CS236781: Deep Learning¶
Tutorial 5: Optimization¶
Introduction¶
In this tutorial, we will cover:
- Descent-based optimization
- Back-propagation
- Automatic differentiation
- PyTorch backward functions
- Bi-level differentiable optimization
- Time-series prediction with CNNs
# Setup
%matplotlib inline
import os
import sys
import time
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14
data_dir = os.path.expanduser('~/.pytorch-datasets')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Theory Reminders¶
Descent-based optimization¶
As we have seen, training deep neural network is performed iteratively using descent-based optimization.
The general scheme is,
- Initialize parameters to some $\vec{\Theta}^0 \in \set{R}^P$, and set $k\leftarrow 0$.
- While not converged:
- Choose a direction $\vec{d}^k\in\set{R}^P$
- Choose a step size $\eta_k\in\set{R}$
- Update: $\vec{\Theta}^{k+1} \leftarrow \vec{\Theta}^k + \eta_k \vec{d}^k$
- $k\leftarrow k+1$
Which descent direction to choose?
The one which maximally decreases the loss function $L(\vec{\Theta})$:
$$ \vec{d} =\arg\min_{\vec{d'}} L(\vec{\Theta}+\vec{d'})-L(\vec{\Theta}) \approx \arg\min_{\vec{d'}}\nabla L(\vec{\Theta})^\top\vec{d'}, \ \mathrm{s.t.} \norm{\vec{d}}_p=1 $$Choice of norm determines $\vec{d}$. For example,
- $p=1$: Coordinate descent: direction of the largest gradient component.
- $p=2$: Gradient descent: $\vec{d}=-\nabla L(\vec{\Theta})$.
| $p=1$ | $p=2$ |
|---|---|
 |
 |
Drawbacks and mitigations?¶
Susceptible to initialization
Initializing near local minima can prevent finding better ones.
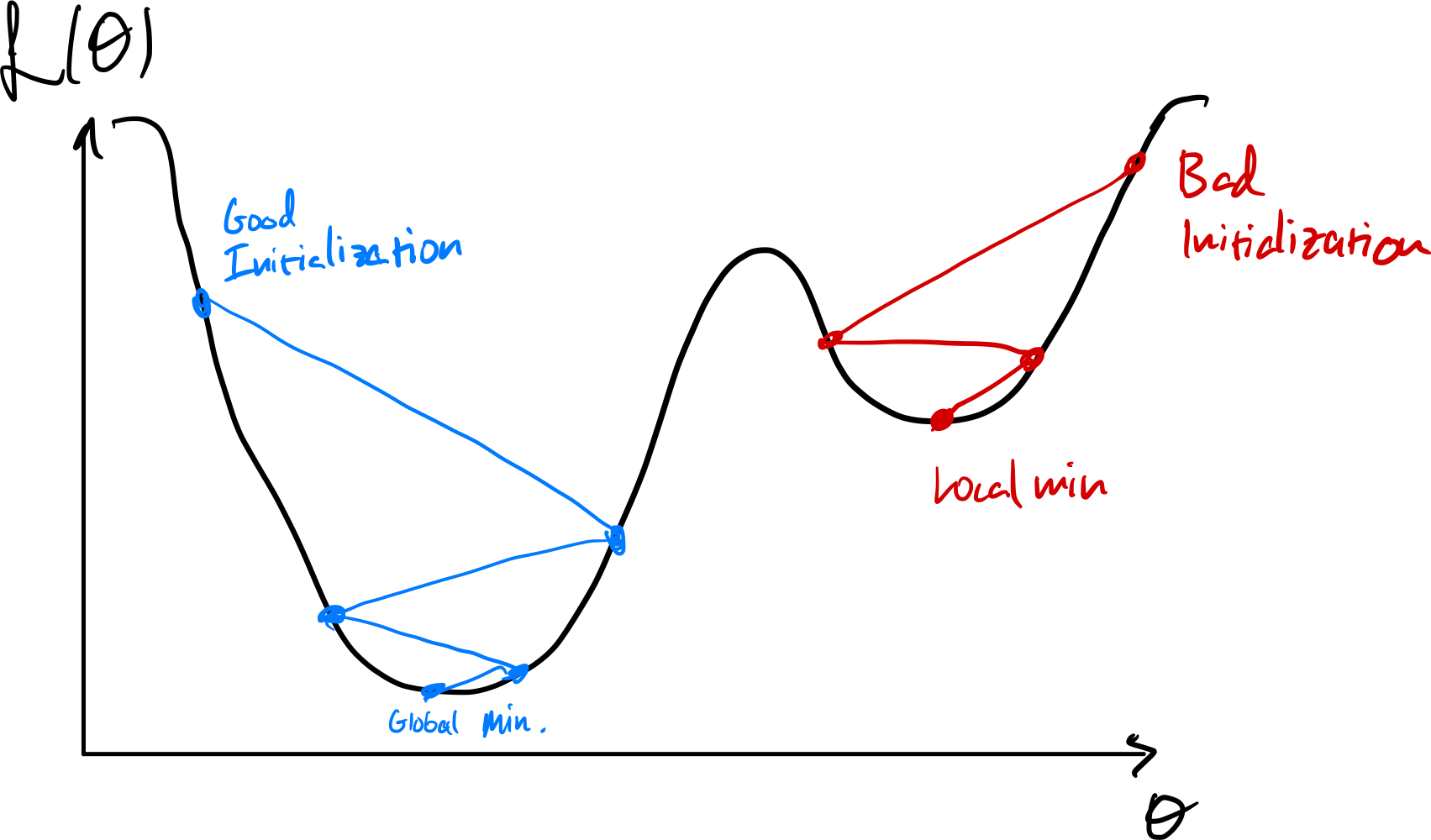
Can use stochastic gradient to get a different loss surface every iteration.

