Optimization in Julia¶
This lecture gives an overview of some optimization tools in Julia.
versioninfo()
Julia Version 1.6.2 Commit 1b93d53fc4 (2021-07-14 15:36 UTC) Platform Info: OS: macOS (x86_64-apple-darwin18.7.0) CPU: Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz WORD_SIZE: 64 LIBM: libopenlibm LLVM: libLLVM-11.0.1 (ORCJIT, skylake)
using Pkg
Pkg.activate("../..")
Pkg.status()
Activating environment at `~/Dropbox/class/M1399.000200/2021/M1399_000200-2021fall/Project.toml`
Status `~/Dropbox/class/M1399.000200/2021/M1399_000200-2021fall/Project.toml` [7d9fca2a] Arpack v0.4.0 [6e4b80f9] BenchmarkTools v1.2.0 [1e616198] COSMO v0.8.1 [f65535da] Convex v0.14.16 [a93c6f00] DataFrames v1.2.2 [31a5f54b] Debugger v0.6.8 [31c24e10] Distributions v0.24.18 [e2685f51] ECOS v0.12.3 [f6369f11] ForwardDiff v0.10.21 [28b8d3ca] GR v0.61.0 [c91e804a] Gadfly v1.3.3 [bd48cda9] GraphRecipes v0.5.7 [2e9cd046] Gurobi v0.9.14 [f67ccb44] HDF5 v0.14.3 [82e4d734] ImageIO v0.5.8 [6218d12a] ImageMagick v1.2.1 [916415d5] Images v0.24.1 [b6b21f68] Ipopt v0.7.0 [42fd0dbc] IterativeSolvers v0.9.1 [4076af6c] JuMP v0.21.10 [b51810bb] MatrixDepot v1.0.4 [6405355b] Mosek v1.2.1 [1ec41992] MosekTools v0.9.4 [76087f3c] NLopt v0.6.3 [47be7bcc] ORCA v0.5.0 [a03496cd] PlotlyBase v0.4.3 [f0f68f2c] PlotlyJS v0.15.0 [91a5bcdd] Plots v1.22.6 [438e738f] PyCall v1.92.3 [d330b81b] PyPlot v2.10.0 [dca85d43] QuartzImageIO v0.7.3 [6f49c342] RCall v0.13.12 [ce6b1742] RDatasets v0.7.5 [c946c3f1] SCS v0.7.1 [276daf66] SpecialFunctions v1.7.0 [2913bbd2] StatsBase v0.33.12 [f3b207a7] StatsPlots v0.14.28 [b8865327] UnicodePlots v2.4.6 [0f1e0344] WebIO v0.8.16 [8f399da3] Libdl [2f01184e] SparseArrays [10745b16] Statistics
Package QuartzImageIO is for macOS only.
Flowchart¶
Category of optimization problems:
Problems with analytical solutions: least squares, principle component analysis, canonical correlation analysis, ...
Problems subject to Disciplined Convex Programming (DCP): linear programming (LP), quadratic programming (QP), second-order cone programming (SOCP), semidefinite programming (SDP), and geometric programming (GP).
Nonlinear programming (NLP): Newton type algorithms, Fisher scoring algorithm, EM algorithm, MM algorithms.
Large scale optimization: ADMM, SGD, ...
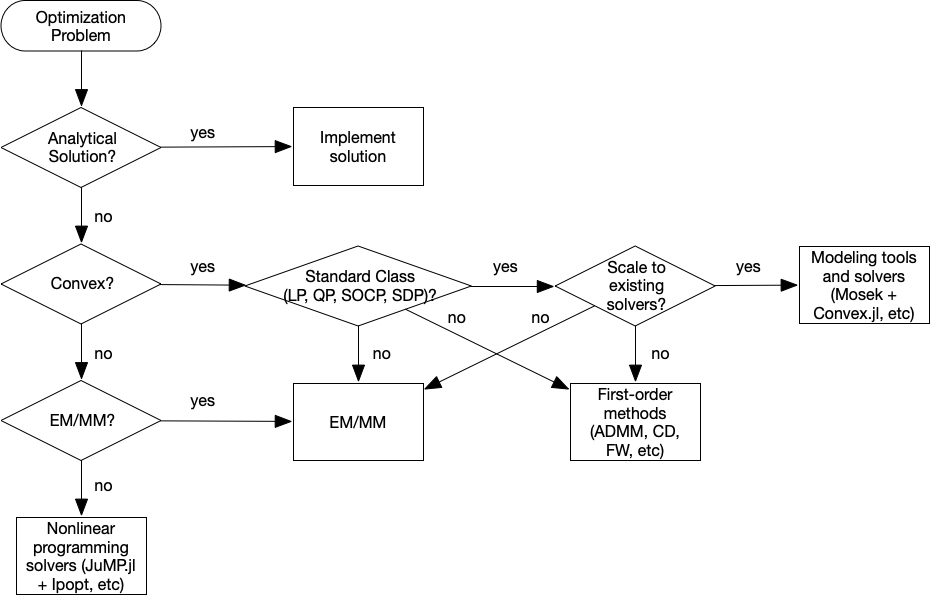
Modeling tools and solvers¶
Getting familiar with good optimization softwares broadens the scope and scale of problems we are able to solve in statistics. Following table lists some of the best optimization softwares.
