Iteration is a huge deal in programming and especially in Python, where it is one of the biggest differences between Python 3 and Python 2, and between Python 3 and some other languages, like MATLAB.
This is a challenging session, but we will start it off with a relatively simple subject and slowly increase the difficulty level.
Some definitions before we begin:
- iterable - an object that you can iterate over, for example with a
forloop. - container - an object that contains other objects, you can use
inon it. - element, item - an object that is contained by a container or produced by iterating on an iterable.
- sequence - an ordered container.
- iterator - an object that provides an iteration over an iterable; one iterable can have several, independent, non-identical iterators.
Not that not every container is iterable (i.e. Bloom filter) and not every iterable is a container (for example, an iterable that provides random numbers). So we can call the union of iterables and containers a collection.
Comprehensions¶
Comprehensions are a compact way to process all or part of the elements in an iterable and return a new container.
List comprehensions¶
Say we have a bunch of measurements in a list called data and we want to calculate the mean and the standard deviation.
"The usual way to do this is with for loops:
data = [1, 7, 3, 6, 9, 2, 7, 8]
mean = sum(data) / len(data)
print('Mean:', mean)
deviations = []
for x in data:
deviations.append((x - mean)**2)
var = sum(deviations) / len(deviations)
stdev = var**0.5
print("Standard deviation:", stdev)
Mean: 5.375 Standard deviation: 2.7810744326608736
We can replace the for loop with a list comprehension:
deviations = [(x - mean)**2 for x in data]
var = sum(deviations) / len(deviations)
stdev = var**0.5
print("Standard deviation:", stdev)
Standard deviation: 2.7810744326608736
We can add a condition, too. Say you want to calculate the deviations of above-average data:
pos_devs = [(x - mean)**2 for x in data if x > mean]
pos_devs
[2.640625, 0.390625, 13.140625, 2.640625, 6.890625]
Exercise¶
Remember that a leap is is a year that is divisible by 400 or divisible by 4 but not by 100.
Write a listcomp to build a list of all leap years until today. Print the length of the list.
Cartesian product¶
We can insert several for statements in a single listcomp, producing all elements of a cartesian product.
For example, consider how we construct a full pack of cards:
suits = ['heart', 'spade', 'club', 'diamond']
numbers = list(range(2,11))
royals = ['J', 'Q', 'K', 'A']
cards = [(s, n) for s in suits for n in numbers + royals]
print(len(cards))
52
Dictionary comprehensions¶
We can also use comprehensions to create dictionaries:
data_devs = {x: (x - mean)**2 for x in data}
data_devs
{1: 19.140625,
2: 11.390625,
3: 5.640625,
6: 0.390625,
7: 2.640625,
8: 6.890625,
9: 13.140625}
Set comprehensions¶
with open('../data/gulliver.txt') as f:
txt = f.read().lower()
unique_words = {w for w in txt.split() if w.isalpha()}
print(len(unique_words))
print('love' in unique_words)
print('war' in unique_words)
4766 True True
If the file is very big we could do it line by line and update the set (it's mutable):
unique_words = set()
with open('../data/gulliver.txt') as f:
for line in f:
line_unique_words = {w for w in line.lower().split() if w.isalpha()}
unique_words.update(line_unique_words)
print(len(unique_words))
print('love' in unique_words)
print('war' in unique_words)
4766 True True
Iterators¶
From Python docs:
Python supports a concept of iteration over containers. This is implemented using two distinct methods; these are used to allow user-defined classes to support iteration. Sequences always support the iteration methods.
__next__: An iterator method, returns the next item from the iteration when the iterator is called withnext(...). If there are no more items this method should raiseStopIteration.__iter__: An iterable method, returns an iterator. If implemented in an iterator, it should return the iterator itself.
Note that an iterable object cannot be its own iterator, because then two concurrent iterations will not be independent.
The easiest way to implement iterators is using generators rather than defining new iterator objects, so that's our next topic.
Generator expressions¶
Generator expressions look similar to list comprehensions but really they return an iterator rather than a new collection.
For example, if we are not interested in the deviations but only in their sum, we don't have to build the actual list, like the comprehension does, but rather we can use a generator, which produces each value as we need it, using lazy evaluation.
Note the use of () instead of []:
deviations = ((x - mean)**2 for x in data)
var = sum(deviations) / len(data)
print("Standard deviation:", var**0.5)
Standard deviation: 2.7810744326608736
type(deviations)
generator
When going over many elements, usually we don't need the list in the memory, just one number at a time. This is where generators shine.
