Demo Pos Hujan¶
Notebook ini akan mendemonstrasikan penggunaan module hidrokit.prepkit dan menunjukkan potensi penggunaan python saat melakukan analisis hidrologi (atau data analisis). Notebook ini diharapkan memberi bayangan apa yang bisa dilakukan oleh python dan jupyter notebook.
Tentang hidrokit.prepkit¶
prepkit merupakan module bagian dari hidrokit yang berisikan fungsi pengolahaan data mentah menjadi data yang siap di analisis (data munging). Saat ini prepkit dibuat dengan dasar berpikir mengolah data hidrologi berupa curah hujan, debit (AWLR), dll. Sehingga, penggunaan prepkit sekarang hanya dibatasi dengan tujuan penggunaan pengolahan data hidrologi. Akan tetapi, Anda bisa mengembangkan prepkit lebih lanjut untuk menyesuaikan kebutuhan Anda.
Penggunaan¶
Saat ini penggunaan script ini tidak langsung pakai, setidaknya pengguna harus terbiasa dengan penggunaan python, serta memahami penggunaan pandas dan sifat dataframe. Berbeda dengan software yang biasa digunakan, dengan dokumentasi terbatas, pengguna diharapkan mampu mengevaluasi kode yang telah dikembangkan. Akan tetapi, diharapkan kedepannya lebih mudah dievaluasi, praktis digunakan, dan teruji.
Catatan: data ../testdata/ tidak tersedia dalam github terkait legalitas penyebaran data informasi.
Aksi prepkit¶
Contoh dalam notebook ini hanya untuk file excel, dengan single sheet, dan nama file menunjukkan tahun dan nama stasiun. (Penggunaan untuk multi sheet, multi file akan dibahas di notebook berikutnya).
Data yang digunakan hanya sebagai contoh
Import Library¶
Melakukan import library yang akan digunakan:
numpy: library utama dalam penggunaan pandaspandas: library untuk pengelolaan datamatplotlib.pyplot: library utama dalam penggunaan plotpathlib: built-in library untuk navigasi sistemprepkit: modulehidrokituntuk persiapan pengelolaan dataviewkit: modulehidrokituntuk penampilan data
# INITIALIZATION, importing library
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pathlib
from hidrokit import prepkit, viewkit
import seaborn as sns
%matplotlib inline
## USE THIS CODE FOR DEVELOPMENT ONLY
# %load_ext autoreload
# %autoreload 2
# %aimport hidrokit
## Temporary View Functions
def viewp(df, fmt='en'):
return viewkit.in_pivot(df, col=df.columns[0], month_fmt=fmt)
Menentukan dokumen¶
Contoh dokumen berupa single file dan single sheet. Berikut gambar isi excelnya:

Nama format dokumen ini saya sebut phderi singkatan poshujan-deri (Karena data excelnya saya dapat dari deri). Saat ini, format tersebut merupakan format default.
Kode dibawah ini mendemokan bagaimana memperoleh tabel hujan dalam excel tanpa perlu membuka file tersebut (karena membuka excel hanya untuk memperoleh data hujan itu cukup merepotkan).
prepkit.get_rawdf(dokumen), fungsi melakukan pengambilan data mentah (raw) dalam bentuk dataframe (df) pandas.
