import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
from scipy import mean
Confidence interval¶
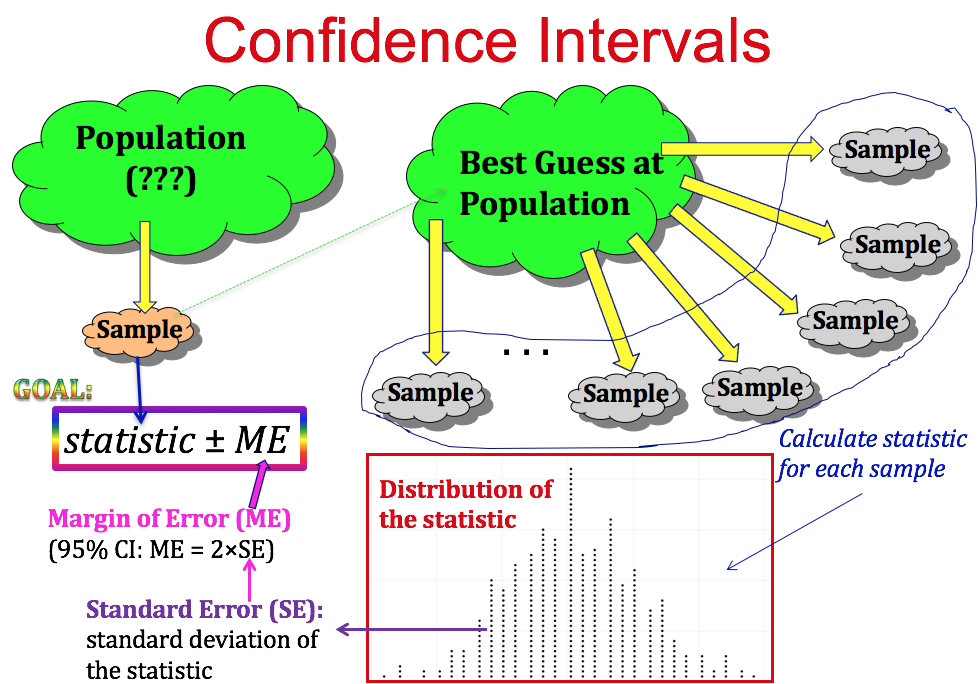
Source: https://psu.instructure.com/courses/1844486/pages/chapter-3-confidence-intervals
Confidence intervals are a calculated range or boundary around a parameter or a statistic that is supported mathematically with a certain level of confidence.
This is different than having a 95% probability that the true population proportion is within our confidence interval. Essentially, if we were to repeat this process, 95% of our calculated confidence intervals would contain the true proportion.
The equation to create a confidence interval can also be shown as:
$$Population\ Proportion\ or\ Mean\ \pm (t-multiplier *\ Standard\ Error)$$The Standard Error is calculated differenly for population proportion and mean:
$$Standard\ Error \ for\ Population\ Proportion = \sqrt{\frac{Population\ Proportion * (1 - Population\ Proportion)}{Number\ Of\ Observations}}$$$$Standard\ Error \ for\ Mean = \frac{Standard\ Deviation}{\sqrt{Number\ Of\ Observations}}$$Or C.I. (Confidence Interval),
$$ C.I. = \mu \pm t*\frac{\sigma}{\sqrt{n}} $$where,
$\mu = \text{sample mean}$, $\sigma = \text{sample standard dev}$, $n = \text{number of samples}$
num_weeks = 52
production = np.random.normal(loc=20,scale=5,size=num_weeks)
plt.figure(figsize=(10,4))
plt.plot(production,c='blue',lw=2,marker='o',markersize=10)
plt.grid(True)
plt.xlabel("Weeks",fontsize=15)
plt.ylabel("Production (tons)",fontsize=15)
plt.hlines(y=production.mean(),xmin=-2,xmax=54,color='red',linestyle='--',lw=3)
plt.show()

n = len(production)
m = production.mean()
production.std()
4.14423961910034
std_err=production.std()/np.sqrt(n)
print(std_err)
0.5747026324798318
confidence = 0.9
h = std_err * stats.t.ppf((1 + confidence) / 2, n)
i90 =[m-h,m+h]
print("90% confidence interval of mean from ",m-h," to ",m+h)
90% confidence interval of mean from 17.920587812526996 to 19.845484342391423
confidence = 0.99
h = std_err * stats.t.ppf((1 + confidence) / 2, n)
i99 =[m-h,m+h]
print("99% confidence interval of mean from ",m-h," to ",m+h)
99% confidence interval of mean from 17.346434321376396 to 20.419637833542023
i90[0],i90[1]