| LP | MILP | SOCP | MISOCP | SDP | GP | NLP | MINLP | R | Matlab | Julia | Python | Cost | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| modeling tools | ||||||||||||||||
| AMPL | x | x | x | x | x | x | x | x | x | x | x | $ | ||||
| cvx | x | x | x | x | x | x | x | x | A | |||||||
| Convex.jl | x | x | x | x | x | x | O | |||||||||
| JuMP.jl | x | x | x | x | x | x | x | O | ||||||||
| MathProgBase.jl | x | x | x | x | x | x | x | O | ||||||||
| MathOptInterface.jl | x | x | x | x | x | x | x | O | ||||||||
| convex solvers | ||||||||||||||||
| Mosek | x | x | x | x | x | x | x | x | x | x | x | A | ||||
| Gurobi | x | x | x | x | x | x | x | x | A | |||||||
| CPLEX | x | x | x | x | x | x | x | x | A | |||||||
| SCS | x | x | x | x | x | x | O | |||||||||
| NLP solvers | ||||||||||||||||
| NLopt | x | x | x | x | x | O | ||||||||||
| Ipopt | x | x | x | x | x | O | ||||||||||
| KNITRO | x | x | x | x | x | x | x | x | $ |
- O: open source
- A: free academic license
- $: commercial
Difference between modeling tools and solvers¶
Solvers¶
Mosek, Gurobi, Cplex, SCS, etc are concrete software implementation of optimization algorithms.
- Mosek/Gurobi/SCS for convex optimization
- Ipopt/NLopt for nonlinear programming
- Mosek and Gurobi are commercial software but free for academic use. SCS/Ipopt/NLopt are open source.
Users need to implement the problem to solve using their application programming interface (API). Example
Modeling tools¶
AMPL (comercial, https://ampl.com) is an algebraic modeling language that allows describe the optimization problem most close to its mathematical formulation. Sample model
cvx (for Matlab) and Convex.jl (Julia) implement the disciplined convex programming (DCP) paradigm proposed by Grant and Boyd (2008). DCP prescribes a set of simple rules from which users can construct convex optimization problems easily.
Convex.jlinterfaces with actural problem solvers via MathOptInterface, an abstraction layer for mathematical optimization solvers in Julia.- For example, MOSEK is an actual interior-point solver for convex and mixed-integer programs. It provides APIs that can be accessed in low-level using Mosek.jl, which is abstractized by MosekTools.jl, which in turn implements
MathOptInterface.
- For example, MOSEK is an actual interior-point solver for convex and mixed-integer programs. It provides APIs that can be accessed in low-level using Mosek.jl, which is abstractized by MosekTools.jl, which in turn implements
Modeling tools usually have the capability to use a variety of solvers. But modeling tools are solver agnostic so users do not have to worry about specific solver interface.
DCP Using Convex.jl¶
Standard convex problem classes like LP (linear programming), QP (quadratic programming), SOCP (second-order cone programming), SDP (semidefinite programming), and GP (geometric programming), are becoming a technology.

Example: microbiome regression analysis -- compositional data¶
We illustrate optimization tools in Julia using microbiome analysis as an example.
Diversity of gut microbiome is believed to be an important factor for human health or diseases such as obesity; respiratory microbiome affects pulmonary function in an HIV-infected population.
16S microbiome sequencing techonology generates sequence counts of various organisms (operational taxonomic units, or OTUs) in samples.

