Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.
- Author: Sebastian Raschka
- GitHub Repository: https://github.com/rasbt/deeplearning-models
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
Sebastian Raschka CPython 3.7.3 IPython 7.9.0 torch 1.3.1
LeNet-5 CIFAR10 Classifier¶
This notebook implements the classic LeNet-5 convolutional network [1] and applies it to the CIFAR10 object classification dataset. The basic architecture is shown in the figure below:
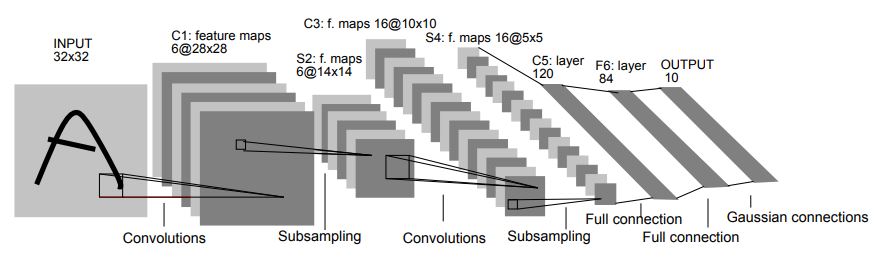
LeNet-5 is commonly regarded as the pioneer of convolutional neural networks, consisting of a very simple architecture (by modern standards). In total, LeNet-5 consists of only 7 layers. 3 out of these 7 layers are convolutional layers (C1, C3, C5), which are connected by two average pooling layers (S2 & S4). The penultimate layer is a fully connexted layer (F6), which is followed by the final output layer. The additional details are summarized below:
- All convolutional layers use 5x5 kernels with stride 1.
- The two average pooling (subsampling) layers are 2x2 pixels wide with stride 1.
- Throughrout the network, tanh sigmoid activation functions are used. (In this notebook, we replace these with ReLU activations)
- The output layer uses 10 custom Euclidean Radial Basis Function neurons for the output layer. (In this notebook, we replace these with softmax activations)
Please note that the original architecture was applied to MNIST-like grayscale images (1 color channel). CIFAR10 has 3 color-channels. I found that using the regular architecture results in very poor performance on CIFAR10 (approx. 50% ACC). Hence, I am multiplying the number of kernels by a factor of 3 (according to the 3 color channels) in each layer, which improves is a little bit (approx. 60% Acc).
References¶
- [1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
Imports¶
import os
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
Model Settings¶
##########################
### SETTINGS
##########################
# Hyperparameters
RANDOM_SEED = 1
LEARNING_RATE = 0.001
BATCH_SIZE = 128
NUM_EPOCHS = 10
# Architecture
NUM_FEATURES = 32*32
NUM_CLASSES = 10
# Other
DEVICE = "cuda:0"
GRAYSCALE = False
MNIST Dataset¶
##########################
### CIFAR-10 Dataset
##########################
# Note transforms.ToTensor() scales input images
# to 0-1 range
train_dataset = datasets.CIFAR10(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.CIFAR10(root='data',
train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
num_workers=8,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
num_workers=8,
shuffle=False)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
Files already downloaded and verified Image batch dimensions: torch.Size([128, 3, 32, 32]) Image label dimensions: torch.Size([128]) Image batch dimensions: torch.Size([128, 3, 32, 32]) Image label dimensions: torch.Size([128])
device = torch.device(DEVICE)
torch.manual_seed(0)
for epoch in range(2):
for batch_idx, (x, y) in enumerate(train_loader):