Sensitive to learning rate

- Line search (1D minimization):
Adaptive LR optimizers, e.g. Adam
LR scheduling

Zig-zags in narrow "ravines"

Momentum: Use previous gradients to build "speed" in the common direction and cancel-out oscillations in opposite directions.
BatchNorm: Normalizes activations to zero-mean and unit variance (reduces curvature)
Second-order methods: Use quadratic local approximation of the loss surface, instead of linear.
- Newton's method: $\vec{d}_k=\mat{H}_k^{-1}\vec{g}_k = \nabla^2 L(\vec{\Theta}_k)^{-1}\nabla L(\vec{\Theta}_k)$.
- Quasi-Newton methods which use some estimate of the Hessian based on first-order information (e.g. BFGS).
The back-propagation algorithm¶
All the above optimization methods have a crucial thing in common: They require calculation of gradients of the loss w.r.t. to the parameters.
In practical settings when training neural networks we have many different parameters tensors we would like to update separately. Thus, we require the gradient of the loss w.r.t. each of them.
Back-propagation is an efficient way to calculate these gradients using the chain rule.
We represent the application of a model as a computation graph. For example, a simple linear regression model can be represented as:

Imagine that in this graph we have $N$ variables $\vec{v}^i,\ 1\leq i \leq N$ and functions $f_i$ which compute them from other variables.
The graph is directional, thus assume $\vec{v}^1, \vec{v}^2,\dots,\vec{v}^N$ represents a topological order of the graph (parents before children).
Define also the notation $\delta\vec{v}\triangleq \pderiv{L}{\vec{v}}$.
The forward pass can therefore we written as:
- For $i=1,2,\dots,N$:
- Graph parents of current node: $$\mathcal{P}_i \leftarrow \left\{\vec{v}^j ~\middle\vert~ \vec{v}^j \text{ parent of } \vec{v}^i\right\}$$
- Evaluate function at current node: $$\vec{v}^i\leftarrow f_i(\mathcal{P}_i)$$
And in the backward pass we traverse the graph in reverse and apply the chain rule:
- Set $\delta\vec{v}^N=1$.
- For $i=N,N-1,\dots,1$:
- Graph children of current node: $$\mathcal{C}_i \leftarrow \left\{\vec{v}^j ~\middle\vert~ \vec{v}^j \text{ child of } \vec{v}^i\right\}$$
- Chain rule: $$\delta\vec{v}^i\leftarrow \sum_{\vec{v}^j\in\mathcal{C}_i} \delta\vec{v}^j\pderiv{\vec{v}^j}{\vec{v}^i}$$
Notes:
- The expression $\delta\vec{v}^j\pderiv{\vec{v}^j}{\vec{v}^i}$ is a "vector"-Jacobian product (VJP).
- When a computation node's output is used by more than one other node (more than one child in the graph), we sum the incoming gradients from these children. This again arises directly from the chain rule.
Backpropagation easily lends itself to a modular and efficient implementation.
Modularity:
- Nodes in the computation graph only need to know how to calculate their own derivatives.
- This is then passed to the parent nodes, which can do the same.

Efficiency:
- Only need to compute each $\delta\vec{v}^i$ once.
- No need to construct the Jacobian, instead calculate the VJP directly since that's what we actually need.
Modern automatic-differentiation packages such as PyTorch's autograd utilize exactly these tricks to implement backprop in an extremely powerful way.
Part 1: Custom automatic differentiation with PyTorch¶
We'll now learn how to extend PyTorch's autograd by defining our own custom nodes in the computation graph.