(17.920587812526996, 19.845484342391423)
i99[0],i99[1]
(17.346434321376396, 20.419637833542023)
Repeat the random process many times¶
def repeat(n):
means = []
interval_90 = []
interval_99 = []
for i in range(n):
num_weeks = 52
production = np.random.normal(loc=20,scale=5,size=num_weeks)
means.append(production.mean())
if i90[0] <= production.mean() <= i90[1]:
interval_90.append(production.mean())
if i99[0] <= production.mean() <= i99[1]:
interval_99.append(production.mean())
return (interval_90,interval_99,np.array(means))
repeatations = 500
int_90,int_99,_ = repeat(repeatations)
len(int_90)/repeatations
0.384
len(int_99)/repeatations
0.694
Random choice, shuffling¶
np.random.choice(4, 12)
array([1, 0, 3, 3, 2, 0, 0, 2, 2, 3, 2, 0])
np.random.choice(4, 12, p=[.4, .1, .1, .4])
array([2, 3, 0, 0, 3, 0, 3, 3, 0, 3, 0, 3])
x = np.random.randint(0, 10, (8, 12))
x
array([[0, 9, 1, 3, 9, 9, 9, 2, 7, 4, 3, 1],
[9, 0, 4, 1, 4, 6, 0, 0, 2, 5, 4, 4],
[8, 2, 9, 0, 4, 7, 1, 3, 6, 8, 8, 7],
[0, 9, 7, 6, 7, 7, 6, 6, 9, 8, 9, 4],
[5, 1, 0, 9, 9, 6, 7, 5, 1, 7, 7, 6],
[7, 7, 0, 6, 4, 1, 5, 1, 8, 7, 8, 7],
[1, 6, 1, 5, 4, 5, 2, 6, 7, 0, 0, 0],
[6, 4, 8, 9, 0, 4, 3, 3, 9, 6, 3, 1]])
# sampling individual elements
np.random.choice(x.ravel(), 12)
array([9, 3, 9, 6, 6, 3, 8, 0, 9, 4, 7, 8])
# sampling rows
idx = np.random.choice(x.shape[0], 4)
x[idx, :]
array([[5, 1, 0, 9, 9, 6, 7, 5, 1, 7, 7, 6],
[9, 0, 4, 1, 4, 6, 0, 0, 2, 5, 4, 4],
[7, 7, 0, 6, 4, 1, 5, 1, 8, 7, 8, 7],
[1, 6, 1, 5, 4, 5, 2, 6, 7, 0, 0, 0]])
# sampling columns
idx = np.random.choice(x.shape[1], 4)
x[:, idx]
array([[4, 2, 9, 1],
[5, 0, 0, 4],
[8, 3, 2, 7],
[8, 6, 9, 4],
[7, 5, 1, 6],
[7, 1, 7, 7],
[0, 6, 6, 0],
[6, 3, 4, 1]])
# Shuffling occurs "in place" for efficiency and only along the first axis for multi-dimensional arrays
np.random.shuffle(x)
x
array([[8, 2, 9, 0, 4, 7, 1, 3, 6, 8, 8, 7],
[6, 4, 8, 9, 0, 4, 3, 3, 9, 6, 3, 1],
[0, 9, 7, 6, 7, 7, 6, 6, 9, 8, 9, 4],
[9, 0, 4, 1, 4, 6, 0, 0, 2, 5, 4, 4],
[7, 7, 0, 6, 4, 1, 5, 1, 8, 7, 8, 7],
[5, 1, 0, 9, 9, 6, 7, 5, 1, 7, 7, 6],
[0, 9, 1, 3, 9, 9, 9, 2, 7, 4, 3, 1],
[1, 6, 1, 5, 4, 5, 2, 6, 7, 0, 0, 0]])
# To shuffle columns instead, transpose before shuffling
np.random.shuffle(x.T)
x
