Accompanying code examples of the book "Introduction to Artificial Neural Networks and Deep Learning: A Practical Guide with Applications in Python" by Sebastian Raschka. All code examples are released under the MIT license. If you find this content useful, please consider supporting the work by buying a copy of the book.
Other code examples and content are available on GitHub. The PDF and ebook versions of the book are available through Leanpub.
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
Sebastian Raschka CPython 3.6.8 IPython 7.2.0 torch 1.0.1.post2
- Runs on CPU (not recommended here) or GPU (if available)
Model Zoo -- CNN Gender Classifier (VGG16 Architecture, CelebA)¶
Implementation of the VGG-16 [1] architecture on the CelebA face dataset [2] to train a gender classifier.
References
- [1] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- [2] Zhang, K., Tan, L., Li, Z., & Qiao, Y. (2016). Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 34-38).
The following table (taken from Simonyan & Zisserman referenced above) summarizes the VGG19 architecture:
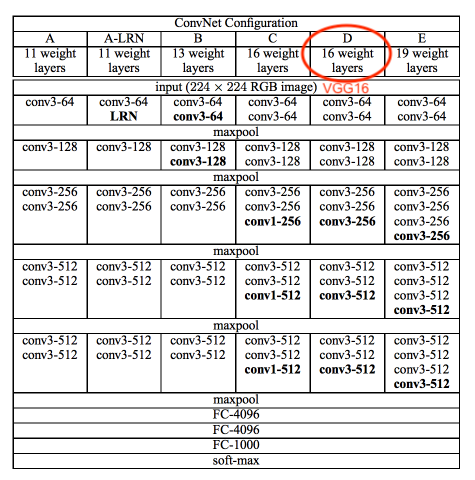
Note that the CelebA images are 218 x 178, not 256 x 256. We resize to 128x128
Imports¶
import os
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
if torch.cuda.is_available():
torch.backends.cudnn.deterministic = True
Dataset¶
Downloading the Dataset¶
Note that the ~200,000 CelebA face image dataset is relatively large (~1.3 Gb). The download link provided below was provided by the author on the official CelebA website at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html.
Download and unzip the file
img_align_celeba.zip, which contains the images in jpeg format.Download the
list_attr_celeba.txtfile, which contains the class labelsDownload the
list_eval_partition.txtfile, which contains training/validation/test partitioning info
Preparing the Dataset¶
df1 = pd.read_csv('list_attr_celeba.txt', sep="\s+", skiprows=1, usecols=['Male'])
# Make 0 (female) & 1 (male) labels instead of -1 & 1
df1.loc[df1['Male'] == -1, 'Male'] = 0
df1.head()
| Male | |
|---|---|
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 1 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df2 = pd.read_csv('list_eval_partition.txt', sep="\s+", skiprows=0, header=None)
df2.columns = ['Filename', 'Partition']
df2 = df2.set_index('Filename')
df2.head()
| Partition | |
|---|---|
| Filename | |
| 000001.jpg | 0 |
| 000002.jpg | 0 |
| 000003.jpg | 0 |
| 000004.jpg | 0 |
| 000005.jpg | 0 |
df3 = df1.merge(df2, left_index=True, right_index=True)
df3.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df3.to_csv('celeba-gender-partitions.csv')
df4 = pd.read_csv('celeba-gender-partitions.csv', index_col=0)
df4.head()
| Male | Partition | |
|---|---|---|
| 000001.jpg | 0 | 0 |
| 000002.jpg | 0 | 0 |
| 000003.jpg | 1 | 0 |
| 000004.jpg | 0 | 0 |
| 000005.jpg | 0 | 0 |
df4.loc[df4['Partition'] == 0].to_csv('celeba-gender-train.csv')
