Abstract: This lecture will look at the changes in hardware that enabled neural networks to be efficient and how neural network models are deployed on hardware.
DeepNN¶
Plan for the Day¶
- Introduction
- How did we get here?
- Hardware Foundation
- Parallelism Leveraging
- Data Movement and Bandwidth Pressures
- Closing messages
Hardware at Deep Learning's birth¶
|
New York Times (1958) |
Eniac, 1950s SoTA Hardware |

|

|
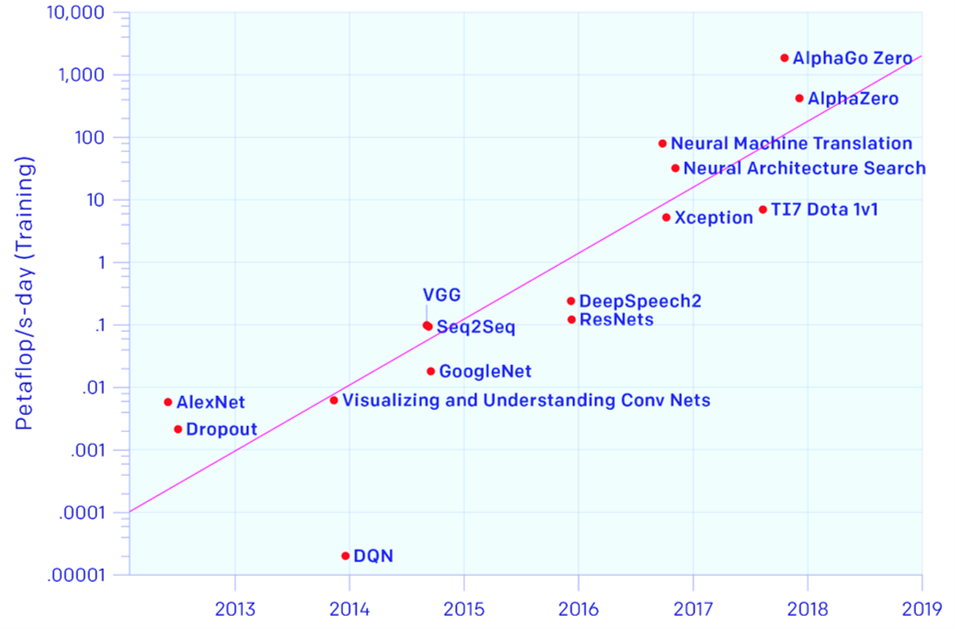
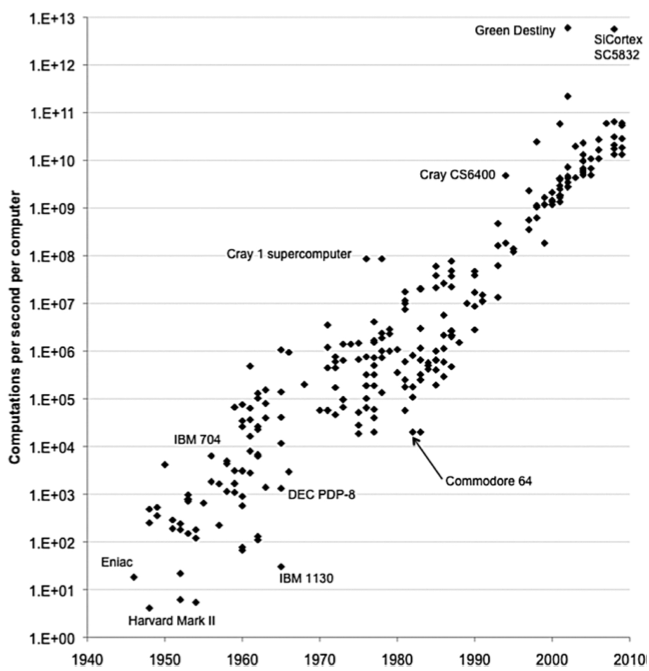
How did we get here? Deep Learning requires peta FLOPS¶
0.01 PFLOP (left) = $10^{13}$ FLOPS (right)
|
|
Credit: Our World in Data
Plan for the Day¶
- Introduction
- Hardware Foundation
- Internal organisation of processors
- A typical organisation of a DL system
- Two pillars: Data Movement & Parallelism
- Parallelism Leveraging
- Data Movement and Bandwidth Pressures
- Closing messages
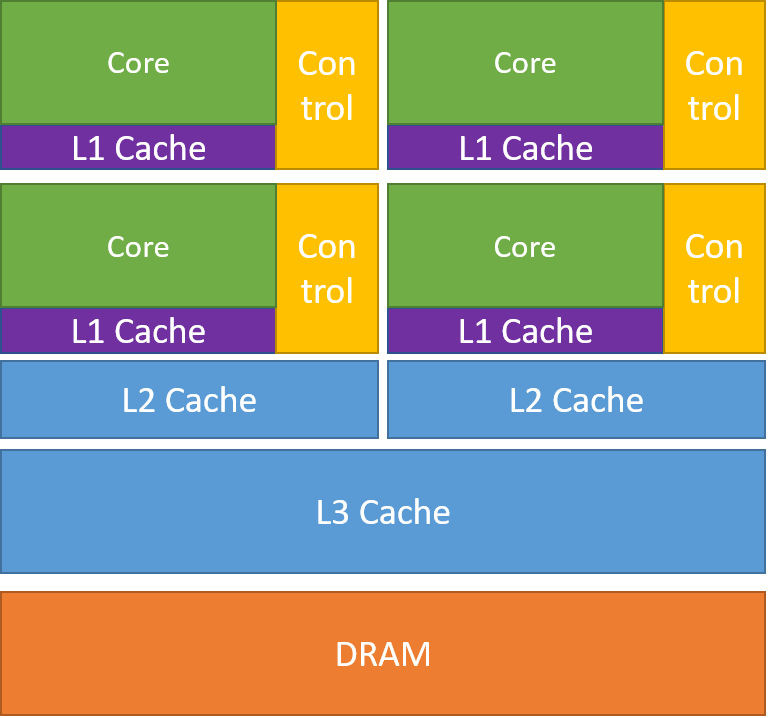
Internal Organisation of Processors¶

|

|

|
Central Processing Unit (CPU)¶
|
|
from custom_imports import *
our_custom_net = BasicFCModel()
our_custom_net.cpu()
# OR
device = torch.device('cpu')
our_custom_net.to(device)
Graphics Processing Unit¶
| ` `{=html}
if torch.cuda.is_available():
our_custom_net.cuda()
# OR
device = torch.device('cuda:0')
our_custom_net.to(device)
# Remember to do the same for all inputs to the network
Graphics Processing Unit¶
| ` `{=html}
