MNIST with torchvision and skorch¶
This notebooks shows how to define and train a simple Neural-Network with PyTorch and use it via skorch with the help of torchvision.
|
|
 View source on GitHub View source on GitHub |
Note: If you are running this in a colab notebook, we recommend you enable a free GPU by going:
Runtime → Change runtime type → Hardware Accelerator: GPU
If you are running in colab, you should install the dependencies and download the dataset by running the following cell:
import subprocess
# Installation on Google Colab
try:
import google.colab
subprocess.run(['python', '-m', 'pip', 'install', 'skorch' , 'torch', 'torchvision'])
except ImportError:
pass
from itertools import islice
from sklearn.model_selection import train_test_split
import torch
import torchvision
from torchvision.datasets import MNIST
import numpy as np
import matplotlib.pyplot as plt
USE_TENSORBOARD = True # whether to use TensorBoard
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
MNIST_FLAT_DIM = 28 * 28
Loading Data¶
Use torchvision's data repository to provide MNIST data in form of a torch Dataset. Originally, the MNIST dataset provides 28x28 PIL images. To use them with PyTorch, we convert those to tensors by adding the ToTensor transform.
mnist_train = MNIST('datasets', train=True, download=True, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
]))
mnist_test = MNIST('datasets', train=False, download=True, transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
]))
Taking a look at the data¶
Each entry in the mnist_train and mnist_test Dataset instances consists of a 28 x 28 images and the corresponding label (numbers between 0 and 9). The image data is already normalized to the range [0; 1]. Let's take a look at the first 5 images of the training set:
X_example, y_example = zip(*islice(iter(mnist_train), 5))
X_example[0].min(), X_example[0].max()
(tensor(0.), tensor(1.))
Print a selection of training images and their labels¶
def plot_example(X, y, n=5):
"""Plot the images in X and their labels in rows of `n` elements."""
fig = plt.figure()
rows = len(X) // n + 1
for i, (img, y) in enumerate(zip(X, y)):
ax = fig.add_subplot(rows, n, i + 1)
ax.imshow(img.reshape(28, 28))
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(y)
plt.tight_layout()
return fig
plot_example(torch.stack(X_example), y_example, n=5);

Preparing a validation split¶
skorch can split the data for us automatically but since we are using Datasets for their lazy-loading property there is no way skorch can do a stratified split automatically without exploring the data completely first (which it doesn't).
If we want skorch to do a validation split for us we need to retrieve the y values from the dataset and pass these values to net.fit later on:
y_train = np.array([y for x, y in iter(mnist_train)])
Build Neural Network with PyTorch¶
Simple, fully connected neural network with one hidden layer. Input layer has 784 dimensions (28x28), hidden layer has 98 (= 784 / 8) and output layer 10 neurons, representing digits 0 - 9.
from torch import nn
import torch.nn.functional as F
A simple neural network classifier with linear layers and a final softmax in PyTorch:
class ClassifierModule(nn.Module):
def __init__(
self,
input_dim=MNIST_FLAT_DIM,
hidden_dim=98,
output_dim=10,
dropout=0.5,
):
super(ClassifierModule, self).__init__()
self.dropout = nn.Dropout(dropout)
self.hidden = nn.Linear(input_dim, hidden_dim)
self.output = nn.Linear(hidden_dim, output_dim)
def forward(self, X, **kwargs):
X = X.reshape(-1, self.hidden.in_features)
X = F.relu(self.hidden(X))
X = self.dropout(X)
X = F.softmax(self.output(X), dim=-1)
return X
skorch allows to use PyTorch with an sklearn API. We will train the classifier using the classic sklearn .fit():
from skorch import NeuralNetClassifier
from skorch.dataset import CVSplit
We might also add tensorboard logging. For that, skorch offers the TensorBoard callback, which automatically logs useful information to tensorboard
Note: Using tensorboard requires installing the following Python packages: tensorboard, future, pillow
After this, to start tensorboard, run:
$ tensorboard --logdir runs
in the directory you are running this notebook in.