print('Epoch:', epoch+1, end='')
print(' | Batch index:', batch_idx, end='')
print(' | Batch size:', y.size()[0])
x = x.to(device)
y = y.to(device)
break
Epoch: 1 | Batch index: 0 | Batch size: 128 Epoch: 2 | Batch index: 0 | Batch size: 128
##########################
### MODEL
##########################
class LeNet5(nn.Module):
def __init__(self, num_classes, grayscale=False):
super(LeNet5, self).__init__()
self.grayscale = grayscale
self.num_classes = num_classes
if self.grayscale:
in_channels = 1
else:
in_channels = 3
self.features = nn.Sequential(
nn.Conv2d(in_channels, 6*in_channels, kernel_size=5),
nn.Tanh(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6*in_channels, 16*in_channels, kernel_size=5),
nn.Tanh(),
nn.MaxPool2d(kernel_size=2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5*in_channels, 120*in_channels),
nn.Tanh(),
nn.Linear(120*in_channels, 84*in_channels),
nn.Tanh(),
nn.Linear(84*in_channels, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
logits = self.classifier(x)
probas = F.softmax(logits, dim=1)
return logits, probas
torch.manual_seed(RANDOM_SEED)
model = LeNet5(NUM_CLASSES, GRAYSCALE)
model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
Training¶
def compute_accuracy(model, data_loader, device):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, NUM_EPOCHS, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%%' % (
epoch+1, NUM_EPOCHS,
compute_accuracy(model, train_loader, device=DEVICE)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/010 | Batch 0000/0391 | Cost: 2.3068 Epoch: 001/010 | Batch 0050/0391 | Cost: 1.8193 Epoch: 001/010 | Batch 0100/0391 | Cost: 1.6464 Epoch: 001/010 | Batch 0150/0391 | Cost: 1.5757 Epoch: 001/010 | Batch 0200/0391 | Cost: 1.4026 Epoch: 001/010 | Batch 0250/0391 | Cost: 1.3116 Epoch: 001/010 | Batch 0300/0391 | Cost: 1.3310 Epoch: 001/010 | Batch 0350/0391 | Cost: 1.2781 Epoch: 001/010 | Train: 54.326% Time elapsed: 0.16 min Epoch: 002/010 | Batch 0000/0391 | Cost: 1.4109 Epoch: 002/010 | Batch 0050/0391 | Cost: 1.3039 Epoch: 002/010 | Batch 0100/0391 | Cost: 1.2601 Epoch: 002/010 | Batch 0150/0391 | Cost: 1.3187 Epoch: 002/010 | Batch 0200/0391 | Cost: 1.2844 Epoch: 002/010 | Batch 0250/0391 | Cost: 1.3451 Epoch: 002/010 | Batch 0300/0391 | Cost: 1.1971 Epoch: 002/010 | Batch 0350/0391 | Cost: 1.1474 Epoch: 002/010 | Train: 60.528% Time elapsed: 0.31 min Epoch: 003/010 | Batch 0000/0391 | Cost: 1.1268 Epoch: 003/010 | Batch 0050/0391 | Cost: 1.1943 Epoch: 003/010 | Batch 0100/0391 | Cost: 1.3056 Epoch: 003/010 | Batch 0150/0391 | Cost: 1.0215 Epoch: 003/010 | Batch 0200/0391 | Cost: 1.0243 Epoch: 003/010 | Batch 0250/0391 | Cost: 0.7985 Epoch: 003/010 | Batch 0300/0391 | Cost: 1.0755 Epoch: 003/010 | Batch 0350/0391 | Cost: 1.1030 Epoch: 003/010 | Train: 64.586% Time elapsed: 0.46 min Epoch: 004/010 | Batch 0000/0391 | Cost: 1.1329 Epoch: 004/010 | Batch 0050/0391 | Cost: 1.0834 Epoch: 004/010 | Batch 0100/0391 | Cost: 1.0509 Epoch: 004/010 | Batch 0150/0391 | Cost: 0.9873 Epoch: 004/010 | Batch 0200/0391 | Cost: 0.8560 Epoch: 