The major interest is the composition of the microbiome in the population, hence for statistical analysis, OTU counts are normalized into proportions for each sample. Thus if there are $p$ OTUs, each observation $\mathbf{z}_i$ lies in the positive probability simplex $\Delta_{p-1,+}=\{z_1, \dotsc, z_p : z_j > 0, \sum_{j=1}^p z_j=1\}$. This unit-sum constraint introduces dependency between the $p$ variables, causing intrinsic difficulties in providing sensible interpretations for the regression parameters. A well-known resolution of this difficulty is the log-ratio transfomation due to Aitchson, which constructs the data matrix $\tilde{\mathbf{X}}=(\log\frac{z_{ij}}{z_{ip}}) \in \mathbb{R}^{n\times (p-1)}$. Thus the regression model is $$ \mathbf{y} = \tilde{\mathbf{X}}\tilde{\boldsymbol\beta} + \boldsymbol{\varepsilon}, \quad \tilde{\boldsymbol\beta} \in \mathbb{R}^{p-1}. $$
By introducing an extra coefficient $\beta_p = -\sum_{j=1}^{p-1}\beta_j$, and letting $\mathbf{X}=(\log z_{ij})$, the above, assymetric model becomes symmetric: $$ \mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}, \quad \boldsymbol{\beta} \in \mathbb{R}^{p}. $$
Zero-sum regression¶
In other words, we need to solve a zero-sum least squares problem
$$
\begin{array}{ll}
\text{minimize} & \frac{1}{2} \|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\|_2^2 \\
\text{subject to} & \mathbf{1}^T\boldsymbol{\beta} = 0.
\end{array}
$$
For details, see
Lin, W., Shi, P., Feng, R. and Li, H., 2014. Variable selection in regression with compositional covariates. Biometrika, 101(4), pp.785-797. https://doi.org/10.1093/biomet/asu031
The sum-to-zero contrained least squares is a standard quadratic programming (QP) problem so should be solved easily by any QP solver.
For simplicity we ignore intercept and non-OTU covariates in this presentation.
Let's first generate an artifical dataset:
using Random, LinearAlgebra, SparseArrays
Random.seed!(123) # seed
n, p = 100, 50
X = rand(n, p)
lmul!(Diagonal(1 ./ vec(sum(X, dims=2))), X)
β = sprandn(p, 0.1) # sparse vector with about 10% non-zero entries
y = X * β + randn(n);
using Convex
β̂cls = Variable(size(X, 2))
problem = minimize(0.5sumsquares(y - X * β̂cls)) # objective
problem.constraints += sum(β̂cls) == 0; # sum-to-zero constraint
Mosek¶
We first use the Mosek solver to solve this QP.
using Mosek, MosekTools
opt = () -> Mosek.Optimizer(LOG=1) # anonymous function
@time solve!(problem, opt)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 157 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 1 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.00 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 157 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 8 Optimizer - solved problem : the dual Optimizer - Constraints : 52 Optimizer - Cones : 3 Optimizer - Scalar variables : 106 conic : 106 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1328 after factor : 1328 Factor - dense dim. : 0 flops : 3.08e+05 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 3.0e+00 5.0e-01 2.0e+00 0.00e+00 0.000000000e+00 -1.000000000e+00 1.0e+00 0.00 1 2.9e-01 4.8e-02 5.7e-01 -9.26e-01 2.915150182e+00 9.703344707e+00 9.7e-02 0.01 2 4.4e-02 7.4e-03 1.3e-01 -7.10e-01 1.845835780e+01 3.574733771e+01 1.5e-02 0.01 3 2.1e-03 3.5e-04 4.6e-04 7.65e-01 2.901642971e+01 2.908435432e+01 7.0e-04 0.02 4 1.7e-06 2.9e-07 1.3e-08 1.00e+00 2.899788909e+01 2.899798941e+01 5.7e-07 0.02 5 2.5e-10 4.2e-11 2.8e-14 1.00e+00 2.899829742e+01 2.899829744e+01 8.4e-11 0.02 Optimizer terminated. Time: 0.02 22.001013 seconds (50.39 M allocations: 2.889 GiB, 7.04% gc time)
