Python3不完全入门指南¶
作者:集美大学 郑如滨
1.第一个Python程序¶
Hello, World入门
- 启动Python Shell
- 使用cmd命令启动windows命令行
- 输入python启动Python Shell
- 在
>>>后面输入python命令进行解释执行 - 在
>>>后面输入quit()或者按住ctrl+z退出Python Shell

基本概念1¶
- 缩进:本教程统一以4个空格作为缩进。下列代码
def hello(name, age):下一行的print左侧有4个空格,这就是缩进。 - def关键字:即define,函数定义关键字。下列代码定义了
hello函数,有两个入参name, age。 - 入参:只需给定入参名,Python中无需指定入参数据类型。
- 多个返回值:Python中,函数可以有多个返回值。
print("你好!欢迎来到Python3的世界.")#直接输出信息到控制台
def hello(name, age):#函数定义
print("{}你好,你的年龄是{}岁!".format(name, age)) #{}代表槽。将fromat后面的变量值依次放入槽中。
return "张"+name,age+1
x, y = hello("小明",12) #函数调用
print("函数返回值:",x, y)
你好!欢迎来到Python3的世界. 小明你好,你的年龄是12岁! 函数返回值: 张小明 13
#Python的函数可以同时返回多个值,本质上多个返回值是以元组类型返回。
def findMaxAndMin(a,b,c):
'''
这里面的内容是注释,不参与运行
功能:求出a,b,c中最大与最小值
输入:a,b,c三个数值类型数据
返回:期中的最大值与最小值
'''
maxNum = minNum = a
if b>maxNum:
maxNum = b
if c>maxNum:
maxNum = c
if b<minNum:
minNum = b
if c<minNum:
minNum = c
return maxNum,minNum #我是注释,返回maxNum与minNum
a,b,c = -1,0,1
x = findMaxAndMin(a,b,c)
print(type(x),x)
maxNum, minNum = findMaxAndMin(a,b,c)
print("maxNum,minNum = ",maxNum,minNum)
<class 'tuple'> (1, -1) maxNum,minNum = 1 -1
基本概念2¶
变量: Python中无需为变量事先指定类型。如
x = 5(实际上x是int型),str1 = "abc"(实际上str1为str型,即字符串型)注释:可以使用#号,如#这是一个注释 来进行注释。还可使用一对 三个
'对多行文本进行注释,如
'''
功能:求出a,b,c中最大与最小值
输入:a,b,c三个数值类型数据
返回:期中的最大值与最小值
'''
- 缩进:Python靠代码块的缩进来体现代码之间的逻辑关系。建议使用4个空格作为标准的缩进量。在IDLE中,可使用Tab键自动缩进4个空格。
- .py扩展名: 代表Python源文件。将上述源代码存为
Test.py文件。然后在命令行下使用命令python Test.py进行解释执行。如下图所示

注1:Test.py文件应采用UTF-8编码。
注2:可在IDLE中选择File-New File,新建Python源文件,然后保存。
2.Python数据类型与流程控制¶
2.1 数据类型¶
2.1.1 数值类型(Numberic Types)¶
包含3种数值类型:整数(int)、浮点(float)、复数(complex)
- 整数:包括了所有的整数,无范围限制。
- 浮点:有小数的数值。
- 复数:如,2+3j
x,y,z = 10, 3.14,2+3j
print(x/3) #除法
print(x//3) #求整
print(x%3) #取余
print(2**x) #乘方
print(z)
x = 9999999999999999999999999999999999999 #整型无范围限制
print("x+1",x+1)
3.3333333333333335 3 1 1024 (2+3j) x+1 10000000000000000000000000000000000000
math模块的导入与使用:
进行数学运算时,可使用math库。
导入方法1: import 模块名 [as 别名]。如
- import math
- import random
- import numpy as np
import math
print(math.sqrt(9)) #求开根号使用“模块名.函数名”形式调用
import math as m
print(m.gcd(1024, 512)) #求最大公约数。使用“别名.函数名”形式调用
import random
x=random.random() #在[0,1)范围上生成浮点型随机数
print(x)
print(random.randint(1,100))#在[1,100]范围上生成随机整数
import numpy as np #导入numpy模块,然后为其取别名np。注意:首先要pip install numpy安装numpy模块后,才可使用。
a = np.array((1,2,3)) #创建numpy中的array
print(a)
3.0 512 0.797131957122589 23 [1 2 3]
导入方法2:from 模块名 import 对象名/函数名 [as 别名]
from 模块名 import 对象名/函数名仅导入指定模块的某个对象或函数。其他未导入的对象/函数无法使用。
from math import *一次性导入模块中的所有对象或函数。
from math import *
print(sqrt(9)) #直接使用math模块中的函数名sqrt调用
from math import sin
print(sin(3))
from math import sin as f
print(f(3))
3.0 0.1411200080598672 0.1411200080598672 2
2.1.2 布尔型¶
值只有True和False。在Python中0或False代表false(假),1或True代表true(真)。
x1 = False
x2 = True
b = 100>101
print(b)
print(1!=2,3!=3,5==5,5==6)
x, y = 10, 11
if x>y:
print(x,"比",y,"较大!")
else:
print(y,"比",x,"大!")
print(1 == True, 0 == False)
False True False True False 11 比 10 大! True True
其他:逻辑运算符
and 与,or 或,not 非
x1 = True
x2 = False
print(not x1,x1 and x2, x1 or x2)
False False True
2.1.3 序列类型(Sequence Types)¶
包含三种类型:字符串(str),列表(list),元组(tuple)。
共同特点:其中的元素均按顺序排列(符合线性表定义).
字符串的形式:两个双引号
""或两个单引号''将字符串括起来。列表的形式 []
元组的形式 ()
2.1.3.1 序列共同操作¶
序列的大部分共同操作可适用于所有序列类型,如字符串、列表与元组。
序列通用函数:索引、分片、连接(加)、重复(乘)、in操作(成员判断)
序列相关函数:len(),min(),max(),sum()
L=[] #定义一个空列表
L1=[1,3,5,7,9]
L2=[11,12]
str1 = "abcde"
str2 = "fgh"
print('索引操作:', L1[1], str1[1])
print('分片操作:', L1[1:3], str1[1:3]) #L1[i:j]代表从L1列表中截取从位置i到位置j-1的所有元素,并作为列表返回。
print('链接操作:', L1 + L2, str1 + str2)
print('重复操作:', L2*2 , str2*2)
print('in操作:', 3 in L1, 'x' in str1) #判断3有无在L1中,'x'有无在str1中
print(len(L1), min(L1), max(L1), sum(L1))
print(len(str1),min(str1),max(str1))
索引操作: 3 b 分片操作: [3, 5] bc 链接操作: [1, 3, 5, 7, 9, 11, 12] abcdefgh 重复操作: [11, 12, 11, 12] fghfgh in操作: True False 5 1 9 25 5 a e
2.1.3.2 列表(list)与for循环¶
list1 = [1,2,3,4,5]
for e in list1: #打印出list1中的所有元素
print(e)
list1.append(1) #列表末尾添加1这个元素
#输出每个元素都在其后加1空格
for e in list1:
print(e,end=' ') #打印e,e后面添加一个空格(不换行)。
print() #换行
print("list1的长度为{},内容为{}".format(len(list1),list1))
print("list1中1的个数为{},第2个元素为{}".format(list1.count(1),list1[1]))
list1.reverse()
print("逆序:",list1)
list1.sort() #就地排序,改变list1中元素的排列
print("升序排序后的结果:",list1)
list1.sort(reverse = True) #就地排序,改变list1中元素的排列
print("降序排序后的结果",list1)
ls = list() #创建一个空列表。也可以使用ls = []创建空列表。
print(len(ls),type(ls))
charList = list("abcde") #使用list函数创建一个字符列表。
print(charList)
1 2 3 4 5 1 2 3 4 5 1 list1的长度为6,内容为[1, 2, 3, 4, 5, 1] list1中1的个数为2,第2个元素为2 逆序: [1, 5, 4, 3, 2, 1] 升序排序后的结果: [1, 1, 2, 3, 4, 5] 降序排序后的结果 [5, 4, 3, 2, 1, 1] 0 <class 'list'> ['a', 'b', 'c', 'd', 'e']
二维或多维数组:
c或者java中有多维数组,Python中也有。
matrix = [[1,1,1],[2,2,2],[3,3,3]] #直接创建二位数组
print(matrix)
print(matrix[0])
print(matrix[2][1])
for line in matrix: #遍历多维数组
for e in line:
print(e, end=" ")
print()
matrix = [[0 for j in range(5)] for i in range(3)] #使用列表生成式语法创建一个3*5的二位数组
print(matrix)
[[1, 1, 1], [2, 2, 2], [3, 3, 3]] [1, 1, 1] 3 1 1 1 2 2 2 3 3 3 [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
2.1.3.3 range¶
顾名思义,range可用来产生某个范围的整数序列。
两种用法:
range(stop) #产生从0开始直到stop-1个整数序列range(start,stop,[,step])#产生从start开始,直到stop-1的整数序列,步进为step
for i in range(3): #range(3)为从0开始,产生包含3个整数的序列。然后使用for在该序列上遍历
print(i, end = " ")
print()
for i in range(1,5):#从1开始,默认步进为1
print(i,end=" ")
print()
for i in range(1,5,2):#步进为2
print(i,end=" ")
print()
for i in range(5,1,-1):#从后往前
print(i,end=" ")
print()
#使用range遍历列表
list1 = ['a','b',3,5,6]#python的list中的元素可以为不同类型
for i in range(len(list1)):
print(list1[i],end = " ")
print()
list2 = list(range(10))
print("使用list函数结合range创建一个有10个大小的list,其内容为",list2)
0 1 2 1 2 3 4 1 3 5 4 3 2 a b 3 5 6 使用list函数结合range创建一个有10个大小的list,其内容为 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2.1.3.4 while循环¶
i,temp = 1,0
while i<=100:
temp += i
i += 1
print(temp)
flag = True
while flag:
str1 = input("输入x退出:")
if str1 == 'x':
flag = False
else:
print("继续输入")
print("flag =",flag)
5050 输入x退出:1 继续输入 输入x退出:x flag = False
2.1.3.5 字符串¶
使用单引号或双引号包含起来的是字符串,如"Hello World"或'Hello World'都代表字符串
如果字符串中包含单引号',可以用"将其包括起来,如"book's price"代表字符串book's price。
反之也成立,如'Zhang says "How are you!"'代表字符串Zhang says "How are you!"
