%matplotlib inline
%reload_ext autoreload
%autoreload 2
from fastai.conv_learner import *
from fastai.dataset import *
from pathlib import Path
import json
from PIL import ImageDraw, ImageFont
from matplotlib import patches, patheffects
from ipywidgets import FloatProgress
from IPython.display import display
Model data¶
Loading the Pascal data.
PATH = Path('../data/pascal')
JPEGS = 'VOCdevkit/VOC2007/JPEGImages'
trn_json = json.load((PATH/'pascal_train2007.json').open())
cats = {o['id']:o['name'] for o in trn_json['categories']}
imgs_fn = {o['id']:o['file_name'] for o in trn_json['images']}
imgs_id = [o['id'] for o in trn_json['images']]
trn_anno = collections.defaultdict(lambda:[])
for annot in trn_json['annotations']:
if annot['ignore'] == 0:
bb = annot['bbox']
#Transforms bb which is left,top, width, height into top, left, bottom, right.
bb = [bb[1],bb[0],bb[1] + bb[3], bb[0]+bb[2]]
trn_anno[annot[('image_id')]].append((bb, annot['category_id']))
len(trn_anno)
2501
CLAS_CSV = PATH/'tmp/clas.csv'
MBB_CSV = PATH/'tmp/mbb.csv'
f_model=resnet34
size=224
batch_size=32
annot_cats = [[cats[int(ann[1])] for ann in trn_anno[i]] for i in imgs_id]
id2cats = list(cats.values())
cats2id = {c:i for i,c in enumerate(id2cats)}
model_cats = np.array([np.array([cats2id[c] for c in ac]) for ac in annot_cats])
val_idx = get_cv_idxs(len(imgs_id))
((val_cats, trn_cats),) = split_by_idx(val_idx, model_cats)
model_bbs = [np.concatenate([ann[0] for ann in trn_anno[i]]) for i in imgs_id]
model_bbsc = [' '.join([str(p) for p in o]) for o in model_bbs]
df = pd.DataFrame({'fn': [imgs_fn[i] for i in imgs_id], 'bbs': model_bbsc},columns=['fn','bbs'])
df.to_csv(MBB_CSV, index=False)
aug_tfms = [RandomRotate(10, tfm_y = TfmType.COORD),
RandomLighting(0.05,0.05, tfm_y = TfmType.COORD),
RandomFlip(tfm_y = TfmType.COORD)]
tfms = tfms_from_model(f_model, size, aug_tfms=aug_tfms, crop_type=CropType.NO, tfm_y = TfmType.COORD)
md = ImageClassifierData.from_csv(PATH, JPEGS, MBB_CSV, tfms=tfms, continuous=True, num_workers=4, val_idxs=val_idx, bs=batch_size)
class ConcatLblDataset(Dataset):
def __init__(self, ds, y2):
self.ds,self.y2 = ds,y2
self.sz = ds.sz
def __len__(self): return len(self.ds)
def __getitem__(self, i):
x,y = self.ds[i]
return (x, (y,self.y2[i]))
trn_ds2 = ConcatLblDataset(md.trn_ds, trn_cats)
val_ds2 = ConcatLblDataset(md.val_ds, val_cats)
md.trn_dl.dataset = trn_ds2
md.val_dl.dataset = val_ds2
Model¶
n_clas = 20
k=9
Backbone: resnet34. We jsut grab the convolutional layers.
f = resnet34
cut,lr_cut = model_meta[f]
def get_base():
layers = cut_model(f(True), cut)
return nn.Sequential(*layers)
This will allow us to save some intermerdiary features when calling the resnet model on an input. We need the last result of the resnet, called c5 in the paper, as well as the ouputs of the two previous groups of layers (c4 and c3).
class SaveFeatures():
features=None
def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output): self.features = output
def remove(self): self.hook.remove()
Same as before, flattens the output of our final convolutional layers that predict boxes/classes. Their size is mb by n by h by w (mb = minibatch, n = k times 20 or 4, h = height, w = width). We want the a tensor of size mb by a by 20/4 where a is the total number of anchors of this layer ($a = h \times w \times k$) so we put the seond dimension at the end before resizing.
def flatten_conv(x,k):
bs,nf,gx,gy = x.size()
x = x.permute(0,2,3,1).contiguous()
return x.view(bs,-1,nf//k)
Head of the network, takes one level of the FPN and predict class/boxes predictions for each anchor of this level.
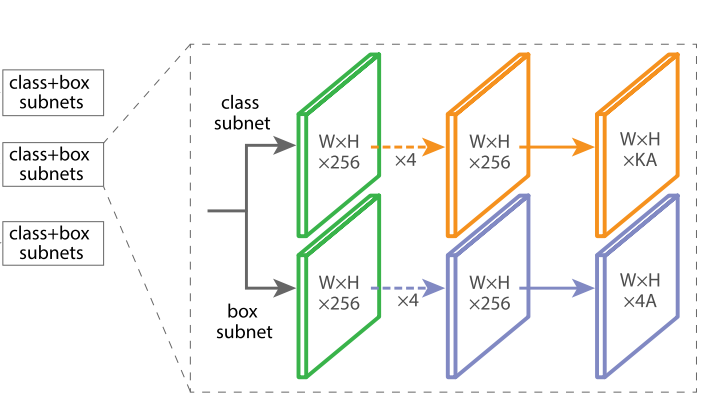
From the paper:
Taking an input feature map with C channels from a given pyramid level, the subnet applies four 3×3 conv layers, each with C filters and each followed by ReLU activations, followed by a 3×3 conv layer with KA filters.
RetinaHead implements those four convolutional layers as well as the two last ones. C = 256, A is our k (9) and K is either the number of classes or 4. We don't include the sigmoid on the activation for the categories as it will be done in the loss function (with the pytoch function BCE with logits).
The bias comes from their idea in terms of initialization:
All new conv layers except the final one in the RetinaNet subnets are initialized with bias b = 0 and a Gaussian weight fill with σ = 0.01. For the final conv layer of the classification subnet, we set the bias initialization to b = −log((1 − π)/π), where π specifies that at the start of training every anchor should be labeled as foreground with confidence of ∼π. We use π = .01 in all ex- periments, although results are robust to the exact value.
This is to make it easy for the network to predict background.
class RetinaHead(nn.Module):
def __init__(self, bias, k):
super().__init__()
self.k = k
self.conv_cls = nn.ModuleList([nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1)] * 4)
self.conv_box = nn.ModuleList([nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1)] * 4)
self.out_cls = nn.Conv2d(256,n_clas * k,kernel_size=3,stride=1,padding=1)
self.out_box = nn.Conv2d(256, 4 * k,kernel_size=3,stride=1,padding=1)
self.out_cls.bias.data.zero_().add_(bias)
def forward(self,x):
y = x.clone()
for i in range(len(self.conv_cls)):
x = F.relu(self.conv_cls[i](x))
y = F.relu(self.conv_box[i](y))
return [flatten_conv(self.out_cls(x), self.k),
flatten_conv(self.out_box(y), self.k)]
RetinaNet
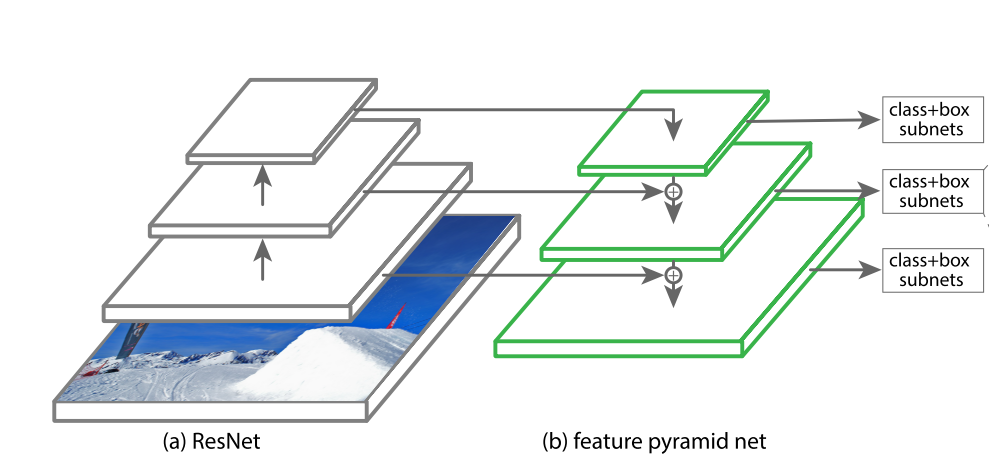
Definition in the paper:
RetinaNet uses feature pyramid levels P3 to P7, where P3 to P5 are computed from the output of the corresponding ResNet residual stage (C3 through C5) using top-down and lateral connections just as in [20], P6 is obtained via a 3×3 stride-2 conv on C5, and P7 is computed by apply- ing ReLU followed by a 3×3 stride-2 conv on P6.