# Check the status, optimal value, and minimizer of the problem
problem.status, problem.optval, β̂cls.value
(MathOptInterface.OPTIMAL, 28.998297421260087, [13.668687461115228; -9.772741354380681; … ; 21.133785591984804; -15.115087762560165])
ENV["GRB_LICENSE_FILE"]="/Users/jhwon/gurobi/gurobi.lic" # set as YOUR path to license file
"/Users/jhwon/gurobi/gurobi.lic"
using Gurobi
const GRB_ENV = Gurobi.Env()
opt = () -> Gurobi.Optimizer(GRB_ENV) # anonymous function
@time solve!(problem, opt)
Academic license - for non-commercial use only - expires 2021-12-30
Gurobi Optimizer version 9.1.2 build v9.1.2rc0 (mac64)
Thread count: 4 physical cores, 8 logical processors, using up to 8 threads
Optimize a model with 107 rows, 157 columns and 5160 nonzeros
Model fingerprint: 0xab10ce97
Model has 2 quadratic constraints
Coefficient statistics:
Matrix range [1e-05, 2e+00]
QMatrix range [1e+00, 1e+00]
Objective range [1e+00, 1e+00]
Bounds range [0e+00, 0e+00]
RHS range [2e-03, 3e+00]
Presolve removed 2 rows and 1 columns
Presolve time: 0.00s
Presolved: 105 rows, 156 columns, 5158 nonzeros
Presolved model has 2 second-order cone constraints
Ordering time: 0.00s
Barrier statistics:
Free vars : 50
AA' NZ : 5.154e+03
Factor NZ : 5.262e+03
Factor Ops : 3.590e+05 (less than 1 second per iteration)
Threads : 1
Objective Residual
Iter Primal Dual Primal Dual Compl Time
0 1.12826689e+01 -5.01000000e-01 2.29e+01 1.00e-01 2.00e-01 0s
1 3.22840813e+00 6.27715458e-02 4.49e+00 3.72e-05 3.88e-02 0s
2 4.08178592e+00 5.62149847e+00 3.32e+00 3.97e-05 2.14e-02 0s
3 1.64813094e+01 8.57926093e+00 9.91e-01 3.54e-05 9.22e-02 0s
4 1.75521420e+01 1.58590777e+01 7.37e-01 4.78e-06 4.66e-02 0s
5 1.92008663e+01 2.62514505e+01 6.28e-01 3.87e-06 1.63e-02 0s
6 3.03618788e+01 2.79564255e+01 9.67e-03 1.02e-07 2.45e-02 0s
7 2.91004528e+01 2.89455416e+01 3.83e-04 4.40e-08 1.54e-03 0s
8 2.90061906e+01 2.89953287e+01 2.12e-05 3.54e-09 1.07e-04 0s
9 2.89983319e+01 2.89982844e+01 2.40e-07 1.52e-09 4.70e-07 0s
10 2.89982975e+01 2.89982974e+01 4.99e-09 3.80e-11 2.65e-09 0s
Barrier solved model in 10 iterations and 0.02 seconds
Optimal objective 2.89982975e+01
User-callback calls 63, time in user-callback 0.00 sec
4.380080 seconds (8.73 M allocations: 511.805 MiB, 5.60% gc time)
# Check the status, optimal value, and minimizer of the problem
problem.status, problem.optval, β̂cls.value
(MathOptInterface.OPTIMAL, 28.998297507778627, [13.668678309342742; -9.7727402141536; … ; 21.133769207305104; -15.115075595252181])
# Use SCS solver
using SCS
opt = () -> SCS.Optimizer(verbose=1) # anonymous function
@time solve!(problem, opt)
5.340976 seconds (10.35 M allocations: 607.867 MiB, 4.62% gc time, 5.22% compilation time)
----------------------------------------------------------------------------
SCS v2.1.4 - Splitting Conic Solver
(c) Brendan O'Donoghue, Stanford University, 2012
----------------------------------------------------------------------------
Lin-sys: sparse-indirect, nnz in A = 5056, CG tol ~ 1/iter^(2.00)
eps = 1.00e-05, alpha = 1.50, max_iters = 5000, normalize = 1, scale = 1.00
acceleration_lookback = 10, rho_x = 1.00e-03
Variables n = 53, constraints m = 107
Cones: primal zero / dual free vars: 2
linear vars: 1
soc vars: 104, soc blks: 2
Setup time: 3.35e-04s
----------------------------------------------------------------------------
