Training Agent, action converters and l2rpn_baselines¶
Try me out interactively with: ![]()
It is recommended to have a look at the 0_basic_functionalities, 1_Observation_Agents and 2_Action_GridManipulation notebooks before getting into this one.
Objectives
In this notebook we will expose :
- how to use the "converters": these allow to link several different representations of the actions (for example as
Actionobjects or integers). - how to train a (naive) Agent using reinforcement learning.
- how to inspect (rapidly) the action taken by the Agent.
NB In this tutorial, we train an Agent inspired from this blog post: deep-reinforcement-learning-tutorial-with-open-ai-gym. Many other different reinforcement learning tutorials exist. The code presented in this notebook only aims at demonstrating how to use the Grid2Op functionalities to train a Deep Reinforcement learning Agent and inspect its behaviour, but not at building a very smart agent. Nothing about the performance, training strategy, type of Agent, meta parameters, etc, should be retained as a common practice.
import os
import sys
import grid2op
res = None
try:
from jyquickhelper import add_notebook_menu
res = add_notebook_menu()
except ModuleNotFoundError:
print("Impossible to automatically add a menu / table of content to this notebook.\nYou can download \"jyquickhelper\" package with: \n\"pip install jyquickhelper\"")
res
I) Manipulating action representation¶
The Grid2op package has been built with an "object-oriented" perspective: almost everything is encapsulated in a dedicated class. This allows for more customization of the plateform.
The downside of this approach is that machine learning methods, especially in deep learning, often prefer to deal with vectors rather than with "complex" objects. Indeed, as we covered in the previous tutorials on the platform, we saw that building our own actions can be tedious and can sometime require important knowledge of the powergrid.
On the contrary, in most of the standard Reinforcement Learning environments, actions have a higher representation. For example in pacman, there are 4 different types of actions: turn left, turn right, go up and do down. This allows for easy sampling (if you need to achieve an uniform sampling, you simply need to randomly pick a number between 0 and 3 included) and an easy representation: each action can be represented as a different component of a vector of dimension 4 [because there are 4 actions].
On the other hand, this representation is not "human friendly". It is quite convenient in the case of pacman because the action space is rather small, making it possible to remember which action corresponds to which component, but in the case of the grid2op package, there are hundreds or even thousands of actions, making it impossible to remember which component corresponds to which action. We suppose that we do not really care about this here, as tutorials on Reinforcement Learning with discrete action space often assume that actions are labeled with integers (such as in pacman for example).
However, to allow RL agent to train more easily, we allow to make some "Converters" whose roles are to allow an agent to deal with a custom representation of the action space. The class AgentWithConverter is perfect for such usage.
# import the usefull class
import numpy as np
from grid2op import make
from grid2op.Agent import RandomAgent
max_iter = 100 # to make computation much faster we will only consider 50 time steps instead of 287
train_iter = 1000
env_name = "rte_case14_redisp"
env = make(env_name, test=True)
env.seed(0) # this is to ensure all sources of randomness in the environment are reproducible
my_agent = RandomAgent(env.action_space)
my_agent.seed(0) # this is to ensure that all actions made by this random agent will be the same
And that's it. This agent will be able to perform any action, but instead of going through the description of the actions from a powersystem point of view (ie setting what is connected to what, what is disconnected etc.) it will simply choose an integer with the method my_act. This integer will then be converted back to a proper action.
Here is an example of the action representation as seen by the Agent (here, integers):
for el in range(3):
print(my_agent.my_act(None, None))
Below you can see that the act function behaves as expected, handling proper Action objects:
for el in range(3):
print(my_agent.act(None, None))
NB lots of these actions are equivalent to the "do nothing" action at some point. For example, trying to reconnect a powerline that is already connected will not do anything. The same for topology. If everything is already connected to bus 1, then the action to connect things to bus 1 on the same substation will not affect the powergrid.
II) Training an Agent¶
In this tutorial, we will show how to build a Q-learning Agent. Most of the code originated from this blog post (which was deleted) https://towardsdatascience.com/deep-reinforcement-learning-tutorial-with-open-ai-gym-c0de4471f368.
