12. 넘파이 패키지¶
12.1 array, numpy, matplotlib 패키지 개요¶
12.1.1 array 패키지¶
12.1.2 numpy 패키지¶
12.1.3 numpy.random 패키지¶
12.1.4 matplotlib 패키지¶
12.2 “array” 패키지 사용하기¶

array 패키지
- 개념적으로 numpy 작동 원리의 기반을 제공
- 1차원 배열만 지원
- python을 설치할 때 기본적으로 존재하는 패키지
일반적인 array(배열)의 특징
- 인덱스(색인 번호)로 각 항목을 참조
- 고정 길이 데이터 구조
- 데이터의 모든 항목이 메모리상에 연속적으로 서로 옆에 존재

형 코드 |
C 형 |
파이썬 형 |
사이즈(바이트) |
|---|---|---|---|
|
signed char |
int |
1 |
|
unsigned char |
int |
1 |
|
wchar_t |
유니코드 문자 |
2 |
|
signed short |
int |
2 |
|
unsigned short |
int |
2 |
|
signed int |
int |
2 |
|
unsigned int |
int |
2 |
|
signed long |
int |
4 |
|
unsigned long |
int |
4 |
|
signed long long |
int |
8 |
|
unsigned long long |
int |
8 |
|
float |
float |
4 |
|
double |
float |
8 |
- array vs. list
In [2]:
import array
In [3]:
a = array.array('h', [1, 2, 3])
a
Out[3]:
array('h', [1, 2, 3])
In [4]:
a = array.array('h', range(100))
a
Out[4]:
array('h', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99])
In [5]:
a = array.array('h', range(1_000_000))
--------------------------------------------------------------------------- OverflowError Traceback (most recent call last) <ipython-input-5-1c7dba2802df> in <module> ----> 1 a = array.array('h', range(1_000_000)) OverflowError: signed short integer is greater than maximum
In [6]:
a = array.array('l', range(1_000_000))
12.4 numpy 소개하기: 1부터 100만까지 더하기¶
- numpy에 의하여 생성되는 모든 데이터들의 타입은 ndarray 라고 함
- ndarray: n-dimensional array
In [7]:
import numpy as np
In [8]:
a_list = list(range(1, 1_000_001))
print(sum(a_list))
500000500000
In [9]:
a = np.arange(1, 1_000_001)
print(sum(a))
500000500000
In [10]:
import numpy as np
from time import time
def benchmarks(n):
t1 = time()
a_list = list(range(1, n + 1)) # Old style!
tot = sum(a_list)
t2 = time()
elapsed_time_1 = t2 - t1
print('Time taken by Python is {0:6.4f}'.format(elapsed_time_1))
t1 = time()
a = np.arange(1, n + 1) # Numpy!
tot = np.sum(a)
t2 = time()
elapsed_time_2 = t2 - t1
print('Time taken by numpy is {0:6.4f}'.format(t2 - t1))
print('{0:5.3f}배의 시간 차이 발생!!!'.format(elapsed_time_1 / elapsed_time_2))
In [11]:
benchmarks(10_000_000)
Time taken by Python is 0.3095 Time taken by numpy is 0.0445 6.949배의 시간 차이 발생!!!
12.5 numpy 배열 만들기¶


