
Máster Propio en Data Science y Big Data (IV Edición)
Arquitecturas y Paradigmas para Ciencia del Dato (APCD)
Técnicas de obtención de datos
Instructor¶

PhD, Estudios Hispánicos y Humanidades Digitales, University of Western Ontario, Canada
Máster en Inteligencia Artificial, Universidad de Sevilla, España
Ex-Ingeniero de Investigación en la Stanford University, California
Ex-Director Técnico del laboratorio de investigación CulturePlex Lab en la University of Western Ontario, Canada
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Introducción¶
La recolección de datos es el proceso de recopilación y medición de la información sobre un conjunto de variables especı́ficas.
Aquı́ surge una pregunta, ¿necesitamos definir un modelo de datos para recolectar los datos asociados?
El primer paso es saber qué se quiere obtener como resultado y qué variables nos harı́an falta.
Introducción¶
Existen infinidad de opciones para recolectar datos dependiendo del proyecto y de la disciplina en la que trabajemos. Hoy en dı́a hay un punto común a todos estos procesos (y cada vez más necesario), es la digitalización de la información.
Por dar una definición breve y simple, podrı́amos llamar digitalización al proceso de transformación de información analógica a formato digital. Esto facilita tareas como el almacenamiento, consulta, gestión, etc.
Introducción¶
Partiendo del ámbito de la ciencia de datos, vamos a ver cuatro tipos de procedimientos en cuanto a recolección u obtención de datos se refiere:
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- APIs
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Repositorios¶
Un repositorio o depósito es un sitio centralizado donde se almacena y mantiene información digital, habitualmente bases de datos o archivos informáticos. Los datos almacenados en un repositorio pueden distribuirse a través de una red informática (Internet) o de un medio fı́sico.
Nosotros, principalmente, usaremos los repositorios para dos tareas:
- Para almacenar y gestionar el código de nuestro proyecto
- Para almacenar, descargar y gestionar los conjuntos de datos con los que trabajamos
- Para facilitar el intercambio de datos
Repositorios¶
- Pueden ser de acceso público o estar protegidos y necesitar de una autentificación previa
- Los repositorios más conocidos son los de carácter académico (investigación) e institucional (datos abiertos)
- Los repositorios suelen contar con sistemas de respaldo y mantenimiento preventivo y correctivo (tolerancia a fallos)
Formatos¶
- Generales: CSV, TXT, WORD, JSON, XML, XLS
- Optimizados: HDF5, Parquet, Arrow
- Semánticos (LOD, SPARQL): RDF, Turtle, N3, JSON-LD
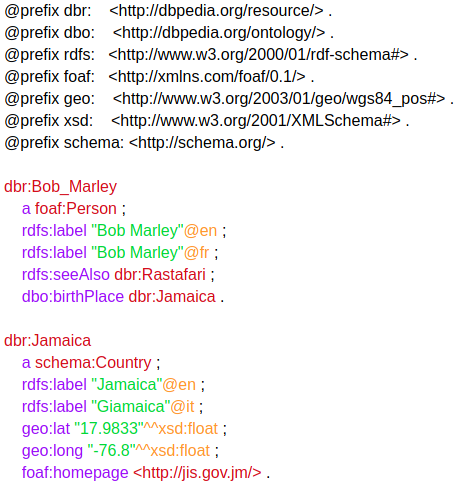
Repositorios de datos¶
Repositorios de datos abiertos enlazados (LOD)¶
Repositorios de código¶
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Scraping¶
Web scraping es una técnica que utiliza programas software para extraer información de sitios web.
Usualmente, estos programas simulan la navegación de un humano en Internet ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.
Scraping¶
Como curiosidad: un concepto muy relacionado con el web scraping es la indexación que se produce en Internet. La indexación se lleva a cabo por programas (llamados spiders o crawlers) que rastrean y navegan automáticamente por toda la web. Esta técnica es la que adoptan la mayorı́a de los motores de búsqueda.
Desde nuestro punto de vista, el web scraping se enfoca más en la transformación de datos sin estructura en la web en datos estructurados que pueden ser almacenados y analizados. Un campo en el que esta técnica es muy utilizada es el periodismo de datos (social media).
