PraatIO - doing speech analysis with Python¶
An introduction and tutorial
TABLE OF CONTENTS
An introduction
- What is Praat?
- TextGrids, IntervalTiers, and PointTiers
- The physical textgrid
- What is PraatIO
- What are some uses of PraatIO?
A tutorial
- Installing PraatIO
- Creating bare textgrid files
- Opening TextGrids
- Getting information from TextGrids and Tiers
- Modifying TextGrids and Tiers with new()
- Working with Textgrid objects
- Cropping TextGrids
- Working with Tier objects
- Operations between tiers
- ProMo
- Pysle
## An introduction
What is Praat?¶
PraatIO or Praat Input and Output was originally conceived as a way to work with Praat from within python.
Praat (http://www.fon.hum.uva.nl/praat/) is a freely available tool for doing speech and phonetic analysis. It has a spectrogram visualization tool with overlays of information like pitch track and intensity. This visualization is paired with an editor for transcribing speech and for analyzing speech. It also has tools for extracting acoustic parameters of speech, generating waveforms, and resynthesizing speech. It is a comprehensive and indispensible tool for speech scientists.
Praat comes with its own scripting language for automating tasks.
TextGrids, IntervalTiers, and PointTiers¶
The heart of any speech analysis is a transcript. Praat calls its transcript files TextGrids, and the same terminology is used here.
More specifically, a TextGrid, used by Praat or PraatIO, is a collection of independent annotation analyses for a given audio recording. Each layer of analysis is known as a tier. There are two kinds of tiers: IntervalTiers and PointTiers. IntervalTiers are used to annotate events that have duration. Like syllables, words, or utterances. PointTiers are used for annotating instaneous events. Like places where the audio clipped. The peak of a pitch contour. Or the sound of a clap. Etc.
Below is a sample textgrid as seen in Praat, with accompanying wavfile. In this example the textgrid contains two interval tiers and a point tier (named 'phone', 'word', and 'maxF0' respectively). 'phone' marks the phonemes--the consonants and vowels of the words. 'word' indicates the word boundaries. And 'maxF0' marks the highest peaks of the pitch contour (the blue curve superimposed over the spectrogram) for each word.
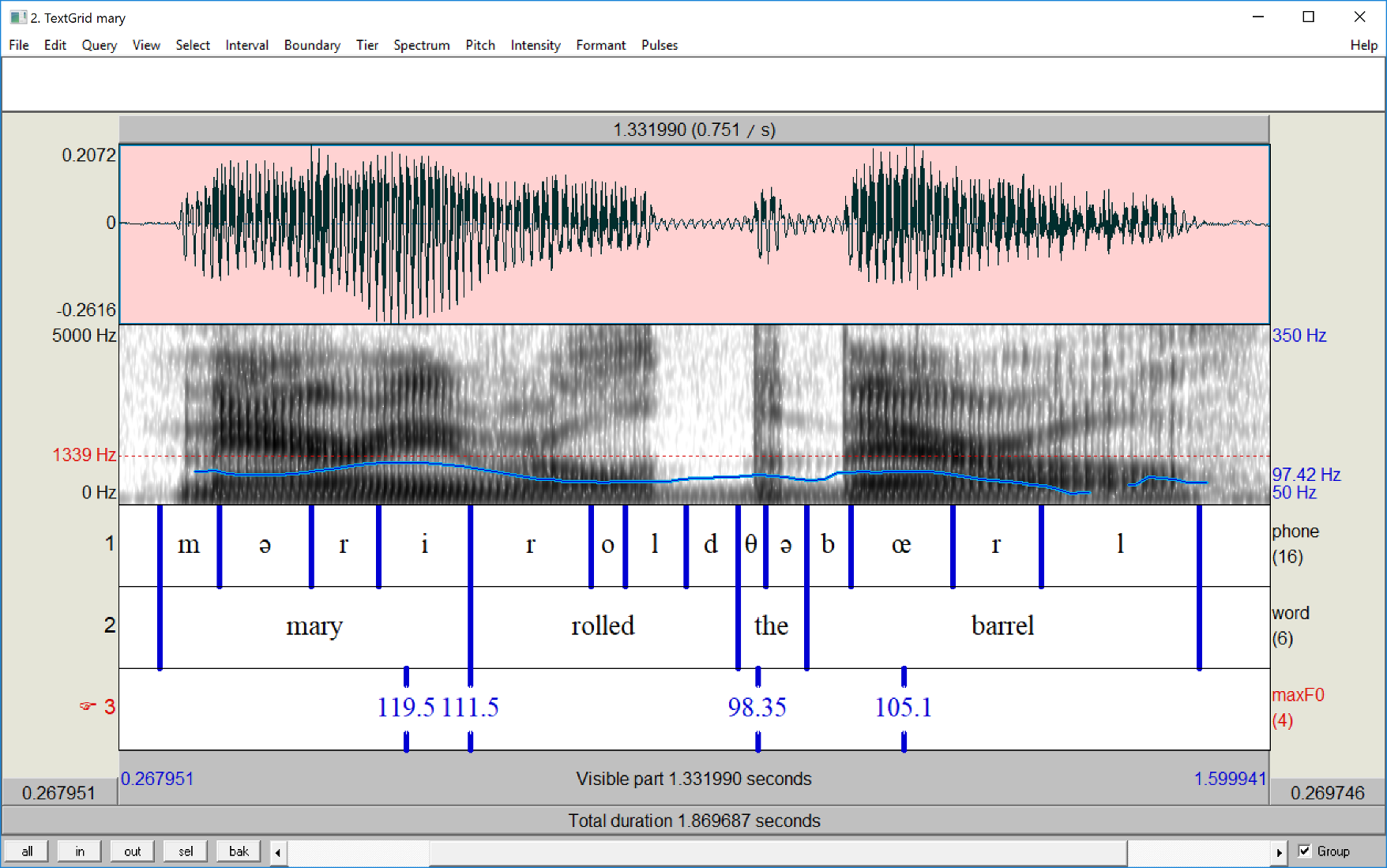
The physical textgrid¶
Praat has its own plain text format for working TextGrids. It's an easy to read and easy to parse. Here is a small snippet. No magic or wizardy. The TextGrid has a few properties defined--min and max times (the start and end of textgrid with respect to the audio file) and the number of tiers. Then the tiers are presented in order of appearance. They too have a few properties defined, followed by the intervals and points that they contain. And thats it!
There is a more condensed version of the TextGrid which contains the same information but without the extraneous text that makes the below example so easy to read. I won't cover that here.
