如果大家看过前面EM的推导,会发现VI与EM的推导十分类似,这一节将要说明它们的推导框架其实是一样的,同时在ELBO函数和KL距离上分析E步和M步更新的本质
一.EM的推导框架¶
前一节推导中我们将参数和隐变量合并到一个变量$Z$中了(其实参数也可以看做隐变量,只是狭义上理解的隐变量会随着观测数据的规模递增,而参数不会),这一节我们将其拆开为$Z$和$\theta$,其中$Z$表示隐变量(狭义上的),$\theta$表示参数,所以上一节的VI框架可以表示如下:
$$ ln\ p(X\mid \theta)=\mathcal{L}(q,\theta)+KL(q\mid\mid p) $$其中:
$$ \mathcal{L}(q,\theta)=\sum_Z q(Z)ln[\frac{p(X,Z\mid\theta)}{q(Z)}]\\ KL(q\mid\mid p)=-\sum_Zq(Z)ln[\frac{p(Z\mid X,\theta)}{q(Z)}] $$这时,三者间的关系可以表示如下:

这似乎和前面的Q函数啥的也扯不上关系呀?别慌,接下来看看E步和M步的更新
二.E步和M步更新¶
EM中要做的事情就是在当前参数$\theta^{old}$的基础上更新一个新的参数$\theta^{new}$使得$ln\ p(X\mid\theta^{new})\geq ln\ p(X\mid\theta^{old})$,接下来看看E步,E步其实做了这么一件事,它令:
$$ q(Z)=p(Z\mid X,\theta^{old}) $$这样就会使得$KL(q\mid\mid p)=0$,所以这时的ELBO函数的值就等于对数似然函数的值,即:
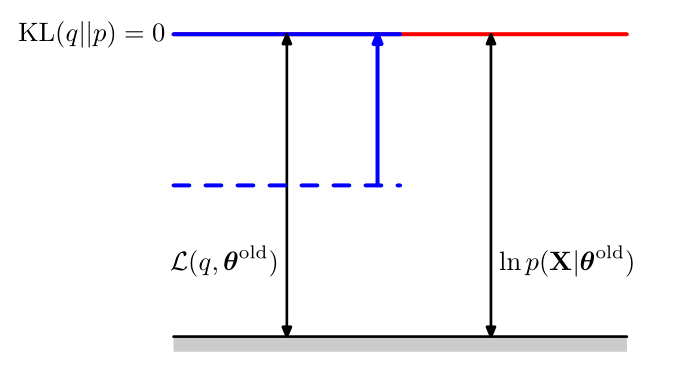
然后接下来的M步就是去最大化ELBO函数咯,由于KL距离一定大于等于0,所以对数似然函数的值必然会升高,等等...记忆好的同学会发现这里不对,之前的EM中不是去最大化Q函数吗?怎么这里变成了最大化ELBO函数了,其实它们的最优解是一样的,两个函数只差了一个常数项,而这个常数项恰好就是$q$分布的熵:
$$ \mathcal{L}(q,\theta)=\sum_Zp(Z\mid X,\theta^{old})ln\ p(X,Z\mid\theta)-\sum_Zp(Z\mid X,\theta^{old})ln\ p(Z\mid X,\theta^{old})\\ =Q(\theta,\theta^{old})+const $$另外需要注意一下的是,KL距离也会升高,因为更新后KL函数中的$q(Z)$项还固定为$p(Z\mid X,\theta^{old})$,而$p(Z\mid X,\theta)$项已经更新为$p(Z\mid X,\theta^{new})$,而通常$p(Z\mid X,\theta^{old})\neq p(Z\mid X,\theta^{new})$,所以M步更新后会有$KL(q\mid\mid p)>0$,这时三者的关系可以表示如下:
 其中,虚线表示取$\theta^{old}$的情况
其中,虚线表示取$\theta^{old}$的情况
三.VI与EM的差别¶
其实VI与EM的差别主要在于:
(1)VI是在求一个函数$q(Z)$,使得$q(Z)\rightarrow p(Z\mid X)$,它并不会影响$ln\ p(X)$的值;
(2)而EM是在求一个最优参数$\theta$使得$ln\ p(X\mid \theta)$尽可能的大