ক্রস ভ্যালিডেশনের প্যারামিটারের টিউনিং, মডেল সিলেকশন¶
জুপিটার নোটবুকের লিংক https://github.com/raqueeb/ml-python/blob/master/cross-validation.ipynb
অ্যাক্যুরেসি বাড়ানোর জন্য "কে ফোল্ড" ক্রস ভ্যালিডেশন¶
মডেল ইভ্যালুয়েশনে "ট্রেইন/টেস্ট স্প্লিট" দেখেছি আগের চ্যাপ্টারে। এখানে এই স্প্লিটে বেশি 'আউট অফ স্যাম্পল' ডেটার জন্য 'ভ্যারিয়েন্স' এস্টিমেট অনেক বেশি হতে পারে। কারণ কোন অবজারভেশনগুলো টেস্ট সেটে যাবে সেটা অনেক সময় আমাদের হাতে থাকে না। আর সেকারণে সেটার আউটকাম টেস্টিং অ্যাক্যুরেসিতে পড়তে পারে। আর আপনি যা করছেন সেটা একবার করছেন। একটা ছোট ডেটাসেটের আলাদা একটা টেস্টসেট তৈরি করতে গিয়ে ট্রেনিং ডেটাসেট কমে যায়।
সেকারণে আমরা এখন চেষ্টা করবো নতুন একটা কনসেপ্ট, "কে ফোল্ড" ক্রস ভ্যালিডেশন। "কে ফোল্ড" অর্থ হচ্ছে ডেটাসেটকে কতোবার আমরা "কে" সংখ্যক একই ভাগে ভাগ করবো।
শুরুতেই লোড করে নেই আগের ডেটাসেট এবং দরকারি মডিউল¶
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# লোড করে নেই আইরিস ডেটাসেট
iris = load_iris()
# তৈরি করে নেই X (ফীচার) এবং y (রেসপন্স)
X = iris.data
y = iris.target
"কে ফোল্ড" ক্রস ভ্যালিডেশন করার কিছু স্টেপস¶
শুরুতেই আমাদের নতুন এই টুল পুরো ডেটাসেটকে ভাগ করবে সমান সাইজের পার্টিশনে। এই পার্টিশনগুলো হচ্ছে ফোল্ড, কয়টা ফোল্ড করতে চাই আমরা?
নিচের ছবিটা দেখুন। পুরো ডেটাকে পাঁচ ভাগে ভাগ করেছে এই টুল। এখানে সবচেয়ে ডানের পার্টিশন মানে ফোল্ডকে সে ডিক্লেয়ার করেছে টেস্ট সেট হিসেবে। বাকি চার ভাগ ট্রেনিং সেট। ট্রেনিং সেট সবসময় টেস্ট সেট থেকে বড় রাখতে হয়।
এরপর সেটা বের করবে "টেস্টিং অ্যাক্যুরেসি"। সাধারণ সিস্টেমে যেভাবে আগে কাজ করেছি সেভাবে।
২য় এবং ৩য় স্টেপগুলো বার বার করতে থাকবো যতক্ষণ পর্যন্ত একেকটা ফোল্ডকে একেকবার টেস্ট সেট হিসেবে ব্যবহার করে শেষ করে ফেলবো। এটা যদি "৫ ফোল্ড" ক্রস ভ্যালিডেশন হয়, এর মানে হচ্ছে পাঁচবার আলাদা করে টেস্ট সেট হিসেবে ধরে ট্রেনিং করে সেটার অ্যাক্যুরেসি সে মনে রাখবে। এগুলো আমরা খালি চোখে দেখবো না, এর সব কাজ হয়ে যাবে মডিউলের ভেতরে।
এই সবগুলোর "টেস্টিং অ্যাক্যুরেসি"কে গড় করে সেটাকে আমরা "আউট অফ স্যাম্পল" এর এস্টিমেট ধারণা করতে পারি।
"৫ ফোল্ড" ক্রস ভ্যালিডেশন এর একটা ছবি¶
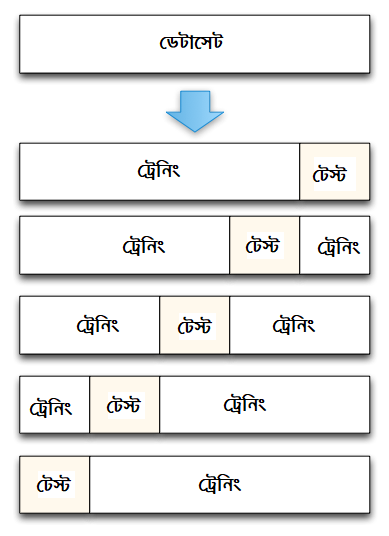
