Training/Validation/Test¶
When creating our model, note that we have 3 sets:
- The training set
- The validation set
- The test set
The training set is used with stochastic gradient descent to train the various weights within the network.
The test set is used to check how good our model is -- can it correctly identify data it hasn't seen before?
But what about the validation set?
Fast.ai tells us the validation set is used to determine what kind of model to use, but let's dig deeper.
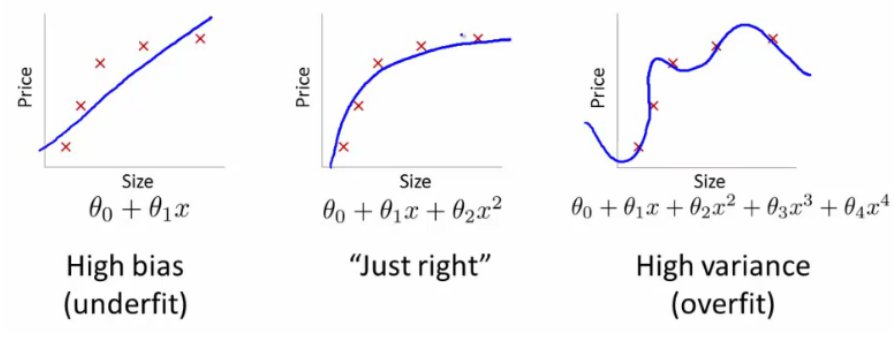
We must go back to the concept of underfitting and overfitting.
Thinking of it like linear regression, if a model is underfitting, it would be like there was a straight line going through the data points, but the line is a bit to general to accurately predict future data points.
If a model is overfitting, it is like the line hits all of the data points exactly. This might seem fine, but the line would be so random that it wouldn't be able to predict any new, unseen data.
(Reminder: You can check if your model is overfitting because the training loss will be a lot lower than the validation loss.)
What you want is a line that is just right. That is, it goes through the data points pretty closely, but there is still a pattern to the line, so you can use it to predict future data.
The problem with just using training sets and test sets is that we might end up overfitting to to the test set as well.
What we want to do is test on data we've never seen before.
So we take a random 20% of the training set, and make that our validation set. That way we ensure we test against a random 20% each time. Also, we might not have the answers for the test set -- the whole point is that it's unseen data. But since the validation set comes from the training set, we know what it's meant to be.
Dropout¶
When we are using a pretrained convolutional neural network (CNN), and we add a new layer to it, we are actually adding several new layers. After declaring your pretrained net as learn = ..., you can type learn to see which layers it added. By default tey will look like this:
- BatchNorm1d: Covered later
- Dropout
- Linear: Does matrix multiplication -- takes the output from a convolution layer as input, and outputs to the number of classes
- ReLU: Gets rid of -ves
- BatchNorm1d
- Dropout
- Linear
- LogSoftmax: The softmax layer to get a prediction (it uses log just for numerical accuracy sake)
from fastai.conv_learner import *
PATH="data/dogbreed/"
size=224
architecture=resnext101_64
batch_size=58
label_csv = f'{PATH}labels.csv'
# num of rows -1 (to account for the header)
n = len(list(open(label_csv)))-1
# random 20% of rows to use as the validation set
# get cross validation indexes
val_idxs = get_cv_idxs(n)
# We're going to use data augmentation, so let's set up our transforms
transforms = tfms_from_model(architecture, size, aug_tfms=transforms_side_on, max_zoom=1.1)
# Convenience method
def get_data(size, batch_size):
transforms = tfms_from_model(architecture, size, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, 'train', f'{PATH}labels.csv', test_name='test', num_workers=4,
val_idxs=val_idxs, suffix='.jpg', tfms=transforms, bs=batch_size)
return data if size>300 else data.resize(340, 'tmp')
data = get_data(size, batch_size)
learn = ConvLearner.pretrained(architecture, data, precompute=True)
Failed to display Jupyter Widget of type HBox.
If you're reading this message in the Jupyter Notebook or JupyterLab Notebook, it may mean that the widgets JavaScript is still loading. If this message persists, it likely means that the widgets JavaScript library is either not installed or not enabled. See the Jupyter Widgets Documentation for setup instructions.
If you're reading this message in another frontend (for example, a static rendering on GitHub or NBViewer), it may mean that your frontend doesn't currently support widgets.
learn
Sequential( (0): BatchNorm1d(4096, eps=1e-05, momentum=0.1, affine=True) (1): Dropout(p=0.25) (2): Linear(in_features=4096, out_features=512) (3): ReLU() (4): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True) (5): Dropout(p=0.5) (6): Linear(in_features=512, out_features=120) (7): LogSoftmax() )
What is the dropout layer doing?
Essentially, if we set p (probability) = 0.5, it just goes through all of the activations in our filtered image and for each activation, there is a 50% change we just drop it. I.e., we get rid of 50% of the activation.
We keep roughly the same shape, and the other activations are doubled to to keep the average activation the same. So why perform dropout?
Simply, it stops the data from overfitting. By randomly dropping a certain number of activations, we ensure our data is always a little different, and so we stop overfitting. It's making the activations more random, solves the generalization problem.

The default dropout probabilities (ps) should work well, but if it's overfitting you can try bumping them up, and vice versa.
# We can set the probability dropout for different layers like this
learn = ConvLearner.pretrained(architecture, data, ps=[0.], precompute=True)