str1,str2 = '张三',"350204200110231013"#使用''或者""将字符串包含在其中
"""
可以使用三个引号"
将多行字符串一起注释
"""
print("字符串的拼接:",str1+"的身份证号是"+str2)
#可以将字符串看成一个字符列表
for e in str1:
print(e,end=" ")
print()
#字符串既然可以看作列表,可以对其进行切片
print(str1,'的出生日期是',str2[6:14])
print(str2,'前6位为',str2[:6])
print(str2,'后4位为',str2[-4:])
#使用ord获得某个字符对应的整数值
print('A =',ord('A'))
#使用chr获取整数值对应的字符
print('65 =',chr(65))
print('打印5个str1:',str1*5)
#演示字符串自带的函数
if str2.isdigit():
print("%s是一个数"%str2)
elif str2.isalpha():
print("%s全是字母"%str2)
elif str2.isalnum:
print("%s包含字母或者数字"%str2)
str3 = 'xyz'
while True:
x = input("请输入一个数字:")
if x in str2:
print(x,"在",str2,'中')
elif x in str3:
print(x,"在",str3,'中')
elif x in "q":
print("您刚才输入了字符q,现在退出循环!")
break;
else:
print("%s既不在%s也不在%s中"%(x,str2,str3))
字符串的拼接: 张三的身份证号是350204200110231013 张 三 张三 的出生日期是 20011023 350204200110231013 前6位为 350204 350204200110231013 后4位为 1013 A = 65 65 = A 打印5个str1: 张三张三张三张三张三 350204200110231013是一个数 请输入一个数字:13 13 在 350204200110231013 中 请输入一个数字:96 96既不在350204200110231013也不在xyz中 请输入一个数字:q 您刚才输入了字符q,现在退出循环!
字符串格式化¶
字符串有两种格式化方法。使用%或使用字符串本身的format函数。
1.使用%
类似于c语言中printf中的%。
常见格式字符:%d 十进制整数, %x 十六进制整数;%f 浮点数;%% 百分号;%s字符串。 例子如下:
name = '手机'
price = 2699.66789
num = 100
rate = 56.1
print("这款%s的价格是%.2f,销量为%d(对应十六进制为%x),销售占比为%F%%."%(name, price, num, num, rate))
这款手机的价格是2699.67,销量为100(对应十六进制为64),销售占比为56.100000%.
2.使用字符串的format函数
不同于使用%,format函数在字符串中使用了占位符槽({})概念。参数可以代入占位符。格式字符与%方式基本相同。
还可使用{}中带数字的方法来使用后面指定位置参数,如{0},代表使用后面第1个参数。
例子如下:
name = '手机'
price = 2699.66789
num = 100
rate = 56.1
print("这款{}的价格是{}".format(name,price))
print("这款{}的价格是{:.2f},销量为{},销售占比为{}%。销量对应的十六进制为{:x}。".format(name, price, num,rate,num))
print("这款{0}的价格是{1:.2f},销量为{2},销售占比为{3}%。销量对应的十六进制为{2:x}。".format(name, price, num,rate)) #指定顺序
这款手机的价格是2699.66789 这款手机的价格是2699.67,销量为100,销售占比为56.1%。销量对应的十六进制为64。 这款手机的价格是2699.67,销量为100,销售占比为56.1%。销量对应的十六进制为64。
字符串相关常用函数¶
字符串专有函数:split, join, strip
split() 通过指定分隔符对字符串进行切片
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串
strip() 移除字符串头尾指定的字符(默认为空格)
#split
str3 = "a b c def g"
str3List = str3.split() #以1个空格或者多个空格为分隔符切片字符串
print(str3List)
str3 = 'x,y,z,abc,def'
str3List = str3.split(',') #以,为分隔符切片字符串
print(str3List)
#join
str1 = '-'
print(str1.join(str3List)) #使用-拼接字符
str2 = " abc def "
print(str2.strip()) #移除字符串前后所有空格
str2 = "**1 * asdfdf 3445**"
print(str2.strip('*')) #移除字符串前后所有*,直到碰到其他字符
字符串与数值类型相互转化¶
str1 = str(123.5)
num1 = int("12")
num2 = float("12.45")
print(type(str1),type(num1),type(num2))
2.1.4 元组(tuple)¶
与列表类似,但元组的元素不能修改,访问速度快,使用小括号()标识。
student1 = ("张三",19,['语文','数学','英语']) #元组、列表中的元素均可为不同类型。
print(type(student1[0]),type(student1[1]),type(student1[2]))#输出元组中每个元素的类型
print(student1[0],student1[1],student1[2])
x,y,z = student1 #序列解包
print(type(z))
print(student1[2][2])
for e in student1: #元组也是序列
print(e,end=" ")
print("")
tup1 = (50,); #只有一个元素的元组,注意:不能使用tup1=(50),这个表达式指的是tup1存放一个整数50
print("元素修改演示:")
student1[2][0] = "体育" #可以修改成功。注意:这里并没有修改元组中的列表,而是修改元组中列表中所包含的元素
print(student1)
student1[1] = 18 #出错!元组不支持修改其中的元素
<class 'str'> <class 'int'> <class 'list'>
张三 19 ['语文', '数学', '英语']
<class 'list'>
英语
张三 19 ['语文', '数学', '英语']
元素修改演示:
('张三', 19, ['体育', '数学', '英语'])
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-5-35fbeddfe469> in <module> 12 student1[2][0] = "体育" #可以修改成功。注意:这里并没有修改元组中的列表,而是修改元组中列表中所包含的元素 13 print(student1) ---> 14 student1[1] = 18 #出错!元组不支持修改其中的元素 TypeError: 'tuple' object does not support item assignment
2.1.5.1 集合(Set)¶
集合中的元素不能重复,使用{}包括起来。
集合常用于去重、成员判断、数学运算。
set0 = {1,2,1}
print("set0",set0)
charSet = set("abcdeabcde")
print("charSet",charSet)
ls = [1,2,3,4,5,1,3,5]
set1 = set(ls) #使用set来去重
print("set1",set1)
set2 = set() #创建一个空集合,不能使用{}来创建空集合。因为这是一个字典
if 7 in set1: #使用in或not in进行成员判断,否则remove一个不存在的元素会异常。
set1.remove(7)
set0 {1, 2}
charSet {'c', 'b', 'e', 'a', 'd'}
set1 {1, 2, 3, 4, 5}
2.1.5.2 字典(dict)¶
字典的创建,可使用{}将一些key:value括起来。
字典用法:通过某个值(key)快速查找对应的值(value)。比如,通过学号这个key来查找学生姓名这个value。
字典中的每一个元素都是一个键值对(key:value),类似于y=f(x)
字典的键不能重复,值可以重复。
示例如下:
dict1 = {"张三":95,"李四":95,"王武":85}
print(dict1["张三"]) #通过key取得对应的value,可能会产生KeyError
print(dict1.items()) #items()获得一个键值对视图
print(dict1.keys()) #keys()获得一个键值视图
print(dict1.values()) #valuess()获得一个值视图
print(dict1.get("张三")) #找到,返回95
print(dict1.get("张")) #没找到,返回None
print("在字典中没找到'张',返回",dict1.get("张",0)) #没找到,返回指定的0
emptyDict = {} #创建一个空字典,也可使用dict()创建空字典
print(emptyDict)
if "赵二" in dict1: #通过in或not in查看key是否在dict1的键集中。如果key不在dict1中,直接del dict1[key]会引发异常
del dict1["赵二"]
95
dict_items([('张三', 95), ('李四', 95), ('王武', 85)])
dict_keys(['张三', '李四', '王武'])
dict_values([95, 95, 85])
95
None
在字典中没找到'张',返回 0
{}
练习(字典):编写一个函数,统计一个字符串中每个字母出现的频率。
2.2 流程控制¶
2.2.1 分支结构(if..elif..else...)¶
if elif else 及break、continue用法基本同C与Java
x = int(input())
if x % 2 == 0:
print("{} b是偶数".format(x))
else:
print("{} 是奇数".format(x))
1 1 是奇数
多重if..elif..lf语句
x = int(input())
if x > 0:
print("大于0")
elif x == 0:
print("等于0")
else:
print("小于0")
2.2.2 循环结构(for与while)¶
和Java中的foreach循环很相似。
ls = list("abcxyz")
for e in ls:
print(e, end = " ")
print()
a b c x y z
但是没有c和java中普遍存在的for(int i = 0; i < 5;i++)语法,即,不存在每个元素都有着对应的下标。如何对每个元素赋予下标?