array([[6, 0, 9, 8, 4, 8, 7, 2, 8, 1, 3, 7],
[9, 9, 8, 3, 0, 6, 1, 4, 6, 3, 3, 4],
[9, 6, 7, 9, 7, 0, 4, 9, 8, 6, 6, 7],
[2, 1, 4, 4, 4, 9, 4, 0, 5, 0, 0, 6],
[8, 6, 0, 8, 4, 7, 7, 7, 7, 5, 1, 1],
[1, 9, 0, 7, 9, 5, 6, 1, 7, 7, 5, 6],
[7, 3, 1, 3, 9, 0, 1, 9, 4, 9, 2, 9],
[7, 5, 1, 0, 4, 1, 0, 6, 0, 2, 6, 5]])
Bootstrapping example (3000 samples)¶
x = np.concatenate([np.random.exponential(size=2000), np.random.normal(size=1000)])
plt.hist(x, 20,edgecolor='k',color='orange')
plt.show()

n = len(x)
reps = 10000
# Bootstrapping n-samples from array x with replacements many times (reps=10000)
xb = np.random.choice(x, (n, reps))
# Mean of the bootstrappen arrays
mb = xb.mean(axis=0)
# Sort the array of means
mb.sort()
# Compute percentile for 90% confidence interval
np.percentile(mb, [5, 95])
array([0.63485132, 0.7038538 ])
# Compute percentile for 99% confidence interval
np.percentile(mb, [0.5, 99.5])
array([0.61583156, 0.72358553])
Same underlying process but only 300 samples¶
x = np.concatenate([np.random.exponential(size=200), np.random.normal(size=100)])
n = len(x)
reps = 10000
# Bootstrapping n-samples from array x with replacements many times (reps=10000)
xb = np.random.choice(x, (n, reps))
# Mean of the bootstrappen arrays
mb = xb.mean(axis=0)
# Sort the array of means
mb.sort()
# Compute percentile for 90% confidence interval
np.percentile(mb, [5, 95])
array([0.55701889, 0.76816666])
# Compute percentile for 99% confidence interval
np.percentile(mb, [0.5, 99.5])
array([0.4984252 , 0.83334772])
Hypothesis testing¶
The process¶
Statistical hypothesis testing reflects the scientific method, adapted to the setting of research involving data analysis. In this framework, a researcher makes a precise statement about the population of interest, then aims to falsify the statement.
In statistical hypothesis testing, the statement in question is the null hypothesis. If we reject the null hypothesis, we have falsified it (to some degree of confidence).
According to the scientific method, falsifying a hypothesis should require an overwhelming amount of evidence against it. If the data we observe are ambiguous, or are only weakly contradictory to the null hypothesis, we do not reject the null hypothesis.