For example, the range function actually returns a generator, which can be converted into a list:
range(10)
range(0, 10)
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
If we were to go over all the numbers from 0 to $10^8$, creating that list before the iteration is costly in space. A generator doesn't create the entire list in memory, but rather lazily creates each elements as it is needed.
We load ipython_memory_usage, a package that monitors memory usage inside the notebook.
Install from with pip install git+https://github.com/ianozsvald/ipython_memory_usage.git, and on Windows (and also recommended on macOS) you will also need to conda install psutil.
import ipython_memory_usage.ipython_memory_usage as imu
imu.start_watching_memory()
In [1] used 0.0234 MiB RAM in 0.10s, peaked 0.00 MiB above current, total RAM usage 39.67 MiB
lst = list(range(10**8))
In [2] used 3863.6953 MiB RAM in 3.37s, peaked 0.00 MiB above current, total RAM usage 3903.37 MiB
rng = range(10**8)
In [3] used 0.0312 MiB RAM in 0.10s, peaked 0.00 MiB above current, total RAM usage 3903.40 MiB
del lst
imu.stop_watching_memory()
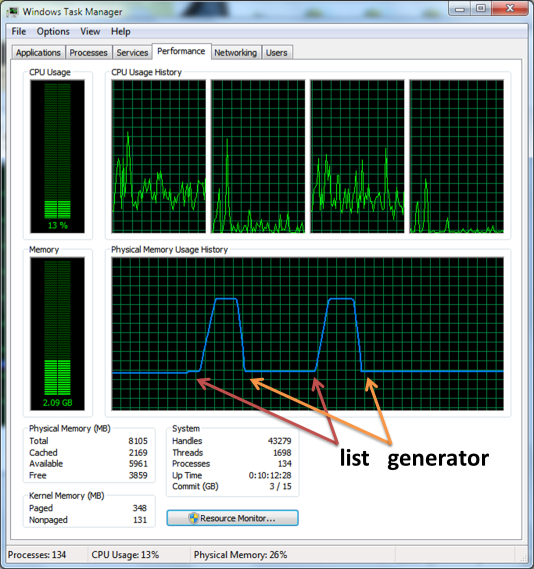
Another example:
%timeit -n 3 [x for x in range(1, 10**6) if x % 2 == 0]
3 loops, best of 3: 68.6 ms per loop
%timeit -n 3 (x for x in range(1, 10**6) if x % 2 == 0)
3 loops, best of 3: 802 ns per loop
%timeit -n 3 list(x for x in range(1, 10**6) if x % 2 == 0)
3 loops, best of 3: 86 ms per loop
Exercise¶
Given in the code below is a dictionary (named code) where the keys represent encrypted characters and the values are the corresponding decrypted characters. Use the dictionary to decrypt an ecnrypted message (named secret) and print out the resulting cleartext message.
- Use a generator expression to decrypt the secret message using the code dictionary.
- Make sure you aren't creating any lists in intermediate steps.
- Experiment with newlines inside
( )to improve readability.
secret = """Mq osakk le eh ue usq qhp, mq osakk xzlsu zh Xcahgq,
mq osakk xzlsu eh usq oqao ahp egqaho,
mq osakk xzlsu mzus lcemzhl gehxzpqhgq ahp lcemzhl oucqhlus zh usq azc, mq osakk pqxqhp ebc Zokahp, msauqjqc usq geou dat rq,
mq osakk xzlsu eh usq rqagsqo,
mq osakk xzlsu eh usq kahpzhl lcebhpo,
mq osakk xzlsu zh usq xzqkpo ahp zh usq oucqquo,
mq osakk xzlsu zh usq szkko;
mq osakk hqjqc obccqhpqc, ahp qjqh zx, mszgs Z pe heu xec a dedqhu rqkzqjq, uszo Zokahp ec a kaclq iacu ex zu mqcq obrfblauqp ahp ouacjzhl, usqh ebc Qdizcq rqtehp usq oqao, acdqp ahp lbacpqp rt usq Rczuzos Xkqqu, mebkp gacct eh usq oucbllkq, bhuzk, zh Lep’o leep uzdq, usq Hqm Meckp, mzus akk zuo iemqc ahp dzlsu, ouqio xecus ue usq cqogbq ahp usq kzrqcauzeh ex usq ekp."""
