样本采样与特征采样¶
类似于randomforest,xgboost也可进行bootstrap的样本采样,和随机列采样,以增强模型的泛化能力,避免过拟合
稀疏/缺失值处理¶
xgboost会为稀疏/缺失值选择一个默认方向,如果训练集中有稀疏/缺失值,通过计算其增益来选择往左还是往右作为默认方向,如果训练集中没有,则选择往右为默认方向
直方图算法:快速切分点查找¶
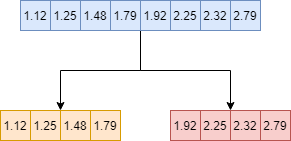
在构建树时,最重要的操作便是特征及其对应的切分阈值的查找,CART一般选择一种精确的贪心搜索,即遍历所有的特征及其所有可能的取值情况,这非常耗时,xgboost采用了直方图优化策略,具体操作其实很简单,就是对数据做了一个分箱的操作,如下图,将8个连续数值分成了两组,分组前有7个切分点需要搜索,而分组后只有一个切分点,而对于更加一般的情况,连续值的取值情况往往要多的多,分组操作将极大的提高搜索速度,而且还能在一定程度上防止过拟合
而且分箱操作还能在存储和计算上带来好处:
(1)存储上,之前需要使用float类型,而分箱后只需要使用int类型,内存使用缩小为$\frac{1}{8}$;
(2)计算上也可以做优化,比如需要计算右孩子节点的直方图分布,只需使用父节点的直方图分布减去左孩子的直方图分布即可,无需再次统计
另外分箱还有两种策略,全局策略和本地策略:
(1)全局策略:全局只做一次分箱操作;
(2)本地策略:每个节点在分裂时,都会重新做一次分箱操作;
全局策略操作简单,而本地策略可能取得更好的精度;上面的分箱操作其实是分位数查找法,xgboost还有其他的分位数查找法:
(1)误差分位数法:对于数据量太大的情况,没法直接将所有特征取值加载进内容,所以没法精确的求解分位点,该算法>>>构造了一种数据,可以以一定误差保存流式数据的分位点;它的优化版本:A fast algorithm for approximate quantiles in high speed data streams 被用于xgboost中
(2)加权分位数法:基本思想是,如果样本的预测结果越不稳定,则需要更细的切分粒度,而二阶导可以用来衡量预测结果的不稳定性,二阶导绝对值越大的样本点越需要被细分
leaf-wise vs level-wise¶
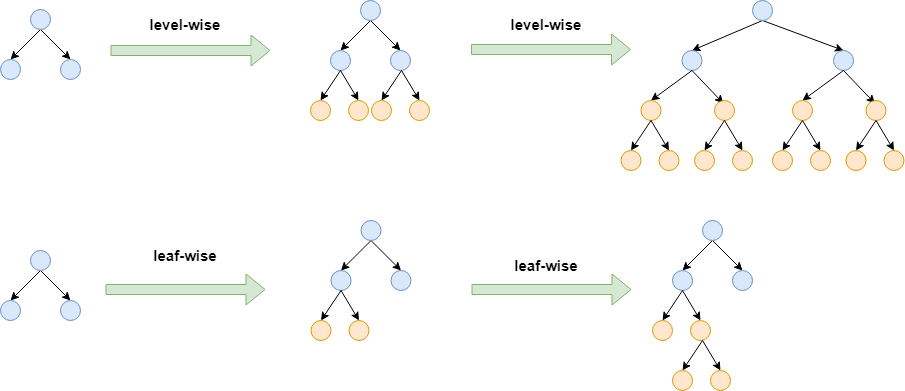
leaf-wise和level-wise是树的两种生成策略,如下图所示,level-wise是逐层生成决策树,而leaf-wise是按需生成决策树,如果切分后某子节点的收益较低,则不会生成该子节点,这极大的提升了训练速度
系统层面的优化¶
这部分内容简略介绍,主要有稀疏数据列压缩、缓存感知访问、外存块计算优化、分布式计算、GPU加速
稀疏数据列压缩¶
xgboost会对稀疏数据进行列压缩(Compressed Sparse Column,CSC),这可以提高特征值排序的效率,方便节点分裂时的特征选择
缓存感知访问¶
由于每个特征其特征值的排序不同,再对一阶、二阶导数的提取时,会有非连续内存访问的问题,将这些数据放入CPU缓存可以提高计算的效率,具体做法是把某些连续有序的mini-batch数据的统计值缓存到CPU缓存,这样其他特征在做特征选择时,有可能命中这部分数据
外存块计算优化¶
整个特征选择的过程其实是按“列”进行的,也就是说对某列进行操作时,其他的列其实并没有被使用(lable除外),所以树的训练过程并不用将所有数据加载到内存,而是可以按需载入,这部分可以分两个线程来做:一个线程负责计算,另一线性负责数据读取
分布式计算¶
目前xgboost在主流的分布式计算平台上均有实现,比如spark,flink等
GPU加速¶
xgboost在按level-wise方式生成树时可以通过gpu提速,通过gpu可以同时对一层的数据进行处理,从而提高最优切分点的查找效率;而节点的桶排序也可通过CUDA原句实现的基数排序优化