File type = "ooTextFile"
Object class = "TextGrid"
xmin = 0
xmax = 1.869687
tiers? <exists>
size = 3
item []:
item [1]:
class = "IntervalTier"
name = "phone"
xmin = 0
xmax = 1.869687
intervals: size = 16
intervals [1]:
xmin = 0
xmax = 0.3154201182247563
text = ""
intervals [2]:
xmin = 0.3154201182247563
xmax = 0.38526757369599995
text = "m"
intervals [3]:
xmin = 0.38526757369599995
xmax = 0.4906833231456586
text = "ə"
What is PraatIO¶
I think python should have its own library for doing robust speech analysis. Thats where praatIO comes in.
PraatIO is not a python implementation of Praat or an interface to Praat. PraatIO is a pure python library that contains a robust toolset for creating, querying, and modifying textgrid annotations. It also comes with a diverse array of tools that use these annotations to modify speech or extract information from speech. It depends on Praat for some but not all of its functionality.
What are some uses of PraatIO?¶
Creating textgrids for annotation in a consistent manner
Extracting pitch, intensity, and duration from labeled regions of interest
Extracting user-made annotations or verifying user-made annotations
Extracting subsegments of recordings, substituting segments with other segments, making supercuts
## A tutorial
Installing PraatIO¶
Before we can run PraatIO, we need to install it. It can be installed easily enough using pip like so. For other installation options, see the main github page for praatio.
%pip install praatio --upgrade
Requirement already satisfied: praatio in /Users/tmahrt/.pyenv/versions/3.10.0/lib/python3.10/site-packages (6.0.0) Requirement already satisfied: typing-extensions in /Users/tmahrt/.pyenv/versions/3.10.0/lib/python3.10/site-packages (from praatio) (4.0.1)
### Creating bare textgrid files
The code for working with textgrids is contained in textgrid.py. This file does not store the classes we will be working with, but it does expose them for convenient access. There are three classes of particular interest and some functions. Let's start with the basics.
TextGrid, IntervalTier, and PointTier are the three classes we'll be using a lot in textgrid.py
For our first, most basic example, we create a TextGrid with a blank IntervalTier and a blank PointTier--ripe for annotating. A minimal Textgrid needs at least one tier but can have as many as you want.
from praatio import textgrid
# Textgrids take no arguments--it gets all of its necessary attributes from the tiers that it contains.
tg = textgrid.Textgrid()
# IntervalTiers and PointTiers take four arguments: the tier name, a list of intervals or points,
# a starting time, and an ending time.
wordTier = textgrid.IntervalTier('words', [], 0, 1.0)
maxF0Tier = textgrid.PointTier('maxF0', [], 0, 1.0)
tg.addTier(wordTier)
tg.addTier(maxF0Tier)
tg.save("empty_textgrid.TextGrid", format="short_textgrid", includeBlankSpaces=True)
The above example gets the job done, but it's frankly not very useful. What about a basic example that does something we would actually need?
