UNdata Informal API¶
The UNdata website offers an official API but it doesn't look overly welcoming to someone not versed in the XML protocol it supports. So here's a hacked solution based on scraping a websearch that let's you search the site for datasets, and then download the one you want as a zipped CSV file that gets automatically parsed into a pandas dataframe.
The UN data search form lets you download data directly from the results page:
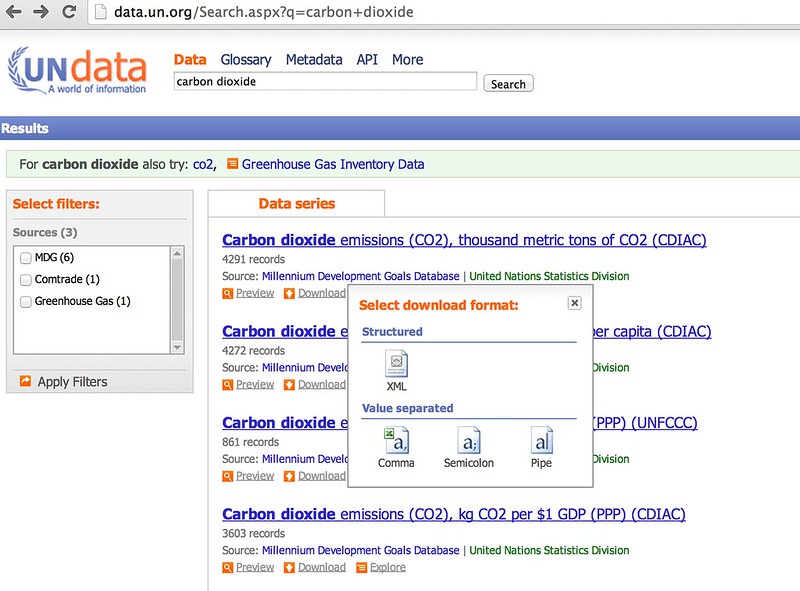
So let's write a simple scraper to grab the results and see if you can download a selected ata file automatically...
If we View Source on the results page we can look for the individual results items - and see what we neeed to parse out.

We also need to have a look at what form the HTTP request for a data download looks like to make sure we get what we need when we do scrape the results...
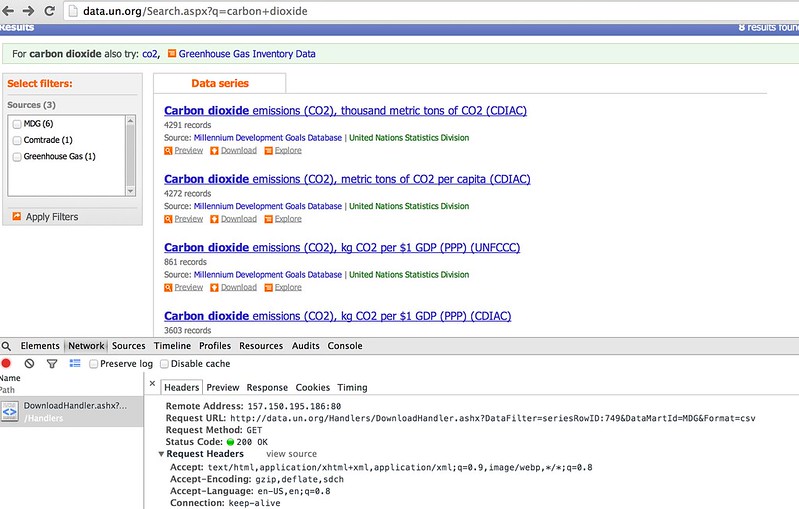
#Load in some libraries to handle the web page requests and the web page parsing...
import requests
#You may need to install BeautifulSoup
#!pip3 install beautifulsoup4
from bs4 import BeautifulSoup
#Note - I'm in Python3
from urllib.parse import parse_qs
#The scraper will be limited to just the first results page...
def searchUNdata(q):
''' Run a search on the UN data website and scrape the results '''
params={'q':q}
url='http://data.un.org/Search.aspx'
response = requests.get(url,params=params)
soup=BeautifulSoup(response.content)
results={}
#Get the list of results
searchresults=soup.findAll('div',{'class':'Result'})
#For each result, parse out the name of the dataset, the datamart ID and the data filter ID
for result in searchresults:
h2=result.find('h2')
#We can find everything we need in the <a> tag...
