Agent, RL and MultiEnvironment¶
Try me out interactively with: ![]()
It is recommended to have a look at the 0_basic_functionalities, 1_Observation_Agents and 2_Action_GridManipulation and especially 3_TrainingAnAgent notebooks before getting into this one.
Objectives
In this notebook we will expose :
- what is a "SingleEnvMultiProcess" (previously MultiEnvironment)
- how can it be used with an agent
- how can it be used to train a agent that uses different environments (using the l2rpn-baselines python package)
res = None
try:
from jyquickhelper import add_notebook_menu
res = add_notebook_menu()
except ModuleNotFoundError:
print("Impossible to automatically add a menu / table of content to this notebook.\nYou can download \"jyquickhelper\" package with: \n\"pip install jyquickhelper\"")
res
import grid2op
from grid2op.Reward import ConstantReward, FlatReward
from tqdm.notebook import tqdm
from grid2op.Runner import Runner
import sys
import os
import numpy as np
TRAINING_STEP = 100
I) Make a regular environment and agent¶
By default we use the test environment. But by passing test=False in the following function will automatically download approximately 300MB from the internet and give you 1000 chronics instead of 2 used for this example.
env = grid2op.make("rte_case14_realistic", test=True)
/home/benjamin/Documents/grid2op_dev/getting_started/grid2op/MakeEnv/Make.py:248: UserWarning: You are using a development environment. This environment is not intended for training agents.
A lot of data have been made available for the default "rte_case14_realistic" environment. Including this data in the package is not convenient.
We chose instead to release them and make them easily available with a utility. To download them in the default directory ("~/data_grid2op/case14_redisp") just pass the argument "test=False" (or don't pass anything else) as local=False is the default value. It will download approximately 300Mo of data.
II) Train a standard RL Agent¶
Make sure you are using a computer with at least 4 cores if you want to notice some speed-ups.
from grid2op.Environment import SingleEnvMultiProcess
from grid2op.Agent import DoNothingAgent
NUM_CORE = 2
IIIa) Using the standard open AI gym loop¶
Here we demonstrate how to use the multi environment class. First let's create a multi environment.
# create a simple agent
agent = DoNothingAgent(env.action_space)
# create the multi environment class
multi_envs = SingleEnvMultiProcess(env=env, nb_env=NUM_CORE)
A multienvironment is just like a regular environment but instead of dealing with one action, and one observation, is requires to be sent multiple actions, and returns a list of observations as well.
It requires a grid2op environment to be initialized and creates some specific "workers", each a replication of the initial environment. None of the "worker" can be accessed directly. Supported methods are:
- multi_env.reset
- multi_env.step
- multi_env.close
That have similar behaviour to "env.step", "env.close" or "env.reset".
It can be used the following manner.
# initiliaze some variable with the proper dimension
obss = multi_envs.reset()
rews = [env.reward_range[0] for i in range(NUM_CORE)]
dones = [False for i in range(NUM_CORE)]
obss
array([<grid2op.Space.GridObjects.CompleteObservation_rte_case14_realistic object at 0x7f779daeecd0>,
<grid2op.Space.GridObjects.CompleteObservation_rte_case14_realistic object at 0x7f779daeed30>],
dtype=object)
dones
[False, False]
As you can see, obs is not a single obervation, but a list (numpy nd array to be precise) of 4 observations, each one being an observation of a given "worker" environment.
Worker environments are always called in the same order. It means the first observation of this vector will always correspond to the first worker environment.
Similarly to Observation, the "step" function of a multi_environment takes as input a list of multiple actions, each action will be implemented in its own environment. It returns a list of observations, a list of rewards, and boolean list of whether or not the worker environment suffer from a game over (in that case this worker environment is automatically restarted using the "reset" method.)
Because orker environments are always called in the same order, the first action sent to the "multi_env.step" function will also be applied on this first environment.
It is possible to use it as follow:
# initialize the vector of actions that will be processed by each worker environment.
acts = [None for _ in range(NUM_CORE)]
for env_act_id in range(NUM_CORE):
acts[env_act_id] = agent.act(obss[env_act_id], rews[env_act_id], dones[env_act_id])
# feed them to the multi_env
obss, rews, dones, infos = multi_envs.step(acts)
# as explained, this is a vector of Observation (as many as NUM_CORE in this example)
obss
array([<grid2op.Space.GridObjects.CompleteObservation_rte_case14_realistic object at 0x7f779da71100>,
<grid2op.Space.GridObjects.CompleteObservation_rte_case14_realistic object at 0x7f779da71160>],
dtype=object)
The multi environment loop is really close to the "gym" loop:
# performs the appropriated steps
for i in range(10):
acts = [None for _ in range(NUM_CORE)]
for env_act_id in range(NUM_CORE):
acts[env_act_id] = agent.act(obss[env_act_id], rews[env_act_id], dones[env_act_id])
obss, rews, dones, infos = multi_envs.step(acts)
# DO SOMETHING WITH THE AGENT IF YOU WANT
## agent.train(obss, rews, dones)
# close the environments created by the multi_env
multi_envs.close()
On the above example, TRAINING_STEP steps are performed on NUM_CORE environments in parrallel. The agent has then acted TRAINING_STEP * NUM_CORE (=10 * 4 = 40 by default) times on NUM_CORE different environments.
III.b) Practical example¶
We reuse the code of the Notebook 4_TrainingAnAgent to train a new agent we strongly recommend you to have a look at it if it is not done already.
In this notebook, We focus on how to make your agent interact wil multiple environment at the same time (eg it means that the batch of data he receives comes from different instance of the same environment, this is a technique used in Asynchronous Actor Critic - A3C type of models for example).
You will see with this method you can, with minimal (actually without any) changes, learn the same baseline this way.
Note on the implementation¶
The most common code for A3C agent can be summarize in the image below (image credit this blog post):
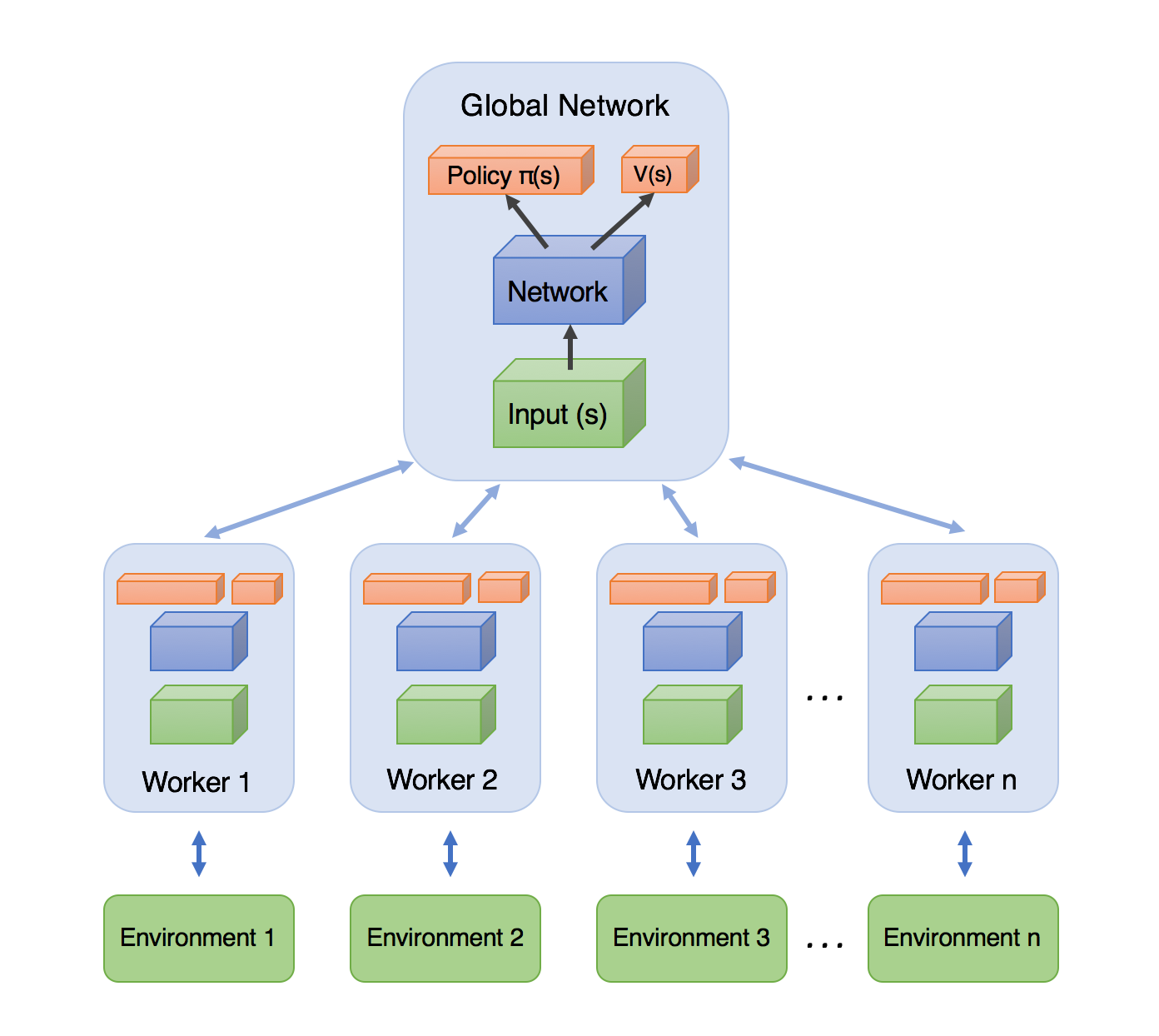
In this image you see different version of the agent that interacts with different versions of the (same) environment (represented here in the different workers). And, from time to time, each "worker" will send its weights to the "global network" and an update procedure will be run there. Though this framework can perfectly be implemented in grid2op, the SingleEnvMultiProcess class work a bit differently.