One problem with the above example is the ending time. It's 1.0. More often then not, we don't know the exact length of an audio file. The start and end time are actually optional arguments to the constructor. If not supplied, praat will get them from the min and max values in the list of intervals or points (not generally recommended). Alternatively, one can supply a wave file to set the ending time of the tier.
Scenario: You have a large corpus of speech recordings--telephone conversations. You are coordinating a team of annotators who will transcribe the words in the corpus. Rather than have the annotators create textgrids from scratch, you use praatio to generate skelaton textgrids that they can fill in themselves.
import os
from os.path import join
from praatio import textgrid
from praatio import audio
inputPath = join('..', 'examples', 'files')
outputPath = join(inputPath, "generated_textgrids")
if not os.path.exists(outputPath):
os.mkdir(outputPath)
for fn in os.listdir(inputPath):
name, ext = os.path.splitext(fn)
if ext != ".wav":
continue
duration = audio.getDuration(join(inputPath, fn))
wordTier = textgrid.IntervalTier('words', [], 0, duration)
tg = textgrid.Textgrid()
tg.addTier(wordTier)
tg.save(join(outputPath, name + ".TextGrid"), format="short_textgrid", includeBlankSpaces=True)
# Did it work?
for fn in os.listdir(outputPath):
ext = os.path.splitext(fn)[1]
if ext != ".TextGrid":
continue
print(fn)
bobby.TextGrid mary_300hz_high_pass_filtered.TextGrid damon_set_test.TextGrid mary_segment.TextGrid mary.TextGrid
Bravo! You've saved your colleagues the tedium of creating empty textgrids for each wav file from scratch and removed one vector of human error from your workflow.
There are more things we can do with bare textgrid files, but for now let's move on to how to work with existing textgrid files in praatio.
### Opening TextGrids
We know how to save textgrids. Now lets learn how to open them.
from os.path import join
from praatio import textgrid
inputFN = join('..', 'examples', 'files', 'mary.TextGrid')
tg = textgrid.openTextgrid(inputFN, includeEmptyIntervals=False) # Give it a file name, get back a Textgrid object
### Getting information from TextGrids and Tiers
So we've opened a TextGrid file. What happens next? A textgrid is just a container for tiers. So after opening a textgrid, probably the first thing you'll want to do is access the tiers.
A TextGrid's tiers are stored in a dictionary called tierDict. The names of the tiers, and their order in the TextGrid, are stored in tierNames.
# What tiers are stored in this textgrid?
print(tg.tierNames)
# It's possible to access the tiers by their position in the TextGrid
# (i.e. the order they were added in)
firstTier = tg.getTier(tg.tierNames[0])
# Or by their names
wordTier = tg.getTier('word')
print(firstTier)
('phone', 'word', 'pitch')
<praatio.data_classes.interval_tier.IntervalTier object at 0x1073a2e30>
Ok, so with the TextGrid, we got a Tier. What happens next? Most of the time, you'll be accessing the intervals or points stored in the tier. These are stored in the entries.
For a pointTier, entries looks like:
[(time, labe1), (time, label), ...]
While for an intervalTier, entries looks like:
[(start, end, label), (start, end, label), ...]
# A PointTier's entries are all Points and an IntervalTier's entries are all Intervals.
# Both types of entries are named tuples, so they can be accessed like a tuple or like an object.
from praatio.utilities.constants import Interval, Point
interval = Interval(0, 1, "hello")
print((interval.label, interval[2]))
point = Point(0.5, "55")
print((point.label, point[1]))
('hello', 'hello')
('55', '55')
# I just want the labels from the entries
labelList = [entry.label for entry in wordTier.entries]
print(labelList)
# Get the duration of each interval
# (in this example, an interval is a word, so this outputs word duration)
durationList = []
for start, stop, _ in wordTier.entries:
durationList.append(stop - start)
print(durationList)
['mary', 'rolled', 'the', 'barrel'] [0.36012987312514183, 0.3083570381281018, 0.07981859410500003, 0.4545282708797298]
I use this idiom--open textgrid, get target tier, and forloop through the entries--on a regular basis. For clarity, here the whole idiom is presented in a concise example
# Print out each interval on a separate line
from os.path import join
from praatio import textgrid
inputFN = join('..', 'examples', 'files', 'mary.TextGrid')
tg = textgrid.openTextgrid(inputFN, includeEmptyIntervals=False)
tier = tg.getTier('word')
for start, stop, label in tier.entries:
print("From:%f, To:%f, %s" % (start, stop, label))
From:0.315420, To:0.675550, mary From:0.675550, To:0.983907, rolled From:0.983907, To:1.063726, the From:1.063726, To:1.518254, barrel
### Modifying TextGrids and Tiers with new()
Textgrids and tiers come with a new() function. This function gives you a new copy of the current instance. The new() function takes the same arguments as the constructor for the object, except that with new() the arguments are all optional. Any arguments you don't provide, will be copied over from the original instance.
