cs1001.py , Tel Aviv University, Spring 2019
Recitation 8¶
We reviewed some properties of prime numbers and used them for primality testing. We reviewed the Diffie-Hellman protocol for finding a shared secret key and also tried to crack it. Then, we discussed Linked lists.
Takeaways:¶
The probabilistic function is_prime, that uses Fermat's primality test, can be used to detect primes quickly and efficiently, but has a (very small) probability of error. Its time complexity is $O(n^3)$, where $n$ is the number of bits of the input.
The DH protocol relies on two main principles: the following equality $(g^{a}\mod p)^b \mod p = g^{ab} \mod p $ and the (believed) hardness of the discrete log problem (given $g,p$, and $x = g^{a} \mod p$ finding $a$ is hard). Make sure you understand the details of the protocol.
OOP allows us to create classes at will and to define complex objects. Remember that the most important thing is to find a good inner representation of the object so that you will have an easy time working with it.
Important properties of Linked lists:
- Not stored continuously in memory.
- Allows for deletion and insertion after a given element in $O(1)$ time.
- Accessing the $i$'th element takes $O(i)$ time.
- Search takes $O(n)$ time (no random access $\implies$ no $O(\log{n})$ search).
Code for printing several outputs in one cell (not part of the recitation):¶
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
Primes and Diffie-Hellman¶
Fermat's little theorem¶
Fermat's little theorem states that if $p$ is prime and $1 < a < p$, then $a^{p-1} (\textrm{mod}\ p) \equiv 1$
Compositeness witnesses¶
A witness is a piece of evidence that can be produced in order to prove a claim. In our case, the problem we are tackling is deciding whether a given number $m$ is prime or composite. We now describe three types of witnesses for compositeness:
- A clear witness for compositeness can be a (not necessarily prime) factor of $m$. That is, a number $1 < b < m$ such that $b ~|~ m$ ($b$ divides $m$). Since $b$ is a non-trivial factor of $m$, $m$ is clearly composite.
- Another, less trivial witness of compositeness is a GCD witness, that is a number $1 < b < m$ such that $\mathrm{gcd}(m,b) > 1$. Think, why is $b$ a witness of compositeness? Let $\mathrm{gcd}(m,b) = r$, then by definition $r ~|~ n$. As $r \leq b < m$ we get that $r$ is a factor of $m$ and thus $m$ is composite.
- Fermat's primality test defines another set of witness of compositeness - a number $1 < a < m$ is a Fermat witness if $a^{m-1} (\textrm{mod}\ m) \not\equiv 1$
Why go through all of this work? Our tactic would be to randomly draw a number $b \in {1,\ldots, m - 1}$ and hope that $b$ is some witness of compositeness. Clearly, we'd like our witness pool to be as large as possible.
Now, if $m$ is a composite number, let $\mathrm{FACT}_m, \mathrm{GCD}_m, \mathrm{FERM}_m$ be the set of prime factors, GCD witnesses and Fermat witnesses for $m$'s compositeness. It is not hard to show that $$\mathrm{FACT}_m \subseteq \mathrm{GCD}_m \subseteq \mathrm{FERM}_m$$
But the real strength of Fermat's primality test comes from the fact that if $m$ is composite, then apart from very rare cases (where $n$ is a Carmichael number) it holds that $|\mathrm{FERM}_m| \geq m/2$. That is - a random number is a Fermat witness w.p. at least $1/2$.
A side note (for reference only) - Carmichael numbers are exactly the composite numbers $m$ where $\mathrm{GCD}_m = \mathrm{FERM}_m$
Every factor of a composite number is a Fermat's witness¶
Let $m$ be a composite number and write $m = ab$ for some $a,b>1$. We claim that $a$ is a Fermat witness. To see this, assume towards contradiction that $a^{m-1} (\textrm{mod}\ m) \equiv 1$, i.e. $a^{m-1} = c\cdot m + 1= c \cdot a \cdot b + 1$ for some $c \geq 1$.
Rearrange the above to get $a(a^{m-2} - c\cdot b) = 1$. However, $a > 1$ and $(a^{m-2} - c\cdot b) \in \mathbb{Z}$, a contradiction.
Primality test using Fermat's witness¶
We can use Fermat's little theorem in order test whether a given number $m$ is prime. That is, we can test whether we find a Fermat's witness $a\in\mathrm{FERM}_m$ for compositeness. Note that if the number has $n$ bits than testing all possible $a$-s will require $O(2^n)$ iterations (a lot!).