Lets first introduce a cousin of ReLU, the Exponential-Linear Unit (ELU) activation function:
$$ f(z) = \begin{cases} z, & z > 0\\ \alpha \left(e^{z}-1\right) & z \leq 0 \end{cases} $$We'll pretend PyTorch does not include this activation function and implement a custom version ourselves.
import torch
import torch.autograd as autograd
import torchviz
from torch import Tensor
First, we'll implement just the actual computation as a standalone function so that we can reuse it later.
def elu_forward(z: Tensor, alpha: float):
elu_positive = z
elu_negative = alpha * (torch.exp(z) - 1)
elu_output = torch.where(z>0, elu_positive, elu_negative)
return elu_output
A quick visualization to see what it looks like:
z = torch.linspace(-5, 5, steps=1000)
plt.plot(z.numpy(), torch.relu(z).numpy(), label='ReLU(z)', linewidth=5);
plt.plot(z.numpy(), elu_forward(z, alpha=0.5).numpy(), label='ELU(z)', linewidth=2); plt.legend(); plt.grid();

Now we'll wrap it as an nn.Module so that we can use it as a layer in a model.
class ELU(torch.nn.Module):
""" ELU Activation layer """
def __init__(self, alpha: float = 0.1):
super().__init__()
self.alpha = alpha
def forward(self, z: Tensor):
return elu_forward(z, self.alpha)
And as usual, we can look at the resulting computation graph.
elu = ELU(alpha=0.5)
z = torch.tensor([-2., -1, 0, 1, 2, 3], requires_grad=True)
torchviz.make_dot(elu(z), params=dict(z=z))
We can see that the computation graph accurately represents the various basic mathematical operations performed bby our elu_forward function.
But what if we want to define the entire ELU operarion as one node in the graph? This can be useful e.g. for performance reasons.
But how can we accomplish this?
The solution is to use a lower-level PyTorch API, autograd.Function
which allows us to define a function in terms of both it's forwards pass
(the regular output computation), and it's backward pass
(the gradient w.r.t. all it's inputs).
From the PyTorch docs:
Every operation performed on Tensor s creates a new Function object, that performs the computation, and records that it happened. The history is retained in the form of a DAG of functions, with edges denoting data dependencies (input <- output). Then, when backward is called, the graph is processed in the topological ordering, by calling backward() methods of each Function object, and passing returned gradients on to next Function s.
We'll first calculate the simple analytic derivative of the ELU function: $$ \pderiv{f(z)}{z} = f'(z) = \begin{cases} 1, & z > 0\\ \alpha e^{z} & z \leq 0 \end{cases} $$
Next, we need to figure out how to compute the vector-Jacobian product efficiently. Note that for any elementwise operation, $\vec{y}=f(\vec{x}),\ f:\set{R}^n\rightarrow\set{R}^n$, we can write the Jacobian as
$$ \pderiv{\vec{y}}{\vec{x}} = \pmatrix{ \ddots & \vdots & \\ \cdots & \pderiv{y_i}{x_j} & \cdots \\ & \vdots & \ddots\\ } = \pmatrix{ f'(x_1) & & \\ & f'(x_i) & \\ & & f'(x_n)\\ } = \diag\{{f'(\vec{x})}\} $$And it follows that the VJP can be computed simply: $$ \delta \vec{x} = \delta{\vec{y}}\pderiv{\vec{y}}{\vec{x}} = \delta{\vec{y}} \odot f'(\vec{x}). $$
Now, equipped with the expression for the VJP, we can proceed to implement the Function object representing ELU.
class ELUFunction(autograd.Function):
@staticmethod
def forward(ctx, z: Tensor, alpha: float):
elu = elu_forward(z, alpha) # Regular forward pass computation from before
ctx.save_for_backward(z) # Tensors should be saved using this method
ctx.alpha = alpha # other properties can bbe saved like so
return elu
@staticmethod
def backward(ctx, grad_output):
z, = ctx.saved_tensors
alpha = ctx.alpha
# Calculate diagonal of d(elu(z))/dz
grad_positive = torch.ones_like(z)
grad_negative = alpha * torch.exp(z)
# Note: This is not the full Jacobian
grad_elu = torch.where(z>0, grad_positive, grad_negative)
# Gradient of the loss w.r.t. our output
δ_elu = grad_output
# Calcualte δz = d(elu(z))/dz * δ_elu
# Note: elementwise multiplication equivalant to vector-Jacobian product
# print(f'{grad_elu.shape=}, {δ_elu.shape=}')
δz = grad_elu * δ_elu
return δz, None
We can now use this custom Function either directly or as part of a layer.