Actually, in this SingleEnvMultiProcess class, there exists only one copy of the "global network" that is kept into the main "thread" (which to be precise is a process) and that interacts (send actions to and receives observations from) with different independant environments. It is really similar to the SubprocVecEnv of open ai gym.
This is especially suited in the case of powersystem operations, as it can be quite computationnally expensive to solve for the powerflow equations at each nodes of the grid (also called Kirchhoff's laws)
What you have to do¶
We recall here the code that we used in the relevant notebook to train the agent:
# create an environment
env = make(env_name, test=True)
# don't forget to set "test=False" (or remove it, as False is the default value) for "real" training
# import the train function and train your agent
from l2rpn_baselines.DuelQSimple import train
from l2rpn_baselines.utils import NNParam, TrainingParam
agent_name = "test_agent"
save_path = "saved_agent_DDDQN_{}".format(train_iter)
logs_dir="tf_logs_DDDQN"
# we then define the neural network we want to make (you may change this at will)
## 1. first we choose what "part" of the observation we want as input,
## here for example only the generator and load information
## see https://grid2op.readthedocs.io/en/latest/observation.html#main-observation-attributes
## for the detailed about all the observation attributes you want to have
li_attr_obs_X = ["prod_p", "prod_v", "load_p", "load_q"]
# this automatically computes the size of the resulting vector
observation_size = NNParam.get_obs_size(env, li_attr_obs_X)
## 2. then we define its architecture
sizes = [300, 300, 300] # 3 hidden layers, of 300 units each, why not...
activs = ["relu" for _ in sizes] # all followed by relu activation, because... why not
## 4. you put it all on a dictionnary like that (specific to this baseline)
kwargs_archi = {'observation_size': observation_size,
'sizes': sizes,
'activs': activs,
"list_attr_obs": li_attr_obs_X}
# you can also change the training parameters you are using
# more information at https://l2rpn-baselines.readthedocs.io/en/latest/utils.html#l2rpn_baselines.utils.TrainingParam
tp = TrainingParam()
tp.batch_size = 32 # for example...
tp.update_tensorboard_freq = int(train_iter / 10)
tp.save_model_each = int(train_iter / 3)
tp.min_observation = int(train_iter / 5)
train(env,
name=agent_name,
iterations=train_iter,
save_path=save_path,
load_path=None, # put something else if you want to reload an agent instead of creating a new one
logs_dir=logs_dir,
kwargs_archi=kwargs_archi,
training_param=tp)
Here, you will see in the next cell how to (not really) change it to train a agent on different environments:
train_iter = TRAINING_STEP
# import the train function and train your agent
from l2rpn_baselines.DuelQSimple import train
from l2rpn_baselines.utils import NNParam, TrainingParam, make_multi_env
agent_name = "test_agent_multi"
save_path = "saved_agent_DDDQN_{}_multi".format(train_iter)
logs_dir="tf_logs_DDDQN"
# just add the relevant import (see above) and this line
my_envs = make_multi_env(env_init=env, nb_env=NUM_CORE)
# and that's it !
# we then define the neural network we want to make (you may change this at will)
## 1. first we choose what "part" of the observation we want as input,
## here for example only the generator and load information
## see https://grid2op.readthedocs.io/en/latest/observation.html#main-observation-attributes
## for the detailed about all the observation attributes you want to have
li_attr_obs_X = ["prod_p", "prod_v", "load_p", "load_q"]
# this automatically computes the size of the resulting vector
observation_size = NNParam.get_obs_size(env, li_attr_obs_X)
## 2. then we define its architecture
sizes = [300, 300, 300] # 3 hidden layers, of 300 units each, why not...