dokumen = '../testdata/xls/fmderi/PHTANJUNGBARU/2016 HUJAN TANJUNG BARU.xls'
rawph = prepkit.get_rawdf(dokumen)
rawph.index = [i for i in range(1,32)]
rawph.columns = [i for i in range(1,13)]
rawph
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | - | 70.3 | 19.3 | - | 17.3 | - | - | 48 | - | - | 80 | 45.5 |
| 2 | 30 | 21.5 | 0.8 | 0.07 | 10.6 | 106.5 | - | 1.8 | - | - | 0.2 | 0.8 |
| 3 | - | 9 | 5.2 | - | 0.4 | - | - | - | - | - | 6.5 | 58.3 |
| 4 | - | 21.9 | - | - | - | - | - | - | - | - | - | 40 |
| 5 | 5.2 | - | - | 15 | 19.8 | - | - | - | - | - | 39.5 | 8.7 |
| 6 | - | 51.6 | - | 8.5 | 16.2 | - | - | - | - | - | 6.3 | - |
| 7 | 4.3 | - | - | - | 25.5 | 10 | 31.5 | 8.2 | - | - | 5 | 25 |
| 8 | - | - | 31.9 | - | - | - | - | - | 2 | - | 36 | 3 |
| 9 | 9.5 | 16.8 | 26.4 | 19.8 | 30.2 | 1.2 | - | - | - | - | 63.2 | 31.8 |
| 10 | - | 75.3 | - | - | - | - | - | - | - | - | 89.4 | 48.5 |
| 11 | - | - | 48 | 62.5 | 167.4 | - | 9.3 | 15 | - | - | 81 | NaN |
| 12 | - | 39 | - | - | 59 | - | - | 2.3 | 3.5 | - | 19.5 | 53 |
| 13 | - | - | 92.5 | - | - | - | - | 110.8 | - | - | 23 | 41.8 |
| 14 | 28.7 | - | - | - | - | - | 2 | 2 | - | - | 0.3 | 9.3 |
| 15 | - | - | 18.4 | - | 8.3 | 1 | - | - | - | - | - | 50.2 |
| 16 | 29.4 | - | - | - | - | - | 35.2 | - | - | - | 30.5 | 16.5 |
| 17 | - | 27.5 | - | 41.3 | 16.5 | - | 16 | - | - | - | 42 | 41.8 |
| 18 | 21.5 | - | 23.5 | - | - | - | 58.7 | 77.3 | - | 6.5 | - | - |
| 19 | - | - | - | 10 | 15.9 | - | - | - | - | - | 3.8 | 9 |
| 20 | 9.7 | - | 80.3 | - | - | - | 13.2 | 9.8 | - | - | - | 7.3 |
| 21 | - | - | 75 | 11.4 | 11 | - | - | 40.2 | - | 1.8 | 18 | - |
| 22 | - | 8 | 102 | - | 32.5 | - | - | 15 | - | - | - | 38.5 |
| 23 | - | - | - | 7 | - | - | - | 23.7 | - | - | 23.7 | 14.8 |
| 24 | 15.4 | - | - | 24 | - | - | 14.2 | - | - | - | - | - |
| 25 | - | 4.5 | 5.2 | - | - | 5.5 | - | 5 | - | - | 17.5 | 0.3 |
| 26 | - | - | - | 18.3 | - | 6 | - | 4 | - | - | - | - |
| 27 | - | 9.4 | 4.5 | 9.5 | 17.7 | 170.5 | - | - | 14 | - | 0.9 | - |
| 28 | - | 18.6 | 7.8 | - | - | - | 2.5 | - | 219 | - | 30.4 | - |
| 29 | - | - | 19 | 35 | 20 | - | 17.8 | - | 4 | - | 102.5 | - |
| 30 | 28.5 | NaN | 3.6 | 78.4 | 18.6 | - | - | - | - | 12.5 | - | - |
| 31 | 0.8 | NaN | - | NaN | - | NaN | - | - | NaN | - | NaN | 56.56 |
Contoh format lain¶
Format pengambilan data berikut mengacu pada 'pdderi' (untuk singkatan 'pos duga-deri'). Untuk melakukan pengambilan spesifik, bisa menggunakaan argumen format=nama_format. Berikut screenshot excelnya:
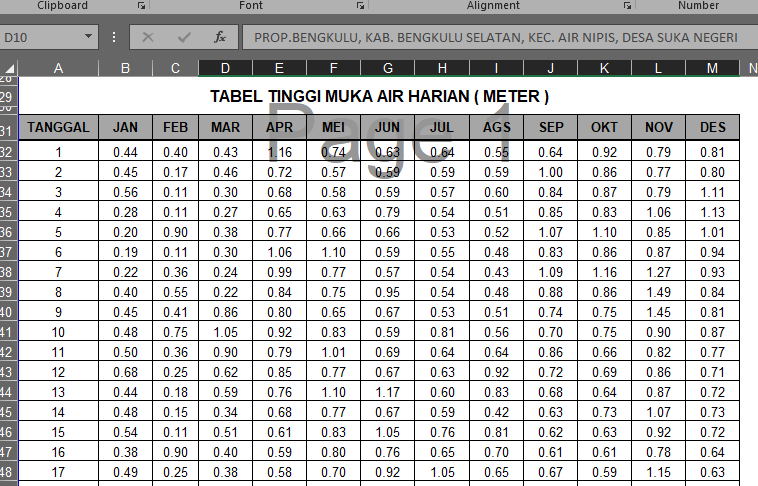
dokumenpd = '../testdata/xls/fmderi/PDAPALAKBERUNG/2016 PALAKBENGKERUNG.xls'
rawxlpd = prepkit.get_rawdf(dokumenpd, format='pdderi')
rawxlpd.index = [i for i in range(1,32)]
rawxlpd
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.44 | 0.4 | 0.43 | 1.16 | 0.74 | 0.63 | 0.64 | 0.55 | 0.64 | 0.92 | 0.79 | 0.81 |
| 2 | 0.45 | 0.17 | 0.46 | 0.72 | 0.57 | 0.59 | 0.59 | 0.59 | 1 | 0.86 | 0.77 | 0.8 |
| 3 | 0.56 | 0.111 | 0.3 | 0.68 | 0.58 | 0.59 | 0.57 | 0.6 | 0.84 | 0.87 | 0.79 | 1.11 |
| 4 | 0.28 | 0.111 | 0.27 | 0.65 | 0.63 | 0.79 | 0.54 | 0.51 | 0.85 | 0.83 | 1.06 | 1.13 |
| 5 | 0.2 | 0.9 | 0.38 | 0.77 | 0.66 | 0.66 | 0.53 | 0.52 | 1.07 | 1.1 | 0.85 | 1.01 |
| 6 | 0.19 | 0.11 | 0.3 | 1.06 | 1.1 | 0.59 | 0.55 | 0.48 | 0.83 | 0.86 | 0.87 | 0.94 |
| 7 | 0.222 | 0.36 | 0.24 | 0.99 | 0.77 | 0.57 | 0.54 | 0.43 | 1.09 | 1.16 | 1.27 | 0.93 |
| 8 | 0.4 | 0.55 | 0.22 | 0.84 | 0.75 | 0.95 | 0.54 | 0.48 | 0.88 | 0.86 | 1.49 | 0.84 |
| 9 | 0.45 | 0.41 | 0.86 | 0.8 | 0.65 | 0.67 | 0.53 | 0.51 | 0.74 | 0.75 | 1.45 | 0.81 |
| 10 | 0.48 | 0.75 | 1.05 | 0.92 | 0.83 | 0.59 | 0.81 | 0.56 | 0.7 | 0.75 | 0.9 | 0.87 |
| 11 | 0.5 | 0.36 | 0.9 | 0.79 | 1.01 | 0.69 | 0.64 | 0.64 | 0.86 | 0.66 | 0.82 | 0.77 |
| 12 | 0.68 | 0.25 | 0.62 | 0.85 | 0.77 | 0.67 | 0.63 | 0.92 | 0.72 | 0.69 | 0.86 | 0.71 |
| 13 | 0.44 | 0.18 | 0.59 | 0.76 | 1.1 | 1.17 | 0.6 | 0.83 | 0.68 | 0.64 | 0.87 | 0.72 |
| 14 | 0.48 | 0.15 | 0.34 | 0.68 | 0.77 | 0.67 | 0.59 | 0.42 | 0.63 | 0.73 | 1.07 | 0.73 |
| 15 | 0.54 | 0.11 | 0.51 | 0.61 | 0.83 | 1.05 | 0.76 | 0.81 | 0.62 | 0.63 | 0.92 | 0.72 |
| 16 | 0.38 | 0.9 | 0.4 | 0.59 | 0.8 | 0.76 | 0.65 | 0.7 | 0.61 | 0.61 | 0.78 | 0.64 |
| 17 | 0.49 | 0.25 | 0.38 | 0.58 | 0.7 | 0.92 | 1.05 | 0.65 | 0.67 | 0.59 | 1.15 | 0.63 |
| 18 | 0.34 | 0.14 | 0.57 | 0.57 | 1.28 | 0.77 | 1.1 | 0.77 | 0.64 | 0.57 | 1.05 | 0.64 |
| 19 | 0.58 | 0.26 | 0.29 | 0.6 | 0.61 | 0.71 | 0.77 | 1.46 | 0.84 | 0.57 | 0.89 | 0.63 |
| 20 | 0.58 | 0.41 | 0.25 | 0.64 | 0.58 | 0.66 | 0.68 | 0.67 | 0.78 | 0.53 | 0.99 | 0.8 |
| 21 | 0.38 | 0.19 | 0.21 | 0.59 | 0.67 | 0.6 | 0.66 | 0.7 | 0.69 | 0.62 | 0.89 | 0.71 |
| 22 | 0.23 | 0.16 | 0.4 | 0.62 | 0.71 | 0.55 | 0.61 | 0.68 | 0.77 | 1.28 | 0.93 | 0.76 |
| 23 | 0.17 | 0.13 | 0.35 | 0.59 | 1.05 | 0.52 | 0.61 | 0.69 | 1.03 | 0.85 | 0.95 | 0.79 |
| 24 | 0.17 | 0.14 | 0.23 | 0.84 | 0.69 | 0.5 | 0.6 | 0.65 | 0.78 | 0.88 | 0.97 | 0.79 |
