This notebook present the most basic use of Grid2Op¶
Objectives
This notebook will cover some basic raw functionality at first. It will then show how these raw functionalities are encapsulated with easy to use functions.
The recommended way to use these is to through the Runner, and not by getting through the instanciation of class one by one.
import os
import sys
import grid2op
res = None
try:
from jyquickhelper import add_notebook_menu
res = add_notebook_menu()
except ModuleNotFoundError:
print("Impossible to automatically add a menu / table of content to this notebook.\nYou can download \"jyquickhelper\" package with: \n\"pip install jyquickhelper\"")
res
0) Summary of RL method¶
Though the Grid2Op package can be used to perform many different tasks, these set of notebooks will be focused on the machine learning part, and its usage in a Reinforcement learning framework.
The reinforcement learning is a framework that allows to train "agent" to solve time dependant domain. We tried to cast the grid operation planning into this framework. The package Grid2Op was inspired by it.
In a reinforcement learning (RL), there are 2 distinct entities:
- Environment: is a modeling of the "world" in which the agent takes some actions to achieve some pre definite objectives.
- Agent: will do actions on the environment that will have consequences.
These 2 entities exchange 3 main type of information:
- Action: it's an information sent by the Agent that will modify the internal state of the environment.
- State / Observation: is the (partial) view of the environment by the Agent. The Agent receive a new state after each actions. He can use the observation (state) at time step t to take the action at time t.
- Reward: is the score received by the agent for the previous action.
A schematic representaiton of this is shown in the figure bellow (Credit: Sutton & Barto):
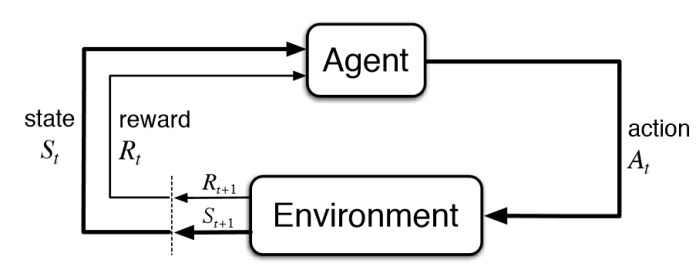
In this notebook, we will develop a simple Agent that takes some action (powerline disconnection) based on the observation of the environment.
For more information about the problem, please visit the Example_5bus notebook which dive more into the casting of the real time operation planning into a RL framework. Note that this notebook is still under development at the moment.
A good material is also provided in the white paper Reinforcement Learning for Electricity Network Operation presented for the L2RPN 2020 Neurips edition.
I) Creating an Environment¶
I.A) Default settings¶
We provide a one function call that will handle the creation of the Environment with default values.
In this example we will use the rte_case14_redisp. In a testing environment setting.
To define/create it, we can call:
env = grid2op.make("rte_case14_redisp", test=True)
/home/tezirg/Code/Grid2Op.BDonnot/getting_started/grid2op/MakeEnv/Make.py:223: UserWarning: You are using a development environment. This environment is not intended for training agents. warnings.warn(_MAKE_DEV_ENV_WARN)
NB By setting "test=True" in the above call, we use only 2 different months or for our environment. If you remove it, grid2op.make will attempt to download more data. By default data corresponding to this environment will be downloaded in your "home" directory, which correspond to the location returned by this script:
import os
print(f"grid2op dataset will be downloaded in {os.path.expanduser('~/data_grid2op')}")
If you want another default saving path, you can add a .grid2opconfig.json and specify where to download the data.
Only 4 environment are available locally when you install grid2op:
rte_case5_example, only available locally, its main goal is to provide example on really small system that people can really study manually and have intuitions on it.rte_case14_test, only available locally, its main goal is to be used inside unit test of grid2op. It is NOT recommended to use it.rte_case14_redispan environment based on the IEEE case14 files, which introduces the redispatching. Only 2 dataset are available for this environment. More can be downloaded automatically by specifying "local=False" [default value of argument "local"]rte_case14_realistican environment "realistic" based on the same grid which has been adapted to be closer to "real" grid. More can be downloaded automatically by specifying "local=False" [default value of argument "local"]
Other environments can be used and are available through the "make" command, to get a list of the possible environments you can do:
grid2op.list_available_remote_env() # this only works if you have an internet connection
['l2rpn_2019', 'l2rpn_case14_sandbox', 'rte_case14_realistic', 'rte_case14_redisp']
And it's also possible to list the environments you have already downloaded (if any). NB we remind that downloading is automatic and is done the first time you call "make" with an environment that has not been already locally downloaded.
grid2op.list_available_local_env()
['rte_case14_realistic', 'rte_case14_redisp', 'l2rpn_2019']
I.B) Custom settings¶
Using the make function you pass additional arguments to customize the environment (useful for training):
param: Parameters used for the Environment.grid2op.Parameters.Parametersbackend: The backend to use for the computation. If provided, it must be an instance of classgrid2op.Backend.Backend.action_class: Type of BaseAction the BaseAgent will be able to perform. If provided, it must be a subclass ofgrid2op.BaseAction.BaseActionobservation_class: Type of BaseObservation the BaseAgent will receive. If provided, It must be a subclass ofgrid2op.BaseAction.BaseObservationreward_class: Type of reward signal the BaseAgent will receive. If provided, It must be a subclass ofgrid2op.BaseReward.BaseRewardgamerules_class: Type of "Rules" the BaseAgent need to comply with. Rules are here to model some operational constraints. If provided, It must be a subclass ofgrid2op.RulesChecker.BaseRulesdata_feeding_kwargs: Dictionnary that is used to build thedata_feeding(chronics) objects.chronics_class: The type of chronics that represents the dynamics of the Environment created. Usually they come from different folders.data_feeding: The type of chronics handler you want to use.volagecontroler_class: The type ofgrid2op.VoltageControler.VoltageControlerto usechronics_path: Path where to look for the chronics dataset (optional)grid_path: The path where the powergrid is located. If provided it must be a string, and point to a valid file present on the hard drive.
For example, to set the number of substation changes allowed per step:
from grid2op.Parameters import Parameters
custom_params = Parameters()
custom_params.MAX_SUB_CHANGED = 1
env = grid2op.make("rte_case14_redisp", param=custom_params, test=True)
/home/tezirg/Code/Grid2Op.BDonnot/getting_started/grid2op/MakeEnv/Make.py:223: UserWarning: You are using a development environment. This environment is not intended for training agents. warnings.warn(_MAKE_DEV_ENV_WARN)
NB The function "make" is highly customizable. For example, you can change the reward you are using:
from grid2op.Reward import L2RPNReward
env = grid2op.make(reward_class=L2RPNReward)
We also gave the possibility to assess different rewards. This can be done with the following code:
from grid2op.Reward import L2RPNReward, FlatReward
env = grid2op.make(reward_class=L2RPNReward,
other_rewards={"other_reward" : FlatReward })
These result of these reward can be accessed in the "info" return value of the call to env.step. See the official document of reward here for more information.
II) Creating an Agent¶
An Agent is the name given to the "operator" / "bot" / "algorithm" that will perform some modification of the powergrid when he faces some "observation".
Some example of Agents are provided in the file Agent.py.
A deeper look at the different Agent provided can be found in the 4_StudyYourAgent notebook. We suppose here we use the most simple Agent, the one that does nothing
from grid2op.Agent import DoNothingAgent
my_agent = DoNothingAgent(env.helper_action_player)
III) Assess how the Agent is performing¶
The performance of each Agent is assessed with the reward. For this example, the reward is a FlatReward that just computes how many times step the Agent has sucessfully managed before breaking any rules. For more control on this reward, it is recommended to use look at the document of the Environment class.
More example of rewards are also available on the official document or here.
done = False
time_step = int(0)
cum_reward = 0.
obs = env.reset()
reward = env.reward_range[0]
max_iter = 10
while not done:
act = my_agent.act(obs, reward, done) # chose an action to do, in this case "do nothing"
obs, reward, done, info = env.step(act) # implement this action on the powergrid
cum_reward += reward
time_step += 1
if time_step > max_iter:
break
We can now evaluate how well this agent is performing:
print("This agent managed to survive {} timesteps".format(time_step))
print("It's final cumulated reward is {}".format(cum_reward))
This agent managed to survive 11 timesteps It's final cumulated reward is 12072.310007859756
IV) More convenient ways to asses an agent¶
All the above steps have been detailed as a "quick start", to give an example of the main classes of the Grid2Op package. Having to code all the above is quite tedious, but offers a lot of flexibility.
Implementing all this before starting to evaluate an agent can be quite tedious. What we expose here is a much shorter way to perfom all of the above. In this section we will expose 2 ways:
- The quickest way, using the grid2op.main API, most suited when basic computations need to be carried out.
- The recommended way using a Runner, it gives more flexibilities than the grid2op.main API but can be harder to configure.
For this section, we assume the same as before:
- The Agent is "Do Nothing"
- The Environment is the default Environment
- PandaPower is used as the backend
- The chronics comes from the files included in this package
- etc.
