Toggle navigation
JUPYTER
FAQ
View as Code
Python 3 Kernel
View on GitHub
Execute on Binder
Download Notebook
Spoken-Digit-Recognizer
docs
Notebook
Demo
Target(1): 結合所有Project成果為GUI展示
¶
Target(2): 使用者可透過麥克風説話,程式將判斷使用者說了哪些中/英數字
¶
Demo影片
¶
對應source code連結
¶
Demo資料夾
¶
main.py (主程式,已結合split_audio.py)
audiostream.py (處理麥克風音訊)
visualizer.ui (介面設計檔)
models (CQT+CNN, STFT+CNN, MFCC+RNN,各有中/英版本,共6個model)
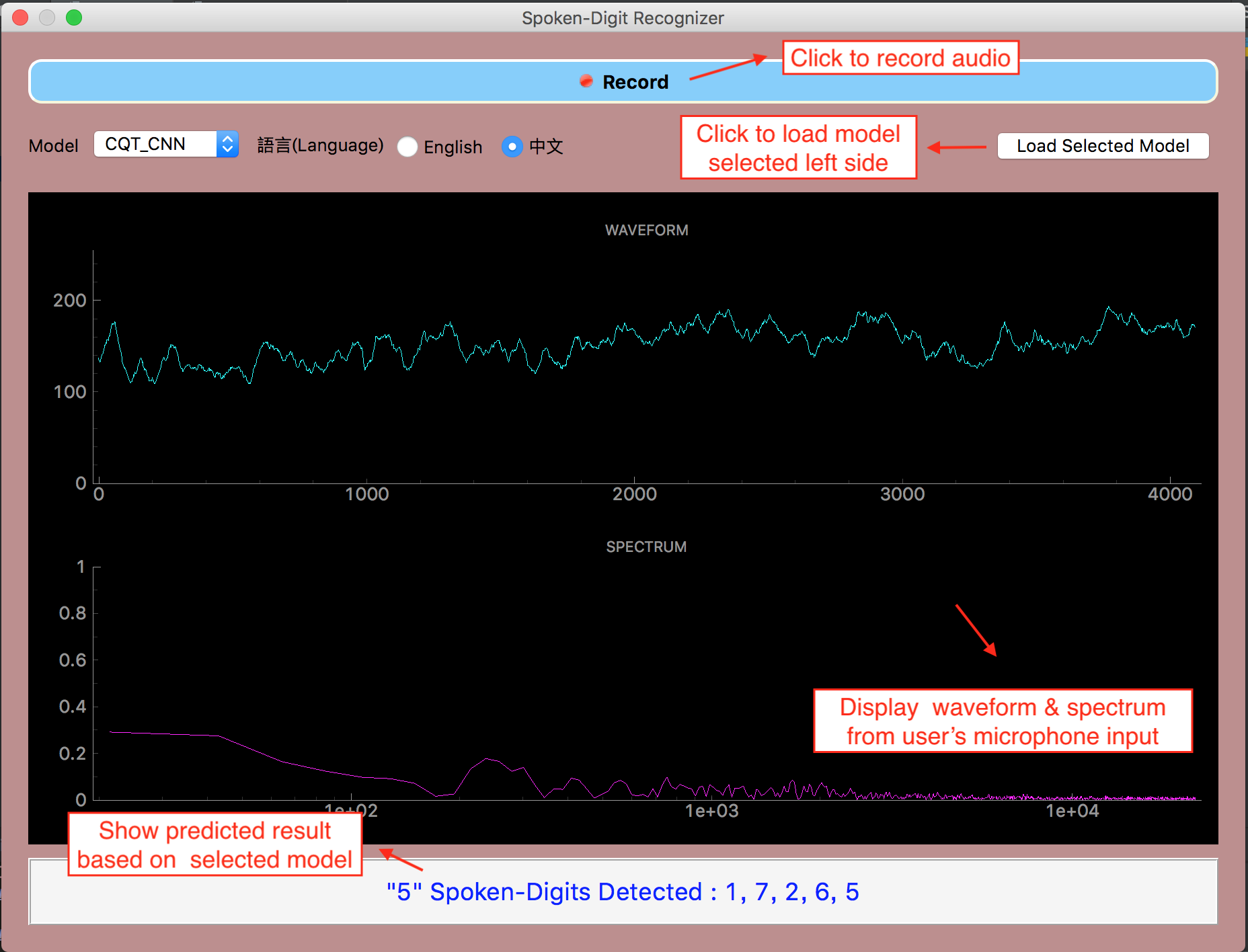
GUI介面
¶
處理流程
¶
使用者選取Model,共六種Model供選擇,分別是
EN_CQT_CNN.h5
CH_CQT_CNN.h5
EN_STFT_CNN.h5
CH_STFT_CNN.h5
EN_MFCC_RNN.h5
CH_MFCC_RNN.h5
點選"Record"按鈕錄音,再按一次停止錄音
程式將使用split_audio.py之程式分割音檔
使用選擇的Model偵測每個分割的音檔數字為何
Reference
¶
https://github.com/markjay4k/Audio-Spectrum-Analyzer-in-Python