For example, here's an ELU layer using our custom backward:
class ELUCustom(torch.nn.Module):
""" ELU Layer with a custom backward pass """
def __init__(self, alpha: float = 0.1):
super().__init__()
self.alpha = alpha
def forward(self, z: Tensor):
# Function.apply() invokes the forward pass
return ELUFunction.apply(z, self.alpha)
elu_custom = ELUCustom(alpha=0.5)
z = torch.tensor([-2., -1, 0, 1, 2, 3], requires_grad=True)
torchviz.make_dot(elu_custom(z), params=dict(z=z),)
This only tested the forward pass. Let's now put our custom layer in the context of a larger model and see that we can backprop through it.
elu_mlp = torch.nn.Sequential(
torch.nn.Linear(in_features=512, out_features=1024),
ELUCustom(alpha=0.01),
torch.nn.Linear(in_features=1024, out_features=1024),
ELUCustom(alpha=0.01),
torch.nn.Linear(in_features=1024, out_features=10),
torch.nn.Softmax(dim=1)
)
x = torch.randn(10, 512, requires_grad=True)
torchviz.make_dot(elu_mlp(x).mean(), params=dict(list(elu_mlp.named_parameters()) + [('x', x)]))
Let's run the backward pass and make sure we have gradients on all parameter tensors.
l = torch.sum(elu_mlp(x))
l.backward()
for name, param in elu_mlp.named_parameters():
print(f"{name} {torch.norm(param.grad).item()}")
0.weight 3.0498824798996793e-07 0.bias 1.9646263282879772e-08 2.weight 5.69895860280667e-07 2.bias 5.812371739466471e-08 4.weight 7.324277930820244e-07 4.bias 1.7035910104823415e-07
Part 2: Differentiable Optimization¶
Now we'll tackle a more interesting use-case for defining our custom backward functions: differentiating though an inner (unconstrained) optimization problem.
What if we want to solve an inner optimization problem as part of our model, while the parameters of the inner problem are also optimized by the end-to-end optimization of the entire model?

Training such a network end-to-end means we're trying to find:
$$ \begin{align} \vec{\Theta}^\ast &= \arg\min_{\vec{\Theta}} \E[(\vec{x},\vec{y})\sim D]{\mathcal{L}(\vec{y}, \hat{\vec{y}})}\\ &= \arg\min_{\vec{\Theta}} \E[(\vec{x},\vec{y})\sim D]{ \mathcal{L}(\vec{y}, \arg\min_{\vec{y}} f(\vec{y}, h_{\vec{\Theta}}(\vec{x}) ) } \end{align} $$This type of setting is also known as a bi-level optimization problem.
From the perspective of the inner problem, $\vec{z}$ is a "fixed" parameter.
However, from the perspective of end-to-end training, we're optimizing $\vec{\Theta}$ in order to reduce the final loss.
Therefore, we can view this as learning to parameterize the inner task.
What do we need in order to train such a model end-to-end?
As usual, we must find a way to calculate a VJP, in this case: $$ \delta \vec{z} = \pderiv{\hat{\vec{y}}}{\vec{z}}\ \delta\hat{\vec{y}}. $$
Assume that $\vec{y}=\arg\min_{\vec{y}'}f(\vec{y}', \vec{z})$.
Since $\vec{y}$ is a minimizer of the function $f$, the necessary optimality condition must hold: $$\nabla_{y}f(y, z)=0.$$
If we then perturb $\vec{z}$ by $d\vec{z}$, we'll get a slightly different minimizer, $\vec{y}+d\vec{y}$. Thus also,
$$\nabla_{y}f(y+dy, z+dz)=0.$$We can take a first-order Taylor expansion of $\nabla_{y}f$ around the point $(y, z)$:
$$ \nabla_{y}f(y+dy, z+dz) \approx \nabla_{y}f(y, z) + \nabla^{2}_{yy}f(y,z)dy + \nabla^{2}_{yz}f(y, z)dz = 0. $$Since $\nabla_{y}f(y, z)=0$, we rearrange to obtain:
$$ \nabla^{2}_{yy}f(y,z)dy = -\nabla^{2}_{yz}f(y, z)dz. $$We'll denote the Hessians as $\mat{K}=\nabla^{2}_{yy}f(y,z)$ and $\mat{R}=\nabla^{2}_{yz}f(y, z)$. We then obtain,
$$ \mat{K}d\vec{y}=-\mat{R}d\vec{z}\Longrightarrow d\vec{y}=-\mat{K}^{-1}\mat{R}d\vec{z}. $$The above equation means that we have found a linear relationship between the change in the function value, $d\vec{y}$ and the change in the argument value, $d\vec{z}$. This linear relationship must be, by definition, related to the gradient of $\vec{y}$ w.r.t. $\vec{z}$.
Writing the above as an inner product, we have $$d\vec{y}=\ip{\mattr{R}\mat{K^{-T}}}{d\vec{z}}{}.$$
Note that $\mat{K}$ is a Hessian, therefore symmetric and we can drop the transpose.
Finally, by the "outer" definition of the gradient we see that $$\pderiv{\vec{y}}{\vec{z}}=\mattr{R}\mat{K^{-1}}.$$
Now back to our VJP: we need $$ \delta \vec{z} = \pderiv{\vec{y}}{\vec{z}} \delta\vec{y} =\mattr{R}\mat{K^{-1}}\delta\vec{y}. $$
We'll do the calculation in two steps:
- Calculate $\delta\vec{u}=\mat{K}^{-1}\delta\vec{y}$: Equivalent to solving the linear system $\mat{K}\delta\vec{u}=\delta\vec{y}$.
- Calculate $\delta\vec{z} = -\mat{R}^\top \delta\vec{u}$.
Finally, based on this, we have a way to implement such an inner-optimization layer:
Forward pass: Compute the optimal solution of the inner problem, either with a some solver or even a closed-form expression.
Backward pass: Calculate $\delta\vec{z}$ using the two-step procedure described above.
Note that it's also possible to develop these expression for the constrained optimization case, by using the KKT conditions where we used the unconstrained optimality condition.
Implementation¶
Before implementing the argmin layer, we need some required helpers.
First, let's implement a helper to calculate an approximated least-squares solution to a linear system of equations $\mat{A}\vec{x}=\vec{b}$.
The built-in torch.solve() only supports a square matrix A.
def solve_ls(A: Tensor, b: Tensor, abs: float = 1e-6, rel: float = 1e-6) -> Tensor:
# Solves the system A x = b in a least-squares sense using SVD, and returns x
U, S, V = torch.svd(A)
th = max(rel * S[0].item(), abs)
# Clip singular values
Sinv = torch.where(S >= th, 1.0 / S, torch.zeros_like(S))
return V @ torch.diag(Sinv) @ (U.transpose(1, 0) @ b)
Quick test for solve:
from sklearn.datasets import make_regression
from sklearn.preprocessing import StandardScaler
dtype = torch.float64
torch.set_default_dtype(dtype)
# Create a simple regression problem
N, D = 1000, 20
X, y, w_gt = make_regression(
n_samples=N, n_features=D, coef=True, random_state=42, bias=10, noise=1,
)
X = StandardScaler().fit_transform(X)
X, y, w_gt = [ torch.from_numpy(t).to(dtype) for t in [X, y, w_gt] ]
# Solve it and check the solution is close to the ground-truth
w_hat = solve_ls(X, y)
assert torch.allclose(w_hat, w_gt, rtol=0.1, atol=0.1)
Notice that in the formulation we used, we considered only one variables vector, $\vec{y}$, one parameters vector, $\vec{z}$, and moreover we treated them both as 1d vectors.
In practice, however, when implementing deep neural networks, we deal with many different parameters tensors, virtually all of which high-dimensional.
In this tutorial, we'll deal with the case of one variable tensor (of any shape) and any number of parameter tensors (of any shape). It's simple to use the approach here to extend to multiple variables as well.
def flatten(*z: Tensor):
# Flattens a sequence of tensors into one "long" tensor of shape (N,)
# Note: cat & reshape maintain differentiability!
flat_z = torch.cat([z_.reshape(-1) for z_ in z], dim=0)
return flat_z
def unflatten_like(t_flat: Tensor, *z: Tensor):
# Un-flattens a "long" tensor into a sequence of multiple tensors of arbitrary shape
t_flat = t_flat.reshape(-1) # make sure it's 1d
ts = []
offset = 0
for z_ in z:
numel = z_.numel()
ts.append(
t_flat[offset:offset+numel].reshape_as(z_)
)
offset += numel
assert offset == t_flat.numel()
return tuple(ts)
Quick test for flatten/unflatten:
t1, t2 = torch.randn(3, 5), torch.randn(2, 4)
t_flat = flatten(t1, t2)
assert t_flat.shape == (t1.numel() + t2.numel(),)
t1_, t2_ = unflatten_like(t_flat, t1, t2)
assert torch.allclose(t1, t1_)
assert torch.allclose(t2, t2_)
Now, finally, we're equipped to write an autograd.Function
which implements differentiable optimization!
Let's start with the forward pass. Here we simply need to solve an unconstrained optimization problem specified in terms of an objective function, variables (just one supported) and parameters.
We'll use the LBFGS algorithm (a quasi-Newton method as seen in the lectures) as a general purpose solver.
from torch.optim import LBFGS
def argmin_forward(ctx, obj_fun, y, *z):
# Note: solving for y, treating the z's as constants
optimizer = LBFGS(params=(y,), lr=0.9, max_iter=1000)
# Closure for LBFGS which evaluates the loss and calcualtes
# gradients of the variables.
def _optimizer_step():
# zero gradients
y.grad = torch.zeros_like(y)
# evaluate loss
f = obj_fun(y, *z)
# Calculate gradients
# Note: not calling backward() because we don't want to compute
# gradients for anything except y
δy = autograd.grad(f, (y,), create_graph=False)[0]
y.grad += δy
return f
# Solve the optimization problem - will evaluate closure multiple times
f_min = optimizer.step(_optimizer_step,)
y_argmin = y # Note: y was modified in place
ctx.save_for_backward(y_argmin, *z)
ctx.obj_fun = obj_fun
return y_argmin
Now the backward pass. Here we use the two-step procedure shown above, to calculate $\delta\vec{z}$.
We'll need to calculate the Hessians $\mat{K}=\nabla^{2}_{yy}f(y,z)$ and $\mat{R}=\nabla^{2}_{yz}f(y, z)$, but luckily autograd can calculate this (by a second automatic differentiation).
The only complication is the shapes of $\vec{y}$ and $\vec{z}$, but we'll flatten them with our helpers.
from torch.autograd.functional import hessian
def argmin_backward(ctx, grad_output):
y_argmin, *z = ctx.saved_tensors
obj_fun = ctx.obj_fun
flat_y = flatten(y_argmin)
flat_z = flatten(*z)
# Wrap objective function so that we can call it with flat tensors
def obj_fun_flat(flat_y, flat_z):
y = unflatten_like(flat_y, y_argmin)
zs = unflatten_like(flat_z, *z)
return obj_fun(*y, *zs)
# Compute the Hessians on flattened y and z
H = hessian(obj_fun_flat, inputs=(flat_y, flat_z), create_graph=False)
Hyy = K = H[0][0]
Hyz = R = H[0][1]
# Now we need to calculate δz = -R^T K^-1 δy
# 1. Solve system for δu: K δu = δy
δy = grad_output
δy = torch.reshape(δy, (-1, 1))
δu = solve_ls(K, δy) # solve_ls(A, B) solves A X = B
# 2. Calculate δz = -R^T δu
δz_flat = -R.transpose(0, 1) @ δu
# Extract gradient of each individual z
δz = unflatten_like(δz_flat, *z)
δy = torch.reshape(δy, y_argmin.shape)
return None, δy, *δz
We now wrap these functions in a autograd.Function class:
class ArgMinFunction(autograd.Function):
@staticmethod
def forward(ctx, obj_fun, y, *z):
return argmin_forward(ctx, obj_fun, y, *z)
@staticmethod
def backward(ctx, grad_output):
return argmin_backward(ctx, grad_output)
Let's run a quick test for argmin_forward: Can we solve the simple regression problem from before?
# Define a simple linear regression objective with l1 and l2 regularization
# (just to test more than one z)
def obj_fun(w: Tensor, l1: Tensor, l2: Tensor):
loss = torch.mean((X @ w - y)**2)
reg1 = l1 * torch.mean(torch.abs(w))
reg2 = l2 * torch.mean(w ** 2)
return torch.sum(loss + reg1 + reg2)
w = torch.randn_like(w_gt, requires_grad=True)
l1 = torch.randn(1, 1, requires_grad=True)
l2 = torch.randn(1, 1, requires_grad=True)
# Function.apply() invokes the forward pass
w_hat_argmin = ArgMinFunction.apply(obj_fun, w, l1, l2)
assert torch.allclose(w_hat_argmin, w_gt, rtol=0.2, atol=3)
w_gt-w_hat_argmin
tensor([ 3.3349, 9.3753, 0.1935, -0.2837, 4.7919, 0.1489, 2.9468, 0.0318,
0.3177, -0.0361, 0.6610, 1.7553, -0.0704, 0.5406, 0.1594, 1.7986,
0.5532, 5.1842, -0.1253, -0.0440], grad_fn=<SubBackward0>)
Quick test for argmin_backward: Do we get gradients on our $\vec{z}$s ?
loss = torch.mean(w_hat_argmin)
print(f'{loss=}\n')
# Before backward: z (l1 & l2) gradients should be None
print(f'{w.grad=}')
print(f'{l1.grad=}')
print(f'{l2.grad=}\n')
loss.backward()
print(f'{w.grad=}')
print(f'{l1.grad=}')
print(f'{l2.grad=}')
loss=tensor(24.1708, grad_fn=<MeanBackward0>)
w.grad=tensor([-6.5928e-06, 5.7268e-06, -4.9958e-06, 3.5084e-06, 9.8241e-06,
-3.1058e-06, 6.1233e-07, -2.9807e-06, 3.5734e-06, -3.0825e-06,
4.5685e-06, 4.8643e-07, -2.8262e-07, -4.6700e-07, -2.2415e-08,
1.5638e-06, -6.6559e-06, 6.6045e-07, 4.7814e-06, 8.2119e-08])
l1.grad=None
l2.grad=None
w.grad=tensor([0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500,
0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500, 0.0500,
0.0500, 0.0500])
l1.grad=tensor([[0.]])
l2.grad=tensor([[0.]])
Example¶
Let's demonstrate how to use our ArgMinFunction in the context of a model.