# Sometimes you just want to have two copies of something
newTG = tg.new()
newTier = tier.new()
# emptiedTier and renamedTier are the same as tier, except for the parameter specified in .new()
emptiedTier = tier.new(entries=[]) # Remove all entries in the entry list
renamedTier = tier.new(name="lexical items") # Rename the tier to 'lexical items'
# Let's reload everything
from os.path import join
from praatio import textgrid
inputFN = join('..', 'examples', 'files', 'mary.TextGrid')
tg = textgrid.openTextgrid(inputFN, includeEmptyIntervals=False)
# Ok, what were our tiers?
print(tg.tierNames)
('phone', 'word', 'pitch')
# We've already seen how to add a new tier to a TextGrid
# Here we add a new tier, 'utterance', which has one entry that spans the length of the textgrid
utteranceTier = textgrid.IntervalTier(name='utterance', entries=[('0', tg.maxTimestamp, 'mary rolled the barrel'), ],
minT=0, maxT=tg.maxTimestamp)
tg.addTier(utteranceTier)
print(tg.tierNames)
('phone', 'word', 'pitch', 'utterance')
# Maybe we decided that we don't need the phone tier. We can remove it using the tier's name.
# The remove function returns the removed tier, in case you want to do something with it later.
wordTier = tg.removeTier('word')
print(tg.tierNames)
print(wordTier)
('phone', 'pitch', 'utterance')
<praatio.data_classes.interval_tier.IntervalTier object at 0x1073a1db0>
# We can also replace one tier with another like so (preserving the order of the tiers)
tg.replaceTier('phone', wordTier)
print(tg.tierNames)
('word', 'pitch', 'utterance')
# Or rename a tier
tg.renameTier('word', 'lexical items')
print(tg.tierNames)
('lexical items', 'pitch', 'utterance')
The above featured functions are perhaps the most useful functions in praatio. But there are some other functions which I'll mention briefly here.
tg.appendTextgrid(tg2) will append tg2 to the end of tg--modifying all of the times in tg2 so that they appear chronologically after tg.
tg.eraseRegion(start, stop, doShrink) will erase a segment of a textgrid. The erased segment can be left blank, or the textgrid can shrink
tg.insertSpace(start, duration, collisionCode) will insert a blank segment into a textgrid. collisionCode determines what happens to segments that span the start location of the insertion.
tg.mergeTiers() will merge all tiers into a single tier. Overlapping intervals on different tiers will have their labels combined by this process.
### Cropping TextGrids
The last function to look at with TextGrids is also a very useful and powerful one. Using crop() you can get a...well...cropped TextGrid.
Crop() takes five arguments: Crop(startTime, endTime, strictFlag, softFlag, rebaseToZero)
startTime, endTime - these are the start and end times that define the crop region. Simple enough
strictFlag - if True, only wholly contained intervals will be included in the output. Intervals that are partially contained are not included. If False, all intervals that are at least partially contained will be included in the cropped textgrid.
softFlag - if False, the crop boundaries are firm. if True and strictFlag is False, partially contained boundaries will extend the boundaries of the crop interval
rebaseToZero - if True, the entry time values will be subtracted by startTime.
Let's see the effects of these different arguments:
# Let's start by observing the pre-cropped entry lists
wordTier = tg.getTier('lexical items')
print(wordTier.entries)
utteranceTier = tg.getTier('utterance')
print(utteranceTier.entries)
print("Start time: %f" % wordTier.minTimestamp)
print("End time: %f" % utteranceTier.maxTimestamp)
(Interval(start=0.3154201182247563, end=0.6755499913498981, label='mary'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the'), Interval(start=1.063725623583, end=1.5182538944627297, label='barrel')) (Interval(start=0.0, end=1.869687, label='mary rolled the barrel'),) Start time: 0.000000 End time: 1.869687