The goal of this notebook is to demonstrate how to train an agent using grid2op framework. The key message is: since grid2op fully implements the gym API, it is rather easy to do. We will use the l2rpn baselines repository and implement a Double Dueling Deep Q learning Algorithm. For more information, you can look for the code in the dedicated repository here.
Requirements This notebook requires having keras installed on your machine as well as the l2rpn_baselines repository.
As always in these notebooks, we will use the rte_case14_realistic test Environment. More data is available if you don't pass the test=True parameters.
II.A) Defining some "helpers"¶
The type of Agent we are using requires a bit of setup, independantly of Grid2Op. We will reuse the code shown in https://towardsdatascience.com/deep-reinforcement-learning-tutorial-with-open-ai-gym-c0de4471f368 and in Reinforcement-Learning-Tutorial from Abhinav Sagar. The code is registered under the MIT license found here: MIT License.
This first section aims at defining these classes.
You will need to install the l2rpn_baselines library. Since this library is uploaded on Pypi this can be done easily.
print("To install l2rpn_baselines, either uncomment the cell below, or type, in a command prompt:\n{}".format(
("\t{} -m pip install l2rpn_baselines".format(sys.executable))))
# !$sys.executable -m pip install l2rpn_baselines
But first let's import the necessary dependencies :
#tf2.0 friendly
import numpy as np
import random
import warnings
import l2rpn_baselines
II.B) Adaptation of the inputs¶
For many of the Deep Reinforcement Learning problems (for example for model used to play Atari games), the inputs are images and the outputs are integers that encode the different possible actions (typically "move up" or "move down" in Atari). In our system (the powergrid) it is rather different. We did our best to make the convertion between complex and simple structures easy. Indeed, the use of converters such as (IdToAct) allows easily to:
- convert the class "Observation" into vectors automatically
- map the actions from integers to complete
Actionobjects defined in the previous notebooks
In essence, a converter allows to manipulate the "action space" of the Agent and is such that:
- the Agent manipulates a simple, custom structure of actions
- the Converter takes care of mapping from this simple structure to complex grid2op Action / Observation objects
- as a whole, the Agent will actually return full Action / Observation objects to the environment while only working with more simple objects
A note on the converter¶
To use this converter, the Agent must inherit from the class grid2op.Agent.AgentWithConverter and implement the following interface (shown here as an example):
from grid2op.Agent import AgentWithConverter
class MyAgent(AgentWithConverter):
def __init__(self, action_space, action_space_converter=None):
super(MyAgent, self).__init__(action_space=action_space, action_space_converter=action_space_converter)
# for example you can define here all the actions you will consider
self.my_actions = [action_space(),
action_space({"redispatching": [0,+1]}),
action_space({"set_line_status": [(0,-1)]}),
action_space({"change_bus": {"lines_or_id": [12]}}),
...
]
# or load them from a file for example...
# self.my_action = np.load("my_action_pre_selected.npy")
# you can also in this agent load a neural network...
self.my_nn_model = model.load("my_saved_neural_network_weights.h5")
def convert_obs(self, observation):
"""
This method is used to convert the observation, represented as a class Observation in input
into a "transformed_observation" that will be manipulated by the agent
An example here will transform the observation into a numpy array.
It is recommended to modify it to suit your needs.
"""
return observation.to_vect()
def convert_act(self, encoded_act):
"""
This method will take an "encoded_act" (for example a integer) into a valid grid2op action.
"""
if encoded_act < 0 or encoded_act > len(self.my_action):
raise RuntimeError("Invalid action with id {}".format(encoded_act))
return self.my_actions[encoded_act]
def my_act(self, transformed_observation, reward, done=False):
"""
This is the main function where you can take your decision.
Instead of:
- calling "act(observation, reward, done)" you implement
"my_act(transformed_observation, reward, done)"
- this manipulates only "transformed_observation" fully flexible as you defined "convert_obs"
- and returns "encoded_action" that are then digest automatically by
"convert_act(encoded_act)" and to return valid actions.
Here we suppose, as many dqn agent, that `my_nn_model` return a vector of size
nb_actions filled with number between 0 and 1 and we take the action given the highest score
"""
pred_score = self.my_nn_model.predict(transformed_observation, reward, done)
res = np.argmax(pred_score)
return res
And that's it. There is nothing else to do, your agent is ready to learn how to control a powergrid using only these 3 functions.
