Optimize your Docker Infrastructure with Python¶
PyData NYC¶
November 11, 2015
- Ryan J. O'Neil (@ryanjoneil)
- Day: Lead Engineer @ Yhat (r@yhathq.com)
- Night: PhD student in Operations Research @ GMU (roneil1@gmu.edu)
- Blog: http://ryanjoneil.github.io/blog.html
- Slides: https://github.com/ryanjoneil/talks/
Motivation¶
Consider the DevOps Engineer.
It's a noble profession...¶

...with grave responsibilities.¶
One of the important functions of DevOps is building environments for:
- Software development
- Testing & quality assurance
- Running operational systems
- Whatever else you might need a computing environment for

A typical DevOps function¶
You work on Yet Another Enterprise Java Application (TM). YAEJA makes $$ for Yet Another Enterprise Software Company!
You need to upgrade components where YAEJA runs.
You can't upgrade production without testing. So you need two environments from your DevOps person.
One for production:
| Command | |
|---|---|
| $A$ | Install the Java compiler and runtime environment. |
| $B$ | Download a set of external dependencies. |
| $C$ | Set up a an EntepriseDB (TM) schema and populate it with data. |
And one for testing it with the upgrade:
| Command | |
|---|---|
| $A$ | Install the Java compiler and runtime environment. |
| $B$ | Download a set of external dependencies. |
| $C$ | Set up a an EntepriseDB (TM) schema and populate it with data. |
| $D$ | Update the underlying system utility. |
If YAJEA integrates with 3rd party apps, you need another test environment for each one.
If those interact in interesting ways, you need test environments for different combinations of them.
Looks like your DevOps person will be working all weekend¶

In the old days...¶
At a big software shop, devops may setup and tear down dozens (or hundreds) of system configurations for a single software project.
This used to be done with physical hardware on (sometimes) fresh OS installs.
Most medium-to-large software shops had an air conditioned room like this.

Environmental setup was often pretty manual¶
If you had to reproduce an environment, you had a few options:
Start with a fresh install of the OS
Setup and save the results to a CD
Hope that uninstalling and resintalling is good enough...
- A lot of people did this
- Probably not good enough
- Software leaves relics
- Logs...
- Data files...
- Configuration...
Nowadays...¶

What's a container?¶
Docker is so hot right now.
I've been getting two questions a lot this week:
- What's Docker?
- Should I be using it?
A1: Docker is a lightweight virtualization platform¶
Docker provides two main things: images & containers.
Images represent the environments containers run it.
A running container acts like it is:
- In it own OS
- On its own hardware
But it doesn't load heavy stuff like a new kernel or device drivers.
A2: I don't know what you should be doing¶
But Yhat uses a ${\large\text{LOT}}$ of Docker.
- Development (MySQL containers)
- Functional tests for our software
- Buiding binary packages for Linux distros
- Productionizing predictive models (ScienceOps)
- Environment management in collaborative tools (ScienceCluster)
So containers are about isolation...¶
Processes and system resources behave as if the are on their own computers.
...but containers are also about sharing.¶
And this is what we care about here.
Specifically, saving and retrieving the results of a computation from the Docker image cache.
Why?
$$\text{SMART CACHE USE} = \text{DEVOPS TIME SAVED!}$$

Docker cache mechanics¶
Maybe I should call this section UnionFS mechanics, but then Docker is so hot right now.
A Tale of Two Dockerfiles¶
Let's say I collect old or non-standard revision control systems.
Everyone needs a hobby.
I set up an environment with a few RCSs in it to play around with.
Dockerfile: rcs1
FROM ubuntu:trusty
RUN apt-get install -y bzr
RUN apt-get install -y cvs
Let's build out our non-standard RCS image!¶
[ryan@localhost dockerfiles]$ docker build --file=rcs1 --tag=rcs1 .
Step 0 would download the base Ubuntu image, but I've already got it.