# Now let's crop and see what changes!
# Crop takes four arguments
# If mode is 'truncated', all intervals contained within the crop region will appear in the
# returned TG--however, intervals that span the crop region will be truncated to fit within
# the crop region
# If rebaseToZero is True, the times in the textgrid are recalibrated with the start of
# the crop region being 0.0s
croppedTG = tg.crop(0.5, 1.0, mode='truncated', rebaseToZero=True)
wordTier = croppedTG.getTier('lexical items')
print(wordTier.entries)
utteranceTier = croppedTG.getTier('utterance')
print(utteranceTier.entries)
print("Start time: %f" % croppedTG.minTimestamp)
print("End time: %f" % croppedTG.maxTimestamp)
(Interval(start=0.0, end=0.17554999134989813, label='mary'), Interval(start=0.17554999134989813, end=0.4839070294779999, label='rolled'), Interval(start=0.4839070294779999, end=0.5, label='the')) (Interval(start=0.0, end=0.5, label='mary rolled the barrel'),) Start time: 0.000000 End time: 0.500000
# If rebaseToZero is False, the values in the cropped textgrid will be what they were in the
# original textgrid (but without values outside the crop region)
# Compare the output here with the output above
croppedTG = tg.crop(0.5, 1.0, mode='truncated', rebaseToZero=False)
wordTier = croppedTG.getTier('lexical items')
print(wordTier.entries)
utteranceTier = croppedTG.getTier('utterance')
print(utteranceTier.entries)
print("Start time: %f" % croppedTG.minTimestamp)
print("End time: %f" % croppedTG.maxTimestamp)
(Interval(start=0.5, end=0.6755499913498981, label='mary'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.0, label='the')) (Interval(start=0.5, end=1.0, label='mary rolled the barrel'),) Start time: 0.500000 End time: 1.000000
# If mode is 'strict', only wholly contained intervals will be included in the output.
# Compare this with the previous result
croppedTG = tg.crop(0.5, 1.0, mode='strict', rebaseToZero=False)
# Let's start by observing the pre-cropped entry lists
wordTier = croppedTG.getTier('lexical items')
print(wordTier.entries)
utteranceTier = croppedTG.getTier('utterance')
print(utteranceTier.entries)
print("Start time: %f" % croppedTG.minTimestamp)
print("End time: %f" % croppedTG.maxTimestamp)
(Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'),) () Start time: 0.500000 End time: 1.000000
# If mode is 'lax', partially contained intervals will be wholly contained in the outpu.
# Compare this with the previous result
croppedTG = tg.crop(0.5, 1.0, mode='lax', rebaseToZero=False)
# Let's start by observing the pre-cropped entry lists
wordTier = croppedTG.getTier('lexical items')
print(wordTier.entries)
utteranceTier = croppedTG.getTier('utterance')
print(utteranceTier.entries)
print("Start time: %f" % croppedTG.minTimestamp)
print("End time: %f" % croppedTG.maxTimestamp)
(Interval(start=0.3154201182247563, end=0.6755499913498981, label='mary'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the')) (Interval(start=0.0, end=1.869687, label='mary rolled the barrel'),) Start time: 0.000000 End time: 1.869687
### Working with Tiers
Textgrids alone aren't very useful for working with data. The real utility is in the tiers contained in the textgrids. In this section we'll learn about functions that help us work with IntervalTiers and PointTiers.
We'll start with the easy stuff. eraseRegion(), insertSpace(), crop(), and editTimestamps() are back and they work exactly the same on tiers as they did for textgrids. If you only need to modify one tier, it's better to take advantage of this feature, rather than modifying a whole textgrid.
Now let's move on to some of the functions that are unique to tiers. We'll start with deleteEntry() and insertEntry()
# Let's reload everything, just as before
from os.path import join
from praatio import textgrid
inputFN = join('..', 'examples', 'files', 'mary.TextGrid')
tg = textgrid.openTextgrid(inputFN, includeEmptyIntervals=False)
# Ok, what are our tiers?
print(tg.tierNames)
('phone', 'word', 'pitch')
# The `entries`, which holds the tier point or interval data, is the heart of the tier.
# Recall the 'new()' function, if you want to modify all of the entries in a tier at once
wordTier = tg.getTier('word')
newEntries = [(start, stop, 'bloop') for start, stop, label in wordTier.entries]
newWordTier = wordTier.new(entries=newEntries)
print(wordTier.entries)
print(newWordTier.entries)
(Interval(start=0.3154201182247563, end=0.6755499913498981, label='mary'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the'), Interval(start=1.063725623583, end=1.5182538944627297, label='barrel')) (Interval(start=0.3154201182247563, end=0.6755499913498981, label='bloop'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='bloop'), Interval(start=0.9839070294779999, end=1.063725623583, label='bloop'), Interval(start=1.063725623583, end=1.5182538944627297, label='bloop'))
# If, however, we only want to modify a few entries, there are some functions for doing so
# deleteEntry() takes an entry and deletes it
maryEntry = wordTier.entries[0]
wordTier.deleteEntry(maryEntry)
print(wordTier.entries)
(Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the'), Interval(start=1.063725623583, end=1.5182538944627297, label='barrel'))
# insertEntry() does the opposite of deleteEntry.
wordTier.insertEntry(maryEntry)
print(wordTier.entries)
print()
# you can also set the collision code to 'merge' or 'replace' to set the behavior in the event an entry already exists
# And the collisionReportingMode can be used to have warnings printed out when a collision occurs
wordTier.insertEntry((maryEntry[0], maryEntry[1], 'bob'), collisionMode='replace', collisionReportingMode='silence')
print(wordTier.entries)
(Interval(start=0.3154201182247563, end=0.6755499913498981, label='mary'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the'), Interval(start=1.063725623583, end=1.5182538944627297, label='barrel')) (Interval(start=0.3154201182247563, end=0.6755499913498981, label='bob'), Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled'), Interval(start=0.9839070294779999, end=1.063725623583, label='the'), Interval(start=1.063725623583, end=1.5182538944627297, label='barrel'))
The next two functions are very useful when working in conjunction with other numerical data:
IntervalTier.getValuesInIntervals() and PointTier.getValuesAtPoints()
# Let's say we have some time series data
# Where the data is organized as [(timeV1, dataV1a, dataV1b, ...), (timeV2, dataV2a, dataV2b, ...), ...]
dataValues = [(0.1, 15), (0.2, 98), (0.3, 105), (0.4, 210), (0.5, ),
(0.6, 154), (0.7, 181), (0.8, 110), (0.9, 203), (1.0, 240)]
# Often times when working with such data, we want to know which data
# corresponds to certain speech events
# e.g. what was the max pitch during the stressed vowel of a particular word etc...
intervalDataList = wordTier.getValuesInIntervals(dataValues)
# The returned list is of the form [(interval1, )]
for interval, subDataList in intervalDataList:
print(interval)
print(subDataList)
print()
Interval(start=0.3154201182247563, end=0.6755499913498981, label='bob') [(0.4, 210), (0.5,), (0.6, 154)] Interval(start=0.6755499913498981, end=0.9839070294779999, label='rolled') [(0.7, 181), (0.8, 110), (0.9, 203)] Interval(start=0.9839070294779999, end=1.063725623583, label='the') [(1.0, 240)] Interval(start=1.063725623583, end=1.5182538944627297, label='barrel') []
Often times, we only want to limit the entries that we analyze.
crop(), which we've already seen, allows us to limit by time. find() allows us to limit by label.
find() returns the index of any matches in the entries. It takes one required argument: the string to match and two optional arguments: a flag for allowing partial matches, and a flag for running searches as a regular expression
bobWordIList = wordTier.find('bob')
bobWord = wordTier.entries[bobWordIList[0]]
print(bobWord)
Interval(start=0.3154201182247563, end=0.6755499913498981, label='bob')
#### Example: Extracting time series data from specific intervals To end this subsection, let's try another real life example using what we've learned. For this, we're going to learn one praatio tool that fits outside of the scope of this tutorial.
This function can be used to extract time and pitch values from audio recordings: praatio.pitch_and_intensity.audioToPI(). Don't worry too much about how the function works--thats for another tutorial.
Scenario: You want to examine the maximum pitch that was produced whenever a speaker was saying someone's name. You're not interested in the pitch for other words.
To do this, 1) we're first going to have to extract the pitch from audio recordings, 2) then we're going to need to find when the words were spoken, 3) then we'll isolate the relevant pitch values for each word, and 4) finally find the maximum value.
import os
from os.path import join
from praatio import textgrid
from praatio import pitch_and_intensity
# For pitch extraction, we need the location of praat on your computer
#praatEXE = r"C:\Praat.exe"
praatEXE = "/Applications/Praat.app/Contents/MacOS/Praat"