| 25 | 0.19 | 0.36 | 0.19 | 0.82 | 0.64 | 0.6 | 0.59 | 0.85 | 0.73 | 0.85 | 0.97 | 0.8 |
| 26 | 0.13 | 0.22 | 0.38 | 0.7 | 0.6 | 1.15 | 0.59 | 0.7 | 0.7 | 0.85 | 0.81 | 0.71 |
| 27 | 0.1 | 0.21 | 0.59 | 0.64 | 0.59 | 0.78 | 0.57 | 0.65 | 1 | 0.87 | 0.76 | 0.85 |
| 28 | 0.1 | 0.5 | 0.77 | 0.78 | 0.75 | 0.64 | 0.72 | 62.5 | 0.8 | 0.81 | 0.74 | 0.78 |
| 29 | 0.1 | 0.53 | 0.81 | 0.72 | 0.94 | 0.61 | 0.61 | 0.61 | 0.72 | 0.81 | 0.71 | 0.73 |
| 30 | 0.11 | NaN | 0.67 | 1.68 | 0.76 | 0.77 | 0.6 | 0.65 | 0.7 | 0.82 | 0.82 | 0.69 |
| 31 | 0.11 | NaN | 0.62 | NaN | 0.68 | NaN | 0.56 | 0.7 | NaN | 0.78 | NaN | 0.69 |
Ubah dalam bentuk kolom¶
Tabel yang kita peroleh biasanya hanya cocok untuk laporan dan bukan untuk penggunaan analisis, sehingga tabel tersebut harus diubah dalam bentuk kolom dengan indexnya berupa tipe seri-waktu.
Dalam prepkit sudah disiapkan fungsi tf_rawdf() untuk mengubah tabel tersebut dalam bentuk kolom tunggal.
Fungsi tf_rawdf memiliki 1 argumen posisi, dan 2 opsional yaitu dataframe mentah yang diperoleh dari get_rawdf (argumen posisi), year yang menunjukkan tahun datanya, name untuk nama stasiun (argumen opsional).
dokumen = pathlib.Path(dokumen) # Mengubah menjadi object pathlib
tahun = int(dokumen.stem.split()[0])
nama = ''.join(dokumen.stem.split()[-2:])
phdf = prepkit.tf_rawdf(rawph, year=tahun, name=nama)
phdf.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 366 entries, 2016-01-01 to 2016-12-31 Data columns (total 1 columns): TANJUNGBARU 365 non-null object dtypes: object(1) memory usage: 5.7+ KB
phdf.head(10)
| TANJUNGBARU | |
|---|---|
| date | |
| 2016-01-01 | - |
| 2016-01-02 | 30 |
| 2016-01-03 | - |
| 2016-01-04 | - |
| 2016-01-05 | 5.2 |
| 2016-01-06 | - |
| 2016-01-07 | 4.3 |
| 2016-01-08 | - |
| 2016-01-09 | 9.5 |
| 2016-01-10 | - |
Eksplorasi Data¶
Karena phdf merupakan dataframe maka berbagai rekayasa pandas dapat dilakukan, seperti:
phdf['20161001':'20161231']: mengambil data dari bulan Oktober sampai akhir Desember. (Disarankan menggunakan.locatau.iloc)phdf.describe(): memunculkan informasi statistikphdf[phdf == '-'] = 100: mengubah data yang memenuhi kondisi== '-'ke nilai100phdf['TANJUNGBARU'] = pd.to_numeric(phdf['TANJUNGBARU']): mengubah ke tipe data numerik
Penggunaan viewkit akan dibahas lebih lanjut, untuk sementara viewkit.in_pivot() mengubah dataframe kolom tunggal menjadi bentuk tabel yang biasanya ada di laporan.