df4.loc[df4['Partition'] == 1].to_csv('celeba-gender-valid.csv')
df4.loc[df4['Partition'] == 2].to_csv('celeba-gender-test.csv')
img = Image.open('img_align_celeba/000001.jpg')
print(np.asarray(img, dtype=np.uint8).shape)
plt.imshow(img);
(218, 178, 3)

Implementing a Custom DataLoader Class¶
class CelebaDataset(Dataset):
"""Custom Dataset for loading CelebA face images"""
def __init__(self, csv_path, img_dir, transform=None):
df = pd.read_csv(csv_path, index_col=0)
self.img_dir = img_dir
self.csv_path = csv_path
self.img_names = df.index.values
self.y = df['Male'].values
self.transform = transform
def __getitem__(self, index):
img = Image.open(os.path.join(self.img_dir,
self.img_names[index]))
if self.transform is not None:
img = self.transform(img)
label = self.y[index]
return img, label
def __len__(self):
return self.y.shape[0]
# Note that transforms.ToTensor()
# already divides pixels by 255. internally
custom_transform = transforms.Compose([transforms.CenterCrop((178, 178)),
transforms.Resize((128, 128)),
#transforms.Grayscale(),
#transforms.Lambda(lambda x: x/255.),
transforms.ToTensor()])
train_dataset = CelebaDataset(csv_path='celeba-gender-train.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
valid_dataset = CelebaDataset(csv_path='celeba-gender-valid.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
test_dataset = CelebaDataset(csv_path='celeba-gender-test.csv',
img_dir='img_align_celeba/',
transform=custom_transform)
BATCH_SIZE=64
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4)
device = torch.device("cuda:2" if torch.cuda.is_available() else "cpu")
torch.manual_seed(0)
num_epochs = 2
for epoch in range(num_epochs):
for batch_idx, (x, y) in enumerate(train_loader):
print('Epoch:', epoch+1, end='')
print(' | Batch index:', batch_idx, end='')
print(' | Batch size:', y.size()[0])
x = x.to(device)
y = y.to(device)
break
Epoch: 1 | Batch index: 0 | Batch size: 64 Epoch: 2 | Batch index: 0 | Batch size: 64
Model¶
##########################
### SETTINGS
##########################
# Device
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
print('Device:', device)
# Hyperparameters
random_seed = 1
learning_rate = 0.001
num_epochs = 3
# Architecture
num_features = 128*128
num_classes = 2
Device: cuda:1
##########################
### MODEL
##########################
class VGG16(torch.nn.Module):
def __init__(self, num_features, num_classes):
super(VGG16, self).__init__()
# calculate same padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
# (1(32-1)- 32 + 3)/2 = 1
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = nn.Sequential(
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = nn.Sequential(
nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = nn.Sequential(
nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = nn.Sequential(
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.classifier = nn.Sequential(
nn.Linear(512*4*4, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
#n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