callbacks = []
if USE_TENSORBOARD:
from torch.utils.tensorboard import SummaryWriter
from skorch.callbacks import TensorBoard
writer = SummaryWriter()
callbacks.append(TensorBoard(writer))
torch.manual_seed(0)
net = NeuralNetClassifier(
ClassifierModule,
max_epochs=10,
iterator_train__num_workers=2,
iterator_valid__num_workers=2,
lr=0.1,
device=DEVICE,
callbacks=callbacks,
)
net.fit(mnist_train, y=y_train);
epoch train_loss valid_acc valid_loss dur
------- ------------ ----------- ------------ -------
1 0.7973 0.8988 0.3627 13.3156
2 0.4256 0.9191 0.2840 7.8078
3 0.3589 0.9297 0.2434 6.6143
4 0.3169 0.9374 0.2165 6.6950
5 0.2919 0.9405 0.2016 6.6883
6 0.2680 0.9474 0.1831 6.5840
7 0.2542 0.9496 0.1718 6.6463
8 0.2432 0.9522 0.1629 6.6640
9 0.2291 0.9548 0.1536 6.6585
10 0.2232 0.9563 0.1479 6.6471
Prediction¶
from sklearn.metrics import accuracy_score
y_pred = net.predict(mnist_test)
y_test = np.array([y for x, y in iter(mnist_test)])
accuracy_score(y_test, y_pred)
0.9578
An accuracy of about 96% for a network with only one hidden layer is not too bad.
Let's take a look at some predictions that went wrong.
We compute the index of elements that are misclassified and plot a few of those to get an idea of what went wrong.
error_mask = y_pred != y_test
Now that we have the mask we need a way to access the images from the mnist_test dataset. Luckily, skorch provides a helper class that lets us slice arbitrary Dataset objects, SlicedDataset:
from skorch.helper import SliceDataset
mnist_test_sliceable = SliceDataset(mnist_test)
X_pred = torch.stack(list(mnist_test_sliceable[error_mask]))
plot_example(X_pred[:5], y_pred[error_mask][:5]);

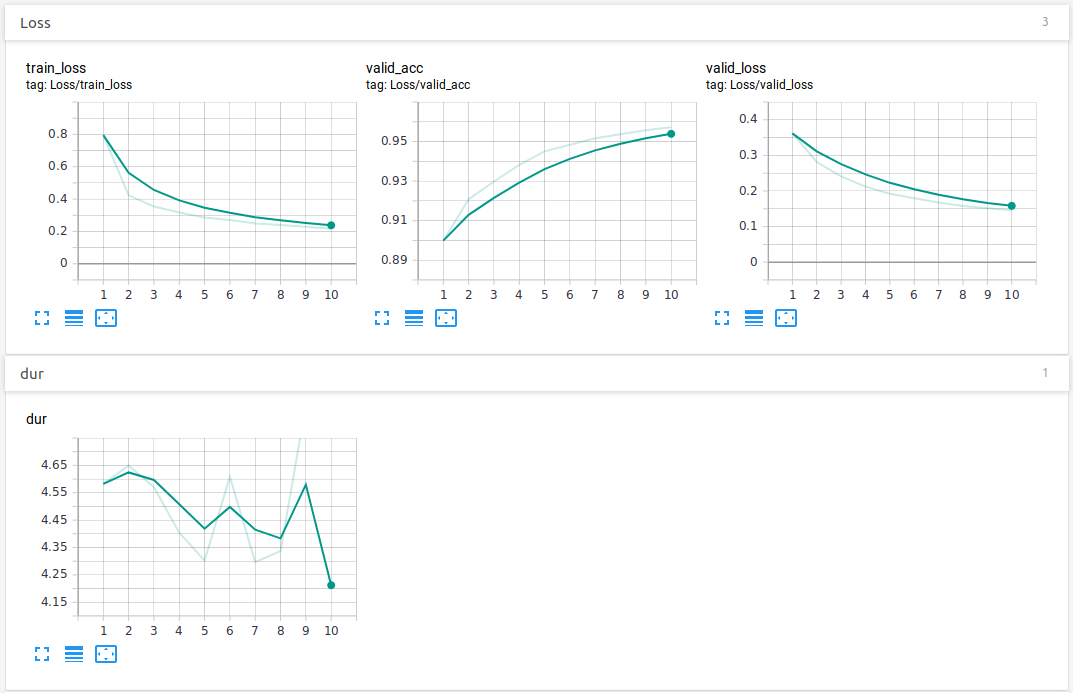
If tensorboard was enabled, here is how the metrics could look like:
Convolutional Network¶
Next we want to turn it up a notch and use a convolutional neural network which is far better suited for images than simple densely connected layers.