Sending build context to Docker daemon 24.58 kB
Step 0 : FROM ubuntu:trusty
---> a5a467fddcb8
bzr require a number of dependencies...
Step 1 : RUN apt-get install -y bzr
---> Running in 7679f0a1525e
Reading package lists...
Building dependency tree...
Reading state information...
The following extra packages will be installed:
ca-certificates dbus gir1.2-glib-2.0 libapparmor1 libassuan0
libdbus-glib-1-2 libgirepository-1.0-1 libglib2.0-0 libglib2.0-data libgmp10
[...snip...]
As does cvs.
Step 2 : RUN apt-get install -y cvs
---> Running in 54229eef94d2
Reading package lists...
Building dependency tree...
Reading state information...
The following extra packages will be installed:
krb5-locales libedit2 libgssapi-krb5-2 libk5crypto3 libkeyutils1 libkrb5-3
libkrb5support0 libx11-6 libx11-data libxau6 libxcb1 libxdmcp6 libxext6
[...snip...]
At the end of this I have a tagged image. I can easily use this to spin up new containers.
[ryan@localhost dockerfiles]$ docker run rcs1 bash -c "which cvs && which bzr"
/usr/bin/cvs
/usr/bin/bzr

I don't have rcs installed. I guess I'll have to build a new image.
Dockerfile: rcs2
FROM ubuntu:trusty
RUN apt-get install -y bzr
RUN apt-get install -y cvs
RUN apt-get install -y software-properties-common
RUN add-apt-repository "deb http://archive.ubuntu.com/ubuntu trusty universe"
RUN apt-get update
RUN apt-get install -y rcs
[ryan@localhost dockerfiles]$ docker build --file=rcs2 --tag=rcs2 .
The first few steps have already been run before and can use the Docker cache!
Step 0 : FROM ubuntu:trusty
---> a5a467fddcb8
Step 1 : RUN apt-get install -y bzr
---> Using cache
---> ed8a8efd04cc
Step 2 : RUN apt-get install -y cvs
---> Using cache
---> 61fe05c24a19
After that it's business as usual.
Step 3 : RUN apt-get install -y software-properties-common
---> Running in 4adc2bb63a73
The following extra packages will be installed:
iso-codes libasn1-8-heimdal libcurl3-gnutls libgssapi3-heimdal
libhcrypto4-heimdal libheimbase1-heimdal libheimntlm0-heimdal
[...snip...]
Step 4 : RUN add-apt-repository "deb http://archive.ubuntu.com/ubuntu trusty universe"
---> Running in 5a023435448c
---> 02439f270099
Removing intermediate container 5a023435448c
Step 5 : RUN apt-get update
---> Running in 449c25ee3537
Get:1 http://archive.ubuntu.com trusty-updates InRelease [64.4 kB]
[...snip...]
Step 6 : RUN apt-get install -y rcs
---> Running in 3574b94bbea3
The following NEW packages will be installed:
rcs
Adding to my stable of random revision control.¶
Also, why are they all three letters long?
So now I have rcs in addition to bzr and cvs. Note that my rcs2 image was built off of my rcs1 image. I didn't have to do any extra work to recreate those shared parts of it.
[ryan@localhost dockerfiles]$ docker run rcs2 bash -c "which bzr && which cvs && which rcs"
/usr/bin/bzr
/usr/bin/cvs
/usr/bin/rcs
What happens if I rebuild the image again?¶
Omigosh everything is cached!
[ryan@localhost dockerfiles]$ docker build --file=rcs2 --tag=rcs2 .