Basis of hypothesis testing has two attributes:
Null Hypothesis: $H_0$
Alternative Hypothesis: $H_a$
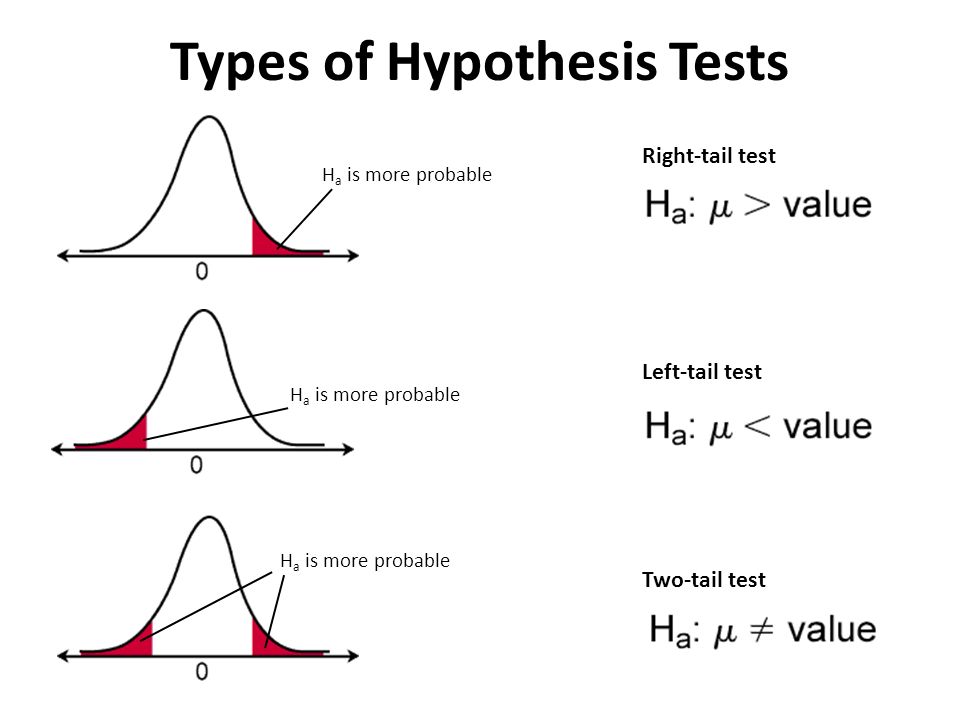
Various cases which are generally used in hypothesis testing are:
- One Population Proportion
- Difference in Population Proportions
- One Population Mean
- Difference in Population Means
The equation to compute the *test statistic* is:
$$test\ statistic = \frac{Best\ Estimate - Hypothesized\ Estimate}{Standard\ Error\ of\ Estimate}$$After computing this test statistic, we ask ourselves, "How likely is it to see this value of the test statistic under the Null hypothesis?" i.e. we compute a probability value.
Depending on that probability, we either reject or fail to reject the null hypothesis. Note, we do not accept the alternate hypothesis because we can never ovserve all the data in the universe.
Type-I and Type-II errors¶
The framework of formal hypothesis testing defines two distinct types of errors. A type I error (false positive) occurs when the null hypothesis is true but is incorrectly rejected. A type II error occurs when the null hypothesis is not rejected when it actually is false.
Most traditional methods for statistical inference aim to strictly control the probability of a type I error, usually at 5%. While we also wish to minimize the probability of a type II error, this is a secondary priority to controlling the type I error.
Let us simulate James Bond's Martini guessing!¶

Suppose we gave Mr. Bond a series of 16 taste tests. In each test, we flipped a fair coin to determine whether to stir or shake the martini.
Then we presented the martini to Mr. Bond and asked him to decide whether it was shaken or stirred. Let's say Mr. Bond was correct on 13 of the 16 taste tests.
Does this prove that Mr. Bond has at least some ability to tell whether the martini was shaken or stirred?
