Project summary¶
The aim of this project is to try and extract useful data from the Sydney Stock exchange stock and share lists held by the ANU Archives.
As the content note indicates:
These are large format bound volumes of the official lists that were posted up for the public to see - 3 times a day - forenoon, noon and afternoon - at the close of the trading session in the call room at the Sydney Stock Exchange. The closing prices of stocks and shares were entered in by hand on pre-printed sheets.
There are 199 volumes covering the period from 1901 to 1950, containing more than 70,000 pages. Each pages is divided into columns. The number of columns varies across the collection. Each column is divided into rows labelled with printed company or stock names. The prices are written alongside the company names.
The challenge is not simply to recognise the printed and handwritten values, but to maintain the tabular structure so that the extracted values form a useful dataset.
Column and header detection¶
- Column detection code
- Columns tester – a tool to test column detection on a single page
- Detect columns in all images by year – code to run column detection across all the images, saving the results for each year in a CSV file
- Explore column detection results
- Visualise column detection results
Examples¶

Results¶

Row detection¶

Identifying page dates¶
Each page in the Stock Exchange volumes is dated, and these dates will provide useful access points. They're also essential if we're going to extract a useful dataset.
Included amongst the column detection code is a function that identifies, slices and saves the header of each page. This header includes the date, and usually the session – eg. 'Morning' or 'Afternoon'. Our initial plan involved uploading samples of these headers to Zooniverse, where Archives staff could transcribe them. I thought we might use this as a training set with Transkribus.
Here's some of analysis of the transcription results. After looking at this data I began to wonder how many dates needed to be identified within a volume before we could fill in the blanks. There are, after all, some fairly regular patterns – days of operatation, number of pages per day etc. Initial experiments looked hopeful, but to go any further I had to know more about public holidays in NSW. Having assembled my own dataset of NSW holidays from 1900 to 1950, I used this and what I already knew about the volumes to make some predictions about the number of pages there should be in each volume and compared this to the actual number. In most cases the differences were small, so it seemed like I was on the right track. Here's a sample.

There were, however, a number of small variations from the norm – pages missing, days off etc. For example, when the death of Queen Victoria was announced, the Stock Exchange was closed and everyone went home. To find and document these variations, I first compared my predictions against the transcribed data. By finding where the predictions diverged I could focus on the problem area and identify the problem. But what about volumes without transcriptions? To find variations in any volume I created a simple testing tool that prints out the predicted date and page number of the first page of each morning session, and then displays the corresponding header image underneath. Again, it's just a matter of finding where the predictions diverge from the images and investigating. In practice I found this was pretty quick, and new patterns started to emerge – eg. no afternoon sessions on the day before Good Friday, and a holiday on Easter Tuesday. As I test each volume, I record these variations in a simple dictionary. For example, here's 1901, the numbers next to each date are the actual number of pages in the volume for that day (missing days have zero pages!):
{
'1901-01-07': 3,
'1901-01-18': 4,
'1901-01-23': 0, # Death of the Queen business abandoned https://trove.nla.gov.au/newspaper/article/14371864/1343690
'1901-02-25': 4,
'1901-03-18': 0,
'1901-03-29': 0, # missing
'1901-04-04': 3, # No afternoon, day before Easter
'1901-04-09': 0, # Extra Easter Tuesday
'1901-04-10': 0, # Extra Easter Wednesday
'1901-05-27': 0, # Holiday Duke of Cornwall visiting
'1901-05-28': 0, # Holiday Duke of Cornwall visiting
'1901-07-03': 0, # Holiday for polling day
'1901-09-16': 4, # No morning
'1901-10-10': 4, # 1 Noon
'1901-10-30': 4, # 1 Noon
'1901-12-16': 2, # Noon only
}
In order to use this testing tool I need first to have extracted the header images. This has to be done on CloudStor using SWAN so I don't have to move all the big TIFF files around. It's quite slow. So far I have headers for 32 volumes, covering 1901 to 1908. I've identified the variations for all of these years, visualised the results, and created new CSV files that map page images to their dates. Here's 1901 in calendar form!
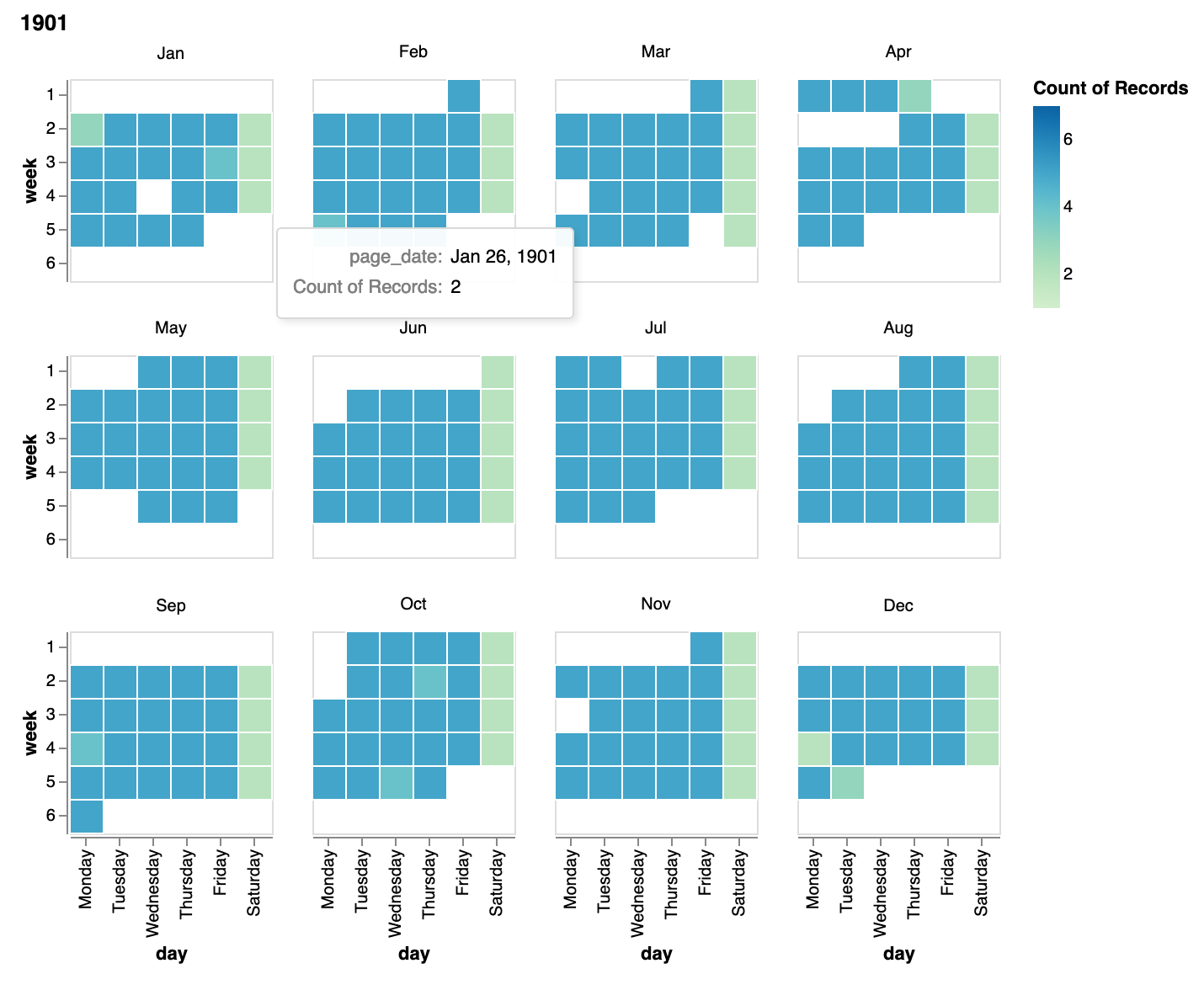
The plan is to keep working year by year as the header images are generated. Hopefully the current patterns are maintained! At the end, each of the 70,000 pages should have a date (and we'll also know more about any gaps or anomalies).
Finally, I've created a simple notebook with a date picker – select a date and the headers of the pages created on that day are displayed. It's a useful way of spot checking the results, and also points to some alternative ways of accessing the collection.
Accessing CloudStor files using WebDav¶
Using the Zooniverse API¶
Using the Transkribus API¶