PyTorch expects a 4 dimensional tensor as input for its 2D convolution layer. The dimensions represent:
- Batch size
- Number of channels
- Height
- Width
MNIST data only has one channel since there is no color information. As stated above, each MNIST vector represents a 28x28 pixel image. Hence, the resulting shape for the input tensor needs to be (x, 1, 28, 28) where x is the batch size and automatically provided by the data loader.
Luckily, our data is already formated that way:
X_example[0].shape
torch.Size([1, 28, 28])
Now let us define the convolutional neural network module using PyTorch:
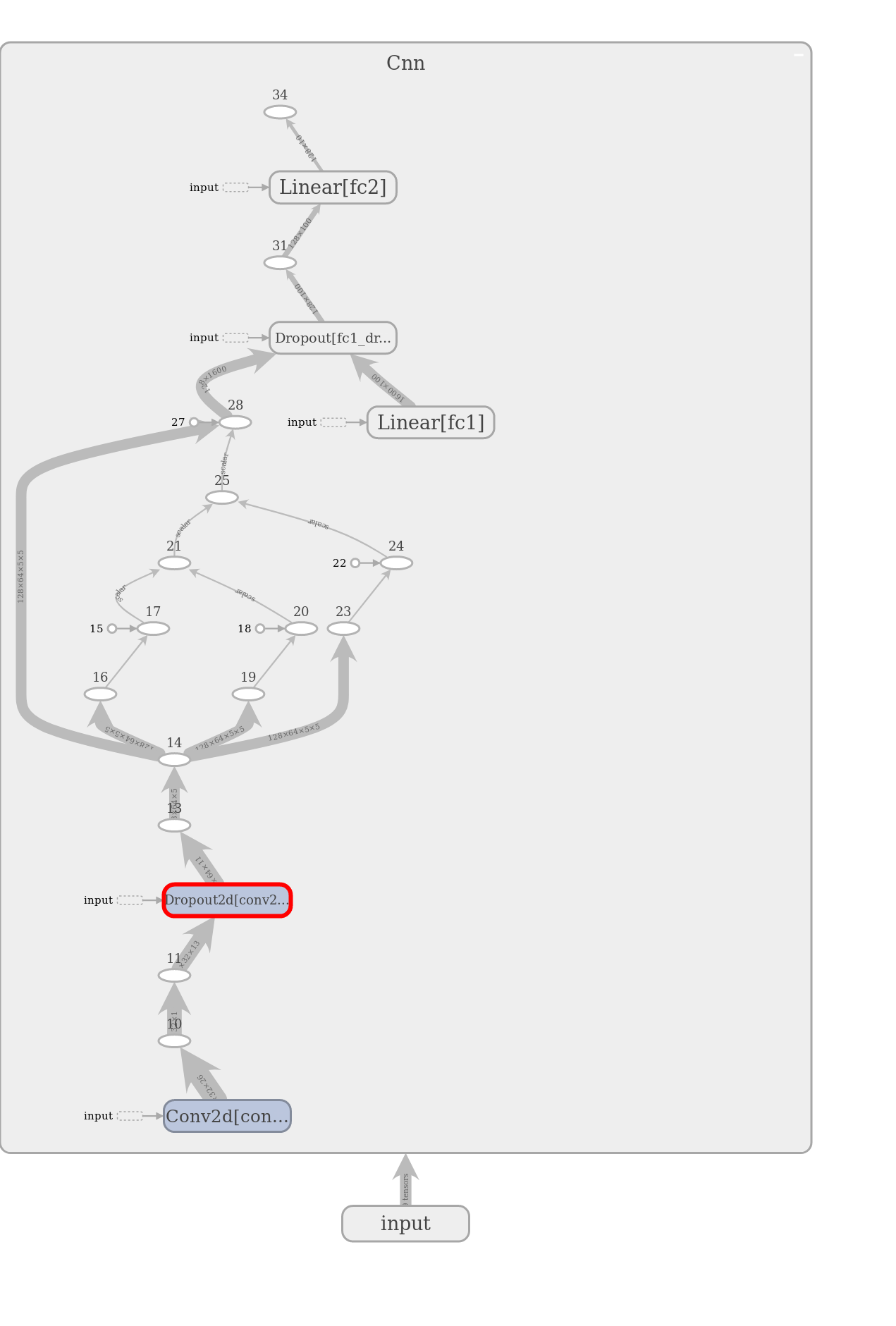
class Cnn(nn.Module):
def __init__(self, dropout=0.5):
super(Cnn, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.conv2_drop = nn.Dropout2d(p=dropout)
self.fc1 = nn.Linear(1600, 100) # 1600 = number channels * width * height
self.fc2 = nn.Linear(100, 10)
self.fc1_drop = nn.Dropout(p=dropout)
def forward(self, x):
x = torch.relu(F.max_pool2d(self.conv1(x), 2))
x = torch.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# flatten over channel, height and width = 1600
x = x.view(-1, x.size(1) * x.size(2) * x.size(3))
x = torch.relu(self.fc1_drop(self.fc1(x)))
x = torch.softmax(self.fc2(x), dim=-1)
return x
We also want to extend tensorboard logging by two more features:
Add the predictions for the misclassified images to tensorboard.
To do this, we subclass the
TensorBoardcallback and callself.writer.add_figurewith our produced images. When subclassing, don't forget to callsuper()or the other logged metrics won't show.Add a graph of the module
To do this, we use the summary writer's ability to add a traced graph of our module to tensorboard by calling
add_graph. We also make sure to only call this on the very first batch by inspecting theself.first_batch_attribute onTensorBoard.
callbacks = []
if USE_TENSORBOARD:
from torch.utils.tensorboard import SummaryWriter
from skorch.callbacks import TensorBoard
writer = SummaryWriter()
class MyTensorBoard(TensorBoard):
def __init__(self, *args, X, **kwargs):
self.X = X
super().__init__(*args, **kwargs)
def add_graph(self, module, X):
""""Add a graph to tensorboard
This requires to run the module with a sample from the
dataset.