code = {'w': 'x', 'L': 'G', 'c': 'r', 'x': 'f', 'G': 'C', 'E': 'O', 'h': 'n', 'O': 'S', 'y': 'q', 'R': 'B', 'd': 'm', 'f': 'j', 'i': 'p', 'o': 's', 'g': 'c', 'a': 'a', 'u': 't', 'k': 'l', 'q': 'e', 'r': 'b', 'V': 'Z', 'X': 'F', 'N': 'K', 'B': 'U', 'T': 'Y', 'M': 'W', 'U': 'T', 'm': 'w', 'C': 'R', 'J': 'V', 't': 'y', 'S': 'H', 'v': 'z', 'e': 'o', 'D': 'M', 'p': 'd', 'K': 'L', 'A': 'A', 'P': 'D', 'l': 'g', 's': 'h', 'W': 'X', 'H': 'N', 'j': 'v', 'z': 'i', 'I': 'P', 'b': 'u', 'Z': 'I', 'F': 'J', 'Y': 'Q', 'Q': 'E', 'n': 'k'}
Can I iterate on it?¶
A generator expression creates a new generator object which implements the iterator protocol, and will be an instance of collections.Iterator.
However, the best way to check if something is iterable is to try to get an iterator from it and catch the TypeError if it can't be iterated:
iter(range(10))
iter(x**2 for x in range(10))
iter(5)
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-1-3f322dc008f2> in <module>() 3 iter(x**2 for x in range(10)) 4 ----> 5 iter(5) TypeError: 'int' object is not iterable
But we can also check if something is an instance of collections.Iterable (this is a peak before you leap approach):
from collections import Iterable
print(isinstance(range(10), Iterable))
print(isinstance((x**2 for x in range(10)), Iterable))
print(isinstance(5, Iterable))
True True False
Generator functions¶
We can write more complex generators using functions in which the yield statement replaces the return statement. These are generator functions, which are special because:
- When calling these functions, we don't get a return value but rather a generator object which implements the iterator protocol,
- Generator functions can be thought of as function that yield a value, suspend, and can then be resumed when further values or further action is required.
Generator functions can provide very flexible iterations, including potentially infinite ones, and can be used for other stuff like creating context managers.
Infinite iteration¶
Say we want to go over all the natural numbers to find a number that matches some condition.
We write a generator for the natural numbers, which is kind of a non-limit range (note that this can be done using itertools.count from the standard library):
def natural_numbers():
n = 0
while True:
n += 1
yield n
gen = natural_numbers()
print(gen)
<generator object natural_numbers at 0x205984db0>
from collections import Iterator
hasattr(gen, '__iter__'), hasattr(gen, '__next__'), isinstance(gen, Iterator)
(True, True, True)
We can consume values from the generator one by one using the next function:
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
1 2 3 4
or by giving it to a for loop (note that the above can be done using itertools.takewhile)
for n in natural_numbers():
if n % 667 == 0 and n**2 % 766 == 0:
break
print(n)
510922
Of course, this can only be done using a generator - we cannot create a list of all natural numbers...
Note that our natural_numbers generator could have been created using the itertools.count function that is sort of a more flexible version of range.
Let's do another small example to understand how a generator works:
def example_generator():
print("Start.")
for x in range(3):
print("Next.")
yield x
print("Done.")
for x in example_generator():
print(x)
Start. Next. 0 Next. 1 Next. 2 Done.
Example¶
Let's use generators to solve Project Euler's Problem 10:
The sum of the primes below 10 is 2 + 3 + 5 + 7 = 17.
Find the sum of all the primes below two million.
Of course, it's not reasonable to make a list of all primes bellow two million, as it will require too much space. So we will use generators.
First, we need a primality test function.
def is_prime(n):
return not (n < 2 or any(n % x == 0 for x in range(2, int(n ** 0.5) + 1)))
We now define a generator of numbers below a certain number (this can be done by combining range and filter):
def primes(top=10):
for n in range(2, top):
if is_prime(n):
yield n
list(primes(30))
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
and we sum all primes bellow 2000000 (this will take a couple of minutes):
sum(primes(2000000))
142913828922
Exercise¶
Create a generator that returns numbers from the Fibonacci series, defined by:
$$ a_0 = 0 \\ a_1 = 1 \\ a_n = a_{n-2} + a_{n-1} $$
Generators as context manager¶
A "real" context manager provides does two things: sets something up when you enter the context, maybe providing some return value; and tears something down when you exit the context. The most common case is:
with open(filename) as f:
# do something with file f
in which open creates a file-like object that implements the context manager interface: on entering the context it opens the file and returns itself (the file-like object); when exiting the context it closes the file.