Scraping¶
Para llevar a cabo técnicas de scraping tenemos que tener en cuenta, esencialmente, dos puntos fundamentales:
- Acceso al código HTML de la página (hay muchas formas de conseguir esto)
- Un lenguaje de programación para obtener los datos que nos interesan
- En nuestro caso, usaremos la consola de desarrollo de Firefox/Google Chrome y Python.
Scraping¶

Scraping¶

Scraping¶

Scraping - Uniform Resource Locator (URL)¶
protocol://hostname:port/path-and-file-name
- Protocol: HTTP, FTP, telnet, etc.
- Hostname: DNS domain name (e.g., www.nowhere123.com) o dirección IP (e.g., 192.128.1.2).
- Port: Puerto TCP de escucha.
- Path: Ruta del recurso en el servidor.
Ejemplo: http://www.nowhere123.com/docs/index.html
Scraping - Uniform Resource Identifier (URI)¶
Una URI es una forma más general de URL. Añade un par de campos más.
protocol://hostname:port/path-and-file-name?query#fragment
- Fragment: Porción dentro del recurso.
- Query: Parámetros de la petición, e.g.,
name=Ana&age=30
Ejemplo:
http://www.nowhere123.com/docs/index.html?order=1#table1
Scraping - HTTP Request¶
GET /docs/index.html HTTP/1.1
Host: www.nowhere123.com
Accept: image/gif, image/jpeg, */*
Accept-Language: en-us
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
Scraping - HTTP Request¶

Scraping - HTTP Request Methods¶
- GET: Un cliente puede utilizar la petición GET para obtener un recurso web del servidor.
- HEAD: Un cliente puede utilizar la solicitud HEAD para obtener el encabezado que habría obtenido una solicitud GET. Dado que la cabecera contiene la última fecha modificada de los datos, se puede utilizar para comparar con la copia de la caché local.
- POST: Se utiliza para enviar datos al servidor web.
- PUT: Pide al servidor que almacene los datos.
- DELETE: Pide al servidor que borre los datos.
Scraping - HTTP Response¶
HTTP/1.1 200 OK
Date: Sun, 18 Oct 2009 08:56:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Sat, 20 Nov 2004 07:16:26 GMT
ETag: "10000000565a5-2c-3e94b66c2e680"
Accept-Ranges: bytes
Content-Length: 44
Connection: close
Content-Type: text/html
<html><body><h1>It works!</h1></body></html>
Scraping - HTTP Response¶

Scraping - HTTP Response Status Codes¶
- 1xx (Informativo): Solicitud recibida, el servidor continúa el proceso.
- 2xx (Éxito): La solicitud fue recibida, comprendida, aceptada y atendida con éxito.
- 3xx (Redirección): Se deben tomar más medidas para completar la solicitud.
- 4xx (Error de cliente): La petición contiene una sintaxis errónea o no puede ser entendida.
- 5xx (Error del servidor): El servidor no cumplió con una petición aparentemente válida.
Scraping - HTTP Response Status Codes¶
Algunos de los códigos de estado más comunes son:
- 100 Continuar: El servidor recibió la solicitud y en el proceso de dar la respuesta.
- 200 OK: La solicitud se ha cumplido.
- 301 Movido permanentemente.
- 302 Encontrado y redirigido (o Movido temporalmente).
Scraping - HTTP Response Status Codes¶
Algunos de los códigos de estado más comunes son:
- 400 Bad Request: El servidor no pudo interpretar o entender la petición, probablemente un error de sintaxis en el mensaje de petición.
- 401 Se requiere autenticación.
- 403 Prohibido.
- 404 No encontrado.
Scraping - HTTP Response Status Codes¶
Algunos de los códigos de estado más comunes son:
- 500 Error interno del servidor: El servidor está confundido, a menudo causado por un error en el programa del lado del servidor que responde a la petición.
- 502 Bad Gateway: Proxy o Gateway indica que recibe una mala respuesta del servidor de entrada.
- 503 Servicio no disponible: El servidor no puede responder debido a sobrecargas o mantenimiento. El cliente puede volver a intentarlo más tarde.
### Scrapping - HTTP
!!pip install requests
import requests
response = requests.get("https://httpbin.org/html")
print(response.status_code, response.ok)
print(response.headers)
### Scrapping - HTTP
print(response.text)
Ejercicio
Escriba una función, `status(urls)`, que dada una lista de de URLs en `urls`, devuelve un diccionario usando como claves los códigos de estado de las peticiones HTTP y como valores la lista correspondiente de URLs que lo producen.
Por ejemplo:
urls = [
"https://httpbin.org/",
"https://httpbin.org/404",
"https://www.eltiempo.es/",
"https://www.pixar.com/cer890h76yt89j768y6590g43e9f4efv54er",
]
status(urls)
Debería producir
{200: ['https://httpbin.org/', 'https://www.eltiempo.es/'],
404: ['https://httpbin.org/404', 'https://www.pixar.com/cer890h76yt89j768y6590g43e9f4efv54er']}
urls = [
"https://httpbin.org/",
"https://httpbin.org/404",
"https://www.eltiempo.es/",
"https://www.pixar.com/cer890h76yt89j768y6590g43e9f4efv54er",
]
def status(urls):
# Escriba su código aquí
pass
status(urls)
{200: ['https://httpbin.org/', 'https://www.eltiempo.es/'],
404: ['https://httpbin.org/404',
'https://www.pixar.com/cer890h76yt89j768y6590g43e9f4efv54er']}
Ejercicio
Escriba el código necesario para descargar el contenido alojado en `https://httpbin.org/html` y devolver las 10 palabras más comunes y su frecuencia absoluta (total de apariciones)
url = "https://httpbin.org/html"
# Escriba aquí su solución
[('', 42),
('the', 34),
('and', 25),
('of', 22),
('to', 17),
('his', 14),
('a', 14),
('in', 11),
('had', 8),
('old', 6)]
Scraping - HTML¶
Idealmente, todas las páginas web siguen una estructura bien definida semánticamente de acuerdo al Document Object Model (DOM). Esto nos permitirı́a extraer datos utilizando reglas como encontrar el elemento <p> cuyo id es "subject" y devolver el "texto" que contiene.
En el mundo real, el código HTML de una web no tiene por qué estar bien formado y anotado. Esto significa que necesitaremos estudiar la estructura de una web antes de extraer información de la misma.
Scraping - HTML¶
<html>
<head>
<title>Mi web</title>
</head>
<body>
<p id="author">Javier de la Rosa</p>
<p id="subject">Ciencia de Datos</p>
</body>
</html>
Scraping - HTML¶
<html>
<head>
<title>Mi web</title>
</head>
<body>
<p>Javier de la Rosa</p>
<p>Ciencia de datos</p>
<p>Noviembre 2019</p>
</body>
</html>
Scraping - robots.txt¶
El archivo robots.txt es un documento que define qué partes de un dominio pueden ser analizadas por los rastreadores de los motores de búsqueda y proporciona un enlace al XML-sitemap (ver ejemplo de sitemap).
# robots.txt for http://www.example.com/
User-agent: UniversalRobot/1.0
User-agent: GoogleBot
Disallow: /sources/dtd/
User-agent: *
Disallow: /nonsense/
Disallow: /temp/
Disallow: /newsticker.shtml
Ejemplo real: https://www.google.com/robots.txt
Scraping con Python¶
- BeautifulSoup, encargada de crear un árbol con los elementos que componen una web y facilitar su acceso
- requests para facilitar la ejecución de peticiones a servidores desde código Python. Aunque nativamente se puede usar urllib3.
- html5lib, para mejorar el tratamiento de los elementos HTML
!!pip install beautifulsoup4
!!pip install requests requests-html
!!pip install html5lib
### Scraping - requests vs urllib3
import requests
print("requests:",
requests.get("http://httpbin.org/ip").json()
)
import urllib3
import json
http = urllib3.PoolManager()
response = http.request('GET', 'http://httpbin.org/ip')
print("urllib3: ",
json.loads(response.data.decode('utf-8'))
)
### Scraping con Python
# elpais.com example - First part
from bs4 import BeautifulSoup
import requests
url = "https://elpais.com/"
html = requests.get(url).text
soup = BeautifulSoup(html, 'html5lib')
links = []
all_news_lines = soup.select('.articulo-titulo')
for line in all_news_lines:
link = line.find('a')
links.append(link)
links[:3]
### Scraping con Python
# elpais.com example - Second part
news = []
for link in links:
new = link.text # link.get("title")
news.append(new)
news[:5]
Selectores¶
- Selector de tipo o etiqueta (todos)
p
p, span
- Selector descendente (dentro)
p span
h1 span
<p>Algo de texto <span>especial</span>!</p>
Selectores (cont.)¶
- Selectores de ID
#destacado
<p id="destacado">Segundo párrafo</p>
- Selector de clase
p.destacado
<p class="destacado">Lorem ipsum dolor sit amet...</p>
Selectores (cont.)¶
- Combinación de selectores básicos
.aviso .especial
<p class="aviso">Algo de texto <span class="especial">especial</span>!</p>
- Hijos directos
td > span
<td><span>Texto</span></td>
Selectores (cont.)¶
- Precedencia directa (sin parentesco)
p + a
<p>Paragraph y</p><a href="#anchor">enlace</a>
- Posicionales
p:first span:last a:n-child(2)
<p>Para 1 <span>Span 1</span><span>Span 2 <a>Enlace 1</a> <a>Enlace 2</a></span></p> <p>Para 2</p>
Ejercicio
Escriba las expresiones de selección para los siguientes casos:
- Todos los
divdel documento. - Todos los
pya. - Todos los
adescedientes dep. - Todos los elementos de las clase
nombreClase. - Los
divde las clasenombreClase.
Scraping - Ejemplo: 43º Congreso de los EEUU¶
<table border="1" cellspacing="2" cellpadding="3">
<tbody>
<tr>
<th>Member Name</th>
<th>Birth-Death</th>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000035">ADAMS, George Madison</a></td>
<td>1837-1920</td>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000074">ALBERT, William Julian</a></td>
<td>1816-1879</td>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000077">ALBRIGHT, Charles</a></td>
<td>1830-1880</td>
</tr>
</tbody>
</table>
### Scraping - Ejemplo: 43º Congreso de los EEUU
html = """<table border="1" cellspacing="2" cellpadding="3">
<tbody>
<tr>
<th>Member Name</th>
<th>Birth-Death</th>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000035">ADAMS, George Madison</a></td>
<td>1837-1920</td>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000074">ALBERT, William Julian</a></td>
<td>1816-1879</td>
</tr>
<tr>
<td><a href="http://bioguide.congress.gov/scripts/biodisplay.pl?index=A000077">ALBRIGHT, Charles</a></td>
<td>1830-1880</td>
</tr>
</tbody>
</table>"""
### Scraping - Ejemplo: 43º Congreso de los EEUU
soup = BeautifulSoup(html)
print(soup.prettify())
### Scraping - Ejemplo: 43º Congreso de los EEUU
links = soup.find_all('a')
for link in links:
names = link.text
full_link = link.get('href')
print([names, full_link])
### Scraping - Ejemplo: 43º Congreso de los EEUU
import csv
with open("congress.csv", "w") as file:
writer = csv.writer(file)
writer.writerow(["Name", "Link"])
links = soup.find_all('a')
for link in links:
names = link.text
full_link = link.get('href')
writer.writerow([names, full_link])
!cat congress.csv
### Scraping con Python
# Marca example - First Part
from bs4 import BeautifulSoup
import requests
url = "http://www.marca.com/futbol/primera/calendario.html"
soup = BeautifulSoup(requests.get(url).text, "html5lib")
jornadas = soup.find_all("div", "jornada")
### Scraping con Python
# Marca example - Second Part
for jornada in jornadas:
nombre_jornada = jornada.find("caption").text
partidos_jornada = jornada.find_all("tr")
nombre_jornada, partidos_jornada[5]
### Scraping con Python
# Marca example - Third Part
for partido_jornada in partidos_jornada[1:]:
local = visitante = resultado = ""
try:
local = partido_jornada.find("td", "local").text.strip()
visitante = partido_jornada.find("td", "visitante").text.strip()
resultado = partido_jornada.find("td", "resultado").text.strip()
except:
pass
local, resultado, visitante
### Scraping con Python
# Marca example - Fourth Part
resultados = []
if "Villarreal" in [local, visitante]:
partido = f"{local} vs {visitante}: {resultado} | {nombre_jornada}"
resultados.append(partido)
resultados
### Scraping con Python
resultados = []
url = "http://www.marca.com/futbol/primera/calendario.html"
equipo = "Villarreal"
soup = BeautifulSoup(requests.get(url).text, "html5lib")
jornadas = soup.find_all("div", "jornada")
for jornada in jornadas:
nombre_jornada = jornada.find("caption").text
partidos_jornada = jornada.find_all("tr")
for partido_jornada in partidos_jornada[1:]:
local = partido_jornada.find("td", "local").text.strip()
visitante = partido_jornada.find("td", "visitante").text.strip()
resultado = partido_jornada.find("td", "resultado").text.strip()
if equipo in [local, visitante]:
partido = f"{local} vs {visitante}: {resultado} | {nombre_jornada}"
if partido not in resultados:
resultados.append(partido)
resultados
Ejercicio
Desde hace años, el portal de alexa.com mantiene listados de los sitios más visitados por país. En https://www.alexa.com/topsites/countries/ES se puede ver la lista de los 50 primeros. Usando la librería [`builtwith`](https://pypi.org/project/builtwith/), se pide escrapear los 50 sitios más visitados de España en el ranking de Alexa y devolver los sitios que usen el *framework* Javascript `React` (clave `'javascript-frameworks'` en el resultado devuelto por `builtwith`).
(**Pista**: Para poder procesar una URL, debe tener el protocolo primero, `https://`. Adem'as algunas webs no funcionan con `builtwith`, así que hay que capturar las excepciones correspondientes)
!!pip install builtwith
import builtwith
# Escriba su código aquí
url = ...
html = requests....
soup = BeautifulSoup(...)
selector = ...
sites_using_react = []
for element in soup.select(selector)[:10]:
element_url = ...
try:
builts = builtwith.builtwith(element_url)
frameworks = builts...
except:
frameworks = []
if "React" in frameworks:
sites_using_react.append(...)
sites_using_react
Scrapping - Problemas¶
- Dificultad a la hora de estudiar la estructura de una página web
- Las páginas webs pueden cambiar a lo largo del tiempo
- Nuestros programas también necesitan cambiar
- Necesitamos revisar las leyes y los derechos de uso de las páginas webs para poder aplicar esta técnica
- Contenido dinámico (☠️ Javascript ☠️)
Ejercicio
Dada la URL https://pythonprogramming.net/parsememcparseface/, se pide scrapearla y obtener el valor textual del id `yesnojs`.
# Escriba su código aquí
Scraping - Contenido dinámico¶
El módulo requests_html permite descargar HTML y ejecutar el contenido dinámico existente.
%%python
from requests_html import HTMLSession
html = HTMLSession().get('https://pythonprogramming.net/parsememcparseface/').html
html.render()
print(html.find('#yesnojs', first=True).text)
Scraping - Contenido dinámico¶
Otra opción, bastante más versátil, es Selenium (y sus drivers para Python), ya que permite controlar programáticamente una instancia real de un navegador.
### Scraping - Contenido dinámico
# En Anaconda !!conda install -yq python-chromedriver-binary
!!pip install selenium chromedriver_binary
from selenium import webdriver
import chromedriver_binary # Adds chromedriver binary to path
driver = webdriver.Chrome()
driver.get("http://www.python.org")
print(driver.title, "Python" in driver.title)
driver.quit()
### Scraping - Contenido dinámico
# renfe.es
driver = webdriver.Chrome()
driver.get("http://www.renfe.es")
### Scraping - Contenido dinámico
# renfe.es
origen = driver.find_element_by_id('IdOrigen')
origen.send_keys("SEVILLA-SANTA JUSTA")
destino = driver.find_element_by_id("IdDestino")
destino.send_keys("MADRID (TODAS)")
comprar = driver.find_element_by_css_selector("#datosBusqueda > button")
comprar.click()
### Scraping - Contenido dinámico
# renfe.es
precios = driver.find_elements_by_css_selector("tr.trayectoRow > td:nth-child(6)")
for precio in precios:
print(precio.text)
driver.quit()
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Extracción de información usando expresiones regulares¶
Una expresión regular (a menudo llamada también regex) es una secuencia de caracteres que forma un patrón de búsqueda, principalmente utilizada para la búsqueda de patrones en textos u operaciones de sustituciones.
Haciendo uso de expresiones regulares sobre texto podremos extraer la información que nos interesa almacenar y/o gestionar.
La teorı́a tras las expresiones regulares es compleja y muy amplia. Aquı́ sólo veremos unos ejemplos sencillos para entender el funcionamiento de esta técnica para nuestros objetivos.
Expresiones regulares¶
Expresiones regulares en Python¶
Seguiremos haciendo uso del lenguaje Python. Estudiaremos las expresiones regulares trabajando sobre una serie de ejemplos.
El paquete Python que usaremos es el paquete re. Una búsqueda de una expresión regular tı́pica serı́a:
match = re.search(pat, str)
donde pat serı́a el patrón de la expresión regular y str la cadena de texto donde buscar. La búsqueda del patrón devuelve el resultado si lo encuentra o None en otro caso.
### Expresiones regulares en Python
import re
text = "nos encanta el:data:science"
match = re.search(r"el:\w\w\w\w", text)
if match:
print("found:", match.group())
else:
print("not found")
Expresiones regulares en Python¶
Patrones básicos que podemos usar:
a,X,9: Caracteres normales buscan la coincidencia de ellos mismos.\w: Busca la coincidencia de letras, dı́gitos o guión bajo[a-zA-Z0-9 ].\Wcoincide con cualquier carácter que no sea uno de los anteriores.
Expresiones regulares en Python¶
Más patrones básicos:
\s: Busca la coincidencia de un único espacio en blanco (space, newline, return, tab, form[ \n \r \t \f]).\Scoincide con cualquier carácter que no sea uno de los anteriores.\d: Busca coincidencias de dı́gitos decimales[0-9].\: Se usa también para tratar los caracteres especiales como caracteres normales (los escapa).
Expresiones regulares en Python¶
Además de estos patrones, podremos usar una serie de caracteres especiales:
.: Coincide con cualquier carácter del texto.ˆ,$: Sirven para indicar que la búsqueda del patrón sea al comienzo o al final del texto respectivamente.*,+,?: Se usan para la repetición de ocurrencias en el texto.{}[]()-: Estos caracteres se usan para la definición de grupos y conjuntos dentro del patrón de búsqueda.
### Expresiones regulares en Python
text = "www.example.com"
numbers = "12345"
mail = "pepe@example.com"
print(re.search(r"www", text))
print(re.search(r"wwwe", text))
print(re.search(r"\d\d\d", numbers))
print(re.search(r"\w\w@\w\w", mail))
Expresiones regulares en Python¶
Caracteres para aplicar repetición de elementos:
+, buscarı́a 1 o más ocurrencias del patrón a su izquierda. Por ejemplo,i+equivale a uno o más caracteresi*, buscarı́a 0 o más ocurrencias del patrón a su izquierda?, buscarı́a 0 o 1 ocurrencia del patrón a su izquierda
### Expresiones regulares en Python
text = "www.example.com"
numbers_words = "hola12345caracola"
numbers_words_spaces = "hola12345 caracola"
mail = "pepe@example.com"
print(re.search(r"w+", text))
print(re.search(r"w?", text))
print(re.search(r"\w\d*\w", numbers_words))
print(re.search(r"\w\d+\w", numbers_words))
print(re.search(r"\w\d+\s+\w", numbers_words_spaces))
print(re.search(r"^p\w+", mail))
print(re.search(r"p\w+", mail))
Expresiones regulares en Python¶
Dentro de nuestras expresiones regulares podemos usar corchetes.
El uso de corchetes indica un conjunto de caracteres. Por ejemplo, [abc] buscarı́a a, b o c.
Dentro de los corchetes podemos usar los patrones que hemos visto, como \w, \s, etc. Sólo hay una excepción, el carácter . significa un punto y no cualquier carácter.
### Expresiones regulares en Python
text = "sevilla prueba@mail.com mas pruebas extras"
match = re.search(r"\w+@\w+", text)
if match:
print(match.group())
match = re.search(r"[\w.-]+@[\w.-]+", text)
if match:
print(match.group())
Expresiones regulares en Python - Extracción de grupos¶
Una caracterı́stica muy útil cuando trabajamos con expresiones regulares son los grupos. Usar grupos nos permite separar el patrón por partes que luego podemos elegir individualmente.
