 ***
# Lecture 2 - Minima of Convex Functions
***
$\newcommand{\vct}[1]{\mathbf{#1}}$
$\newcommand{\mtx}[1]{\mathbf{#1}}$
$\newcommand{\e}{\varepsilon}$
$\newcommand{\norm}[1]{\|#1\|}$
$\newcommand{\minimize}{\text{minimize}\quad}$
$\newcommand{\maximize}{\text{maximize}\quad}$
$\newcommand{\subjto}{\quad\text{subject to}\quad}$
$\newcommand{\R}{\mathbb{R}}$
$\newcommand{\trans}{T}$
$\newcommand{\ip}[2]{\langle {#1}, {#2} \rangle}$
$\newcommand{\zerovct}{\vct{0}}$
***
# Lecture 2 - Minima of Convex Functions
***
$\newcommand{\vct}[1]{\mathbf{#1}}$
$\newcommand{\mtx}[1]{\mathbf{#1}}$
$\newcommand{\e}{\varepsilon}$
$\newcommand{\norm}[1]{\|#1\|}$
$\newcommand{\minimize}{\text{minimize}\quad}$
$\newcommand{\maximize}{\text{maximize}\quad}$
$\newcommand{\subjto}{\quad\text{subject to}\quad}$
$\newcommand{\R}{\mathbb{R}}$
$\newcommand{\trans}{T}$
$\newcommand{\ip}[2]{\langle {#1}, {#2} \rangle}$
$\newcommand{\zerovct}{\vct{0}}$
In this lecture we will study the unconstrained problem
[1] \begin{equation*} \minimize\ f(\vct{x}), \end{equation*}
where $\vct{x}\in \R^n$. Optimality conditions aim to identify properties that potential minimizers need to satisfy in relation to $f(\vct{x})$. We will review the well known local optimality conditions for differentiable functions from calculus. We then introduce convex functions and discuss some of their properties.
Solutions to [1] come in different flavours, as in the following definition.
Definition. A point $\vct{x}^*\in \R^n$ is a
- global minimizer of [1] if for all $\vct{x}\in U$, $f(\vct{x}^*)\leq f(\vct{x})$;
- a local minimizer, if there is an open neighbourhood $U$ of $\vct{x}$ such that $f(\vct{x}^*)\leq f(\vct{x})$ for all $\vct{x}\in U$;
- a strict local minimizer, if there is an open neighbourhood $U$ of $\vct{x}$ such that $f(\vct{x}^*)<f(\vct{x})$ for all $\vct{x}\in U$;
- an isolated minimizer if there is an open neighbourhood $U$ of $\vct{x}^*$ such that $\vct{x}^*$ is the only local minimizer in $U$.
Without any further assumptions on $f$, finding a minimizer is a hopeless task: we simply can't examine the function at all points in $\R^n$. The situation becomes more tractable if we assume some smoothness conditions. Recall that $C^k(U)$ denotes the set of functions that are $k$ times continuously differentiable on some set $U$. The following first-order necessary condition for optimality is well known. We write $\nabla f(\vct{x})$ for the gradient of $f$ at $\vct{x}$, i.e., the vector
\begin{equation*} \nabla f(\vct{x}) = \left(\frac{\partial f}{\partial x_1}(\vct{x}),\dots,\frac{\partial f}{\partial x_n}(\vct{x})\right)^{\trans} \end{equation*}Theorem. Let $\vct{x}^*$ be a local minimizer of $f$ and assume that $f\in C^1(U)$ for a neighbourhood of $U$ of $\vct{x}^*$. Then $\nabla f(\vct{x}^*) = \zerovct$.