Iter | pri res | dua res | rel gap | pri obj | dua obj | kap/tau | time (s)
----------------------------------------------------------------------------
0| 9.17e+19 5.76e+19 1.00e+00 -1.04e+21 8.59e+20 1.59e+21 5.64e-04
100| 1.44e-05 9.44e-06 5.09e-06 2.90e+01 2.90e+01 7.55e-16 1.01e-02
120| 3.60e-06 2.64e-06 1.23e-06 2.90e+01 2.90e+01 3.93e-16 1.10e-02
----------------------------------------------------------------------------
Status: Solved
Timing: Solve time: 1.10e-02s
Lin-sys: avg # CG iterations: 6.79, avg solve time: 7.90e-05s
Cones: avg projection time: 1.69e-07s
Acceleration: avg step time: 9.57e-06s
----------------------------------------------------------------------------
Error metrics:
dist(s, K) = 3.5527e-15, dist(y, K*) = 4.4409e-16, s'y/|s||y| = -8.9856e-17
primal res: |Ax + s - b|_2 / (1 + |b|_2) = 3.6046e-06
dual res: |A'y + c|_2 / (1 + |c|_2) = 2.6431e-06
rel gap: |c'x + b'y| / (1 + |c'x| + |b'y|) = 1.2313e-06
----------------------------------------------------------------------------
c'x = 28.9983, -b'y = 28.9983
============================================================================
# Check the status, optimal value, and minimizer of the problem
problem.status, problem.optval, β̂cls.value
(MathOptInterface.OPTIMAL, 28.99834367864642, [13.668719778517216; -9.772627374792503; … ; 21.13380901845421; -15.115084607474534])
# Use COSMO solver
using COSMO
opt = () -> COSMO.Optimizer(max_iter=5000) # anonymous function
@time solve!(problem, opt)
------------------------------------------------------------------
COSMO v0.8.1 - A Quadratic Objective Conic Solver
Michael Garstka
University of Oxford, 2017 - 2021
------------------------------------------------------------------
Problem: x ∈ R^{53},
constraints: A ∈ R^{107x53} (5056 nnz),
matrix size to factor: 160x160,
Floating-point precision: Float64
Sets: SecondOrderCone) of dim: 101
SecondOrderCone) of dim: 3
ZeroSet) of dim: 2
Nonnegatives) of dim: 1
Settings: ϵ_abs = 1.0e-05, ϵ_rel = 1.0e-05,
ϵ_prim_inf = 1.0e-04, ϵ_dual_inf = 1.0e-04,
ρ = 0.1, σ = 1e-06, α = 1.6,
max_iter = 5000,
scaling iter = 10 (on),
check termination every 25 iter,
check infeasibility every 40 iter,
KKT system solver: QDLDL
Acc: Anderson Type2{QRDecomp},
Memory size = 15, RestartedMemory,
Safeguarded: true, tol: 2.0
Setup Time: 998.06ms
Iter: Objective: Primal Res: Dual Res: Rho:
1 -2.4722e+00 6.0889e+00 3.8576e+02 1.0000e-01
25 2.6959e+01 1.5279e-01 5.7669e+00 1.0000e-01
50 2.8666e+01 1.4083e-02 5.0905e-03 1.2134e-02
75 2.8998e+01 4.2267e-09 4.8880e-11 1.2134e-02
------------------------------------------------------------------
>>> Results
Status: Solved
Iterations: 85 (incl. 10 safeguarding iter)
Optimal objective: 29
Runtime: 2.924s (2923.52ms)
18.050220 seconds (51.06 M allocations: 2.824 GiB, 8.01% gc time, 1.91% compilation time)
# Check the status, optimal value, and minimizer of the problem
problem.status, problem.optval, β̂cls.value
(MathOptInterface.OPTIMAL, 28.998297502384982, [13.668687496059547; -9.772741376125092; … ; 21.133785644856946; -15.115087801073152])
Zero-sum lasso¶
Suppose we want to know which organisms (OTUs) are associated with the response. We can answer this question using a zero-sum contrained lasso $$ \begin{array}{ll} \text{minimize} & \frac 12 \|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\|_2^2 + \lambda \|\boldsymbol{\beta}\|_1 \\ \text{subject to} & \mathbf{1}^T\boldsymbol{\beta} = 0. \end{array} $$
Varying $\lambda$ from small to large values will generate a solution path.