NB A few things are worth noting:
- if you use an agent with a converter, do not modify the method act but rather change the method my_act, this is really important !
- the method my_act, which you will have to implement, takes a transformed observation as an argument and must return a transformed action. This transformed action will then be converted back to the original action space to an actual
Actionobject in the act method, that you must leave unchanged. - some automatic functions can compute the set of all possible actions, so there is no need to write "self.my_actions = ...". This was done as an example only.
- if the converter is properly set up, you don't even need to modify "convert_obs(self, observation)" and "convert_act(self, encoded_act)" as default convertions are already provided in the implementation. However, if you want to work with a custom observation space and action space, you can modify these two methods in order to have the convertions that you need.
Here, we consider the observation as a whole and do not try any modifications of the features. This means that the vector (the observation) that the agent will receive is going to be really big, not scaled and filled with a lot of information that may not be really useful. It could be tried to select only a subset of the available features and apply a pre-processing function to them.
II.C) Writing the code of the Agent and train it¶
a) Code of the agent¶
Here we show the most interesting part (in this tutorial) of the code that is implemented as a baseline. For a full description of the code, you can go take a look here.
This is the DuelQ_NN.py file (we copy pasted the function defined in its base class l2rpn_baselines.utils.BaseDeepQ.py for clarity):
import tensorflow.keras as tfk
class DuelQ_NN(BaseDeepQ):
"""Constructs the desired deep q learning network"""
def __init__(self,
nn_params, # neural network meta parameters, defining its architecture
training_param=None # training scheme (learning rate, learning rate decay, etc.)
):
self.action_size = action_size
self.observation_size = observation_size
HIDDEN_FOR_SIMPLICITY
def construct_q_network(self):
"""
It uses the architecture defined in the `nn_archi` attributes.
"""
self.model = Sequential()
input_layer = Input(shape=(self.nn_archi.observation_size,),
name="observation")
lay = input_layer
for lay_num, (size, act) in enumerate(zip(self.nn_archi.sizes, self.nn_archi.activs)):
lay = Dense(size, name="layer_{}".format(lay_num))(lay) # put at self.action_size
lay = Activation(act)(lay)
fc1 = Dense(self.action_size)(lay)
advantage = Dense(self.action_size, name="advantage")(fc1)
fc2 = Dense(self.action_size)(lay)
value = Dense(1, name="value")(fc2)
meaner = Lambda(lambda x: K.mean(x, axis=1))
mn_ = meaner(advantage)
tmp = subtract([advantage, mn_])
policy = add([tmp, value], name="policy")
self.model = Model(inputs=[input_layer], outputs=[policy])
self.schedule_model, self.optimizer_model = self.make_optimiser()
self.model.compile(loss='mse', optimizer=self.optimizer_model)
self.target_model = Model(inputs=[input_layer], outputs=[policy])
def predict_movement(self, data, epsilon, batch_size=None):
"""
Predict movement of game controler where is epsilon
probability randomly move.
This was part of the BaseDeepQ and was copy pasted without any modifications
"""
if batch_size is None:
batch_size = data.shape[0]
rand_val = np.random.random(batch_size)
q_actions = self.model.predict(data, batch_size=batch_size)
opt_policy = np.argmax(np.abs(q_actions), axis=-1)
opt_policy[rand_val < epsilon] = np.random.randint(0, self.action_size, size=(np.sum(rand_val < epsilon)))
return opt_policy, q_actions[0, opt_policy]
This is the DoubleDuelingDQN.py file:
from grid2op.Agent import AgentWithConverter # all converter agent should inherit this
from grid2op.Converter import IdToAct # this is the automatic converter to convert action given as ID (integer)
# to valid grid2op action (in particular it is able to compute all actions).
from l2rpn_baselines.DoubleDuelingDQN.DoubleDuelingDQN_NN import DoubleDuelingDQN_NN
class DuelQSimple(DeepQAgent):
def __init__(self,
action_space,
nn_archi,
HIDDEN_FOR_SIMPLICITY
):
...
HIDDEN_FOR_SIMPLICITY
...
