Reinforcement Learning with Doom - Increasing complexity and monitoring the model¶
Leandro Kieliger contact@lkieliger.ch
Description¶
In this notebook we are going to build upon the setup introduced in the previous part of this series. We will tackle a more difficult scenario, add useful logging to the learning process and finally start competing against in-game bots in a first attemps at playing a deathmatch game using reinforcement learning.
The notebook is structured in 3 parts:
Part 1 - Increasing complexity¶
Part 2 - Monitoring the model¶
Part 3 - Playing doom deathmatch¶
%load_ext autoreload
%autoreload 2
import cv2
import gym
import matplotlib.pyplot as plt
import numpy as np
import torch as th
import typing as t
import vizdoom
from stable_baselines3 import ppo
from stable_baselines3.common.callbacks import EvalCallback
from stable_baselines3.common import evaluation, policies
from torch import nn
from common import envs, plotting
New scenario: Defend The Center¶
The next scenario we are going to tackle is called "Defend the center". In this scenario, the agent is stuck in the center of a circular arena and will be attacked by monsters spawning at random intervals and locations. Here are the rewards for this scenario:
- 1 point for each ennemy killed.
- -1 point for dying.
Since there is a limit on the total ammunition of the agent, 26, the theoretical maximum reward achievable for this scenario is 25. The buttons available are ATTACK, TURN_LEFT and TURN_RIGHT.
We are going to define a little helper function that will streamline the training and evaluation process as we will need to repeat it several time in this notebook. The function simply create the environments, instantiate an agent based on the PPO algorithm and start training and optionally evaluating the agent for a given number of steps.
def solve_env(env_args, agent_args, n_envs, timesteps, callbacks, eval_freq=None, init_func=None):
"""Helper function to streamline the learning and evaluation process.
Args:
env_args: A dict containing arguments passed to the environment.
agent_args: A dict containing arguments passed to the agent.
n_envs: The number of parallel training envs to instantiate.
timesteps: The number of timesteps for which to train the model.
callbacks: A list of callbacks for the training process.
eval_freq: The frequency (in steps) at which to evaluate the agent.
init_func: A function to be applied on the agent before training.
"""
# Create environments.
env = envs.create_vec_env(n_envs, **env_args)
# Build the agent.
agent = ppo.PPO(policies.ActorCriticCnnPolicy, env, tensorboard_log='logs/tensorboard', seed=0, **agent_args)
# Optional processing on the agent.
if init_func is not None:
init_func(agent)
# Optional evaluation callback.
if eval_freq is not None:
eval_env = envs.create_eval_vec_env(**env_args)
callbacks.append(EvalCallback(
eval_env,
n_eval_episodes=10,
eval_freq=eval_freq,
log_path=f'logs/evaluations/{env_args["scenario"]}',
best_model_save_path=f'logs/models/{env_args["scenario"]}'))
# Start the training process.
agent.learn(total_timesteps=timesteps, tb_log_name=env_args['scenario'], callback=callbacks)
# Cleanup.
env.close()
if eval_freq is not None: eval_env.close()
return agent
Next, we configure the environments like we have seen in the previous notebook. We will be training for only 100k steps as this is already enough to reach a good score in this scenario. Don't forget to specify the frame skip parameter as we have seen that this is one of the most efficient way to speed up the learning process along with the learning rate.
# Results in a 100x156 image, no pixel lost due to padding with the default CNN architecture
frame_processor = lambda frame: cv2.resize(frame[40:, 4:-4], None, fx=.5, fy=.5, interpolation=cv2.INTER_AREA)
env_args = {'scenario': 'defend_the_center', 'frame_skip': 4, 'frame_processor': frame_processor}
agent_args = {'n_epochs': 3, 'n_steps': 2048, 'learning_rate': 1e-4, 'batch_size': 32}
solve_env(env_args, agent_args, n_envs=2, timesteps=150000, callbacks=[], eval_freq=2048)
Eval num_timesteps=4096, episode_reward=-1.00 +/- 0.00 Episode length: 72.80 +/- 7.95 New best mean reward! Eval num_timesteps=8192, episode_reward=-0.50 +/- 0.81 Episode length: 78.10 +/- 15.14 New best mean reward! Eval num_timesteps=12288, episode_reward=3.40 +/- 1.91 Episode length: 139.10 +/- 43.52 New best mean reward! Eval num_timesteps=16384, episode_reward=1.90 +/- 0.70 Episode length: 110.20 +/- 6.78 Eval num_timesteps=20480, episode_reward=9.40 +/- 7.14 Episode length: 248.20 +/- 130.42 New best mean reward! Eval num_timesteps=24576, episode_reward=9.30 +/- 4.88 Episode length: 227.70 +/- 82.49 Eval num_timesteps=28672, episode_reward=17.80 +/- 4.31 Episode length: 400.10 +/- 93.08 New best mean reward! Eval num_timesteps=32768, episode_reward=18.50 +/- 5.37 Episode length: 404.40 +/- 106.92 New best mean reward! Eval num_timesteps=36864, episode_reward=16.90 +/- 4.53 Episode length: 370.10 +/- 94.13 Eval num_timesteps=40960, episode_reward=19.50 +/- 2.01 Episode length: 427.40 +/- 28.64 New best mean reward! Eval num_timesteps=45056, episode_reward=19.50 +/- 