And in [20]:
We upsample the spatial resolution by a factor of 2 (using nearest neighbor upsampling for simplicity). The upsampled map is then merged with the corresponding bottom-up map (which undergoes a 1×1 convolutional layer to reduce channel dimensions) by element-wise addition. This process is iterated until the finest resolution map is generated.
To start the iteration, we simply attach a 1×1 convolutional layer on C5 to produce the coarsest resolution map. Finally, we append a 3×3 convolution on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling. This final set of feature maps is
called {P2,P3,P4,P5}, corresponding to {C2,C3,C4,C5} that are respectively of the same spatial sizes.
Note that RetinaNet doesn't use P2/C2.
class RetinaNet(nn.Module):
def __init__(self, rn, k, bias):
super().__init__()
self.rn = rn
self.sfs = [SaveFeatures(rn[i]) for i in [5,6]]
end_ch = 512 #would be 2048 in Resnet50
self.top1 = nn.Conv2d(end_ch,256,kernel_size=3,stride=2,padding=1) #512 would be 2048 in Resnet50
self.top2 = nn.Conv2d(256,256,kernel_size=3,stride=2,padding=1)
self.lat1 = nn.Conv2d(end_ch,256,kernel_size=1)
self.lat2 = nn.Conv2d(end_ch//2,256,kernel_size=1)
self.lat3 = nn.Conv2d(end_ch//4,256,kernel_size=1)
self.down1 = nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1)
self.down2 = nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1)
self.head = RetinaHead(bias, k)
def forward(self, x):
c5 = F.relu(self.rn(x))
p5 = self.lat1(c5)
p4 = self.down1(self.up_add(p5,self.lat2(self.sfs[1].features)))
p3 = self.down2(self.up_add(p4, self.lat3(self.sfs[0].features)))
p6 = self.top1(c5)
p7 = self.top2(F.relu(p6))
out_cls, out_box = [], []
for p in [p3,p4,p5,p6,p7]:
oc, ob = self.head(p)
out_cls.append(oc)
out_box.append(ob)
return [torch.cat(out_cls, dim=1),
torch.cat(out_box, dim=1)]
def up_add(self,x,y):
_,_,h,w = y.size()#//we want x to have y size.
return F.upsample(x, size=(h,w), mode='nearest') + y
Wraps up the model in fastai with the correct group layers.
class UpsampleModel():
def __init__(self,model,name='upsample'):
self.model,self.name = model,name
def get_layer_groups(self, precompute):
lgs = list(split_by_idxs(children(self.model.rn), [lr_cut]))
return lgs + [children(self.model)[1:]]
Anchors¶
With an initial size of 224, features P3 to P7 have a size of 28 by 28, 14 by 14, 7 by 7, 4 by 4 and 2 by 2 respectively.
As in [20], at each pyramid level we use anchors at three aspect ratios {1:2, 1:1, 2:1}. For denser scale coverage than in [20], at each level we add anchors of sizes {2^0, 2^1/3, 2^2/3} of the original set of 3 aspect ratio anchors. This improve AP in our setting. In total there are A = 9 anchors.
anc_grids = [28,14,7,4,2] #Depends of the initial size 224.
anc_zooms = [1., 2**(1/3), 2**(2/3)]
anc_ratios = [(1.,1.), (1.,2), (2,1.)]
anchor_scales = [(anz*i,anz*j) for anz in anc_zooms for (i,j) in anc_ratios]
anc_offsets = [1/(o*2) for o in anc_grids]
k, len(anchor_scales)
(9, 9)
Generate all the anchors.