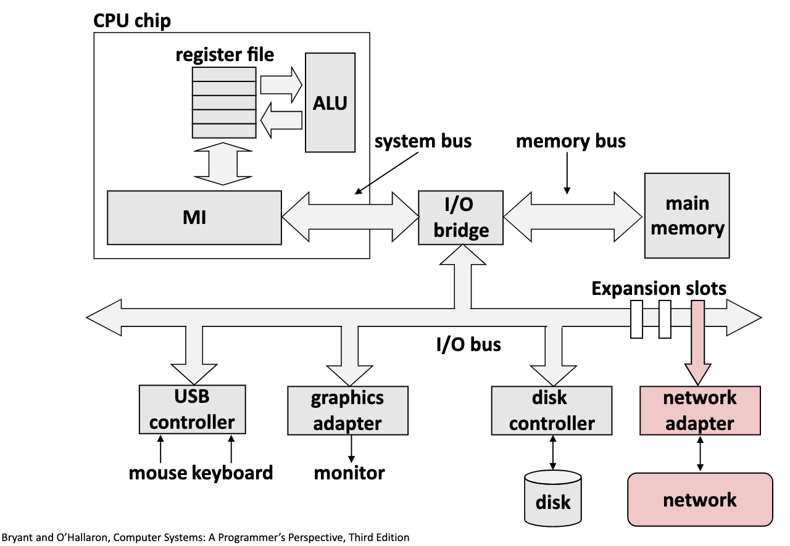
A typical organisation of a DL system¶
|
|
Data Movement & Parallelism¶
Memory and bandwidth: memory hierarchy¶
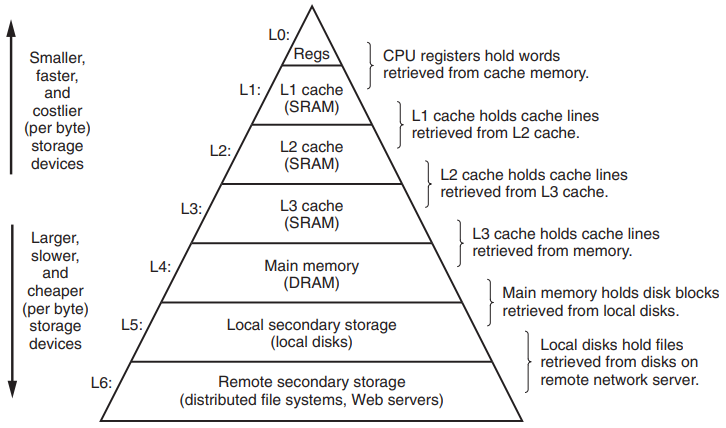
Memory and bandwidth: data movement¶
- Energy and latency are commensurate
- Accessing RAM is 3 to 4 orders of magnitude slower than executing MAC

Processor comparison based on memory and bandwidth¶
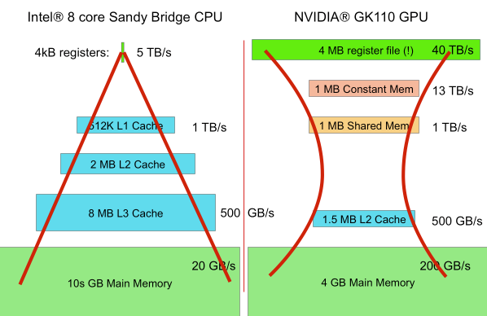
- CPU has faster I/O bus than GPU, but it has lower bandwidth than
GPU.
CPU can fetch small pieces of data very fast, GPU fetches them slower but in bulk. - GPU has more lower-level memory than CPU.
Even though each individual thread and thread block have less memory than the CPU threads and cores do, there are just so much more threads in the GPU that taken as a whole they have much more lower-level memory. This is memory inversion.
The case for parallelism - Moore's law is slowing down¶
- Moore's law fuelled the prosperity of the past 50 years.
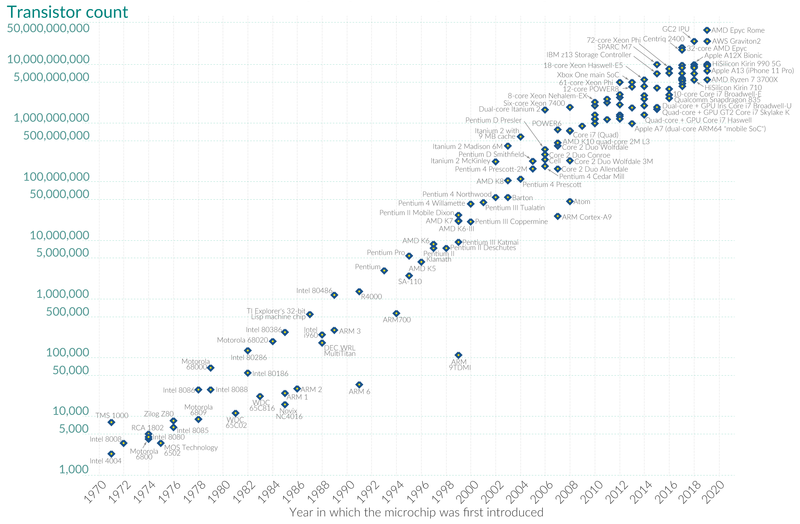
Credit: Our World in Data
Plan for the Day¶
- Introduction
- Hardware Foundation
- Parallelism Leveraging
- Parallelism in Deep Learning
- Leveraging Deep Learning parallelism
- Data Movement and Bandwidth Pressures
- Closing messages
The case for parallelism - Moore’s law is slowing down¶
- As it slows, programmers and hardware designers are searching for alternative drivers of performance growth.
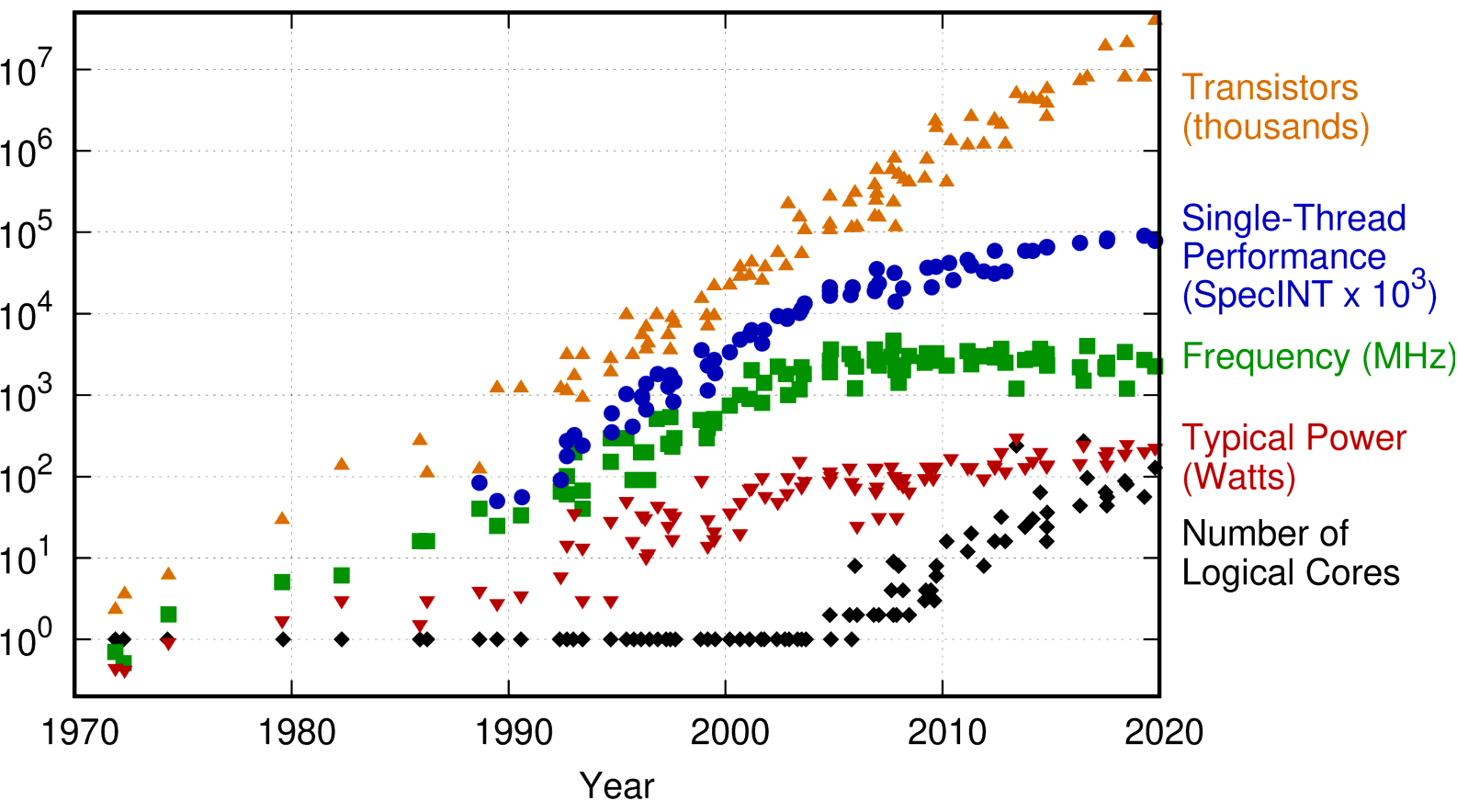
Credit: Karl Rupp
Processor comparison based on parallelism¶
print("CPU matrix multiplication")
a, b = [torch.rand(2**10, 2**10) for _ in range(2)]
start = time()
a * b
print(f'CPU took {time() - start} seconds')
print("GPU matrix multiplication")
start = time()
a * b
print(f'GPU took {time() - start} seconds')
CPU matrix multiplication
CPU took 0.0005156993865966797 seconds
GPU matrix multiplication
GPU took 0.0002989768981933594 seconds
Plan for the Day¶
- Introduction
- Hardware Foundation
- Parallelism Leveraging
- Parallelism in Deep Learning
- Leveraging Deep Learning parallelism
- Data Movement and Bandwidth Pressures
- Closing messages
Parallelism in Deep Learning training¶
- Minibatch model update:
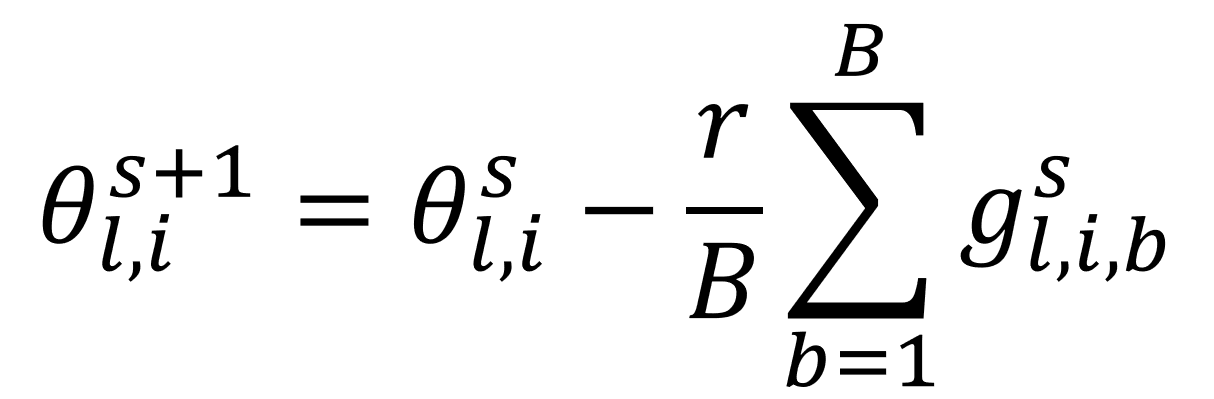
- where $\theta^{s}_{l,i}$ is an $i$'s parameter at layer $l$ value at step $s$ of the training process; $r$ is the learning rate; $B$ is the batch size; and $g^{s}_{l,i,b}$ is the $s$-th training step gradient coming from $b$-th training example for parameter update of $i$-th parameter at layer $l$.
DL parallelism: parallelize backprop through an example¶
- The matrix multiplications in the forward and backward passes can be parallelized:
- Fast inference is unthinkable without parallel matrix multiplication.
- Frequent synchronization is needed - at each layer the parallel threads need to sync up.
DL parallelism: parallelize gradient sample computation¶
- Gradients for individual training examples can be computed in parallel:

- Synchronization is needed only at the point where we sum the individual gradients across the batch.
DL parallelism: parallelize update iterations¶
- Gradient updates from separate batches can be computed in parallel:

- Imagine computing $N$ batches at the same time in parallel:
- We can see this as using $N-1$ outdated gradient when making update based on the second batch.
- We can see this as using $N$ gradient estimates in place of the usual $1$ that SGD is based on.
DL parallelism: parallelize the training of multiple models¶
- In the course of solving a given DL problem one would often train
competing models because of:
- The choice of hyperparameters such as architecture, initialization, dropout and learning rates, regularization, ...
- The desire to build a model ensemble.
- The models are independent of each other and thus can be computed in parallel.
Leveraging Deep Learning parallelism¶
- CPUs, GPUs, multi-GPU, and multi-machine each offer unique opportunities to leverage the four sources of parallelism.
XXXX
XXXX
XXXX
XXXX
CPU training¶
The most a CPU can do for this setup is to:
- Run through the batches sequentially
- Run through the model sequentially
- Run through the batch sequentially
- Potentially, parallelize each layer computation between its cores
- Best case scenario: individual cores can tackle separate nodes / channels as these are independent of each other
- Parallelize matrix multiplication
- Best case scenario: Matrix multiplication is split between separate cores and threads. The degree of parallelism is, however, negligent.
CPU training¶
Consequently:
- Overpowered CPU threads are scrambling to juggle the many nodes / channels they need to compute.
- The CPU is slowed down considerably by the fact that it needs to access its own L3 cache many more times than the GPU would, due to its lower memory access bandwidth.
print("CPU training code")
print("CPU training of the above-defined model short example of how long it takes")
our_custom_net.cpu()
start = time()
train(lenet, MNIST_trainloader)
print(f'CPU took {time()-start:.2f} seconds')
CPU training code
CPU training of the above-defined model short example of how long it takes
Epoch 1, iter 469, loss 1.980: : 469it [00:02, 181.77it/s]
Epoch 2, iter 469, loss 0.932: : 469it [00:02, 182.58it/s]
CPU took 5.22 seconds
GPU training¶
The GPU, on the other hand, can:
- Run through the batches sequentially
- Run through the model sequentially
- The model and the batch size just fit once in the memory of the GPU we chose.
- In the best case scenario run through the training examples in a
batch in parallel
- For most GPUs the computation is, however, sequential if their memory is not big enough to hold the entire batch of training examples.
- Parallelize each layer computation between its cores
- Groups of several cores are assigned to separate network layers / channels. Cores in the group need not be physically close to each other.
- Parallelize matrix multiplication
- The matrix multiplication needed to compute a given node / channel is split between the threads in the group that was assigned to it. Each thread computes separate sector of the input.
GPU training¶
Consequently:
- GPU cores are engaged at all times as they sequentially push through the training examples all at the same time.
- All threads need to sync-up at the end of each layer computation so that their outputs can become the inputs to the next layer.
print("GPU training")
print("GPU training of the same example as in CPU")
lenet.cuda()
batch_size = 512
gpu_trainloader = make_MNIST_loader(batch_size=batch_size)
start = time()
gpu_train(lenet, gpu_trainloader)
print(f'GPU took {time()-start:.2f} seconds')
GPU training
GPU training of the same example as in CPU
Epoch 1, iter 118, iter loss 0.786: : 118it [00:02, 52.62it/s]
Epoch 2, iter 118, iter loss 0.760: : 118it [00:02, 57.48it/s]
GPU took 4.37 seconds
GPU parallelism: matrix multiplication example¶
|
GPU 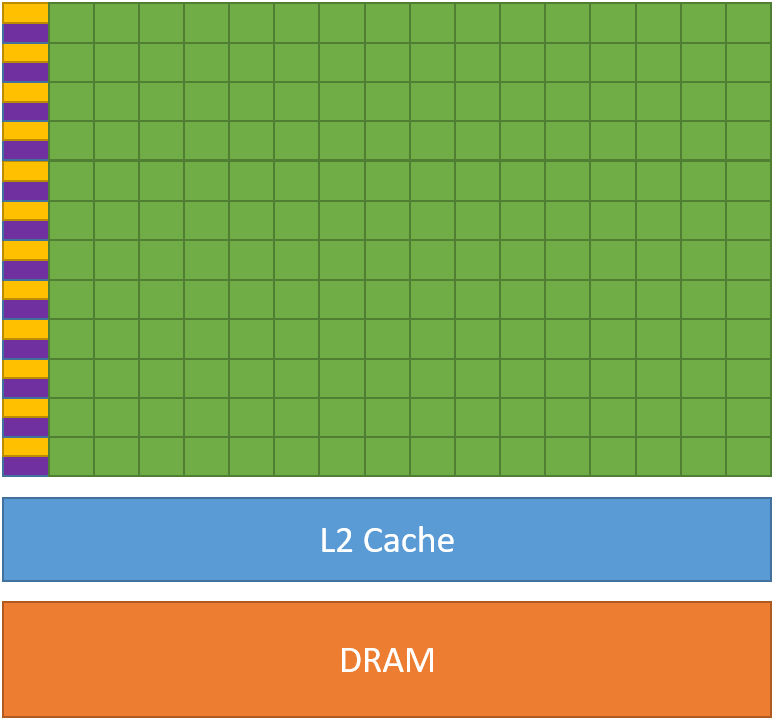
12 thread blocks, each with 16 threads. |
Naive implementation 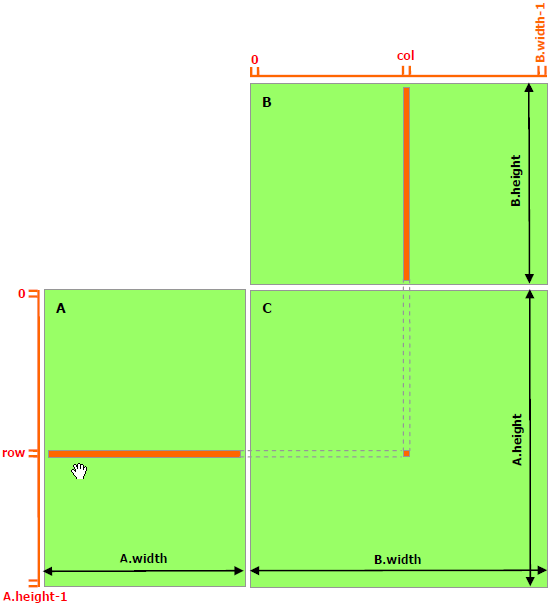
Each thread* reads one row of A, one |
Shared memory implementation 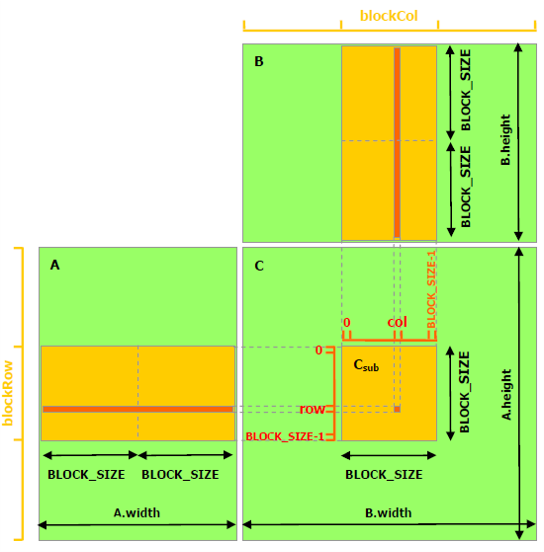
Each thread block* is computing |
GPU parallelism: matrix multiplication example¶
Multi-GPU training¶
With multiple GPUs we can choose one of the following:
- Distribute the training examples of a batch between GPUs
- When individual GPUs can not hold the whole batch in the memory, this can be distributed between multiple cards.
- The computation has to sync-up for each Batch-Norm.
- Parallelize the model computation
- Separate layers or groups of layers are handled by separate GPUs.
- Computation syncs between pairs of GPU cards - as the one's outputs are the other's inputs.
- This creates a flow-through system that will keep all GPUs busy at all times during the training.
- Batch is processed sequentially, all GPUs sync up after each batch - either dead time or outdated gradients.
- Parallelize the gradient computation
- Each GPU can be given its own batch if we accept outdated model in gradient computations.
Multi-GPU training¶
print("multi-GPU training")
print("GPU training of the same example as in single GPU but with two GPUs")
our_custom_net_dp = lenet
our_custom_net_dp.cuda()
our_custom_net_dp = nn.DataParallel(our_custom_net_dp, device_ids=[0, 1])
batch_size = 1024
multigpu_trainloader = make_MNIST_loader(batch_size=batch_size)
start = time()
gpu_train(our_custom_net_dp, multigpu_trainloader)
print(f'2 GPUs took {time()-start:.2f} seconds')
multi-GPU training
GPU training of the same example as in single GPU but with two GPUs
Epoch 1, iter 59, iter loss 0.745: : 59it [00:02, 21.24it/s]
Epoch 2, iter 59, iter loss 0.736: : 59it [00:01, 31.70it/s]
2 GPUs took 4.72 seconds
Multi-Machine training¶
In principle the same options as in multi-GPU:
- Distribute the training examples of a batch between GPUs
- This is rarely if ever needed on the scale of multi-Machine
- Parallelize the model computation
- Same principles as in multi-GPU.
- Parallelize the gradient computation
- Same principles as in multi-GPU.
In practice we would either take advantage of the latter two. In extreme examples one might do a combination of multiple options.
Parallelism summary: model and data parallelism¶
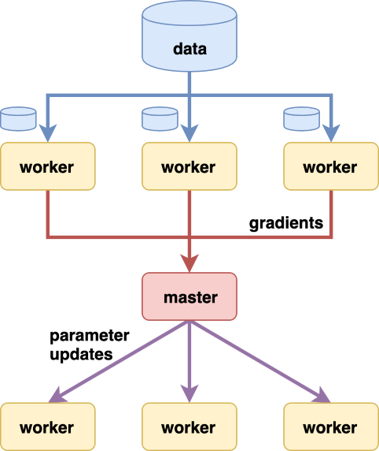
|
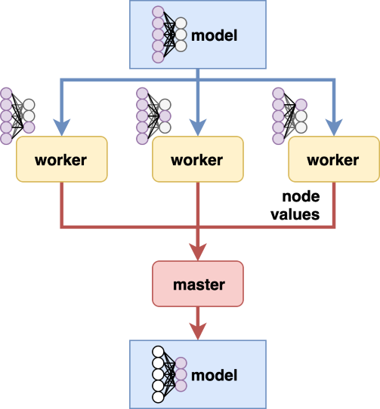
|
Parallelism bottlenecks: Synchronization & Communication¶
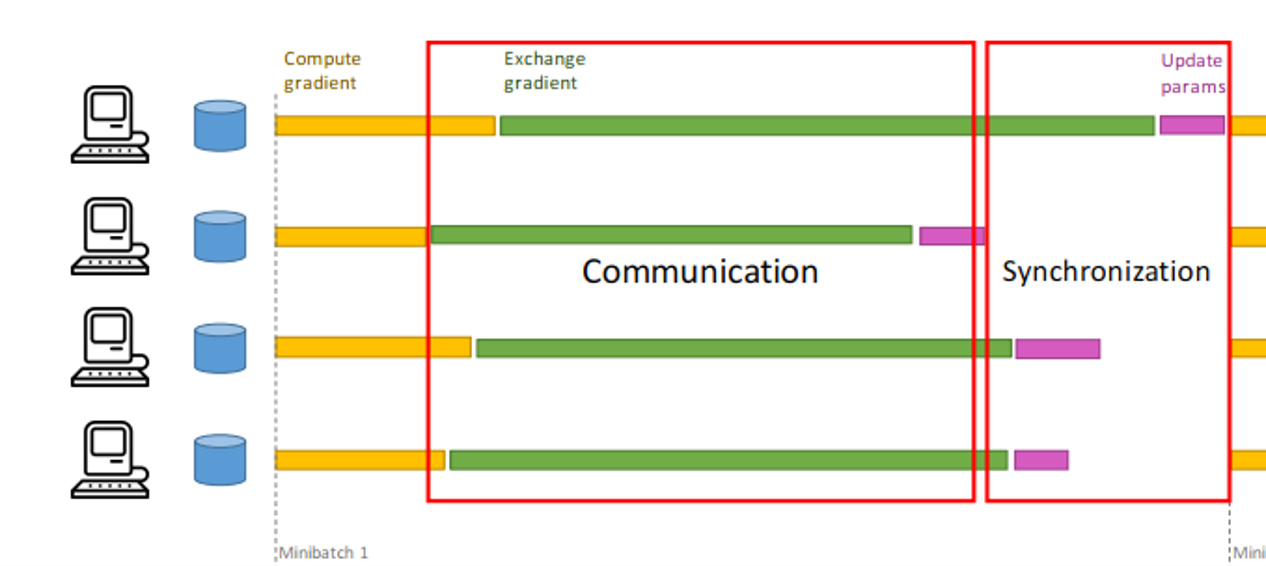
- DL-training hardware needs to synchronize and communicate very
frequently
- Model nodes are heavily interconnected at each model layer.
- Data nodes are interconnected by batch-norm-style layers
- Data nodes are interconnected at gradient computation
- This communication occurs between
- Threads in a core (CPU and GPU)
- Cores within a chip
- Pieces of hardware example: SLI bridge is a connector and a protocol for such a communication
Bottlenecks beyond parallelism¶
- DL training and inference do not take place solely on the
accelerator.
- The accelerator accelerates the gradient computations and updates.
- The CPU will still need to be loading the data (model, train set) and saving the model (checkpointing).
- The accelerator starves if it waits idly for its inputs due for example to slow CPU, I/O buses, or storage interface (SATA, SSD, NVMe).
print("starving GPUs")
print("show in-code what starving GPU looks like")
# Deliberately slow down data flow into the gpu
# Do you have any suggestions how to do this in a more realistic way than just to force waiting?
print('Using only 1 worker for the dataloader, the time the GPU takes increases.')
lenet.cuda()
batch_size = 64
gpu_trainloader = make_MNIST_loader(batch_size=batch_size, num_workers=1)
start = time()
gpu_train(lenet, gpu_trainloader)
print(f'GPU took {time()-start:.2f} seconds')
starving GPUs
show in-code what starving GPU looks like
Using only 1 worker for the dataloader, the time the GPU takes increases.
Epoch 1, iter 938, iter loss 0.699: : 938it [00:04, 214.02it/s]
Epoch 2, iter 938, iter loss 0.619: : 938it [00:04, 208.96it/s]
GPU took 8.92 seconds
Plan for the Day¶
- Introduction
- Hardware Foundation
- Parallelism Leveraging
- Data Movement and Bandwidth Pressures
- Deep Learning working set
- Mapping Deep Learning onto hardware
- Addressing memory pressure
- Closing messages
Deep Learning resource characterisation¶
print("profiling demo")
print("in-house DL training resource profiling code & output - based on the above model and training loop")
#for both of the below produce one figure for inference and one for training
#MACs profiling - first slide; show as piechard
lenet.cpu()
profile_ops(lenet, shape=(1,1,28,28))
profiling demo
in-house DL training resource profiling code & output - based on the above model and training loop
Operation OPS
------------------------------------- -------
LeNet/Conv2d[conv1]/onnx::Conv 89856
LeNet/ReLU[relu1]/onnx::Relu 6912
LeNet/MaxPool2d[pool1]/onnx::MaxPool 2592
LeNet/Conv2d[conv2]/onnx::Conv 154624
LeNet/ReLU[relu2]/onnx::Relu 2048
LeNet/MaxPool2d[pool2]/onnx::MaxPool 768
LeNet/Linear[fc1]/onnx::Gemm 30720
LeNet/ReLU[relu3]/onnx::Relu 240
LeNet/Linear[fc2]/onnx::Gemm 7200
LeNet/ReLU[relu4]/onnx::Relu 120
LeNet/Linear[fc3]/onnx::Gemm 600
LeNet/ReLU[relu5]/onnx::Relu 20
------------------------------------ ------
Input size: (1, 1, 28, 28)
295,700 FLOPs or approx. 0.00 GFLOPs
Deep Learning working set¶
- Working set - a collection of all elements needed for executing a
given DL layer
- Input and output activations
- Parameters (weights & biases)
print("working set profiling")
# compute the per-layer required memory:
# memory to load weights, to load inputs, to save oputputs
# visualize as a per-layer bar chart, each bar consists of three sections - the inputs, outputs, weights
profile_layer_mem(lenet)
working set profiling
Working Set requirement exceeding RAM¶
print("exceeding RAM+Swap demo")
print("exceeding working set experiment - see the latency spike over a couple of bytes of working set")
# sample* a training speed of a model whose layer working sets just first in the memory
# bump up layer dimensions which are far from reaching the RAM limit - see that the effect on latency is limited
# bump up the layer(s) that are at the RAM limit - observe the latency spike rapidly
# add profiling graphs for each of the cases, print out latency numbers.
# *train for an epoch or two, give the latency & give a reasonable estimate of how long would the full training take (assuming X epochs)
estimate_training_for(LeNet, 1000)
exceeding RAM+Swap demo
exceeding working set experiment - see the latency spike over a couple of bytes of working set
Using 128 hidden nodes took 2.42 seconds, training for 1000 epochs would take ~2423.7449169158936s
Using 256 hidden nodes took 2.31 seconds, training for 1000 epochs would take ~2311.570882797241s
Using 512 hidden nodes took 2.38 seconds, training for 1000 epochs would take ~2383.8846683502197s
Using 1024 hidden nodes took 2.56 seconds, training for 1000 epochs would take ~2559.4213008880615s
Using 2048 hidden nodes took 3.10 seconds, training for 1000 epochs would take ~3098.113536834717s
Using 4096 hidden nodes took 7.20 seconds, training for 1000 epochs would take ~7196.521997451782s
Using 6144 hidden nodes took 13.21 seconds, training for 1000 epochs would take ~13207.558155059814s
Working Set requirement exceeding RAM + Swap¶
print("OOM - massive images")
print("show in-code how this can hapen - say massive images; maybe show error message")
# How could we do this without affecting the recording process?
print('Loading too many images at once causes errors.')
lenet.cuda()
batch_size = 6000
gpu_trainloader = make_MNIST_loader(batch_size=batch_size, num_workers=1)
start = time()
gpu_train(lenet, gpu_trainloader)
print(f'GPU took {time()-start:.2f} seconds')
OOM - massive images
show in-code how this can hapen - say massive images; maybe show error message
Loading too many images at once causes errors.
Epoch 1, iter 10, iter loss 0.596: : 10it [00:03, 2.78it/s]
Epoch 2, iter 2, iter loss 0.592: : 2it [00:01, 1.69it/s]
Mapping Deep Models to hardware: Systolic Arrays¶
|
Core principle 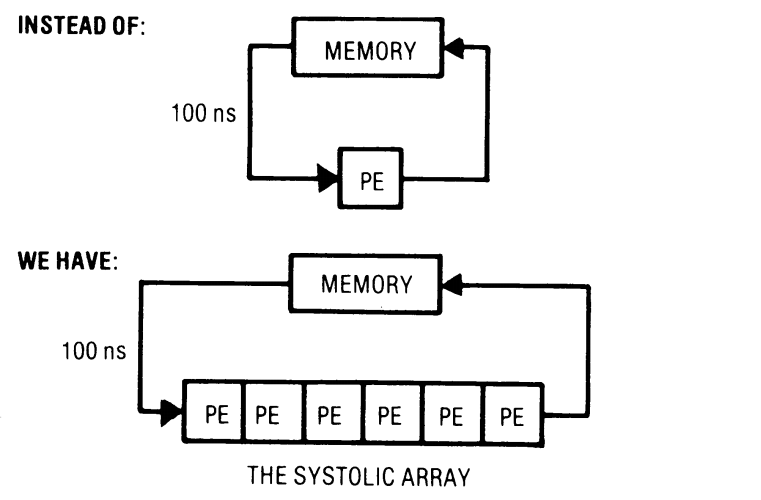
|
Systolic system matrix multiplication |
Mapping Deep Models to hardware: weight, input, and output stationarity¶
Weight stationary design
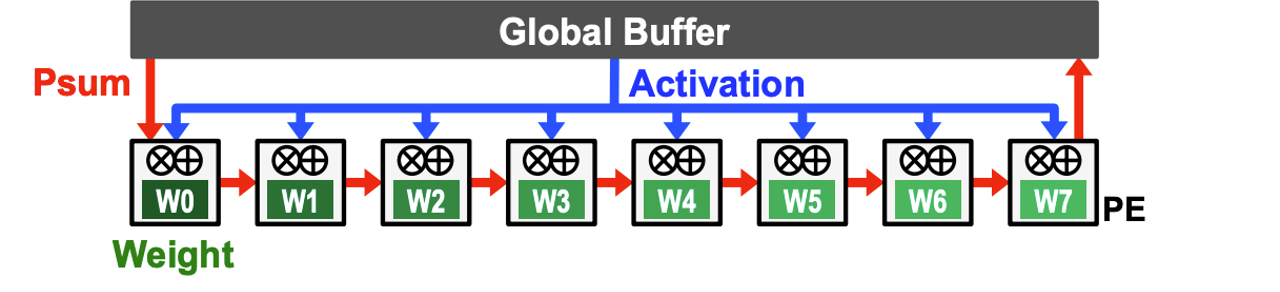
Input stationary design
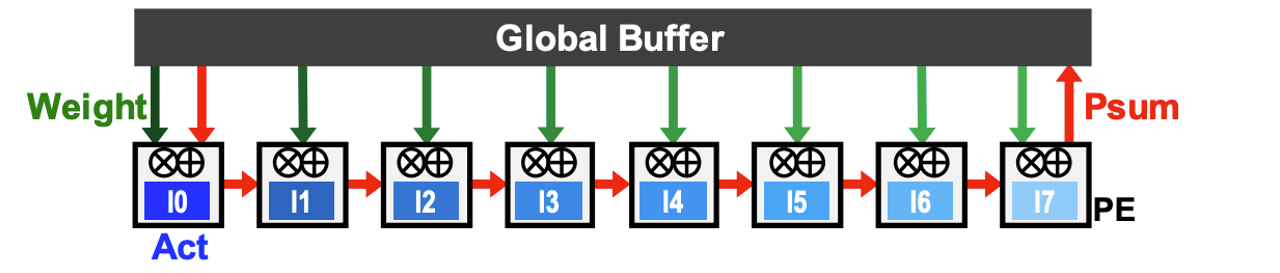
Output stationary design
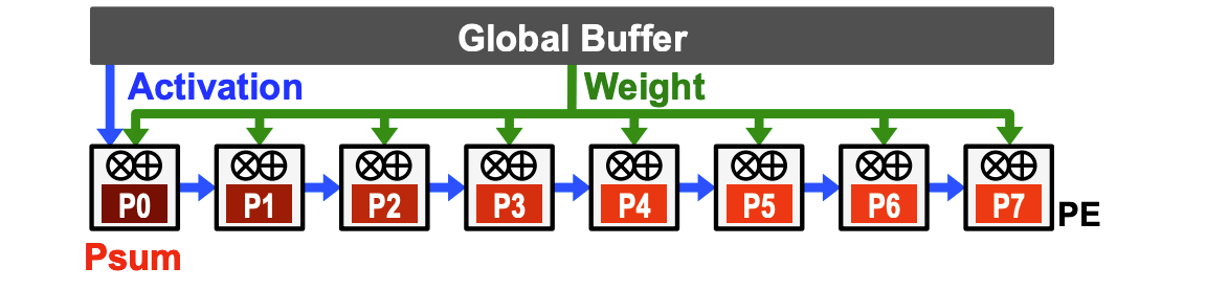
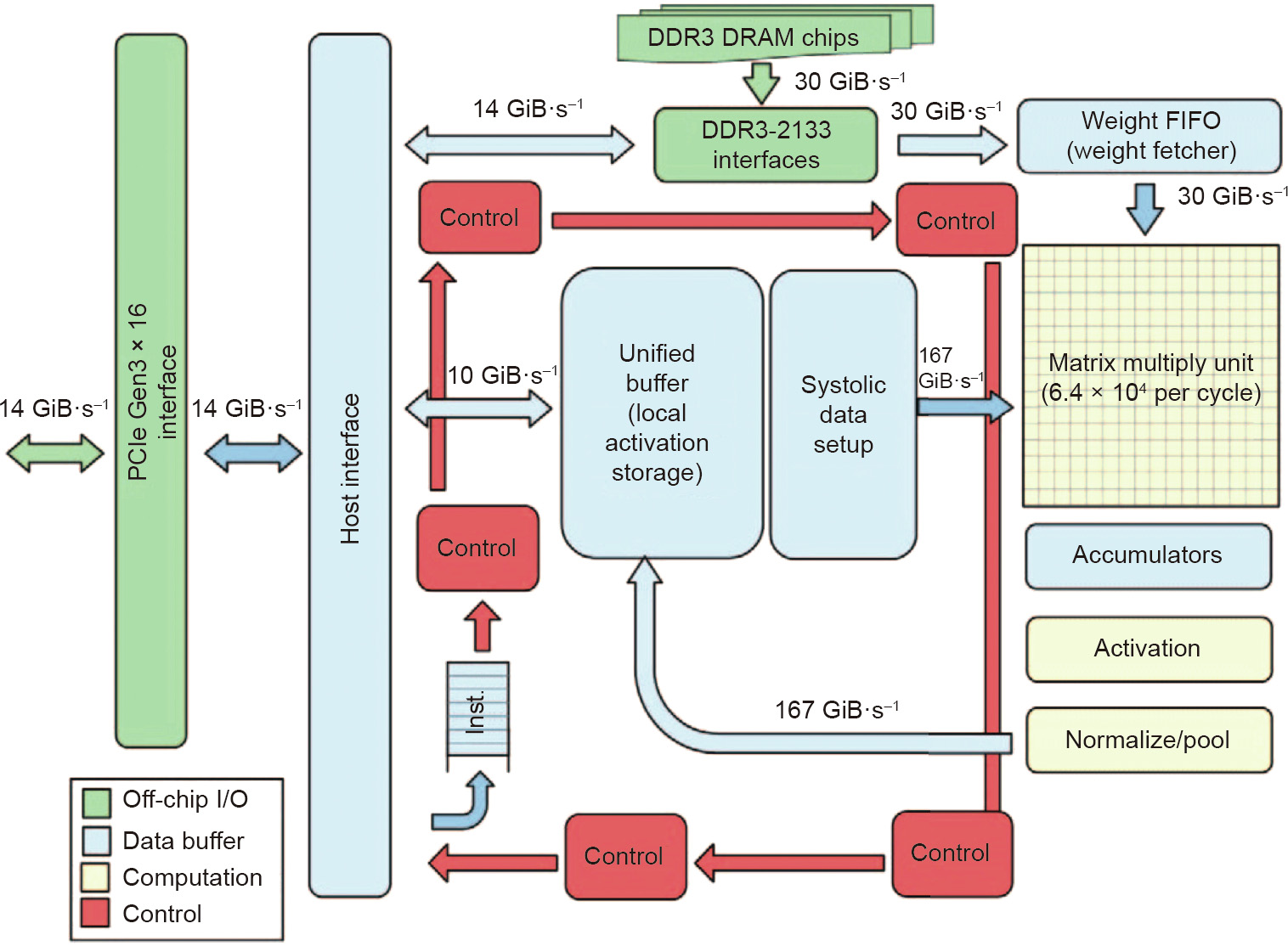
Systolic array example: weight stationary Google Tensor Processing Unit (TPU)¶
Plan for the Day¶
- Introduction
- Hardware Foundation
- Parallelism Leveraging
- Data Movement and Bandwidth Pressures
- Closing messages
- Deep Learning stack
- Deep Learning and accelerator co-design
- The Hardware and the Software Lottery
Deep Learning stack¶
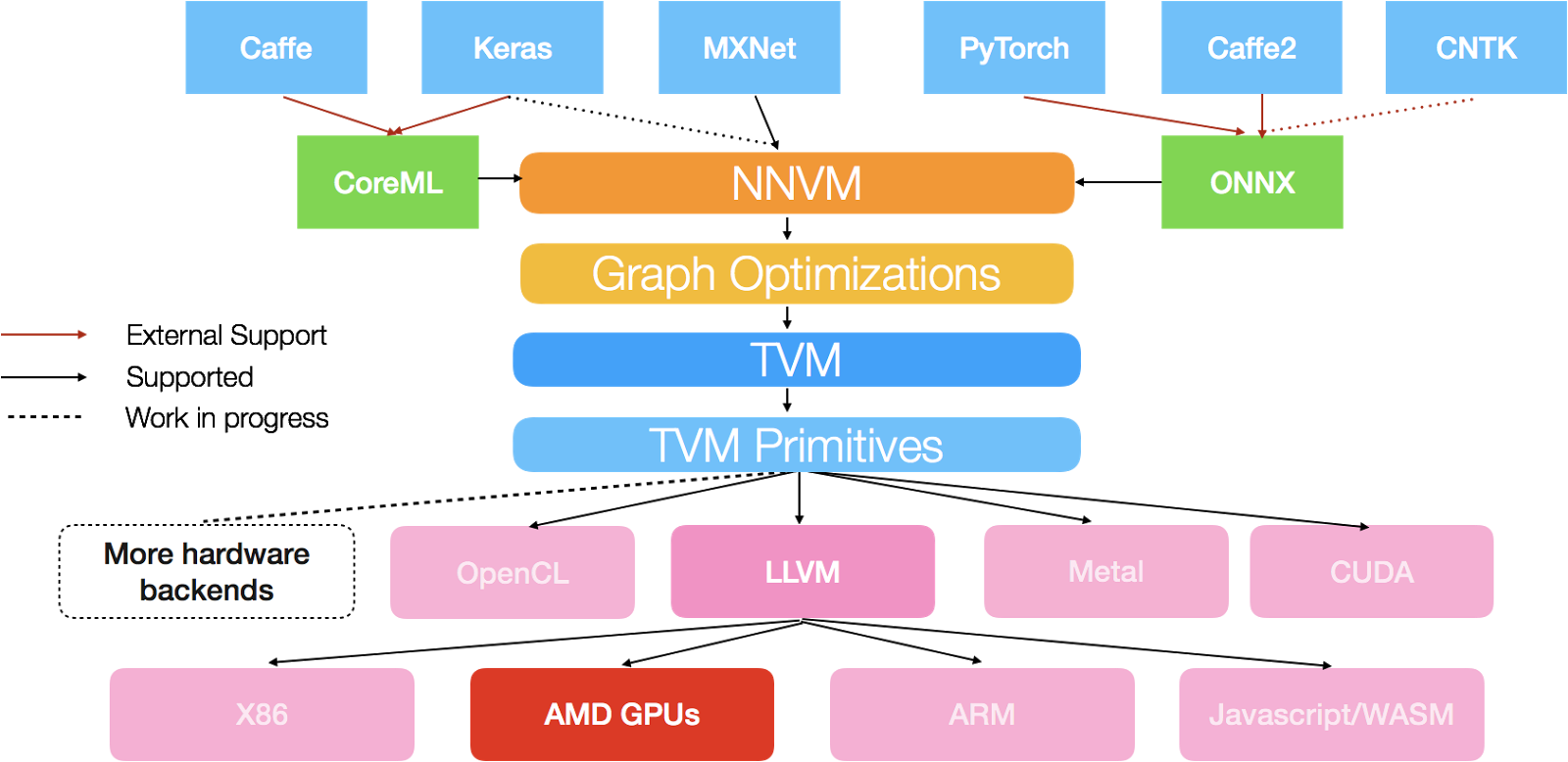
Beyond hardware methods¶
- Sparsity leveraging
- Sparsity-inducing compression
- Sparsity leveraging hardware
- Numerical representation
- Low precision
- bfloat16
- Quantization
- Low-level implementations
- GEMM
- cuDNN
Deep Learning and accelerator co-design¶
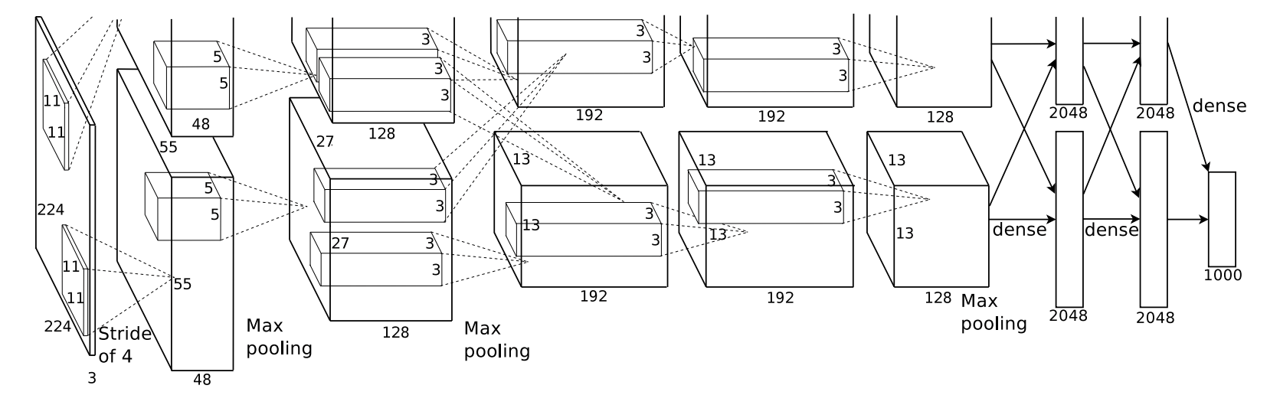
AlexNet: how GPU memory defined its architecture¶
- Alex Krizhevsky used two GTX 580 GPUs, each with 3GB of memory.
- Theoretical AlexNet (without mid-way split) working set profiling:
print("profile AlexNet layers - show memory requirements")
print("per-layer profiling of AlexNet - connects to the preceding slide")
from torchvision.models import alexnet as net
anet = net()
profile_layer_alexnet(anet)
profile AlexNet layers - show memory requirements
per-layer profiling of AlexNet - connects to the preceding slide
The actual AlexNet architecture¶
AlexNet's architecture had to be split down the middle to accommodate the 3GB limit per unit in its two GPUs.
Beyond hardware methods¶
- Sparsity leveraging
- Sparsity-inducing compression
- Sparsity leveraging hardware
- Numerical representation
- Low precision
- bfloat16
- Quantization
- Low-level implementations
- GEMM
- cuDNN
The Hardware and the Software Lotteries¶
The software and hardware lottery describes the success of a software or a piece of hardware resulting not from its universal superiority, but, rather, from its fit to the broader hardware and software ecosystem.
|
Eniac (1950s)
|
All-optical NN (2019) 
|
Summary of the Day¶
- Introduction
- Hardware Foundation
- Parallelism Leveraging
- Data Movement and Bandwidth Pressures
- Closing messages
Thank you for your attention!¶
Deep Learning resource characterisation¶
# memory requirements profiling - second slide; show as piechard
# Show proportion of data required for input, parameters and outputs
profile_mem(lenet)