Sending build context to Docker daemon 3.072 kB
Step 0 : FROM ubuntu:trusty
---> a5a467fddcb8
Step 1 : RUN apt-get install -y bzr
---> Using cache
---> ed8a8efd04cc
Step 2 : RUN apt-get install -y cvs
---> Using cache
---> 61fe05c24a19
Step 3 : RUN apt-get install -y software-properties-common
---> Using cache
---> 942207de6f7f
Step 4 : RUN add-apt-repository "deb http://archive.ubuntu.com/ubuntu trusty universe"
---> Using cache
---> 02439f270099
Step 5 : RUN apt-get update
---> Using cache
---> 220536dfc3ff
Step 6 : RUN apt-get install -y rcs
---> Using cache
---> 1a8cd22cb14d
Successfully built 1a8cd22cb14d

What if I change the order of that Dockerfile?¶
I'd really rather have the commands to add universe at the top.
Dockerfile: rcs3
FROM ubuntu:trusty
RUN apt-get install -y software-properties-common
RUN add-apt-repository "deb http://archive.ubuntu.com/ubuntu trusty universe"
RUN apt-get update
RUN apt-get install -y bzr
RUN apt-get install -y cvs
RUN apt-get install -y rcs
What happens when I build an image with the commands reordered?¶
Nothing except the base image is cached!
[ryan@localhost dockerfiles]$ docker build --file=rcs3 --tag=rcs3 .
Sending build context to Docker daemon 4.096 kB
Step 0 : FROM ubuntu:trusty
---> a5a467fddcb8
Step 1 : RUN apt-get install -y software-properties-common
---> Running in 713e49f1f323
Reading package lists...
Building dependency tree...
Reading state information...
The following extra packages will be installed:
ca-certificates gir1.2-glib-2.0 iso-codes krb5-locales libasn1-8-heimdal
libcurl3-gnutls libdbus-glib-1-2 libgirepository-1.0-1 libglib2.0-0
libglib2.0-data libgssapi-krb5-2 libgssapi3-heimdal libhcrypto4-heimdal
libheimbase1-heimdal libheimntlm0-heimdal libhx509-5-heimdal libidn11
libk5crypto3 libkeyutils1 libkrb5-26-heimdal libkrb5-3 libkrb5support0
libldap-2.4-2 libroken18-heim
[...etc...]
So Docker can use the cache when...¶
It has seen the exact same commands in the same order.
If it sees something new, it stops using the cache.
Certain commands, like COPY, break the cache entirely.
If we structure them as such, they share nothing:


This is what would really happen:

This would be better:
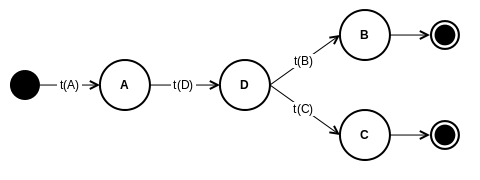
Problem formulation¶
Let's write this thing in LaTeX!
What are we trying to do again?¶
Given a set of Docker images and their commands, find the best order to run the commands and minimize required computing time.
Could also read: maximize use of the Docker cache.
Say we know a priori the time required by each command¶
We could also use a prior.
$$C = \{\text{set of commmands}\}$$$$t_c > 0 = \text{time required by command c}$$We also know the images we need to create and the commands each one requires.
$$I = \{\text{set of images}\}$$$$C_i = \{\text{commands requires for image I}\}$$We need some decision variables¶
We define a set $P$ of (image set, command set) pairs, starting with each image $i \in I$ and, for each of these, every command $c \in C_i$.
In our first example we had two images, $I = \{1, 2\}$.
The commands for the images were:
$$C_1 = \{A, B, C\}$$$$C_2 = \{A, B, C, D\}$$So our set $P$ initially contains:
$$P = \{(\{1\},\{A\}), (\{1\},\{B\}), (\{1\},\{C\}), \\ (\{2\},\{A\}), (\{2\},\{B\}), (\{2\},\{C\}), (\{2\},\{D\})\}$$Now define $x_p \in \{0,1\}$ for each $p \in P$.
If $x_p = 1$, then we run the commands in $p$ for the images in $p$.