anc_x = np.concatenate([np.tile(np.linspace(ao, 1-ao, ag), ag)
for ao,ag in zip(anc_offsets,anc_grids)])
anc_y = np.concatenate([np.repeat(np.linspace(ao, 1-ao, ag), ag)
for ao,ag in zip(anc_offsets,anc_grids)])
anc_ctrs = np.repeat(np.stack([anc_x,anc_y], axis=1), k, axis=0)
def hw2corners(ctr, hw): return torch.cat([ctr-hw/2,ctr+hw/2], dim=1)
anc_sizes = np.concatenate([np.array([[o/ag,p/ag] for i in range(ag*ag) for o,p in anchor_scales])
for ag in anc_grids])
grid_sizes = V(np.concatenate([np.array([ 1/ag for i in range(ag*ag) for o,p in anchor_scales])
for ag in anc_grids]), requires_grad=False).unsqueeze(1)
anchors = V(np.concatenate([anc_ctrs, anc_sizes], axis=1), requires_grad=False).float()
anchor_cnr = hw2corners(anchors[:,:2], anchors[:,2:])
anchors.size()
torch.Size([9441, 4])
9441 anchors box total!!!
Matching and Focal loss
No change from the Pascal notebook apart from one:
The total focal loss of an image is computed as the sum of the focal loss over all ∼100k anchors, normalized by the number of anchors assigned to a ground-truth box.
(They have 100K anchors because their initial resolution is higher than 224.)
def one_hot_embedding(labels, num_classes):
return torch.eye(num_classes)[labels.data.cpu()]
class Focal_Loss(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.num_classes = num_classes
def forward(self, preds, targets):
t = one_hot_embedding(targets, self.num_classes+1)
t = V(t[:,:-1].contiguous()) #bg class is predicted when none of the others go out.
w = self.get_weight(preds,t)
return F.binary_cross_entropy_with_logits(preds, t, w, size_average=False) / self.num_classes
def get_weight(self,x,t):
alpha,gamma = 0.25,2.
p = x.sigmoid()
pt = p*t + (1-p)*(1-t)
w = alpha*t + (1-alpha)*(1-t)
return w * (1-pt).pow(gamma)
loss_f = Focal_Loss(len(id2cats))
def intersection(box_a,box_b):
min_xy = torch.max(box_a[:,None,:2],box_b[None,:,:2])
max_xy = torch.min(box_a[:,None,2:],box_b[None,:,2:])
inter = torch.clamp(max_xy-min_xy,min=0)
return inter[:,:,0] * inter[:,:,1]
def get_size(box):
return (box[:,2]-box[:,0]) * (box[:,3] - box[:,1])
def jaccard(box_a,box_b):
inter = intersection(box_a,box_b)
union = get_size(box_a).unsqueeze(1) + get_size(box_b).unsqueeze(0) - inter
return inter/union
#Removes the zero padding in the target bbox/class
def get_y(bbox,clas):
bbox = bbox.view(-1,4)/size
bb_keep = ((bbox[:,2] - bbox[:,0])>0.).nonzero()[:,0]
return bbox[bb_keep], clas[bb_keep]
def actn_to_bb(actn, anchors):
actn_bbs = torch.tanh(actn)
actn_ctrs = (actn_bbs[:,:2] * grid_sizes/2) + anchors[:,:2]
actn_hw = (1 + actn_bbs[:,2:]/2) * anchors[:,2:]
return hw2corners(actn_ctrs,actn_hw)
def map_to_ground_truth(overlaps, print_it=False):
prior_overlap, prior_idx = overlaps.max(1)
if print_it: print(prior_overlap)
# pdb.set_trace()
gt_overlap, gt_idx = overlaps.max(0)
gt_overlap[prior_idx] = 1.99
for i,o in enumerate(prior_idx): gt_idx[o] = i
return gt_overlap,gt_idx
def ssd_1_loss(b_c,b_bb,bbox,clas,print_it=False, use_ab=True):
bbox,clas = get_y(bbox,clas)
a_ic = actn_to_bb(b_bb, anchors)
overlaps = jaccard(bbox.data, (anchor_cnr if use_ab else a_ic).data)
gt_overlap,gt_idx = map_to_ground_truth(overlaps,print_it)
gt_clas = clas[gt_idx]
pos = gt_overlap > 0.5
pos_idx = torch.nonzero(pos)[:,0]
gt_clas[1-pos] = len(id2cats)
gt_bbox = bbox[gt_idx]
loc_loss = ((a_ic[pos_idx] - gt_bbox[pos_idx]).abs()).mean()
clas_loss = loss_f(b_c, gt_clas) / len(pos_idx) #Normalized by the number of anchors matched to a GT object
return loc_loss, clas_loss
def ssd_loss(pred,targ,print_it=False):
lcs,lls = 0.,0.
