In [21]:
import numpy as np
import pandas as pd
from numpy.random import randn
In [2]:
labels = ['a','b','c']
data = [10,20,30]
arr = np.array(data)
d = {'a':10,'b':20,'c':30}
In [3]:
labels
Out[3]:
['a', 'b', 'c']
In [4]:
data
Out[4]:
[10, 20, 30]
In [5]:
arr
Out[5]:
array([10, 20, 30])
In [6]:
d
Out[6]:
{'a': 10, 'b': 20, 'c': 30}
Criando Series¶
In [7]:
pd.Series(data = data)
Out[7]:
0 10 1 20 2 30 dtype: int64
In [8]:
pd.Series(data=data,index=labels)
Out[8]:
a 10 b 20 c 30 dtype: int64
In [9]:
pd.Series(data,labels)
Out[9]:
a 10 b 20 c 30 dtype: int64
In [10]:
pd.Series(arr)
Out[10]:
0 10 1 20 2 30 dtype: int64
In [11]:
pd.Series(arr,labels)
Out[11]:
a 10 b 20 c 30 dtype: int64
In [12]:
pd.Series(d)
Out[12]:
a 10 b 20 c 30 dtype: int64
In [13]:
pd.Series(data=labels)
Out[13]:
0 a 1 b 2 c dtype: object
In [14]:
pd.Series(data=[sum,print,len])
Out[14]:
0 <built-in function sum> 1 <built-in function print> 2 <built-in function len> dtype: object
Índices¶
In [15]:
ser1 = pd.Series([1,2,3,4],['USA','Russia','China','Japan'])
ser1
Out[15]:
USA 1 Russia 2 China 3 Japan 4 dtype: int64
In [16]:
ser2 = pd.Series([1,2,5,4],['USA','Russia','India','Japan'])
ser2
Out[16]:
USA 1 Russia 2 India 5 Japan 4 dtype: int64
In [17]:
ser1['USA']
Out[17]:
1
In [18]:
ser3 = pd.Series(data=labels)
ser3
Out[18]:
0 a 1 b 2 c dtype: object
In [19]:
ser3[0]
Out[19]:
'a'
In [20]:
ser1 + ser2
Out[20]:
China NaN India NaN Japan 8.0 Russia 4.0 USA 2.0 dtype: float64
DataFrames¶
In [22]:
np.random.seed(101)
In [23]:
df = pd.DataFrame(randn(5,4),['A','B','C','D','E'],['W','X','Y','Z'])
In [24]:
df
Out[24]:
| W | X | Y | Z | |
|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [25]:
df['W']
Out[25]:
A 2.706850 B 0.651118 C -2.018168 D 0.188695 E 0.190794 Name: W, dtype: float64
In [26]:
type(df['W'])
Out[26]:
pandas.core.series.Series
In [27]:
type(df)
Out[27]:
pandas.core.frame.DataFrame
In [28]:
df.W
Out[28]:
A 2.706850 B 0.651118 C -2.018168 D 0.188695 E 0.190794 Name: W, dtype: float64
In [30]:
df[['W','Z']]
Out[30]:
| W | Z | |
|---|---|---|
| A | 2.706850 | 0.503826 |
| B | 0.651118 | 0.605965 |
| C | -2.018168 | -0.589001 |
| D | 0.188695 | 0.955057 |
| E | 0.190794 | 0.683509 |
In [31]:
df['new'] = df['W'] + df['Y']
df['new']
Out[31]:
A 3.614819 B -0.196959 C -1.489355 D -0.744542 E 2.796762 Name: new, dtype: float64
In [32]:
df
Out[32]:
| W | X | Y | Z | new | |
|---|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 | 3.614819 |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 | -0.196959 |
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 | -1.489355 |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 | -0.744542 |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 | 2.796762 |
In [34]:
df.drop('new', axis=1, inplace=True) # 1 refere-se ao eixo das colunas
In [35]:
df
Out[35]:
| W | X | Y | Z | |
|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [36]:
df.drop('E') # 0 refere-se ao eixo das linhas, definido como padrão