"""
self.writer.add_graph(module, X.to(DEVICE))
def on_batch_begin(self, net, batch, **kwargs):
X, y = batch
if self.first_batch_:
# only add graph on very first batch
self.add_graph(net.module_, X)
def add_figure(self, net):
# show how difficult images were classified
epoch = net.history[-1, 'epoch']
y_pred = net.predict(self.X)
fig = plot_example(self.X, y_pred)
self.writer.add_figure('difficult images', fig, global_step=epoch)
def on_epoch_end(self, net, **kwargs):
self.add_figure(net)
super().on_epoch_end(net, **kwargs) # call super last
X_difficult = torch.stack(list(mnist_test_sliceable[error_mask][:15]))
callbacks.append(MyTensorBoard(writer, X=X_difficult))
As before we can wrap skorch's NeuralNetClassifier around our module and start training it like every other sklearn model using .fit:
torch.manual_seed(0)
cnn = NeuralNetClassifier(
Cnn,
max_epochs=10,
lr=0.0002,
optimizer=torch.optim.Adam,
device=DEVICE,
iterator_train__num_workers=2,
iterator_valid__num_workers=2,
callbacks=callbacks,
)
cnn.fit(mnist_train, y=y_train);
epoch train_loss valid_acc valid_loss dur
------- ------------ ----------- ------------ ------
1 0.9490 0.9257 0.2535 9.3405
2 0.3174 0.9561 0.1501 7.4618
3 0.2211 0.9656 0.1177 7.4806
4 0.1819 0.9712 0.1002 7.4573
5 0.1578 0.9735 0.0880 8.0541
6 0.1435 0.9768 0.0775 8.4212
7 0.1316 0.9781 0.0728 7.4816
8 0.1197 0.9795 0.0690 9.6584
9 0.1100 0.9808 0.0651 7.4606
10 0.1051 0.9822 0.0620 7.4750
y_pred_cnn = cnn.predict(mnist_test)
accuracy_score(y_test, y_pred_cnn)
0.9848
An accuracy of >98% should suffice for this example!
Let's see how we fare on the examples that went wrong before:
accuracy_score(y_test[error_mask], y_pred_cnn[error_mask])
0.7132701421800948
Great success! The majority of the previously misclassified images are now correctly identified.
On tensorboard, in the "IMAGES" section, we can see how well the CNN classified the difficult images, and how that changed over the epochs:

In the "GRAPHS" section, we can see the graph of our module.
Grid searching parameter configurations¶
Finally we want to show an example of how to use sklearn grid search when using torch Dataset instances.
When doing k-fold validation grid search we have the same problem as before that sklearn is only able to do (stratified) splits when the data is sliceable. While skorch knows how to deal with PyTorch Dataset objects and only needs y to be known beforehand, sklearn doesn't know how to deal with Datasets and needs a wrapper that makes them sliceable.
Fortunately, we already know that skorch provides such a helper: SliceDataset.
What is left to do is to define our parameter search space and run the grid search with a sliceable instance of mnist_train:
from sklearn.model_selection import GridSearchCV
cnn.set_params(max_epochs=2, verbose=False, train_split=False, callbacks=[])
<class 'skorch.classifier.NeuralNetClassifier'>[initialized](
module_=Cnn(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(conv2_drop): Dropout2d(p=0.5, inplace=False)
(fc1): Linear(in_features=1600, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=10, bias=True)
(fc1_drop): Dropout(p=0.5, inplace=False)
),
)
params = {
'module__dropout': [0, 0.5, 0.8],
}
The parameter we are interested in here is the dropout rate. We want to see which of the values (no dropout, 50%, 80%) is the best choice for our network.
Additionally:
- We use only two epochs (
max_epochs=2) for each.fit(only to reduce execution time, normally we wouldn't change this and possibly add anEarlyStoppingcallback). - Disable the network print output (
verbose=False) - Disable the internal train/validation split (
train_split=False) since the grid search will do k-fold validation anyway - Turn off tensorboard logging (
callbacks=[])
cnn.initialize();
gs = GridSearchCV(cnn, param_grid=params, scoring='accuracy', verbose=1, cv=3)
mnist_train_sliceable = SliceDataset(mnist_train)
gs.fit(mnist_train_sliceable, y_train)
Fitting 3 folds for each of 3 candidates, totalling 9 fits
GridSearchCV(cv=3,
estimator=<class 'skorch.classifier.NeuralNetClassifier'>[initialized](
module_=Cnn(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(conv2_drop): Dropout2d(p=0.5, inplace=False)
(fc1): Linear(in_features=1600, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=10, bias=True)
(fc1_drop): Dropout(p=0.5, inplace=False)
),
),
param_grid={'module__dropout': [0, 0.5, 0.8]}, scoring='accuracy',
verbose=1)
After running the grid search we now know the best configuration in our search space:
gs.best_params_
{'module__dropout': 0}