ls = list("abc")
for i,e in enumerate(ls):
print(i,e)
ls[i] = ord(e)
print(ls)
0 a 1 b 2 c [97, 98, 99]
# 输入quit推出,输入其他值直接输出
x = input()
while (x!='quit'):
print('You just input:',x)
x = input()
print('end')
hi You just input: hi quit end
2.2.3 pass关键字¶
仅用于占位,什么都不做
x = input()
if x == "n": #如果x==n,则什么都不做
pass
else:
print(x)
n
pass常见方法:
定义函数、类的时候还未想好定义,或者某个部分暂时不知道怎么写的使用pass关键字代替
def foo():
pass
class StuClass:
pass
foo() #调用foo函数,碰到pass,什么也不做
2.3 其他¶
2.3.1 del 关键字¶
del作用于变量名与列表名,将解除变量与值之间的指向关系。当再次使用时,将出现NameError。
x = 3
del x
print(x) #会出错,因为x已经被释放
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-49-17e0ae5ab1a4> in <module> 1 x = 3 2 del x ----> 3 print(x) NameError: name 'x' is not defined
list1 = [1,2,3]
del list1 #这里是删除列表,也可以删除某个元组
print(list1) #会出错,因为list1已经被释放
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-2-31bf9fa929dc> in <module> 1 list1 = [1,2,3] 2 del list1 #这里是删除列表,也可以删除某个元组 ----> 3 print(list1) #会出错,因为list1已经被释放 NameError: name 'list1' is not defined
将del用于列表中的某个元素,为删除该元素。
注1:del不能用于元组,因为元组是不可变序列
list1 = [0,1,2,3,4,5,6,7,8,9,10]
del list1[3]
print(list1)
del list1[5:8] #删除分片
print(list1)
[0, 1, 2, 4, 5, 6, 7, 8, 9, 10] [0, 1, 2, 4, 5, 9, 10]
2.3.2 生成列表与列表生成式¶
有多种方式生成列表。
ls1 = [] #生成一个空的列表
ls2 = [1,2,3] #定义的时候直接生成一个列表
ls3 = list(range(10)) #利用range函数生成列表
print('ls1=',ls1,'ls2=',ls2,'ls3=',ls3)
print(list("abc")) #利用可迭代对象(字符串)生成列表
print(list(ls2)) #利用可迭代对象(列表)生成列表
print(list((1,3,5))) #利用可迭代对象(元组)生成列表
ls4 = ls3[::] #利用切片生成一个列表
print('ls4=',ls4,'id(ls3)==id(ls4)',id(ls3)==id(ls4))
for e in ls3: #将ls3中的所有偶数都加入ls1中
if e % 2 == 0:
ls1.append(e)
print(ls1)
ls1= [] ls2= [1, 2, 3] ls3= [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] ['a', 'b', 'c'] [1, 2, 3] [1, 3, 5] ls4= [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] id(ls3)==id(ls4) False [0, 2, 4, 6, 8]
列表生成(推导)式(List Comprehension)
ls = list(range(10))
strls = [str(e) for e in ls] #将ls中的元素转化为字符串然后放入新生成的列表
print(strls)
evenls = [e for e in ls if e % 2 == 0] #将ls中的所有偶数抽出放到一个新的列表中
print(evenls)
nestedls = [[1,1,1],[2,2,2],[3,3,3]]
ls1 = [e for line in nestedls for e in line ]
print("将nestedls变平",ls1)
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] [0, 2, 4, 6, 8] 将nestedls变平 [1, 1, 1, 2, 2, 2, 3, 3, 3]
2.3.3 yield关键字¶
简述:yield常用于函数体内,用来返回值,有点类似return。但与return不同的是,return将值返回后跳出函数,yield则将值返回但不跳出函数而是挂起等待。当下一次再访问该函数时,则从上一次挂起等待的地方(即上一次执行yield的地方)继续往下执行。
原理:yield关键字将函数变成一个生成器(generator)。当调用带有yield语句的函数时,获得一个生成器,然后往下执行直到碰到yield,然后挂起(suspend)并返回值。下一次再调用该函数时,从挂起的地方继续执行。
def foo():
print("first in") #多次调用也只执行1次
i = 1
while True: #看起来要生成并返回无穷多个数,然而因为使用了yield关键字,只有当调用foo函数的时候,才返回1次值,而不是一下全部返回。
yield i**2 #执行到这句通过yield返回值,然后停下来等待下一次的调用。下一次调用时,再接下去执行,然后再通过yield返回值。
i += 1
print("end.") #这句永远不会被执行,思考一下为什么?
x = 0
for e in foo(): #使用for e in foo()这种方式调用,使得foo()看起来像是一个元素的集合,但实际上不是。而是调用1次,计算并返回1次。
print(e)
x += 1
if x == 5:
break
first in 1 4 9 16 25
def printX(x, n):
print(str(x).center(n, "*" )) #x字符居中对齐,且占n个字符,不足部分用*填充
def addFromBeginToEnd(begin, end): #函数定义
'''累加从begin到end(包括end)之间的所有整数
Args:
begin:累加的第一个值
end: 累加的最后一个值
Returns:
返回从begin到end(包括end)之间的所有整数之和
'''
n = 0
for i in range(begin, end):
n += i
return n
result = addFromBeginToEnd(1,101) #函数调用时直接使用:函数名(入参..) 的形式
for i in range(5):
printX(result, i*5)
5050 *5050 ***5050*** ******5050***** ********5050********
3.1.2 函数的返回值¶
return语句用于跳出函数,也可用来返回值。
def findX(numList, x):
'''
如果找到x则跳出,否则输出
'''
for e in numList:
if x == e:
return
print(e, end = " ")
xList = "12 23 34 end 1 2".split()
findX(xList, "end")
12 23 34
1. Python中函数可以有多个返回值,函数值以元组形式返回
def findMinAndMaxWord(strList):
minW = maxW = strList[0]
for e in strList:
maxW = e if len(e) > len(maxW) else maxW
minW = e if len(e) < len(minW) else minW
return minW, maxW
strList = "This is a test!".split()
result = findMinAndMaxWord(strList)
print(type(strList), result)
mx, mw = findMinAndMaxWord(strList) #自动解包
print(mx, mw)
<class 'list'> ('a', 'test!')
a test!