We'll tackle the task of time-series prediction, by applying linear regression on a learned, non-linear representation of the inputs.
We'll implement the following model:

Notes:
- The encoder and decoder will be simple 1D CNNs.
- The encoder calculates some non-linear embedding of the input while the decoder maps an embedding back to the input space.
- The predictor applies linear regression to try fit optimal weights for predict the last part of the embedding, $\vec{Y}_e$ from the first part, $\vec{X}_e$ ("post-diction"):
- Postdiction: $\vec{w}^\ast=\arg\min_{\vec{w}} \norm{\vec{X}_e\vec{w}-\vec{Y}_e}^2+\lambda\norm{\vec{w}}^2$
- Prediction: $\hat{\vec{Y}}_e=\vec{Z}_e\vec{w}^\ast$ where $\vec{Z}_e$ is the last part of the embedding with the same length as $\vec{X}_e$.
Let's load some data: We'll use a open dataset from Kaggle, containing 12 years of daily stock price data from equities included in the Dow Jones Industrial Average (DJIA).
You can obtain this dataset here.
import pandas as pd
import numpy as np
import matplotlib.dates as mdates
from datetime import datetime
df = pd.read_csv("DJIA_30/all_stocks_2006-01-01_to_2018-01-01.csv.gz", compression='gzip')
df.shape
(93612, 7)
# Plot some stocks
stock_names = ["AAPL", "GOOGL", "MSFT", "AMZN"]
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.xaxis.set_major_locator(mdates.YearLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
for stock_name in stock_names:
df_stock = df[df['Name'] == stock_name]
df_stock_dates = [datetime.strptime(d,'%Y-%m-%d').date() for d in df_stock['Date']]
ax.plot(df_stock_dates, df_stock['Close'], label=stock_name)
ax.set_ylabel('Close Price ($)'); ax.legend();
<matplotlib.legend.Legend at 0x7f89428ea610>

Let's do some minimal processing to make the data useable:
- Split the data into segments of a fixed number of days.
- Split each secment into a BASE ($\vec{X}$) and a TARGET ($\vec{Y}$).
- Split all segments into a training and test set.
SEG_LEN = 40
SEG_BASE = 30
SEG_TARGET = SEG_LEN - SEG_BASE
# Filter out only selected stocks
df = df[df['Name'].isin(stock_names)]
# Split into segments of SEG_LEN days
X = torch.tensor(df['Close'].values, dtype=dtype)
X = X[0:SEG_LEN*(X.shape[0]//SEG_LEN)]
X = torch.reshape(X, (-1, 1, SEG_LEN)) # adding channel dimension
# Train-test split
test_ratio = 0.3
N = X.shape[0]
N_train = int(N * (1-test_ratio))
idxs = torch.randperm(X.shape[0],)
X_train, X_test = X[idxs[:N_train]], X[idxs[N_train:]]
# Split out target segment at the end
X_train, Y_train = X_train[..., :SEG_BASE], X_train[..., SEG_BASE:]
X_test, Y_test = X_test[..., :SEG_BASE], X_test[..., SEG_BASE:]
print(f"{X_train.shape=}\n{Y_train.shape=}\n\n")
print(f"{X_test.shape=}\n{Y_test.shape=}")
X_train.shape=torch.Size([210, 1, 30]) Y_train.shape=torch.Size([210, 1, 10]) X_test.shape=torch.Size([91, 1, 30]) Y_test.shape=torch.Size([91, 1, 10])
We can plot some random BASE and TARGET pairs.
np.random.seed(42)
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
idx_perm = np.random.permutation(range(N_train))
for i in range(10):
ax.plot(range(SEG_BASE), X_train[idx_perm[i], 0, :])
ax.plot(range(SEG_BASE, SEG_LEN), Y_train[idx_perm[i], 0, :])
ax.axvline(x=SEG_BASE, color='k', linestyle=":", linewidth="5")
ax.grid();

We'll expose the processed data to PyTorch DalaLoaders via the TensorDataset class.
from torch.utils.data import TensorDataset, DataLoader
BATCH_SIZE = 8
dl_train, dl_test = [
DataLoader(TensorDataset(X, Y), batch_size=BATCH_SIZE, shuffle=True)
for X, Y in [(X_train, Y_train), (X_test, Y_test)]
]
Both the encoder and decoder will use the same model, a 1D CNN.