A first, misguided stab at our image construction model¶
Find the minimum cost schedule based on our set $P$ and the requirements of our images.
$$ \begin{array}{r l} \min & t_a x_{1,a} + t_b x_{1,b} + t_c x_{1,c} + t_a x_{2,a} + t_b x_{2,b} + t_c x_{2,c} + t_c x_{2,d} \\ \text{s.t.} & x_{1,a} = 1 \\ & x_{1,b} = 1 \\ & x_{1,c} = 1 \\ & x_{2,a} = 1 \\ & x_{2,b} = 1 \\ & x_{2,c} = 1 \\ & x_{2,d} = 1 \\ & x_p \in \{0,1\}\, \forall\, p \in P \end{array} $$Well that's just ridiculous.
The solution is trivially:
$$x_{1,a} = x_{1,b} = x_{1,c} = x_{2,a} = x_{2,b} = x_{2,c} = x_{2,d} = 1$$The cost of implementing this plan is actually the worst we could possibly do:
$$2 \left(t_a + t_b + t_c\right) + t_d$$In fact it looks pretty much like we did this:
We need a variable that allows us to use the Docker cache¶
In this problem, commands $\{A, B, C\}$ are shared between images $\{1,2\}$.
So let's make a variable for that and add it to $P$.
$$x_{12,abc} \in \{0,1\}$$Of course this changes the constraints.
$$x_{1,a} + x_{12,abc} = 1$$$$x_{1,b} + x_{12,abc} = 1$$$$x_{1,c} + x_{12,abc} = 1$$$$x_{2,a} + x_{12,abc} = 1$$$$x_{b,b} + x_{12,abc} = 1$$$$x_{c,c} + x_{12,abc} = 1$$This time, with feeling¶
This one actually allows us to share the time required to run commands between images.
$$ \begin{array}{r l} \min & t_a x_{1,a} + t_b x_{1,b} + t_c x_{1,c} + t_a x_{2,a} + t_b x_{2,b} + t_c x_{2,c} + t_c x_{2,d} + \left(t_a + t_b + t_c\right) x_{12,abc}\\ \text{s.t.} & x_{1,a} + x_{12,abc} = 1 \\ & x_{1,b} + x_{12,abc} = 1 \\ & x_{1,c} + x_{12,abc} = 1 \\ & x_{2,a} + x_{12,abc} = 1 \\ & x_{2,b} + x_{12,abc} = 1 \\ & x_{2,c} + x_{12,abc} = 1 \\ & x_{2,d} = 1 \\ & x_p \in \{0,1\}\, \forall\, p \in P \end{array} $$This is much better. It gives us the correct solution.
$$x_{1,a} = x_{1,b} = x_{1,c} = x_{2,a} = x_{2,b} = x_{2,c} = 0$$$$x_{12,abc} = x_{2,d} = 1$$The minimum time is:
$$t_a + t_b + t_c + t_d$$Visually this could be represented as:

But things are not always so simple.¶
We created the variable $x_{12,abc}$ because it was obvious. $I_1 \bigcap I_2 = \{A, B, C\}$, so it was the best possible option.
But consider this set of 4 images:
$$I_3 = \{A, B, C\}$$$$I_4 = \{B, C, D\}$$$$I_5 = \{A, C, E\}$$$$I_6 = \{B, D, E\}$$In this problem instance, the values $t_a, \dots, t_e$ are what drive our final schedule.
If $t_c$ is big enough, the optimal schedule might be:
I3: C B A
I4: C B D
I5: C A E
I6: B D E
And if $t_a > t_b$ it might be:
I3: C A B
I4: C B D
I5: C A E
I6: B D E
So if we set $x_{345,c} = 1$, we have the option to use two other variables to create our schedule:
$$x_{345,c,34,b} \in \{0,1\}$$$$x_{345,c,35,a} \in \{0,1\}$$But this can only happen if $x_{345,c} = 1$. That is, $x_{345,c,34,b}$ and $x_{345,c,35,a}$ are dependent on it.
$$x_{345,c,34,b} \le x_{345,c}$$$$x_{345,c,35,a} \le x_{345,c}$$We will represent these dependencies using another set, $R$.