# Use Mosek solver
#opt = () -> Mosek.Optimizer(LOG=0)
## Use Gurobi solver
##solver = Gurobi.Optimizer(GRB_ENV)
#using JuMP
#opt = () -> Gurobi.Optimizer(GRB_ENV)
##model = direct_model(Gurobi.Optimizer(GRB_ENV))
##MOI.set(model, MOI.RawParameter("OutputFlag"), 0)
##set_optimizer_attribute(JuMP.Model(opt), "OutputFlag", 0)
# Use SCS solver
opt = () -> SCS.Optimizer(verbose=0)
## Use COSMO solver
#opt = () -> COSMO.Optimizer(max_iter=10000, verbose=false)
# solve at a grid of λ
λgrid = 0:0.01:0.35
β̂path = zeros(length(λgrid), size(X, 2)) # each row is β̂ at a λ
β̂classo = Variable(size(X, 2))
@time for i in 1:length(λgrid)
λ = λgrid[i]
# objective
problem = minimize(0.5sumsquares(y - X * β̂classo) + λ * sum(abs, β̂classo))
# constraint
problem.constraints += sum(β̂classo) == 0 # constraint
solve!(problem, opt)
β̂path[i, :] = β̂classo.value
end
1.631235 seconds (3.64 M allocations: 264.189 MiB, 4.66% gc time, 50.18% compilation time)
using Plots; gr()
p = plot(collect(λgrid), β̂path, legend=:none)
xlabel!(p, "lambda")
ylabel!(p, "beta_hat")
title!(p, "Zero-sum Lasso")
Zero-sum group lasso¶
Suppose we want to do variable selection not at the OTU level, but at the Phylum level. OTUs are clustered into various Phyla. We can answer this question using a sum-to-zero contrained group lasso $$ \begin{array}{ll} \text{minimize} & \frac 12 \|\mathbf{y} - \mathbf{X} \boldsymbol{\beta}\|_2^2 + \lambda \sum_j \|\boldsymbol{\beta}_j\|_2 \\ \text{subject to} & \mathbf{1}^T\boldsymbol{\beta} = 0, \end{array} $$ where $\boldsymbol{\beta}_j$ is the $j$th partition of the regression coefficients corresponding to the $j$th phylum. This is a second-order cone programming (SOCP) problem readily modeled by Convex.jl.
Let's assume each 10 contiguous OTUs belong to one Phylum.
# Use Mosek solver
#opt = () -> Mosek.Optimizer(LOG=0)
## Use Gurobi solver
##solver = Gurobi.Optimizer(GRB_ENV)
#using JuMP
#opt = () -> Gurobi.Optimizer(GRB_ENV)
##model = direct_model(Gurobi.Optimizer(GRB_ENV))
##MOI.set(model, MOI.RawParameter("OutputFlag"), 0)
##set_optimizer_attribute(JuMP.Model(opt), "OutputFlag", 0)
# Use SCS solver
opt = () -> SCS.Optimizer(verbose=0)
## Use COSMO solver
#opt = () -> COSMO.Optimizer(max_iter=5000, verbose=false)
# solve at a grid of λ
λgrid = 0.1:0.005:0.5
β̂pathgrp = zeros(length(λgrid), size(X, 2)) # each row is β̂ at a λ
β̂classo = Variable(size(X, 2))
@time for i in 1:length(λgrid)
λ = λgrid[i]
# loss
obj = 0.5sumsquares(y - X * β̂classo)
# group lasso penalty term
for j in 1:(size(X, 2)/10)
βj = β̂classo[(10(j-1)+1):10j]
obj = obj + λ * norm(βj)
end
problem = minimize(obj)
# constraint
problem.constraints += sum(β̂classo) == 0 # constraint
solve!(problem, opt)
β̂pathgrp[i, :] = β̂classo.value
end
2.747849 seconds (3.03 M allocations: 249.958 MiB, 3.58% gc time, 31.95% compilation time)
It took Mosek <1 second to solve this seemingly hard optimization problem at 80 different $\lambda$ values.
p2 = plot(collect(λgrid), β̂pathgrp, legend=:none)
xlabel!(p2, "lambda")
ylabel!(p2, "beta_hat")
title!(p2, "Zero-Sum Group Lasso")
{kind=link}
using Images
lena = load("lena128missing.png")

# convert to real matrices
Y = Float64.(lena)
128×128 Matrix{Float64}:
0.0 0.0 0.635294 0.0 … 0.0 0.0 0.627451
0.627451 0.623529 0.0 0.611765 0.0 0.0 0.388235
0.611765 0.611765 0.0 0.0 0.403922 0.219608 0.0
0.0 0.0 0.611765 0.0 0.223529 0.176471 0.192157
0.611765 0.0 0.615686 0.615686 0.0 0.0 0.0
0.0 0.0 0.0 0.619608 … 0.0 0.0 0.2
0.607843 0.0 0.623529 0.0 0.176471 0.192157 0.0
0.0 0.0 0.623529 0.0 0.0 0.0 0.215686
0.619608 0.619608 0.0 0.0 0.2 0.0 0.207843
0.0 0.0 0.635294 0.635294 0.2 0.192157 0.188235
0.635294 0.0 0.0 0.0 … 0.192157 0.180392 0.0