#m.weight.data.normal_(0, np.sqrt(2. / n))
m.weight.detach().normal_(0, 0.05)
if m.bias is not None:
m.bias.detach().zero_()
elif isinstance(m, torch.nn.Linear):
m.weight.detach().normal_(0, 0.05)
m.bias.detach().detach().zero_()
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
logits = self.classifier(x.view(-1, 512*4*4))
probas = F.softmax(logits, dim=1)
return logits, probas
torch.manual_seed(random_seed)
model = VGG16(num_features=num_features,
num_classes=num_classes)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
Training¶
def compute_accuracy(model, data_loader):
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, num_epochs, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%% | Valid: %.3f%%' % (
epoch+1, num_epochs,
compute_accuracy(model, train_loader),
compute_accuracy(model, valid_loader)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
Epoch: 001/003 | Batch 0000/2544 | Cost: 8999.8145 Epoch: 001/003 | Batch 0050/2544 | Cost: 0.6257 Epoch: 001/003 | Batch 0100/2544 | Cost: 0.6558 Epoch: 001/003 | Batch 0150/2544 | Cost: 0.5469 Epoch: 001/003 | Batch 0200/2544 | Cost: 0.4937 Epoch: 001/003 | Batch 0250/2544 | Cost: 0.4867 Epoch: 001/003 | Batch 0300/2544 | Cost: 0.4602 Epoch: 001/003 | Batch 0350/2544 | Cost: 0.5152 Epoch: 001/003 | Batch 0400/2544 | Cost: 0.4264 Epoch: 001/003 | Batch 0450/2544 | Cost: 0.5137 Epoch: 001/003 | Batch 0500/2544 | Cost: 0.3916 Epoch: 001/003 | Batch 0550/2544 | Cost: 0.3165 Epoch: 001/003 | Batch 0600/2544 | Cost: 0.6117 Epoch: 001/003 | Batch 0650/2544 | Cost: 0.3909 Epoch: 001/003 | Batch 0700/2544 | Cost: 0.4242 Epoch: 001/003 | Batch 0750/2544 | Cost: 0.4540 Epoch: 001/003 | Batch 0800/2544 | Cost: 0.2755 Epoch: 001/003 | Batch 0850/2544 | Cost: 0.4310 Epoch: 001/003 | Batch 0900/2544 | Cost: 0.2823 Epoch: 001/003 | Batch 0950/2544 | Cost: 0.3737 Epoch: 001/003 | Batch 1000/2544 | Cost: 0.3263 Epoch: 001/003 | Batch 1050/2544 | Cost: 0.3984 Epoch: 001/003 | Batch 1100/2544 | Cost: 0.1611 Epoch: 001/003 | Batch 1150/2544 | Cost: 0.1784 Epoch: 001/003 | Batch 1200/2544 | Cost: 0.1977 Epoch: 001/003 | Batch 1250/2544 | Cost: 0.2410 Epoch: 001/003 | Batch 1300/2544 | Cost: 0.2847 Epoch: 001/003 | Batch 1350/2544 | Cost: 0.1814 Epoch: 001/003 | Batch 1400/2544 | Cost: 0.2212 Epoch: 001/003 | Batch 1450/2544 | Cost: 0.2007 Epoch: 001/003 | Batch 1500/2544 | Cost: 0.2087 Epoch: 001/003 | Batch 1550/2544 | Cost: 0.2115 Epoch: 001/003 | Batch 1600/2544 | Cost: 0.1731 Epoch: 001/003 | Batch 1650/2544 | Cost: 0.2568 Epoch: 001/003 | Batch 1700/2544 | Cost: 0.2419 Epoch: 001/003 | Batch 1750/2544 | Cost: 0.2979 Epoch: 001/003 | Batch 1800/2544 | Cost: 0.1316 Epoch: 001/003 | Batch 1850/2544 | Cost: 0.3287 Epoch: 001/003 | Batch 1900/2544 | Cost: 0.1634 Epoch: 001/003 | Batch 1950/2544 | Cost: 0.2639 Epoch: 001/003 | Batch 2000/2544 | Cost: 0.0619 Epoch: 001/003 | Batch 2050/2544 | Cost: 0.1673 Epoch: 001/003 | Batch 2100/2544 | Cost: 0.2950 Epoch: 001/003 | Batch 2150/2544 | Cost: 0.0905 Epoch: 