# Load network graph
self.deep_q = None ## is loaded when first called or when explicitly loaded
## Agent Interface
def convert_obs(self, observation):
"""
Generic way to convert an observation. This transform it to a vector and the select the attributes
that were selected in :attr:`l2rpn_baselines.utils.NNParams.list_attr_obs` (that have been
extracted once and for all in the :attr:`DeepQAgent._indx_obs` vector).
"""
obs_as_vect = observation.to_vect()
self._tmp_obs[:] = obs_as_vect[self._indx_obs]
return self._tmp_obs
def convert_act(self, action):
"""
calling the convert_act method of the base class.
This is not mandatory as this is the standard behaviour in OOP (object oriented programming)
We only show it here as illustration.
"""
return super().convert_act(action)
def my_act(self, transformed_observation, reward, done=False):
"""
This function will return the action (its id) selected by the underlying
:attr:`DeepQAgent.deep_q` network.
Before being used, this method require that the :attr:`DeepQAgent.deep_q` is created.
To that end a call to :func:`DeepQAgent.init_deep_q` needs to have been performed
(this is automatically done if you use baseline we provide and their `evaluate`
and `train` scripts).
"""
predict_movement_int, *_ = self.deep_q.predict_movement(transformed_observation, epsilon=0.0)
res = int(predict_movement_int)
self._store_action_played(res)
return res
b) Training the model¶
Now we can define the agent and train it.
To that extent, we will use the "train" method provided in the l2rpn_baselines repository.
NB The code below can take a few minutes to run. It's training a Deep Reinforcement Learning Agent after all. It this takes too long on your machine, you can always decrease the "nb_frame", and set it to 1000 for example. In this case, the Agent will probably not be really good.
NB It would take much longer to train a good agent.
# create an environment
env = make(env_name, test=True)
# don't forget to set "test=False" (or remove it, as False is the default value) for "real" training
# import the train function and train your agent
from l2rpn_baselines.DuelQSimple import train
from l2rpn_baselines.utils import NNParam, TrainingParam
agent_name = "test_agent"
save_path = "saved_agent_DDDQN_{}".format(train_iter)
logs_dir="tf_logs_DDDQN"
# we then define the neural network we want to make (you may change this at will)
## 1. first we choose what "part" of the observation we want as input,
## here for example only the generator and load information
## see https://grid2op.readthedocs.io/en/latest/observation.html#main-observation-attributes
## for the detailed about all the observation attributes you want to have
li_attr_obs_X = ["prod_p", "prod_v", "load_p", "load_q"]
# this automatically computes the size of the resulting vector
observation_size = NNParam.get_obs_size(env, li_attr_obs_X)
## 2. then we define its architecture
sizes = [300, 300, 300] # 3 hidden layers, of 300 units each, why not...
activs = ["relu" for _ in sizes] # all followed by relu activation, because... why not
## 4. you put it all on a dictionnary like that (specific to this baseline)
kwargs_archi = {'observation_size': observation_size,
'sizes': sizes,
'activs': activs,
"list_attr_obs": li_attr_obs_X}
# you can also change the training parameters you are using
# more information at https://l2rpn-baselines.readthedocs.io/en/latest/utils.html#l2rpn_baselines.utils.TrainingParam
tp = TrainingParam()
tp.batch_size = 32 # for example...
tp.update_tensorboard_freq = int(train_iter / 10)
tp.save_model_each = int(train_iter / 3)
tp.min_observation = int(train_iter / 5)
train(env,
name=agent_name,
iterations=train_iter,
save_path=save_path,
load_path=None, # put something else if you want to reload an agent instead of creating a new one
logs_dir=logs_dir,
kwargs_archi=kwargs_archi,
training_param=tp)
Logs are saved in the "tf_logs_DDDQN" log repository. To watch what happens during training, you can type the command (from a bash command line for example):
tensorboard --logdir='tf_logs_DDDQN'
You can even do it while it's training. Tensorboard allows you to monitor, during training, different quantities, for example the loss of your neural network or even the last number of steps the agent performed before getting a game over etc.
