经过前面11、13、14、15章的知识铺垫,这一章可以开始介绍LDA(latent Dirichlet allocation,潜在狄利克雷分配)主题模型了,其中会涉及到多项分布、狄利克雷分布,共轭先验,Gibbs采样,EM(期望最大化),VI(变分推断)相关背景知识可在前面章节中找到
一.基本想法¶
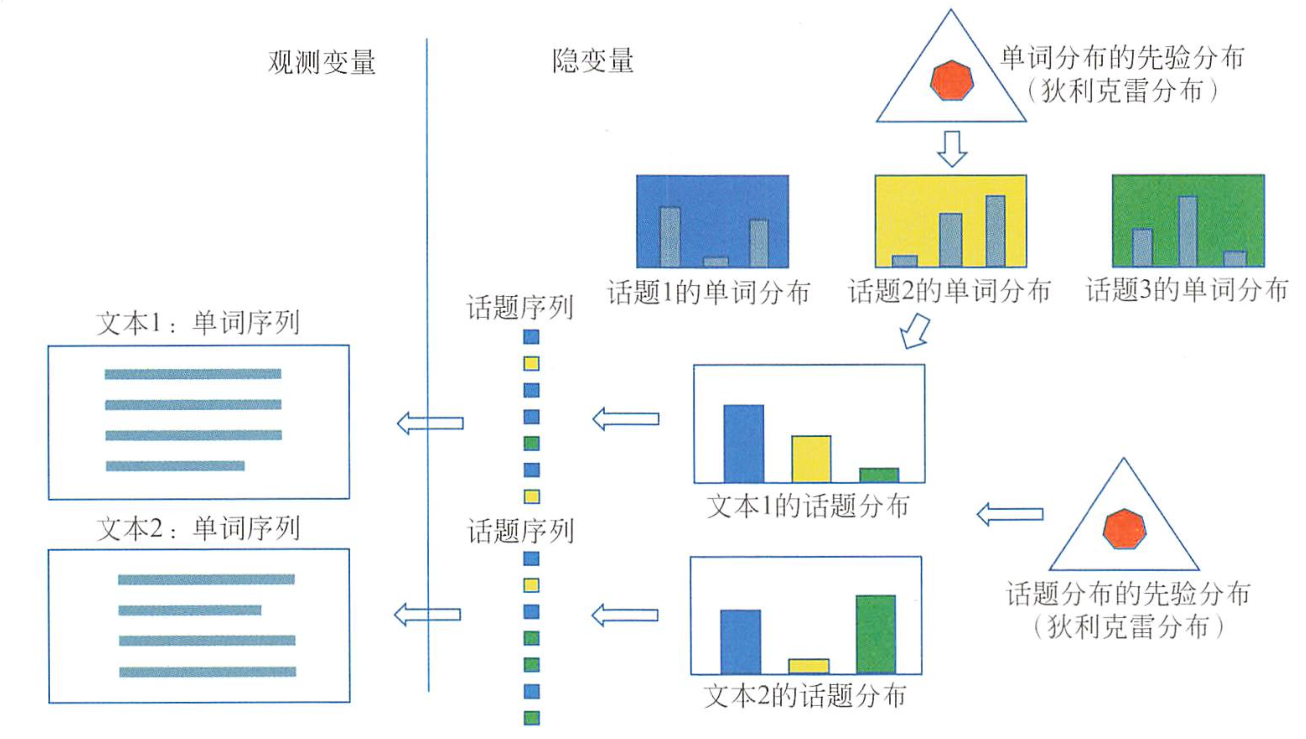
当我们读完一篇文章后,大脑中会对这篇文章所涉及的主题(topic)进行大致归类,比如我们会判断某篇文章介绍的主要是“科技”类主题,那么想想是什么影响因素让我们做出这样的判断?大部分情况是因为文章中涉及的词大多与“科技”相关,比如“人工智能”,“3D打印”,“自动驾驶”等等,这些词语更有可能出现在“科技”类的文章中,而不是出现在比如“房地产”的文章。而LDA便是基于这种自然的想法,假设一篇文章是这样生成的:
(1)为文章定义一个基调,即主题分布,比如“科技”主题出现概率为75%,“金融”主题出现概率为20%,“地产”主题出现概率为5%;
(2)为每个主题定义一个基调,即词语的分布,比如“科技”主题中,10%的概率出现“特斯拉”,10%的概率出现“3D打印”....,而“金融”主题中,仅1%的概率出现“特斯拉”,2%的概率出现“3D”打印...;
(3)遍历文章的每一个位置,假设它的词是这样产生的,从主题分布中随机选择一个主题,然后从该主题中随机选择一个词出来,重复该过程,直到文章结束。
其生成过程可以表示成如下图所示
二.概率图表示¶
接下来,我们将上面的过程抽象为盘子图,表示如下
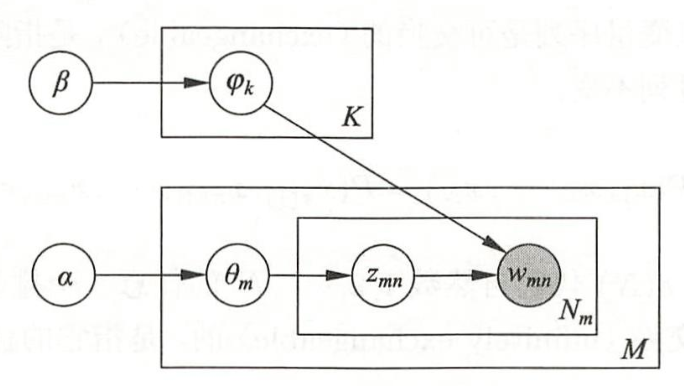
这里:
(1)$\beta=(\beta_1,\beta_2,...,\beta_V)$是狄利克雷分布$Dir(\beta)$的超参数,$V$表示词典$W=(w_1,w_2,...,w_V)$的大小,所以$Dir(\beta)$表示单词分布的先验分布,通过$Dir(\beta)$随机生成一个参数向量$\varphi_k,\varphi_k\sim Dir(\beta)$,作为话题$z_k$的单词分布$p(w\mid z_k),w\in W$,重复该过程$K$次,即$k=1,2,...,K$,共$K$个话题
(2)$\alpha=(\alpha_1,\alpha_2,...,\alpha_K)$是狄利克雷分布$Dir(\alpha)$的超参数,$K$即上面的话题数,而$\theta_m\sim Dir(\alpha)$,它表示第$m$篇文本$W_m$的话题分布$p(z\mid W_m)$,重复该过程$M$次,即$m=1,2,...,M$
(3)$z_{mn}$表示第$m$篇文本的第$n$个词所属的话题,它满足$z_{mn}\sim \theta_m$,而$w_{mn}$即是我们观测到的词,它满足$w_{mn}\sim\varphi_{z_{mn}}$,重复该过程$N_m$次,即$n=1,2,...,N_m$,$N_m$表示第$m$篇文本的词数