# The 'os.getcwd()' is kindof a hack. With jypter __file__ is undefined and
# os.getcwd() seems to default to the praatio installation files.
rootPath = join(os.getcwd(), '..', 'examples', 'files')
pitchPath = join(rootPath, "pitch_extraction", "pitch")
fnList = [('mary.wav', 'mary.TextGrid'),
('bobby.wav', 'bobby_words.TextGrid')]
# The names of interest -- in an example working with more data, this would be more comprehensive
nameList = ['mary', 'BOBBY', 'lisa', 'john', 'sarah', 'tim', ]
outputList = []
for wavName, tgName in fnList:
pitchName = os.path.splitext(wavName)[0] + '.txt'
tg = textgrid.openTextgrid(join(rootPath, tgName), includeEmptyIntervals=False)
# 1 - get pitch values
pitchList = pitch_and_intensity.extractPitch(join(rootPath, wavName),
join(pitchPath, pitchName),
praatEXE, 50, 350,
forceRegenerate=True)
# 2 - find the intervals where a name was spoken
nameIntervals = []
targetTier = tg.getTier('word')
for name in nameList:
findMatches = targetTier.find(name)
for i in findMatches:
nameIntervals.append(targetTier.entries[i])
# 3 - isolate the relevant pitch values
matchedIntervals = []
intervalDataList = []
for entry in nameIntervals:
start, stop, label = entry
croppedTier = targetTier.crop(start, stop, "truncated", False)
intervalDataList = croppedTier.getValuesInIntervals(pitchList)
matchedIntervals.extend(intervalDataList)
# 4 - find the maximum value
for interval, subDataList in intervalDataList:
pitchValueList = [pitchV for timeV, pitchV in subDataList]
maxPitch = max(pitchValueList)
outputList.append((wavName, interval, maxPitch))
# Output results
for name, interval, value in outputList:
print((name, interval, value))
('mary.wav', Interval(start=0.3154201182247563, end=0.6755499913498981, label='mary'), 119.56262121912178)
('bobby.wav', Interval(start=0.06469123242311078, end=0.41156462585, label='BOBBY'), 136.1707851512811)
### Operations between Tiers
A lot of functions require a second tier. Two are only useful in specific situations. I'll just introduce them here:
append() is a function on tiers that appends a tier to another one. Could be useful if you are combining two audio files that have been transcribed.
morph() changes the duration of labeled segments in one textgrid to that of another while leaving silences alone and leaving alone the labels. It's used by my ProMo library. Maybe you'll find some other use for it.
Of more general use, there are the functions that do set operations: difference(), intersection(), and union()
# Let's reload everything
from os.path import join
from praatio import textgrid
# We'll use a special textgrid for this purpose
inputFN = join('..', 'examples', 'files', 'damon_set_test.TextGrid')
tg = textgrid.openTextgrid(inputFN, includeEmptyIntervals=False)
# Ok, what are our tiers?
print(tg.tierNames)
('phons', 'syllable', 'tonicVowel', 'tonicSyllable', 'words', 'manually_labeled_pitch_errors')
# Let's take set operations between these two tiers
syllableTier = tg.getTier('tonicSyllable')
errorTier = tg.getTier('manually_labeled_pitch_errors')
print(syllableTier.entries)
print(errorTier.entries)