004/010 | Batch 0250/0391 | Cost: 1.1286 Epoch: 004/010 | Batch 0300/0391 | Cost: 0.8377 Epoch: 004/010 | Batch 0350/0391 | Cost: 1.1735 Epoch: 004/010 | Train: 66.656% Time elapsed: 0.61 min Epoch: 005/010 | Batch 0000/0391 | Cost: 1.1260 Epoch: 005/010 | Batch 0050/0391 | Cost: 0.8605 Epoch: 005/010 | Batch 0100/0391 | Cost: 0.9007 Epoch: 005/010 | Batch 0150/0391 | Cost: 0.9166 Epoch: 005/010 | Batch 0200/0391 | Cost: 0.9488 Epoch: 005/010 | Batch 0250/0391 | Cost: 1.0388 Epoch: 005/010 | Batch 0300/0391 | Cost: 0.9526 Epoch: 005/010 | Batch 0350/0391 | Cost: 0.9109 Epoch: 005/010 | Train: 71.504% Time elapsed: 0.76 min Epoch: 006/010 | Batch 0000/0391 | Cost: 0.7038 Epoch: 006/010 | Batch 0050/0391 | Cost: 0.6849 Epoch: 006/010 | Batch 0100/0391 | Cost: 0.6817 Epoch: 006/010 | Batch 0150/0391 | Cost: 0.8213 Epoch: 006/010 | Batch 0200/0391 | Cost: 0.7984 Epoch: 006/010 | Batch 0250/0391 | Cost: 0.9680 Epoch: 006/010 | Batch 0300/0391 | Cost: 0.7650 Epoch: 006/010 | Batch 0350/0391 | Cost: 0.9355 Epoch: 006/010 | Train: 74.812% Time elapsed: 0.91 min Epoch: 007/010 | Batch 0000/0391 | Cost: 0.8488 Epoch: 007/010 | Batch 0050/0391 | Cost: 0.8332 Epoch: 007/010 | Batch 0100/0391 | Cost: 0.6777 Epoch: 007/010 | Batch 0150/0391 | Cost: 0.6288 Epoch: 007/010 | Batch 0200/0391 | Cost: 0.6278 Epoch: 007/010 | Batch 0250/0391 | Cost: 0.6197 Epoch: 007/010 | Batch 0300/0391 | Cost: 0.7163 Epoch: 007/010 | Batch 0350/0391 | Cost: 0.7765 Epoch: 007/010 | Train: 78.272% Time elapsed: 1.06 min Epoch: 008/010 | Batch 0000/0391 | Cost: 0.5051 Epoch: 008/010 | Batch 0050/0391 | Cost: 0.5975 Epoch: 008/010 | Batch 0100/0391 | Cost: 0.6060 Epoch: 008/010 | Batch 0150/0391 | Cost: 0.6763 Epoch: 008/010 | Batch 0200/0391 | Cost: 0.5805 Epoch: 008/010 | Batch 0250/0391 | Cost: 0.6076 Epoch: 008/010 | Batch 0300/0391 | Cost: 0.5982 Epoch: 008/010 | Batch 0350/0391 | Cost: 0.8050 Epoch: 008/010 | Train: 82.530% Time elapsed: 1.22 min Epoch: 009/010 | Batch 0000/0391 | Cost: 0.4763 Epoch: 009/010 | Batch 0050/0391 | Cost: 0.4632 Epoch: 009/010 | Batch 0100/0391 | Cost: 0.6612 Epoch: 009/010 | Batch 0150/0391 | Cost: 0.5145 Epoch: 009/010 | Batch 0200/0391 | Cost: 0.6276 Epoch: 009/010 | Batch 0250/0391 | Cost: 0.7371 Epoch: 009/010 | Batch 0300/0391 | Cost: 0.6105 Epoch: 009/010 | Batch 0350/0391 | Cost: 0.6129 Epoch: 009/010 | Train: 84.632% Time elapsed: 1.37 min Epoch: 010/010 | Batch 0000/0391 | Cost: 0.4477 Epoch: 010/010 | Batch 0050/0391 | Cost: 0.3956 Epoch: 010/010 | Batch 0100/0391 | Cost: 0.4634 Epoch: 010/010 | Batch 0150/0391 | Cost: 0.4358 Epoch: 010/010 | Batch 0200/0391 | Cost: 0.5757 Epoch: 010/010 | Batch 0250/0391 | Cost: 0.4659 Epoch: 010/010 | Batch 0300/0391 | Cost: 0.4999 Epoch: 010/010 | Batch 0350/0391 | Cost: 0.4897 Epoch: 010/010 | Train: 88.534% Time elapsed: 1.51 min Total Training Time: 1.51 min
Evaluation¶
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))
Test accuracy: 67.30%
%watermark -iv
torch 1.3.1 pandas 0.24.2 PIL.Image 6.2.1 torchvision 0.4.2 matplotlib 3.1.0 numpy 1.17.4