2. Python中的函数如过无return语句,则返回None
def foo():
print("test")
x = foo()
print(type(x), x)
test <class 'NoneType'> None
3.1.3 Lambda表达式¶
Lambda表达式可用于创建匿名函数。形式如下 :
lambda <参数列表>: <表达式>
参数列表为匿名函数的入参,"return 表达式"为匿名函数的函数体。如下图所示:

使用Lambda表达式创建的是函数对象。可将该函数对象赋值给一个变量,然后通过该变量就可以调用该函数对象。形式如下所示:
func1 = lambda <参数列表>: <表达式> #定义
func1(<参数列表>) #通过func1变量调用该函数对象
通过lambda表达式定义的函数与正常函数一样,是函数定义的简化写法。
func1 = lambda x, y: x +y
print(type(func1), func1(2, 3)) #可以看到lambda表达式是一个function类对象
<class 'function'> 5
lambda表达式小练习:
key = lambda x:x[1]
print(key("abc")) #返回b
key = lambda x:x[1].upper()
print(key("abc")) #返回B
key = lambda a, b: a if a>b else b #返回较大的值
print(key(1,2))
print(key(100,9))
b B 2 100
lambda表达式的应用:
Lambda表达式应用广泛。Python内置函数sorted就可通过接收不同的函数(可以用Lambda表达式),来实现对不同关键字进行排序。
#学生数据以元组形式存储,分别是"编号、姓名、分数"
xList = [(1,"zhang", 65), (3, "Fang", 76),(5, "li", 100), (4, "bo", 56), (2, "chen", 76)]
print(sorted(xList, key = lambda x: x[0])) #按编号排序
print(sorted(xList, key = lambda x: x[1])) #按姓名排序
print(sorted(xList, key = lambda x: x[1].lower())) #忽略大小写按姓名排序
print(sorted(xList, key = lambda x: x[2])) #按成绩排序
print(sorted(xList, key = lambda x: x[2])) #按成绩排序
[(1, 'zhang', 65), (2, 'chen', 76), (3, 'Fang', 76), (4, 'bo', 56), (5, 'li', 100)] [(3, 'Fang', 76), (4, 'bo', 56), (2, 'chen', 76), (5, 'li', 100), (1, 'zhang', 65)] [(4, 'bo', 56), (2, 'chen', 76), (3, 'Fang', 76), (5, 'li', 100), (1, 'zhang', 65)] [(4, 'bo', 56), (1, 'zhang', 65), (3, 'Fang', 76), (2, 'chen', 76), (5, 'li', 100)] [(4, 'bo', 56), (1, 'zhang', 65), (3, 'Fang', 76), (2, 'chen', 76), (5, 'li', 100)]
key参数为函数,可以使用Lambda表达式。排序过程中,两个元素比较前,要对元素调用key所指定的函数。
然后,对函数调用后的结果进行比较。比如(1,"zhang", 65)和(3, "fang", 76)这两个元素进行比较。如果
指定key = lambda x: x[0],那么对这两个元素应用该Lambda表达式分别得到值1和3。也就是对这两个值
进行比较。
def test(x):
print("Before Change id(x) =", id(x)) #形参x的id与实参n的id一样
x = x + 10
print("After Change id(x) =", id(x))
return x
n = 5
print("id(n) =", id(n))
print(test(n))
id(n) = 140724864512384 Before Change id(x) = 140724864512384 After Change id(x) = 140724864512704 15
小思考:
如下代码中changeX函数能改变n的值吗?为什么
def changeX(x):
x = 10
n = 1
changeX(n)
print(n)
1
3.2.2 默认值参数、关键参数、可变量参数¶
默认值参数:函数定义的时候,指定参数的默认值。需放在函数所有形参的最右边。调用时如不指定默认值参数的值,则用默认值。
关键参数:可以按参数名字传递值,实参顺序可以和形参顺序不一致。
可变数量参数:如果为函数定义了可变数量参数。调用函数时,传递的变量个数可变。参数以元组或字典形式传入。
#演示:默认值参数
print("演示:默认值参数")
def foo(x, y = 1):
return x, y
print(foo(2), foo(2, 2), foo(2, y = 3), foo(x = 3, y = 4))
#演示:关键参数
print("演示:关键参数")
def fooK(x, y, z):
return x, y, z
print(fooK(1, 2, 3), fooK(z = 1, x = 3, y =2))
#演示:可变数量参数,参数前1个*
print("演示:可变数量参数,参数前1个*")
def fooV(*x): # *x,代表的是将多个参数以元组的形式传入函数
print(type(x),x)
for e in x:
print(e, end = " ")
print()
fooV()
fooV(1)
fooV(1, 2, 3)
#演示:可变数量参数,参数前2个*
print("演示:可变数量参数,参数前2个*")
def fooVV(**x): # **x,代表的是将多个参数以字典的形式传入函数
print(type(x), x)
for e in x.items():
print(e, end = " ")
print()
fooVV()
fooVV(x = 1, y = 2) #参数必须以 arg1 = value1, arg2 = value2 ...这样的方式给出
演示:默认值参数
(2, 1) (2, 2) (2, 3) (3, 4)
演示:关键参数
(1, 2, 3) (3, 2, 1)
演示:可变数量参数,参数前1个*
<class 'tuple'> ()
<class 'tuple'> (1,)
1
<class 'tuple'> (1, 2, 3)
1 2 3
演示:可变数量参数,参数前2个*
<class 'dict'> {}
<class 'dict'> {'x': 1, 'y': 2}
('x', 1) ('y', 2)
# 演示:局部变量
def test(n):
i = 0 #i为局部变量
for e in range(n):
i += 1
test(5)
print(x) # 报错:name 'x' is not defined
# 演示:全局变量
x = 3
n = 2
def test():
x = 7 #这里给x赋值,使得x成为局部变量。不再是函数外定义的那个x。
global n
n = 5
print("Before test(): x = {}, n = {}".format(x, n))
test()
print("After test(): x = {}, n = {}".format(x, n)) #可以看到x未被改变,而被声明为global的n被改变了
Before test(): x = 3, n = 2 After test(): x = 3, n = 5
函数外创建的变量其作用域包括函数内部。即,函数内可以访问函数外定义的变量,但不能改变该变量的值。
换句话说:函数不能修改函数外创建的变量,但可以修改函数外创建的变量所指向的对象(如list)内部的值。
# 演示:全局变量
def test(n):
print(x) #可以获得函数外的x所指向的值。此处未改变x存储的引用。
print(xList) #可以获得函数心里的xList所指向的列表。此处未改变xList存储的引用。
#x = 5 #会出错。因为 x = 5 代表x是局部变量。那么第4行的print(x)就使得x在第6行赋值前就被引用。所以报错
for e in range(n):
xList.append(e) #此处知识改变了xList指向的那个列表列表内部的值,所以不会出错。
xList = []
print("Before: x = {}, xList = {}".format(x, xList))
test(5)
print("After: x = {}, xList = {}".format(x, xList))
Before: x = 3, xList = [] 3 [] After: x = 3, xList = [0, 1, 2, 3, 4]
3.3 函数对象¶
在Python中函数也是对象。
在代码中只写函数名,而不写后面的括号与参数,就代表要使用的是函数对象。
def foo(x, y):
return x + y
fun1 = foo #这时候fun1与foo是同一个函数对象。相当于为foo函数起了一个别名
print(type(fun1), type(foo))
print(id(fun1) == id(foo))
print(fun1(1, 2), foo(1,2))
for e in dir(foo): #列出函数对象的所有方法
print(e, end = " ")
<class 'function'> <class 'function'> True 3 3 __annotations__ __call__ __class__ __closure__ __code__ __defaults__ __delattr__ __dict__ __dir__ __doc__ __eq__ __format__ __ge__ __get__ __getattribute__ __globals__ __gt__ __hash__ __init__ __init_subclass__ __kwdefaults__ __le__ __lt__ __module__ __name__ __ne__ __new__ __qualname__ __reduce__ __reduce_ex__ __repr__ __setattr__ __sizeof__ __str__ __subclasshook__
函数对象作为函数参数:
函数对象可以作为函数的参数值传递进去(实际上是指向函数的引用传递到函数中去)。类似C语言中的函数指针。
这为Python编程带来极大的灵活性。
下述代码中的applyFxToNumbers适用于所有接收两个入参的函数。从addAB到complex函数均可用于applyFxToNumbers。
def applyFxToNumbers(fx, a, b):
return fx(a, b)
def addAB(a, b):
return a + b
fx = lambda a, b: a * b
print(applyFxToNumbers(addAB, 1, 2))
print(applyFxToNumbers(lambda a,b: a - b, 1, 2))
print(applyFxToNumbers(fx, 1, 2))
print(applyFxToNumbers(complex, 1, 2))
3 -1 2 (1+2j)
3.4 递归函数¶
函数可以被别人调用,也可在函数内部中被自己调用。
递归函数:在函数内部直接调用自己或通过一系列的调用语句间接地调用自己的函数。
递归程序包含两大特征:
- 调用自身。
- 必须有递归出口。保证递归函数不会无限调用下去。
def foo(n):
print(n)
if n == 0: # 2. 递归出口。只有n == 0,就跳出本次调用。
return 0
x = 2 + foo(n-1) # 1.调用自身
print(x)
return x
print("递归函数最终返回值:",foo(3))# 输出什么?why?