1.20 Episode length: 407.80 +/- 23.39 Eval num_timesteps=49152, episode_reward=19.70 +/- 1.79 Episode length: 406.10 +/- 31.34 New best mean reward! Eval num_timesteps=53248, episode_reward=16.30 +/- 1.27 Episode length: 342.70 +/- 29.71 Eval num_timesteps=57344, episode_reward=18.50 +/- 2.11 Episode length: 375.00 +/- 40.77 Eval num_timesteps=61440, episode_reward=18.30 +/- 1.79 Episode length: 357.50 +/- 24.90 Eval num_timesteps=65536, episode_reward=19.40 +/- 2.11 Episode length: 363.90 +/- 30.47 Eval num_timesteps=69632, episode_reward=18.50 +/- 1.69 Episode length: 362.10 +/- 37.28 Eval num_timesteps=73728, episode_reward=17.10 +/- 2.21 Episode length: 342.00 +/- 33.39 Eval num_timesteps=77824, episode_reward=19.00 +/- 2.19 Episode length: 346.60 +/- 25.57 Eval num_timesteps=81920, episode_reward=18.90 +/- 2.70 Episode length: 377.80 +/- 33.54 Eval num_timesteps=86016, episode_reward=18.00 +/- 1.73 Episode length: 347.80 +/- 23.25 Eval num_timesteps=90112, episode_reward=18.80 +/- 2.23 Episode length: 367.70 +/- 27.82 Eval num_timesteps=94208, episode_reward=18.80 +/- 2.44 Episode length: 356.70 +/- 38.54 Eval num_timesteps=98304, episode_reward=20.90 +/- 1.64 Episode length: 357.10 +/- 31.33 New best mean reward! Eval num_timesteps=102400, episode_reward=18.80 +/- 1.89 Episode length: 339.60 +/- 21.56 Eval num_timesteps=106496, episode_reward=19.50 +/- 1.43 Episode length: 342.50 +/- 25.11 Eval num_timesteps=110592, episode_reward=19.40 +/- 2.15 Episode length: 348.50 +/- 28.62 Eval num_timesteps=114688, episode_reward=19.70 +/- 1.19 Episode length: 333.40 +/- 16.79 Eval num_timesteps=118784, episode_reward=21.60 +/- 2.62 Episode length: 355.60 +/- 30.08 New best mean reward! Eval num_timesteps=122880, episode_reward=20.10 +/- 1.30 Episode length: 339.40 +/- 29.45 Eval num_timesteps=126976, episode_reward=20.50 +/- 1.63 Episode length: 337.50 +/- 19.14 Eval num_timesteps=131072, episode_reward=18.70 +/- 1.27 Episode length: 306.70 +/- 14.32 Eval num_timesteps=135168, episode_reward=20.60 +/- 1.74 Episode length: 329.50 +/- 18.01 Eval num_timesteps=139264, episode_reward=18.80 +/- 1.33 Episode length: 308.50 +/- 21.88 Eval num_timesteps=143360, episode_reward=19.20 +/- 2.14 Episode length: 314.00 +/- 22.63 Eval num_timesteps=147456, episode_reward=18.20 +/- 1.17 Episode length: 299.30 +/- 17.75 Eval num_timesteps=151552, episode_reward=19.40 +/- 2.84 Episode length: 336.90 +/- 41.69
<stable_baselines3.ppo.ppo.PPO at 0x7fb2ffe58e20>
We see that very quickly we reach satisfactory results. This is not surprising since the scenario is not much more difficult than the basic one we have seen in the previous notebook. Let's try to add some complexity.
Defend the center (difficult version)¶
Remember that our ultimate goal is to train an agent to play Doom deathmatch against bots. We will use the scenario we just solved as a good middle ground to perform some experiments before jumping to the more difficult task of playing against bots. In general, it is often a good idea to start simple and progressively add complexity to the task.
The increased complexity here will arise from the fact that in a deathmatch environment, we will need to perform more actions than simply turning around and shooting. Here is the list of buttons we will be using:
ATTACK, TURN_LEFT, TURN_RIGHT, MOVE_FORWARD, MOVE_LEFT, MOVE_RIGHT
A simple solution would be to directly add more buttons to the config file. Although this will work, you will notice that the agent will be quite slow in the sense that he can only perform one action at a time. Either shoot, turn or move. Although this is not a big issue in the current scenario, when playing later against bots running all over the place our agent will be unfairly disadvantaged because of the limitations in its actions.

VizDoom allows us to provide a list of button states but our model uses a discrete action space. A simple workaround is to generate all possible combination of buttons and use each combination as a single action. However, the number of such possible combination is $2^n$ where $n$ is the number of available buttons. Even is our simple case with only 6 buttons, this would mean having 64 possible outputs. To mitigate the combinatorial explosion of our action space, we are going to forbid certain combination. Indeed, it does not make much sense to allow for example both TURN_RIGHT and TURN_LEFT to be activated at the same time. Therefore, we will remove the following combinations:
TURN_RIGHTandTURN_LEFTMOVE_RIGHTandMOVE_LEFT
And we will also only allow the ATTACK button to be used alone. This will not hurt performance as most weapons in Doom have a cooldown period between two attacks anyway. In the end, the total number of different possible actions is given by the cartesian product of:
{ATTACK} + {TURN_RIGHT, TURN_LEFT, NOTHING} x {MOVE_RIGHT, MOVE_LEFT, NOTHING} x {MOVE_FORWARD, NOTHING}
Since we don't want the all-zero state (no button pressed) this will give us a grand total of 18 which is much better than the 64 we could have ended up with. Here is the code to generate the action space given a list of buttons and our exclusion lists.
import itertools
import typing as t
from vizdoom import Button
# Buttons that cannot be used together
MUTUALLY_EXCLUSIVE_GROUPS = [
[Button.MOVE_RIGHT, Button.MOVE_LEFT],
[Button.TURN_RIGHT, Button.TURN_LEFT],
[Button.MOVE_FORWARD, Button.MOVE_BACKWARD],
]
# Buttons that can only be used alone.
EXCLUSIVE_BUTTONS = [Button.ATTACK]
def has_exclusive_button(actions: np.ndarray, buttons: np.array) -> np.array:
exclusion_mask = np.isin(buttons, EXCLUSIVE_BUTTONS)
# Flag actions that have more than 1 active button among exclusive list.
return (np.any(actions.astype(bool) & exclusion_mask, axis=-1)) & (np.sum(actions, axis=-1) > 1)
def has_excluded_pair(actions: np.ndarray, buttons: np.array) -> np.array:
# Create mask of shape (n_mutual_exclusion_groups, n_available_buttons), marking location of excluded pairs.
mutual_exclusion_mask = np.array([np.isin(buttons, excluded_group)
for excluded_group in MUTUALLY_EXCLUSIVE_GROUPS])
# Flag actions that have more than 1 button active in any of the mutual exclusion groups.
return np.any(np.sum(
# Resulting shape (n_actions, n_mutual_exclusion_groups, n_available_buttons)
(actions[:, np.newaxis, :] * mutual_exclusion_mask.astype(int)),
axis=-1) > 1, axis=-1)
def get_available_actions(buttons: np.array) -> t.List[t.List[float]]:
# Create list of all possible actions of size (2^n_available_buttons x n_available_buttons)
action_combinations = np.array([list(seq) for seq in itertools.product([0., 1.], repeat=len(buttons))])
# Build action mask from action combinations and exclusion mask
illegal_mask = (has_excluded_pair(action_combinations, buttons)
| has_exclusive_button(action_combinations, buttons))
possible_actions = action_combinations[~illegal_mask]
possible_actions = possible_actions[np.sum(possible_actions, axis=1) > 0] # Remove no-op
print('Built action space of size {} from buttons {}'.format(len(possible_actions), buttons))
return possible_actions.tolist()
possible_actions = get_available_actions(np.array([
Button.ATTACK, Button.MOVE_FORWARD, Button.MOVE_LEFT,
Button.MOVE_RIGHT, Button.TURN_LEFT, Button.TURN_RIGHT]))
possible_actions
Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_LEFT: 15> <Button.TURN_RIGHT: 14>]
[[0.0, 0.0, 0.0, 0.0, 0.0, 1.0], [0.0, 0.0, 0.0, 0.0, 1.0, 0.0], [0.0, 0.0, 0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 0.0, 1.0, 0.0, 1.0], [0.0, 0.0, 0.0, 1.0, 1.0, 0.0], [0.0, 0.0, 1.0, 0.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0, 0.0, 1.0], [0.0, 0.0, 1.0, 0.0, 1.0, 0.0], [0.0, 1.0, 0.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0, 0.0, 1.0], [0.0, 1.0, 0.0, 0.0, 1.0, 0.0], [0.0, 1.0, 0.0, 1.0, 0.0, 0.0], [0.0, 1.0, 0.0, 1.0, 0.0, 1.0], [0.0, 1.0, 0.0, 1.0, 1.0, 0.0], [0.0, 1.0, 1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 1.0, 0.0, 0.0, 1.0], [0.0, 1.0, 1.0, 0.0, 1.0, 0.0], [1.0, 0.0, 0.0, 0.0, 0.0, 0.0]]
Here is what a trained agent the uses the modified 18-output version navigate across the map. It looks much more dynamic and we can expect better results when competing in a deathmatch.

Training the model in this more challenging environment will definitely require more training time. This is a good opportunity to log some metrics to help us monitor the training process.
^ Part 2 - Monitoring the model¶
Stable-baselines already logs several useful metrics for us such as the value, policy or entropy losses, mean episode length and mean episode reward. The next most useful quantity to keep an eye on is the evolution of the model weights and activations. In particular, we'd like to make sure that our activations are well behaved. That is, they are not always zero (which would suggest we have dead neurons) and that the variance of each layer output stays away from zero as well. If this is not the case, we might end up with vanishing gradient issues and ultimately poor learning performance.
I already mentioned the amazing course from FastAI's in the previous part of this series. We are going to implement several suggestions from the 10th lesson of the course. Namely:
- Activation layer monitoring with hooks
- Kaiming initialization
- Batch/Layer normalization
Hooks¶
Let's start by tracking neuron activations. This is particularly important for the first layers of our model. To do this, we will use FastAI's approach of defining hook wrappers. A hook is a function that can be attached to a specific layer of our model and that will be called for each forward pass. This is a feature offered by PyTorch and the idea is to build on top of that to keep track of useful statistics.
We will combine this approach with Tensorboard ability to log tensors to get the distribution over time of our layer activations. Our hooks will contain a single attribute, activation_data, that will store the layer output.
from collections import deque
from functools import partial
class Hook:
"""Wrapper for PyTorch forward hook mechanism."""
def __init__(self, module: nn.Module, func: t.Callable):
self.hook = None # PyTorch's hook.
self.module = module # PyTorch layer to which the hook is attached to.
self.func = func # Function to call on each forward pass.
self.register()
def register(self):
self.activation_data = deque(maxlen=1024)
self.hook = self.module.register_forward_hook(partial(self.func, self))
def remove(self):
self.hook.remove()
def store_activation(hook, module, inp, outp):
"""Function intented to be called by a hook on a forward pass.
Args:
hook: The hook object that generated the call.
module: The module on which the hook is registered.
inp: Input of the module.
outp: Output of the module.
"""
hook.activation_data.append(outp.data.cpu().numpy())
Monitoring callback¶
The second step is to define a callback that will periodically log hook data. For simplicity, we will only be logging in Tensorboard the latest activation value of each training phase.
Of course, if you need more granularity, you can easily log more values. Keep in mind though that stable-baselines logger implementation aligns everything on the rollout time steps (which do not correspond to forward passes in training) when logging to Tensorboard. So you will need to do some adjustments there to either log to a file yourself or to adapt stable-baseline's implementation. You can also take a look at the plotting helpers which make use of the complete list of activation to create the diagnostic plots below.
The callback will also compute and log some basic statistics:
- The mean of each activation layer
- The standard deviation of each activation layer
- The proportion of activations that are between -0.2 and 0.2
from stable_baselines3.common.callbacks import BaseCallback
def get_low_act(data, threshold=0.2):
"""Computes the proportion of activations that have value close to zero."""
low_activation = ((-threshold <= data) & (data <= threshold))
return np.count_nonzero(low_activation) / np.size(low_activation)
# Callback for periodic logging to tensorboard.
class LayerActivationMonitoring(BaseCallback):
def _on_rollout_start(self) -> None:
"""Called after the training phase."""
hooks = self.model.policy.features_extractor.hooks
# Remove the hooks so that they don't get called for rollout collection.
for h in hooks: h.remove()
# Log last datapoint and statistics to tensorboard.
for i, hook in enumerate(hooks):
if len(hook.activation_data) > 0:
data = hook.activation_data[-1]
self.logger.record(f'diagnostics/activation_l{i}', data)
self.logger.record(f'diagnostics/mean_l{i}', np.mean(data))
self.logger.record(f'diagnostics/std_l{i}', np.std(data))
self.logger.record(f'diagnostics/low_act_prop_l{i}', get_low_act(data))
def _on_rollout_end(self) -> None:
"""Called before the training phase."""
for h in self.model.policy.features_extractor.hooks: h.register()
def _on_step(self):
pass
Finally, we define a function that will attach hooks to every activation layer.
def register_hooks(model):
model.policy.features_extractor.hooks = [
Hook(layer, store_activation)
for layer in model.policy.features_extractor.cnn
if isinstance(layer, nn.ReLU) or isinstance(layer, nn.LeakyReLU)]
Let's observe the behaviour of the model using our new logging mechanism. We train the model for a few steps and let the hook collect the activations during the forward passes. Note that for the PPO algorithm, we first need to collect a rollout sample using the current policy before any training can take place. Logging those activation is not very useful as the layer weights are not being updated yet. This is why we detach and reattach the hooks in the _on_rollout_start and _on_rollout_end functions respectively from the callback above.
The helper function below will simply extract the list of layer outputs collected by the hook, compute and then plot some statistics. Using the idea presented in FastAI's course, it will also plot an histogram of the layer activations. The horizontal axis represents training steps (processing of one minibatch), in chronological order from left to right. The vertical axis represents the histogram bins from -7 to 7 (bottom to top). Brighter regions indicate larger histogram frequencies.
# Train for a few steps to collect the activations.
agent = solve_env(env_args, agent_args, 1, 1024, [LayerActivationMonitoring()], init_func=register_hooks)
# Plot statistics.
plotting.plot_activations(agent.policy.features_extractor.hooks)

We notice at the beginning of the training phase several potential issues. First, the variance of the output of each layer is very close to zero and there is a noticeable decrease between the first and the last layer. Also, almost all the outputs are near zero which can be seen both on the graph showing the proportion of small activations over time and the activation histogram.
In addition to using LeakyReLU instead of ReLU and following FastAI's recommendation, we will perform two changes:
- Use Kaiming initialization
- Use some normalization (layer norm in our case)
def init_net(m: nn.Module):
if len(m._modules) > 0:
for subm in m._modules:
init_net(m._modules[subm])
elif isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
nn.init.kaiming_normal_(
m.weight,
a=0.1, # Same as the leakiness parameter for LeakyReLu.
mode='fan_in', # Preserves magnitude in the forward pass.
nonlinearity='leaky_relu')
Normalization¶
To add layer normalization, we need to redefine a model. We will then tell stable-baselines to use our customized model instead of the default one. For the sake of brevity, sizes for the different layers of our model have been hardcoded.
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor
class CustomCNN(BaseFeaturesExtractor):
def __init__(self, observation_space: gym.spaces.Box, features_dim: int = 128, **kwargs):
super().__init__(observation_space, features_dim)
self.cnn = nn.Sequential(
nn.LayerNorm([3, 100, 156]),
nn.Conv2d(3, 32, kernel_size=8, stride=4, padding=0, bias=False),
nn.LayerNorm([32, 24, 38]),
nn.LeakyReLU(**kwargs),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=0, bias=False),
nn.LayerNorm([64, 11, 18]),
nn.LeakyReLU(**kwargs),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0, bias=False),
nn.LayerNorm([64, 9, 16]),
nn.LeakyReLU(**kwargs),
nn.Flatten(),
)
self.linear = nn.Sequential(
nn.Linear(9216, features_dim, bias=False),
nn.LayerNorm(features_dim),
nn.LeakyReLU(**kwargs),
)
def forward(self, observations: th.Tensor) -> th.Tensor:
return self.linear(self.cnn(observations))
Let's collect some data again but this time using the modified model.
def init_model(model):
register_hooks(model)
init_net(model.policy)
agent_args['policy_kwargs'] = {'features_extractor_class': CustomCNN}
agent = solve_env(env_args, agent_args, 1, 1024, [LayerActivationMonitoring()], init_func=init_model)
plotting.plot_activations(agent.policy.features_extractor.hooks)

We notice now that the variance is better behaved, hovering around 0.6. The proportion of activations that are close to zero is significantly lower at ~65% instead of nearly 90% before. In particular, we can notice that the model is now using the full range of the ReLU activation function.
Comparing the models¶
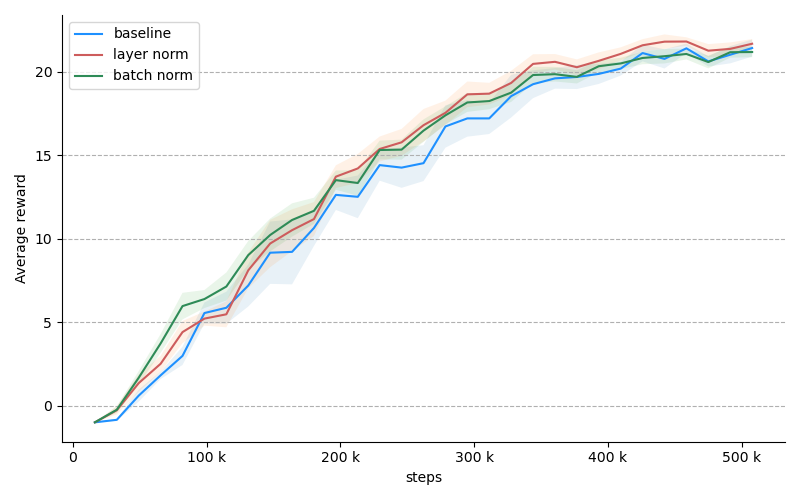
The metrics associated with our model look much better now. But does this translate into better performance? In FastAI example, adding normalization was the most impactful factor in improving the results. To see whether we get similar benefits in our setup, let's solve the more difficult variable variant of "defend the center" with different parameters: no normalization, layer normalization and batch normalization. In the plot below, each line is the average of 6 consecutive trials. The coloured region denotes the error mean: $ \frac{\sigma}{\sqrt{n}}$.
Unfortunately, although our modified model exhibits nicer telemetry, it seems to have very little impact on the training performance. We will keep the changes nonetheless since we know they help with the fundamentals.
Finally, here is the final setup to train against the more difficult verion of "defend the center". It includes the modified architecture with layer normalization as well as the layer activation monitoring callback that will periodically save to tensorboard. To reach satisfactory results in this more difficult environment, you will need to let the agent train for roughly 500k steps.
env_args = {
'scenario': 'defend_the_center_relaxed',
'frame_skip': 4,
'frame_processor': frame_processor
}
agent_args = {
'n_epochs': 3,
'n_steps': 4096,
'learning_rate': 1e-4,
'batch_size': 32,
'policy_kwargs': {'features_extractor_class': CustomCNN}
}
agent = solve_env(env_args,
agent_args,
n_envs=2,
timesteps=300000,
callbacks=[LayerActivationMonitoring()],
eval_freq=4096,
init_func=init_model)
Eval num_timesteps=8192, episode_reward=-1.00 +/- 0.00 Episode length: 107.00 +/- 24.96 New best mean reward! Eval num_timesteps=16384, episode_reward=-1.00 +/- 0.00 Episode length: 94.00 +/- 16.63 Eval num_timesteps=24576, episode_reward=-0.70 +/- 0.46 Episode length: 88.70 +/- 7.28 New best mean reward! Eval num_timesteps=32768, episode_reward=-0.70 +/- 0.64 Episode length: 91.70 +/- 13.19 Eval num_timesteps=40960, episode_reward=0.50 +/- 1.20 Episode length: 105.30 +/- 36.72 New best mean reward! Eval num_timesteps=49152, episode_reward=1.60 +/- 0.80 Episode length: 112.90 +/- 11.49 New best mean reward! Eval num_timesteps=57344, episode_reward=8.30 +/- 4.78 Episode length: 255.00 +/- 102.23 New best mean reward! Eval num_timesteps=65536, episode_reward=3.70 +/- 2.41 Episode length: 154.50 +/- 59.59 Eval num_timesteps=73728, episode_reward=4.70 +/- 2.53 Episode length: 164.20 +/- 45.98 Eval num_timesteps=81920, episode_reward=7.40 +/- 5.24 Episode length: 212.10 +/- 109.29 Eval num_timesteps=90112, episode_reward=21.10 +/- 3.01 Episode length: 463.70 +/- 65.06 New best mean reward! Eval num_timesteps=98304, episode_reward=16.10 +/- 8.09 Episode length: 377.40 +/- 159.12 Eval num_timesteps=106496, episode_reward=22.90 +/- 2.59 Episode length: 510.60 +/- 32.05 New best mean reward! Eval num_timesteps=114688, episode_reward=22.80 +/- 1.08 Episode length: 502.20 +/- 38.03 Eval num_timesteps=122880, episode_reward=22.40 +/- 1.91 Episode length: 489.50 +/- 29.52 Eval num_timesteps=131072, episode_reward=23.10 +/- 1.45 Episode length: 506.60 +/- 43.25 New best mean reward! Eval num_timesteps=139264, episode_reward=20.80 +/- 2.68 Episode length: 449.30 +/- 61.72 Eval num_timesteps=147456, episode_reward=23.10 +/- 1.45 Episode length: 492.70 +/- 32.17 Eval num_timesteps=155648, episode_reward=22.70 +/- 1.10 Episode length: 492.30 +/- 29.32 Eval num_timesteps=163840, episode_reward=24.00 +/- 0.89 Episode length: 489.10 +/- 44.19 New best mean reward! Eval num_timesteps=172032, episode_reward=23.00 +/- 0.63 Episode length: 457.00 +/- 56.27 Eval num_timesteps=180224, episode_reward=23.10 +/- 1.45 Episode length: 486.70 +/- 47.28 Eval num_timesteps=188416, episode_reward=21.90 +/- 1.30 Episode length: 478.80 +/- 52.28 Eval num_timesteps=196608, episode_reward=23.20 +/- 1.25 Episode length: 479.10 +/- 53.99 Eval num_timesteps=204800, episode_reward=24.20 +/- 0.75 Episode length: 499.60 +/- 45.08 New best mean reward! Eval num_timesteps=212992, episode_reward=23.80 +/- 1.47 Episode length: 499.50 +/- 44.55 Eval num_timesteps=221184, episode_reward=22.70 +/- 1.85 Episode length: 458.10 +/- 46.97 Eval num_timesteps=229376, episode_reward=22.70 +/- 1.49 Episode length: 422.00 +/- 61.13 Eval num_timesteps=237568, episode_reward=23.40 +/- 1.50 Episode length: 444.30 +/- 66.48 Eval num_timesteps=245760, episode_reward=21.70 +/- 2.41 Episode length: 438.60 +/- 65.30 Eval num_timesteps=253952, episode_reward=23.00 +/- 1.48 Episode length: 434.40 +/- 63.06 Eval num_timesteps=262144, episode_reward=23.40 +/- 2.29 Episode length: 442.10 +/- 85.72 Eval num_timesteps=270336, episode_reward=23.10 +/- 1.70 Episode length: 487.20 +/- 61.11 Eval num_timesteps=278528, episode_reward=22.90 +/- 1.81 Episode length: 442.80 +/- 71.75 Eval num_timesteps=286720, episode_reward=23.20 +/- 2.23 Episode length: 478.10 +/- 71.42 Eval num_timesteps=294912, episode_reward=23.20 +/- 1.99 Episode length: 470.80 +/- 83.41 Eval num_timesteps=303104, episode_reward=22.60 +/- 1.11 Episode length: 463.10 +/- 80.52
^ Part 3 - Playing against bots¶
Scenario presentation¶
We are now ready to tackle the task of playing Doom deathmatch against programmed bots! To play in deathmatch mode, we need a proper map with items like ammunition, health and respawn points. Using Slade, I created a simple map to train the agent on. It is designed to be easy to navigate through while still requiring some movement to find ennemies. There are 10 spawn points, several ammunition and health items. Players can increase their firepower by picking up one of the four shotguns scattered across the map. The map is contained in the bots_deathmatch_v1.wad, next to the corresponding bots_deathmatch_v1.cfg scenario config.
A game of deatchmatch consists in a session of 2:30 minutes during which 8 bots in addition of our agent will fight against each other in order to get the most frags. A "frag" corresponds to an enemy killed. Each player starts with a pistol and a couple of second of invicinbility. As soon as the agent dies, it is respawned at one of the respawn point picked uniformly at random. The actions available are the same as the difficul variant of "defend the center". That is, the agent can move, turn and shoot according to the rules we defined earlier.
The rewards here will be directly obtained from the frags obtained by the agent: 1 frag = 1 point. Note that in the case of a suicide (which can happen when using rocket launchers for example), the frag count will decrease by one. Conveniently, this will work as a penalty to discourage the agent of ending with such outcomes.

Modified environment¶
Setting up a deathmatch game requires a slightly different config for VizDoom as we need to tell it to launch a host for the multiplayer game with a couple of multiplayer-specific parameters.
We also need to adapt the environment wrapper to handle bots and the deathmatch mechanics. In particular, we need to keep track of the "frags" obtained by our agent as this constitutes our reward basis.
The cell below shows how we can adapt the environment wrapper developped so far to make it compatible for a deathmatch game. The code is pretty self-explanatory. Notice how we redefine the action space in the constructor using the button combinations. Also, to add and remove bots we use the send_game_command from the VizDoom game instance.
Important note: for the following to work, you will need to have the bots.cfg file in the same directory as the one used for execution (the notebook in this case). Otherwise, adding bots will have no effect!
from gym import spaces
from vizdoom.vizdoom import GameVariable
class DoomWithBots(envs.DoomEnv):
def __init__(self, game, frame_processor, frame_skip, n_bots):
super().__init__(game, frame_processor, frame_skip)
self.n_bots = n_bots
self.last_frags = 0
self._reset_bots()
# Redefine the action space using combinations.
self.possible_actions = get_available_actions(np.array(game.get_available_buttons()))
self.action_space = spaces.Discrete(len(possible_actions))
def step(self, action):
self.game.make_action(self.possible_actions[action], self.frame_skip)
# Compute rewards.
frags = self.game.get_game_variable(GameVariable.FRAGCOUNT)
reward = frags - self.last_frags
self.last_frags = frags
# Check for episode end.
self._respawn_if_dead()
done = self.game.is_episode_finished()
self.state = self._get_frame(done)
return self.state, reward, done, {}
def reset(self):
self._reset_bots()
self.last_frags = 0
return super().reset()
def _respawn_if_dead(self):
if not self.game.is_episode_finished():
if self.game.is_player_dead():
self.game.respawn_player()
def _reset_bots(self):
# Make sure you have the bots.cfg file next to the program entry point.
self.game.send_game_command('removebots')
for i in range(self.n_bots):
self.game.send_game_command('addbot')
The other adaptation required is to pass several game arguments via the add_game_args function when creating the actual VizDoom game instance. We also redefine the function creating vectorized environments so that it uses the newly defined wrapper.
from stable_baselines3.common.vec_env import VecTransposeImage, DummyVecEnv
def env_with_bots(scenario, **kwargs) -> envs.DoomEnv:
# Create a VizDoom instance.
game = vizdoom.DoomGame()
game.load_config(f'scenarios/{scenario}.cfg')
game.add_game_args('-host 1 -deathmatch +viz_nocheat 0 +cl_run 1 +name AGENT +colorset 0' +
'+sv_forcerespawn 1 +sv_respawnprotect 1 +sv_nocrouch 1 +sv_noexit 1') # Players can't crouch.
game.init()
return DoomWithBots(game, **kwargs)
def vec_env_with_bots(n_envs=1, **kwargs) -> VecTransposeImage:
return VecTransposeImage(DummyVecEnv([lambda: env_with_bots(**kwargs)] * n_envs))
And that's it, we have all the elements required to play Doom deathmatch! Let us define one final time the environment and agent arguments and launch the training process using our latest model.
Training an agent to play deathmatch is significantly harder than the previous scenarios we have tried so far. We will need to be patient and train for a long time.
# Define new environment parameters.
env_args = {
'scenario': 'deathmatch_simple',
'frame_skip': 4,
'frame_processor': frame_processor,
'n_bots': 8
}
# Defines new agent parameters.
agent_args = {
'n_epochs': 3,
'n_steps': 4096,
'learning_rate': 1e-4,
'batch_size': 32,
'policy_kwargs': {'features_extractor_class': CustomCNN}
}
# Create environments with bots.
env = vec_env_with_bots(4, **env_args)
eval_env = vec_env_with_bots(1, **env_args)
# Build the agent.
agent = ppo.PPO(policies.ActorCriticCnnPolicy, env, tensorboard_log='logs/tensorboard', seed=0, **agent_args)
init_model(agent)
# Create callbacks.
monitoring_callback = LayerActivationMonitoring()
eval_callback = EvalCallback(
eval_env,
n_eval_episodes=10,
eval_freq=16384,
log_path=f'logs/evaluations/{env_args["scenario"]}',
best_model_save_path=f'logs/models/{env_args["scenario"]}')
# Start the training process.
agent.learn(total_timesteps=3000000, tb_log_name=env_args['scenario'], callback=[monitoring_callback, eval_callback])
# Cleanup.
env.close()
eval_env.close()
Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_RIGHT: 14> <Button.TURN_LEFT: 15>] Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_RIGHT: 14> <Button.TURN_LEFT: 15>] Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_RIGHT: 14> <Button.TURN_LEFT: 15>] Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_RIGHT: 14> <Button.TURN_LEFT: 15>] Built action space of size 18 from buttons [<Button.ATTACK: 0> <Button.MOVE_FORWARD: 13> <Button.MOVE_LEFT: 11> <Button.MOVE_RIGHT: 10> <Button.TURN_RIGHT: 14> <Button.TURN_LEFT: 15>] Eval num_timesteps=65536, episode_reward=0.30 +/- 0.46 Episode length: 1257.50 +/- 11.60 New best mean reward! Eval num_timesteps=131072, episode_reward=0.30 +/- 0.46 Episode length: 1261.40 +/- 5.78 Eval num_timesteps=196608, episode_reward=0.10 +/- 0.30 Episode length: 1266.40 +/- 11.50 Eval num_timesteps=262144, episode_reward=0.50 +/- 0.67 Episode length: 1263.20 +/- 17.54 New best mean reward! Eval num_timesteps=327680, episode_reward=0.40 +/- 0.49 Episode length: 1264.50 +/- 11.59 Eval num_timesteps=393216, episode_reward=0.50 +/- 0.92 Episode length: 1252.40 +/- 12.31 Eval num_timesteps=458752, episode_reward=0.90 +/- 0.70 Episode length: 1253.30 +/- 12.44 New best mean reward! Eval num_timesteps=524288, episode_reward=0.20 +/- 0.40 Episode length: 1253.70 +/- 13.35 Eval num_timesteps=589824, episode_reward=0.40 +/- 0.66 Episode length: 1257.40 +/- 13.81 Eval num_timesteps=655360, episode_reward=1.00 +/- 0.89 Episode length: 1257.60 +/- 14.04 New best mean reward! Eval num_timesteps=720896, episode_reward=0.50 +/- 0.50 Episode length: 1250.30 +/- 15.60 Eval num_timesteps=786432, episode_reward=0.50 +/- 0.67 Episode length: 1262.00 +/- 15.26 Eval num_timesteps=851968, episode_reward=0.70 +/- 0.64 Episode length: 1255.10 +/- 18.52 Eval num_timesteps=917504, episode_reward=0.60 +/- 0.66 Episode length: 1253.70 +/- 14.26 Eval num_timesteps=983040, episode_reward=1.10 +/- 0.70 Episode length: 1257.00 +/- 10.93 New best mean reward! Eval num_timesteps=1048576, episode_reward=0.60 +/- 0.80 Episode length: 1260.10 +/- 12.91 Eval num_timesteps=1114112, episode_reward=0.50 +/- 0.67 Episode length: 1249.00 +/- 15.59 Eval num_timesteps=1179648, episode_reward=0.50 +/- 0.50 Episode length: 1247.60 +/- 16.48 Eval num_timesteps=1245184, episode_reward=0.30 +/- 0.46 Episode length: 1249.00 +/- 10.86 Eval num_timesteps=1310720, episode_reward=1.10 +/- 1.30 Episode length: 1256.90 +/- 11.24 Eval num_timesteps=1376256, episode_reward=0.70 +/- 0.90 Episode length: 1254.10 +/- 9.33 Eval num_timesteps=1441792, episode_reward=1.50 +/- 1.20 Episode length: 1258.10 +/- 13.02 New best mean reward! Eval num_timesteps=1507328, episode_reward=0.90 +/- 0.83 Episode length: 1257.70 +/- 16.12 Eval num_timesteps=1572864, episode_reward=1.10 +/- 0.70 Episode length: 1261.80 +/- 11.75 Eval num_timesteps=1638400, episode_reward=0.90 +/- 1.04 Episode length: 1255.10 +/- 10.50 Eval num_timesteps=1703936, episode_reward=0.60 +/- 0.80 Episode length: 1246.20 +/- 12.46 Eval num_timesteps=1769472, episode_reward=1.30 +/- 1.10 Episode length: 1256.10 +/- 12.45 Eval num_timesteps=1835008, episode_reward=1.60 +/- 1.62 Episode length: 1249.80 +/- 9.61 New best mean reward! Eval num_timesteps=1900544, episode_reward=1.40 +/- 1.02 Episode length: 1258.50 +/- 15.84 Eval num_timesteps=1966080, episode_reward=2.10 +/- 0.94 Episode length: 1254.70 +/- 13.51 New best mean reward! Eval num_timesteps=2031616, episode_reward=1.60 +/- 1.02 Episode length: 1251.80 +/- 12.52 Eval num_timesteps=2097152, episode_reward=2.70 +/- 1.27 Episode length: 1252.60 +/- 11.96 New best mean reward! Eval num_timesteps=2162688, episode_reward=1.90 +/- 1.14 Episode length: 1253.00 +/- 13.01 Eval num_timesteps=2228224, episode_reward=1.90 +/- 1.14 Episode length: 1255.30 +/- 10.67 Eval num_timesteps=2293760, episode_reward=2.20 +/- 1.33 Episode length: 1252.70 +/- 8.01 Eval num_timesteps=2359296, episode_reward=2.30 +/- 1.27 Episode length: 1262.00 +/- 9.62 Eval num_timesteps=2424832, episode_reward=1.60 +/- 1.36 Episode length: 1252.70 +/- 12.53 Eval num_timesteps=2490368, episode_reward=1.50 +/- 1.43 Episode length: 1259.30 +/- 11.29 Eval num_timesteps=2555904, episode_reward=3.00 +/- 1.90 Episode length: 1255.00 +/- 12.29 New best mean reward! Eval num_timesteps=2621440, episode_reward=2.60 +/- 1.50 Episode length: 1252.20 +/- 11.53 Eval num_timesteps=2686976, episode_reward=2.20 +/- 1.54 Episode length: 1258.20 +/- 13.07 Eval num_timesteps=2752512, episode_reward=3.90 +/- 1.58 Episode length: 1256.80 +/- 8.28 New best mean reward! Eval num_timesteps=2818048, episode_reward=2.90 +/- 1.70 Episode length: 1250.50 +/- 11.56 Eval num_timesteps=2883584, episode_reward=2.30 +/- 1.35 Episode length: 1242.40 +/- 14.11 Eval num_timesteps=2949120, episode_reward=3.50 +/- 1.36 Episode length: 1256.70 +/- 12.78 Eval num_timesteps=3014656, episode_reward=2.70 +/- 1.55 Episode length: 1248.90 +/- 16.13
So, how did the agent perform? Plotting the average reward over time depicts a tragic situation: although there seems to be some improvement over time, the performance of our model is really not great. Even after 2 million steps the agent barely reaches 2 frags per match on average. Compare that to the best bot which has around 13 frags at the end of each game and our objective seem still pretty far away.
plotting.plot_evaluation_results('logs/evaluations/deathmatch_simple/evaluations.npz')

Discussion¶
So the learning process did not go as smoothly as one could have expected. Why is that?
The issue lies in the fact that the rewards are very sparse. In other words, only a few combinations of state and action generate useful signals that our agent can use for learning. Indeed, to obtain a frag, the agent has to perform several steps "just right". It has to move and track ennemies, repeatedly shoot them until eventually their health reaches zero.
The way to solve this issue is by means of "reward shaping". The idea is simple: give small positive reward to action that we believe will help towards our main objective of obtaining frags. For example, we can give rewards proportional to damage inflicted to ennemies or proportional to the ammo and health collected.
Another option to help with the learning process is to design some learning curriculum. The idea here is to simplify the task early in the learning process and gradually increase the difficulty. For example, we could reduce the speed and the health of ennemies to make it easier for our agent to obtain positive rewards.
We will implement these ideas in the next part of this series to get much better results so stay tuned!