0.631373 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.627451 0.635294 0.666667 0.172549 0.0 0.184314
⋮ ⋱ ⋮
0.0 0.129412 0.0 0.541176 0.0 0.286275 0.0
0.14902 0.129412 0.196078 0.537255 0.345098 0.0 0.0
0.215686 0.0 0.262745 0.0 0.301961 0.0 0.207843
0.345098 0.341176 0.356863 0.513725 0.0 0.0 0.231373
0.0 0.0 0.0 0.0 … 0.0 0.243137 0.258824
0.298039 0.415686 0.458824 0.0 0.0 0.0 0.258824
0.0 0.368627 0.4 0.0 0.0 0.0 0.235294
0.0 0.0 0.34902 0.0 0.0 0.239216 0.207843
0.219608 0.0 0.0 0.0 0.0 0.0 0.2
0.0 0.219608 0.235294 0.356863 … 0.0 0.0 0.0
0.196078 0.207843 0.211765 0.0 0.0 0.270588 0.345098
0.192157 0.0 0.196078 0.309804 0.266667 0.356863 0.0
We fill out the missing pixels uisng a matrix completion technique developed by Candes and Tao $$ \begin{array}{ll} \text{minimize} & \|\mathbf{X}\|_* \\ \text{subject to} & x_{ij} = y_{ij} \text{ for all observed entries } (i, j). \end{array} $$
Here $\|\mathbf{X}\|_* = \sum_{i=1}^{\min(m,n)} \sigma_i(\mathbf{X})$ is the nuclear norm. It can be shown that $$ \|\mathbf{X}\|_* = \sup_{\|\mathbf{Y}\|_2 \le 1} \langle \mathbf{X}, \mathbf{Y} \rangle, $$ where $\|\mathbf{Y}\|_2=\sigma_{\max}(\mathbf{Y})$ is the spectral (operator 2-) norm, and $\langle \mathbf{X}, \mathbf{Y} \rangle = \text{tr}(\mathbf{X}^T\mathbf{Y})$. That is, $\|\cdot\|_*$ is the dual norm of $\|\cdot\|_2$.
The nuclear norm can be considered as the best convex approximation to $\text{rank}(M)$, just like $\|\mathbf{x}\|_1$ is the best convex approximation to $\|\mathbf{x}\|_0$. We want the matrix with the lowest rank that agrees with the observed entries, but instead seek one with the minimal nuclear norm as a convex relaxation.
This is a semidefinite programming (SDP) problem readily modeled by Convex.jl.
This example takes long because of high dimensionality.
# Use COSMO solver
using COSMO
opt = () -> COSMO.Optimizer()
## Use SCS solver
#using SCS
#opt = () -> SCS.Optimizer()
## Use Mosek solver
#using Mosek
#opt = () -> Mosek.Optimizer()
# Linear indices of obs. entries
obsidx = findall(Y[:] .≠ 0.0)
# Create optimization variables
X = Convex.Variable(size(Y))
# Set up optmization problem
problem = minimize(nuclearnorm(X))
problem.constraints += X[obsidx] == Y[obsidx]
# Solve the problem by calling solve
@time solve!(problem, opt)
------------------------------------------------------------------
COSMO v0.8.1 - A Quadratic Objective Conic Solver
Michael Garstka
University of Oxford, 2017 - 2021
------------------------------------------------------------------
Problem: x ∈ R^{49153},
constraints: A ∈ R^{73665x49153} (73793 nnz),
matrix size to factor: 122818x122818,
Floating-point precision: Float64
Sets: ZeroSet) of dim: 40769
DensePsdConeTriangle) of dim: 32896
Settings: ϵ_abs = 1.0e-05, ϵ_rel = 1.0e-05,
ϵ_prim_inf = 1.0e-04, ϵ_dual_inf = 1.0e-04,
ρ = 0.1, σ = 1e-06, α = 1.6,
max_iter = 5000,
scaling iter = 10 (on),
check termination every 25 iter,
check infeasibility every 40 iter,
KKT system solver: QDLDL
Acc: Anderson Type2{QRDecomp},
Memory size = 15, RestartedMemory,
Safeguarded: true, tol: 2.0
Setup Time: 112.44ms
Iter: Objective: Primal Res: Dual Res: Rho:
1 -1.4426e+03 1.1678e+01 5.9856e-01 1.0000e-01
25 1.4495e+02 5.5360e-02 1.1033e-03 1.0000e-01
50 1.4754e+02 1.2369e-02 1.6744e-03 7.4179e-01
75 1.4797e+02 4.9490e-04 5.5696e-05 7.4179e-01
100 1.4797e+02 1.4115e-05 1.3438e-06 7.4179e-01
------------------------------------------------------------------
>>> Results
Status: Solved
Iterations: 100
Optimal objective: 148
Runtime: 2.103s (2103.34ms)
10.198321 seconds (18.36 M allocations: 1.704 GiB, 7.96% gc time, 70.20% compilation time)
colorview(Gray, X.value)

Nonlinear programming (NLP)¶
We use MLE of Gamma distribution to illustrate some rudiments of nonlinear programming (NLP) in Julia.