Ubah ke Tabel Numerik¶
Karena data yang diperoleh dari excel tidak otomatis terubah menjadi tipe data numerik (karena isian - dan kosong), maka perlu diubah tipe data object menjadi numerik float64. Berikut langkah yang akan dilakukan:
- Mengubah isian
-menjadi0. - Memeriksa apakah ada data kosong (data tak terukur/diragukan).
- Mengisi data kosong tersebut dengan metode yang digunakan. Untuk contoh ini, digunakan metode
ffill(forward fill) yang nilainya diperoleh dari data hari sebelumnya. - Pastikan kolom dalam bentuk tipe data numerik dengan melakukan metode
.info().
# Mengecek jumlah data '-'
print((phdf == '-').sum())
TANJUNGBARU 211 dtype: int64
Maka dapat dinyatakan bahwa pada tahun ini terjadi hujan sebanyak 211 hari. Diubah isian - menjadi 0.0, dan menggunakan metode infer_objects() untuk mengubah data tersebut otomatis menjadi numerik.
phdf[phdf == '-'] = 0.
phdf = phdf.infer_objects()
phdf.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 366 entries, 2016-01-01 to 2016-12-31 Data columns (total 1 columns): TANJUNGBARU 365 non-null float64 dtypes: float64(1) memory usage: 5.7 KB
Cek apakah ada data yang kosong (diragukan/tidak diisi/bukan -) dengan menggunakan metode .isnull atau .isna.
phdf.isna().values.any()
True
phdf[phdf['TANJUNGBARU'].isnull()]
| TANJUNGBARU | |
|---|---|
| date | |
| 2016-12-11 | NaN |
Maka, diketahui bahwa pada tanggal 11 Desember 2016, data tidak tercatat. Data tersebut akan diisi dengan cara ffill dari metode .fillna.
phdf.loc['20161205':'20161215'].T
| date | 2016-12-05 00:00:00 | 2016-12-06 00:00:00 | 2016-12-07 00:00:00 | 2016-12-08 00:00:00 | 2016-12-09 00:00:00 | 2016-12-10 00:00:00 | 2016-12-11 00:00:00 | 2016-12-12 00:00:00 | 2016-12-13 00:00:00 | 2016-12-14 00:00:00 | 2016-12-15 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TANJUNGBARU | 8.7 | 0.0 | 25.0 | 3.0 | 31.8 | 48.5 | NaN | 53.0 | 41.8 | 9.3 | 50.2 |
phdf.fillna(method='ffill', inplace=True)
phdf.loc['20161205':'20161215'].T
| date | 2016-12-05 00:00:00 | 2016-12-06 00:00:00 | 2016-12-07 00:00:00 | 2016-12-08 00:00:00 | 2016-12-09 00:00:00 | 2016-12-10 00:00:00 | 2016-12-11 00:00:00 | 2016-12-12 00:00:00 | 2016-12-13 00:00:00 | 2016-12-14 00:00:00 | 2016-12-15 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TANJUNGBARU | 8.7 | 0.0 | 25.0 | 3.0 | 31.8 | 48.5 | 48.5 | 53.0 | 41.8 | 9.3 | 50.2 |
Setelah data kosong tersebut diisi, dilakukan pengecekan kembali.
Catatan: Pengisian data kosong tersebut bisa dikembangkan lebih lanjut kembali dengan menggunakan metode pengisian data hilang hidrologi, semisal data rata-rata hujan pada bulan tersebut, rata-rata stasiun lain pada DAS yang sama, dll.
phdf.isna().values.any()
False
Mengambil data pada periode tertentu¶
Dengan index yang telah bertipe data pd.TimeStamp, maka melakukan pengambilan dengan periode tertentu akan lebih mudah juga. Format tanggal ditulis YYYYMMDD (terdapat juga format penulisan yang diterima oleh pandas, lihat dokumentasinya untuk lebih lanjut).
Catatan: Abaikan penggunaan viewp (fungsi yang dideklarasikan di awal notebook). Penggunaan viewp hanya sebatas menampilkan data berbentuk kolom tunggal menjadi tabel yang biasa ditampilkan dalam laporan. viewp tidak mengubah data.
