![]()
I wanted to show how Neural network is better than generic machine learning.
I wanted to show with sklearn, it is difficult when we wanted to show descision boundary in non linear data.
I used SVM to do this, but with a helper function like 'plot_decision_regions', can it be done with logistic regression with straight line to show that it is not possible. See [out] 13.
[Out] shows that with only input 1, output 1 neuron it is not possible. It need atleast 4 input neuron to make it happen.
I could not make [out] 13 look like [out] 16.
Please ignore the text markups.
দুটো ফিচার নিয়ে আইরিশ ডেটাসেটকে প্লট করি¶
সরল রেখায় ডিসিশন সারফেস/বাউন্ডারি বানানো যায় সহজে। কোড কমানোর জন্য 'plot_decision_regions' নামের একটা হেলপার ফাংশন ব্যবহার করি।
from sklearn import datasets
from sklearn.svm import SVC
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
%matplotlib inline
# Loading some example data
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
# Training a classifier
svm = SVC(C=0.5, kernel='linear')
svm.fit(X, y)
# Plotting decision regions
plot_decision_regions(X, y, clf=svm, legend=2)
# Adding axes annotations
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.title('SVM on Iris')
plt.show()

বয়সের সাথে ওজন বাড়বে, বাড়ি স্কয়ার ফিট এর সাথে দাম বাড়বে, এধরনের লিনিয়ার সম্পর্কগুলোতে ডাটাকে প্লট করলে সেগুলোকে সোজা লাইন দিয়ে আলাদা করে দেখা যায় সহজে। কিন্তু ডাটা যদি এমন হয়? কিভাবে একটা লাইন দিয়ে দুটো ফিচারকে ভাগ করবেন?
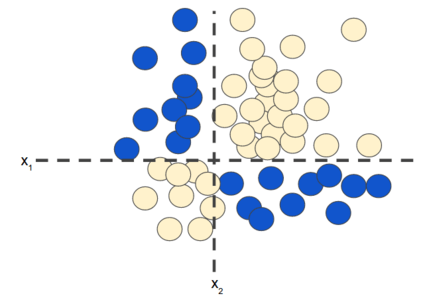 চিত্রঃ নন-লিনিয়ার ক্লাসিফিকেশন সমস্যা
চিত্রঃ নন-লিনিয়ার ক্লাসিফিকেশন সমস্যা
এটা নন-লিনিয়ার ক্লাসিফিকেশন সমস্যা। নন-লিনিয়ার এর সমস্যা হচ্ছে তাদের 'ডিসিশন সারফেস' সরলরেখা নয়। এই ছবিতে যদি দুটো ফিচার থাকে তাহলে সেটা দিয়ে এই সমস্যার সমাধান করা সম্ভব নয়। সেটার জন্য প্রয়োজন ফিচার ক্রস। মানে এই নতুন ফিচার কয়েকটা ফিচার স্পেসের গুণফলের আউটকাম নন-লিনিয়ারিটিকে এনকোড করে মানে আরেকটা সিনথেটিক ফিচার তৈরি করে সেটার মাধ্যমে এই নন-লিনিয়ারিটিকে কিছুটা ডিল করা যায়। ক্রস এসেছে ক্রস প্রোডাক্ট থেকে। এখানে x1 = x2x3 (সাবস্ক্রিপ্ট হবে)
একটা নন-লিনিয়ারিটির উদাহরণ দেখি আসল ডেটা থেকে¶
import pandas as pd
import numpy as np
import sklearn
from sklearn.model_selection import train_test_split
ভার্সন চেক করি¶
sklearn.__version__
'0.21.3'
try:
# %tensorflow_version only exists in Colab.
# শুধুমাত্র কোলাবে চেষ্টা করবো টেন্সর-ফ্লো ২.০ এর জন্য
%tensorflow_version 2.x
except Exception:
pass
TensorFlow 2.x selected.
