 | JA_N | ... | QN_6 | JA_RR | JA_MX_RS | eor | |
|---|---|---|---|---|---|---|---|---|---|
| MESS_DATUM_BEGINN | |||||||||
| 1930-01-01 | 3490 | 19301231 | 5 | nan | ... | nan | nan | nan | eor |
| 1931-01-01 | 3490 | 19311231 | 5 | nan | ... | 5 | 648.3 | 23.1 | eor |
| 1932-01-01 | 3490 | 19321231 | 5 | nan | ... | 5 | 491.2 | 16.6 | eor |
| 1933-01-01 | 3490 | 19331231 | 5 | nan | ... | 5 | 440 | 22.5 | eor |
| 1934-01-01 | 3490 | 19341231 | 5 | nan | ... | 5 | 592.5 | 36.4 | eor |
5 rows × 16 columns
klima_jahr_1930.tail()
| STATIONS_ID | MESS_DATUM_ENDE | QN_4 | JA_N | ... | QN_6 | JA_RR | JA_MX_RS | eor | |
|---|---|---|---|---|---|---|---|---|---|
| MESS_DATUM_BEGINN | |||||||||
| 2013-01-01 | 3490 | 20131231 | 10 | nan | ... | 9 | 684.5 | 65.5 | eor |
| 2014-01-01 | 3490 | 20141231 | 10 | nan | ... | 9 | 719.7 | 39.7 | eor |
| 2015-01-01 | 3490 | 20151231 | 10 | nan | ... | 9 | 652.7 | 50.6 | eor |
| 2018-01-01 | 3490 | 20181231 | 3 | nan | ... | 9 | 478.3 | 33.6 | eor |
| 2019-01-01 | 3490 | 20191231 | 3 | nan | ... | 9 | 593.1 | 25.5 | eor |
5 rows × 16 columns
sns.lineplot( data=klima_jahr_1930.JA_MX_RS, );

sns.histplot( data=klima_jahr_1930.JA_MX_RS, bins=20, kde=True);

Pretty remarkable that the historical dataset for yearly maxima has no value above 70 mm/day. On the other hand there were values around 170 mm/day for the day of the big flood.
from reliability.Distributions import Weibull_Distribution
from reliability.Probability_plotting import Weibull_probability_plot
import matplotlib.pyplot as plt
from reliability.Other_functions import make_right_censored_data
#dist = Exponential_Distribution(Lambda=0.25, gamma=12)
raw_data =klima_jahr_1930.JA_MX_RS.dropna() # dist.random_samples(100, seed=42)draw some random data from an exponential distributio
raw_data =raw_data.values
#data = make_right_censored_data(raw_data, threshold=17) # right censor the data at 17
Weibull_Distribution(alpha=20,beta=2, gamma=5 ).CDF(linestyle='--', label='True CDF') # we can't plot dist because it will be location shifted
Weibull_probability_plot(failures=raw_data, fit_gamma=True) # do the probability plot. Note that we have specified to fit gamma
plt.legend()
plt.show()

Highwater marks on an old house in Dernau. Source: Dirk Sebastian

High water level events of the Ahr¶
It is actually easy to find many sources with good information online: google "hochwasser der Ahr"
Beim Hochwasser am 21. Juli 1804 starben 64 Menschen. Beim Hochwasser am 13. Juni 1910 starben 57 (or 150?) Menschen;[9] danach mussten alle Ahr-Brücken – außer der bei Rech – wiederaufgebaut werden. Im Ahrstraßentunnel in Altenahr sind Marken der höchsten Pegel angebracht.
Am 2. Juni 2016 erreichte der Pegel der Ahr in Kreuzberg und Altenahr seinen seit Messbeginn bis dahin höchsten Stand. Am Pegel Altenahr stieg die Ahr auf 369 Zentimeter, 20 cm mehr als beim zuvor höchsten Hochwasser 1993.[10]
Im Laufe des 14. Juli 2021 führten starke und anhaltende Regenfälle zu den bisher höchsten Pegelständen, die jemals gemessen wurden. Die Messstation in Altenahr gab um 20:45 Uhr einen Pegelstand von 575 cm an[11] und in Bad Bodendorf am 15. Juli 2021 um 03:45 Uhr einen Stand von 483 cm.[12] Am 14. Juli 2021 erreichte der Pegel Altenahr einen Wasserstand von etwa 700 cm.[13] Somit wurden die Pegelstände des „Jahrhunderthochwassers“[14] von 2016 um rund 3,3 Meter übertroffen.
Heimatforscher Dr. Hans Frick, der das Hochwasser von 1804 im Jahre 1929 als Erster umfassend darstellte: Jede Vorsorge war nutzlos, denn so hoch hatte die Ahr bis dahin noch nie gestanden. Über der Steinbrücke bei Rech soll sie eine Höhe von acht Fuß (etwa 2,50 Meter) erreicht haben... Fast alle Ahrbrücken – einer Aufstellung nach 30 Stück – stürzten ein, auch die aus Stein. Nach der gleichen Quelle verschwand auch der 18 Fuß (5,50 Meter) über normalem Wasserstand der Ahr gelegene Stotzheimer Hof bei Rech spurlos.
Dr. Hans Frick was the first geographer who searched for historical source materials which dated more than 100 years ago.
Here are translations of some of the old texts, and citation from Hr. Seel: „Die Ahr und ihre Hochwässer in alten Quellen“ :
- The Antweiler Chronicle **does not report how great the damage was further downstream** in Anno Domini 1601. But one can assume that they were also considerable, because Antweiler is located on the upper reaches of the Ahr and the tidal wave of the "storm" flowed further downstream, then as now. About ten kilometers away in the village of Schuld, which was hit particularly hard by the floods last week. *The similarity with the build up and the damage of the 2021 flood is striking.*
Tuesday, August 1, 1719. This time too, the Ahr emerged from its river bed. Not as devastating as 118 years ago but with power. The chronicle of the monastery on Kalvarienberg in today's Bad Neuenahr-Ahrweiler reports that a wall in Heppingen was simply "overturned" by the flood, as was an avenue whose posts were "driven as far as Lorsdorf", i.e. about two current kilometers by car downstream. Two servants and an administrator of the monastery had only been able to save themselves in the trees until "help" came. The water had come so quickly.
- The flood had also caused damage to the upper reaches of the Ahr, for example the village chapel in Schuld, which had only been built 20 years earlier, had to be completely renovated.
July 21, 1804: According to reports from the French authorities responsible at the time, the Ahr had been flooding for days when a storm followed on July 21. Within a short time all tributaries swelled up. Then the tide came. In today's Bad Neuenahr-Ahrweiler a chronicler wrote that the whole "getraidt was flooded". And Pastor Fey in Bodendorf, six kilometers downriver, noted in his diary: 'On July 21st, I went with Herr[n] Dean Radermacher over the mountain to Remagen [on the Rhine] and it started to rain this hard on top of the mountain so that we both arrived in Remagen soaked to the skin. In the same night the Ahr grew so much that ... all possible household utensils, timber and dead people were found in the field who had been driven there with the Ahr.'
Fields washed away down to the rock.
A plaque in the community center of Dorsel on the upper reaches of the Ahr still reminds of the devastating flood of 1804: “21. Julius at 3 o'clock in the afternoon, during a terrible thunderstorm coming from the north, the water fell in streams from the clouds, causing the bottom to flow from many fields to the rocks ... [and] the steel foundry suddenly "wiped out". The water covered "large masses of earth, sand, hedges and shrubs" and also tore away the "very strong stone foundry bridge".
The only reminder of the Dorsel steel foundry, to which the bridge belonged, is the campsite of the same name.
A total of 63 people were killed in the disaster. The same happened to many horses, draft cattle and feeder cattle. A total of 129 houses, 162 barns and stables, 18 mills, eight blacksmiths and almost all bridges were destroyed. Another 469 houses, 234 barns and stables, two mills and a forge were damaged. Churches and houses were almost without exception under water. Fruit trees were uprooted, vineyards washed away, the harvest destroyed and the meadows of the floodplains silted up with gravel and rubble.
The top 10 high water events 1946 - 2019¶
... to which I added the estimated, sts. calculated, values of some historical flood events.
Hochwasser= Hochwasser.sort_index( ascending=True)
Hochwasser.head(19)
| Nr. | Abfluss in m3/s | Abflussspende in L/(s*km2) | Wasserstand in cm | |
|---|---|---|---|---|
| Datum | ||||
| 1804-07-21 | 14 | 1200 | 1600 | 650.0 |
| 1888-06-24 | 13 | 360 | 482 | 386.0 |
| 1910-06-13 | 0 | 630 | 615 | 445.0 |
| 1910-11-01 | 12 | 141 | 188 | 290.0 |
| 1918-01-16 | 15 | 236 | 316 | NaN |
| 1920-11-01 | 16 | 170 | 227 | NaN |
| 1961-01-31 | 6 | 175 | 234 | 378.0 |
| 1966-11-12 | 5 | 178 | 238 | 380.0 |
| 1984-05-30 | 3 | 192 | 257 | 391.0 |
| 1984-07-02 | 9 | 158 | 211 | 362.0 |
| 1984-11-23 | 7 | 167 | 223 | 370.0 |
| 1988-03-16 | 4 | 190 | 254 | 393.0 |
| 1993-12-01 | 10 | 145 | 194 | 293.0 |
| 1993-12-21 | 2 | 214 | 286 | 399.0 |
| 1995-01-23 | 8 | 165 | 221 | 311.0 |
| 2016-02-06 | 1 | 236 | 316 | 418.0 |
| 2021-07-14 | 11 | 650 | 800 | 895.0 |
Hochwasser2021= Hochwasser[~Hochwasser.iloc[6,:] ] #Hochwasser= "1993-12-01" Hochwasser2021
Hochwasser.iloc[6,:]
Nr. 6.0 Abfluss in m3/s 175.0 Abflussspende in L/(s*km2) 234.0 Wasserstand in cm 378.0 Name: 1961-01-31 00:00:00, dtype: float64
Hochwasser.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 17 entries, 1804-07-21 to 2021-07-14 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Nr. 17 non-null int64 1 Abfluss in m3/s 17 non-null int64 2 Abflussspende in L/(s*km2) 17 non-null int64 3 Wasserstand in cm 15 non-null float64 dtypes: float64(1), int64(3) memory usage: 680.0 bytes
Hochwasser[Hochwasser["Nr."]==14]
| Nr. | Abfluss in m3/s | Abflussspende in L/(s*km2) | Wasserstand in cm | |
|---|---|---|---|---|
| Datum | ||||
| 1804-07-21 | 14 | 1200 | 1600 | 650.0 |
- the former lowest value in the official list of top 10 HW events should go as I inserted the 2021 event
- calculate the time interval between the events of flooding > recurrence interval
Hochwasser["year"]= Hochwasser.index.year
Hochwasser["years"]=2021.5- Hochwasser["year"] # avoid 0
import datetime
today = datetime.date.today()
Hochwasser["days"]= (pd.to_datetime(today) - Hochwasser.index).days
pd.to_datetime('1910/06/13', format='%Y/%m/%d')-pd.to_datetime('2021/07/26', format='%Y/%m/%d')
Timedelta('-40586 days +00:00:00')
fig,ax=plt.subplots( 1,1, figsize=(12,5))
sns.scatterplot(x=Hochwasser["Abfluss in m3/s"] ,y=Hochwasser.years, data=Hochwasser,hue=Hochwasser["year"],palette="magma")#hue=int10 [:-1]
plt.xscale("log") #ax.xaxis_scale("log")

fig,ax=plt.subplots( 1,1, figsize=(12,6))
sns.scatterplot(x=Hochwasser["years"] ,y=Hochwasser["Wasserstand in cm"].values, data=Hochwasser,hue=Hochwasser["year"],palette="magma")#hue=int10
plt.xscale("log") #ax.xaxis_scale("log")
plt.legend() ;