martini = ['shaken','stirred']
glasses = []
for _ in range(16):
glasses.append(np.random.choice(martini))
for g in glasses:
print(g,end=', ')
shaken, stirred, shaken, shaken, shaken, stirred, shaken, shaken, stirred, stirred, stirred, shaken, stirred, shaken, stirred, shaken,
A function to generate Mr. Bond's response (when he is randomly guessing)¶
def bond_guess(n,verbose=True):
score=[]
for _ in range(n):
bond_answers = []
for _ in range(16):
bond_answers.append(np.random.choice(martini))
if verbose:
print("My name is Bond...James Bond, and I say the glasses are as follows:",bond_answers)
correct_guess = np.sum(np.array(bond_answers)==np.array(glasses))
if verbose:
print("\nMr. James Bond gave {} correct answers".format(correct_guess))
print("-"*100)
score.append(correct_guess)
return np.array(score)
Print 5 typical responses when Mr. Bond is randomly guessing¶
_=bond_guess(5)
My name is Bond...James Bond, and I say the glasses are as follows: ['shaken', 'shaken', 'stirred', 'stirred', 'shaken', 'stirred', 'stirred', 'stirred', 'stirred', 'shaken', 'stirred', 'shaken', 'shaken', 'stirred', 'stirred', 'shaken'] Mr. James Bond gave 8 correct answers ---------------------------------------------------------------------------------------------------- My name is Bond...James Bond, and I say the glasses are as follows: ['stirred', 'stirred', 'shaken', 'shaken', 'shaken', 'shaken', 'stirred', 'shaken', 'stirred', 'shaken', 'stirred', 'shaken', 'stirred', 'shaken', 'stirred', 'stirred'] Mr. James Bond gave 11 correct answers ---------------------------------------------------------------------------------------------------- My name is Bond...James Bond, and I say the glasses are as follows: ['shaken', 'stirred', 'stirred', 'stirred', 'stirred', 'stirred', 'shaken', 'stirred', 'stirred', 'stirred', 'stirred', 'shaken', 'stirred', 'shaken', 'stirred', 'shaken'] Mr. James Bond gave 12 correct answers ---------------------------------------------------------------------------------------------------- My name is Bond...James Bond, and I say the glasses are as follows: ['shaken', 'shaken', 'stirred', 'shaken', 'stirred', 'shaken', 'shaken', 'shaken', 'stirred', 'shaken', 'shaken', 'shaken', 'shaken', 'stirred', 'stirred', 'shaken'] Mr. James Bond gave 8 correct answers ---------------------------------------------------------------------------------------------------- My name is Bond...James Bond, and I say the glasses are as follows: ['shaken', 'shaken', 'stirred', 'shaken', 'stirred', 'stirred', 'shaken', 'shaken', 'shaken', 'shaken', 'shaken', 'shaken', 'stirred', 'stirred', 'stirred', 'shaken'] Mr. James Bond gave 9 correct answers ----------------------------------------------------------------------------------------------------
Compute the probability of score >=13¶
score = bond_guess(10000,verbose=False)
print(np.sum(score>=13)/10000)
0.0092
Show probabilities of all the correct guesses (1-16)¶
score = bond_guess(10000,verbose=False)
prob = []
guess = []
for i in range(17):
print(f"Probability of answering {i} correct: {np.sum(score==i)/10000}")
prob.append(np.sum(score==i)/10000)
guess.append(i)
Probability of answering 0 correct: 0.0 Probability of answering 1 correct: 0.0003 Probability of answering 2 correct: 0.003 Probability of answering 3 correct: 0.0091 Probability of answering 4 correct: 0.0259 Probability of answering 5 correct: 0.0649 Probability of answering 6 correct: 0.1194 Probability of answering 7 correct: 0.1774 Probability of answering 8 correct: 0.1953 Probability of answering 9 correct: 0.176 Probability of answering 10 correct: 0.119 Probability of answering 11 correct: 0.0686 Probability of answering 12 correct: 0.0295 Probability of answering 13 correct: 0.0094 Probability of answering 14 correct: 0.0018 Probability of answering 15 correct: 0.0004 Probability of answering 16 correct: 0.0
plt.figure(figsize=(9,5))
plt.plot(guess,prob,c='k',lw=3)
plt.xlabel("Number of exactly these many correct guesses",fontsize=14)
plt.ylabel("Probability",fontsize=14)
plt.xticks(guess,fontsize=14)
plt.yticks(fontsize=14)
plt.hlines(y=0.05,xmin=0,xmax=16,color='blue',linestyle='--')
plt.text(s="p-value 0.05",x=6,y=0.07,fontsize=16,color='red')
plt.grid(True)
plt.show()