(Interval(start=0.05127748605468781, end=0.16128645133720465, label='T'), Interval(start=0.3020979268988262, end=0.505, label='T'), Interval(start=0.615, end=0.755, label='T')) (Interval(start=0.06278710646000359, end=0.17536306002462773, label='x'), Interval(start=0.5350436443504402, end=0.649222328635095, label='x'))
# Set difference -- the entries that are not in errorTier are kept
diffTier = syllableTier.difference(errorTier)
diffTier = diffTier.new(name="different")
print(diffTier.entries)
# Set intersection -- the overlapping regions between the two tiers are kept
interTier = syllableTier.intersection(errorTier)
interTier = interTier.new(name="intersection")
print(interTier.entries)
# Set union -- the two tiers are merged
unionTier = syllableTier.union(errorTier)
unionTier = unionTier.new(name="union")
print(unionTier.entries)
(Interval(start=0.05127748605468781, end=0.06278710646000359, label='T'), Interval(start=0.3020979268988262, end=0.505, label='T'), Interval(start=0.649222328635095, end=0.755, label='T')) (Interval(start=0.06278710646000359, end=0.16128645133720465, label='T-x'), Interval(start=0.615, end=0.649222328635095, label='T-x')) (Interval(start=0.05127748605468781, end=0.17536306002462773, label='T-x'), Interval(start=0.3020979268988262, end=0.505, label='T'), Interval(start=0.5350436443504402, end=0.755, label='x-T'))
That output might be a little hard to visualize. Here is what the output looks like in a textgrid:
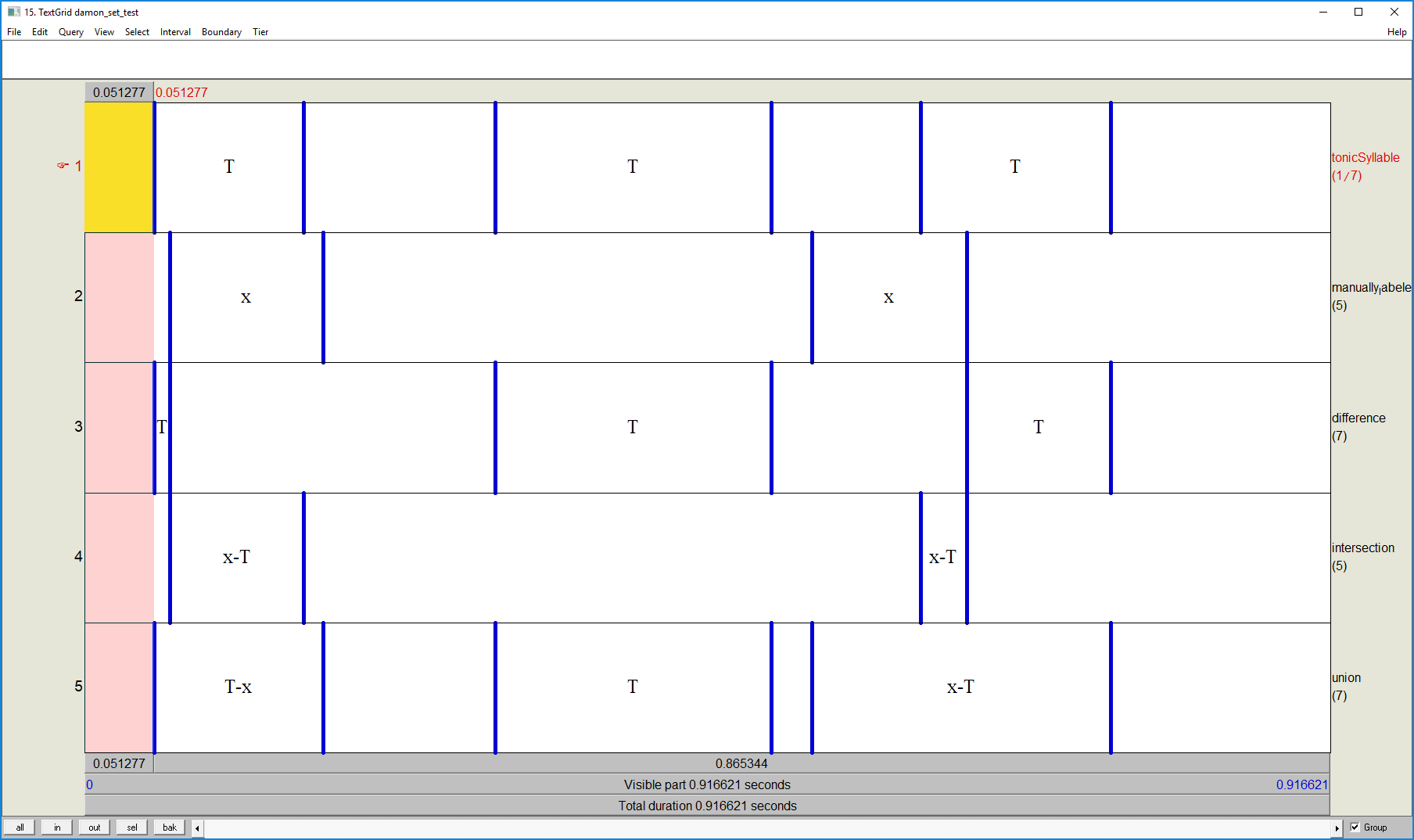
Just for more practice, this textgrid could be generated with code like the following:
outputFN = join('..', 'examples', 'files', 'damon_set_test_output.TextGrid')
setTG = textgrid.Textgrid()
for tier in [syllableTier, errorTier, diffTier, interTier, unionTier]:
setTG.addTier(tier)
setTG.save(outputFN, format="short_textgrid", includeBlankSpaces=True)
## Summary
In this tutorial we covered the basics of working with TextGrids in a programmatic fashion. This tutorial may have given you some ideas for your own project. However, in the next tutorials (which don't exist yet) we'll cover more functionality in praatio which will make it easier to work with real data and might make it clearer how to use textgrid.py.
Stay tuned!
## Beyond PraatIO
I've developed some 'advanced' libraries that extend the functionality of PraatIO but have larger dependencies and might not be of interest to everyone. For these reasons they were spun out as their own thing.
If you've got a cool thing that uses PraatIO, let me know and I can add it to this list!
ProMo¶
ProMo, or Prosody Morph, is a library for resynthesizing the prosodic qualities of speech--in particular the pitch and duration. The key feature is to 'morph' from a source file to a target. The prosodic qualities of one utterance can be superimposed onto another.
Psyle¶
ISLE is an English plain text pronunciation dictionary. It lists pronunciations using the International Phonetic Alphabet and indicates syllables, stress information, and part of speech.
Pysle is a python interface to ISLE. Using it, one can search words based on how they are pronounced or find out information about the canonical way of pronouncing a word.
Pysle has some functionality that depends on PraatIO. For example, one can mark the stressed syllable in a textgrid that has been labeled with words and syllables or phones.