A generator is great for that because use the yield statement to return a value and suspend the generator, thus the code until the yield implements "entering" the context; the code after the yield implements "exiting" the context, and Python can call next once when entering and again when exiting.
Let's do an example - we'll write a tictoc context manager that measures and prints how much time we were inside the context (similar to MATLAB's tic; toc; idiom).
import time
import contextlib
@contextlib.contextmanager
def tictoc():
tic = time.time()
yield
toc = time.time()
print("Elapsed time: {} seconds".format(toc - tic))
with tictoc():
list(primes(1000))
Elapsed time: 0.0022890567779541016 seconds
Note that to tell Python that tictoc should be used as a context manager we need to apply the contextmanager decorator; this is not magic, it just does:
def tictoc():
tic = time.time()
yield
toc = time.time()
print("Elapsed time: {} seconds".format(toc - tic))
tictoc = contextlib.contextmanager(tictoc)
with tictoc():
list(primes(1000))
Elapsed time: 0.002093076705932617 seconds
which wraps tictoc with some neccesary boilerplate to convert it from a generator function to a context manager factory.
Pass values into generators¶
We said that generators are functions that can yield a value, suspend, and then be resumed by calling next - which can be done outside of an iteration context (for loop). Calling next on a generator object will give the next result of the generator (run generator to next yield statement):
double_digit_primes = primes(100)
next(double_digit_primes), next(double_digit_primes), next(double_digit_primes), next(double_digit_primes)
(2, 3, 5, 7)
If we can resume the generator, why not resume it with some value?
send allows us to pass values into generators. For example, say we want to iterator over the natural numbers but make from one value to the next, and these jumps are not constant (can't be arguments to the generator function):
def jumping_natural_numbers():
n = 0
while True:
jump = yield n
if jump is None:
jump = 1
n += jump
gen = jumping_natural_numbers()
gen.send(None), gen.send(3), gen.send(1)
(0, 3, 4)
Example¶
A more whole example is given by the following generator that calculates a running average of a stream of numbers fed to it. It does so by keeping just three numbers - the sum, the count (number of numbers), and the average.
Each time a new number is sent, it yields the updated average and then waits for another number to be sent.
This is much more effcient it terms of space then actually keeping all the numbers; also, it's great for cases in which we actually have a stream of numbers.
def running_average():
summ = 0
count = 0
avg = 0
while True:
n = yield avg
count += 1
summ += n
avg = summ / count
import time
import random
avg = running_average()
avg.send(None) # initialize the generator by sending None or by next(avg)
# mimick a stream of random integers between 0 and 9, inclusive
random_stream = (random.randint(0, 9) for _ in range(10))
for n in random_stream:
current_avg = avg.send(n)
print('{:d}: {:.4f}'.format(n, current_avg))
9: 9.0000 2: 5.5000 1: 4.0000 9: 5.2500 9: 6.0000 1: 5.1667 7: 5.4286 2: 5.0000 0: 4.4444 2: 4.2000
See more at Jeff Knupp's blog.
Exercise¶
Write a generator have_seen that accepts a string via send and yields a boolean in response.
The function will yield True if the input string was already seen by the function, and False otherwise. The function should be case insensitive.
Use it to find all the words appear more than once in the following text (the first paragraph from Gulliver's Travels).
This exercise follows Readable Python coroutines by Thomas Kluyver. See solution in have_seen.py.
def have_seen():
pass
text = """My father had a small estate in Nottinghamshire; I was the third of five
sons. He sent me to Emmanuel College in Cambridge at fourteen years old,
where I resided three years, and applied myself close to my studies;
but the charge of maintaining me, although I had a very scanty
allowance, being too great for a narrow fortune, I was bound apprentice
to Mr. James Bates, an eminent surgeon in London, with whom I continued
four years; and my father now and then sending me small sums of money, I
laid them out in learning navigation, and other parts of the mathematics
useful to those who intend to travel, as I always believed it would be,
some time or other, my fortune to do. When I left Mr. Bates, I went down
to my father, where, by the assistance of him, and my uncle John and
some other relations, I got forty pounds, and a promise of thirty
pounds a year, to maintain me at Leyden. There I studied physic two
years and seven months, knowing it would be useful in long voyages."""