At first glimpse here is what it could look like (only the first graph out of :
| Monitoring of the training | Representation as a graph of the neural network |
|---|---|
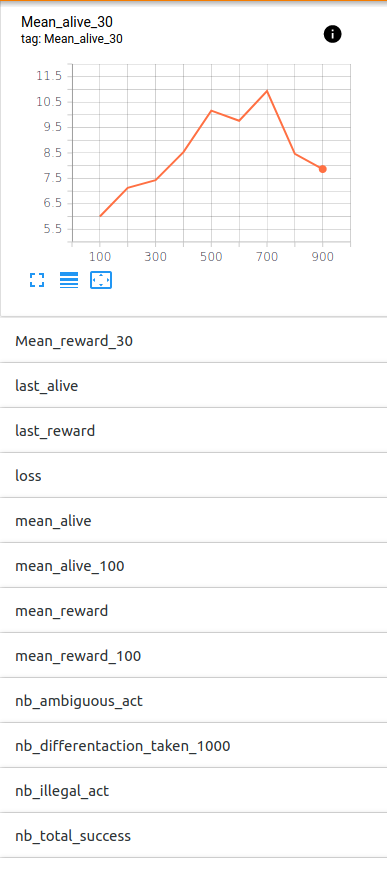 |
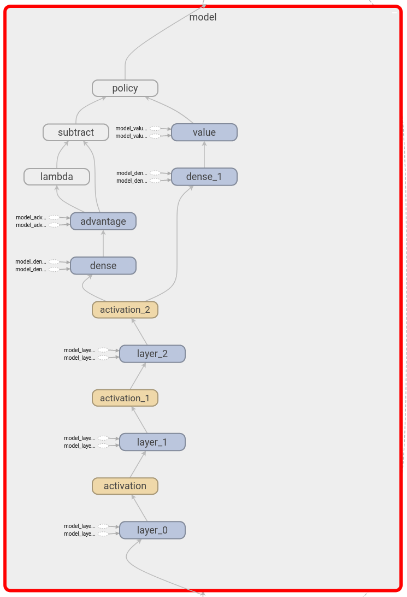 |
III) Evaluating the Agent¶
And now, it is time to test the agent that we trained.
To do that, we have multiple choices.
We can either re-code the "DeepQAgent" class to load the stored weights (that have been saved during training) when it is initialized (this is not covered in this notebook), or we can also directly specify the instance of the Agent to use in the Grid2Op Runner.
Doing this is fairly simple. First, you need to specify that you won't use the "agentClass" argument by setting it to None, and secondly you simply have to provide the agent instance to be used as the agentInstance argument.
NB If you don't do that, the Runner will be created (the constructor will raise an exception). If you choose to feed the "agentClass" argument with a class, your agent will be re-instanciated from scratch with this class. If you do re-instanciate your agent and if it is not planned in the class to load pre-trained weights, then the agent will not be pre-trained and will be unlikely to perform well on the task.
III.A) Evaluate the Agent¶
Now that we have "successfully" trained our Agent, we will evaluate it. The evaluation can be done classically using a standard Runner with the following code:
from grid2op.Runner import Runner
from tqdm.notebook import tqdm
# chose a scoring function (might be different from the reward you use to train your agent)
from grid2op.Reward import L2RPNReward
scoring_function = L2RPNReward
path_save_results = "{}_results".format(save_path)
# load your agent (a bit technical to know exactly what to import and how to use it)
# this is why we made the "evaluate" function that simplifies greatly the process.
from l2rpn_baselines.DuelQSimple import DuelQSimple
from l2rpn_baselines.DuelQSimple import DuelQ_NNParam
path_model, path_target_model = DuelQ_NNParam.get_path_model(save_path, agent_name)
nn_archi = DuelQ_NNParam.from_json(os.path.join(path_model, "nn_architecture.json"))
my_agent = DuelQSimple(env.action_space, nn_archi, name=agent_name)
my_agent.load(save_path)
my_agent.init_obs_extraction(env)
# here we do that to limit the time take, and will only assess the performance on "max_iter" iteration
dict_params = env.get_params_for_runner()
dict_params["gridStateclass_kwargs"]["max_iter"] = max_iter
# make a runner from an intialized environment
runner = Runner(**dict_params, agentClass=None, agentInstance=my_agent)
# run the episode
res = runner.run(nb_episode=2, path_save=path_save_results, pbar=tqdm)
print("The results for the trained agent are:")
for _, chron_name, cum_reward, nb_time_step, max_ts in res:
msg_tmp = "\tFor chronics located at {}\n".format(chron_name)
msg_tmp += "\t\t - total score: {:.6f}\n".format(cum_reward)
msg_tmp += "\t\t - number of time steps completed: {:.0f} / {:.0f}".format(nb_time_step, max_ts)
print(msg_tmp)
NB In this case, the Runner will use a "scoring function" that might be different from the "reward function" used during training. In our case, We use the L2RPNReward function for both training and evaluating. This is not mandatory.