# Jika ditampilkan dalam bentuk kolom, maka akan menghabiskan tempat. viewp() digunakan untuk mengatasi masalah tersebut.
viewp(phdf).head(15)
| month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| day | ||||||||||||
| 1 | 0.0 | 70.3 | 19.3 | 0.00 | 17.3 | 0.0 | 0.0 | 48.0 | 0.0 | 0.0 | 80.0 | 45.5 |
| 2 | 30.0 | 21.5 | 0.8 | 0.07 | 10.6 | 106.5 | 0.0 | 1.8 | 0.0 | 0.0 | 0.2 | 0.8 |
| 3 | 0.0 | 9.0 | 5.2 | 0.00 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 6.5 | 58.3 |
| 4 | 0.0 | 21.9 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 40.0 |
| 5 | 5.2 | 0.0 | 0.0 | 15.00 | 19.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 39.5 | 8.7 |
| 6 | 0.0 | 51.6 | 0.0 | 8.50 | 16.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 6.3 | 0.0 |
| 7 | 4.3 | 0.0 | 0.0 | 0.00 | 25.5 | 10.0 | 31.5 | 8.2 | 0.0 | 0.0 | 5.0 | 25.0 |
| 8 | 0.0 | 0.0 | 31.9 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 36.0 | 3.0 |
| 9 | 9.5 | 16.8 | 26.4 | 19.80 | 30.2 | 1.2 | 0.0 | 0.0 | 0.0 | 0.0 | 63.2 | 31.8 |
| 10 | 0.0 | 75.3 | 0.0 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 89.4 | 48.5 |
| 11 | 0.0 | 0.0 | 48.0 | 62.50 | 167.4 | 0.0 | 9.3 | 15.0 | 0.0 | 0.0 | 81.0 | 48.5 |
| 12 | 0.0 | 39.0 | 0.0 | 0.00 | 59.0 | 0.0 | 0.0 | 2.3 | 3.5 | 0.0 | 19.5 | 53.0 |
| 13 | 0.0 | 0.0 | 92.5 | 0.00 | 0.0 | 0.0 | 0.0 | 110.8 | 0.0 | 0.0 | 23.0 | 41.8 |
| 14 | 28.7 | 0.0 | 0.0 | 0.00 | 0.0 | 0.0 | 2.0 | 2.0 | 0.0 | 0.0 | 0.3 | 9.3 |
| 15 | 0.0 | 0.0 | 18.4 | 0.00 | 8.3 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 50.2 |
# Mengambil data dari periode 10 oktober 2016 sampai 13 Desember 2016.
viewp(phdf['20161010':'20161213'])
| month | Oct | Nov | Dec |
|---|---|---|---|
| day | |||
| 1 | NaN | 80.0 | 45.5 |
| 2 | NaN | 0.2 | 0.8 |
| 3 | NaN | 6.5 | 58.3 |
| 4 | NaN | 0.0 | 40.0 |
| 5 | NaN | 39.5 | 8.7 |
| 6 | NaN | 6.3 | 0.0 |
| 7 | NaN | 5.0 | 25.0 |
| 8 | NaN | 36.0 | 3.0 |
| 9 | NaN | 63.2 | 31.8 |
| 10 | 0.0 | 89.4 | 48.5 |
| 11 | 0.0 | 81.0 | 48.5 |
| 12 | 0.0 | 19.5 | 53.0 |
| 13 | 0.0 | 23.0 | 41.8 |
| 14 | 0.0 | 0.3 | NaN |
| 15 | 0.0 | 0.0 | NaN |
| 16 | 0.0 | 30.5 | NaN |
| 17 | 0.0 | 42.0 | NaN |
| 18 | 6.5 | 0.0 | NaN |
| 19 | 0.0 | 3.8 | NaN |
| 20 | 0.0 | 0.0 | NaN |
| 21 | 1.8 | 18.0 | NaN |
| 22 | 0.0 | 0.0 | NaN |
| 23 | 0.0 | 23.7 | NaN |
| 24 | 0.0 | 0.0 | NaN |
| 25 | 0.0 | 17.5 | NaN |
| 26 | 0.0 | 0.0 | NaN |
| 27 | 0.0 | 0.9 | NaN |
| 28 | 0.0 | 30.4 | NaN |
| 29 | 0.0 | 102.5 | NaN |
| 30 | 12.5 | 0.0 | NaN |
| 31 | 0.0 | NaN | NaN |
Menampilkan data statistik dengan .describe¶
phdf.describe()
| TANJUNGBARU | |
|---|---|
| count | 366.000000 |
| mean | 12.140246 |
| std | 26.038050 |
| min | 0.000000 |
| 25% | 0.000000 |
| 50% | 0.000000 |
| 75% | 14.650000 |
| max | 219.000000 |
Dari perintah menghasilkan informasi statistik berupa jumlah data dalam dataframe, rata-rata, standar deviasi, nilai minimum dan maksimum, kuartial bawah dan atas, dan median. Fungsi describe juga dapat digunakan untuk melihat statistik untuk setiap bulannya dengan bantuan viewp.