Instead, we will try 100 random $a$-s in the range and see if one works as a Fermat's witness.
import random
def is_prime(m, show_witness=False):
""" probabilistic test for m's compositeness """''
for i in range(0, 100):
a = random.randint(1, m - 1) # a is a random integer in [1..m-1]
if pow(a, m - 1, m) != 1:
if show_witness: # caller wishes to see a witness
print(m, "is composite", "\n", a, "is a witness, i=", i + 1)
return False
return True
For $a,b,c$ of at most $n$ bits each, time complexity of modpower is $O(n^3)$
def modpower(a, b, c):
""" computes a**b modulo c, using iterated squaring """
result = 1
while b > 0: # while b is nonzero
if b % 2 == 1: # b is odd
result = (result * a) % c
a = (a*a) % c
b = b // 2
return result
Runtime analysis:¶
- The main loop runs over $b$, dividing $b \to b/2$ at each iteration, so it runs $O(n)$ times.
- In each iteration we do:
- One operation of $b~\%~2$ in $O(1)$ time (check least significant bit of $b$)
- One operation of $b~//~2$ in $O(1)$ time (snip $b$'s least significant bit)
- At most two multiplication and two modulu operations
- Multiplication of two $n$ bit numbers runs in time $O(n^2)$
- Modulu can be implemented by addition, division and multiplication: $a \textrm{ mod } b = a - (a // b) b$ and division runs in time $O(n^2)$ same as multiplication
- Finally, the modulu operation keeps all numbers at most $n$ bits, thus the running time does not increase with each iteration
- In total - $O(n^3)$
The probability of error:¶
First, notice that if the function says that an input number $m$ is not prime, then it is true. Stated the other way around, if $m$ is prime, the function is always right.
The function can make a mistake only in the case where a number $m$ is not prime, and is accidentally categorized by the function as prime. This can happen if all $100$ $a$'s that the function had drawn were not witnesses.
A quick computation shows that if $m$ is not a Charmichael number then at least $\frac{1}{2}$ of all possible $a$s are witnesses, so in almost all cases the probability for error is $(\frac{1}{2})^{100}$ (which is negligible).
Testing the prime number theorem: For a large n, a number of n bits is prime with a prob. of O(1/n)¶
We decide on the size of the sample (to avoid testing all possible $2^{n-1}$ numbers of $n$ bits) and test whether each number we sample is prime. Then we divide the number of primes with the size of the sample.
def prob_prime(n, sample):
cnt = 0
for i in range(sample):
m = random.randint(2**(n-1), 2**n - 1)
cnt += is_prime(m)
return cnt / sample
prob_prime(2, 10**4)
prob_prime(3, 10**4)
1.0
0.5057
prob_prime(100, 10**4)
0.0148
prob_prime(200, 10**4)
0.0081
Diffie Hellman from lecture
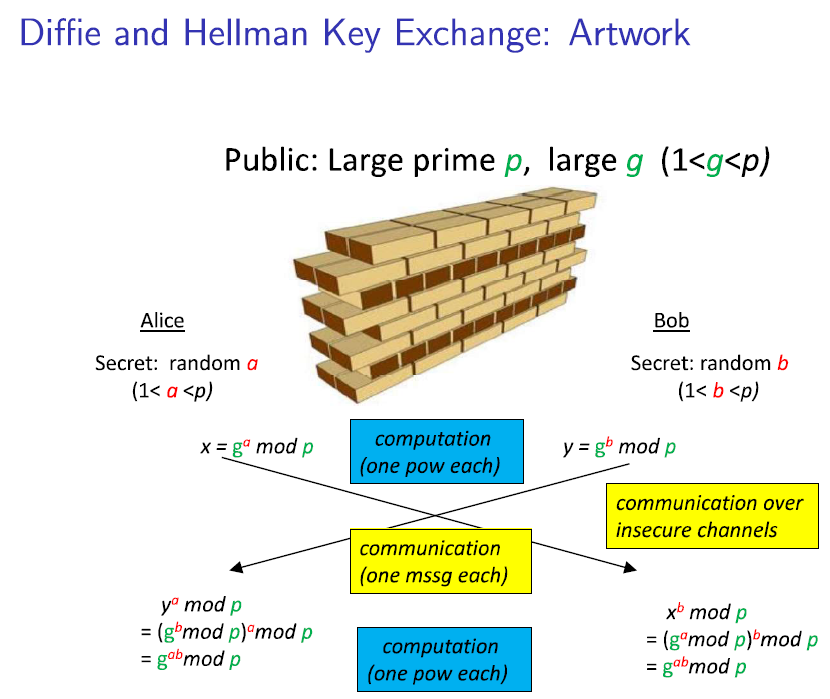
The protocol as code¶
def DH_exchange(p):
""" generates a shared DH key """
g = random.randint(1, p - 1)
a = random.randint(1, p - 1) #Alice's secret
b = random.randint(1, p - 1) #Bob's secret
x = pow(g, a, p)
y = pow(g, b, p)
key_A = pow(y, a, p)
key_B = pow(x, b, p)
#the next line is different from lecture
return g, a, b, x, y, key_A #key_A=key_B
Find a prime number¶
def find_prime(n):
""" find random n-bit long prime """
while(True):
candidate = random.randrange(2**(n-1), 2**n)
if is_prime(candidate):
return candidate
Demostration:
import random
p = find_prime(10)
print(p)
g, a, b, x, y, key = DH_exchange(p)
g, a, b, x, y, key
557
(247, 88, 353, 367, 2, 206)
print(pow(g, a, p))
print(pow(x, b, p))
367 206
Crack the Diffie Hellman code¶
There is no known way to find $a$ efficiently, so we try the naive one: iterating over all $a$-s and cheking whether the equation $g^a \mod p = x$ holds for them.