Hochwasser["Wasserstand in cm"]
Datum 1804-07-21 650.0 1888-06-24 386.0 1910-06-13 445.0 1910-11-01 290.0 1918-01-16 NaN 1920-11-01 NaN 1961-01-31 378.0 1966-11-12 380.0 1984-05-30 391.0 1984-07-02 362.0 1984-11-23 370.0 1988-03-16 393.0 1993-12-01 293.0 1993-12-21 399.0 1995-01-23 311.0 2016-02-06 418.0 2021-07-14 895.0 Name: Wasserstand in cm, dtype: float64
Hochwasser
| Nr. | Abfluss in m3/s | Abflussspende in L/(s*km2) | Wasserstand in cm | year | years | days | |
|---|---|---|---|---|---|---|---|
| Datum | |||||||
| 1804-07-21 | 14 | 1200 | 1600 | 650.0 | 1804 | 217.5 | 79283 |
| 1888-06-24 | 13 | 360 | 482 | 386.0 | 1888 | 133.5 | 48629 |
| 1910-06-13 | 0 | 630 | 615 | 445.0 | 1910 | 111.5 | 40606 |
| 1910-11-01 | 12 | 141 | 188 | 290.0 | 1910 | 111.5 | 40465 |
| 1918-01-16 | 15 | 236 | 316 | NaN | 1918 | 103.5 | 37832 |
| 1920-11-01 | 16 | 170 | 227 | NaN | 1920 | 101.5 | 36812 |
| 1961-01-31 | 6 | 175 | 234 | 378.0 | 1961 | 60.5 | 22111 |
| 1966-11-12 | 5 | 178 | 238 | 380.0 | 1966 | 55.5 | 20000 |
| 1984-05-30 | 3 | 192 | 257 | 391.0 | 1984 | 37.5 | 13591 |
| 1984-07-02 | 9 | 158 | 211 | 362.0 | 1984 | 37.5 | 13558 |
| 1984-11-23 | 7 | 167 | 223 | 370.0 | 1984 | 37.5 | 13414 |
| 1988-03-16 | 4 | 190 | 254 | 393.0 | 1988 | 33.5 | 12205 |
| 1993-12-01 | 10 | 145 | 194 | 293.0 | 1993 | 28.5 | 10119 |
| 1993-12-21 | 2 | 214 | 286 | 399.0 | 1993 | 28.5 | 10099 |
| 1995-01-23 | 8 | 165 | 221 | 311.0 | 1995 | 26.5 | 9701 |
| 2016-02-06 | 1 | 236 | 316 | 418.0 | 2016 | 5.5 | 2017 |
| 2021-07-14 | 11 | 650 | 800 | 895.0 | 2021 | 0.5 | 32 |
A small correction to avoid a log error because of a year with value 0: let's assume that 2021 was a 100 year flood event
# small correction to avoid log error for a year with value 0: a 100 year flood event
Hochwasser.loc[Hochwasser["Nr."]==11, "years"]=100
Hochwasser
| Nr. | Abfluss in m3/s | Abflussspende in L/(s*km2) | Wasserstand in cm | year | years | days | |
|---|---|---|---|---|---|---|---|
| Datum | |||||||
| 1804-07-21 | 14 | 1200 | 1600 | 650.0 | 1804 | 217.5 | 79283 |
| 1888-06-24 | 13 | 360 | 482 | 386.0 | 1888 | 133.5 | 48629 |
| 1910-06-13 | 0 | 630 | 615 | 445.0 | 1910 | 111.5 | 40606 |
| 1910-11-01 | 12 | 141 | 188 | 290.0 | 1910 | 111.5 | 40465 |
| 1918-01-16 | 15 | 236 | 316 | NaN | 1918 | 103.5 | 37832 |
| 1920-11-01 | 16 | 170 | 227 | NaN | 1920 | 101.5 | 36812 |
| 1961-01-31 | 6 | 175 | 234 | 378.0 | 1961 | 60.5 | 22111 |
| 1966-11-12 | 5 | 178 | 238 | 380.0 | 1966 | 55.5 | 20000 |
| 1984-05-30 | 3 | 192 | 257 | 391.0 | 1984 | 37.5 | 13591 |
| 1984-07-02 | 9 | 158 | 211 | 362.0 | 1984 | 37.5 | 13558 |
| 1984-11-23 | 7 | 167 | 223 | 370.0 | 1984 | 37.5 | 13414 |
| 1988-03-16 | 4 | 190 | 254 | 393.0 | 1988 | 33.5 | 12205 |
| 1993-12-01 | 10 | 145 | 194 | 293.0 | 1993 | 28.5 | 10119 |
| 1993-12-21 | 2 | 214 | 286 | 399.0 | 1993 | 28.5 | 10099 |
| 1995-01-23 | 8 | 165 | 221 | 311.0 | 1995 | 26.5 | 9701 |
| 2016-02-06 | 1 | 236 | 316 | 418.0 | 2016 | 5.5 | 2017 |
| 2021-07-14 | 11 | 650 | 800 | 895.0 | 2021 | 0.5 | 32 |
fig,ax=plt.subplots( 1,1, figsize=(9,6))
sns.regplot(x=Hochwasser["years"] ,y=Hochwasser["Wasserstand in cm"].values, data=Hochwasser,order=3, ci=67);#logx=True,
#plt.xscale("log") #ax.xaxis_scale("log")
plt.ylim(0,);

The 2 waterlevels for 1804 have been described for the locations Rech and Altenahr.
Hochwasser_exc2021= Hochwasser.loc["1800":"2020"]; Hochwasser_exc2021
| Nr. | Abfluss in m3/s | Abflussspende in L/(s*km2) | Wasserstand in cm | year | years | days | |
|---|---|---|---|---|---|---|---|
| Datum | |||||||
| 1804-07-21 | 14 | 1200 | 1600 | 650.0 | 1804 | 217.5 | 79283 |
| 1888-06-24 | 13 | 360 | 482 | 386.0 | 1888 | 133.5 | 48629 |
| 1910-06-13 | 0 | 630 | 615 | 445.0 | 1910 | 111.5 | 40606 |
| 1910-11-01 | 12 | 141 | 188 | 290.0 | 1910 | 111.5 | 40465 |
| 1918-01-16 | 15 | 236 | 316 | NaN | 1918 | 103.5 | 37832 |
| 1920-11-01 | 16 | 170 | 227 | NaN | 1920 | 101.5 | 36812 |
| 1961-01-31 | 6 | 175 | 234 | 378.0 | 1961 | 60.5 | 22111 |
| 1966-11-12 | 5 | 178 | 238 | 380.0 | 1966 | 55.5 | 20000 |
| 1984-05-30 | 3 | 192 | 257 | 391.0 | 1984 | 37.5 | 13591 |
| 1984-07-02 | 9 | 158 | 211 | 362.0 | 1984 | 37.5 | 13558 |
| 1984-11-23 | 7 | 167 | 223 | 370.0 | 1984 | 37.5 | 13414 |
| 1988-03-16 | 4 | 190 | 254 | 393.0 | 1988 | 33.5 | 12205 |
| 1993-12-01 | 10 | 145 | 194 | 293.0 | 1993 | 28.5 | 10119 |
| 1993-12-21 | 2 | 214 | 286 | 399.0 | 1993 | 28.5 | 10099 |
| 1995-01-23 | 8 | 165 | 221 | 311.0 | 1995 | 26.5 | 9701 |
| 2016-02-06 | 1 | 236 | 316 | 418.0 | 2016 | 5.5 | 2017 |
fig,ax=plt.subplots( 1,1, figsize=(9,6))
sns.regplot(x=Hochwasser["years"] ,y=Hochwasser["Abfluss in m3/s"].values, data=Hochwasser_exc2021,logx=True,truncate=True);#[:-2]hue=int10
plt.ylim(0,); #plt.xscale("log") #ax.xaxis_scale("log")

fig,ax=plt.subplots( 1,1, figsize=(9,6))
sns.regplot(x=Hochwasser["years"] ,y=Hochwasser["Abfluss in m3/s"].values, data=Hochwasser_exc2021,order=1,truncate=True);#[:-2]hue=int10
plt.ylim(0,); #plt.xscale("log") #ax.xaxis_scale("log")

The effect of applying a short time range for historical data.¶
I made an interval curve based on historical sources, versus the official interval curve based on 'instrumental data'.
Ahrstats
| Abfluss [m³/s] | Abflussspende [l/s km²] | |
|---|---|---|
| Jährlichkeiten | ||
| 2 | 93.5 | 125 |
| 5 | 125.0 | 168 |
| 10 | 149.0 | 200 |
| 20 | 176.0 | 236 |
| 25 | 185.0 | 248 |
| 50 | 212.0 | 284 |
| 100 | 241.0 | 323 |
fig,ax=plt.subplots(1,1, figsize=(16,7),sharey=True) #
#sns.regplot(x=Hochwasser.iloc[[0,14,11,12,13,15,16],: ].years ,y=Hochwasser.iloc[[0,14,11,12,13,15,16],: ]["Abfluss in m3/s"].values, #"Abfluss in m3/s"
# data=Hochwasser.iloc[[0,14,11,12,13,15,16],: ], logx=True, ci=95,truncate=True,ax=ax[0],label="Based on historical sources")#[1:-1]hue=int10 days.values
#sns.regplot(x=Hochwasser[1:11].years ,y=Hochwasser[1:11]["Abfluss in m3/s"].values, data=Hochwasser[1:11],logx=True, ci=95,ax=ax[0],label="Based on 'instrumental data'")
plt.ylabel("Discharge in m3/s")
sns.regplot(x=Ahrstats.years.values ,y=Ahrstats["Abfluss [m³/s]"].values,color="darkorange", data=Ahrstats,logx=True, ci=95,ax=ax, label="Top 10 data starting 1946")#hue=int10
sns.regplot(x=Hochwasser_exc2021.years ,y=Hochwasser_exc2021["Abfluss in m3/s"].values,
data=Hochwasser_exc2021, logx=True, ci=95,truncate=True,ax=ax, label="Top 17 data starting 1800")
plt.ylim(0,1250) #ax.xaxis_scale("log")
plt.legend()
plt.title("Top 15 data starting 1800 vs Discharge in m3/s");

Hochwasser.iloc[[0,14,11,12,13],: ].year
Datum 1804-07-21 1804 2016-02-06 2016 1993-12-01 1993 1993-12-21 1993 1995-01-23 1995 Name: year, dtype: int64
The highwater curve is merely based on data from 1946-2016. The timeline of that dataset was not large enough to be able to predict a flooding the size of 2021. However, there are high water level markings left from the horrible flood of June 1911, and the insane massive flood of 1804. The 3rd highest flood level was reached in 1601, according authors before the flood of 2016.
„30. May 1601, Antweiler: An diesem Tag erhob sich unversehens am Nachmittag ein Ungewitter mit Regen und Hagel, verfinsterte sich der Himmel, die Schleusen des Himmels öffneten sich und unvorstellbare Wassermassen stürzten hernieder, so daß die entsetzten Bewohner an den Weltuntergang glaubten“ in SEEL: „Die Ahr und ihre Hochwässer in alten Quellen“
The streettunnel in Altenahr was only build in the 1830's, so the flood of 1804 could not make a bypass at that point. In 1910 the flood did exactly that, and reached a height in the tunnel of 2 meters. This tunnel has been made a bit more high and wide later on.
Estimation of altitude of the streettunnel in AltenAhr: it is located about 6.5 meter above the average level of the Ahr. Considering a water level of +- 2 meter in the tunnel, and the formation of some bulging of the water front by about 25-50 cm, I come to a water level of about 850 mm or more. This value is based on the recent water level calibration.
Ahrstats['Abfluss [m³/s]'].plot();

Ahrstats.columns
Index(['Abfluss [m³/s]', 'Abflussspende [l/s km²]', 'days', 'years'], dtype='object')

print( "hydr. radius", 8.5*4/(4+8.5+4), (8.25*2.25+6.25*2.25)*4)
hydr. radius 2.0606060606060606 130.5
R=8.5*4/(4+8.5+4)
S=0.005
n=0.033
V= R**(2/3)*(S**0.5)/n
V
3.4697728476650513
The velocity of water flowing in a stream or open channel is affected by a number of factors.
R=8.5*4/(4+8.5+4)
S=0.005
n=0.15 # very overgrown
V= R**(2/3)*(S**0.5)/n
V
0.7633500264863113
The rate by which the flood rose on 2021-07-14.¶
The hydrometers were positioned in order to be able to survive a "100 year flood" event, which was in fact based on a poor dataset. Eventually the hydrometers failed on 14 July, because they were placed to withstand floods not higher than 3 meters above the "average high water extreme". This is only a translation from the German text on wasserportal.rlp-umwelt.de.
Ahr["2021-07-13":"2021-07-14"].plot(figsize=(16,5));

Abflussspende, Wassermenge in Liter pro Sekunde, die in einem Einzugsgebiet bezogen auf eine Einheitsfläche von 1 km² abfließt.
fig,ax=plt.subplots( 1,1, figsize=(16,5))
sns.scatterplot(data=Abfluss.iloc[:,1 ]["2021-07-14"])
sns.lineplot( data=Ahr.iloc[:,0 ]["2021-07-14"],color="crimson", ax=ax);

Exclusive photo of the tunnels in Altenahr in the morning of 15 07 2021. It was taken by alerted inhabitants who left to warn family members in Altenahr, because they could not reach them by phone. They had to spent the night in the hills, and were probably the first "rescuers" in Altenahr.

Discharge vs. waterlevel for Altenahr¶
Here we combine recent and historical waterlevels together with the discharges calculated by various authors.
fig,ax=plt.subplots( 1,1, figsize=(16,5))
plt.title("Discharge vs. waterlevel for Altenahr")
sns.scatterplot(x=Abfluss["2021-07-14"]["Abfluss in m3/s"], y=Ahr["2021-07-14"]["Wasserstand in cm"], data=Abfluss["2021-07-14"], label="pegel 2021-07-14");
sns.scatterplot(x=Hochwasser.iloc[:,1], y=Hochwasser.iloc[:,3], data=Hochwasser,hue=Hochwasser.index.date,palette="magma",); #**{marker.edgecolor:"indigo"}

The difference between the series can be caused by human measurements in the past, a different river profile, sediment removal, or flood deposits. In fact there was in 2021 at least 1 bridge which watergates were completely clogged by a mix of debris: cars, wood logs, trees...