for b_c,b_bb,bbox,clas in zip(*pred,*targ):
loc_loss,clas_loss = ssd_1_loss(b_c,b_bb,bbox,clas,print_it)
lls += loc_loss
lcs += clas_loss
if print_it: print(f'loc: {lls.data[0]}, clas: {lcs.data[0]}')
return lls+lcs
def ssd_loss2(pred,targ):
lcs,lls = 0.,0.
for b_c,b_bb,bbox,clas in zip(*pred,*targ):
loc_loss,clas_loss = ssd_1_loss(b_c,b_bb,bbox,clas,use_ab=False)
lls += loc_loss
lcs += clas_loss
return lls+lcs
Training¶
pi = 0.01
init_b = - np.log((1-pi)/pi)
init_b
-4.59511985013459
m_base = get_base()
m = to_gpu(RetinaNet(m_base,k,init_b))
models = UpsampleModel(m)
learn = ConvLearner(md, models)
learn.opt_fn=partial(optim.SGD,momentum=0.9)
learn.crit = ssd_loss
learn.lr_find()
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
73%|███████▎ | 46/63 [00:43<00:15, 1.06it/s, loss=6.23e+11]
learn.sched.plot(10,1)

learn.fit(4e-2,1,cycle_len=20, use_clr_beta=(10,10,0.95,0.85))
HBox(children=(IntProgress(value=0, description='Epoch', max=20), HTML(value='')))
13%|█▎ | 8/63 [00:08<00:59, 1.09s/it, loss=4.38] 14%|█▍ | 9/63 [00:09<00:57, 1.06s/it, loss=4.38]
Exception in thread Thread-79:
Traceback (most recent call last):
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_monitor.py", line 62, in run
for instance in self.tqdm_cls._instances:
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/_weakrefset.py", line 60, in __iter__
for itemref in self.data:
RuntimeError: Set changed size during iteration
epoch trn_loss val_loss
0 4.179486 3.675616
1 3.548343 3.483081
2 3.314251 3.179786
3 3.114109 2.951253
4 2.94859 2.911555
5 2.825 2.855429
6 2.741265 2.899068
7 2.705045 2.86702
8 2.6504 2.759199
9 2.592447 2.686992
10 2.540801 2.695075
11 2.483211 2.634425
12 2.460438 2.669449
13 2.411031 2.67982
14 2.345259 2.555904
15 2.272705 2.515783
16 2.198426 2.531861
17 2.129172 2.453766
18 2.043373 2.433579
19 1.986656 2.425147
[array([2.42515])]
learn.save('retina-net1')
learn.load('retina-net1')
lr = 4e-2
lrs = np.array([lr/100,lr/10,lr])
learn.unfreeze()
learn.lr_find(start_lr = lrs/1000, end_lr = lrs*10)
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
92%|█████████▏| 58/63 [01:07<00:05, 1.16s/it, loss=2.01e+06]
learn.sched.plot(5,5)

lr = 8e-3
lrs = np.array([lr/100,lr/10,lr])
learn.fit(lrs,1,cycle_len=20, use_clr_beta=(10,10,0.95,0.85))
HBox(children=(IntProgress(value=0, description='Epoch', max=20), HTML(value='')))
2%|▏ | 1/63 [00:02<02:05, 2.03s/it, loss=1.83]
Exception in thread Thread-100:
Traceback (most recent call last):
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_monitor.py", line 62, in run
for instance in self.tqdm_cls._instances:
File "/home/paperspace/anaconda3/envs/fastai/lib/python3.6/_weakrefset.py", line 60, in __iter__
for itemref in self.data:
RuntimeError: Set changed size during iteration
epoch trn_loss val_loss
0 2.03119 2.452585
1 2.003591 2.429261
2 1.978251 2.425843
3 1.976334 2.446684
4 1.95894 2.398513
5 1.9375 2.425037
6 1.913259 2.394798
7 1.894273 2.394383
8 1.871497 2.398675
9 1.861104 2.382021
10 1.837772 2.372421
11 1.818771 2.354843
12 1.793786 2.386068
13 1.770864 2.365866
14 1.750781 2.361709
15 1.713707 2.355853
16 1.694742 2.358977
17 1.668011 2.361244
18 1.659317 2.339267
19 1.627629 2.343643