If we found $a'$ that satisfies the condition but is not the original $a$, does it matter?
The time complexity of crack_DH is $O(2^nn^3)$
def crack_DH(p, g, x):
''' find secret "a" that satisfies g**a%p == x
Not feasible for large p '''
for a in range(1, p - 1):
if a % 100000 == 0:
print(a) #just to estimate running time
if pow(g, a, p) == x:
return a
return None #should never get here
#g, a, b, x, y, key = DH_exchange(p)
print(a)
crack_DH(p, g, x)
88
88
Cracking DH with different values of $a$ (different private keys)¶
The algorithm crack_DH can return a different private key ($a$) than the one chosen by Alice, i.e. - $crack\_DH(p,g,x) = a' \neq a$, however, in this case we have, by definition of the cracking algorithm: $g^{a'} \textrm{ mod } p = g^{a} \textrm{ mod } p$, thus:
$$y^{a'} \textrm{ mod } p = \left(g^{b}\right)^{a'} \textrm{ mod } p = \left(g^{a'}\right)^{b} \textrm{ mod } p = \left(g^{a} \textrm{ mod } p \right)^{b} \textrm{ mod } p = g^{ab} \textrm{ mod } p$$I.e. - we can still compute the shared secret!
Trying to crack the protocol with a 100 bit prime¶
import random
p = find_prime(100)
print(p)
g, a, b, x, y, key = DH_exchange(p)
print(g, a, b, x, y, key)
crack_DH(p, g, x)
870752849128025769690613494727 556076925348494470910111020503 563975178376164531572554628719 591095820882694542257093278496 683629518338524578223612745129 622210352872361792591098681438 318844905364032174750094749602 100000 200000 300000 400000 500000 600000
--------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) <ipython-input-26-6b3d13779c00> in <module> 5 print(g, a, b, x, y, key) 6 ----> 7 crack_DH(p, g, x) <ipython-input-17-9a63fe3af2e8> in crack_DH(p, g, x) 3 Not feasible for large p ''' 4 for a in range(1, p - 1): ----> 5 if a % 100000 == 0: 6 print(a) #just to estimate running time 7 if pow(g, a, p) == x: KeyboardInterrupt:
Analyzing the nubmer of years it will take to crack the protocol if $a$ is found at the end (assuming iterating over 100000 $a$s takes a second)
a
563975178376164531572554628719
a//100000/60/60/24/365
1.7883535590314707e+17
Linked Lists¶
A linked list is a linear data structure (i.e. - nodes can be accessed one after the other). The list is composed of nodes, where each node contains a value and a "pointer" to the next node in the list.
Linked lists support operations such as insertion, deletion, search and many more.
class Node():
def __init__(self, val):
self.value = val
self.next = None
def __repr__(self):
#return str(self.value)
#for today's recitation, we print the id of self as well
return str(self.value) + "(" + str(id(self))+ ")"
class Linked_list():
def __init__(self, seq=None):
self.next = None
self.len = 0
if seq != None:
for x in seq[::-1]:
self.add_at_start(x)
def __repr__(self):
out = ""
p = self.next
while p != None :
out += str(p) + ", " # str(p) envokes __repr__ of class Node
p = p.next
return "[" + out[:-2] + "]"
def __len__(self):
''' called when using Python's len() '''
return self.len
def add_at_start(self, val):
''' add node with value val at the list head '''
p = self
tmp = p.next
p.next = Node(val)
p.next.next = tmp
self.len += 1
def add_at_end(self, val):
''' add node with value val at the list tail '''
p = self
while (p.next != None):
p = p.next
p.next = Node(val)
self.len += 1
def insert(self, loc, val):
''' add node with value val after location 0<=loc<len of the list '''
assert 0 <= loc < len(self)
p = self
for i in range(0, loc):
p = p.next
tmp = p.next
p.next = Node(val)
p.next.next = tmp
self.len += 1
def __getitem__(self, loc):
''' called when using L[i] for reading
return node at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self.next
for i in range(0, loc):
p = p.next
return p
def __setitem__(self, loc, val):
''' called when using L[loc]=val for writing
assigns val to node at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self.next
for i in range(0, loc):
p = p.next
p.value = val
return None
def find(self, val):
''' find (first) node with value val in list '''
p = self.next
# loc = 0 # in case we want to return the location
while p != None:
if p.value == val:
return p
else:
p = p.next
#loc=loc+1 # in case we want to return the location
return None
def delete(self, loc):
''' delete element at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self
for i in range(0, loc):
p = p.next
# p is the element BEFORE loc
p.next = p.next.next
self.len -= 1
def insert_ordered(self, val):
''' assume self is an ordered list,
insert Node with val in order '''
p = self
q = self.next
while q != None and q.value < val:
p = q
q = q.next
newNode = Node(val)
p.next = newNode
newNode.next = q
self.len += 1
def find_ordered(self, val):
''' assume self is an ordered list,
find Node with value val '''
p = self.next
while p != None and p.value < val:
p = p.next
if p != None and p.value == val:
return p
else:
return None
Converting a string to a list
L= Linked_list("abc")
L
[a(2165820022568), b(2165820022736), c(2165820022624)]
Memory View¶

Adding elements one by one. Try using Python tutor.
l = Linked_list()
l.add_at_start("a")
l.add_at_start("b")
l
[b(2165819893856), a(2165819894528)]
A short summary of methods complexity of Linked lists vs. lists:¶
| Method | List | Linked list |
| init | $O(1)$ | $O(1)$ |
| init with $k$ items | $O(k)$ | $O(k)$ |
| for the rest of the methods we assume that the structure contains $n$ items | ||
| add at start | $O(n)$ | $O(1)$ |
| add at end | $O(1)$ | $O(n)$ |
| $lst[k]$ (get the $k$th item) | $O(1)$ | $O(k)$ |
| delete $lst[k]$ | $O(n-k)$ | $O(k)$ |
Reversing a linked list in $O(1)$ additional memory. See the code and demo here
class Node():
def __init__(self, val):
self.value = val
self.next = None
def __repr__(self):
#return str(self.value)
#for today's recitation, we print the id of self as well
return str(self.value) + "(" + str(id(self))+ ")"
class Linked_list():
def __init__(self, seq=None):
self.next = None
self.len = 0
if seq != None:
for x in seq[::-1]:
self.add_at_start(x)
def __repr__(self):
out = ""
p = self.next
while p != None :
out += str(p) + ", " # str(p) envokes __repr__ of class Node
p = p.next
return "[" + out[:-2] + "]"
def __len__(self):
''' called when using Python's len() '''
return self.len
def add_at_start(self, val):
''' add node with value val at the list head '''
p = self
tmp = p.next
p.next = Node(val)
p.next.next = tmp
self.len += 1
def add_at_end(self, val):
''' add node with value val at the list tail '''
p = self
while (p.next != None):
p = p.next
p.next = Node(val)
self.len += 1
def insert(self, loc, val):
''' add node with value val after location 0<=loc<len of the list '''
assert 0 <= loc < len(self)
p = self
for i in range(0, loc):
p = p.next
tmp = p.next
p.next = Node(val)
p.next.next = tmp
self.len += 1
def __getitem__(self, loc):
''' called when using L[i] for reading
return node at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self.next
for i in range(0, loc):
p = p.next
return p
def __setitem__(self, loc, val):
''' called when using L[loc]=val for writing
assigns val to node at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self.next
for i in range(0, loc):
p = p.next
p.value = val
return None
def find(self, val):
''' find (first) node with value val in list '''
p = self.next
# loc = 0 # in case we want to return the location
while p != None:
if p.value == val:
return p
else:
p = p.next
#loc=loc+1 # in case we want to return the location
return None
def delete(self, loc):
''' delete element at location 0<=loc<len '''
assert 0 <= loc < len(self)
p = self
for i in range(0, loc):
p = p.next
# p is the element BEFORE loc
p.next = p.next.next
self.len -= 1
def insert_ordered(self, val):
''' assume self is an ordered list,
insert Node with val in order '''
p = self
q = self.next
while q != None and q.value < val:
p = q
q = q.next
newNode = Node(val)
p.next = newNode
newNode.next = q
self.len += 1
def find_ordered(self, val):
''' assume self is an ordered list,
find Node with value val '''
p = self.next
while p != None and p.value < val:
p = p.next
if p != None and p.value == val:
return p
else:
return None
def reverse(self):
prev = None
curr = self.next
while curr != None:
tmp = curr.next
curr.next = prev
prev = curr
curr = tmp
self.next = prev
ll = Linked_list("abc")
ll
ll.reverse()
ll
[a(2165820113248), b(2165820113192), c(2165820113136)]
[c(2165820113136), b(2165820113192), a(2165820113248)]