3 2 1 0 2 4 6 递归函数最终返回值: 6
使用递归思想解决问题:
一般来说可以使用递归解决的问题,都可以化简为与原问题相似但规模更小的问题。
比如求n!。求解n!这个问题可以化简为如下步骤:
- 求解(n-1)!这个规模更小,但于与问题相似的问题。
- 将n*r。该问题直接可解。
其中第1步又可不断化简,直到n=1的时候,即求解1!这个问题。1!结果为1,问题解决。然后将结果不断返回进行上层进行步骤2。
在这个问题的求解中,我们看到了可以使用递归函数解决该问题。代码如下:
def fac(n): #求解n!
print("求解{}!问题".format(n))
if n == 1:
print("{}! = {}".format(n, 1))
return 1
result = n*fac(n-1)
print("{}! = {}".format(n, result))
return result
print(fac(5))
求解5!问题 求解4!问题 求解3!问题 求解2!问题 求解1!问题 1! = 1 2! = 2 3! = 6 4! = 24 5! = 120 120
小练习:尝试使用递归思想解决如下问题
- 求解斐波那契数列
- 在一个列表中找到最大的数
- 拆分整数
- 结合tutle库使用递归法绘制二叉树
拆分整数: 这个问题考察的是如何将一个自然数拆成若干个小自然数的和,比如:
3 = 3
3 = 2 + 1
3 = 1 + 1 + 1
或者
5 = 5
5 = 4 + 1
5 = 3 + 2
5 = 3 + 1 + 1
5 = 2 + 2 + 1
5 = 2 + 1 + 1 + 1
5 = 1 + 1 + 1 + 1 + 1
很明显这里只考虑不同的小自然数的组合,顺序是无关的,所以5=2+3和5=3+2被认为是一样
的。写个小程序(语言不限),找出来12345这个数有多少种拆分方法
print("{:-^100}".format("id演示"))
x,y = 1,1
print("x与y的地址一样:",id(x),id(y))
ls = [3,1,2]
ls1 = [3,1,2]
ls2 = [4,5,3]
print("两个列表的地址不一样,地址分别为:",id(ls),id(ls1))
print("{:-^100}".format("sorted()与list.sort()演示"))
print("升序排序前ls:",ls)
ls3 = sorted(ls)
print("升序排序后ls:",ls)
print("升序排序后新生成的ls3:",ls3)
print("升序排序后生成了一个新的列表ls3,并未改变原来的列表ls:",id(ls),id(ls3))
ls.sort() #就地排序
print("就地升序排序后,ls中的值:",ls)
print("{:-^100}".format("降序排序演示"))
print("降序排序前ls2:",ls2)
reversels = sorted(ls2, reverse = True) #降序排列
print("降序排序后新生成的reversels:",reversels)
ls2.sort(reverse = True)
print("就地降序排序后ls2:",ls2)
print("{:-^100}".format("逆序演示:reversed()与list.reverse()"))
print("逆序输出前ls:",ls)
ls4 = reversed(ls)
print("逆序输出后ls:", ls)
print("逆序输出后的结果:", end = "")
for e in ls4:
print(e, end = "")
print()
ls.reverse()
print("对ls就地逆序:",ls)
------------------------------------------------id演示------------------------------------------------ x与y的地址一样: 140734523601152 140734523601152 两个列表的地址不一样,地址分别为: 2561276168264 2561276168328 ---------------------------------------sorted()与list.sort()演示--------------------------------------- 升序排序前ls: [3, 1, 2] 升序排序后ls: [3, 1, 2] 升序排序后新生成的ls3: [1, 2, 3] 升序排序后生成了一个新的列表ls3,并未改变原来的列表ls: 2561276168264 2561276168648 就地升序排序后,ls中的值: [1, 2, 3] -----------------------------------------------降序排序演示----------------------------------------------- 降序排序前ls2: [4, 5, 3] 降序排序后新生成的reversels: [5, 4, 3] 就地降序排序后ls2: [5, 4, 3] -----------------------------------逆序演示:reversed()与list.reverse()----------------------------------- 逆序输出前ls: [1, 2, 3] 逆序输出后ls: [1, 2, 3] 逆序输出后的结果:321 对ls就地逆序: [3, 2, 1]
3.5.2 sorted函数可用于所有序列(字符串、列表、元组)数据类型¶
sorted(x):可以对序列x进行排序,并返回新的序列。
sorted函数接收key参数与reversed参数。
key为一个函数,作用于每个元素。用于抽取所要比较的元素。reverse为布尔值,决定是否逆序排序,默认为False
列表本身也有sort方法,对列表本身进行排序(就地排序),不产生新队列。同时,也接收key于reverse参数。
多关键字排序:请见Operator模块。
print("sorted()函数可以应用于所有序列类型(字符串、列表、元组),reversed()也可以应用于所有序列类型")
ls = ["1d","3A","2b","5C"]
print("对列表应用sorted()")
print("排序前ls:",ls)
ls2 = sorted(ls)
print("排序后ls:",ls)
print("排序后ls2:",ls2)
print("id(ls) = ",id(ls), "id(ls2) = ",id(ls2)) #id不一致,说明ls2是新的列表
ls.sort()
print("对ls进行就地排序:",ls)
print("对ls中的元素的第2个元素逆序排序:", sorted(ls, key = lambda x: x[1], reverse = True)) #对ls中的元素的第2个元素逆序排序,并生成新列表
chars = "DabCe"
print("对字符串应用sorted()")
print("排序前:",chars)
chars2 = sorted(chars)
print("排序后:",chars)
print("忽略大小写后进行排序:",sorted(chars, key = str.lower)) #注意:要传递进去的是str.lower函数对象
t1 = (3,2,1,5,4)
print("对元组应用sorted()")
print("排序前t1:",t1)
t2 = sorted(t1)
print("排序后t2:",t2)
print(t2)
sorted()函数可以应用于所有序列类型(字符串、列表、元组),reversed()也可以应用于所有序列类型 对列表应用sorted() 排序前ls: ['1d', '3A', '2b', '5C'] 排序后ls: ['1d', '3A', '2b', '5C'] 排序后ls2: ['1d', '2b', '3A', '5C'] id(ls) = 2727408171272 id(ls2) = 2727446183112 对ls进行就地排序: ['1d', '2b', '3A', '5C'] 对ls中的元素的第2个元素逆序排序: ['1d', '2b', '5C', '3A'] 对字符串应用sorted() 排序前: DabCe 排序后: DabCe 忽略大小写后进行排序: ['a', 'b', 'C', 'D', 'e'] 对元组应用sorted() 排序前t1: (3, 2, 1, 5, 4) 排序后t2: [1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
3.5.3 eval函数¶
eval(strx): 将字符串strx进行表达式来运算。
print("eval演示")
str1,str2 = "6","1+2"
a = 3
str3 = "a+2"
print(eval(str1),eval(str2),eval(str3))
str4 = "'abc'+str1"
print(eval(str4))
xlist = eval("[1, 2, 3]") #用eval生成列表
print(type(xlist), xlist)
dict1 = eval('{"zhang":"张","chen":"陈"}')#用eval生成字典
print(type(dict1), dict1)
eval演示
6 3 5
abc6
<class 'list'> [1, 2, 3]
<class 'dict'> {'zhang': '张', 'chen': '陈'}
strx = "1 2 3 4 5"
strList = strx.split()
xmap = map(int, strList) #将int函数应用于strList中的每个元素
print(type(xmap))
for e in xmap:
print(e,type(e))
<class 'map'> 1 <class 'int'> 2 <class 'int'> 3 <class 'int'> 4 <class 'int'> 5 <class 'int'>
例2. map函数常与list函数配合使用。使用list函数可将map对象转化为列表。
xlist = list(map(int, strList))
print("字符串列表被转化为int列表xlist:", xlist)
print("字符串(字符列表)转化为int列表:",list(map(int, "12345"))) #将字符串序列中每个元素转化为int型
字符串列表被转化为int列表xlist: [1, 2, 3, 4, 5] 字符串(字符列表)转化为int列表: [1, 2, 3, 4, 5]
例3. map函数与lambda函数配合使用
nameList = "zhang wang li chen".split()
print(list(map(lambda x: x.capitalize(), nameList))) #首字母大写
print(list(map(lambda x: x + 5, xlist))) #对序列中每个元素加5
['Zhang', 'Wang', 'Li', 'Chen'] [6, 7, 8, 9, 10]
4.将map函数包含两个及以上的入参
lastNameList = "Zhang Wang Chen Li".split()
firstNameList = "飞 宇 官 逵".split()
#将两个序列中的元素依次拼接
print(list(map(lambda x, y: x+y, lastNameList, firstNameList)))
['Zhang飞', 'Wang宇', 'Chen官', 'Li逵']
3.5.5 zip函数¶
zip,英文中拉链的意思。就像拉链可以将拉链两侧的齿扣严丝合缝的一一扣起来。zip函数可将多个可迭代对象(如序列等)中的元素一一对应绑起来(这些元素以元组形式绑起来),然后以元组迭代器的形式返回。
例1. 将多个列表中的元素zip起来。
a = [1, 2, 3]
b = [4, 5, 6]