There are simple examples that show that this is not a sufficient condition: maxima and saddle points will also have a vanishing gradient. If we have access to second-order information, in form of the second derivative, or Hessian, of $f$, then we can say more. Recall that the Hessian of $f$ at $\vct{x}$, $\nabla^2f(\vct{x})$, is the $n\times n$ symmetric matrix given by the second derivatives,
\begin{equation*} \nabla^2f(\vct{x}) = \left(\frac{\partial^2 f}{\partial x_i \partial x_j}\right)_{1\leq i,j\leq n}. \end{equation*}In the one-variable case we know that if $x^*$ is a local minimizer of $f\in C^2([a,b])$, then $f'(x^*)=0$ and $f''(x^*)\geq 0$. Moreover, the conditions $f'(x^*)=0$ and $f''(x^*)>0$ guarantee that we have a local minimizer. These conditions generalise to higher dimension, but first we need to know what $f''(x)>0$ means when we have more than one variable.
Recall that a matrix $\mtx{A}$ is positive semidefinite, written $\mtx{A}\succeq \zerovct$, if for every $\vct{x}\in \R^n$, $\vct{x}^{\top}\mtx{A}\vct{x}\geq 0$, and positive definite, written $\mtx{A}\succ \zerovct$, if $\vct{x}^{\top}\mtx{A}\vct{x}>0$. The property that the Hessian matrix is positive semidefinite is a multivariate generalization of the property that the second derivative is nonnegative. The known conditions for a minimizer involving the second derivative generalise accordingly.
Theorem. Let $f\in C^2(U)$ for some open set $U$ and $\vct{x}^*\in U$. If $\vct{x}^*$ is a local minimizer, then $\nabla f(\vct{x}^*)=0$ and $\nabla^2f(\vct{x}^*)$ is positive semidefinite. Conversely, if $\nabla f(\vct{x}^*)=\zerovct$ and $\nabla^2f(\vct{x}^*)$ is positive definite, then $\vct{x}^*$ is a strict local minimizer.
Unfortunately, the above criteria are not able to identify global minimizers, as differentiability is a local property. If, however, the function is convex, then we can say a lot more!
We now come to the central notion of this course.
Definition. A set $C\subseteq \R^n$ is convex if for all $\vct{x},\vct{y}\in C$ and $\lambda \in [0,1]$, the line $\lambda \vct{x}+(1-\lambda)\vct{y}\in C$. A convex body is a convex set that is closed and bounded.
Definition. Let $S\subseteq \R^n$. A function $f\colon S\to \R$ is called convex if $S$ is convex and for all $\vct{x},\vct{y}\in \R^n$ and $\lambda\in [0,1]$,
\begin{equation*} f(\lambda \vct{x}+(1-\lambda)\vct{y})\leq \lambda f(\vct{x})+(1-\lambda)f(\vct{y}). \end{equation*}The function $f$ is called strictly convex if
\begin{equation*} f(\lambda \vct{x}+(1-\lambda)\vct{y})< \lambda f(\vct{x})+(1-\lambda)f(\vct{y}). \end{equation*}A function $f$ is called concave, if $-f$ is convex.
The next figure illustrates how a convex set in $\R^2$ and a function of one variable looks like. The graph of the function lies below any line connecting two points on it.
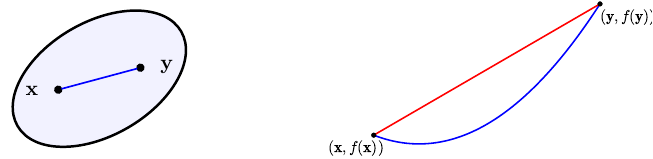
Convex function have pleasant properties, while at the same time covering many of the functions that arise in applications. Perhaps the most important property is that local minima are global minima.
Theorem. Let $f\colon \R^n\to \R$ be a convex function. Then any local minimizer of $f$ is a global minimizer.