import tensorflow as tf
tf.__version__
'2.0.0-rc2'
১. ডেটাকে আমরা লোড করে সেটাকে ট্রেইন এবং টেস্টসেটে ভাগ করি¶
ধরুন আপনি ডাটা প্লট করে দেখলেন এই অবস্থা। কি করবেন? নিচের ছবি দেখুন। এই ডাটাসেটে অক্ষাংশ, দ্রাঘিমাংশ, ভূমির উচ্চতা ইত্যাদি আছে। আমরা সবগুলোর মধ্যে শুধুমাত্র অক্ষাংশ, দ্রাঘিমাংশ প্লট করছি। দেখুন কি অবস্থা। একটা ফিচার ভেতরে আরেকটা ঘিরে রয়েছে সেটাকে চারপাশ দিয়ে। এখন কিভাবে এদুটোকে আলাদা করবেন? সোজা লাইন টেনে সম্ভব না। চেষ্টা করি নিউরাল নেটওয়ার্ক দিয়ে।
# df = pd.read_csv('geoloc_elev.csv')
df = pd.read_csv('https://raw.githubusercontent.com/raqueeb/TensorFlow2/master/datasets/geoloc_elev.csv')
# আমাদের দুটো ফিচার হলেই যথেষ্ট
X = df[['lat', 'lon']].values
y = df['target'].values
df.plot(kind='scatter',
x='lat',
y='lon',
c='target',
cmap='bwr');

from sklearn.svm import SVC
clf = SVC(gamma='auto')
clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# Loading Plotting Utilities
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.xlabel("x", size=5)
plt.ylabel("y", size=5)
plt.title('SVM Decision Region Boundary', size=6)
plt.show()

মেশিন লার্নিং এ ফিচার ক্রসের সুবিধা থাকলেও আমার পছন্দের ব্যাপার হচ্ছে মডেলে নন লিনিয়ারিটি ঢুকানো। মডেলে নন লিনিয়ারিটি ঢুকাতে গেলে নিউরাল নেটওয়ার্ক ভালো একটা উপায়। আমরা একটা ছবি আঁকি লিনিয়ার মডেলের। তিনটে ইনপুট ফিচার। ইনপুট ফিচারের সাথে ওয়েটকে যোগ করে নিয়ে এলাম আউটপুটে। আপনার কি মনে হয় এভাবে মডেলে নন-লিনিয়ারিটি ঢুকানোর সম্ভব? আপনি বলুন।
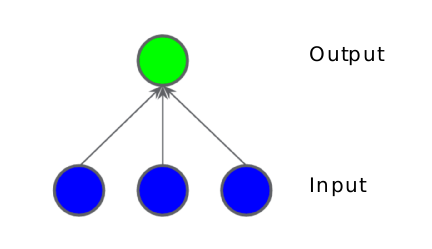
চিত্রঃ তিনটা ইনপুট যাচ্ছে একটা নিউরাল নেটওয়ার্কে
পরের ছবিতে আমরা একটা হিডেন লেয়ার যোগ করি। হিডেন লেয়ারের অর্থ হচ্ছে এর মধ্যে কিছু মাঝামাঝি ভ্যালু যোগ করা। আগের ইনপুট লেয়ার থেকে এই লেয়ারে তাদের ওয়েটগুলোর যোগফল পাঠিয়ে দিচ্ছে সামনের লেয়ারে। এখানে সামনে লেয়ার হচ্ছে আউটপুট। ইনপুট থেকে ওয়েট যোগ করে সেগুলোকে পাঠিয়ে দিচ্ছে আউটপুট লেয়ারে। ইংরেজিতে আমরা বলি 'ওয়েটেড সাম অফ প্রিভিয়াস নোডস'। এখনো কি মডেলটা লিনিয়ার? মডেল অবশ্যই লিনিয়ার হবে কারণ আমরা এ পর্যন্ত যা করেছি তা সব লিনিয়ার ইনপুটগুলোকেই একসাথে করেছি। নন-লিনিয়ারিটি যোগ করার মতো এখনো কিছু করিনি।
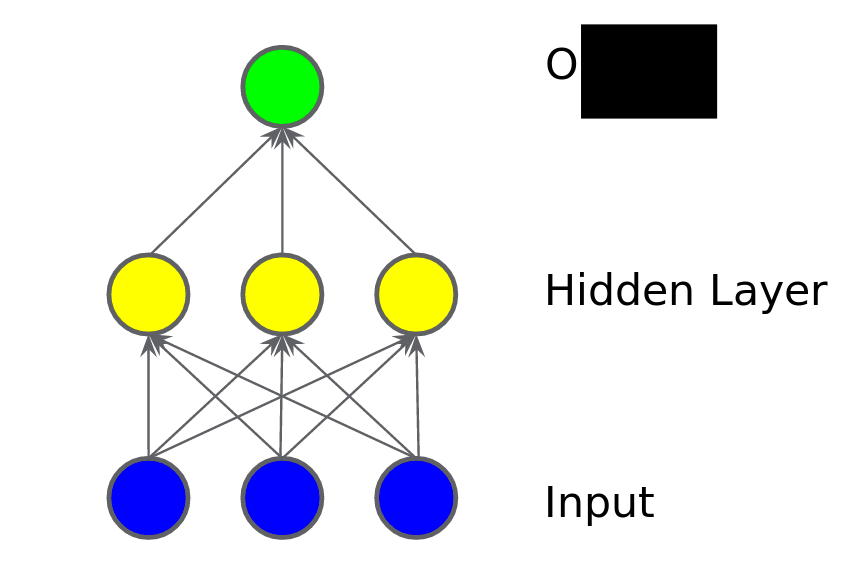 চিত্রঃ যোগ করলাম প্রথম হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম প্রথম হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
এরকম করে আমরা যদি আরেকটা হিডেন লেয়ার যোগ করি তাহলে কি হবে? নন লিনিয়ার কিছু হতে পারে? না। আমরা যতই লেয়ার বাড়াই না কেন এই আউটপুট হচ্ছে আসলে ইনপুটের একটা ফাংশন। মানে হচ্ছে ইনপুটের ওয়েট গুলোর একটা যোগফল। যাই যোগফল হোকনা কেন সবই লিনিয়ার। এই যোগফল আসলে আমাদের নন লিনিয়ার সমস্যা মেটাবে না।
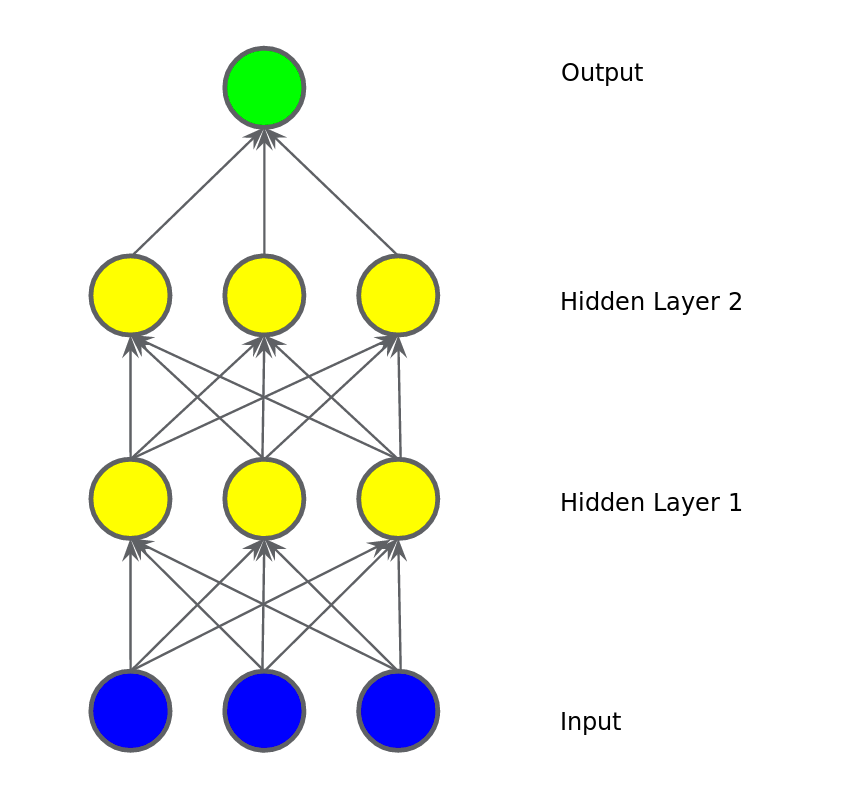 চিত্রঃ যোগ করলাম দ্বিতীয় হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
চিত্রঃ যোগ করলাম দ্বিতীয় হিডেন লেয়ার, লিনিয়ারিটি বজায় থাকবে?
একটা নন লিনিয়ার সমস্যাকে মডেল করতে গেলে আমাদের মডেলে যোগ করতে হবে নন লিনিয়ার কিছু ফাংশন। ব্যাপারটা আমাদেরকে নিজেদেরকেই ঢোকাতে হবে। সবচেয়ে মজার কথা হচ্ছে আমরা এই ইনপুটগুলোকে পাইপ করে হিডেন লেয়ারের শেষে একটা করে নন লিনিয়ার ফাংশন যোগ করে দিতে পারি। এই ছবিটা দেখুন। আমরা এক নাম্বার হিডেন লেয়ার এর পর একটা করে নন লিনিয়ার ফাংশন যোগ করে দিয়েছি যাতে সেটার আউটপুট সে পাঠাতে পারে দ্বিতীয় হিডেন লেয়ারে। এই ধরনের নন লিনিয়ার ফাংশনকে আমরা এর আগেও বলেছি অ্যাক্টিভেশন ফাংশন।
আমাদের পছন্দের অ্যাক্টিভেশন ফাংশন হচ্ছে রেল্যু, রেকটিফাইড লিনিয়ার ইউনিট অ্যাক্টিভেশন ফাংশন। কাজে এটা স্মার্ট, অনেকের থেকে ভালো আর সে কারণে এর ব্যবহার অনেক বেশি। ভুল হবার চান্স কম। ডায়াগ্রাম দেখলেই বুঝতে পারবেন - যদি ইনপুট শূন্য হয় তাহলে আউটপুট ০ আর ইনপুটের মান ০ থেকে বেশি হয় তাহলে সেটার আউটপুটে যাবে পরের লেয়ারে যাওয়ার জন্য।
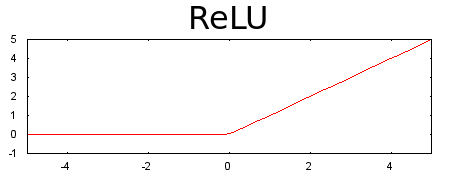 চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' থেকে ০ আসলে সেটাই থাকবে বেশি হলে ১, মানে পরের লেয়ারে পার
চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' থেকে ০ আসলে সেটাই থাকবে বেশি হলে ১, মানে পরের লেয়ারে পার
আমরা যখন অ্যাক্টিভেশন ফাংশন যোগ করব তার সঙ্গে বেশি বেশি লেয়ার মডেলে ভালো কাজ করে। একটা নন লিনিয়ারিটি আরেকটা নন লিনিয়ারিটির উপর থাকাতে মডেল অনেক কমপ্লেক্স সম্পর্ক ধরতে পারে ইনপুট থেকে আউটপুট পর্যন্ত। মডেলের প্রতিটা লেয়ার তার অংশে কমপ্লেক্স জিনিসগুলো এক্সট্রাক্ট করতে পারে সেই কারণেই। অ্যাক্টিভেশন ফাংশন ছাড়া একটা নিউরাল নেটওয়াক আসলে আরেকটা লিনিয়ার রিগ্রেশন মডেল। এদিকে অ্যাক্টিভেশন ফাংশনে ব্যাক-প্রপাগেশন সম্ভব করে কারণ এর গ্রেডিয়েন্ট, তার এরর, ওয়েট এবং বায়াসকে আপডেট পাঠায়। শুরুর দিকের অ্যাক্টিভেশন ফাংশন হচ্ছে সিগময়েড। যার কাজ হচ্ছে যাই পাক না কেন সেটাকে ০ অথবা ১ এ পাঠিয়ে দেবে।
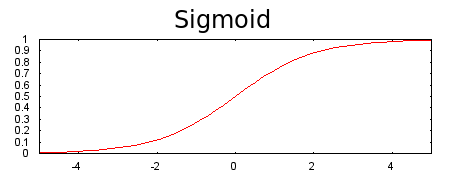 চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' পাল্টে দেবে ০ থেকে ১ এর মধ্যে এই সিগময়েড
চিত্রঃ ইনপুটের সবকিছুর 'ওয়েটেড সাম' পাল্টে দেবে ০ থেকে ১ এর মধ্যে এই সিগময়েড
আবারো বলছি - সিগময়েড অ্যাক্টিভেশন ফাংশন লেয়ারগুলোর ইনপুটের/আউটপুটের যোগফলকে ০ অথবা ১ এর মধ্যে ফেলে দেয়। হয় এসপার না হলে ওসপার। লিনিয়ারিটির কোন স্কোপ থাকবে না। একটা ছবি দেখুন। ইকুয়েশন সহ।
আমার আরেকটা পছন্দের অ্যাক্টিভেশন ফাংশন হচ্ছে সফটম্যাক্স। এটা সাধারণত আমরা ব্যবহার করি দুইয়ের বেশি ক্লাসিফিকেশন সমস্যা হ্যান্ডেল করতে। সিগময়েড ভালো যখন আমরা দুটো ক্লাসিফিকেশন করি, তবে মাল্টিপল ক্লাসিফিকেশন এর জন্য সফটম্যাক্স অসাধারণ। যখন আউটপুট লেয়ার একটার সাথে আরেকটা 'মিউচুয়ালি এক্সক্লুসিভ' হয়, মানে কোন আউটপুট একটার বেশী আরেকটার ঘরে পড়বে না তাহলে সেটা 'সফটম্যাক্'স হ্যান্ডেল করবে। আমাদের যেকোনো শার্ট অথবা হাতে লেখা MNIST ইমেজগুলো যেকোন একটা ক্লাসেই পড়বে তার বাইরে নয়।
ট্রেনিং/টেস্ট স্প্লিট করা¶
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.3, random_state=0)
একটা লজিস্টিক রিগ্রেশন করি¶
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
/usr/local/lib/python3.6/dist-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning. FutureWarning)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
একটা প্লটিং দেখি¶
hticks = np.linspace(-2, 2, 101)
vticks = np.linspace(-2, 2, 101)
aa, bb = np.meshgrid(hticks, vticks)
ab = np.c_[aa.ravel(), bb.ravel()]
c = lr.predict(ab)
cc = c.reshape(aa.shape)
ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')
ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)
<matplotlib.contour.QuadContourSet at 0x7fadbea07710>

২. একদম বেসিক নিউরাল নেটওয়ার্কে দেখি¶
১টা ইনপুট লেয়ার, ১টা নিউরন, ১টা আউটপুট
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_dim=2, activation='tanh'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(tf.keras.optimizers.SGD(lr=0.5), 'binary_crossentropy', metrics=['accuracy'])
result = model.fit(X_train, y_train, epochs=20, validation_split=0.1)
Train on 945 samples, validate on 105 samples Epoch 1/20 WARNING:tensorflow:From /tensorflow-2.0.0-rc2/python3.6/tensorflow_core/python/ops/nn_impl.py:183: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.where in 2.0, which has the same broadcast rule as np.where 945/945 [==============================] - 1s 1ms/sample - loss: 0.6506 - accuracy: 0.6476 - val_loss: 0.6544 - val_accuracy: 0.6381 Epoch 2/20 945/945 [==============================] - 0s 66us/sample - loss: 0.6435 - accuracy: 0.6582 - val_loss: 0.6544 - val_accuracy: 0.6381 Epoch 3/20 945/945 [==============================] - 0s 59us/sample - loss: 0.6439 - accuracy: 0.6582 - val_loss: 0.6560 - val_accuracy: 0.6381 Epoch 4/20 945/945 [==============================] - 0s 66us/sample - loss: 0.6433 - accuracy: 0.6582 - val_loss: 0.6539 - val_accuracy: 0.6381 Epoch 5/20 945/945 [==============================] - 0s 61us/sample - loss: 0.6422 - accuracy: 0.6582 - val_loss: 0.6535 - val_accuracy: 0.6381 Epoch 6/20 945/945 [==============================] - 0s 90us/sample - loss: 0.6430 - accuracy: 0.6582 - val_loss: 0.6551 - val_accuracy: 0.6381 Epoch 7/20 945/945 [==============================] - 0s 71us/sample - loss: 0.6407 - accuracy: 0.6582 - val_loss: 0.6505 - val_accuracy: 0.6381 Epoch 8/20 945/945 [==============================] - 0s 63us/sample - loss: 0.6351 - accuracy: 0.6582 - val_loss: 0.6458 - val_accuracy: 0.6381 Epoch 9/20 945/945 [==============================] - 0s 60us/sample - loss: 0.6225 - accuracy: 0.6582 - val_loss: 0.6180 - val_accuracy: 0.6381 Epoch 10/20 945/945 [==============================] - 0s 60us/sample - loss: 0.5999 - accuracy: 0.6466 - val_loss: 0.5931 - val_accuracy: 0.6381 Epoch 11/20 945/945 [==============================] - 0s 62us/sample - loss: 0.5808 - accuracy: 0.6582 - val_loss: 0.5776 - val_accuracy: 0.6381 Epoch 12/20 945/945 [==============================] - 0s 56us/sample - loss: 0.5644 - accuracy: 0.6212 - val_loss: 0.5599 - val_accuracy: 0.6381 Epoch 13/20 945/945 [==============================] - 0s 59us/sample - loss: 0.5542 - accuracy: 0.6466 - val_loss: 0.5478 - val_accuracy: 0.6381 Epoch 14/20 945/945 [==============================] - 0s 56us/sample - loss: 0.5443 - accuracy: 0.5958 - val_loss: 0.5449 - val_accuracy: 0.6381 Epoch 15/20 945/945 [==============================] - 0s 60us/sample - loss: 0.5408 - accuracy: 0.6328 - val_loss: 0.5355 - val_accuracy: 0.6381 Epoch 16/20 945/945 [==============================] - 0s 56us/sample - loss: 0.5347 - accuracy: 0.5873 - val_loss: 0.5313 - val_accuracy: 0.4476 Epoch 17/20 945/945 [==============================] - 0s 58us/sample - loss: 0.5318 - accuracy: 0.5884 - val_loss: 0.5291 - val_accuracy: 0.6381 Epoch 18/20 945/945 [==============================] - 0s 60us/sample - loss: 0.5307 - accuracy: 0.6159 - val_loss: 0.5268 - val_accuracy: 0.6381 Epoch 19/20 945/945 [==============================] - 0s 63us/sample - loss: 0.5262 - accuracy: 0.6529 - val_loss: 0.5245 - val_accuracy: 0.6381 Epoch 20/20 945/945 [==============================] - 0s 57us/sample - loss: 0.5248 - accuracy: 0.6095 - val_loss: 0.5244 - val_accuracy: 0.6381
অ্যাক্যুরেসি প্লটিং দেখি¶
pd.DataFrame(result.history).plot(ylim=(-0.05, 1.05))
<matplotlib.axes._subplots.AxesSubplot at 0x7fadbe9aa358>

ডিসিশন বাউন্ডারি কি ঠিক হলো?¶
hticks = np.linspace(-2, 2, 101)
vticks = np.linspace(-2, 2, 101)
aa, bb = np.meshgrid(hticks, vticks)
ab = np.c_[aa.ravel(), bb.ravel()]
c = model.predict(ab)
cc = c.reshape(aa.shape)
ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')
ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)
<matplotlib.contour.QuadContourSet at 0x7fadb498f198>

model = tf.keras.models.Sequential([
tf.keras.layers.Dense(4, input_dim=2, activation='tanh'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(tf.keras.optimizers.SGD(lr=0.5), 'binary_crossentropy', metrics=['accuracy'])
h = model.fit(X_train, y_train, epochs=20, validation_split=0.1)
Train on 945 samples, validate on 105 samples Epoch 1/20 945/945 [==============================] - 1s 640us/sample - loss: 0.6562 - accuracy: 0.5937 - val_loss: 0.6172 - val_accuracy: 0.6381 Epoch 2/20 945/945 [==============================] - 0s 60us/sample - loss: 0.5760 - accuracy: 0.6571 - val_loss: 0.5294 - val_accuracy: 0.6381 Epoch 3/20 945/945 [==============================] - 0s 62us/sample - loss: 0.4803 - accuracy: 0.8138 - val_loss: 0.4245 - val_accuracy: 0.9238 Epoch 4/20 945/945 [==============================] - 0s 67us/sample - loss: 0.3789 - accuracy: 0.9429 - val_loss: 0.3197 - val_accuracy: 0.9810 Epoch 5/20 945/945 [==============================] - 0s 55us/sample - loss: 0.2817 - accuracy: 0.9884 - val_loss: 0.2379 - val_accuracy: 0.9905 Epoch 6/20 945/945 [==============================] - 0s 64us/sample - loss: 0.2037 - accuracy: 0.9989 - val_loss: 0.1719 - val_accuracy: 1.0000 Epoch 7/20 945/945 [==============================] - 0s 63us/sample - loss: 0.1492 - accuracy: 1.0000 - val_loss: 0.1312 - val_accuracy: 1.0000 Epoch 8/20 945/945 [==============================] - 0s 53us/sample - loss: 0.1146 - accuracy: 1.0000 - val_loss: 0.1045 - val_accuracy: 1.0000 Epoch 9/20 945/945 [==============================] - 0s 63us/sample - loss: 0.0919 - accuracy: 1.0000 - val_loss: 0.0858 - val_accuracy: 1.0000 Epoch 10/20 945/945 [==============================] - 0s 59us/sample - loss: 0.0766 - accuracy: 1.0000 - val_loss: 0.0722 - val_accuracy: 1.0000 Epoch 11/20 945/945 [==============================] - 0s 61us/sample - loss: 0.0651 - accuracy: 1.0000 - val_loss: 0.0630 - val_accuracy: 1.0000 Epoch 12/20 945/945 [==============================] - 0s 60us/sample - loss: 0.0569 - accuracy: 1.0000 - val_loss: 0.0549 - val_accuracy: 1.0000 Epoch 13/20 945/945 [==============================] - 0s 61us/sample - loss: 0.0502 - accuracy: 1.0000 - val_loss: 0.0488 - val_accuracy: 1.0000 Epoch 14/20 945/945 [==============================] - 0s 61us/sample - loss: 0.0449 - accuracy: 1.0000 - val_loss: 0.0442 - val_accuracy: 1.0000 Epoch 15/20 945/945 [==============================] - 0s 59us/sample - loss: 0.0407 - accuracy: 1.0000 - val_loss: 0.0400 - val_accuracy: 1.0000 Epoch 16/20 945/945 [==============================] - 0s 60us/sample - loss: 0.0371 - accuracy: 1.0000 - val_loss: 0.0366 - val_accuracy: 1.0000 Epoch 17/20 945/945 [==============================] - 0s 56us/sample - loss: 0.0341 - accuracy: 1.0000 - val_loss: 0.0338 - val_accuracy: 1.0000 Epoch 18/20 945/945 [==============================] - 0s 60us/sample - loss: 0.0315 - accuracy: 1.0000 - val_loss: 0.0315 - val_accuracy: 1.0000 Epoch 19/20 945/945 [==============================] - 0s 57us/sample - loss: 0.0294 - accuracy: 1.0000 - val_loss: 0.0292 - val_accuracy: 1.0000 Epoch 20/20 945/945 [==============================] - 0s 55us/sample - loss: 0.0274 - accuracy: 1.0000 - val_loss: 0.0274 - val_accuracy: 1.0000
একটা কনফিউশন ম্যাট্রিক্স তৈরি করি¶
from sklearn.metrics import confusion_matrix, classification_report
y_pred = model.predict_classes(X_test)
cm = confusion_matrix(y_test, y_pred)
pd.DataFrame(cm,
index=["Miss", "Hit"],
columns=['pred_Miss', 'pred_Hit'])
| pred_Miss | pred_Hit | |
|---|---|---|
| Miss | 311 | 0 |
| Hit | 0 | 139 |
train_score = model.evaluate(X_train, y_train, verbose=0)[1]
test_score = model.evaluate(X_test, y_test, verbose=0)[1]
print("""Accuracy scores:
Train:\t{:0.3}
Test:\t{:0.3}""".format(train_score, test_score))
Accuracy scores: Train: 1.0 Test: 1.0
নতুন ডিসিশন বাউন্ডারি, অল্প লেয়ারেই¶
hticks = np.linspace(-2, 2, 101)
vticks = np.linspace(-2, 2, 101)
aa, bb = np.meshgrid(hticks, vticks)
ab = np.c_[aa.ravel(), bb.ravel()]
c = model.predict(ab)
cc = c.reshape(aa.shape)
ax = df.plot(kind='scatter', c='target', x='lat', y='lon', cmap='bwr')
ax.contourf(aa, bb, cc, cmap='bwr', alpha=0.5)
<matplotlib.contour.QuadContourSet at 0x7fadb58f3e10>