[array([2.34364])]
learn.save('retina-net2')
NMS¶
def nms(boxes, scores, overlap=0.5, top_k=100):
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0: return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order
idx = idx[-top_k:] # indices of the top-k largest vals
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
count = 0
while idx.numel() > 0:
i = idx[-1] # index of current largest val
keep[count] = i
count += 1
if idx.size(0) == 1: break
idx = idx[:-1] # remove kept element from view
# load bboxes of next highest vals
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)]
return keep, count
Plots¶
import matplotlib.cm as cmx
import matplotlib.colors as mcolors
def get_cmap(N):
color_norm = mcolors.Normalize(vmin=0, vmax=N-1)
return cmx.ScalarMappable(norm=color_norm, cmap='Set3').to_rgba
num_colr = 12
cmap = get_cmap(num_colr)
colr_list = [cmap(float(x)) for x in range(num_colr)]
def bb_to_hw(bb):
return [bb[1],bb[0],bb[3]-bb[1], bb[2]-bb[0]]
def show_img(im, figsize=None, axis=None):
if not axis:
fig,axis = plt.subplots(figsize=figsize)
axis.imshow(im)
axis.get_xaxis().set_visible(False)
axis.get_yaxis().set_visible(False)
return axis
def draw_outline(obj,lw):
obj.set_path_effects([patheffects.Stroke(linewidth=lw, foreground='black'), patheffects.Normal()])
def draw_rect(axis, box, color='white'):
patch = axis.add_patch(patches.Rectangle(box[:2],box[-2],box[-1],fill=False,edgecolor=color,lw=2))
draw_outline(patch,4)
def draw_text(axis,xy,text,text_size=14, color='white'):
patch = axis.text(*xy, text, verticalalignment='top', color=color, fontsize=text_size, weight='bold')
draw_outline(patch,1)
def show_img_all(id_img):
img = open_image(IMG_PATH/imgs_fn[id_img])
axis = show_img(img, figsize=(16,8))
for bbox, id_cat in trn_anno[id_img]:
new_box = bb_to_hw(bbox)
draw_rect(axis, new_box)
draw_text(axis, new_box[:2], cats[id_cat])
def show_ground_truth(ax, im, bbox, clas = None, prs = None, tresh = 0.3):
bb = [bb_to_hw(o) for o in bbox.reshape(-1,4)]
if clas is None: clas = [None] * len(bb)
if prs is None: prs = [None] * len(bb)
ax = show_img(im,axis=ax)
for i, (b,c,pr) in enumerate(zip(bb,clas,prs)):
if b[2] > 0 and (pr is None or pr > tresh):#Show the bow only if there is something to show
draw_rect(ax, b, colr_list[i%num_colr])
txt = f'{i}: '
if c is not None: txt += ('bg' if c == len(id2cats) else id2cats[c])
if pr is not None: txt += f'{pr:.2f}'
draw_text(ax,b[:2],txt,color=colr_list[i%num_colr])
def torch_gt(ax, ima, bbox, clas, prs=None, thresh=0.4):
return show_ground_truth(ax, ima, to_np((bbox*224).long()),
to_np(clas), to_np(prs) if prs is not None else None, thresh)
def np_gt(ax, ima, bbox, clas, prs=None, thresh=0.4):
return show_ground_truth(ax, ima, (bbox*224).astype(np.uint8),
clas, prs if prs is not None else None, thresh)
See some results¶
learn.load('retina-net2')
learn.model.eval()
x,y = next(iter(md.val_dl))
x,y = V(x),V(y)
pred = learn.model(x)
def get1preds(b_clas,b_bb,bbox,clas,thresh=0.25):
bbox,clas = get_y(bbox, clas)
a_ic = actn_to_bb(b_bb, anchors)
clas_pr, clas_ids = b_clas.max(1)
conf_scores = b_clas.sigmoid().t().data
out1,out2,cc = [],[],[]
for cl in range(conf_scores.size(0)-1):
cl_mask = conf_scores[cl] > thresh