IV.A) Using the grid2op.runner API¶
When only simple assessment need to be performed, the grid2op.main API is perfectly suited. This API can also be access with the command line:
python3 -m grid2op.main
We detail here its usage as an API, to assess the performance of a given Agent.
As opposed to building en environment from scratch (see the previous section) this requires much less effort: we don't need to initialize (instanciate) anything. All is carried out inside the Runner called by the main function.
We ask here 1 episode (eg. we play one scenario until: either the agent does a game over, or until the scenario ends). But this method would work as well if we more.
from grid2op.Runner import Runner
runner = Runner(**env.get_params_for_runner(), agentClass=DoNothingAgent)
res = runner.run(nb_episode=1, max_iter=max_iter)
A call of the single 2 lines above will:
- Create a valid environment
- Create a valid agent
- Assess how well an agent performs on one episode.
print("The results are:")
for chron_name, _, cum_reward, nb_time_step, max_ts in res:
msg_tmp = "\tFor chronics located at {}\n".format(chron_name)
msg_tmp += "\t\t - cumulative reward: {:.2f}\n".format(cum_reward)
msg_tmp += "\t\t - number of time steps completed: {:.0f} / {:.0f}".format(nb_time_step, max_ts)
print(msg_tmp)
The results are: For chronics located at /home/tezirg/Code/Grid2Op.BDonnot/getting_started/grid2op/data/rte_case14_redisp/chronics/0 - cumulative reward: 10948.05 - number of time steps completed: 10 / 10
This is particularly suited to evaluate different agents, for example we can quickly evaluate a second agent. For the below example, we can import an agent class PowerLineSwitch whose job is to connect and disconnect the power lines in the power network. This PowerLineSwitch Agent will simulate the effect of disconnecting each powerline on the powergrid and take the best action found (its execution can take a long time, depending on the scenario and the amount of powerlines on the grid). The execution of the code below can take a few moments
from grid2op.Agent import PowerLineSwitch
runner = Runner(**env.get_params_for_runner(), agentClass=PowerLineSwitch)
res = runner.run(nb_episode=1, max_iter=max_iter)
print("The results are:")
for chron_name, _, cum_reward, nb_time_step, max_ts in res:
msg_tmp = "\tFor chronics located at {}\n".format(chron_name)
msg_tmp += "\t\t - cumulative reward: {:.2f}\n".format(cum_reward)
msg_tmp += "\t\t - number of time steps completed: {:.0f} / {:.0f}".format(nb_time_step, max_ts)
print(msg_tmp)
The results are: For chronics located at /home/tezirg/Code/Grid2Op.BDonnot/getting_started/grid2op/data/rte_case14_redisp/chronics/0 - cumulative reward: 10950.26 - number of time steps completed: 10 / 10
Using this API it's also possible to store the results for a detailed examination of the aciton taken by the Agent. Note that writing on the hard drive has an overhead on the computation time.
To do this, only a simple argument need to be added to the main function call. An example can be found below (where the outcome of the experiment will be stored in the saved_experiment_donothing directory):
runner = Runner(**env.get_params_for_runner(),
agentClass=PowerLineSwitch
)
res = runner.run(nb_episode=1, max_iter=max_iter, path_save=os.path.abspath("saved_experiment_donothing"))
print("The results are:")
for chron_name, _, cum_reward, nb_time_step, max_ts in res:
msg_tmp = "\tFor chronics located at {}\n".format(chron_name)
msg_tmp += "\t\t - cumulative reward: {:.2f}\n".format(cum_reward)
msg_tmp += "\t\t - number of time steps completed: {:.0f} / {:.0f}".format(nb_time_step, max_ts)
print(msg_tmp)
The results are: For chronics located at /home/tezirg/Code/Grid2Op.BDonnot/getting_started/grid2op/data/rte_case14_redisp/chronics/0 - cumulative reward: 10950.26 - number of time steps completed: 10 / 10
!ls saved_experiment_donothing/0
actions.npy episode_meta.json _parameters.json agent_exec_times.npy episode_times.json rewards.npy disc_lines_cascading_failure.npy observations.npy env_modifications.npy other_rewards.json
All the informations saved are showed above. For more information about them, please don't hesitate to read the documentation of Runner.
NB A lot more of informations about Action is provided in the 2_Action_GridManipulation notebook. In the 3_TrainingAnAgent there is an quick example on how to read / write action from a saved repository.
In the notebook 7 more details are given as for the advantages of the runner, especially for post analysis of the agent performances.
The use of make + runner makes it easy to assess the performance of trained agent. Beside, Runner has been particularly integrated with other tools and makes easy the replay / post analysis of the episode. It is the recommended method to use in grid2op for evaluation.