Out[36]:
| W | X | Y | Z | |
|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
In [37]:
df.shape
Out[37]:
(5, 4)
Selecionando Linhas¶
In [41]:
df.loc['C']
Out[41]:
W -2.018168 X 0.740122 Y 0.528813 Z -0.589001 Name: C, dtype: float64
In [42]:
df.iloc[2] # Localiza por posição numérica, mesmo os índices sendo strings
Out[42]:
W -2.018168 X 0.740122 Y 0.528813 Z -0.589001 Name: C, dtype: float64
In [43]:
df.loc['B','Y']
Out[43]:
-0.8480769834036315
In [44]:
df.loc[['A','B'],['W','Y']]
Out[44]:
| W | Y | |
|---|---|---|
| A | 2.706850 | 0.907969 |
| B | 0.651118 | -0.848077 |
Condições¶
In [46]:
booldf = df > 0
In [47]:
df[booldf]
Out[47]:
| W | X | Y | Z | |
|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| B | 0.651118 | NaN | NaN | 0.605965 |
| C | NaN | 0.740122 | 0.528813 | NaN |
| D | 0.188695 | NaN | NaN | 0.955057 |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [48]:
df['W'] > 0
Out[48]:
A True B True C False D True E True Name: W, dtype: bool
In [49]:
df[df['W'] > 0]
Out[49]:
| W | X | Y | Z | |
|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [50]:
df[df['Z'] < 0]
Out[50]:
| W | X | Y | Z | |
|---|---|---|---|---|
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
In [51]:
df[df['W'] > 0][['Y','X']]
Out[51]:
| Y | X | |
|---|---|---|
| A | 0.907969 | 0.628133 |
| B | -0.848077 | -0.319318 |
| D | -0.933237 | -0.758872 |
| E | 2.605967 | 1.978757 |
In [52]:
df[df['W'] < 0][['Y','X']]
Out[52]:
| Y | X | |
|---|---|---|
| C | 0.528813 | 0.740122 |
In [53]:
df[(df['W'] > 0) & (df['Y'] > 1)] # and
Out[53]:
| W | X | Y | Z | |
|---|---|---|---|---|
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [59]:
df[(df['W'] > 0) | (df['Y'] > 1)] # or
Out[59]:
| W | X | Y | Z | States | |
|---|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 | CA |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 | NY |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 | OR |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 | CO |
Índices¶
In [54]:
df.reset_index() # não ocorre in_place
Out[54]:
| index | W | X | Y | Z | |
|---|---|---|---|---|---|
| 0 | A | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| 1 | B | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| 2 | C | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
| 3 | D | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
| 4 | E | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
In [55]:
new_index = 'CA NY WY OR CO'.split()
new_index
Out[55]:
['CA', 'NY', 'WY', 'OR', 'CO']
In [56]:
df['States'] = new_index
In [57]:
df
Out[57]:
| W | X | Y | Z | States | |
|---|---|---|---|---|---|
| A | 2.706850 | 0.628133 | 0.907969 | 0.503826 | CA |
| B | 0.651118 | -0.319318 | -0.848077 | 0.605965 | NY |
| C | -2.018168 | 0.740122 | 0.528813 | -0.589001 | WY |
| D | 0.188695 | -0.758872 | -0.933237 | 0.955057 | OR |
| E | 0.190794 | 1.978757 | 2.605967 | 0.683509 | CO |
In [58]:
df.set_index('States') # não ocorre in_place
Out[58]:
| W | X | Y | Z | |
|---|---|---|---|---|
| States | ||||
| CA | 2.706850 | 0.628133 | 0.907969 | 0.503826 |
| NY | 0.651118 | -0.319318 | -0.848077 | 0.605965 |
| WY | -2.018168 | 0.740122 | 0.528813 | -0.589001 |
| OR | 0.188695 | -0.758872 | -0.933237 | 0.955057 |
| CO | 0.190794 | 1.978757 | 2.605967 | 0.683509 |
Hierarquia de Índices¶
In [63]:
fora = ['G1', 'G1', 'G1', 'G2', 'G2', 'G2']
dentro = [1,2,3,1,2,3]
In [64]:
hier_index = list(zip(fora,dentro))
hier_index
Out[64]:
[('G1', 1), ('G1', 2), ('G1', 3), ('G2', 1), ('G2', 2), ('G2', 3)]
In [66]:
hier_index = pd.MultiIndex.from_tuples(hier_index)
hier_index
Out[66]:
MultiIndex(levels=[['G1', 'G2'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 1], [0, 1, 2, 0, 1, 2]])
In [67]:
df = pd.DataFrame(randn(6,2), hier_index, ['A','B'])
In [68]:
df
Out[68]:
| A | B | ||
|---|---|---|---|
| G1 | 1 | 0.302665 | 1.693723 |
| 2 | -1.706086 | -1.159119 | |
| 3 | -0.134841 | 0.390528 | |
| G2 | 1 | 0.166905 | 0.184502 |
| 2 | 0.807706 | 0.072960 | |
| 3 | 0.638787 | 0.329646 |
Chamando Dados de um Índice de Múltiplos Níveis¶
In [70]:
df.loc['G1']
Out[70]:
| A | B | |
|---|---|---|
| 1 | 0.302665 | 1.693723 |
| 2 | -1.706086 | -1.159119 |
| 3 | -0.134841 | 0.390528 |
In [71]:
df.index.names = ['Grupos','Numeros']
In [72]:
df
Out[72]:
| A | B | ||
|---|---|---|---|
| Grupos | Numeros | ||
| G1 | 1 | 0.302665 | 1.693723 |
| 2 | -1.706086 | -1.159119 | |
| 3 | -0.134841 | 0.390528 | |
| G2 | 1 | 0.166905 | 0.184502 |
| 2 | 0.807706 | 0.072960 | |
| 3 | 0.638787 | 0.329646 |
In [73]:
df.loc['G2'].loc[2]['B']
Out[73]:
0.07295967531703869
In [74]:
df.xs('G1')
Out[74]:
| A | B | |
|---|---|---|
| Numeros | ||
| 1 | 0.302665 | 1.693723 |
| 2 | -1.706086 | -1.159119 |
| 3 | -0.134841 | 0.390528 |
In [76]:
df.xs(1,level='Numeros') # Linhas com Numeros = 1
Out[76]:
| A | B | |
|---|---|---|
| Grupos | ||
| G1 | 0.302665 | 1.693723 |
| G2 | 0.166905 | 0.184502 |
Dados Faltantes¶
In [77]:
dic = {'A':[1,2,np.nan],'B':[5,np.nan,np.nan],'C':[1,2,3]}
In [79]:
dados = pd.DataFrame(dic)
dados
Out[79]:
| A | B | C | |
|---|---|---|---|
| 0 | 1.0 | 5.0 | 1 |
| 1 | 2.0 | NaN | 2 |
| 2 | NaN | NaN | 3 |
In [81]:
dados.dropna() # por padrão o eixo é 0, ou seja, linhas
Out[81]:
| A | B | C | |
|---|---|---|---|
| 0 | 1.0 | 5.0 | 1 |
In [82]:
dados.dropna(axis=1)
Out[82]:
| C | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
In [85]:
dados.dropna(thresh=2)
# necessário ter pelo menos 2 NaN para a linha ser removida
Out[85]:
| A | B | C | |
|---|---|---|---|
| 0 | 1.0 | 5.0 | 1 |
| 1 | 2.0 | NaN | 2 |
In [87]:
dados.fillna(value='Nulo')
Out[87]:
| A | B | C | |
|---|---|---|---|
| 0 | 1 | 5 | 1 |
| 1 | 2 | Nulo | 2 |
| 2 | Nulo | Nulo | 3 |
In [88]:
dados['A'].fillna(value=df['A'].mean())
Out[88]:
0 1.000000 1 2.000000 2 0.012523 Name: A, dtype: float64
Agrupando Dados¶
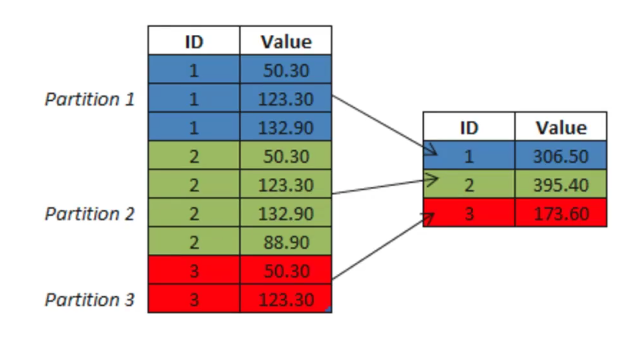
In [93]:
data = {'Company':['GOOG','GOOG','MSFT','MSFT','FB','FB'],
'Person':['Sam','Charlie','Amy','Vanessa','Carl','Sarah'],
'Sales':[200,120,340,124,243,350]}
In [94]:
df = pd.DataFrame(data)
df
Out[94]:
| Company | Person | Sales | |
|---|---|---|---|
| 0 | GOOG | Sam | 200 |
| 1 | GOOG | Charlie | 120 |
| 2 | MSFT | Amy | 340 |
| 3 | MSFT | Vanessa | 124 |
| 4 | FB | Carl | 243 |
| 5 | FB | Sarah | 350 |
In [95]:
comp = df.groupby('Company')
comp.mean()
Out[95]:
| Sales | |
|---|---|
| Company | |
| FB | 296.5 |
| GOOG | 160.0 |
| MSFT | 232.0 |
In [96]:
comp.sum()
Out[96]:
| Sales | |
|---|---|
| Company | |
| FB | 593 |
| GOOG | 320 |
| MSFT | 464 |
In [97]:
comp.std()
Out[97]:
| Sales | |
|---|---|
| Company | |
| FB | 75.660426 |
| GOOG | 56.568542 |
| MSFT | 152.735065 |
In [98]:
comp.sum().loc['FB']
Out[98]:
Sales 593 Name: FB, dtype: int64
In [99]:
df.groupby('Company').count()
Out[99]:
| Person | Sales | |
|---|---|---|
| Company | ||
| FB | 2 | 2 |
| GOOG | 2 | 2 |
| MSFT | 2 | 2 |
In [100]:
df.groupby('Company').max()
Out[100]:
| Person | Sales | |
|---|---|---|
| Company | ||
| FB | Sarah | 350 |
| GOOG | Sam | 200 |
| MSFT | Vanessa | 340 |
In [102]:
df.groupby('Company').describe()
Out[102]:
| Sales | ||||||||
|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | |
| Company | ||||||||
| FB | 2.0 | 296.5 | 75.660426 | 243.0 | 269.75 | 296.5 | 323.25 | 350.0 |
| GOOG | 2.0 | 160.0 | 56.568542 | 120.0 | 140.00 | 160.0 | 180.00 | 200.0 |
| MSFT | 2.0 | 232.0 | 152.735065 | 124.0 | 178.00 | 232.0 | 286.00 | 340.0 |
In [103]:
df.groupby('Company').describe().transpose()
Out[103]:
| Company | FB | GOOG | MSFT | |
|---|---|---|---|---|
| Sales | count | 2.000000 | 2.000000 | 2.000000 |
| mean | 296.500000 | 160.000000 | 232.000000 | |
| std | 75.660426 | 56.568542 | 152.735065 | |
| min | 243.000000 | 120.000000 | 124.000000 | |
| 25% | 269.750000 | 140.000000 | 178.000000 | |
| 50% | 296.500000 | 160.000000 | 232.000000 | |
| 75% | 323.250000 | 180.000000 | 286.000000 | |
| max | 350.000000 | 200.000000 | 340.000000 |
Merging, Joining e Concatenating¶
In [105]:
df1 = pd.DataFrame({'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']},
index=[0,1,2,3])
df1
Out[105]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
In [106]:
df2 = pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7'],
'D':['D4','D5','D6','D7']},
index=[4,5,6,7])
df2
Out[106]:
| A | B | C | D | |
|---|---|---|---|---|
| 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 |
| 6 | A6 | B6 | C6 | D6 |
| 7 | A7 | B7 | C7 | D7 |
In [107]:
df3 = pd.DataFrame({'A':['A8','A9','A10','A11'],
'B':['B8','B9','B10','B11'],
'C':['C8','C9','C10','C11'],
'D':['D8','D9','D10','D11']},
index=[8,9,10,11])
df3
Out[107]:
| A | B | C | D | |
|---|---|---|---|---|
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
Concatenação¶
Concatenção basicamente conecta os DataFrames. Tenha em mente que a dimensão deve corresponder ao longo do eixo que você está concatenando.
In [108]:
pd.concat([df1,df2,df3])
Out[108]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 |
| 6 | A6 | B6 | C6 | D6 |
| 7 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
In [109]:
pd.concat([df1,df2,df3], axis=1)
Out[109]:
| A | B | C | D | A | B | C | D | A | B | C | D | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | D2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | A3 | B3 | C3 | D3 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN | A4 | B4 | C4 | D4 | NaN | NaN | NaN | NaN |
| 5 | NaN | NaN | NaN | NaN | A5 | B5 | C5 | D5 | NaN | NaN | NaN | NaN |
| 6 | NaN | NaN | NaN | NaN | A6 | B6 | C6 | D6 | NaN | NaN | NaN | NaN |
| 7 | NaN | NaN | NaN | NaN | A7 | B7 | C7 | D7 | NaN | NaN | NaN | NaN |
| 8 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | A8 | B8 | C8 | D8 |
| 9 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | A9 | B9 | C9 | D9 |
| 10 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | A10 | B10 | C10 | D10 |
| 11 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | A11 | B11 | C11 | D11 |
Exemplos¶
In [110]:
left = pd.DataFrame({'key': ['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key': ['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
In [111]:
left
Out[111]:
| key | A | B | |
|---|---|---|---|
| 0 | K0 | A0 | B0 |
| 1 | K1 | A1 | B1 |
| 2 | K2 | A2 | B2 |
| 3 | K3 | A3 | B3 |
In [112]:
right
Out[112]:
| key | C | D | |
|---|---|---|---|
| 0 | K0 | C0 | D0 |
| 1 | K1 | C1 | D1 |
| 2 | K2 | C2 | D2 |
| 3 | K3 | C3 | D3 |
Merging¶
A função merge permite você unir DataFrames usando uma lógica similar ao SQL merging de tabelas. Exemplos:
In [113]:
pd.merge(left,right,how='inner',on='key')
Out[113]:
| key | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | A1 | B1 | C1 | D1 |
| 2 | K2 | A2 | B2 | C2 | D2 |
| 3 | K3 | A3 | B3 | C3 | D3 |
In [114]:
left = pd.DataFrame({'key1': ['K0','K0','K1','K2'],
'key2': ['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'key1': ['K0','K1','K1','K2'],
'key2': ['K0','K0','K0','K0'],
'A':['C0','C1','C2','C3'],
'B':['D0','D1','D2','D3']})
In [115]:
pd.merge(left,right,on=['key1','key2'])
Out[115]:
| key1 | key2 | A_x | B_x | A_y | B_y | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
In [116]:
pd.merge(left,right,how='outer',on=['key1','key2'])
Out[116]:
| key1 | key2 | A_x | B_x | A_y | B_y | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
| 5 | K2 | K0 | NaN | NaN | C3 | D3 |
In [117]:
pd.merge(left, right, how='right', on=['key1','key2'])
Out[117]:
| key1 | key2 | A_x | B_x | A_y | B_y | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
| 3 | K2 | K0 | NaN | NaN | C3 | D3 |
In [118]:
pd.merge(left, right, how='left', on=['key1','key2'])
Out[118]:
| key1 | key2 | A_x | B_x | A_y | B_y | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
Joining¶
Joining é um método conveniente para combinar as colunas em potencial dois DataFrames de índices diferentes em um único resultante DataFrame
In [120]:
left = pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']},
index=['K0','K1','K2'])
right = pd.DataFrame({'C':['C0','C1','C2'],
'D':['D0','D1','D2']},
index=['K0','K2','K3'])
In [121]:
left.join(right)
Out[121]:
| A | B | C | D | |
|---|---|---|---|---|
| K0 | A0 | B0 | C0 | D0 |
| K1 | A1 | B1 | NaN | NaN |
| K2 | A2 | B2 | C1 | D1 |
In [122]:
left.join(right,how='outer')
Out[122]:
| A | B | C | D | |
|---|---|---|---|---|
| K0 | A0 | B0 | C0 | D0 |
| K1 | A1 | B1 | NaN | NaN |
| K2 | A2 | B2 | C1 | D1 |
| K3 | NaN | NaN | C2 | D2 |
Operações¶
In [123]:
df = pd.DataFrame({'col1':[1,2,3,4],
'col2':[444,555,666,444],
'col3':['abc','def','ghi','xyz']})
df.head()
Out[123]:
| col1 | col2 | col3 | |
|---|---|---|---|
| 0 | 1 | 444 | abc |
| 1 | 2 | 555 | def |