zipped = zip(a, b) #这时候得到了一个迭代器zipped,里面包含了来自a,b两个列表中一一对应的元素组成元组迭代器。
print("元组迭代器zipped中的内容(两个列表):")
for e in zipped:
print(e)
c = [7, 8, 9]
zipped1 = zip(a, b, c)
print("元组迭代器zipped1中的内容(三个列表):")
for e in zipped1:
print(e)
元组迭代器zipped中的内容(两个列表): (1, 4) (2, 5) (3, 6) 元组迭代器zipped1中的内容(三个列表): (1, 4, 7) (2, 5, 8) (3, 6, 9)
例2. zip函数常与list函数配合使用。 使用list可将zip对象转化为列表。
ziplist = list(zip(a,b,c))
print(ziplist)
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
例3. zip函与*运算符结合可用来将一个zip迭代对象拆成列表。
a = [1, 2, 3]
b = [4, 5, 6]
zipped = zip(a, b) #(1, 4), (2, 5), (3, 6)
x, y = zip(*zipped) #*把上面由a与b绑起来的zip对象拆开,然后用zip组装成元组x与y
print(type(x), x)
print(type(y), y)
<class 'tuple'> (1, 2, 3) <class 'tuple'> (4, 5, 6)
例4. 使用zip函数快速生成字典。
grade = [90,80,70,60]
level = ['A','B','C','D']
gradeDict = dict(zip(grade,level))
print(gradeDict)
{90: 'A', 80: 'B', 70: 'C', 60: 'D'}
3.5.6 filter函数¶
筛选出某个可迭代对象(如列表等)中符合要求的元素。使用指定函数来判断该元素是否符合要求。
xlist = list(range(100))
def greaterThan90(x):
return x > 90
result = filter(greaterThan90, xlist)
print(type(result), list(result))
result = filter(lambda x: x % 25 == 0, xlist) #返回了一个迭代器
print(list(result))
#输出所有不是aeiou的字符
print(list(filter(lambda x: x not in "aeiou", "abcdefghijklmnop")))
<class 'filter'> [91, 92, 93, 94, 95, 96, 97, 98, 99] [0, 25, 50, 75] ['b', 'c', 'd', 'f', 'g', 'h', 'j', 'k', 'l', 'm', 'n', 'p']
3.5.7 reduce函数¶
reduce函数是functools模块中的一个函数。其形式为reduce(function, iterable[, initializer])。
该函数对可迭代对象(如列表、range对象等)中的元素,从左到右,对其中的元素依次应用有两个入参
的函数(function),从而实现累积运算,最后将值返回。
这个过程就相当于,把迭代对象中多个元素,通过逐步处理,逐渐reduce(缩减)为一个值。
为了说明方便,以下例子使用列表进行说明:
1.如果列表中只有一个元素,且不设置初值(initializer)
使用reduce函数应用于这样的列表,直接返回列表中的元素。见如下代码3-4行。
2.如果列表中只有一个元素,但设置初值
如下代码6-8行,将初值100赋值给x,列表中的第1个值10赋值给y。然后计算x+y。
from functools import reduce
xlist = [1]
print(reduce(lambda x, y: x+y, xlist))
xlist = [10]
n = reduce(lambda x, y: x + y, xlist, 100)
print(type(n), n)
1 <class 'int'> 110
3.如果列表中超过1个元素,不设置初值
如下代码3-4行中。第一趟,将迭代过程的初值x设为第一个元素1,然后从xlist中取出下一个值(2)赋给y。
然后将x+y即3赋值为下一轮运算的x,然后再从列表中取出下一个值3赋值给y,在进行x+y运算。
直到取出5。整个迭代过程类似于6-9行代码。可以看出,通过reduce,可以大幅精简这种迭代过程的代码。
至于列表中超过1个元素,同时设置初值。大家可依次类推。
from functools import reduce
xlist = [1, 2, 3, 4, 5]
print(reduce(lambda x, y: x + y, xlist))
n = 0
for e in xlist:
n += e
print(n)
15 15
上面的例子演示了对列表使用reduce函数。实际上reduce函数适用于所有可迭代对象。如下代码所示:
#使用reduce函数实现求6的阶乘
from functools import reduce
result = reduce(lambda x, y: x * y, range(1, 6)) #计算((((1*2)*3)*4)*5)
print(result)
print(reduce(lambda x, y: int(x)*int(y), "12345" ))
print(reduce(lambda x, y: x + "+" + y, "12345" ))
gradeDict = {">=90":10,"80<=x<90":30, "60<=x<80":22, "0<=x<60":15}
print("班级总人数:"+str(reduce(lambda x, y: x + y, gradeDict.values())))
120 120 1+2+3+4+5 班级总人数:77
map与reduce结合使用:
求凯撒密码:
对每个英文字符(大小写)将其变化为后面第n个字符,且范围超出,则折返。
假设n为3,如果对如字符z变化,则得到c,对字符'A'变化,则得到'D'。对非英文字符保持
不变。
在整个过程中包含两个步骤:
- 求出给定字母的经凯撒转化后的字母。使用getNextChar(x, n)转换。
- 将这些转换后的字母拼接起来。
思路:
- plainText为待加密的明文。使用map函数对其每个字符应用getNextChar函数。
- 使用
reduce(lambda x, y: x + y .....)函数将转换后的每个字符拼接起来
优化:
因为getNextChar需要两个入参,一个是字符,还有一个是n。并且对每个字符都是使用n进行变换。
所以第13行代码中的[n]*len(plainText)生成了一个列表,长度与plainText相同,值为n。比较占用空间。
我们可以定义一个产生length个n的生成器nGenerator(length, n)。比较节省空间。
import random
def getNextChar(x, n):
if x.islower():
return chr((ord(x) - ord('a') + n) % 26 + ord('a'))
elif x.isupper():
return chr((ord(x) - ord('A') + n) % 26 + ord('A'))
else:
return x
plainText = "ThisI12sMyPasswordZ*"
n = 3
print(reduce(lambda x, y: x + y, map(getNextChar, plainText, [n]*len(plainText))))
def nGenerator(length, n):
for i in range(length):
yield n
#使用生成器进行优化
print(reduce(lambda x, y: x + y, map(getNextChar, plainText, nGenerator(len(plainText), n))))
WklvL12vPbSdvvzrugC* WklvL12vPbSdvvzrugC*
3.6 random模块¶
random模块实现了各种分布的伪随机数生成器。更多random库说明请见文档random --- 生成伪随机数
random.random()在[0.0,1.0)范围内生成随机数
import random
for i in range(5):
print(random.random(), end = ' ')
0.8649866132338427 0.5267219480941976 0.19735233180737644 0.6101665714392257 0.22115358552669073
for i in range(5):
print(random.randint(1,10) , end = ' ') #在[a,b]范围内生成随机整数
5 1 3 1 6
alphabet = "abcdefghijklmnopqrstuvwxyz"
for i in range(5):
print(random.choice(alphabet),end = ' ') #随机从字符串序列中抽取出5个元素
print()
alphabetList = [x for x in alphabet]
print("shuffule前:",alphabetList)
random.shuffle(alphabetList) #将序列 x 随机打乱位置。
print("shuffule后:",alphabetList)
print('从alphabetList列表中随机抽样5个元素组成新的列表',random.sample(alphabetList, 5))
k l t v u shuffule前: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] shuffule后: ['e', 'g', 'b', 'j', 'c', 'l', 'i', 'z', 'q', 'r', 'x', 'v', 'm', 'y', 'o', 'h', 'u', 's', 'w', 'd', 'n', 'a', 'f', 't', 'p', 'k'] 从alphabetList列表中随机抽样5个元素组成新的列表 ['r', 'z', 'm', 'l', 'h']
3.7 datetime模块¶
未完成
4. 处理异常(try...except)¶
程序运行时难免会碰到一些无法处理的错误(异常)。比如,要求输入若干数值类型求和,但输入过程中不小心输入了一个非数值类型的字符,如下列代码所示:
def SumAll(n):
x = 0
while(n!=0):
x += int(input())
n -= 1
return x
SumAll(3)
1 2 x
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-13-88273fb46776> in <module> 6 return x 7 ----> 8 SumAll(3) <ipython-input-13-88273fb46776> in SumAll(n) 2 x = 0 3 while(n!=0): ----> 4 x += int(input()) 5 n -= 1 6 return x ValueError: invalid literal for int() with base 10: 'x'
可以看到,程序运行中碰到了ValueError,程序无法处理该错误,于是直接崩溃。
为了让我们编写的SumAll函数更健壮(碰到错误输入,不至于程序崩溃),我们可以使用try语句改进如上程序。当输入引发错误时,重新输入。
def SumAll(n):
x = 0
while(n!=0):
try:
x += int(input()) #1
n -= 1 #2
except: #3
print("输入错误,请重输!")