For all $\left(x_m, x_n\right) \in R$, any feasible solution requires that $x_m \le x_n$.
Note that dependencies have structure. We may have:
$$x_m \le x_n$$$$x_n \le x_o$$We also have to worry about intersections...¶
Recall our set of 4 images:
$$I_3 = \{A, B, C\}$$$$I_4 = \{B, C, D\}$$$$I_5 = \{A, C, E\}$$$$I_6 = \{B, D, E\}$$In addition to the variables $x_{3,a}$, $x_{3,b}$, $\dots$, $x_{6,e}$, we create $x_{345,c}$, $x_{34,bc}$, $\dots$, $x_{56,e}$ and add the appropriate $\left(\text{images}, \text{commands}\right)$ pairs to $P$.
For each image $i \in I$, and command $c \in C_i$, exactly one $x_p$ that provides $c$ for $i$ must be set to $1$. This restricts intersections in our schedule.
$$\sum_{p = \left(p_i,p_c\right) \in P,\, i \in p_i,\, c \in p_c} x_p = 1\, \forall\, i \in I,\, c \in C_i$$Now we have everything we need to build our model!
$$ \begin{array}{r l l l} \min & \sum_{p \in I} \sum_{c \in C_i} t_c x_p & \\ \text{s.t.} & \sum_{p = \left(p_i,p_c\right) \in P,\, i \in p_i,\, c \in p_c} x_p = 1 & \forall & i \in I,\, c \in C_i \\ & x_m \le x_n & \forall & \left(m, n\right) \in R \\ & x_p \in \{0,1\} & \\ \end{array} $$All we have to do is generate $P$ and $R$!
Right?
Finding maximal cliques with NetworkX¶
At some point, somebody is going to write some code.
So how do we generate $P$ and $R$?
Naive option:
- Make a graph with all images and commands
- Connect each image to its commands
- Connect images to each other
- Connect commands to each other
- Find maximal cliques!
Q: What's a maximal clique?
A: A subgraph where each pair of nodes is adjacent. If it can't be contained in another clique, it's maximal.
 A clique. Source: Wikipedia
A clique. Source: Wikipedia
Creating a graph and connect every image to its commands.

Now connect every pair of image, and every pair of commands.
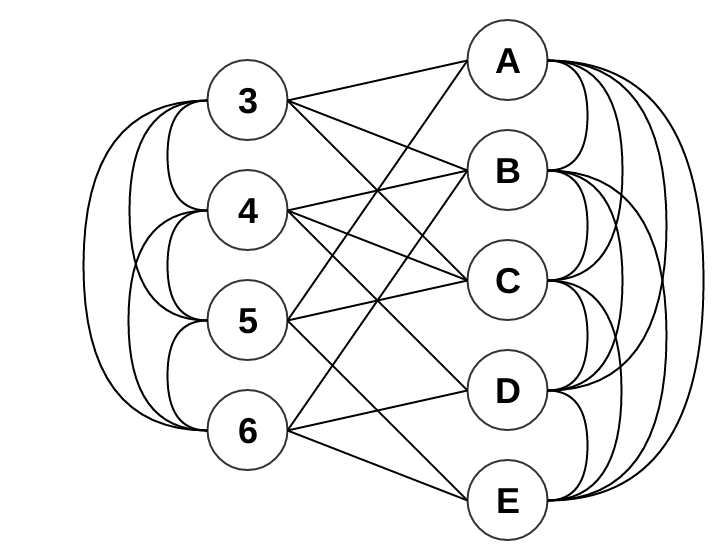
# Define the commands we have available.
commands = ['A','B','C','D','E']
# And the images we need to construct from them.
images = [3,4,5,6]