But there is, and this is a requirement for all "baselines" an "evaluate" function that does precisely that. We will use that in this notebook.
from l2rpn_baselines.DuelQSimple import evaluate
path_save_results = "{}_results".format(save_path)
evaluated_agent, res_runner = evaluate(env,
name=agent_name,
load_path=save_path,
logs_path=path_save_results,
nb_episode=2,
nb_process=1,
max_steps=100,
verbose=True,
save_gif=False)
III.B) Inspect the Agent¶
Please refer to the official documentation for more information about the contents of the directory where the data is saved. Note that saving the information is triggered by the "path_save" argument of the "runner.run" function.
The information contained in this output will be saved in a structured way and includes : For each episode :
"episode_meta.json": json file that represents some meta information about:
- "backend_type": the name of the
grid2op.Backendclass used - "chronics_max_timestep": the maximum number of timesteps for the chronics used
- "chronics_path": the path where the temporal data (chronics) are located
- "env_type": the name of the
grid2op.Environmentclass used. - "grid_path": the path where the powergrid has been loaded from
- "backend_type": the name of the
"episode_times.json": json file that gives some information about the total time spent in multiple parts of the runner, mainly the
grid2op.Agent(and especially its methodgrid2op.Agent.act) and thegrid2op.Environment"_parameters.json": json representation of the
grid2op.Parametersused for this episode"rewards.npy": numpy 1d-array giving the rewards at each time step. We adopted the convention that the stored reward at index
iis the one observed by the agent at timeiand NOT the reward sent by thegrid2op.Environmentafter the action has been taken."exec_times.npy": numpy 1d-array giving the execution time for each time step in the episode
"actions.npy": numpy 2d-array giving the actions that have been taken by the
grid2op.Agent. At rowiof "actions.npy" is a vectorized representation of the action performed by the agent at timestepiie. after having observed the observation present at rowiof "observation.npy" and the reward showed in rowiof "rewards.npy"."disc_lines.npy": numpy 2d-array that tells which lines have been disconnected during the simulation of the cascading failure at each time step. The same convention has been adopted for "rewards.npy". This means that the powerlines are disconnected when the
grid2op.Agenttakes thegrid2op.Actionat time stepi."observations.npy": numpy 2d-array representing the
grid2op.Observationat the disposal of thegrid2op.Agentwhen he took his action.
We can first look at the repository were the data is stored:
import os
os.listdir(path_save_results)
As we can see there are 2 folders, each corresponding to a chronics. There are also additional json files.
Now let's see what is inside one of these folders:
os.listdir(os.path.join(path_save_results, "0"))
For example, we can load the actions chosen by the Agent, and have a look at them.
To do that, we will load the action array and use the action_space function to convert it back to Action objects.
from grid2op.Episode import EpisodeData
this_episode = EpisodeData.from_disk(path_save_results, name="0")
all_actions = this_episode.get_actions()
li_actions = []
for i in range(all_actions.shape[0]):
try:
tmp = runner.env.action_space.from_vect(all_actions[i,:])
li_actions.append(tmp)
except:
break
This allows us to have a deeper look at the actions, and their effects.
Now we will inspect the actions that has been taken by the agent :
line_disc = 0
line_reco = 0
for act in li_actions:
dict_ = act.as_dict()
if "set_line_status" in dict_:
line_reco += dict_["set_line_status"]["nb_connected"]
line_disc += dict_["set_line_status"]["nb_disconnected"]
print(f'Total reconnected lines : {line_reco}')
print(f'Total disconnected lines : {line_disc}')
As we can see, during this episode, our agent never tries to disconnect or reconnect a line.