Proof. Let $\vct{x}^*$ be a local minimizer and assume that it is not a global minimizer. Then there exists a vector $\vct{y}\in \R^n$ such that $f(\vct{y})<f(\vct{x}^*)$. Since $f$ is convex, for any $\lambda\in [0,1]$ and $\vct{x}=\lambda \vct{y}+(1-\lambda)\vct{x}^*$ we have
\begin{equation*} f(\vct{x}) \leq \lambda f(\vct{y})+(1-\lambda) f(\vct{x}^*) < \lambda f(\vct{x}^*)+(1-\lambda)f(\vct{x}^*) = f(\vct{x}^*). \end{equation*}
This holds for all $\vct{x}$ on the line segment connecting $\vct{y}$ and $\vct{x}^*$. Since every open neighbourhood $U$ of $\vct{x}^*$ contains a bit of this line segment, this means that every open neighbourhood $U$ of $\vct{x}^*$ contains an $\vct{x}\neq \vct{x}^*$ such that $f(\vct{x})\leq f(\vct{x}^*)$, in contradiction to the assumption that $\vct{x}^*$ is a local minimizer. It follows that $\vct{x}^*$ has to be a global minimizer.
** Remark.** Note that in the above theorem we made no assumptions about the differentiability of the function $f$! In fact, while a convex function is always continuous, it need not be differentiable. The function $f(x) = |x|$ is a typical example: it is convex, but not differentiable at $x=0$.
Example. Affine functions $f(\vct{x})=\ip{\vct{x}}{\vct{a}}+b$ and the exponential function $e^x$ are examples of convex functions.
Example. In optimization we will often work with functions of matrices, where an $m\times n$ matrix is considered as a vector in $\R^{m\times n}\cong \R^{mn}$. If the matrix is symmetric, that is, if $\mtx{A}^{\trans}=\mtx{A}$, then we only care about the upper diagonal entries, and we consider the space $\mathcal{S}^n$ of symmetric matrices as a vector space of dimension $n(n+1)/2$ (the number of entries on and above the main diagonal). Important functions on symmetric matrices that are convex are the operator norm $\norm{\mtx{A}}_2$, defined as \begin{equation*} \norm{\mtx{A}}_2 := \max_{\vct{x}\colon \norm{\vct{x}}\leq 1} \frac{\norm{\mtx{A}\vct{x}}_2}{\norm{\vct{x}}_2}, \end{equation*} or the function $\log \det(\mtx{X})$, defined on the set of positive semidefinite symmetric matrices $\mathcal{S}_+^n$.
There are useful ways of characterising convexity using differentiability.
Theorem.
- Let $f\in C^1(\R^n)$. Then $f$ is convex if and only if for all $\vct{x}, \vct{y}\in \R^n$,
\begin{equation*} f(\vct{y})\geq f(\vct{x})+\nabla f(\vct{x})^{\trans} (\vct{y}-\vct{x}). \end{equation*}
- Let $f\in C^2(\R^n)$. Then $f$ is convex if and only if $\nabla^2 f(\vct{x})$ is positive semidefinite. If $\nabla^2f(\vct{x})$ is positive definite, then $f$ is strictly convex.