if cl_mask.sum() == 0: continue
scores = conf_scores[cl][cl_mask]
l_mask = cl_mask.unsqueeze(1).expand_as(a_ic)
boxes = a_ic[l_mask].view(-1, 4)
ids, count = nms(boxes.data, scores, 0.4, 50)
ids = ids[:count]
out1.append(scores[ids])
out2.append(boxes.data[ids])
cc.append([cl]*count)
cc = T(np.concatenate(cc)) if cc != [] else None
out1 = torch.cat(out1) if out1 != [] else None
out2 = torch.cat(out2) if out2 != [] else None
return out1,out2,cc
def show_results(idx, thresh=0.25, ax=None):
if ax is None: fig, ax = plt.subplots(figsize=(6,6))
ima=md.val_ds.ds.denorm(x)[idx]
out1,out2,cc = get1preds(pred[0][idx],pred[1][idx],y[0][idx],y[1][idx],thresh)
torch_gt(ax, ima, out2, cc, out1, 0.1)
def show_gt(idx, ax=None):
if ax is None: fig, ax = plt.subplots(figsize=(6,6))
ima = md.val_ds.ds.denorm(x)[idx]
show_ground_truth(ax,ima,to_np(y[0][idx]),to_np(y[1][idx]))
def compare(idx,thresh=0.25):
fig, axs = plt.subplots(1,2,figsize=(12,6))
show_results(idx,thresh,ax=axs[0])
show_gt(idx,ax=axs[1])
plt.tight_layout()
compare(0)

compare(1)

compare(4)

compare(5)

compare(7)

mAP¶
See this notebook for more details.
def count(L):
result = collections.defaultdict(int)
if L is not None:
for x in L:
result[x] += 1
return result
from ipywidgets import FloatProgress
from IPython.display import display
def multiTPFPFN():
n = 40
threshes = np.linspace(.05, 0.95, n, endpoint=True)
tps,fps,fns = np.zeros((n,len(id2cats))),np.zeros((n,len(id2cats))),np.zeros((n,len(id2cats)))
prog = FloatProgress(min=0,max=len(md.val_dl))
display(prog)
for data in md.val_dl:
x,y = data
x,y = V(x),V(y)
pred = learn.model(x)
for idx in range(x.size(0)):
bbox,clas = get_y(y[0][idx],y[1][idx])#unpad the target
p_scrs,p_box,p_cls = get1preds(pred[0][idx],pred[1][idx],y[0][idx],y[1][idx],threshes[0])
overlaps = to_np(jaccard(p_box,bbox.data))
overlaps = np.where(overlaps > 0.5, overlaps, 0)
clas, np_scrs, np_cls = to_np(clas.data),to_np(p_scrs), to_np(p_cls)
for k in range(threshes.shape[0]):
new_tp = collections.defaultdict(int)
for cls in list(set(clas)):
msk_clas = np.bitwise_and((clas == cls)[None,:],(np_cls == cls)[:,None])
ov_clas = np.where(msk_clas,overlaps,0.)
mx_idx = np.argmax(ov_clas,axis=1)
for i in range(0,len(clas)):
if (clas[i] == cls):
keep = np.bitwise_and(np.max(ov_clas,axis=1) > 0.,mx_idx==i)
keep = np.bitwise_and(keep,np_scrs > threshes[k])
if keep.sum() > 0:
new_tp[cls] += 1
count_pred = count(np_cls[np_scrs > threshes[k]])
count_gt = count(clas)
for c in range(len(id2cats)):
tps[k,c] += new_tp[c]
fps[k,c] += count_pred[c] - new_tp[c]
fns[k,c] += count_gt[c] - new_tp[c]
prog.value += 1
return tps, fps, fns
tps, fps, fns = multiTPFPFN()
FloatProgress(value=0.0, max=16.0)
def avg_prec(clas):
eps = 1e-15
precisions = tps[:,clas]/(tps[:,clas] + fps[:,clas] + eps)
recalls = tps[:,clas]/(tps[:,clas] + fns[:,clas] + eps)
prec_at_rec = []
for recall_level in np.linspace(0.0, 1.0, 11):
try:
args = np.argwhere(recalls >= recall_level).flatten()
prec = max(precisions[args])
except ValueError:
prec = 0.0
prec_at_rec.append(prec)
return np.array(prec_at_rec).mean()
def mAP():
S = 0
for i in range(len(id2cats)):
S += avg_prec(i)
return S/len(id2cats)
mAP()
0.19297799947515568