# এটা আমাদের কাজে লাগবেনা, তবে ধারণা নেবার জন্য এখানে দেয়া
# আমরা ২৫টা রেকর্ড নিয়ে সেটাকে ৫ ফোল্ডে ভাগ করে একটা সিমুলেশন দেখাই এখানে
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=False).split(range(25))
# প্রতিটা ট্রেনিং এবং টেস্ট সেট এর কনটেন্ট দেখি একটা একটা করে, সংখ্যাগুলো ডেটাসেটের একেকটা রেকর্ড
print('{} {:^61} {}'.format('Iteration', 'Training set observations', 'Testing set observations'))
for iteration, data in enumerate(kf, start=1):
print('{:^9} {} {:^25}'.format(iteration, data[0], str(data[1])))
Iteration Training set observations Testing set observations
1 [ 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4]
2 [ 0 1 2 3 4 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [5 6 7 8 9]
3 [ 0 1 2 3 4 5 6 7 8 9 15 16 17 18 19 20 21 22 23 24] [10 11 12 13 14]
4 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 20 21 22 23 24] [15 16 17 18 19]
5 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24]
আপনাদের বোঝানোর জন্য ছোট একটা পঁচিশটা অবজারভেশনের ডেটাসেট দেখানো হচ্ছে এখানে। এর সাথে আইরিস ডেটাসেটের কোন সম্পর্ক নেই। এর অবজারভেশনগুলো হচ্ছে ০ থেকে ২৪ পর্যন্ত।
যেহেতু এটা একটা ৫ ফোল্ড ক্রস ভালিডেশন, সে কারণে এটার কিন্তু পাঁচটা ‘আইটারেশন’। একই জিনিস পাঁচবার আলাদা আলাদা করে চলবে।
প্রতিটা ‘আইটারেশনে’, আমাদের এক একটা রেকর্ড - হয় ট্রেনিং সেটে অথবা টেস্টিং সেটে থাকবে, কিন্তু দু'জায়গায় একসময়ে থাকবে না।
আবার টেস্টিং সেটে প্রতিটা অবজারভেশন একবারই আসবে, এর বেশি নয়।
ক্রস ভ্যালিডেশনের কিছু বেস্ট প্রাক্টিসেস¶
আমাদের "কে" ফোল্ড অংশে "কে" এর সংখ্যা ইচ্ছেমতো হতে পারে তবে আমাদের রেকমেন্ডেশন হচ্ছে K=10।
ক্লাসিফিকেশন সমস্যায় সেখানে আমরা "স্ট্র্যাটিফাইড স্যাম্পলিং" ব্যবহার করবো ফোল্ড তৈরি করার জন্য। প্রতিটা রেসপন্স ক্লাস কিন্তু একই অনুপাতে আনতে হবে প্রতিটা "কে" ফোল্ডে। এটা একটা সমস্যা। তবে সাইকিট লার্নের
cross_val_scoreফাংশন জিনিসটা করে দেয় এমনিতেই। আর সেকারণে সাইকিট লার্নের এতো নাম ডাক।
অ্যাক্যুরেসি বাড়াতে আইরিস ডেটাসেটের জন্য প্যারামিটার টিউনিং¶
অনেক গল্প শুনি আমরা "হাইপার-প্যারামিটার" টিউনিং নিয়ে। আইরিস ডেটাসেট নিয়ে "কে নিয়ারেস্ট নেইবার"এর সবচেয়ে ভালো টিউনিং প্যারামিটার কি হতে পারে?