activs = ["relu" for _ in sizes] # all followed by relu activation, because... why not
## 4. you put it all on a dictionnary like that (specific to this baseline)
kwargs_archi = {'observation_size': observation_size,
'sizes': sizes,
'activs': activs,
"list_attr_obs": li_attr_obs_X}
# you can also change the training parameters you are using
# more information at https://l2rpn-baselines.readthedocs.io/en/latest/utils.html#l2rpn_baselines.utils.TrainingParam
tp = TrainingParam()
tp.batch_size = 32 # for example...
tp.update_tensorboard_freq = int(train_iter / 10)
tp.save_model_each = int(train_iter / 3)
tp.min_observation = int(train_iter / 5)
train(my_envs,
name=agent_name,
iterations=train_iter,
save_path=save_path,
load_path=None, # put something else if you want to reload an agent instead of creating a new one
logs_dir=logs_dir,
kwargs_archi=kwargs_archi,
training_param=tp)
/home/benjamin/Documents/l2rpn-baselines/l2rpn_baselines/utils/DeepQAgent.py:412: UserWarning: Training using 2 environments 100%|██████████| 100/100 [00:06<00:00, 14.36it/s]
II c) Assess the performance of the trained agent¶
Nothing is changing... Like really, it's the same code as in notebook 4 (we told you to have a look ;-) )
from l2rpn_baselines.DuelQSimple import evaluate
path_save_results = "{}_results_multi".format(save_path)
evaluated_agent, res_runner = evaluate(env,
name=agent_name,
load_path=save_path,
logs_path=path_save_results,
nb_episode=2,
nb_process=1,
max_steps=100,
verbose=True,
save_gif=False)
WARNING:tensorflow:No training configuration found in the save file, so the model was *not* compiled. Compile it manually.
episode: 0%| | 0/2 [00:00<?, ?it/s]
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
observation (InputLayer) [(None, 32)] 0
__________________________________________________________________________________________________
layer_0 (Dense) (None, 300) 9900 observation[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 300) 0 layer_0[0][0]
__________________________________________________________________________________________________
layer_1 (Dense) (None, 300) 90300 activation[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 300) 0 layer_1[0][0]
__________________________________________________________________________________________________
layer_2 (Dense) (None, 300) 90300 activation_1[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 300) 0 layer_2[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 451) 135751 activation_2[0][0]
__________________________________________________________________________________________________
advantage (Dense) (None, 451) 203852 dense[0][0]
__________________________________________________________________________________________________
lambda (Lambda) (None,) 0 advantage[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 451) 135751 activation_2[0][0]
__________________________________________________________________________________________________
subtract (Subtract) (None, 451) 0 advantage[0][0]
lambda[0][0]
__________________________________________________________________________________________________
value (Dense) (None, 1) 452 dense_1[0][0]
__________________________________________________________________________________________________
policy (Add) (None, 451) 0 subtract[0][0]
value[0][0]
==================================================================================================
Total params: 666,306
Trainable params: 666,306
Non-trainable params: 0
__________________________________________________________________________________________________
INFO: "Sequential runner used."
episode: 0%| | 0/100 [00:00<?, ?it/s] episode: 3%|▎ | 3/100 [00:00<00:03, 25.74it/s]
INFO: "Creating path "/home/benjamin/Documents/grid2op_dev/getting_started/saved_agent_DDDQN_100_multi_results_multi/000" to save the episode 000"