image_commands = {
3: ['A','B','C'],
4: ['B','C','D'],
5: ['A','C','E'],
6: ['B','D','E'],
}
# Make up some times we expect the commands to take.
command_times = {
'A': 5,
'B': 10,
'C': 7,
'D': 12,
'E': 8,
}
# Construct the graph shown above.
# Prefix images with 'i' and commands with 'c'.
from itertools import combinations
import networkx as nx
def build_graph(image_dict):
g = nx.Graph()
all_cmds = set()
for i, cmds in image_dict.items():
for c in cmds:
g.add_edge('i%d' % i, 'c%s' % c)
all_cmds.add(c)
for i1, i2 in combinations(image_dict, 2):
g.add_edge('i%d' % i1, 'i%d' % i2)
for c1, c2 in combinations(all_cmds, 2):
g.add_edge('c%s' % c1, 'c%s' % c2)
return g
build_graph(image_commands).nodes()
['cD', 'i3', 'cA', 'i5', 'i6', 'cE', 'i4', 'cC', 'cB']
# Generate all maximal cliques with > 1 image and >= 1 command.
from networkx.algorithms import find_cliques
def command_cliques(image_dict):
max_cliques = []
g = build_graph(image_dict)
for c in find_cliques(g):
imgs = set([int(x.replace('i','')) for x in c if x.startswith('i')])
cmds = set([x.replace('c','') for x in c if x.startswith('c')])
if len(imgs) > 1 and cmds:
max_cliques.append((imgs, cmds))
return max_cliques
# Top-level cliques (these depend on nothing)
top_cliques = command_cliques(image_commands)
top_cliques
[({4, 6}, {'B', 'D'}),
({3, 4, 6}, {'B'}),
({5, 6}, {'E'}),
({3, 4, 5}, {'C'}),
({3, 4}, {'B', 'C'}),
({3, 5}, {'A', 'C'})]
Add each of these to $P$.
Now consider each maximal clique. Let's look at $\left(\{3,4,5\},\{C\}\right)$.
$x_{345,c} = 1$ if images $\{3,4,5\}$ share command $C$.
Can they share anything after that?
Repeat the process with remaining commands for images $\{3,4,5\}$. Leave out $C$.


Max cliques:
$$\{3,4,B\}$$$$\{3,5,A\}$$Add variables to $P$:
$$x_{345,c,34,b} \in \{0,1\}$$$$x_{345,c,35,a} \in \{0,1\}$$Both depend on "parent" clique:
$$x_{345,c,34,b} \le x_{345,c}$$$$x_{345,c,35,a} \le x_{345,c}$$So add dependencies to $R$:
$$\left(x_{345,c,34,b}, x_{345,c}\right)$$$$\left(x_{345,c,35,a}, x_{345,c}\right)$$Maximal clique detection is NP-complete.
But it works better than you might think! Why?
There are more efficient ways, but that's for another day.
Partitioning sets with PuLP¶
"NP-Complete" is a term used to scare graduate students.
We have a "set partitioning problem" with side constraints.¶
Let's ignore dependencies. Say $R = \emptyset$.
A optimal "schedule" is a set of $x_p$ variables we set to $1$ that:
- Assigns each image all its commands once
- Minimizes required compute time
Mathematically, set partitioning looks like:
$$ \begin{array}{r l} \min|\max & c^\intercal x \\ \text{s.t.} & Ax = 1 \\ & x \in \{0,1\}^n \\ \end{array} $$Where $c^\intercal \in \mathcal{R}^n$ and $A \in \{0,1\}^{m \times n}$
Real world data is usually NOT pathological.
We have really good technology for solving set partitions.
- Heuristics
- Optimization (combinatorial, dynamic)
So even with the dependency constraints, we're probably OK.
# Let's build a model!
import pulp
m = pulp.LpProblem('Docker schedule', pulp.LpMinimize)
x = {} # binary variables
obj = 0.0 # objective = minimize required time
# These variables are on when images do not share the results of commands.
for i, cmds in image_commands.items():
for c in cmds:
n = '%d-%s' % (i,c)
x[n] = pulp.LpVariable(name=n, cat=pulp.LpBinary)
# Create variables for cliques. (Normally we'd do this automatically.)
x['46-BD'] = pulp.LpVariable(name='46-BD', cat=pulp.LpBinary)
x['346-B'] = pulp.LpVariable(name='346-B', cat=pulp.LpBinary)
x['56-E' ] = pulp.LpVariable(name='56-E', cat=pulp.LpBinary)
x['345-C'] = pulp.LpVariable(name='345-C', cat=pulp.LpBinary)
x['34-BC'] = pulp.LpVariable(name='34-BC', cat=pulp.LpBinary)
x['35-AC'] = pulp.LpVariable(name='35-AC', cat=pulp.LpBinary)
# These are child cliques we generate using subgraphs.
x['346-B-34-C'] = pulp.LpVariable(name='346-B-34-C', cat=pulp.LpBinary)
x['346-B-46-D'] = pulp.LpVariable(name='346-B-46-D', cat=pulp.LpBinary)
x['345-C-34-B'] = pulp.LpVariable(name='345-C-34-B', cat=pulp.LpBinary)
x['345-C-35-A'] = pulp.LpVariable(name='345-C-35-A', cat=pulp.LpBinary)
# Dependencies from parent to child cliques.
m += x['346-B-34-C'] <= x['346-B']
m += x['346-B-46-D'] <= x['346-B']
m += x['345-C-34-B'] <= x['345-C']
m += x['345-C-35-A'] <= x['345-C']
# Restrict intersecting cliques at the same level.
m += x['346-B'] + x['345-C'] + x['34-BC'] + x['35-AC'] <= 1 # image 3
m += x['46-BD'] + x['346-B'] + x['345-C'] + x['34-BC'] <= 1 # image 4
m += x['56-E' ] + x['345-C'] + x['35-AC'] <= 1 # image 5
m += x['46-BD'] + x['346-B'] + x['56-E' ] <= 1 # image 6
m += x['346-B-34-C'] + x['346-B-46-D'] <= 1 # image 4
m += x['345-C-34-B'] + x['345-C-35-A'] <= 1 # image 3
# Each image runs each command exactly once.
for i, cmds in image_commands.items():
for c in cmds:
m += sum(x[n] for n in x if str(i) in n and c in n) == 1
# Objective: minimize the required compute time.
obj = 0.0
for n, x_p in x.items():
t = sum(command_times.get(c,0) for c in n) # a little hacky...
obj += t * x_p
# Use a variable so it's easy to pull out the objective value.
z = pulp.LpVariable('objective', lowBound=0)
m += z == obj
m.setObjective(z)
assert m.solve() == pulp.LpStatusOptimal
print('Time required:', pulp.value(z))
print('Schedule:')
for n, x_p in x.items():
if pulp.value(x_p) > 0.5:
print('\t', n)
Time required: 67.0 Schedule: 35-AC 46-BD 6-E 3-B 5-E 4-C
To translate that output into a real schedule, first add any cliques to the schedule:
I3: A C
I4: B D
I5: A C
I6: B D
The remaining commands go at the end:
I3: A C B
I4: B D C
I5: A C E
I6: B D E
Computational example¶
No, really. That's how we do this thing.
An example with 15 images and 25 commands.¶
A randomly generated instance. These are the images and their commands.
{
"images": {
"01": ["03", "05", "07", "08", "09", "11", "14", "15", "18", "19", "24"],
"02": ["02", "05", "07", "10", "15", "20", "22", "23", "25"],
"03": ["08", "12", "14", "15", "16", "17"],
"04": ["03", "05", "13", "14", "17"],
"05": ["03", "05", "09", "15", "17", "18", "20", "21", "22", "23", "24", "25"],
"06": ["04", "08", "12", "13", "16", "17"],
"07": ["01", "03", "04", "05", "07", "08", "12", "15", "19", "24", "25"],
"08": ["11", "13", "15", "16"],
"09": ["01", "03", "11", "13", "17", "22", "24"],
"10": ["08", "12", "13", "14", "15", "19", "24", "25"],
"11": ["04"],
"12": ["07", "12", "16", "19", "22", "25"],
"13": ["01", "06", "07", "16", "18", "19", "21", "25"],
"14": ["05", "10", "11", "13", "14", "22"],
"15": ["01", "02", "03", "04", "11", "15"]
},
And the time required for each command.
"commands": {
"01": 58,
"02": 98,
"03": 68,
"04": 152,
"05": 60,
"06": 79,
"07": 463,
"08": 95,
"09": 532,
"10": 51,
"11": 128,
"12": 88,
"13": 65,
"14": 155,
"15": 97,
"16": 148,
"17": 340,
"18": 115,
"19": 109,
"20": 14,
"21": 94,
"22": 61,
"23": 149,
"24": 43,
"25": 31
}
}
And the optimal image construction schedule!
{
"unique_images": 73,
"compute_time": 9414,
"schedule": {
"01": ["15", "08", "24", "19", "05", "07", "03", "11", "14", "09", "18"],
"02": ["15", "05", "20", "23", "22", "25", "07", "10", "02"],
"03": ["15", "08", "14", "12", "16", "17"],
"04": ["13", "17", "03", "05", "14"],
"05": ["15", "05", "20", "23", "22", "25", "18", "24", "17", "09", "03", "21"],
"06": ["13", "17", "16", "08", "04", "12"],
"07": ["15", "08", "24", "19", "05", "07", "03", "12", "04", "25", "01"],
"08": ["15", "11", "16", "13"],
"09": ["13", "17", "03", "01", "22", "11", "24"],
"10": ["15", "08", "24", "19", "12", "14", "25", "13"],
"11": ["04"],
"12": ["19", "07", "25", "16", "12", "22"],
"13": ["19", "07", "25", "16", "18", "21", "01", "06"],
"14": ["13", "14", "05", "10", "11", "22"],
"15": ["15", "11", "01", "04", "02", "03"]
}
}
How does this compare to a heuristic solution?¶
We'll call this the most-common heuristic. It makes the greediest choice possible at each step.
most-common(images):- Choose the most common unscheduled command for
images - Add it to the schedule next for
images images2= subset ofimagesfor which command was scheduledmost-common(images2)most-common(images \ images2)
- Choose the most common unscheduled command for
The heuristic is > 10% worse for this particular instance.
{
"unique_images": 80,
"compute_time": 10531,
"schedule": {
"01": ["15", "03", "24", "05", "11", "07", "19", "18", "08", "09", "14"],
"02": ["15", "02", "10", "25", "05", "20", "07", "22", "23"],
"03": ["15", "08", "12", "14", "17", "16"],
"04": ["13", "17", "03", "14", "05"],
"05": ["15", "03", "24", "05", "25", "20", "21", "18", "09", "17", "22", "23"],
"06": ["13", "17", "08", "12", "04", "16"],
"07": ["15", "03", "24", "05", "25", "12", "19", "08", "01", "07", "04"],
"08": ["15", "13", "11", "16"],
"09": ["13", "17", "03", "11", "24", "01", "22"],
"10": ["15", "13", "24", "19", "25", "08", "12", "14"],
"11": ["04"],
"12": ["25", "07", "16", "19", "12", "22"],
"13": ["25", "07", "16", "19", "18", "01", "06", "21"],
"14": ["13", "11", "10", "14", "22", "05"],
"15": ["15", "03", "02", "11", "01", "04"]
}
}