Let $x_1,\ldots,x_m$ be a random sample from the gamma density with shape parameter $\alpha$ and rate parameter $\beta$: $$ f(x) = \Gamma(\alpha)^{-1} \beta^{\alpha} x^{\alpha-1} e^{-\beta x} $$ on $(0,\infty)$. The log likelihood function is $$ L(\alpha, \beta) = m [- \ln \Gamma(\alpha) + \alpha \ln \beta + (\alpha - 1)\overline{\ln x} - \beta \bar x], $$ where $\overline{x} = \frac{1}{m} \sum_{i=1}^m x_i$ and $\overline{\ln x} = \frac{1}{m} \sum_{i=1}^m \ln x_i$.
using Random, Statistics, SpecialFunctions
Random.seed!(280)
function gamma_logpdf(x::Vector, α::Real, β::Real)
m = length(x)
avg = mean(x)
logavg = sum(log, x) / m
m * (- loggamma(α) + α * log(β) + (α - 1) * logavg - β * avg)
end
x = rand(5)
gamma_logpdf(x, 1.0, 1.0)
-2.7886541275400365
Many optimization algorithms involve taking derivatives of the objective function. The ForwardDiff.jl package implements automatic differentiation. For example, to compute the derivative and Hessian of the log-likelihood with data x at α=1.0 and β=1.0.
using ForwardDiff
ForwardDiff.gradient(θ -> gamma_logpdf(x, θ...), [1.0; 1.0])
2-element Vector{Float64}:
-1.058800554530917
2.2113458724599635
ForwardDiff.hessian(θ -> gamma_logpdf(x, θ...), [1.0; 1.0])
2×2 Matrix{Float64}:
-8.22467 5.0
5.0 -5.0
Generate data:
using Distributions, Random
Random.seed!(280)
(n, p) = (1000, 2)
(α, β) = 5.0 * rand(p)
x = rand(Gamma(α, β), n)
println("True parameter values:")
println("α = ", α, ", β = ", β)
True parameter values: α = 0.5535947086407722, β = 4.637963827225865
We use JuMP.jl to define and solve our NLP problem.
Recall that we want to solve the optimization problem: $$ \begin{array}{ll} \text{maximize} & L(\alpha, \beta)= m [- \ln \Gamma(\alpha) + \alpha \ln \beta + (\alpha - 1)\overline{\ln x} - \beta \bar x] \\ \text{subject to} & \alpha \ge 0 \\ ~ & \beta \ge 0 \end{array} $$
Observe the similarity and difference in modeling with Convex.jl:
using JuMP, Ipopt, NLopt
#m = Model(with_optimizer(Ipopt.Optimizer, print_level=3))
m = Model(
optimizer_with_attributes(
NLopt.Optimizer, "algorithm" => :LD_MMA
)
)
myf(a, b) = gamma_logpdf(x, a, b)
JuMP.register(m, :myf, 2, myf, autodiff=true)
@variable(m, α >= 1e-8)
@variable(m, β >= 1e-8)
@NLobjective(m, Max, myf(α, β))
print(m)
status = JuMP.optimize!(m)
println("MLE (JuMP):")
println("α = ", JuMP.value(α), ", β = ", JuMP.value(β))
println("Objective value: ", JuMP.objective_value(m))
MLE (JuMP): α = 0.5489638225054433, β = 0.20038521795829256 Objective value: -1853.384817360246
Then convert the rate parameter to the scale parameter to compare the result with fit_mle() in the Distribution package:
println("α = ", JuMP.value(α), ", θ = ", 1 / JuMP.value(β))
println("MLE (Distribution package):")
println(fit_mle(Gamma, x))
α = 0.5489638225054433, θ = 4.990388064493541
MLE (Distribution package):
Gamma{Float64}(α=0.5489317142213413, θ=4.990963923701522)
Acknowledgment¶
Many parts of this lecture note is based on Dr. Hua Zhou's 2019 Spring Statistical Computing course notes available at http://hua-zhou.github.io/teaching/biostatm280-2019spring/index.html.