001/003 | Batch 2200/2544 | Cost: 0.2496 Epoch: 001/003 | Batch 2250/2544 | Cost: 0.0577 Epoch: 001/003 | Batch 2300/2544 | Cost: 0.1660 Epoch: 001/003 | Batch 2350/2544 | Cost: 0.0848 Epoch: 001/003 | Batch 2400/2544 | Cost: 0.1184 Epoch: 001/003 | Batch 2450/2544 | Cost: 0.1357 Epoch: 001/003 | Batch 2500/2544 | Cost: 0.1050 Epoch: 001/003 | Train: 94.248% | Valid: 95.153% Time elapsed: 18.15 min Epoch: 002/003 | Batch 0000/2544 | Cost: 0.1842 Epoch: 002/003 | Batch 0050/2544 | Cost: 0.1251 Epoch: 002/003 | Batch 0100/2544 | Cost: 0.1211 Epoch: 002/003 | Batch 0150/2544 | Cost: 0.1347 Epoch: 002/003 | Batch 0200/2544 | Cost: 0.0831 Epoch: 002/003 | Batch 0250/2544 | Cost: 0.0941 Epoch: 002/003 | Batch 0300/2544 | Cost: 0.0322 Epoch: 002/003 | Batch 0350/2544 | Cost: 0.0987 Epoch: 002/003 | Batch 0400/2544 | Cost: 0.2358 Epoch: 002/003 | Batch 0450/2544 | Cost: 0.1771 Epoch: 002/003 | Batch 0500/2544 | Cost: 0.1429 Epoch: 002/003 | Batch 0550/2544 | Cost: 0.1097 Epoch: 002/003 | Batch 0600/2544 | Cost: 0.1186 Epoch: 002/003 | Batch 0650/2544 | Cost: 0.1154 Epoch: 002/003 | Batch 0700/2544 | Cost: 0.0751 Epoch: 002/003 | Batch 0750/2544 | Cost: 0.0558 Epoch: 002/003 | Batch 0800/2544 | Cost: 0.0821 Epoch: 002/003 | Batch 0850/2544 | Cost: 0.0999 Epoch: 002/003 | Batch 0900/2544 | Cost: 0.0926 Epoch: 002/003 | Batch 0950/2544 | Cost: 0.1036 Epoch: 002/003 | Batch 1000/2544 | Cost: 0.1237 Epoch: 002/003 | Batch 1050/2544 | Cost: 0.0967 Epoch: 002/003 | Batch 1100/2544 | Cost: 0.1108 Epoch: 002/003 | Batch 1150/2544 | Cost: 0.0619 Epoch: 002/003 | Batch 1200/2544 | Cost: 0.1765 Epoch: 002/003 | Batch 1250/2544 | Cost: 0.1120 Epoch: 002/003 | Batch 1300/2544 | Cost: 0.1478 Epoch: 002/003 | Batch 1350/2544 | Cost: 0.1043 Epoch: 002/003 | Batch 1400/2544 | Cost: 0.1552 Epoch: 002/003 | Batch 1450/2544 | Cost: 0.1066 Epoch: 002/003 | Batch 1500/2544 | Cost: 0.1669 Epoch: 002/003 | Batch 1550/2544 | Cost: 0.1202 Epoch: 002/003 | Batch 1600/2544 | Cost: 0.1832 Epoch: 002/003 | Batch 1650/2544 | Cost: 0.1841 Epoch: 002/003 | Batch 1700/2544 | Cost: 0.1070 Epoch: 002/003 | Batch 1750/2544 | Cost: 0.0350 Epoch: 002/003 | Batch 1800/2544 | Cost: 0.0825 Epoch: 002/003 | Batch 1850/2544 | Cost: 0.1070 Epoch: 002/003 | Batch 1900/2544 | Cost: 0.1570 Epoch: 002/003 | Batch 1950/2544 | Cost: 0.0853 Epoch: 002/003 | Batch 2000/2544 | Cost: 0.0901 Epoch: 002/003 | Batch 2050/2544 | Cost: 0.1085 Epoch: 002/003 | Batch 2100/2544 | Cost: 0.1375 Epoch: 002/003 | Batch 2150/2544 | Cost: 0.2110 Epoch: 002/003 | Batch 2200/2544 | Cost: 0.1989 Epoch: 002/003 | Batch 2250/2544 | Cost: 0.0780 Epoch: 002/003 | Batch 2300/2544 | Cost: 0.1963 Epoch: 002/003 | Batch 2350/2544 | Cost: 0.2093 Epoch: 002/003 | Batch 2400/2544 | Cost: 0.1517 Epoch: 002/003 | Batch 2450/2544 | Cost: 0.1733 Epoch: 002/003 | Batch 2500/2544 | Cost: 0.1134 Epoch: 002/003 | Train: 94.474% | Valid: 95.455% Time elapsed: 36.37 min Epoch: 003/003 | Batch 0000/2544 | Cost: 0.2171 Epoch: 003/003 | Batch 