接下来,我们使用符号化的语言来描述LDA文本生成过程:
(0)给定超参数$\alpha,\beta$;
(1)对于话题$z_k(k=1,2,...,K)$,生成多项分布参数$\varphi_k\sim Dir(\beta)$,作为话题的单词分布$p(w\mid z_k)$;
(2)对于文本$W_m(m=1,2,...,M)$,生成多项分布参数$\theta_m\sim Dir(\alpha)$,作为该文本的话题分布$p(z\mid W_m)$;
(3)对于文本$W_m$的单词$w_{mn},m=1,2,..,M,n=1,2,...,N_m$:
(a)生成话题$z_{mn}\sim Mult(\theta_m)$,作为第$n$个位置的话题;
(b)生成单词$w_{mn}\sim \varphi_{z_{mn}}$
三.概率公式¶
根据概率图模型的结构,我们可以写出联合概率分布为:
$$ p(W,Z,\theta,\varphi\mid\alpha,\beta)=\left[\prod_{k=1}^Kp(\varphi_k\mid\beta)\right]\prod_{m=1}^M\left[p(\theta_m\mid\alpha)\prod_{n=1}^{N_m}p(z_{mn}\mid\theta_m)p(w_{mn}\mid z_{mn},\varphi) \right]\\ =\left[\prod_{k=1}^Kp(\varphi_k\mid\beta)\right]\prod_{m=1}^M\left[p(\theta_m\mid\alpha)\prod_{n=1}^{N_m}\left[\sum_{l=1}^Kp(z_{mn}=l\mid\theta_m)p(w_{mn}\mid \varphi_l) \right] \right] $$这里,$W$表示所有文本的单词序列,隐变量$Z$为$W$对应的话题序列,$\theta$表示所有文本的话题分布参数,$\varphi$表示所有话题的单词分布参数,$\alpha,\beta$为已知的超参数
四.参数估计¶
接下来需要考虑的就是如何估计我们的参数$\theta,\varphi$,这本质上等价于对$M+K$个分布的估计,即$p(w\mid z_k),k=1,2,...,K$和$p(z\mid W_m),m=1,2,...,M$,虽然我们上面写出了联合概率分布,并且从理论上来说联合概率分布可以推导出任意我们想要的条件概率分布或者边缘概率分布,但直觉告诉我们LDA的条件概率分布显然不是那么容易求解的,哈哈哈哈~~~,所以我们需要考虑去近似它,通过前面章节的介绍,可以知道:一种方式是利用MCMC采样去近似,后面我们会利用Gibbs采样去近似参数$\theta,\varphi$,而另一种方式便是采用变分推断的方式,利用一些相对简单的分布去解析近似我们的目标分布,接下来两节分别对这两种方式进行实践