from sklearn.model_selection import cross_val_score
# "কে নিয়ারেস্ট নেইবার" K=5, n_neighbors হচ্ছে প্যারামিটার + "কে ফোল্ড" ক্রস ভ্যালিডেশন এর cv=10
knn = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
print(scores)
[ 1. 0.93333333 1. 1. 0.86666667 0.93333333 0.93333333 1. 1. 1. ]
# গড় করি সবগুলোর "আউট অফ স্যাম্পল" অ্যাক্যুরেসি পেতে
print(scores.mean())
0.966666666667
# "কে নিয়ারেস্ট নেইবার" কতো হলে মডেলটা অপটিমাইজড হয়? ১ থেকে ৩১ পর্যন্ত
# এখানে "কে ফোল্ড" ক্রস ভ্যালিডেশন = ১০ মানে cv=10
k_range = list(range(1, 31))
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
print(k_scores)
[0.95999999999999996, 0.95333333333333337, 0.96666666666666656, 0.96666666666666656, 0.96666666666666679, 0.96666666666666679, 0.96666666666666679, 0.96666666666666679, 0.97333333333333338, 0.96666666666666679, 0.96666666666666679, 0.97333333333333338, 0.98000000000000009, 0.97333333333333338, 0.97333333333333338, 0.97333333333333338, 0.97333333333333338, 0.98000000000000009, 0.97333333333333338, 0.98000000000000009, 0.96666666666666656, 0.96666666666666656, 0.97333333333333338, 0.95999999999999996, 0.96666666666666656, 0.95999999999999996, 0.96666666666666656, 0.95333333333333337, 0.95333333333333337, 0.95333333333333337]
# ছবি আঁকতে হবে না? %matplotlib inline মানে হচ্ছে ছবিটা জুপিটার নোটবুকের ভেতরেই দেখাবে
import matplotlib.pyplot as plt
%matplotlib inline
# plot the value of K for KNN (x-axis) versus the cross-validated accuracy (y-axis)
# কে এর মান ফেললাম এক্স এক্সিসে, অ্যাক্যুরেসি ওয়াই এক্সিসে
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
Text(0,0.5,'Cross-Validated Accuracy')

"কে ফোল্ড" ক্রস ভ্যালিডেশন: মডেল বাছাই¶
আগের ছবিটা দেখুন। খালি চোখে "কে" এর মান ০.৯৮ দেখছি এক্স এক্সিসে ১৩, ১৮ এবং ২০এ। দেখি মডেলে ব্যবহার করে।
Goal: Compare the best KNN model with logistic regression on the iris dataset দুটো মডেল তুলনা করি এখানে। "কে নিয়ারেস্ট নেইবার" আর লজিস্টিক রিগ্রেশন, কোনটা ভালো? সঙ্গে n_neighbors=20 এবং cv=10।
# "কে নিয়ারেস্ট নেইবার" সঙ্গে ১০ "কে ফোল্ড" ক্রস ভ্যালিডেশন
knn = KNeighborsClassifier(n_neighbors=20)
print(cross_val_score(knn, X, y, cv=10, scoring='accuracy').mean())
0.98
# লজিস্টিক রিগ্রেশন সঙ্গে একই ১০ "কে ফোল্ড" ক্রস ভ্যালিডেশন
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
print(cross_val_score(logreg, X, y, cv=10, scoring='accuracy').mean())
0.953333333333
দুটোর মধ্যে অ্যাক্যুরেসির বেশ ফারাক। এর মানে মডেল সিলেকশন একটা জরুরি বিষয় বটে।