In [1]:
import parallel as para
import NeuroDataResource as ndr
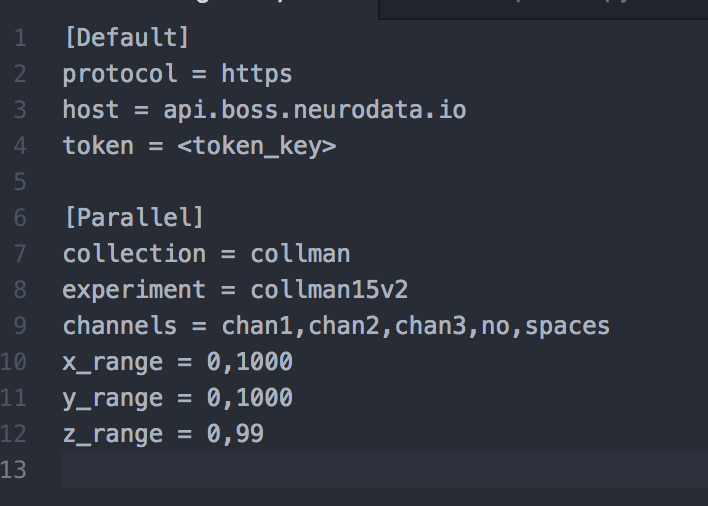
1. Change parameters in neurodata.cfg file.¶
Note: channels list should not be separated by spaces, just commas!
In [2]:
config_file = "neurodata.cfg"
resource = ndr.get_boss_resource(config_file)
2. Specify function to be run in file. Must accept a data dictionary as input¶
Data dictionary: key is channel, value is numpy array
In [ ]:
def pipeline(input_data, verbose=False):
data = format_data(input_data)
if verbose:
print('Normalizing Data')
normed_data = normalize_data(data)
if verbose:
print('Generating Covariance Map')
cov_map = compute_convolutional_cov(normed_data[0],
normed_data[1],
(3, 3, 3))
if verbose:
print('Binarizing Covariance Map')
predictions = predict_from_feature_map(cov_map)
if verbose:
print('Pruning Predictions')
filtered_predictions = remove_low_volume_predictions(predictions, 30)
return filtered_predictions
3. Now to run on multiple cores, just provide the module path and function that you want to run in parallel¶
For this demo:¶
We will import the module nomads and run the function pipeline in the code. For the actual script, you can just provide the module name and function name as arguments when running the parallel script.
In [3]:
from importlib import import_module
mod = import_module("nomads")
function = getattr(mod, "pipeline")
para.run_parallel(config_file, function = function)
Starting job, retrieiving data Starting algorithm Done with job ['0_0_0']
This next part shows that you can hotswap algorithms.¶
We will be calling the dummy module with the dummy function that
In [4]:
mod = import_module("dummy")
function = getattr(mod, "dummy")
para.run_parallel(config_file, function = function)
Starting job, retrieiving data Starting algorithm Hi, hi, hi Done with job ['0_0_0']
In [ ]: