What is this?¶
There are many topics in the Open Digital Archaeology Text for which there are supporting 'Jupyter Notebooks'. What you are looking at right now is one such notebook.
These notebooks mix explanatory text with chunks of code. Generally, each notebook is structured so that each code block depends on the one before having been run. You progress through these from top to bottom. By having explanations mixed in with the code, you learn what the code does, what to expect, or why it's framed the way it is. This is called 'literate programming'.
Each of our notebooks are contined in a Github repository. We use the Binder service to launch these notebooks online in a computing environment that contains all the necessary software that you'll need to work through the notebooks. Look for the
![]()
... and click on it!
Warning: Currently, Binder will time-out after ten minutes of inactivity, and you will lose any changes. Work does not persist between sessions
Run these notebooks on your own machine¶
You can download these repositories to your own computer, if you like (there is a green 'download' button for each repository on Github). You will then need to install Jupyter for your computer. If you have Git installed on your computer you can download via the command line or terminal prompt:
$ git clone https://github.com/o-date/notebooks.git # change this line as appropriate, right?
$ cd notebooks
$ jupyter notebook
How do I work through a notebook?¶
In the toolbar across the top, the most important button for the time being is the 'run' button. Click on the cellblock below so that a box appears around it, and hit 'Run'.
2 + 2
Notice what happened - the notebook calculated the result of the equation, and created a new block with the answer! While the block was running, an asterisk also appeared at the left hand side of the block, like so: In [*]. Once the calculation finished, the notebook will put a number within those square brackets, eg In [1] so that you know the order in which you've run the blocks. Now, 2 + 2 is a trivial calculation, and happened so fast that you probably didn't even spot the [*]. Sometimes, it can take quite a lot of time for the block to run. Watch for that asterisk! You will get errors if you run subsequent code blocks that depend on the results of an earlier calculation!
When things go wrong¶
If things go wrong, the notebook will output a message in red text. Read these carefully - sometimes they are merely warnings that some underlying software is not the most up-to-date version; more often you may have neglected to finish (or perform) a necessary earlier step. If worse comes to worse, copy and paste the text of the error into a search engine; you may be able to work out what has gone wrong and solve it yourself!
What language is the notebook using?¶
That is a very good question. If you look at the top right of the screen, you'll see that it says Python 3. This is known as the 'kernel'. Generally, for any notebook that we provide to you, we have already loaded up the necessary language interpreters - the kernels - that you will need. If you're running a notebook on your own machine, you can install other kernels as necessary. You can even mix languages inside a notebook! We don't do that in ODATE but you can find how to do so easily enough with a search. Stackoverflow is very useful in this regard.
Running a command for the terminal inside a notebook¶
Sometimes, you might like to run a command for the terminal as part of your work. If you click on the 'jupyter' icon at the top left, you can start a terminal prompt:

This is a screenshot from Shawn's computer - he has several kernels installed - but you can see where the terminal prompt can be found. Starting a new terminal will open a new tab in your browser and you will be presented with a terminal prompt. You can enter command line commands there.
You can also do this inside a notebook, however. Try running the codeblocks below:
!pwd
!ls
The ! character tells the notebook to pass the command to the terminal, and print the response. This can be handy, as sometimes perhaps you might want to install a 'package' (a bundle of pre-made functions that extend what you can do) for Python using the pip command:
!pip install requests
Making Changes¶
You can add new blocks by clicking the + button in the toolbar ribbon. These will appear underneath whatever block you currently have highlighted. You can move the block up or down on the page relative to the other blocks by hitting the up and down arrows on the toolbar ribbon. Similarly you can cut or copy codeblocks by highlighting them then hitting the scissors or paste icons. If you double-click inside a block, you can edit the code or text. The kind of block you are dealing with will be indicated in the dropdown menu in the ribbon - code, markdown, heading, and so on. If you are just adding text (perhaps you are keeping track of your observations and thoughts!) select Markdown. Markdown lets you add links, images, make headings, bullet points quite easily - here are the basics of Markdown. In the block below, add some Markdown, then save this notebook to your computer.
Saving your work¶
If you are making changes or experimenting with our notebooks, by all means, save your work. If you hit the 'save' icon in the top ribbon, the notebook will save - but if you're running the notebook via our Binder (eg, it's online), when you quit your saved work will not be there. In that case, use the download as option under file and choose 'notebook':
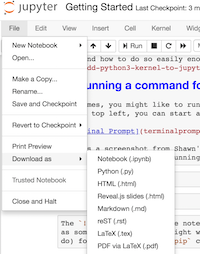
Finishing Up¶
Sometimes the code will create a number of files of output. To find these, remember that you can always list ls the contents of the directory you are working with. If you click on the Jupyter logo at the top left of the notebook, you will be taken to the home page for your work. Any running notebooks or open files will be listed in green. You can select files by ticking off the check box beside them, and then either 'stop' or 'download' or 'remove' files as you wish. If you hit the 'logout' button at top right and you are running one of our notebooks from Binder, you will shut the notebook down and lose whatever work has not been saved directly to your own computer.
Explore!¶
So, hit the Jupyter icon, and examine the list of files. Notebook files carry the ipynb file extension. Click, and explore! The R scripts should be run from RStudio - From the Home page for this binder, select new -> RStudio. Then open the Extracting Data from PDFs using Tabulizer.R file.