Example. Consider a quadratic function of the form
\begin{equation*} f(\vct{x}) = \frac{1}{2}\vct{x}^{\trans}\mtx{A}\vct{x}+\vct{b}^{\trans}\vct{x}+c, \end{equation*}
where $\mtx{A}\in \R^{n\times n}$ is symmetric. Writing out the product, we get
\begin{equation*} \mtx{x}^{T}\mtx{A}\vct{x} = \begin{pmatrix} x_1 & \cdots & x_n \end{pmatrix} \begin{pmatrix} a_{11} & \cdots & a_{1n}\\ \vdots & \ddots & \vdots\\ a_{n1} & \cdots & a_{nn} \end{pmatrix} \begin{pmatrix} x_1\\ \vdots \\ x_n \end{pmatrix} = \begin{pmatrix} x_1 & \cdots & x_n \end{pmatrix} \begin{pmatrix} a_{11}x_1+\cdots+a_{1n}x_n\\ \vdots \\ a_{n1}x_1+\cdots+a_{nn}x_n \end{pmatrix} = \sum_{i=1}^n \sum_{j=1}^n a_{ij} x_i x_j. \end{equation*}
Because $\mtx{A}$ is symmetric, we have $a_{ij}=a_{ji}$, and the above product simplifies to
\begin{equation*} \vct{x}^{T}\mtx{A}\vct{x} = \sum_{i=1}^n a_{ii} x_i^2 + 2\sum_{1\leq i<j\leq n} a_{ij}x_i x_j. \end{equation*}
This is a quadratic function, because it involves products of the $x_i$. The gradient and the Hessian of $f(\vct{x})$ are found by computing the first and second order partial derivatives of $f$:
\begin{equation*} \frac{\partial f}{\partial x_i} = \sum_{j=1}^n a_{ij} x_j + b_i, \quad \frac{\partial^2 f}{\partial x_i \partial x_j} = a_{ij}. \end{equation*}
In summary, we have \begin{equation*} \nabla f(\vct{x}) = \mtx{A}\vct{x} + \vct{b}, \quad \nabla^2f(\vct{x}) = \mtx{A}. \end{equation*}
Using the previous theorem, we see that $f$ is convex if and only if $\mtx{A}$ is positive semidefinite. A typical example for such a function is the least squares function encountered in Lecture 1,
\begin{equation*} f(\vct{x}) = \|\mtx{X}\vct{\beta}-\vct{y}\|^2 = (\mtx{X}\vct{\beta}-\vct{y})^{T}(\mtx{X}\vct{\beta}-\vct{y}) = \vct{\beta}^{T}\mtx{X}^{T}\mtx{X}\vct{\beta} -2\vct{y}^{T}\mtx{X}\vct{\beta}+\vct{y}^T\vct{y}. \end{equation*}
The matrix $\mtx{A}=\mtx{X}^T\mtx{X}$ is always symmetric and positive semidefinite (why?) so that the function $f$ is convex. In the example below, we plot the mean squared error of a random least squares problem (see Lecture 1 for an explanation).
A convenient way to visualise a function $f\colon \R^2\to \R$ is through contour plots. A level set of the function $f$ is a set of the form
\begin{equation*} \{\vct{x}\mid f(\vct{x}) = c\}, \end{equation*}where $c$ is the level. Each such level set is a curve in $\R^2$, and a contour plot is a plot of a collection of such curves for various $c$. If one colours the areas between adjacent curves, one gets a plot as in the following figure. A convex function is has the property that there is only one sink in the contour plot.
import numpy as np
import numpy.linalg as la
import matplotlib.pyplot as plt
% matplotlib inline
# Create random data: we use the randn function
X = np.random.randn(3,2)
y = np.random.randn(3)
# Solve least squares problem minimize \|X\beta-y\|^2
# the index 0 says that we get the first component of the solution
# (the function lstsq give more output than just the beta vector)
beta = la.lstsq(X,y)[0]
# Create function and plot the contours
def f(a,b):
return sum((a*X[:,0]+b*X[:,1]-y)**2)
# Find the "right" boundaries around the minimum
xx = np.linspace(beta[0]-8,beta[0]+8,100)
yy = np.linspace(beta[1]-8,beta[1]+8,100)
# A mesh grid gives a pair of matrix XX and YY,
# such that for each (i,j), the pairs (XX[i,j],YY[i,j])
# cover all the points on the square defined by xx and yy
XX, YY = np.meshgrid(xx,yy)
# Compute the Z values corresponding to the meshgrid
Z = np.zeros(XX.shape)
for i in range(Z.shape[0]):
for j in range(Z.shape[1]):
Z[i,j] = f(XX[i,j],YY[i,j])
# Before plotting the contour map, choose a nice colormap
cmap = plt.cm.get_cmap("coolwarm")
plt.contourf(XX,YY,Z, cmap = cmap)
plt.show()