This Image by Roggenkamp T. and co. Herget lays bare the drama of the fall out of the hydrometers. I guess the peak in Altenahr arrived at or just after midnight. These authors say that the tributary Sahrbach had a big impact on the pegel in Altenahr, so I take a look at the public available measure station there: Kreuzberg. source:
Estimated parameters of the 1910 flood in Bad Neuenahr¶
flood1910= pd.read_excel(r"Ahr2.xlsx", skiprows=1,engine="openpyxl",index_col=0,na_values= "", sheet_name="flood_1910")
flood1910T= flood1910.iloc[:,:4].T
flood1910T
| Parameter | cross-section area | mean flow velocity | mean peak discharge |
|---|---|---|---|
| Non-built-up area | 8.0 | 1.87 | 15.0 |
| Northern river bank | 36.0 | 2.49 | 90.0 |
| River channel | 99.0 | 4.09 | 405.0 |
| Southern river bank and floodplain | 68.0 | 1.12 | 76.0 |
sns.scatterplot( data=flood1910T ,)
plt.yscale("log")

Main tributaries of the Ahr¶
https://wasserportal.rlp-umwelt.de/servlet/is/8181/
| Location | Pegelnullpunkt | Stream | Distance to Altenahr (km) |
|---|---|---|---|
| Altenahr | 160,522 m | Ahr | 0 |
| Kreuzberg | 178,894 m | Sahrbach | 1.5 |
| Denn | 191,151 m | Kesselingerbach | 4.3 |
| Niederadenau | 222,015 m | Adenauerbach | 10.8 |
| Müsch | 292,769 m | Ahr * Trierbach | 25.5 |
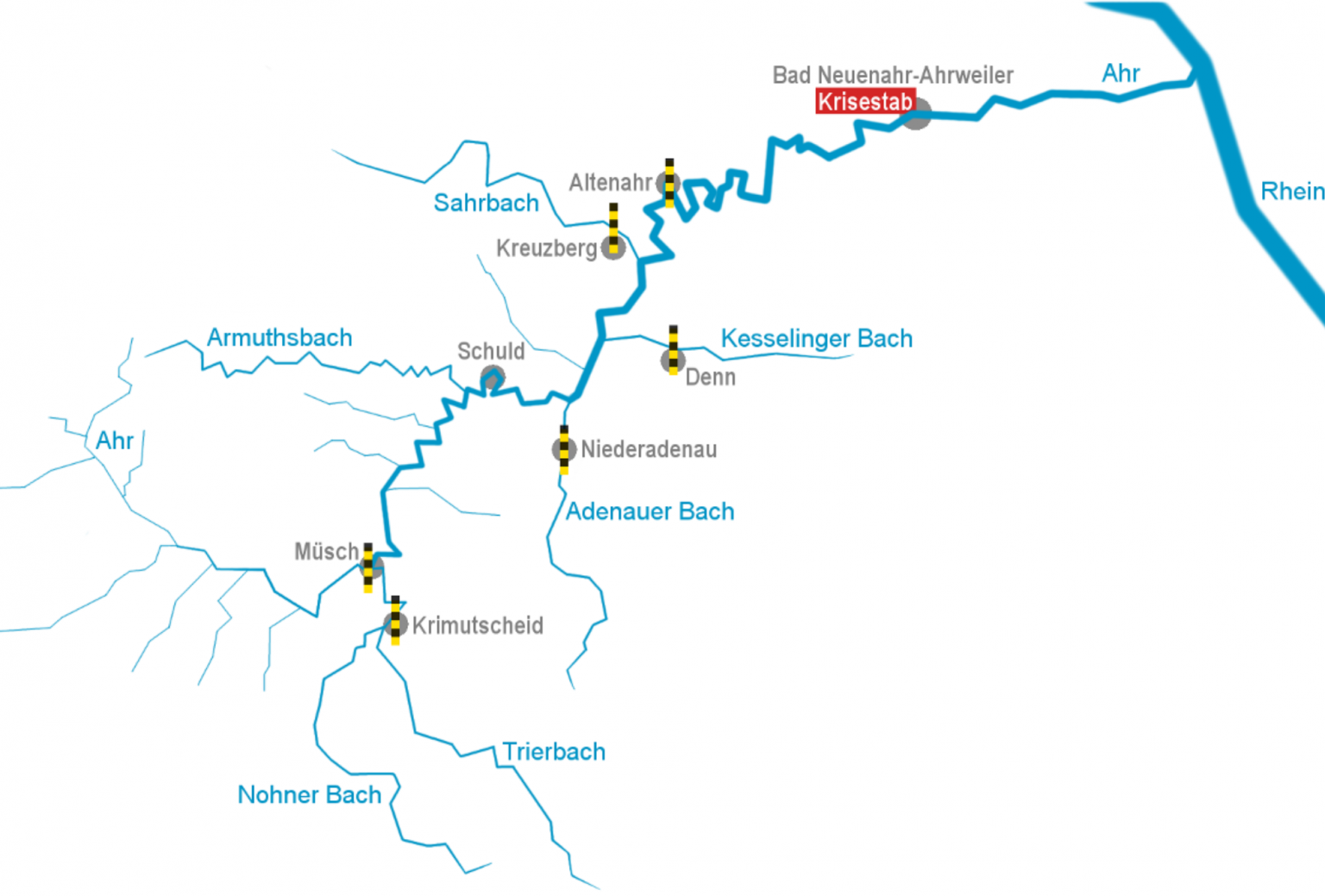
Estimated average waterspeed in km/h during flooding.
waterspeed= 2.5 # m/s
waterspeedkmh= waterspeed*3.6
waterspeedkmh
9.0
streams= pd.read_excel(r"Ahr.xlsx", skiprows=2,engine="openpyxl",index_col=0,na_values= "-")
streams= streams.sort_values("Elevation_Terminal", ascending=False)
streams
| Elevation_Source | Elevation_Terminal | Heightdiff | Length | Lage oberhalb Altenahr | TimetoAltenahr | Slope | Drainagearea | DpL_S | log10_L | log10_S | log10_D | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stream | ||||||||||||
| Nohnerbach | 570.00 | 330.0 | 240.00 | 18.40 | NaN | NaN | 1.30 | 33.18 | 2.35 | 1.26 | 0.12 | 1.52 |
| Ahbach | 548.00 | 320.0 | 228.00 | 21.00 | NaN | NaN | 1.09 | 90.96 | 4.70 | 1.32 | 0.04 | 1.96 |
| Trierbach | 567.00 | 300.0 | 367.00 | 20.00 | 25.5 | 170.00 | 1.84 | 88.00 | 8.07 | 1.30 | 0.26 | 1.94 |
| Dreisbach | 480.00 | 260.0 | 220.00 | 14.00 | NaN | NaN | 1.57 | 26.07 | 2.93 | 1.15 | 0.20 | 1.42 |
| Armutsbach | 520.00 | 240.0 | 280.00 | 15.00 | NaN | NaN | 1.87 | 60.53 | 7.53 | 1.18 | 0.27 | 1.78 |
| Weidenbach/Herschbach | 520.00 | 230.0 | 290.00 | 12.00 | NaN | NaN | 2.42 | 36.68 | 7.39 | 1.08 | 0.38 | 1.56 |
| Adenauerbach | 500.00 | 210.0 | 290.00 | 14.00 | 10.8 | 72.00 | 2.07 | 58.47 | 8.65 | 1.15 | 0.32 | 1.77 |
| Liesbach | 495.00 | 200.0 | 295.00 | 14.00 | NaN | NaN | 2.11 | 60.00 | 9.03 | 1.15 | 0.32 | 1.78 |
| Sahrbach/Effelsberger Bach | 460.00 | 190.0 | 270.00 | 14.00 | 1.5 | 10.00 | 1.93 | 45.00 | 6.20 | 1.15 | 0.29 | 1.65 |
| Kesselinger-/Blasweiler Bach | 550.00 | 190.0 | 360.00 | 14.00 | 4.3 | 28.67 | 2.57 | 95.00 | 17.45 | 1.15 | 0.41 | 1.98 |
| Harbach | 250.00 | 60.0 | 190.00 | 9.80 | NaN | NaN | 1.94 | 14.34 | 2.84 | 0.99 | 0.29 | 1.16 |
| Ahr_tail | 60.25 | 58.0 | 2.25 | 2.02 | NaN | NaN | 0.11 | NaN | 0.00 | NaN | NaN | NaN |
| Ahr_total | 483.00 | 58.0 | 425.00 | 90.00 | NaN | NaN | 0.47 | 875.00 | 413.19 | NaN | NaN | NaN |
| Pegel Altenahr | NaN | NaN | NaN | NaN | 31.7 | 31.70 | NaN | NaN | NaN | NaN | NaN | NaN |
Adenauerbach= pd.read_csv(r"Adenauerbach Aktuelle Wasserstände.csv",sep="\t", skiprows=1,usecols=[1,2],index_col=0,na_values="-")
Adenauerbach.index = pd.to_datetime(Adenauerbach.index, format="%d.%m.%Y %H:%M") # ,parse_dates=["Datum"] ,parse_dates=["Datum"]
Denn = pd.read_csv(r"Denn Aktuelle Wasserstände.csv",sep="\t", skiprows=1,usecols=[1,2],index_col=0,na_values="-")
Denn.index = pd.to_datetime(Denn.index, format="%d.%m.%Y %H:%M")
Kreuzberg =pd.read_csv(r"Kreuzberg Aktuelle Wasserstände.csv",sep="\t", skiprows=1,usecols=[1,2],index_col=0,na_values="-")
Kreuzberg.index = pd.to_datetime(Kreuzberg.index, format="%d.%m.%Y %H:%M")
Müsch= pd.read_csv(r"Müsch Aktuelle Wasserstände.csv",sep="\t", skiprows=1,usecols=[1,2],index_col=0,na_values="-")
Müsch.index = pd.to_datetime(Müsch.index, format="%d.%m.%Y %H:%M")
Adenauerbach
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-27 18:00:00 | 11.0 |
| 2021-06-27 18:15:00 | 12.0 |
| 2021-06-27 18:30:00 | 12.0 |
| 2021-06-27 18:45:00 | 11.0 |
| 2021-06-27 19:00:00 | 11.0 |
| ... | ... |
| 2021-07-28 22:45:00 | NaN |
| 2021-07-28 23:00:00 | NaN |
| 2021-07-28 23:15:00 | NaN |
| 2021-07-28 23:30:00 | NaN |
| 2021-07-28 23:45:00 | NaN |
3000 rows × 1 columns
DennAbf = pd.read_csv(r"Denn Abfluss.csv",sep="\t", skiprows=1,parse_dates=["Datum"],usecols=[1,2],index_col=0,na_values="-",decimal=",",dayfirst=True)
KreuzbergAbf = pd.read_csv(r"Kreuzberg Abfluss.csv",sep="\t", skiprows=1,parse_dates=["Datum"],usecols=[1,2],index_col=0,na_values="-",decimal=",",dayfirst=True)
MüschAbf = pd.read_csv(r"Müsch Abfluss.csv",sep="\t", skiprows=1,parse_dates=["Datum"],usecols=[1,2],index_col=0,na_values="-",decimal=",",dayfirst=True)
# located near Wirft, and south of Müsch
Kirmut = pd.read_csv(r"Kirmutscheid Aktuelle Wasserstände.csv",sep="\t", skiprows=1,parse_dates=["Datum"],usecols=[1,2],index_col=0,na_values="-",dayfirst=True)
KirmutAbf = pd.read_csv(r"Kirmutscheid Abfluss.csv",sep="\t", skiprows=1,parse_dates=["Datum"],usecols=[1,2],index_col=0,na_values="-",decimal=",")
KirmutAbf.loc["14-07-2021 14:30": "14-07-2021 18:30"]
| Abfluss in m3/s | |
|---|---|
| Datum | |
| 2021-07-14 14:30:00 | 58.74 |
| 2021-07-14 14:45:00 | 60.33 |
| 2021-07-14 15:00:00 | 60.33 |
| 2021-07-14 15:15:00 | 63.55 |
| 2021-07-14 15:30:00 | 65.72 |
| 2021-07-14 15:45:00 | 69.01 |
| 2021-07-14 16:00:00 | 71.78 |
| 2021-07-14 16:15:00 | 72.89 |
| 2021-07-14 16:30:00 | 74.01 |
| 2021-07-14 16:45:00 | 76.26 |
| 2021-07-14 17:00:00 | 82.52 |
| 2021-07-14 17:15:00 | 87.71 |
| 2021-07-14 17:30:00 | 90.04 |
| 2021-07-14 17:45:00 | 91.20 |
| 2021-07-14 18:00:00 | 95.30 |
| 2021-07-14 18:15:00 | 97.64 |
| 2021-07-14 18:30:00 | 100.59 |
Kirmut
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-07-05 17:45:00 | 42.0 |
| 2021-07-05 18:00:00 | 42.0 |
| 2021-07-05 18:15:00 | 42.0 |
| 2021-07-05 18:30:00 | 42.0 |
| 2021-07-05 18:45:00 | 42.0 |
| ... | ... |
| 2021-08-05 22:45:00 | NaN |
| 2021-08-05 23:00:00 | NaN |
| 2021-08-05 23:15:00 | NaN |
| 2021-08-05 23:30:00 | NaN |
| 2021-08-05 23:45:00 | NaN |
3001 rows × 1 columns
Kirmut["2021-07-14":"2021-07-16"].plot();

Water levels of tributaries¶
tributaries= pd.merge(Adenauerbach,Denn , left_index=True, right_index=True, suffixes=["Adenauerbach","Denn"] )
tributaries= pd.merge(tributaries ,Kreuzberg, left_index=True, right_index=True, suffixes=[None , "Kreuzberg"] )
tributaries= pd.merge(tributaries ,Müsch, left_index=True, right_index=True, suffixes=[None , "Müsch"] )
tributaries= pd.merge(tributaries ,Kirmut, left_index=True, right_index=True, suffixes=[None , "Kirmut"] )
tributaries.columns= ["Adenauerbach","Denn" ,"Kreuzberg","Müsch","Kirmut"]
The station of Kreuzberg broke down after 18:00. That curve shows an acceleration of the water discharge by the Sahrbach.
When we look at the rainfall values in its drainage area, we'll see that the records will be broken stream downwards.
tributaries["2021-07-14":"2021-07-16"].plot( figsize=(16,5));

Discharge levels of tributaries¶
#tribut_Abf= pd.merge(Adenauerbach,Denn , left_index=True, right_index=True, suffixes=["Adenauerbach","Denn"] )
tribut_Abf= pd.merge(DennAbf ,KreuzbergAbf, left_index=True, right_index=True, suffixes=["Denn" , "Kreuzberg"] )
tribut_Abf= pd.merge(tribut_Abf ,MüschAbf, left_index=True, right_index=True, suffixes=[None , "Müsch"] )
tribut_Abf= pd.merge(tribut_Abf ,KirmutAbf, left_index=True, right_index=True, suffixes=[None , "Kirmut"] )
tribut_Abf.columns= ["Denn" ,"Kreuzberg","Müsch","Kirmut"] # "Adenauerbach",
Adenauerbach intraday 15 minute interval data was not available, only the daily averages. Perhaps we can interpolate or make a decent regression between those 2 sets.
Adenauerbach_mittelwerte_Abf= pd.read_csv(r"2718085500_Niederadenau_Messdaten_Tagesmittelwerte_Abfluss.csv",sep=",",#parse_dates=["Datum"],
index_col=2,na_values="-",decimal=".")#usecols=[1,2],
Adenauerbach_mittelwerte_Abf.index = pd.to_datetime(Adenauerbach_mittelwerte_Abf.index, format="%d.%m.%Y")
Adenauerbach_mittelwerte_Abf.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 719 entries, 2019-08-07 to 2021-08-01 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Messstellennummer 719 non-null int64 1 Messstellenbezeichnung 719 non-null object 2 Abfluss in m³/s 719 non-null float64 dtypes: float64(1), int64(1), object(1) memory usage: 22.5+ KB
There have been measurements every 15 minutes, like this is the case for the other stations, for which we can calculate an outflow per day.
Adenauerbach_mittelwerte_Abf.describe()
| Messstellennummer | Abfluss in m³/s | |
|---|---|---|
| count | 7.19e+02 | 7.19e+02 |
| mean | 2.72e+09 | 3.42e-01 |
| std | 0.00e+00 | 7.75e-01 |
| min | 2.72e+09 | 9.70e-03 |
| 25% | 2.72e+09 | 6.20e-02 |
| 50% | 2.72e+09 | 1.64e-01 |
| 75% | 2.72e+09 | 3.42e-01 |
| max | 2.72e+09 | 1.40e+01 |
#Adenauerbach_mittelwerte_Abf=
Adenauerbach_mittelwerte_Abf.loc["2020-07-12":"2021-07-16"]["Abfluss in m³/day"].plot(figsize=(16,5)); #.loc[:,"Abfluss in m³/s"] #

I'm not sure that by multiplying by 24*4=96 we'll get the total discharge for the day. This can leads us to...
sns.histplot( Adenauerbach_mittelwerte_Abf["Abfluss in m³/s"]);

The histogram shows the average discharge values of the last 2 years for Adenauerbach.
The value for 13-07-2021 is a prelude to the magnitude of the flood event the following day.
15 minute interval data starts at 27.06.2021 18:00, the end is 28.07.2021 23:45
Adenauerbach.loc["14-07-2021 14:30": "14-07-2021 23:50"]["Wasserstand in cm"]
Datum 2021-07-14 14:30:00 108.0 2021-07-14 14:45:00 118.0 2021-07-14 15:00:00 129.0 2021-07-14 15:15:00 134.0 2021-07-14 15:30:00 140.0 2021-07-14 15:45:00 146.0 2021-07-14 16:00:00 150.0 2021-07-14 16:15:00 155.0 2021-07-14 16:30:00 160.0 2021-07-14 16:45:00 164.0 2021-07-14 17:00:00 166.0 2021-07-14 17:15:00 172.0 2021-07-14 17:30:00 175.0 2021-07-14 17:45:00 178.0 2021-07-14 18:00:00 185.0 2021-07-14 18:15:00 189.0 2021-07-14 18:30:00 194.0 2021-07-14 18:45:00 197.0 2021-07-14 19:00:00 201.0 2021-07-14 19:15:00 201.0 2021-07-14 19:30:00 202.0 2021-07-14 19:45:00 202.0 2021-07-14 20:00:00 202.0 2021-07-14 20:15:00 202.0 2021-07-14 20:30:00 203.0 2021-07-14 20:45:00 202.0 2021-07-14 21:00:00 201.0 2021-07-14 21:15:00 202.0 2021-07-14 21:30:00 202.0 2021-07-14 21:45:00 204.0 2021-07-14 22:00:00 203.0 2021-07-14 22:15:00 202.0 2021-07-14 22:30:00 202.0 2021-07-14 22:45:00 201.0 2021-07-14 23:00:00 200.0 2021-07-14 23:15:00 199.0 2021-07-14 23:30:00 198.0 2021-07-14 23:45:00 196.0 Name: Wasserstand in cm, dtype: float64
Adenauerbach.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 3000 entries, 2021-06-27 18:00:00 to 2021-07-28 23:45:00 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Wasserstand in cm 2972 non-null float64 dtypes: float64(1) memory usage: 46.9 KB
Dropping the last hours which are nan's.
Adenauerbach= Adenauerbach.dropna()
Adenauerbach.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 2972 entries, 2021-06-27 18:00:00 to 2021-07-28 16:45:00 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Wasserstand in cm 2972 non-null float64 dtypes: float64(1) memory usage: 46.4 KB
AdenauerbachDayMean= Adenauerbach.resample('D').mean() #["Wasserstand in cm"]on='Wasserstand in cm' Adenauerbach.resample("D").mean(); AdenauerbachDayMean["Wasserstand in cm"].tail(10)
AdenauerbachDayMean
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-27 | 10.79 |
| 2021-06-28 | 10.34 |
| 2021-06-29 | 15.96 |
| 2021-06-30 | 21.09 |
| 2021-07-01 | 17.18 |
| 2021-07-02 | 14.72 |
| 2021-07-03 | 13.06 |
| 2021-07-04 | 13.43 |
| 2021-07-05 | 13.67 |
| 2021-07-06 | 13.70 |
| 2021-07-07 | 12.27 |
| 2021-07-08 | 15.10 |
| 2021-07-09 | 18.80 |
| 2021-07-10 | 17.23 |
| 2021-07-11 | 17.09 |
| 2021-07-12 | 15.51 |
| 2021-07-13 | 22.45 |
| 2021-07-14 | 95.21 |
| 2021-07-15 | 137.23 |
| 2021-07-16 | 68.12 |
| 2021-07-17 | 37.19 |
| 2021-07-18 | 22.83 |
| 2021-07-19 | 16.50 |
| 2021-07-20 | 12.00 |
| 2021-07-21 | 8.86 |
| 2021-07-22 | 6.64 |
| 2021-07-23 | 5.22 |
| 2021-07-24 | 6.68 |
| 2021-07-25 | 5.17 |
| 2021-07-26 | 3.18 |
| 2021-07-27 | 16.30 |
| 2021-07-28 | 23.82 |
Perhaps it is better to bring also std into account.
AdenauerbachDayStd= Adenauerbach.resample('D').std() #on='Wasserstand in cm' Adenauerbach.resample("D").mean(); AdenauerbachDayMean["Wasserstand in cm"].tail(10)
AdenauerbachDayStd
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-27 | 0.59 |
| 2021-06-28 | 0.63 |
| 2021-06-29 | 10.50 |
| 2021-06-30 | 1.65 |
| 2021-07-01 | 0.85 |
| 2021-07-02 | 0.85 |
| 2021-07-03 | 0.68 |
| 2021-07-04 | 1.43 |
| 2021-07-05 | 0.61 |
| 2021-07-06 | 0.87 |
| 2021-07-07 | 0.80 |
| 2021-07-08 | 4.86 |
| 2021-07-09 | 1.18 |
| 2021-07-10 | 0.80 |
| 2021-07-11 | 0.93 |
| 2021-07-12 | 0.50 |
| 2021-07-13 | 4.37 |
| 2021-07-14 | 73.37 |
| 2021-07-15 | 33.35 |
| 2021-07-16 | 17.35 |
| 2021-07-17 | 4.54 |
| 2021-07-18 | 2.62 |
| 2021-07-19 | 2.17 |
| 2021-07-20 | 1.40 |
| 2021-07-21 | 1.16 |
| 2021-07-22 | 0.48 |
| 2021-07-23 | 0.84 |
| 2021-07-24 | 2.79 |
| 2021-07-25 | 0.83 |
| 2021-07-26 | 0.74 |
| 2021-07-27 | 11.81 |
| 2021-07-28 | 0.69 |
AdenauerbachDayStd2= Adenauerbach["Wasserstand in cm"].rolling(3).std().fillna(method='bfill')
AdenauerbachDayStd2
Datum
2021-06-27 18:00:00 0.58
2021-06-27 18:15:00 0.58
2021-06-27 18:30:00 0.58
2021-06-27 18:45:00 0.58
2021-06-27 19:00:00 0.58
...
2021-07-28 22:45:00 NaN
2021-07-28 23:00:00 NaN
2021-07-28 23:15:00 NaN
2021-07-28 23:30:00 NaN
2021-07-28 23:45:00 NaN
Name: Wasserstand in cm, Length: 3000, dtype: float64
sns.lineplot( data=AdenauerbachDayMean);
sns.lineplot(data=AdenauerbachDayStd);
sns.lineplot(data=AdenauerbachDayStd2);

sns.histplot(AdenauerbachDayMean);

sns.histplot(AdenauerbachDayStd);

AdenauerbachDayMean.tail(35)
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-27 | 10.79 |
| 2021-06-28 | 10.34 |
| 2021-06-29 | 15.96 |
| 2021-06-30 | 21.09 |
| 2021-07-01 | 17.18 |
| 2021-07-02 | 14.72 |
| 2021-07-03 | 13.06 |
| 2021-07-04 | 13.43 |
| 2021-07-05 | 13.67 |
| 2021-07-06 | 13.70 |
| 2021-07-07 | 12.27 |
| 2021-07-08 | 15.10 |
| 2021-07-09 | 18.80 |
| 2021-07-10 | 17.23 |
| 2021-07-11 | 17.09 |
| 2021-07-12 | 15.51 |
| 2021-07-13 | 22.45 |
| 2021-07-14 | 95.21 |
| 2021-07-15 | 137.23 |
| 2021-07-16 | 68.12 |
| 2021-07-17 | 37.19 |
| 2021-07-18 | 22.83 |
| 2021-07-19 | 16.50 |
| 2021-07-20 | 12.00 |
| 2021-07-21 | 8.86 |
| 2021-07-22 | 6.64 |
| 2021-07-23 | 5.22 |
| 2021-07-24 | 6.68 |
| 2021-07-25 | 5.17 |
| 2021-07-26 | 3.18 |
| 2021-07-27 | 16.30 |
| 2021-07-28 | 23.82 |
Discharge averages for Adenauerbach¶
drop values for 2021-07-28, because there are not covering the complete day.
Adenauerbach_mittelwerte_Abf.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 719 entries, 2019-08-07 to 2021-08-01 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Messstellennummer 719 non-null int64 1 Messstellenbezeichnung 719 non-null object 2 Abfluss in m³/s 719 non-null float64 dtypes: float64(1), int64(1), object(1) memory usage: 22.5+ KB
Adenauerbach_mittelwerte_Abf.head() # Niederadenau
| Messstellennummer | Messstellenbezeichnung | Abfluss in m³/s | |
|---|---|---|---|
| Datum | |||
| 2019-08-07 | 2718085500 | Niederadenau | 0.07 |
| 2019-08-08 | 2718085500 | Niederadenau | 0.03 |
| 2019-08-09 | 2718085500 | Niederadenau | 0.15 |
| 2019-08-10 | 2718085500 | Niederadenau | 0.18 |
| 2019-08-11 | 2718085500 | Niederadenau | 0.06 |
Adenauer_mittelwerte_AbfDayMean= Adenauerbach_mittelwerte_Abf["Abfluss in m³/s"].resample('D').mean()
Adenauer_mittelwerte_AbfDayMean
Datum
2019-08-07 0.07
2019-08-08 0.03
2019-08-09 0.15
2019-08-10 0.18
2019-08-11 0.06
...
2021-07-28 0.54
2021-07-29 0.44
2021-07-30 0.38
2021-07-31 0.35
2021-08-01 0.33
Freq: D, Name: Abfluss in m³/s, Length: 726, dtype: float64
Adenauer_mittelwerte_AbfDayStd= Adenauerbach_mittelwerte_Abf["Abfluss in m³/s"].rolling(3).std().fillna(method='bfill')
Adenauer_mittelwerte_AbfDayStd
Datum
2019-08-07 0.06
2019-08-08 0.06
2019-08-09 0.06
2019-08-10 0.08
2019-08-11 0.06
...
2021-07-28 0.28
2021-07-29 0.07
2021-07-30 0.08
2021-07-31 0.05
2021-08-01 0.02
Name: Abfluss in m³/s, Length: 719, dtype: float64
sns.lineplot ( data=Adenauer_mittelwerte_AbfDayMean.loc["July 2021"] )
sns.lineplot ( data=Adenauer_mittelwerte_AbfDayStd.loc["July 2021"] )
plt.xlim()
(18807.5, 18840.5)

Stdmerg= pd.merge( Adenauer_mittelwerte_AbfDayMean, Adenauer_mittelwerte_AbfDayStd, left_index=True, right_index=True, )
Stdmerg
Stdmerge= pd.merge( AdenauerbachDayMean, AdenauerbachDayStd2, left_index=True, right_index=True)
Stdmerge
| Wasserstand in cm_x | Wasserstand in cm_y | |
|---|---|---|
| Datum | ||
| 2021-06-28 | 10.34 | 0.00e+00 |
| 2021-06-29 | 15.96 | 0.00e+00 |
| 2021-06-30 | 21.09 | 5.77e-01 |
| 2021-07-01 | 17.18 | 5.77e-01 |
| 2021-07-02 | 14.72 | 5.13e-07 |
| 2021-07-03 | 13.06 | 5.77e-01 |
| 2021-07-04 | 13.43 | 5.64e-07 |
| 2021-07-05 | 13.67 | 5.26e-07 |
| 2021-07-06 | 13.70 | 5.51e-07 |
| 2021-07-07 | 12.27 | 5.51e-07 |
| 2021-07-08 | 15.10 | 5.76e-07 |
| 2021-07-09 | 18.80 | 4.49e-07 |
| 2021-07-10 | 17.23 | 5.77e-01 |
| 2021-07-11 | 17.09 | 5.77e-01 |
| 2021-07-12 | 15.51 | 5.20e-07 |
| 2021-07-13 | 22.45 | 5.33e-07 |
| 2021-07-14 | 95.21 | 5.77e-01 |
| 2021-07-15 | 137.23 | 2.00e+00 |
| 2021-07-16 | 68.12 | 0.00e+00 |
| 2021-07-17 | 37.19 | 5.77e-01 |
| 2021-07-18 | 22.83 | 5.77e-01 |
| 2021-07-19 | 16.50 | 0.00e+00 |
| 2021-07-20 | 12.00 | 0.00e+00 |
| 2021-07-21 | 8.86 | 0.00e+00 |
| 2021-07-22 | 6.64 | 0.00e+00 |
| 2021-07-23 | 5.22 | 0.00e+00 |
| 2021-07-24 | 6.68 | 0.00e+00 |
| 2021-07-25 | 5.17 | 0.00e+00 |
| 2021-07-26 | 3.18 | 0.00e+00 |
| 2021-07-27 | 16.30 | 0.00e+00 |
| 2021-07-28 | 23.82 | 0.00e+00 |
Stdmerger=pd.merge( Stdmerg, Stdmerge, left_index=True, right_index=True)
Stdmerger
| Abfluss in m³/s_x | Abfluss in m³/s_y | Wasserstand in cm_x | Wasserstand in cm_y | |
|---|---|---|---|---|
| Datum | ||||
| 2021-06-28 | 0.08 | 7.94e-03 | 10.34 | 0.00e+00 |
| 2021-06-29 | 0.35 | 1.52e-01 | 15.96 | 0.00e+00 |
| 2021-06-30 | 0.44 | 1.87e-01 | 21.09 | 5.77e-01 |
| 2021-07-01 | 0.27 | 8.24e-02 | 17.18 | 5.77e-01 |
| 2021-07-02 | 0.19 | 1.27e-01 | 14.72 | 5.13e-07 |
| 2021-07-03 | 0.14 | 6.75e-02 | 13.06 | 5.77e-01 |
| 2021-07-04 | 0.15 | 2.48e-02 | 13.43 | 5.64e-07 |
| 2021-07-05 | 0.16 | 8.67e-03 | 13.67 | 5.26e-07 |
| 2021-07-06 | 0.16 | 2.68e-03 | 13.70 | 5.51e-07 |
| 2021-07-07 | 0.12 | 2.20e-02 | 12.27 | 5.51e-07 |
| 2021-07-08 | 0.23 | 5.72e-02 | 15.10 | 5.76e-07 |
| 2021-07-09 | 0.34 | 1.10e-01 | 18.80 | 4.49e-07 |
| 2021-07-10 | 0.28 | 5.40e-02 | 17.23 | 5.77e-01 |
| 2021-07-11 | 0.27 | 3.84e-02 | 17.09 | 5.77e-01 |
| 2021-07-12 | 0.21 | 3.45e-02 | 15.51 | 5.20e-07 |
| 2021-07-13 | 0.53 | 1.67e-01 | 22.45 | 5.33e-07 |
| 2021-07-14 | 9.63 | 5.35e+00 | 95.21 | 5.77e-01 |
| 2021-07-15 | 13.99 | 6.87e+00 | 137.23 | 2.00e+00 |
| 2021-07-16 | 4.57 | 4.71e+00 | 68.12 | 0.00e+00 |
| 2021-07-17 | 1.37 | 6.56e+00 | 37.19 | 5.77e-01 |
| 2021-07-18 | 0.52 | 2.14e+00 | 22.83 | 5.77e-01 |
| 2021-07-19 | 0.25 | 5.83e-01 | 16.50 | 0.00e+00 |
| 2021-07-20 | 0.11 | 2.07e-01 | 12.00 | 0.00e+00 |
| 2021-07-21 | 0.05 | 1.01e-01 | 8.86 | 0.00e+00 |
| 2021-07-22 | 0.03 | 4.28e-02 | 6.64 | 0.00e+00 |
| 2021-07-23 | 0.02 | 1.74e-02 | 5.22 | 0.00e+00 |
| 2021-07-24 | 0.04 | 9.16e-03 | 6.68 | 0.00e+00 |
| 2021-07-25 | 0.02 | 1.07e-02 | 5.17 | 0.00e+00 |
| 2021-07-26 | 0.01 | 1.38e-02 | 3.18 | 0.00e+00 |
| 2021-07-27 | 0.41 | 2.29e-01 | 16.30 | 0.00e+00 |
| 2021-07-28 | 0.54 | 2.76e-01 | 23.82 | 0.00e+00 |
Stdmerger.plot()
<AxesSubplot:xlabel='Datum'>

Stdmerger["DebitStdtoAvg"]=Stdmerger["Abfluss in m³/s_y"] / Stdmerger["Abfluss in m³/s_x"]
Stdmerger["PegelStdtoAvg"]=Stdmerger["Wasserstand in cm_y"] /Stdmerger["Wasserstand in cm_x"]
Stdmerger["DebitStdtoAvg"].plot()
Stdmerger["PegelStdtoAvg"].plot()
<AxesSubplot:xlabel='Datum'>

Select the outflow of only the complete day series for interpolation
Adenauerbach_mittelwerte_AbfJuly= Adenauerbach_mittelwerte_Abf.loc["27-06-2021":"27-07-2021"][["Abfluss in m³/s"] ] # .loc
#Adenauerbach_Day_total_AbfJuly= Adenauerbach_mittelwerte_Abf.loc["27-06-2021":"27-07-2021"][["Abfluss in m³/day"] ]
Adenauerbach_mittelwerte_AbfJuly
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-06-27 | 0.09 |
| 2021-06-28 | 0.08 |
| 2021-06-29 | 0.35 |
| 2021-06-30 | 0.44 |
| 2021-07-01 | 0.27 |
| 2021-07-02 | 0.19 |
| 2021-07-03 | 0.14 |
| 2021-07-04 | 0.15 |
| 2021-07-05 | 0.16 |
| 2021-07-06 | 0.16 |
| 2021-07-07 | 0.12 |
| 2021-07-08 | 0.23 |
| 2021-07-09 | 0.34 |
| 2021-07-10 | 0.28 |
| 2021-07-11 | 0.27 |
| 2021-07-12 | 0.21 |
| 2021-07-13 | 0.53 |
| 2021-07-14 | 9.63 |
| 2021-07-15 | 13.99 |
| 2021-07-16 | 4.57 |
| 2021-07-17 | 1.37 |
| 2021-07-18 | 0.52 |
| 2021-07-19 | 0.25 |
| 2021-07-20 | 0.11 |
| 2021-07-21 | 0.05 |
| 2021-07-22 | 0.03 |
| 2021-07-23 | 0.02 |
| 2021-07-24 | 0.04 |
| 2021-07-25 | 0.02 |
| 2021-07-26 | 0.01 |
| 2021-07-27 | 0.41 |
# need to be multipl with counts (nan's)
sns.scatterplot(data=AdenauerbachDayMean)
sns.scatterplot(data=Adenauerbach_mittelwerte_AbfJuly*24,color='orange') ;

AdenauerbachDayMean.columns
Index(['Wasserstand in cm'], dtype='object')
sns.scatterplot(x=AdenauerbachDayMean['Wasserstand in cm'].iloc[:26], #['Wasserstand in cm'].values
y=Adenauerbach_mittelwerte_AbfJuly["Abfluss in m³/s"], #.loc["Abfluss in m³/s"].values
data=Adenauerbach_mittelwerte_AbfJuly
) ;

AdenauerbachDayMean
| Wasserstand in cm | |
|---|---|
| Datum | |
| 2021-06-27 | 10.79 |
| 2021-06-28 | 10.34 |
| 2021-06-29 | 15.96 |
| 2021-06-30 | 21.09 |
| 2021-07-01 | 17.18 |
| 2021-07-02 | 14.72 |
| 2021-07-03 | 13.06 |
| 2021-07-04 | 13.43 |
| 2021-07-05 | 13.67 |
| 2021-07-06 | 13.70 |
| 2021-07-07 | 12.27 |
| 2021-07-08 | 15.10 |
| 2021-07-09 | 18.80 |
| 2021-07-10 | 17.23 |
| 2021-07-11 | 17.09 |
| 2021-07-12 | 15.51 |
| 2021-07-13 | 22.45 |
| 2021-07-14 | 95.21 |
| 2021-07-15 | 137.23 |
| 2021-07-16 | 68.12 |
| 2021-07-17 | 37.19 |
| 2021-07-18 | 22.83 |
| 2021-07-19 | 16.50 |
| 2021-07-20 | 12.00 |
| 2021-07-21 | 8.86 |
| 2021-07-22 | 6.64 |
| 2021-07-23 | 5.22 |
| 2021-07-24 | 6.68 |
| 2021-07-25 | 5.17 |
| 2021-07-26 | 3.18 |
| 2021-07-27 | 16.30 |
| 2021-07-28 | 23.82 |
# perhaps bug in pandas
pd.__version__
'1.2.5'
interpolating from daily to 15 minutes values.
Adenauerbach_Day_total_AbfJuly.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 31 entries, 2021-06-27 to 2021-07-27 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Abfluss in m³/day 31 non-null float64 dtypes: float64(1) memory usage: 496.0 bytes
df=Adenauerbach_mittelwerte_AbfJuly #Adenauerbach_Day_total_AbfJuly
df = df.resample('15T').asfreq()
df
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-06-27 00:00:00 | 0.09 |
| 2021-06-27 00:15:00 | NaN |
| 2021-06-27 00:30:00 | NaN |
| 2021-06-27 00:45:00 | NaN |
| 2021-06-27 01:00:00 | NaN |
| ... | ... |
| 2021-07-26 23:00:00 | NaN |
| 2021-07-26 23:15:00 | NaN |
| 2021-07-26 23:30:00 | NaN |
| 2021-07-26 23:45:00 | NaN |
| 2021-07-27 00:00:00 | 0.41 |
2881 rows × 1 columns
df.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 2881 entries, 2021-06-27 00:00:00 to 2021-07-27 00:00:00 Freq: 15T Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Abfluss in m³/s 31 non-null float64 dtypes: float64(1) memory usage: 45.0 KB
Dischargeincubicmday = df.interpolate(method="cubic") # ['Abfluss in m³/day']
Dischargeincubicmday
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-06-27 00:00:00 | 0.09 |
| 2021-06-27 00:15:00 | 0.08 |
| 2021-06-27 00:30:00 | 0.08 |
| 2021-06-27 00:45:00 | 0.08 |
| 2021-06-27 01:00:00 | 0.07 |
| ... | ... |
| 2021-07-26 23:00:00 | 0.38 |
| 2021-07-26 23:15:00 | 0.39 |
| 2021-07-26 23:30:00 | 0.40 |
| 2021-07-26 23:45:00 | 0.40 |
| 2021-07-27 00:00:00 | 0.41 |
2881 rows × 1 columns
Dischargeincubicmday.plot()
<AxesSubplot:xlabel='Datum'>

df.to_excel('Discharge.xlsx')
divide by 96 to get back Discharge in m³/s
Dischargeincubicmday .loc["14-07-2021"]
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-07-14 00:00:00 | 9.63 |
| 2021-07-14 00:15:00 | 9.74 |
| 2021-07-14 00:30:00 | 9.84 |
| 2021-07-14 00:45:00 | 9.94 |
| 2021-07-14 01:00:00 | 10.04 |
| ... | ... |
| 2021-07-14 22:45:00 | 14.18 |
| 2021-07-14 23:00:00 | 14.15 |
| 2021-07-14 23:15:00 | 14.11 |
| 2021-07-14 23:30:00 | 14.08 |
| 2021-07-14 23:45:00 | 14.04 |
96 rows × 1 columns
#dfD=pd.DataFrame()
Dischargeincubicm_sec= Dischargeincubicmday/96 # cos we went from 1 to 96 values # *60*15/(24*3600)
Dischargeincubicm_sec.plot(); #dfD['Discharge in m³/sec']

#Dischargeincubicm_sec.columns= ["Abfluss in m³/sec"]
Dischargeincubicm_sec.loc["14-07-2021"] # Abfluss in m³/day> Abfluss in m³/sec
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-07-14 00:00:00 | 0.10 |
| 2021-07-14 00:15:00 | 0.10 |
| 2021-07-14 00:30:00 | 0.10 |
| 2021-07-14 00:45:00 | 0.10 |
| 2021-07-14 01:00:00 | 0.10 |
| ... | ... |
| 2021-07-14 22:45:00 | 0.15 |
| 2021-07-14 23:00:00 | 0.15 |
| 2021-07-14 23:15:00 | 0.15 |
| 2021-07-14 23:30:00 | 0.15 |
| 2021-07-14 23:45:00 | 0.15 |
96 rows × 1 columns
#Dischargeincubicm_sec.columns= ["Abfluss in m³/sec"]
Dischargeincubicm_sec.loc["15-07-2021"] # Abfluss in m³/day> Abfluss in m³/sec
| Abfluss in m³/s | |
|---|---|
| Datum | |
| 2021-07-15 00:00:00 | 0.15 |
| 2021-07-15 00:15:00 | 0.15 |
| 2021-07-15 00:30:00 | 0.14 |
| 2021-07-15 00:45:00 | 0.14 |
| 2021-07-15 01:00:00 | 0.14 |
| ... | ... |
| 2021-07-15 22:45:00 | 0.05 |
| 2021-07-15 23:00:00 | 0.05 |
| 2021-07-15 23:15:00 | 0.05 |
| 2021-07-15 23:30:00 | 0.05 |
| 2021-07-15 23:45:00 | 0.05 |
96 rows × 1 columns
Dischargeincubicm_sec['Discharge in m³/15m']= Dischargeincubicm_sec['Abfluss in m³/s'] #ec *15*60 = overkill
Dischargeincubicm_sec['Discharge in m³/15m']
Datum
2021-06-27 00:00:00 8.97e-04
2021-06-27 00:15:00 8.63e-04
2021-06-27 00:30:00 8.29e-04
2021-06-27 00:45:00 7.97e-04
2021-06-27 01:00:00 7.65e-04
...
2021-07-26 23:00:00 3.97e-03
2021-07-26 23:15:00 4.05e-03
2021-07-26 23:30:00 4.13e-03
2021-07-26 23:45:00 4.21e-03
2021-07-27 00:00:00 4.29e-03
Freq: 15T, Name: Discharge in m³/15m, Length: 2881, dtype: float64
Dischargeincubicm_sec['Discharge in m³/15m'].loc["14-07-2021"].sum()
12.971682619002106
tribut_Abf
| Denn | Kreuzberg | Müsch | Kirmut | Total | Totallags | |
|---|---|---|---|---|---|---|
| Datum | ||||||
| 2021-07-07 11:45:00 | 0.24 | 0.12 | 2.00 | 0.48 | 2.83 | NaN |
| 2021-07-07 12:00:00 | 0.24 | 0.12 | 2.00 | 0.48 | 2.83 | NaN |
| 2021-07-07 12:15:00 | 0.24 | 0.12 | 2.00 | 0.48 | 2.83 | NaN |
| 2021-07-07 12:30:00 | 0.24 | 0.10 | 2.00 | 0.45 | 2.78 | NaN |
| 2021-07-07 12:45:00 | 0.24 | 0.10 | 2.00 | 0.45 | 2.78 | NaN |
| ... | ... | ... | ... | ... | ... | ... |
| 2021-07-14 22:45:00 | 97.38 | 52.81 | 254.31 | 79.67 | 484.16 | 575.26 |
| 2021-07-14 23:00:00 | 95.38 | 52.24 | 251.61 | 79.10 | 478.33 | 562.59 |
| 2021-07-14 23:15:00 | 94.38 | 51.96 | 250.24 | 78.53 | 475.11 | 553.68 |
| 2021-07-14 23:30:00 | 94.38 | 51.39 | 247.49 | 77.96 | 471.22 | 542.06 |
| 2021-07-14 23:45:00 | 94.38 | 50.81 | 244.70 | 76.83 | 466.72 | 535.22 |
241 rows × 6 columns
tribut_Abf["Total"]=tribut_Abf["Denn"]+tribut_Abf["Kreuzberg"]+tribut_Abf["Müsch"]+tribut_Abf["Kirmut"]
tribut_Abfmerge= pd.merge( tribut_Abf["Total"],Dischargeincubicm_sec['Abfluss in m³/sec'], left_index=True, right_index=True,)
tribut_Abfmerge
| Total | Abfluss in m³/sec | |
|---|---|---|
| Datum | ||
| 2021-07-07 11:45:00 | 2.83 | 0.16 |
| 2021-07-07 12:00:00 | 2.83 | 0.16 |
| 2021-07-07 12:15:00 | 2.83 | 0.16 |
| 2021-07-07 12:30:00 | 2.78 | 0.16 |
| 2021-07-07 12:45:00 | 2.78 | 0.16 |
| ... | ... | ... |
| 2021-07-14 22:45:00 | 484.16 | 14.18 |
| 2021-07-14 23:00:00 | 478.33 | 14.15 |
| 2021-07-14 23:15:00 | 475.11 | 14.11 |
| 2021-07-14 23:30:00 | 471.22 | 14.08 |
| 2021-07-14 23:45:00 | 466.72 | 14.04 |
241 rows × 2 columns
fig, ax=plt.subplots( 1,1, figsize=(16,5))
sns.lineplot( data=tribut_Abfmerge.loc["2021-07-13 12:00":"2021-07-17"]);
<AxesSubplot:xlabel='Datum'>

print(14*3600, "m³/hr")
50400 m³/hr
This is not a decent method, so I'll study the rainfall-outflow balance later.
The total sum of discharge of 4 principal tributaries.¶
Let's compare the discharges of 4 principal tributaries with the measurements of Altenahr.
These discharges represent 85% of the Ahr drainage area, as water levels of the Armuthsbach with 61 km² is not measured yet.
- The (virtual) total sum is - in the beginning - 3 hours ahead of the arrival of the same discharge value in Altenahr.
- It shortens to 2 hours when the discharges increase.
- discharge values are derived from the water levels, and were downloaded from the RLP Umwelt site
fig, ax=plt.subplots( 1,1, figsize=(16,5))
sns.lineplot( data=tribut_Abf.loc["2021-07-13 12:00":"2021-07-17"])
sns.lineplot( data=Abfluss.loc["2021-07-13 12:00":"2021-07-17"]["Abfluss in m3/s"], label="Altenahr") ;

count= tribut_Abf.loc["14-07-2021 19:00":"2021-07-14 23:45"]["Müsch"].count()
recessioncoef= (tribut_Abf.loc["14-07-2021 19:00"]["Müsch"]- tribut_Abf.loc["14-07-2021 23:45"]["Müsch"])/ count
recessioncoef
3.7650000000000006
tribut_Abf.loc["2021-07-14 19:00"]["Müsch"]
320.0
tribut_Abf["2021-07-14 18:15":"2021-07-14 23:45"]["Müsch"].count()
23
Last Kreuzberg datapoint: 2718090200 14.07.2021 18:15 66,445
Let's suppose the recession curve of the missing data is similar to that of Müsch...
taking the time into consideration for the water flows to travel to Altenahr¶
It takes some time for a flow to travel downstream from one point to another. This is done via time lags with a shift, where 1 shift equals 15 minutes later...
tribut_Abfmerge["Totallags"]=tribut_Abf["Denn"].shift(2)+tribut_Abf["Kreuzberg"].shift(1)+tribut_Abf["Müsch"].shift(12)+tribut_Abf["Kirmut"].shift(14)+ tribut_Abfmerge['Abfluss in m³/sec'].shift(5)
fig,ax=plt.subplots(1,1, figsize=(16,5))
sns.lineplot( data=tribut_Abf.loc["2021-07-13 12:00":"2021-07-15 2:00"] )
sns.lineplot( data=tribut_Abfmerge.loc["2021-07-13 12:00":"2021-07-15 2:00"],marker="v", color='gold', ax=ax );
# x= dfD.loc["2021-07-13 12:00":"2021-07-15 2:00"],y= dfD['Discharge in m³/sec'].loc["2021-07-13 12:00":"2021-07-15 2:00"],

A witness who survived the flood at Altenahr said that the peak level was about 23:00, standing at a level 30 cm higher than the level of the roof.
tribut_Abfmerge.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 241 entries, 2021-07-07 11:45:00 to 2021-07-14 23:45:00 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Total 241 non-null float64 1 Abfluss in m³/sec 241 non-null float64 2 Totallags 227 non-null float64 dtypes: float64(3) memory usage: 15.6 KB
Kirmut_WSAbf.columns
Index(['Wasserstand in cm', 'Abfluss in m3/s'], dtype='object')
Discharge - waterlevel curve for Kirmutscheid¶
Trierbach waterlevel.
Kirmut_WSAbf = pd.merge(Kirmut, KirmutAbf ,left_index=True, right_index=True, )
sns.scatterplot(x="Abfluss in m3/s" , y="Wasserstand in cm" , data=Kirmut_WSAbf["2021-07-14"]);
<AxesSubplot:xlabel='Abfluss in m3/s', ylabel='Wasserstand in cm'>

This seems to be a theoretical derived curve, as empirical curves tend to have an increasing trend in the end, instead of a lineair.
Kirmut_WSAbf.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 2998 entries, 2021-05-07 18:30:00 to 2021-05-08 23:45:00 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Wasserstand in cm 2969 non-null float64 1 Abfluss in m3/s 2972 non-null float64 dtypes: float64(2) memory usage: 70.3 KB
from scipy.integrate import trapezoid
y14pm =KirmutAbf["2021-07-14 12:00":"2021-07-14 23:45"]["Abfluss in m3/s"]
y14am =KirmutAbf["2021-07-14 00:00":"2021-07-14 11:45"]["Abfluss in m3/s"]
y147pm =KirmutAbf["2021-07-14 19:00":"2021-07-14 19:45"]["Abfluss in m3/s"]
Qpy14pm =trapezoid(y14pm, x=None, axis=- 1) #dx=15.0*60,
Qpy14am =trapezoid(y14am, x=None, axis=- 1)#dx=15.0*60,
Qpy147pm =trapezoid(y147pm, x=None, axis=- 1)# dx=45.0,
print(Qpy14am,"Abfluss in m3/12h", Qpy14pm,"Abfluss in m3/12h", Qpy147pm,"Abfluss in m3/h")
242.75799999999995 Abfluss in m3/12h 3395.5840000000007 Abfluss in m3/12h 306.7935 Abfluss in m3/h
100*3600
360000
0.104*3600/88000000*1000 # l/s> m³/hour / 88 km² > m² >> m/hour = 1000mm/hour
0.004254545454545454
Hochwasser.columns
Index(['Nr.', 'Abfluss in m3/s', 'Abflussspende in L/(s*km2)', 'Wasserstand in cm', 'km2', 'year', 'years', 'days'], dtype='object')
Estimation of the volume of water/sec for a water level of 9.5 meter.¶
only done to get an idea of the height of the waves
from sklearn import linear_model
reg = linear_model.Lasso(alpha=0.1)
df=pd.DataFrame()
df["Wasserstand in cm"] =Ahr["2021-07-14 12:00":"2021-07-14 19:15"]["Wasserstand in cm"].to_list()
df["Abfluss in m3/s"] =Abfluss["2021-07-14 12:00":"2021-07-14 19:15"]["Abfluss in m3/s"].to_list()
pegel2volume= pd.merge(df["Wasserstand in cm"],df["Abfluss in m3/s"], left_index=True, right_index=True)
pegel2volume=pegel2volume.dropna()
#pegel2volume=pegel2volume.iloc[40:,:]
X =pegel2volume["Wasserstand in cm"].values.reshape(-1,1)
y =pegel2volume["Abfluss in m3/s"].values.reshape(-1,1)
reg.fit( X,y ,) #.values .values
reg.predict(np.array(1000).reshape(1, -1) ) # .values.reshape(1, -1)
array([748.88])
1000 cm: 748.88 m³/s
950 cm: 707 m³/s
875 cm: 644.65 m³/s
800 cm: 582 m³/s
df["Wasserstand in cm"]
0 117.0
1 120.0
2 123.0
3 126.0
4 130.0
...
300 113.0
301 113.0
302 113.0
303 113.0
304 113.0
Name: Wasserstand in cm, Length: 305, dtype: float64
pegel2volume["Wasserstand in cm"].shape
(30,)
df["Abfluss in m3/s"].shape
(30,)
df["Abfluss in m3/s"].tail(20)
76 309.93 77 332.27 78 NaN 79 NaN 80 NaN 81 NaN 82 NaN 83 NaN 84 NaN 85 NaN 86 NaN 87 NaN 88 NaN 89 NaN 90 NaN 91 NaN 92 NaN 93 NaN 94 NaN 95 NaN Name: Abfluss in m3/s, dtype: float64
Measurement stations of the Ahr and its tributaries.¶
Messstation.xlsx
Messstat= pd.read_excel("./data/Messstation.xlsx", index_col=0, engine='openpyxl',na_values="-",verbose=1,sheet_name="Blad1" ) #
Messstat=Messstat.T
Messstat["Eingerichtet"]=pd.to_datetime(Messstat["Eingerichtet"])
Messstat["Pegelnullpunkt"]=Messstat["Pegelnullpunkt"].astype(float)
Messstat["Einzugsgebiet (km2)"]=Messstat["Einzugsgebiet (km2)"].astype(float)
Messstat["Lat"]=Messstat["Lat"].astype(float)
Messstat["Long"]=Messstat["Long"].astype(float)
Messstat["Maximum_Abfluss_m³s"]=Messstat["Maximum_Abfluss_m³s"].astype(float)
Messstat["Maximum_Wasserstand"]=Messstat["Maximum_Wasserstand"].astype(float)
Messstat["HQ 100 (m³/s)"]=Messstat["HQ 100 (m³/s)"].astype(float)
Messstat["HW_waterlevel"]=Messstat["HW_waterlevel"].astype(float)
Messstat["HW_Debit"]=Messstat["HW_Debit"].astype(float)
for time in Messstat["Outage_time"]:
if time != (0 or np.nan):
Messstat["Outage_time"]=pd.to_datetime(Messstat["Outage_time"], format='%H:%M:%S') # %d/%m/%Y
else:
print(time)
pass
Messstat["Exceedance"]=Messstat["Exceedance"].astype(float)
Messstat
Reading sheet 0
| Pegelname | Gewässer | Messstellennummer | Stromgebiet | Einzugsgebiet (km2) | Lage oberhalb Mündung (km) | Pegelnullpunkt | Eingerichtet | Lat | Long | Maximum_Abfluss_m³s | Maximum_Wasserstand | HQ 100 (m³/s) | HW_waterlevel | HW_Debit | Outage_time | Exceedance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kirmutscheid | Trierbach | 2718050500 | Ahr+-+Rhein | 88.00 | 3.5 | 317.75 | 1945-01-01 | 50.37 | 6.84 | 82.3 | 269.0 | 94.7 | 307.00 | 104.13 | NaT | 0.10 |
| Niederadenau | Adenauerbach | 2718085500 | Ahr+-+Rhein | 57.03 | 1.26 | 222.01 | 2013-11-13 | 50.44 | 6.93 | NaN | NaN | NaN | 204.00 | 69.66 | NaT | NaN |
| Kreuzberg | Sahrbach | 2718090200 | Ahr+-+Rhein | 45.00 | 1 | 178.89 | 1956-01-01 | 50.51 | 6.97 | 17.9 | 199.0 | 18.9 | 327.00 | 66.44 | 2021-07-14 18:30:00 | 2.52 |
| Altenahr | Ahr | 2718040300 | Rhein | 746.00 | 31.7 | 160.52 | 1991-01-01 | 50.52 | 6.99 | 236.0 | 371.0 | 241.0 | 575.00 | 332.27 | 2021-07-14 19:15:00 | 0.38 |
| Müsch | Ahr | 2718010800 | Rhein | 352.65 | 63 | 292.77 | 1952-01-01 | 50.39 | 6.83 | 132.0 | 273.0 | 152.0 | 304.25 | 320.00 | NaT | 1.11 |
| Denn | Kesselingerbach | 2718070900 | Ahr+-+Rhein | 94.00 | 0.7 | 191.15 | 1955-01-01 | 50.48 | 6.98 | 71.6 | 241.0 | 67.8 | 293.00 | 97.38 | NaT | 0.44 |
Messstat.info()
<class 'pandas.core.frame.DataFrame'> Index: 6 entries, Kirmutscheid to Denn Data columns (total 16 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Gewässer 6 non-null object 1 Messstellennummer 6 non-null object 2 Stromgebiet 6 non-null object 3 Einzugsgebiet (km2) 6 non-null float64 4 Lage oberhalb Mündung (km) 6 non-null object 5 Pegelnullpunkt 6 non-null float64 6 Eingerichtet 6 non-null datetime64[ns] 7 Lat 6 non-null float64 8 Long 6 non-null float64 9 Maximum_Abfluss_m³s 5 non-null float64 10 Maximum_Wasserstand 5 non-null float64 11 HQ 100 (m³/s) 5 non-null float64 12 HW_waterlevel 6 non-null float64 13 HW_Debit 6 non-null float64 14 Outage_time 2 non-null datetime64[ns] 15 Exceedance 5 non-null float64 dtypes: datetime64[ns](2), float64(10), object(4) memory usage: 816.0+ bytes
"Highest measurements" since 1946 vs. the catastrophic flood 14-07-2021¶
The estimation of the return intervals for "high water" were merely based on measured, thus numerical data. This lead to a selection of top 10 events since 1946.
Historical data and writings, letters, watermarks, were available in archives, internet and books, but were bluntly ignored.
However, in 2014 Roggenkamp Thomas published a research with "reconstructed" estimates of outflows for the flood events of 1910 and 1804. The flood of 2016 happened, and "new record" measurements were added to the top 10 events of every station. However, Roggenkamp's work results were not added, perhaps because it does not contain return interval period estimates.
Note that 2 stations were destroyed during the flood, so this plot reflects what has been measured until breaking point.
Later on some estimations of the maxima might be added for a better insight of impact of the failure by neglecting older events.
Messstatdrop = Messstat.drop( index='Niederadenau') # no Niederadenau
Messstatdrop.Exceedance = Messstatdrop.Exceedance*100 #(from % to real )
fig,ax= plt.subplots( 1,1,figsize=(17,5))
plt.title("Highest measurements since 1946 vs. Catastrophic flood 14-07-2021" )
sns.scatterplot(y="Maximum_Wasserstand", x="Maximum_Abfluss_m³s",data=Messstatdrop, hue="Gewässer", marker="o",size="Exceedance",palette="tab10"); #
sns.scatterplot(y="HW_waterlevel", x="HW_Debit", data=Messstatdrop, hue="Gewässer", marker="d",size="Exceedance",palette="tab10" ); # ,
plt.grid(which='both')
ax.set_xscale('log')
plt.legend (loc="lower left", bbox_to_anchor=(0.05, -0.35), ncol= 8);
#sns.barplot(x="Gewässer", y="Maximum_Wasserstand" , data=Messstat, );