episode: 7%|▋ | 7/100 [00:00<00:03, 27.20it/s] episode: 11%|█ | 11/100 [00:00<00:03, 28.34it/s] episode: 14%|█▍ | 14/100 [00:00<00:03, 28.22it/s] episode: 18%|█▊ | 18/100 [00:00<00:02, 29.59it/s] episode: 22%|██▏ | 22/100 [00:00<00:02, 30.53it/s] episode: 26%|██▌ | 26/100 [00:00<00:02, 30.82it/s] episode: 30%|███ | 30/100 [00:00<00:02, 31.28it/s] episode: 34%|███▍ | 34/100 [00:01<00:02, 31.64it/s] episode: 38%|███▊ | 38/100 [00:01<00:01, 31.51it/s] episode: 42%|████▏ | 42/100 [00:01<00:01, 31.34it/s] episode: 46%|████▌ | 46/100 [00:01<00:01, 29.73it/s] episode: 49%|████▉ | 49/100 [00:01<00:01, 29.61it/s] episode: 52%|█████▏ | 52/100 [00:01<00:01, 29.58it/s] episode: 55%|█████▌ | 55/100 [00:01<00:01, 29.55it/s] episode: 58%|█████▊ | 58/100 [00:01<00:01, 28.56it/s] episode: 62%|██████▏ | 62/100 [00:02<00:01, 29.90it/s] episode: 66%|██████▌ | 66/100 [00:02<00:01, 29.60it/s] episode: 69%|██████▉ | 69/100 [00:02<00:01, 28.58it/s] episode: 73%|███████▎ | 73/100 [00:02<00:00, 29.35it/s] episode: 77%|███████▋ | 77/100 [00:02<00:00, 30.00it/s] episode: 81%|████████ | 81/100 [00:02<00:00, 30.54it/s] episode: 85%|████████▌ | 85/100 [00:02<00:00, 30.86it/s] episode: 89%|████████▉ | 89/100 [00:02<00:00, 30.09it/s] episode: 93%|█████████▎| 93/100 [00:03<00:00, 29.76it/s] episode: 100%|██████████| 100/100 [00:03<00:00, 30.11it/s][A episode: 50%|█████ | 1/2 [00:03<00:03, 3.81s/it] episode: 0%| | 0/100 [00:00<?, ?it/s]
INFO: "Env: 1.77s - apply act 0.29s - run pf: 1.45s - env update + observation: 0.03s Agent: 1.49s Total time: 3.32s Cumulative reward: 122875.406250" INFO: "Creating path "/home/benjamin/Documents/grid2op_dev/getting_started/saved_agent_DDDQN_100_multi_results_multi/001" to save the episode 001"
episode: 3%|▎ | 3/100 [00:00<00:03, 28.92it/s] episode: 6%|▌ | 6/100 [00:00<00:03, 28.84it/s] episode: 10%|█ | 10/100 [00:00<00:02, 30.03it/s] episode: 14%|█▍ | 14/100 [00:00<00:02, 30.38it/s] episode: 18%|█▊ | 18/100 [00:00<00:02, 30.94it/s] episode: 22%|██▏ | 22/100 [00:00<00:02, 31.22it/s] episode: 26%|██▌ | 26/100 [00:00<00:02, 31.71it/s] episode: 30%|███ | 30/100 [00:00<00:02, 32.05it/s] episode: 34%|███▍ | 34/100 [00:01<00:02, 25.39it/s] episode: 38%|███▊ | 38/100 [00:01<00:02, 27.39it/s] episode: 42%|████▏ | 42/100 [00:01<00:02, 28.63it/s] episode: 46%|████▌ | 46/100 [00:01<00:01, 30.12it/s] episode: 50%|█████ | 50/100 [00:01<00:01, 30.14it/s] episode: 54%|█████▍ | 54/100 [00:01<00:01, 31.00it/s] episode: 58%|█████▊ | 58/100 [00:01<00:01, 31.36it/s] episode: 62%|██████▏ | 62/100 [00:02<00:01, 31.83it/s] episode: 66%|██████▌ | 66/100 [00:02<00:01, 32.41it/s] episode: 70%|███████ | 70/100 [00:02<00:00, 32.26it/s] episode: 74%|███████▍ | 74/100 [00:02<00:00, 32.84it/s] episode: 78%|███████▊ | 78/100 [00:02<00:00, 33.31it/s] episode: 82%|████████▏ | 82/100 [00:02<00:00, 33.35it/s] episode: 86%|████████▌ | 86/100 [00:02<00:00, 32.85it/s] episode: 90%|█████████ | 90/100 [00:02<00:00, 32.39it/s] episode: 94%|█████████▍| 94/100 [00:03<00:00, 31.31it/s] episode: 100%|██████████| 100/100 [00:03<00:00, 31.05it/s][A episode: 100%|██████████| 2/2 [00:07<00:00, 3.61s/it]
INFO: "Env: 1.66s - apply act 0.27s - run pf: 1.36s - env update + observation: 0.02s Agent: 1.50s Total time: 3.22s Cumulative reward: 122950.523438" Evaluation summary: chronics at: 000 total score: 122875.406250 time steps: 100/100 chronics at: 001 total score: 122950.523438 time steps: 100/100 The agent played 1 different action Action with ID 350 was played 200 times This action will: - NOT change anything to the injections - NOT perform any redispatching action - NOT force any line status - NOT switch any line status - Change the bus of the following element: - switch bus of line (extremity) 4 [on substation 4] - NOT force any particular bus configuration -----------
II d) That is it ?¶
Yes there is nothing more to say about it. As long as you use one of the compatible baselines (at the date of writing):
You will not anything more to do :-)
If you want to use another baseline that does not support this feature, feel free to add an issue in the l2rpn-baselines official github at this adress https://github.com/rte-france/l2rpn-baselines/issues