text = text.lower().split()
poets = [
'Shel Silverstein',
'Pablo Neruda',
'Maya Angelou',
'Edgar Allan Poe',
'Robert Frost',
'Emily Dickinson',
'Walt Whitman'
]
first_names = (name.partition(' ')[0] for name in poets)
first_names
<generator object <genexpr> at 0x10e337938>
for n in first_names:
print(n)
Shel Pablo Maya Edgar Robert Emily Walt
Note that in general partition is better for this use than split because it only looks for one sep and returns 3 items, whereas split will look for all seperators, so for a name like Jeff van Gundy it will take slightly more time ot run.
name = 'Jeff van Gundy'
%timeit name.split()[0]
%timeit name.partition(' ')[0]
The slowest run took 9.00 times longer than the fastest. This could mean that an intermediate result is being cached. 1000000 loops, best of 3: 267 ns per loop The slowest run took 9.08 times longer than the fastest. This could mean that an intermediate result is being cached. 10000000 loops, best of 3: 191 ns per loop
You could say that a generator expression does more or else the same thing as a map. And that's true. However, sometimes a map is more suitable in terms of readability. Also, another advantage of a map is that it operates a function that has it's own scope, whereas a generator expression lives in the parent scope.
Filter¶
A filter iterates over the elements in an iterable that pass a certain test ore predicate.
def is_even(n):
return n % 2 == 0
evens = (n for n in natural_numbers() if is_even(n))
for n in evens:
print(n, end=", ")
if n >= 20:
break
2, 4, 6, 8, 10, 12, 14, 16, 18, 20,
Reduce¶
reduce applies a function of two arguments ($f:R^2 \to R$) cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.
reduce is part of the functools module
from functools import reduce
import operator
The easiest example is a replacement for sum:
reduce(operator.add, range(10))
45
What about coding a product equivalent of sum?
reduce(operator.mul, range(1, 10))
362880
Another example: find intersection of several lists.
lists = [[1, 2, 3, 4, 5], [2, 3, 4, 5, 6], [3, 4, 5, 6, 7]]
reduce(set.intersection, (set(x) for x in lists))
{3, 4, 5}
Bonus example¶
Calculating the Fibonacci series up to the n-th element can also be done with reduce. Here we can set the initial seed to be different from the first element of the sequence, and we ignore the values from the input sequence as we always assign the "right" value to _:
def fib_reducer(x, _):
return x + [x[-1] + x[-2]]
def fib(n):
return reduce(fib_reducer, range(n - 2), [0, 1])
fib(10)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
Exercise¶
Use reduce and something from the operator module to write the function my_all(iterable) that return True if all elements of iterable are True and False otherwise.
Note Python already has an all function, so you can compare your results to it.
seq1 = [True, True, True]
seq2 = [True, False, True]
def myall(iterable):
# Your code here
pass
assert myall(seq1) == all(seq1)
assert myall(seq2) == all(seq2)
Note that all (or any) is implemented with a short-circuit so that once it sees a False (or True) it stops the iteration.
This can be much faster if a False appears early on in the sequence:
data = [False] + [True] * 100000
%timeit -n 10 myall(data)
%timeit -n 10 all(data)
10 loops, best of 3: 6.21 ms per loop 10 loops, best of 3: 121 ns per loop
Solutions¶
- For the decryption exercise:
decoded = (code.get(c, c) for c in secret)
joined = str.join('', decoded)
print(joined)
Note that code.get is only called when join starts pulling elements from decoded.
- For the custom
all:
def myall(iterable):
booleans = (bool(e) for e in iterable)
return reduce(operator.and_, booleans)
References¶
- Some code and ideas were taken from CS1001.py
- Some code and ideas were taken from Code like a Pythonista
- The itertools module has some functions and tools for creating iterators.
- The operator module has more functions that emulate operators to used in map, reduce, etc.
- Functional programming HOWTO has some more information, as the comprehensions, iterators, map-reduce and filter are the building blocks of functional programming.
- The toolz package has many more tools to use in a functional programming style.
- Read Chapter 14 in the Fluent Python book by Luciano Ramalho for a deep dive into Iterators and everything related.
Colophon¶
This notebook was written by Yoav Ram and is part of the Python for Engineers course.
The notebook was written using Python 3.6.1. Dependencies listed in environment.yml, full versions in environment_full.yml.
This work is licensed under a CC BY-NC-SA 4.0 International License.
![]()