We can also analyse the observations of the recorded episode :
all_observations = this_episode.get_observations()
li_observations = []
nb_real_disc = 0
for i in range(all_observations.shape[0]):
try:
tmp = runner.env.observation_space.from_vect(all_observations[i,:])
li_observations.append(tmp)
nb_real_disc += (np.sum(tmp.line_status == False))
except:
break
print(f'Total number of disconnected powerlines cumulated over all the timesteps : {nb_real_disc}')
We can also look at the kind of actions that the agent chose:
actions_count = {}
for act in li_actions:
act_as_vect = tuple(act.to_vect())
if not act_as_vect in actions_count:
actions_count[act_as_vect] = 0
actions_count[act_as_vect] += 1
print("The agent did {} different valid actions:\n".format(len(actions_count)))
The actions chosen by the agent were :
all_act = np.array(list(actions_count.keys()))
for act in all_act:
print(runner.env.action_space.from_vect(act))
IV) Improve your Agent¶
As we saw, the agent we developped was not really interesting. To improve it, we could think about:
- a better encoding of the observation. For now everything, the whole observation is fed to the neural network, and we do not try to modify it at all. This is a real problem for learning algorithms.
- a better neural network architecture (as said, we didn't pay any attention to it in our model)
- training it for a longer time
- adapting the learning rate and all the hyper-parameters of the learning algorithm.
- etc.
In this notebook, we will focus on changing the observation representation, by only feeding to the agent a part of the available information.
To do so, the only thing that we need to do is to modify the way the observation is converted in the convert_obs method, and that is it. Nothing else needs to be changed. Here for example, we could think of only using the flow ratio (i.e., the current flow divided by the thermal limit, named rho) instead of feeding the whole observation to the agent
And we can reuse the generic method provided by l2rpn_baselines to train it.
train_iter2 = int(1.5*train_iter) # train longer
agent_name2 = "{}_2".format(agent_name)
save_path2 = "saved_agent2_DDDQN_{}".format(train_iter2)
logs_dir2="tf_logs_DDDQN"
# we then define the neural network we want to make (you may change this at will)
## 1. first we choose what "part" of the observation we want as input,
## here for example only the generator and load information
## see https://grid2op.readthedocs.io/en/latest/observation.html#main-observation-attributes
## for the detailed about all the observation attributes you want to have
li_attr_obs_X2 = ["prod_p", "prod_v", "load_p", "load_q", "rho", "topo_vect"] # add some more information
# this automatically computes the size of the resulting vector
observation_size2 = NNParam.get_obs_size(env, li_attr_obs_X2)
## 2. then we define its architecture
sizes2 = [500, 500, 500, 500] # 3 put a bigger network (both deeper and wider)
activs2 = ["relu" for _ in sizes] # all followed by relu activation, because... why not
## 4. you put it all on a dictionnary like that (specific to this baseline)
kwargs_archi2 = {'observation_size': observation_size2,
'sizes': sizes2,
'activs': activs2,
"list_attr_obs": li_attr_obs_X2}
# you can also change the training parameters you are using
# more information at https://l2rpn-baselines.readthedocs.io/en/latest/utils.html#l2rpn_baselines.utils.TrainingParam
tp2 = TrainingParam()
tp2.batch_size = 32 # for example...
tp2.update_tensorboard_freq = int(train_iter2 / 10)
tp2.save_model_each = int(train_iter2 / 3)
tp2.min_observation = int(train_iter2 / 5)
train(env,
name=agent_name2,
iterations=train_iter2,
save_path=save_path2,
load_path=None, # put something else if you want to reload an agent instead of creating a new one
logs_dir=logs_dir,
kwargs_archi=kwargs_archi2,
training_param=tp2)
And we re-use the code that we wrote earlier to assess its performance.
path_save_results2 = "{}_results".format(save_path2)
evaluated_agent2, res_runner2 = evaluate(env,
name=agent_name2,
load_path=save_path2,
logs_path=path_save_results2,
nb_episode=2,
nb_process=1,
max_steps=100,
verbose=True,
save_gif=False)