return x
SumAll(3)
1 x 输入错误,请重输! 5 0
6
从程序的运行结果可以看到,该程序正确处理了输入错误(输入a)的情况。
具体原理为,当语句1发生错误的时产生异常,程序不会正常往下执行,即,未执行语句2,n也就不会-1。
但是会跳到语句3处,随后提示错误信息,然后回到while语句处继续执行,并且因为n未-1,所以n的值永
远无达到0,也就无法跳出循环。
总结: 使用try...except可以提高程序的健壮性,当程序运行产生异常时,程序中断正常运行流程,try..except机制可以让程序跳转到错误处理的地方(except块)来进行出错处理。
关于try...except更多内容请参考文章:异常处理try...except、raise
5. 自定义数据类型(面向对象入门)¶
这里仅给出一个简介,更多面向对象的知识点请参考Python官方文档-类
5.1 类的定义(class关键字)¶
类可以将数据(属性)与功能(方法)综合起来。创建一个类相当于定义一个新的类型。使用这个新的类型可以创建很多该类的实例(对象)。
示例代码定义一个Student类,利用Student类可以创建出很多Student类型的对象,如下面的s1与s2两个对象。
该类中有两个关键点如下:
- __init__方法:Python类中的一种特殊方法,方法名的开始和结束都是双下划线,该方法称为构造函数主要用于初始化对象。当创建类的对象时,它被自动调用
- self关键字:对于一个类的所有方法,包括构造函数,其参数中都有一个self参数,用来代表对象本身。
class Student:
def __init__(self, sid, name, age):#构造函数,用于初始化。一定要有self参数且为第一个参数
self.sid = sid #实例属性sid,每个实例(对象)都独有一个
self.name = name
self.age = age
def printMe(self): #在类中定义的一个方法,self必不可少
print("sid = {},name = {}, age = {}".format(self.sid,self.name,self.age))
def __del__(self): #析构函数。删除一个对象时执行该函数
print("析构函数执行。这里应该执行一些清理工作。")
s1 = Student(1,"Jordan",18) #创建了一个Student实例(对象)
print(s1.name,s1.age) #使用"对象.属性名"访问属性
s1.printMe() #使用"对象.方法名"执行方法
s2 = Student(2,"Rose",18)
del s2
析构函数执行。这里应该执行一些清理工作。 Jordan 18 sid = 1,name = Jordan, age = 18 析构函数执行。这里应该执行一些清理工作。
5.2 继承与多态¶
子类(派生类)可以继承自父类(基类)。可以复用父类的属性与方法。
不同于Java,Python允许多重继承。详见官方文档。
class Shape:
PI = 3.141593 #类属性(类变量),属于该类所有对象。通过"类名.属性名"访问
def __init__(self, name): #相当于Java中的构造函数,用于初始化对象
self.name = name
def printMe(self): #将在子类中被复用
print("name=",self.name," area=", self.getArea())
def __str__(self): #类似java的toString方法。返回对象的字符串表示
return "name = "+self.name+" area= "+str(self.getArea())
def getArea(self):
raise AttributeError('子类必须实现这个方法') #抛出异常
class Circle(Shape):
def __init__(self, name, r):
super().__init__(name) #复用父类的__init__函数
self.r = r #对象属性
def getArea(self): #覆盖父类的getArea方法,体现了自己的特点,多态的一种表现
return Shape.PI*self.r*self.r #使用Shape的类属性PI
class Rect(Shape):
def __init__(self, name, width, length):
super().__init__(name)
self.width = width #对象属性
self.length = length
def getArea(self): #覆盖父类的getArea方法
return self.width*self.length
def sumShapesArea(shapes): #体现了多态,虽然都是执行了getArea方法,但是根据不同的实现类调用不同的代码
area = 0
for e in shapes:
area += e.getArea() #这行代码适用于任何拥有getArea()方法的类
return area
shapes = []
shapes.append(Circle('圆形',10))
shapes.append(Rect('方形',3,5))
print("sumShapesArea方法体现了多态:")
print(sumShapesArea(shapes))
print("复用了Shape中printMe方法:")
for e in shapes:
e.printMe()
print("调用Shape类型对象的__str__方法:")
for e in shapes:
print(e) #print时,会调用对象e的__str__方法
print(isinstance(shapes[0], Shape)) #使用isinstance判断一个对象是否是某个类型shapes[0]是Circle,同时继承自Shape,所以为True
print(isinstance(shapes[1], Circle))#shapes[1] 是Rect,不是Circle,所以返回False
print(issubclass(Rect, Shape)) #使用issubclass判断一个类是否是某个类型的子类
sumShapesArea方法体现了多态: 329.1593 复用了Shape中printMe方法: name= 圆形 area= 314.1593 name= 方形 area= 15 调用Shape类型对象的__str__方法: name = 圆形 area= 314.1593 name = 方形 area= 15 True False True
常用函数:
isinstance(obj, type): 用来判断obj是否为type类型对象或其type的子类型对象。
issubclass(type1, type2): 用来判断type1是否为type2类型或type2的子类型。
class Person:
def __init__(self, name):
self.name = name
def __str__(self):
return self.name;
class Student(Person):
def __init__(self, name, stuNo):
self.name = name
self.stuNo = stuNo
def __str__(self):
return super().__str__() + " " + str(self.stuNo)
class Employee(Person):
def __init__(self, name, salary):
self.name = name
self.salary = salary
def __str__(self):
return super().__str__() + " " + str(self.salary)
p = Person("张")
s1 = Student("张", 1)
e1 = Employee("王", 7000.34)
print(isinstance(p, Person), isinstance(p, Student), isinstance(s1, Person))
print(p, s1, e1, sep = "\n")
print(issubclass(Employee, Person), issubclass(Student, Person), issubclass(Person, Person))
print(issubclass(Employee, Student), issubclass(Person, Student))
True False True 张 张 1 王 7000.34 True True True False False
5.3 私有属性与私有方法¶
class Foo:
def __init__(self, name):
self.__name = name #双下划线__开头的属性为私有属性。无法被在类外部被直接访问,所以产生异常。
def __printMe(self): #双下划线__开头的方法私有方法,类外部无法调用。但类内部可以调用。
print("我的类型为Foo")
def getName(self):
return self.__name
def printMe(self):
self.__printMe()
x = Foo("图灵")
print(x.getName())
print(x._Foo__name) #可以使用_类名__属性名的方式强行访问对象的私有属性,但不要这么做
x.printMe()
#以下两句均无法执行
print(x.__name)
print(x.__printMe()) #这句也无法执行
图灵 图灵 我的类型为Foo
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-11-87060554d54a> in <module> 15 16 #以下两句均无法执行 ---> 17 print(x.__name) 18 print(x.__printMe()) #这句也无法执行 AttributeError: 'Foo' object has no attribute '__name'
5.4 动态设置属性¶
Python是动态语言,所以可以动态地为对象定义其原本不存在的属性。
可以将其当作c语言中的结构体使用。只让类与数据绑定而不与行为绑定。
除非你确实知道要这么用,否则不要用。
class Stu: #创建了一个空类
pass
x = Stu()
x.name = "zhang"
print(x.name)
class Person:
pass
# 当结构体使用
stuList = [(1,"张",18),(2,"王",19),(3,"赵",18),(4,"李",20)]
persons = []
for e in stuList:
x = Person()
x.id, x.name, x.age = e
persons.append(x)
for p in persons:
print("id = {}, name = {}, age = {}".format(p.id, p.name, p.age))
zhang id = 1, name = 张, age = 18 id = 2, name = 王, age = 19 id = 3, name = 赵, age = 18 id = 4, name = 李, age = 20
5.5 对象的__hash__()方法与__eq__()方法¶
前面学习的集合(set),可以实现对相同元素的去重。
set如何判定两个加入的元素是否相同?
set首先使用对象的__hash__()函数算出其哈希值。如果两个元素的哈希值相同,则使用了__eq__()函数来判断这两个元素是否相等。
__hash__()方法为计算对象的哈希值__eq__()方法用来判断两个对象是否相同。eq为equal的缩写。
line = "aba"
xset = set(line)
print(xset)
x, y = line[0], line[2]
print(x.__eq__(y))
print(x.__hash__() == y.__hash__())
{'b', 'a'}
True
True
set也可以放入自定义类的对象。set也是通过上述两个方法来判断两个自定义类的对象是否相同。
从以下代码可以看到两个对象s1、s2的属性虽然都一样,但是他们不是同一个对象。所以两个对象都放入了stuSet。
class Student:
def __init__(self, name, age, major):
self.name = name
self.age = age
self.major = major
s1, s2 = Student("zhang", 18, "数学"), ("zhang", 18, "数学")
print(hash(s1.__hash__()), hash(s2.__hash__()))
print(s1.__eq__(s2)) ##Student未实现__eq__方法
stuSet = set([s1, s2])
print(len(stuSet), stuSet)
119495857230 -1649071504362339002
NotImplemented
2 {('zhang', 18, '数学'), <__main__.Student object at 0x000001BD282144E0>}
如果我们希望两个Student对象只要name与age相同,就算作相同对象,要怎么实现呢?
我们可以为自己的类覆盖__hash__()与__eq__()来实现上述功能。
class Student:
def __init__(self, name, age, major):
self.name = name
self.age = age
self.major = major
def __str__(self):
#return self.name + " " + str(self.age) + " " + self.major
return "id={}, name={}, age={}, major={}".format(id(self), self.name, self.age, self.major)
def __hash__(self):
return hash((self.name, self.age)) #Python官方文档推荐将要hash的属性作为一个元组进行hash
def __eq__(self, other):
if other == None:
return False
if id(self) == id(other):
return True
if self.name == other.name and self.age == other.age:
return True;
return False
s1 = Student("zhang", 18, "数学")
s2 = Student("zhang", 18, "计算机")
s3 = Student("王", 17, "计算机")
s4 = Student("王", 18, "计算机")
s5 = s2
s6 = None
s7 = Student("zhang", 18, "物理")
stuList = [s1, s2, s3, s4, s5, s6, s7, None]
print("len(stuList)=",len(stuList))
stuSet = set(stuList)
print("len(stuSet)=",len(stuSet))
for e in stuSet:
print(e)
len(stuList)= 8 len(stuSet)= 4 id=1911934786136, name=王, age=17, major=计算机 id=1911934786360, name=王, age=18, major=计算机 None id=1911934785408, name=zhang, age=18, major=数学
从以上代码可以看出,集合将s1、s2、s5、s7当作同一个元素。所以只存1份。
s3、s4虽然name与major相同,但是age不同,所以不是同一个元素,所以存两份。
一个集合中最多只能存放一个None。
覆盖__hash__()与__eq__()的原则:
一般来说如果需覆盖自定义类的__hash__()与__eq__()方法,那么这两个方法都要覆盖、且结果要一致。
即,如果对A、B两个对象A.__eq__(B)为True,那么这A、B的__hash__()方法返回的哈希值也要一样。
因为__eq__()方法在语义上是用来判定两个对象是否相等。A.__eq__(B)为True,那么A与B从语义上来
说是相等的对象。但是如果其哈希值不一样的话,A、B这两个被认定为相等的对象将都会被放入集合(set)中。
这在语义上来说是不对的。
6. 使用第三方库完成复杂程序¶
6.1 使用Numpy库画图正弦曲线¶
依赖库:
numpy,matplotlib
步骤:
pip install numpy
pip install matplotlib
注意: 使用pip安装numpy时,可能会碰到需要C编译器,一个简单的解决方法,就是安装一个Visual Studio 2015,或者直接安装Anaconda集成安装包。
参考资料:
使用Numpy处理数据: http://old.sebug.net/paper/books/scipydoc/numpy_intro.html#
用Python做科学计算: http://old.sebug.net/paper/books/scipydoc/index.html#
Numpy官方文档: http://www.numpy.org/
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x=np.arange(0, 2*np.pi, 0.1) #生成一个从0到2*PI之间以0.1作为间隔的序列
print(x)
y=np.sin(x)
plt.plot(x,y)
plt.show()
[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2]

6.2 二维码¶
简介:Python 二维码生成器 GitHub - sylnsfar/qrcode: artistic QR Code in Python (Animated GIF qr code) 可生成普通二维码、带图片的艺术二维码(黑白与彩色)、动态二维码(黑白与彩色)。

安装: pip install myqr
依赖库:pillow, numpy, imageio
说明: 安装myqr的时候可能会自动安装相关的依赖库,如果没有自动安装,请自行安装,如pip install pillow
拓展: 生成自己的名片二维码。
参考资料: 二维码名片的格式 - vcard http://blog.csdn.net/johnsuna/article/details/8482454
from MyQR import myqr
words = 'http://cec.jmu.edu.cn'
pic='jmu.png'
saveName = 'jmuQRCode.png'
saveDir = '.'
version, level, qr_name = myqr.run(
words,
version=1,
level='H',
picture=pic,
colorized=True,
contrast=1.0,
brightness=1.0,
save_name=saveName,
save_dir=saveDir
)
jmu.png如下图:
 生成的二维码jmuQRCode.png如下图,可以扫一扫:
生成的二维码jmuQRCode.png如下图,可以扫一扫:

from turtle import *
fillcolor("red")
begin_fill()
while True:
forward(200)
right(144)
if abs(pos()) < 1:
break
end_fill()
效果如下图:
 **参考资料:**
**参考资料:**
官方文档 https://docs.python.org/2/library/turtle.html
海龟绘图中文教程参考资料 http://www.jb51.net/article/52659.htm
6.4 验证码识别¶
安装:
- 需安装Pillow与pytesseract库
- 安装软件tesseract-ocr,下载地址https://sourceforge.net/projects/tesseract-ocr-alt/files/ 选择里面的tesseract-ocr-setup-3.02.02.exe
注:Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本。
库安装步骤:
pip install pillow
pip install pytesseract
例子:
现在需要识别如下验证码
import pytesseract
from PIL import Image
image = Image.open('vcode3.png')#可将此处替换为vcode2.png实验
vcode = pytesseract.image_to_string(image)
print('图片中的字符是:',vcode)
图片中的字符是: 3948
参考资料:
使用Python识别验证码 http://www.tuicool.com/articles/E3MNziM
利用Tesseract来识别验证码 http://blog.csdn.net/zhangxb35/article/details/49592071
说明:识别能力还较弱。如下图,就无法识别。
 如需增强识别能力,还需学习线性代数、图像、模式识别等知识。
如需增强识别能力,还需学习线性代数、图像、模式识别等知识。
7. 附录:¶
7.1 Python的下载与安装¶
官网: https://www.python.org/ Python官网。尽量在官网下载文件。
版本说明: 2.7.x 或 3.5.x。注意:如果操作系统是xp,请安装3.4.x版本。操作系统是32位请安装32位,是64位请安装64位安装文件。
安装过程中:要选择"Add python.exe to Path"
控制台启动python:在CMD命令行提示符下输入python,将显示Python控制台。控制台上将显示所安装的Python版本号。
IDLE(Python GUI):在开始菜单中Python项目下点击IDLE,可启动Python图形界面,如下图所示。可在其中编写简单的Python文件。常用快捷键:Alt+P,查看上一条命令。Alt+/,自动补全曾经出现过的单词。
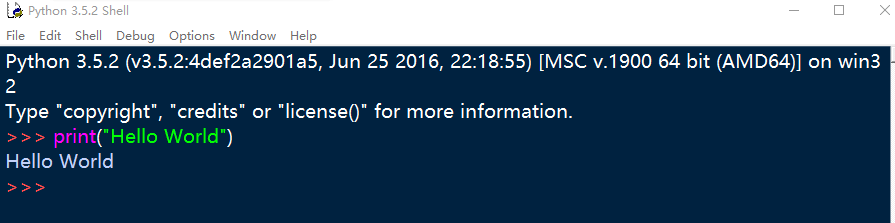
7.2 使用pip管理Python扩展库¶
三种常见的pip命令:
pip install SomePackage #安装SomePackage模块,如pip install numpy
pip install -upgrade SomePackage #升级SomePackage模块
pip uninstall SomePackage #卸载SomePackage模块
注1:在CMD命令行提示符下输入上述命令,如 C:\temp>pip install numpy
注2:pip安装慢时,可指定国内源,如下命令指定使用豆瓣的源
pip install numpy -i https://pypi.douban.com/simple
注3:如果提示“拒绝访问”或者碰到其他的安装错误时,尝试以管理员身份运行命令提示符,然后安装。
注4: Python3下也可使用pip3或者pip3.5命令代替pip命令,Python3下执行pip相当于执行pip3。均在Python安装目录下的Scripts目录中可以找到相应的文件。
7.3 Python常见参考资料¶
7.4 IPython与Jupyter项目¶
IPython:
一个功能强大的Python命令行交互程序。可以尝试一下。一般来说安装了Jupyter,就会安装IPython。
Jupyter:
Jupyter项目包含经典的Jupyter Notebook与更新的Jupyter Lab,他们的内核基于IPython。
这两个项目提供一个基于Web的交互开发环境,还支持Markdown语法。因此,不仅可用其运行Python
代码,还可以使用其做笔记,笔记内部可以内嵌代码及代码运行结果。通过结合使用GitHub与
Jupyter Notebook Viewer还可分享自己的Juyter笔记。
相关参考资料:
7.6 Anaconda集成安装包¶
一个Python的发行版本。集成了如numpy等科学计算、IPython、Jupyter Notebook、Spyder(一个小型的Python IDE)常用第三方模块的集成安装包。无需考虑各种依赖,使用方便。推荐科学计算的研究人员直接使用。
注意:安装了Anaconda也会自动安装IPython与Jupyter。
7.7 本笔记相关链接¶
- 笔记项目的github地址:https://github.com/zhrb/NoteBook
- 笔记内容留言反馈地址:http://www.cnblogs.com/zhrb/p/6223192.html
- 本笔记的NBViewer地址:https://nbviewer.jupyter.org/github/zhrb/NoteBook/blob/master/LearnPython3In90Min.ipynb