class EncDec(torch.nn.Module):
def __init__(self, channels=[1, 4, 8], out_nl=True):
super().__init__()
layers = []
channel_pairs = zip(channels[:-1], channels[1:])
for in_channels, out_channels in channel_pairs:
layers.extend([
torch.nn.Conv1d(
in_channels, out_channels, kernel_size=5, padding=2, bias=True
),
ELUCustom(alpha=0.5),
])
if not out_nl:
layers = layers[:-1]
self.layers = torch.nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
enc = EncDec(channels=[1, 4, 8], out_nl=True)
enc
EncDec(
(layers): Sequential(
(0): Conv1d(1, 4, kernel_size=(5,), stride=(1,), padding=(2,))
(1): ELUCustom()
(2): Conv1d(4, 8, kernel_size=(5,), stride=(1,), padding=(2,))
(3): ELUCustom()
)
)
Test encoder forward pass:
x0, y0 = next(iter(dl_train))
print(f"{x0.shape=}\n")
print(f"{enc(x0).shape=}\n")
x0.shape=torch.Size([8, 1, 30]) enc(x0).shape=torch.Size([8, 8, 30])
Now, our regression layer will use the custom ArgMinFunction to solve an optimization problem during the forward pass.
class PredictorArgMinLayer(torch.nn.Module):
def __init__(self, in_features: int, out_features: int):
super().__init__()
self.prediction_len = in_features - out_features
self.prediction_target_len = out_features
# We'll train both W and lambda
self.w = torch.nn.Parameter(torch.randn(
self.prediction_target_len, self.prediction_len, requires_grad=True,
))
self.reg_lambda = torch.nn.Parameter(torch.tensor([1.], requires_grad=True))
@staticmethod
def obj_fun(w: Tensor, x: Tensor, y: Tensor, reg_lambda: Tensor):
# Objective function performing linear regression
xw = torch.matmul(x, w.T)
loss = torch.mean((xw - y)**2)
reg = reg_lambda * torch.mean(w ** 2)
return torch.sum(loss + reg)
def forward(self, x):
# Postdiction
# X = | ------ X_e ------ | -- Y_e -- |
x_post = x[..., :self.prediction_len] # X_e
y_post = x[..., self.prediction_len:] # Y_e
w_opt = ArgMinFunction.apply(self.obj_fun, self.w, x_post, y_post, self.reg_lambda)
# Prediction
# X = | --------- | ------ Z_e ------ |
x_pred = x[..., -self.prediction_len:] # Z_e in the text
return torch.matmul(x_pred, w_opt.T)
Finally, we'll create a model containing the full architecture of encoder, predictor and decoder.
from typing import List
class EncPredictorDec(torch.nn.Module):
def __init__(
self, in_features: int, postdiction_length: int,
encoder_channels: List[int], decoder_channels: List[int]=None
):
super().__init__()
if decoder_channels is None:
decoder_channels = list(reversed(encoder_channels))
self.enc = EncDec(encoder_channels, out_nl=True)
self.dec = EncDec(decoder_channels, out_nl=False)
self.pred = PredictorArgMinLayer(in_features, postdiction_length)
self.postdiction_length = postdiction_length
def forward(self, x: Tensor):
# Calculate embeding
x_emb = self.enc(x)
# Postdict then predict
y_hat_emb = self.pred(x_emb)
# Decode back to input space
y_hat = self.dec(y_hat_emb)
return y_hat
Time to train! Notes:
- Here we define the "outer" optimizer which performs the end-to-end optimization.
- We'll demonstrate how to employ simple a simple decaying learning rate schedule.
torch.manual_seed(42)
model = EncPredictorDec(
in_features=SEG_BASE, postdiction_length=SEG_TARGET,
encoder_channels=[1, 4, 8, 16]
)
loss_fn = torch.nn.MSELoss()
# End-to-end optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=0.01, eps=1e-6)
# Decay learning rate each epoch
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
from tqdm import tqdm
def run_epoch(model, dl, epoch_idx, max_batches, train=True):
desc = f'Epoch #{epoch_idx:02d}: {"Training" if train else "Evaluating"} '
losses = []
pbar = tqdm(dl, desc=desc)
for i, (x, y) in enumerate(pbar):
y_pred = model(x)
loss = loss_fn(y, y_pred)
if train:
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
pbar.desc = desc + f"[loss={loss.item():.3f}]"
if max_batches and i >= max_batches:
break
pbar.desc = desc + f"avg. loss = {np.mean(losses)}"
pbar.update()
num_epochs = 1
max_batches = None
for epoch in range(num_epochs):
run_epoch(model, dl_train, epoch, max_batches, train=True)
with torch.no_grad():
run_epoch(model, dl_test, epoch, max_batches, train=False)
scheduler.step()
Epoch #00: Training [loss=103.402]: 100%|██████████| 27/27 [00:16<00:00, 1.68it/s] Epoch #00: Evaluating [loss=326759.975]: 100%|██████████| 12/12 [00:07<00:00, 1.65it/s]
Thanks!¶
Image credits
Some images in this tutorial were taken and/or adapted from:
- Dr. Roger Grosse, UToronto, cs321
- Fundamentals of Deep Learning, Nikhil Buduma, Oreilly 2017