0050/2544 | Cost: 0.0676 Epoch: 003/003 | Batch 0100/2544 | Cost: 0.1667 Epoch: 003/003 | Batch 0150/2544 | Cost: 0.1690 Epoch: 003/003 | Batch 0200/2544 | Cost: 0.0785 Epoch: 003/003 | Batch 0250/2544 | Cost: 0.1078 Epoch: 003/003 | Batch 0300/2544 | Cost: 0.1877 Epoch: 003/003 | Batch 0350/2544 | Cost: 0.1541 Epoch: 003/003 | Batch 0400/2544 | Cost: 0.1434 Epoch: 003/003 | Batch 0450/2544 | Cost: 0.1019 Epoch: 003/003 | Batch 0500/2544 | Cost: 0.1591 Epoch: 003/003 | Batch 0550/2544 | Cost: 0.0601 Epoch: 003/003 | Batch 0600/2544 | Cost: 0.0426 Epoch: 003/003 | Batch 0650/2544 | Cost: 0.0988 Epoch: 003/003 | Batch 0700/2544 | Cost: 0.0573 Epoch: 003/003 | Batch 0750/2544 | Cost: 0.1278 Epoch: 003/003 | Batch 0800/2544 | Cost: 0.1110 Epoch: 003/003 | Batch 0850/2544 | Cost: 0.1133 Epoch: 003/003 | Batch 0900/2544 | Cost: 0.1783 Epoch: 003/003 | Batch 0950/2544 | Cost: 0.1281 Epoch: 003/003 | Batch 1000/2544 | Cost: 0.1118 Epoch: 003/003 | Batch 1050/2544 | Cost: 0.1484 Epoch: 003/003 | Batch 1100/2544 | Cost: 0.1325 Epoch: 003/003 | Batch 1150/2544 | Cost: 0.1699 Epoch: 003/003 | Batch 1200/2544 | Cost: 0.0831 Epoch: 003/003 | Batch 1250/2544 | Cost: 0.0780 Epoch: 003/003 | Batch 1300/2544 | Cost: 0.0710 Epoch: 003/003 | Batch 1350/2544 | Cost: 0.1472 Epoch: 003/003 | Batch 1400/2544 | Cost: 0.1385 Epoch: 003/003 | Batch 1450/2544 | Cost: 0.0456 Epoch: 003/003 | Batch 1500/2544 | Cost: 0.0435 Epoch: 003/003 | Batch 1550/2544 | Cost: 0.1055 Epoch: 003/003 | Batch 1600/2544 | Cost: 0.2022 Epoch: 003/003 | Batch 1650/2544 | Cost: 0.1517 Epoch: 003/003 | Batch 1700/2544 | Cost: 0.1221 Epoch: 003/003 | Batch 1750/2544 | Cost: 0.1058 Epoch: 003/003 | Batch 1800/2544 | Cost: 0.1964 Epoch: 003/003 | Batch 1850/2544 | Cost: 0.1567 Epoch: 003/003 | Batch 1900/2544 | Cost: 0.1164 Epoch: 003/003 | Batch 1950/2544 | Cost: 0.0284 Epoch: 003/003 | Batch 2000/2544 | Cost: 0.2034 Epoch: 003/003 | Batch 2050/2544 | Cost: 0.0262 Epoch: 003/003 | Batch 2100/2544 | Cost: 0.0662 Epoch: 003/003 | Batch 2150/2544 | Cost: 0.0846 Epoch: 003/003 | Batch 2200/2544 | Cost: 0.2315 Epoch: 003/003 | Batch 2250/2544 | Cost: 0.0953 Epoch: 003/003 | Batch 2300/2544 | Cost: 0.1228 Epoch: 003/003 | Batch 2350/2544 | Cost: 0.0512 Epoch: 003/003 | Batch 2400/2544 | Cost: 0.1387 Epoch: 003/003 | Batch 2450/2544 | Cost: 0.2434 Epoch: 003/003 | Batch 2500/2544 | Cost: 0.1623 Epoch: 003/003 | Train: 95.849% | Valid: 96.628% Time elapsed: 54.64 min Total Training Time: 54.64 min
Evaluation¶
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader)))
Test accuracy: 95.48%
for batch_idx, (features, targets) in enumerate(test_loader):
features = features
targets = targets
break
plt.imshow(np.transpose(features[0], (1, 2, 0)))
<matplotlib.image.AxesImage at 0x7f115ce7bbe0>

model.eval()
logits, probas = model(features.to(device)[0, None])
print('Probability Female %.2f%%' % (probas[0][0]*100))
Probability Female 90.72%
%watermark -iv
numpy 1.15.4 pandas 0.23.4 torch 1.0.1.post2 PIL.Image 5.3.0