df.HW_Debit.min()
Messstat2= pd.read_excel("./data/Messstation.xlsx", index_col=0, engine='openpyxl',na_values="-",verbose=1,sheet_name="Blad2" ) #
Messstat2=Messstat2.T
Messstat2["Eingerichtet"]=pd.to_datetime(Messstat2["Eingerichtet"])
Messstat2["Pegelnullpunkt"]=Messstat2["Pegelnullpunkt"].astype(float)
Messstat2["Einzugsgebiet (km2)"]=Messstat2["Einzugsgebiet (km2)"].astype(float)
Messstat2["Lat"]=Messstat2["Lat"].astype(float)
Messstat2["Long"]=Messstat2["Long"].astype(float)
Messstat2["Maximum_Abfluss_m³s"]=Messstat2["Maximum_Abfluss_m³s"].astype(float)
Messstat2["Maximum_Wasserstand"]=Messstat2["Maximum_Wasserstand"].astype(float)
Messstat2["HQ 100 (m³/s)"]=Messstat2["HQ 100 (m³/s)"].astype(float)
Messstat2["HW_waterlevel"]=Messstat2["HW_waterlevel"].astype(float)
Messstat2["HW_Debit"]=Messstat2["HW_Debit"].astype(float)
for time in Messstat2["Outage_time"]:
if time != (0 or np.nan):
Messstat2["Outage_time"]=pd.to_datetime(Messstat2["Outage_time"], format='%H:%M:%S') # %d/%m/%Y
else:
print(time)
pass
Messstat2["Exceedance"]=Messstat2["Exceedance"].astype(float)
Messstat2
Reading sheet Blad2
| Pegelname | Gewässer | Messstellennummer | Stromgebiet | Einzugsgebiet (km2) | Lage oberhalb Mündung (km) | Pegelnullpunkt | Eingerichtet | Lat | Long | Maximum_Abfluss_m³s | Maximum_Wasserstand | HQ 100 (m³/s) | HW_waterlevel | HW_Debit | Outage_time | Exceedance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kirmutscheid | Trierbach | 2718050500 | Ahr+-+Rhein | 88.00 | 3.5 | 317.75 | 1945-01-01 | 50.37 | 6.84 | 82.3 | 269.0 | 94.7 | 307.0 | 104.13 | NaT | 0.10 |
| Niederadenau | Adenauerbach | 2718085500 | Ahr+-+Rhein | 57.03 | 1.26 | 222.01 | 2013-11-13 | 50.44 | 6.93 | NaN | NaN | NaN | 204.0 | 69.66 | NaT | NaN |
| Kreuzberg | Sahrbach | 2718090200 | Ahr+-+Rhein | 45.00 | 1 | 178.89 | 1956-01-01 | 50.51 | 6.97 | 17.9 | 199.0 | 18.9 | 550.0 | 132.89 | NaT | 6.03 |
| Altenahr | Ahr | 2718040300 | Rhein | 746.00 | 31.7 | 160.52 | 1991-01-01 | 50.52 | 6.99 | 236.0 | 371.0 | 241.0 | 975.0 | 850.00 | NaT | 2.53 |
| Müsch | Ahr | 2718010800 | Rhein | 352.65 | 63 | 292.77 | 1952-01-01 | 50.39 | 6.83 | 132.0 | 273.0 | 152.0 | 400.0 | 320.00 | NaT | 1.11 |
| Denn | Kesselingerbach | 2718070900 | Ahr+-+Rhein | 94.00 | 0.7 | 191.15 | 1955-01-01 | 50.48 | 6.98 | 71.6 | 241.0 | 67.8 | 293.0 | 97.38 | NaT | 0.44 |
With a realistic estimation of actual waterlevel
Messstat2drop = Messstat2.drop( index='Niederadenau') # no Niederadenau
Messstat2drop.Exceedance = Messstat2drop.Exceedance*100 #(from % to real )
fig,ax= plt.subplots( 1,1,figsize=(17,5))
plt.title("Highest measurements since 1946 vs. Catastrophic flood 14-07-2021" )
sns.scatterplot(y="Maximum_Wasserstand", x="Maximum_Abfluss_m³s",data=Messstat2drop, hue="Gewässer", marker="o",size="Exceedance",palette="tab10"); #
sns.scatterplot(y="HW_waterlevel", x="HW_Debit", data=Messstat2drop, hue="Gewässer", marker="d",size="Exceedance",palette="tab10" ); # ,
plt.grid(which='both')
ax.set_xscale('log')
plt.legend (loc="lower left", bbox_to_anchor=(0.05, -0.35), ncol= 8);
#sns.barplot(x="Gewässer", y="Maximum_Wasserstand" , data=Messstat2, );

Historical peak discharges¶
These values were carefully estimated, based on good information gathered by German author Roggenkamp Thomas.
I also added data of some noteworthy historical flood events that had casualties.
peakdisch =pd.read_csv(r"Scheitelabflüsse historischer Ahr-Hochwasser.csv",parse_dates=["Date"],dayfirst=True,
sep=",",index_col=0, skipfooter=2,engine='python', na_values= "-");
peakdisch.head(10)
| Altenahr | Dernau | Walporzheim | Bad Neuenahr | Deaths__missing_persons_excluded | |
|---|---|---|---|---|---|
| Date | |||||
| 21 June 1804 | NaN | 1208.0 | 1180.0 | NaN | 65.0 |
| 24 June 1888 | 280.0 | NaN | NaN | NaN | NaN |
| 13 June 1910 | 496.0 | 549.0 | 541.0 | 585.0 | 150.0 |
| 16 January 1918 | 236.0 | NaN | NaN | NaN | NaN |
| 11 January 1920 | 170.0 | NaN | NaN | NaN | NaN |
| 30 May 1601 | NaN | NaN | NaN | NaN | 9.0 |
| 1 August 1719 | NaN | NaN | NaN | NaN | NaN |
we have to drop the date "30 May 1601", as pandas does not support days for dates earlier than +- 1700.
peakdisch1601 = peakdisch.index[5]
peakdisch = peakdisch.drop( index="30 May 1601")
peakdisch.index = pd.to_datetime( peakdisch.index,) # euro dates\n", format='%d/%m/%Y'
#peakdisch =peakdisch.sort_index(ascending=True) # (\"Date\", inplace=True)\n",
peakdisch.head(10)
| Altenahr | Dernau | Walporzheim | Bad Neuenahr | Deaths__missing_persons_excluded | |
|---|---|---|---|---|---|
| Date | |||||
| 1804-06-21 | NaN | 1208.0 | 1180.0 | NaN | 65.0 |
| 1888-06-24 | 280.0 | NaN | NaN | NaN | NaN |
| 1910-06-13 | 496.0 | 549.0 | 541.0 | 585.0 | 150.0 |
| 1918-01-16 | 236.0 | NaN | NaN | NaN | NaN |
| 1920-01-11 | 170.0 | NaN | NaN | NaN | NaN |
| 1719-08-01 | NaN | NaN | NaN | NaN | NaN |
print(peakdisch.iloc[0,1]/peakdisch.iloc[0,2], peakdisch.iloc[2,1]/peakdisch.iloc[2,2], peakdisch.iloc[2,0]/peakdisch.iloc[2,1])
1.023728813559322 1.0147874306839186 0.9034608378870674
Altenahr1804= 0.9034608378870674*1208
Altenahr1804
1091.3806921675775
(peakdisch.iloc[0,1]/peakdisch.iloc[0,2])/ (peakdisch.iloc[2,1]/peakdisch.iloc[2,2])*( peakdisch.iloc[2,0]/peakdisch.iloc[2,1])*1208/496
2.2197519054939985
fig,ax=plt.subplots(2,1, figsize=(12,6.5) ,sharex=True )
sns.scatterplot(data=peakdisch.iloc[:,:4], label="discharge m³/s", ax=ax[0]);
sns.scatterplot(data=peakdisch.iloc[:,4], label="Deaths__missing_persons_excluded", ax=ax[1]); # x=peakdisch.iloc[:,4].index ,y="Deaths__missing_persons_excluded",

peakdisch.iloc[:,4]
Date 1804-06-21 65.0 1888-06-24 NaN 1910-06-13 150.0 1918-01-16 NaN 1920-01-11 NaN 1719-08-01 NaN Name: Deaths__missing_persons_excluded, dtype: float64
peakdisch.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 6 entries, 1804-06-21 to 1719-08-01 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Altenahr 4 non-null float64 1 Dernau 2 non-null float64 2 Walporzheim 2 non-null float64 3 Bad Neuenahr 1 non-null float64 4 Deaths__missing_persons_excluded 2 non-null float64 dtypes: float64(5) memory usage: 288.0 bytes
Conclusions¶
This is rather a place for interesting points and relevations, than a list of conclusions.
- It is remarkable how many elaborate texts have been produced to establish a system for better highwater protection, alert levels and warning mechanisms etc.
- The omission of non-measured, historical data was a capital mistake.
- Flood event predictions were haplessly underestimated by impact and recurrence interval
- Hence, waterlevel equipment was placed too low, and too close to the flood streams.
- Later I found out that some station had backup sensors, which also produced inconsistent data, and failed in the end.
- The Ahr has not been classified as a "main waterlevel river", although it has a drainage area of 900 km². This has several consequences in the field of highwater protection:
- a highwater event does not lead to a planwise orchestrated information effort to the habitants
- a highwater danger does not lead to a 24 hour service at the highwater notification office
- so there was outside office hours no human supervision of the water level data of the Ahr guaranteed
- luckily the odd data was noted by a higher level federal service, which made a correction
Flood Analysis with Log-Pearson Type III Distribution¶
Notes:¶
- I have based this attempt following "Streamflow Evaluations for Watershed
Restoration Planning and Design", http://water.oregonstate.edu/streamflow/, Oregon State University, 2002-2005, which was based on the guidelines of the USGS.
2. The USA and USGS mainly use the Log-Pearson Type III Distribution for flood modelling, but in Europe authors seem to prefer several (General) Extreme Values models. As a consequence the variance of the regional skewness for Europe is currently under discussion. Moreover there is pretty great variation for this parameter inside the 5 Eur. regions.
Calculator Table 1¶
Pearson_Type_III_Calc =pd.read_excel(r"Log_Pearson_Type_III_Calculator_without2021data.xlsx",index_col=0,skipfooter=98,
usecols="J:K", skiprows=4,engine='openpyxl',); # na_values= "-"parse_dates=["Date"],
#floods["Date"] = pd.to_datetime( River_Arno.Date, format='%d/%m/%Y' ) #floods.set_index(\"Date\", inplace=True),
Pearson_Type_III_Calc.head(39)
| 16 | |
|---|---|
| No. Years in Record | |
| Avg_Qpeak_cfs | 2.81e+02 |
| Avg_LogQ_cfs | 2.35e+00 |
| Sum {(log Q – avg(logQ))^2} | 9.29e-01 |
| Sum {(log Q – avg(logQ))^3 | 4.42e-01 |
| Variance_LogQ_cfs | 6.19e-02 |
| Stdev_LogQ_cfs | 2.49e-01 |
| Skewness (Cs) | 2.18e+00 |
| Skew Coefficient (Cm) | 5.25e-03 |
| Variance of Regional Skewness V(Cm) | 3.02e-01 |
| NaN | NaN |
| Variance of Station Skewness (V(Cs): | 1.05e+00 |
| A value | 1.35e-01 |
| B value | 5.50e-01 |
| Weighting Factor (W) | 2.23e-01 |
| Weighted Skewness (Cw) | 4.90e-01 |
| NaN | NaN |
| NaN | NaN |
| Table Cw upper | 5.00e-01 |
| Table Cw lower | 4.00e-01 |
| Calculated Cw Value | 4.90e-01 |
Calculator Table 2¶
Pearson_Type_III_Calc_Tab2 =pd.read_excel(r"Log_Pearson_Type_III_Calculator_without2021data.xlsx",index_col=0,skipfooter=89,
usecols="J:P", skiprows=26,engine='openpyxl',); # na_values= "-"parse_dates=["Date"],
#floods["Date"] = pd.to_datetime( River_Arno.Date, format='%d/%m/%Y' ) #floods.set_index("Date", inplace=True),
Pearson_Type_III_Calc_Tab2.head(39)
| K lower | K upper | Slope | K calculated | LogQTr_cfs | QTr_cfs | |
|---|---|---|---|---|---|---|
| Tr | ||||||
| 2 | -0.07 | -0.08 | -0.17 | -0.08 | 2.33 | 215.75 |
| 5 | 0.82 | 0.81 | -0.08 | 0.81 | 2.56 | 359.29 |
| 10 | 1.32 | 1.32 | 0.06 | 1.32 | 2.68 | 482.22 |
| 25 | 1.88 | 1.91 | 0.30 | 1.91 | 2.83 | 674.11 |
| 50 | 2.26 | 2.31 | 0.50 | 2.31 | 2.93 | 847.29 |
| 100 | 2.62 | 2.69 | 0.71 | 2.68 | 3.02 | 1049.15 |
| 200 | 2.95 | 3.04 | 0.92 | 3.03 | 3.11 | 1284.30 |
Return times in years based on only recently measured discharges.¶
- The 2nd half of the table is derived from recent data, the first half is based on a timespan of 220 years of data.
- Altenahr was chosen as focus point as it has the most historical data.
AltenahrFloods =pd.read_excel(r"Ahr.xlsx",skipfooter=19, index_col=0,
usecols="A:F", skiprows=41,engine='openpyxl',sheet_name= "floods"); # na_values= "-"parse_dates=["Date"],
AltenahrFloods.style.background_gradient(axis=0, cmap='YlOrRd', low=0.05, high=1) #gmap=AltenahrFloods['Temp (c)']
#AltenahrFloods.head(9)
| LogQ Tr m³s | Q Tr m³/s | Jährlichkeiten Abfluss in m3/s | Abfluss [m³/s] | Abflussspende [l/s km²] | |
|---|---|---|---|---|---|
| Tr for Altenahr | |||||
| 2 | 2.33 | 215.75 | 2 | 93.50 | 125 |
| 5 | 2.56 | 359.29 | 5 | 125.00 | 168 |
| 10 | 2.68 | 482.22 | 10 | 149.00 | 200 |
| 25 | 2.83 | 674.11 | 20 | 176.00 | 236 |
| 50 | 2.93 | 847.29 | 25 | 185.00 | 248 |
| 100 | 3.02 | 1049.15 | 50 | 212.00 | 284 |
| 200 | 3.11 | 1284.30 | 100 | 241.00 | 323 |
AltenahrFloods.info()
<class 'pandas.core.frame.DataFrame'> Int64Index: 7 entries, 2 to 200 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 LogQ Tr m³s 7 non-null float64 1 Q Tr m³/s 7 non-null float64 2 Jährlichkeiten Abfluss in m3/s 7 non-null int64 3 Abfluss [m³/s] 7 non-null float64 4 Abflussspende [l/s km²] 7 non-null int64 dtypes: float64(3), int64(2) memory usage: 336.0 bytes
So based on only recent data, the model - which I doubt to be based on decent hydrological nor decent statistical knowledge - to estimate the flooded areas or the depth of the water estimating an extreme flood, produces a geomap on the official website pictured here:

The map for a less worse "100 year flood" is added under for comparison.

In case you see a clear difference in less than 15 seconds, you must have the eyesight of an eagle.
Return times in years based on 220 years of realistic discharge data.¶
Altenahr was chosen as focus point as it has the most historical data.
fig, ax = plt.subplots(1, 1, figsize=(14,6))
sns.lineplot(x="Tr for Altenahr ", y="Q Tr m³/s" , data=AltenahrFloods,marker="o",label="Data starts 1804" ); #log_x=True,
sns.lineplot(x="Jährlichkeiten Abfluss in m3/s", y="Abfluss [m³/s]", data=AltenahrFloods,marker="o",label="Data starts 1946",color="r",markerfacecolor="crimson" ); #log_x=True,
plt.grid(b=True, which='minor', axis='both')
plt.xscale("log")

Roggenkamp T. estimated the recent flood had a discharge of about 800 m³/s. I think this number will get a bit higher when the waterlevels or outflows of the Adenauerbach station, if ever, get published.
According to this plot we have a return period of 40 years for that discharge value.
Let's hope more useful data gets retrieved...


fig, ax = plt.subplots(1, 1, figsize=(14,6)); sns.regplot(x=AltenahrFloods.index, y="LogQ Tr m³s", data=AltenahrFloods,logx=True,ci=95 ); #"Tr for Altenahr "
plt.grid(b=True, which='minor', axis='both'); plt.ylim(2,3.4)
plt.xscale("log")

fig, ax = plt.subplots(1, 1, figsize=(14,6)); sns.regplot(x=AltenahrFloods.index, y="Q Tr m³/s" , data=AltenahrFloods,logx=True,ci=95); #"Tr for Altenahr "
plt.grid(b=True, which='minor', axis='both'); plt.ylim(0,1300)
plt.xscale("log")

Fit several distributions¶
module reliability
Water levels of 1st flood day¶
from reliability.Distributions import Exponential_Distribution
from reliability.Probability_plotting import Exponential_probability_plot
import matplotlib.pyplot as plt
from reliability.Other_functions import make_right_censored_data
#dist = Exponential_Distribution(Lambda=0.25, gamma=12)
raw_data =Ahr["2021-07-14 12:00":"2021-07-14 19:45"]["Wasserstand in cm"].values # dist.random_samples(100, seed=42)draw some random data from an exponential distribution
#data = make_right_censored_data(raw_data, threshold=17) # right censor the data at 17
Exponential_Distribution(Lambda=0.75).CDF(linestyle='--', label='True CDF') # we can't plot dist because it will be location shifted
Exponential_probability_plot(failures=raw_data, fit_gamma=False) # do the probability plot. Note that we have specified to fit gamma
plt.legend()
plt.show()

1/0.00444
225.22522522522522
As the hydrostation got destroyed, it might be ok to improvise some missing levels and fit again.
from reliability.Fitters import Fit_Everything
data = Ahr["2021-07-14 12:00":"2021-07-14 22:45"]["Wasserstand in cm"].dropna() # created using Weibull_Distribution(alpha=5,beta=2), and rounded to nearest int
data =data.values
Fit_Everything(failures=data, show_histogram_plot=True, show_probability_plot=True, show_PP_plot=True, show_best_distribution_probability_plot=True)




<reliability.Fitters.Fit_Everything at 0x243b959a190>
from reliability.Fitters import Fit_Everything
data = Hochwasser["Wasserstand in cm"].values # created using Weibull_Distribution(alpha=5,beta=2), and rounded to nearest int
Fit_Everything(failures=data, show_histogram_plot=True, show_probability_plot=True, show_PP_plot=True, show_best_distribution_probability_plot=True)




<reliability.Fitters.Fit_Everything at 0x243b8b148e0>
from scipy.stats import gumbel_r
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
#Calculate the first four moments: mean, var, skew, kurt = gumbel_r.stats(moments='mvsk')
#Display the probability density function (pdf): x = np.linspace(gumbel_r.ppf(0.01), gumbel_r.ppf(0.99), 100)
x=[100,200,300,350,375,400,425,450,500,550,600,650,700,800,900]
ax.plot(x, gumbel_r.pdf(x, loc=444.438, scale=65.035), 'r-', lw=1, alpha=0.6, label='gumbel_r pdf');

gumbel_r.pdf(700, loc=444.438, scale=65.035)
0.00029628636780576294
gumbel_r.pdf(900, loc=444.438, scale=65.035)
1.3940569037754993e-05
1/215*gumbel_r.pdf(900, loc=444.438, scale=65.035) # 365.25*
6.48398559895581e-08
yearly maxima¶
from reliability.Fitters import Fit_Everything
raw_data =klima_jahr_1930.JA_MX_RS.dropna() # dist.random_samples(100, seed=42)draw some random data from an exponential distributio
raw_data =raw_data.values
new_arr = np.delete(raw_data, [1])
#data = Hochwasser["Wasserstand in cm"].values # created using Weibull_Distribution(alpha=5,beta=2), and rounded to nearest int
Fit_Everything(failures=new_arr, show_histogram_plot=True, show_probability_plot=True, show_PP_plot=True, show_best_distribution_probability_plot=True)




<reliability.Fitters.Fit_Everything at 0x243beb5deb0>
np.exp(3.51167)
33.504173059055965
from scipy.stats import lognorm
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
raw_data =klima_jahr_1930.JA_MX_RS.dropna() # dist.random_samples(100, seed=42)draw some random data from an exponential distributio
x = raw_data.values # np.linspace(lognorm.ppf(0.01, s), lognorm.ppf(0.99, s), 100)
ax.plot(x, lognorm.pdf(x, s=33.5, loc=3.51167, scale= 0.284678), #
'r+', lw=1.5, alpha=0.6, label='lognorm pdf');

that minimum is an outlier, and should be deleted
type(raw_data.values)
new_arr = np.delete(raw_data.values, [1])
from scipy.stats import lognorm
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
#raw_data =klima_jahr_1930.JA_MX_RS.dropna() # dist.random_samples(100, seed=42)draw some random data from an exponential distributio
x = new_arr # np.linspace(lognorm.ppf(0.01, s), lognorm.ppf(0.99, s), 100)
ax.plot(x, lognorm.pdf(x, s=33.227, loc=3.51167, scale= 0.284678), #
'r+', lw=1.5, alpha=0.6, label='lognorm pdf');

lognorm.pdf(100, s=33.5, loc=3.51167, scale= 0.284678)
0.00012156912574352142
1/lognorm.pdf(100, s=33.5, loc=3.51167, scale= 0.284678)
8225.77273533853
from scipy.stats import lognorm
def test_fix_fit_2args_lognorm(self):
"""Regression test for #1551."""
np.random.seed(12345)
with np.errstate(all='ignore'):
x = lognorm.rvs(0.25, 0., 20.0, size=20)
np.allclose(np.array( lognorm.fit(x, loc=0, scale=20)), # assert
[0.25888672, 0, 20], atol=1e-5)
test_fix_fit_2args_lognorm(20)