a=h2.find('a')
p=parse_qs(a.attrs['href'])
results[a.text]=(p['d'][0],p['f'][0])
return results
#A couple of helper functions to let us display the results
results=searchUNdata('carbon dioxide')
def printResults(results):
''' Nicely print the search results '''
for result in results.keys():
print(result)
def unDataSearch(q):
''' Simple function to take a search phrase, run the search on the UN data site, and print and return the results. '''
results=searchUNdata(q)
printResults(results)
return results
printResults(results)
#q='carbon dioxide'
#unDataSearch(q)
Carbon dioxide emissions (CO2), metric tons of CO2 per capita (CDIAC) Carbon dioxide emissions (CO2), thousand metric tons of CO2 (UNFCCC) Carbon dioxide emissions (CO2), kg CO2 per $1 GDP (PPP) (CDIAC) Carbon dioxide (CO2) Emissions without Land Use, Land-Use Change and Forestry (LULUCF), in Gigagrams (Gg) Carbon dioxide emissions (CO2), thousand metric tons of CO2 (CDIAC) Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC) Carbon dioxide emissions (CO2), kg CO2 per $1 GDP (PPP) (UNFCCC) Trade of goods , US$, HS 1992, 28 Inorganic chemicals, precious metal compound, isotope
#Just in case - a helper routine for working with the search results data
def search(d, substr):
''' Partial string match search within dict key names '''
#via http://stackoverflow.com/a/10796050/454773
result = []
for key in d:
if substr.lower() in key.lower():
result.append((key, d[key]))
return result
search(results, 'per capita')
[('Carbon dioxide emissions (CO2), metric tons of CO2 per capita (CDIAC)',
('MDG', 'seriesRowID:751')),
('Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC)',
('MDG', 'seriesRowID:752'))]
#Note - I'm in Python3
from io import BytesIO
import zipfile
import pandas as pd
def getUNdata(undataSearchResults,dataset):
''' Download a named dataset from the UN Data website and load it into a pandas dataframe '''
datamartID,seriesRowID=undataSearchResults[dataset]
url='http://data.un.org/Handlers/DownloadHandler.ashx?DataFilter='+seriesRowID+'&DataMartId='+datamartID+'&Format=csv'
r = requests.get(url)
s=BytesIO(r.content)
z = zipfile.ZipFile(s)
#Show the files in the zip file
#z.namelist()
#Let's assume we just get one file per zip...
#Drop any all blank columns
df=pd.read_csv( BytesIO( z.read( z.namelist()[0] ) )).dropna(axis=1,how='all')
return df
results=unDataSearch('carbon dioxide')
Carbon dioxide emissions (CO2), metric tons of CO2 per capita (CDIAC) Carbon dioxide emissions (CO2), thousand metric tons of CO2 (UNFCCC) Carbon dioxide emissions (CO2), kg CO2 per $1 GDP (PPP) (CDIAC) Carbon dioxide (CO2) Emissions without Land Use, Land-Use Change and Forestry (LULUCF), in Gigagrams (Gg) Carbon dioxide emissions (CO2), thousand metric tons of CO2 (CDIAC) Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC) Carbon dioxide emissions (CO2), kg CO2 per $1 GDP (PPP) (UNFCCC) Trade of goods , US$, HS 1992, 28 Inorganic chemicals, precious metal compound, isotope
dd=getUNdata(results,'Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC)')
#Preview the last few rows
dd[-5:]
| Country or Area | Year | Value | Value Footnotes | Value Footnotes.1 | |
|---|---|---|---|---|---|
| 922 | United States | 1991 | 19.357277 | 1 | 1 |
| 923 | United States | 1990 | 19.746756 | 1 | 1 |
| 924 | NaN | NaN | NaN | NaN | NaN |
| 925 | footnoteSeqID | Footnote | NaN | NaN | NaN |
| 926 | 1 | For Denmark, France, United Kingdom and United... | NaN | NaN | NaN |
#One thing to note is that footnotes may appear at the bottom of a dataframe
#We can spot the all empty row and drop rows from that
#We can also drop the footnote related columns
def dropFootnotes(df):
return df[:pd.isnull(dd).all(1).nonzero()[0][0]].drop(['Value Footnotes','Value Footnotes.1'], 1)
dropFootnotes(dd)[-5:]
| Country or Area | Year | Value | |
|---|---|---|---|
| 919 | United States | 1994 | 19.903438 |
| 920 | United States | 1993 | 19.788616 |
| 921 | United States | 1992 | 19.568633 |
| 922 | United States | 1991 | 19.357277 |
| 923 | United States | 1990 | 19.746756 |
#Create a function that automatically drops the footnotes and any empty rows
def getUNdata2(undataSearchResults, dataset, footnotes=False):
df=getUNdata(undataSearchResults, dataset)
if footnotes:
return df
return dropFootnotes(df)
getUNdata2(results,'Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC)')[-5:]
| Country or Area | Year | Value | |
|---|---|---|---|
| 919 | United States | 1994 | 19.903438 |
| 920 | United States | 1993 | 19.788616 |
| 921 | United States | 1992 | 19.568633 |
| 922 | United States | 1991 | 19.357277 |
| 923 | United States | 1990 | 19.746756 |
getUNdata2(results,'Carbon dioxide emissions (CO2), metric tons of CO2 per capita (UNFCCC)',footnotes=True)[-5:]
| Country or Area | Year | Value | Value Footnotes | Value Footnotes.1 | |
|---|---|---|---|---|---|
| 922 | United States | 1991 | 19.357277 | 1 | 1 |
| 923 | United States | 1990 | 19.746756 | 1 | 1 |
| 924 | NaN | NaN | NaN | NaN | NaN |
| 925 | footnoteSeqID | Footnote | NaN | NaN | NaN |
| 926 | 1 | For Denmark, France, United Kingdom and United... | NaN | NaN | NaN |
Summary¶
This notebook demonstrates a simple, informal scraper based API to the UN data website. Searches can be run on the UN data website to obtain a list of named datasets, and then a specified named dataset can be automatically downloaded into a pandas dataframe.