| 2 | 3 | 666 | ghi |
| 3 | 4 | 444 | xyz |
In [124]:
df['col2'].unique()
Out[124]:
array([444, 555, 666])
In [126]:
df['col2'].nunique()
Out[126]:
3
In [128]:
df['col2'].value_counts()
Out[128]:
444 2 555 1 666 1 Name: col2, dtype: int64
In [129]:
def times(x):
return x*2
In [130]:
df['col1'].apply(times) # Aplicando a função times
Out[130]:
0 2 1 4 2 6 3 8 Name: col1, dtype: int64
In [131]:
df['col3'].apply(len)
Out[131]:
0 3 1 3 2 3 3 3 Name: col3, dtype: int64
In [133]:
df['col2'].apply(lambda x: x*3)
Out[133]:
0 1332 1 1665 2 1998 3 1332 Name: col2, dtype: int64
In [134]:
df.drop('col1',axis=1)
Out[134]:
| col2 | col3 | |
|---|---|---|
| 0 | 444 | abc |
| 1 | 555 | def |
| 2 | 666 | ghi |
| 3 | 444 | xyz |
In [138]:
df.columns
Out[138]:
Index(['col1', 'col2', 'col3'], dtype='object')
In [139]:
df.index
Out[139]:
RangeIndex(start=0, stop=4, step=1)
In [141]:
df.sort_values(by='col2')
Out[141]:
| col1 | col2 | col3 | |
|---|---|---|---|
| 0 | 1 | 444 | abc |
| 3 | 4 | 444 | xyz |
| 1 | 2 | 555 | def |
| 2 | 3 | 666 | ghi |
In [142]:
df.isnull()
Out[142]:
| col1 | col2 | col3 | |
|---|---|---|---|
| 0 | False | False | False |
| 1 | False | False | False |
| 2 | False | False | False |
| 3 | False | False | False |
In [145]:
data = {'A':['foo','foo','foo','bar','bar','bar'],
'B':['one','one','two','two','one','one'],
'C':['x','y','x','y','x','y'],
'D':[1,3,2,5,4,1]}
df = pd.DataFrame(data)
df
Out[145]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | x | 1 |
| 1 | foo | one | y | 3 |
| 2 | foo | two | x | 2 |
| 3 | bar | two | y | 5 |
| 4 | bar | one | x | 4 |
| 5 | bar | one | y | 1 |
In [146]:
df.pivot_table(values='D', index=['A','B'], columns='C')
Out[146]:
| C | x | y | |
|---|---|---|---|
| A | B | ||
| bar | one | 4.0 | 1.0 |
| two | NaN | 5.0 | |
| foo | one | 1.0 | 3.0 |
| two | 2.0 | NaN |
In [147]:
pwd
Out[147]:
'/home/talantyr/Documentos/Projetos/Python Data Science'
In [148]:
pd.read_csv('example')
Out[148]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [149]:
df = pd.read_csv('example')
df
Out[149]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [150]:
df.to_csv('new_example',index=False)
pd.read_csv('new_example')
Out[150]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [152]:
pd.read_excel('Excel_Sample.xlsx',sheet_name='Sheet1')
Out[152]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [153]:
df.to_excel('New_Excel_Sample.xlsx',sheet_name='NewSheet')
In [154]:
data = pd.read_html('https://www.fdic.gov/bank/individual/failed/banklist.html')
In [155]:
type(data)
Out[155]:
list
In [158]:
data[0].head()
Out[158]:
| Bank Name | City | ST | CERT | Acquiring Institution | Closing Date | Updated Date | |
|---|---|---|---|---|---|---|---|
| 0 | The Enloe State Bank | Cooper | TX | 10716 | Legend Bank, N. A. | May 31, 2019 | June 18, 2019 |
| 1 | Washington Federal Bank for Savings | Chicago | IL | 30570 | Royal Savings Bank | December 15, 2017 | February 1, 2019 |
| 2 | The Farmers and Merchants State Bank of Argonia | Argonia | KS | 17719 | Conway Bank | October 13, 2017 | February 21, 2018 |
| 3 | Fayette County Bank | Saint Elmo | IL | 1802 | United Fidelity Bank, fsb | May 26, 2017 | January 29, 2019 |
| 4 | Guaranty Bank, (d/b/a BestBank in Georgia & Mi... | Milwaukee | WI | 30003 | First-Citizens Bank & Trust Company | May 5, 2017 | March 22, 2018 |
In [159]:
from sqlalchemy import create_engine
In [161]:
engine = create_engine('sqlite:///:memory:') # Banco de dados em memória
In [162]:
df.to_sql('tabela',engine)
In [163]:
sqldf = pd.read_sql('tabela', con=engine)
In [164]:
sqldf
Out[164]:
| index | a | b | c | d | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2 | 3 |
| 1 | 1 | 4 | 5 | 6 | 7 |
| 2 | 2 | 8 | 9 | 10 | 11 |
| 3 | 3 | 12 | 13 | 14 | 15 |