Show probabilities of at least certain number of correct guesses¶
score = bond_guess(10000,verbose=False)
prob = []
guess = []
for i in range(1,17):
print(f"Probability of answering at least {i} correct: {np.sum(score>=i)/10000}")
prob.append(np.sum(score>=i)/10000)
guess.append(i)
Probability of answering at least 1 correct: 1.0 Probability of answering at least 2 correct: 0.9997 Probability of answering at least 3 correct: 0.998 Probability of answering at least 4 correct: 0.9896 Probability of answering at least 5 correct: 0.9596 Probability of answering at least 6 correct: 0.8916 Probability of answering at least 7 correct: 0.7767 Probability of answering at least 8 correct: 0.6003 Probability of answering at least 9 correct: 0.4045 Probability of answering at least 10 correct: 0.2255 Probability of answering at least 11 correct: 0.1062 Probability of answering at least 12 correct: 0.0406 Probability of answering at least 13 correct: 0.0117 Probability of answering at least 14 correct: 0.0024 Probability of answering at least 15 correct: 0.0002 Probability of answering at least 16 correct: 0.0
plt.figure(figsize=(9,5))
plt.plot(guess,prob,c='k',lw=3)
plt.xlabel("Number of at least these many correct guesses",fontsize=14)
plt.ylabel("Probability",fontsize=14)
plt.xticks(guess,fontsize=14)
plt.yticks(fontsize=14)
plt.hlines(y=0.05,xmin=0,xmax=16,color='blue',linestyle='--')
plt.text(s="p-value 0.05",x=4,y=0.15,fontsize=16,color='red')
plt.grid(True)
plt.show()

What can we deduce from this probability distribution?¶
If we are going with p=0.05 or 95% significance level, then we can conclude that anything above 12 correct answers are unlikely if Mr. Bond was guessing randomly.
Hypothesis testing alternative example with population proportions¶
Research Question¶
Is there a significant difference between the population proportions of parents of Black children and parents of Hispanic children who report that their child has had some swimming lessons? (A real-life study from the Univ. of Michigan)
Formulation¶
*Populations: All parents of black children age 6-18 and all parents of Hispanic children age 6-18 Parameter of Interest*: p1 - p2, where p1 = black and p2 = hispanic
*Null Hypothesis:* p1 - p2 = 0
*Alternative Hypthosis:* p1 - p2 $\neq$ 0
Data¶
247 Parents of Black Children 36.8% of parents report that their child has had some swimming lessons.
308 Parents of Hispanic Children 38.9% of parents report that their child has had some swimming lessons.
Function used in the code¶
Numpy Binomial distribution because this is a matter of YES/NO answers (from the parents)
Scipy independent t-test because we are interested in a two-sided test of equal/unequal means
import scipy.stats
n1 = 247
p1 = .37
n2 = 308
p2 = .39
population1 = np.random.binomial(1, p1, n1)
population2 = np.random.binomial(1, p2, n2)
print("Parents of Black children")
print("-"*55)
print(f"{population1.sum()} parents answered YES and {n1-population1.sum()} parents answered NO")
print("\nParents of Hispanic children")
print("-"*55)
print(f"{population2.sum()} parents answered YES and {n2-population2.sum()} parents answered NO")
Parents of Black children ------------------------------------------------------- 86 parents answered YES and 161 parents answered NO Parents of Hispanic children ------------------------------------------------------- 114 parents answered YES and 194 parents answered NO
t_stat,pval=scipy.stats.ttest_ind(population1, population2)
print("The t-statistic from this data:",t_stat)
print("Corresponding p-value from this data:",pval)
The t-statistic from this data: -0.5344882669395735 Corresponding p-value from this data: 0.5932185803894023
if pval>0.05:
print("Based on this data, NULL hypothesis cannot be rejected \ni.e. there is no significant difference between the proportion of Black and Hispanic parents,\nwho reporpted that their children had a swimming lesson")
else:
print("There seems to be a statisticlly significant difference in the proportion of Black and Hispanic parents,\nwho reporpted that their children had a swimming lesson")
Based on this data, NULL hypothesis cannot be rejected i.e. there is no significant difference between the proportion of Black and Hispanic parents, who reporpted that their children had a swimming lesson