viewp(phdf).describe()
| month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 31.000000 | 29.000000 | 31.000000 | 30.000000 | 31.000000 | 30.000000 | 31.000000 | 31.000000 | 30.000000 | 31.000000 | 30.000000 | 31.000000 |
| mean | 5.903226 | 12.875862 | 18.174194 | 11.359000 | 15.706452 | 10.023333 | 6.464516 | 11.712903 | 8.083333 | 0.670968 | 23.973333 | 20.940645 |
| std | 10.408217 | 21.186091 | 29.768910 | 19.548427 | 31.259835 | 35.991941 | 13.449846 | 25.263620 | 39.926243 | 2.501892 | 30.462186 | 21.693582 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.050000 | 0.000000 |
| 50% | 0.000000 | 0.000000 | 3.600000 | 0.000000 | 8.300000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 12.000000 | 9.300000 |
| 75% | 7.350000 | 18.600000 | 21.400000 | 14.100000 | 18.150000 | 0.000000 | 5.900000 | 9.000000 | 0.000000 | 0.000000 | 34.625000 | 41.800000 |
| max | 30.000000 | 75.300000 | 102.000000 | 78.400000 | 167.400000 | 170.500000 | 58.700000 | 110.800000 | 219.000000 | 12.500000 | 102.500000 | 58.300000 |
Plotting distribusi untuk setiap bulan¶
phdf_month = phdf.assign(month=phdf.index.month)
g = sns.FacetGrid(phdf_month[phdf_month['month'] <= 4], col='month')
g.map(sns.distplot, 'TANJUNGBARU')
g = sns.FacetGrid(
phdf_month[(phdf_month['month'] > 4) & (phdf_month['month'] <= 8)],
col='month')
g.map(sns.distplot, 'TANJUNGBARU')
g = sns.FacetGrid(phdf_month[(phdf_month['month'] > 8)], col='month')
g.map(sns.distplot, 'TANJUNGBARU')
### Abaikan peringatan dibawah, hal tersebut tidak mempengaruhi hasil perhitungan/plotting.
### Gunakan paket warnings untuk menghilangkan peringatan tersebut.
C:\Miniconda3\envs\testhidrokit\lib\site-packages\scipy\stats\stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result. return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
<seaborn.axisgrid.FacetGrid at 0x2a3d8044b00>



Plotting¶
Plotting dengan periode seluruh yang ada di dataframe
phdf.plot();

Plotting dengan periode tertentu
phdf['20160501':'20161001'][:-1].plot();

phdf.plot.hist(bins=10)
<matplotlib.axes._subplots.AxesSubplot at 0x2a3d9b3ac18>

plt.figure(figsize=(15,8))
g = sns.heatmap(viewp(phdf), cmap='plasma', annot=True, fmt='.2f')
g.set_title('Heatmap Data Hujan');

plt.figure(figsize=(15,10))
g = sns.heatmap(viewp(phdf).iloc[:,1::2], cmap='viridis', annot=True, fmt='.2f')
g.set_title('Heatmap Data Hujan');
plt.tight_layout()

viewp(phdf, fmt='id').plot.bar(stacked=True, figsize=(20,10))
# ini plot untuk coba-coba saja,
# kenyataannya gak mungkin dalam bentuk seperti ini untuk representasi hujan dalam satu tahun.
<matplotlib.axes._subplots.AxesSubplot at 0x2a3d9ac7898>

g = phdf.loc['20160501':'20160801',:][:-1].plot(legend=False)
pddf = prepkit.tf_rawdf(rawxlpd, 2016, name='PALAKBENGKERUNG')
g = pddf.loc['20160501':'20160801',:][:-1].plot(secondary_y=True, ax=g, legend=False)

Update Notes¶
> 20190109
- koreksi penulisan dan tata bahasa, menambahkan keterangan.
> 20181019
- fix typo, add info.
> 20181018
- struktur folder baru
> 20181015
- tambah grafik
- viewp dapat menampilkan dengan bulan
> 20181014
- merombak penulisan dan struktur notebook
- tambah sns plot
> 20181012
- initial commit