Para conseguir esto, englobamos las partes que nos interesan con paréntesis. Para obtener los valores de los grupos obtenidos, simplemente usamos la función match.group(), pasándole como parámetro el ı́ndice grupo que queremos seleccionar. Si no le pasamos ningún valor obtendremos el resultado de todo el patrón (funcionamiento normal).
### Expresiones regulares en Python
text = "betis prueba@mail.com mas pruebas extras"
match = re.search("([\w.-]+)@([\w.-]+)", text)
if match:
print(match.group()) ## the whole match
print(match.group(1)) ## the user
print(match.group(2)) ## the host
Expresiones regulares en Python - findall¶
El método re.search() nos devuelve el primer resultado del patrón buscado sobre un texto. Usando el método findall() obtenemos todos los resultados del patrón buscado sobre el texto, devueltos en una lista de resultados.
Por ejemplo, si queremos encontrar un patrón en un archivo de texto necesitarı́amos iterar sobre todas las lı́neas e ir buscando el patrón en cada una. Si usamos findall() podrı́amos pasar como parámetro el propio archivo completo, dejando que el método haga la búsqueda en todo el documento.
### Expresiones regulares en Python
text = "betis prueba@mail.com scientist@hostmail.com mas prueba2@pepemail.com pruebas extras"
emails = re.findall(r"[\w\.-]+@[\w\.-]+", text)
for email in emails:
print(email)
Expresiones regulares en Python - findall¶
Si unimos la forma de trabajar de los grupos con el método findall(), en vez de obtener una lista de resultados obtendremos una lista de tuplas.
Cada una de las tuplas contendrá los resultados de los grupos (group(1), group(2), etc.).
### Expresiones regulares en Python
text = "betis prueba@mail.com scientist@hostmail.com mas prueba2@pepemail.com pruebas extras"
tuples = re.findall(r"([\w\.-]+)@([\w\.-]+)", text)
print(tuples)
for pair in tuples:
print(pair[0])
print(pair[1])
Expresiones regulares en Python - Substitution¶
Por último, la función re.sub(pat, replacement, str) busca todas las coincidencias del patrón pat en la cadena str y los reemplaza con el valor de replacement.
La cadena replacement puede incluir los valores \1, \2, etc. en referencia al texto de group(1), group(2), etc.
### Expresiones regulares en Python
text = "betis prueba@mail.com scientist@hostmail.com mas prueba2@pepemail.com pruebas extras"
print(re.sub(r"([\w\.-]+)@([\w\.-]+)", r"alex@my_mail.com", text))
Ejercicio
Escriba la expresión regular para validar los sguientes supuestos (una expresión para cada uno):
- Validar numero real positivo con x decimales.
- Validar numero real negativo con x decimales.
- Validar una fecha con formato dd/mm/aaaa
- Validar un nombre, incluyendo nombres compuestos.
- Validar un email.
- Valida un nombre de usuario en twitter, empieza por @ y puede contener letras mayusculas y minusculas, numeros, guiones y guiones bajos.
- Validar ISBN de 13 digitos, siempre empieza en 978 o 979.
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Conclusiones¶
En nuestro dı́a a dı́a en proyectos tecnológicos vamos a trabajar con repositorios de datos y de código.
El scraping es una técnica muy usada y útil para estructurar dato procedente de la web. Entre los principales campos de aplicación encontramos el periodismo de datos (social media).
Entre las dificultades que presenta el scraping destacamos el mantenimiento del código y el tener en cuenta los términos de uso legales.
Las expresiones regulares nos permiten extraer información a partir de la aplicación de patrones a un texto dado. Esto facilita la creación de conjuntos de datos con un modelo de datos concreto.
Índice¶
- Introducción
- Repositorios
- Scraping
- Extracción de información usando expresiones regulares
- Conclusiones
- Bibliografı́a
Bibliografı́a¶
- Data Science from scratch, by Joel Grus, O'reilly, 2015
- https://en.wikipedia.org/wiki/Data_collection
- https://es.wikipedia.org/wiki/Repositorio
- https://es.wikipedia.org/wiki/Web_scraping
- https://es.wikipedia.org/wiki/Expresi%C3%B3n_regular
- https://developers.google.com/edu/python/regular-expressions