12.5.1 array 함수 (array로 변환)¶
numpy.arrayis a function that returns anumpy.ndarray.- There is no object type numpy.array.
In [31]:
import numpy as np
1차원 ndarray 생성¶
In [35]:
a = np.array([1, 2, 3], dtype=np.int64)
print(a)
print(type(a))
[1 2 3] <class 'numpy.ndarray'>
In [39]:
print("-" * 80)
print("{0:>10}: {1}".format("a.T", a.T))
print("{0:>10}: {1}".format("a.data", a.data))
print("{0:>10}: {1}".format("a.dtype", a.dtype))
print("{0:>10}: {1}".format("a.flat", a.flat)) # A 1-D iterator over the array
--------------------------------------------------------------------------------
a.T: [1 2 3]
a.data: <memory at 0x7f8cb01831c8>
a.dtype: int64
a.flat: <numpy.flatiter object at 0x7f8cdf85aa00>
In [40]:
print("{0:>10}: {1}".format("a.imag", a.imag))
print("{0:>10}: {1}".format("a.real", a.real))
a.imag: [0 0 0]
a.real: [1 2 3]
In [41]:
print("{0:>10}: {1}".format("a.size", a.size))
print("{0:>10}: {1}".format("a.itemsize", a.itemsize)) # Length of one array element in bytes
print("{0:>10}: {1}".format("a.nbytes", a.nbytes)) # Number of elements in the array
a.size: 3 a.itemsize: 8 a.nbytes: 24
- 중요!!! (암기해야할 속성: ndim, shape)
In [44]:
print("{0:>10}: {1}".format("a.ndim", a.ndim)) # Number of array dimensions.
print("{0:>10}: {1}".format("a.shape", a.shape)) # Tuple of array dimensions.
a.ndim: 1 a.shape: (3,)
In [43]:
print("{0:>10}: {1}".format("a.strides", a.strides)) # Tuple of bytes to step in each dimension when traversing an array.
print("{0:>10}: {1}".format("a.ctypes", a.ctypes)) # An object to simplify the interaction of the array with the ctypes module
print("{0:>10}: {1}".format("a.base", a.base)) # Base object if memory is from some other object
print("{0:>10}:==>\n{1}".format("a.flags", a.flags))
a.strides: (8,)
a.ctypes: <numpy.core._internal._ctypes object at 0x7f8cc0fce6a0>
a.base: None
a.flags:==>
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
2차원 ndarray 생성¶
In [45]:
a = np.array([[1, 2, 3], [10, 20, 30], [0, 0, -1]])
print(a)
print(type(a))
[[ 1 2 3] [10 20 30] [ 0 0 -1]] <class 'numpy.ndarray'>
In [46]:
print("-" * 80)
print("{0:>10}: {1}".format("a.T", a.T))
print("{0:>10}: {1}".format("a.data", a.data))
print("{0:>10}: {1}".format("a.dtype", a.dtype))
print("{0:>10}: {1}".format("a.flat", a.flat)) # A 1-D iterator over the array
--------------------------------------------------------------------------------
a.T: [[ 1 10 0]
[ 2 20 0]
[ 3 30 -1]]
a.data: <memory at 0x7f8cb01861f8>
a.dtype: int64
a.flat: <numpy.flatiter object at 0x7f8d1f855600>
In [47]:
print("{0:>10}: {1}".format("a.imag", a.imag))
print("{0:>10}: {1}".format("a.real", a.real))
a.imag: [[0 0 0]
[0 0 0]
[0 0 0]]
a.real: [[ 1 2 3]
[10 20 30]
[ 0 0 -1]]
In [48]:
print("{0:>10}: {1}".format("a.size", a.size))
print("{0:>10}: {1}".format("a.itemsize", a.itemsize)) # Length of one array element in bytes
print("{0:>10}: {1}".format("a.nbytes", a.nbytes)) # Number of elements in the array
a.size: 9 a.itemsize: 8 a.nbytes: 72
- 중요!!! (암기해야할 속성: ndim, shape)
In [49]:
print("{0:>10}: {1}".format("a.ndim", a.ndim)) # Number of array dimensions.
print("{0:>10}: {1}".format("a.shape", a.shape)) # Tuple of array dimensions.
a.ndim: 2 a.shape: (3, 3)
In [50]:
print("{0:>10}: {1}".format("a.strides", a.strides)) # Tuple of bytes to step in each dimension when traversing an array.
print("{0:>10}: {1}".format("a.ctypes", a.ctypes)) # An object to simplify the interaction of the array with the ctypes module
print("{0:>10}: {1}".format("a.base", a.base)) # Base object if memory is from some other object
print("{0:>10}:==>\n{1}".format("a.flags", a.flags))
a.strides: (24, 8)
a.ctypes: <numpy.core._internal._ctypes object at 0x7f8cc0fce630>
a.base: None
a.flags:==>
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
In [12]:
a = np.array([[1, 2, 3], [10, 20, 300]])
a
Out[12]:
array([[ 1, 2, 3],
[ 10, 20, 300]])
- 가지런하지 않은 배열 형태로 생성될 때 각 원소는 object 타입 (실제로는 list)이 된다.
In [13]:
a = np.array([[1, 2, 3], [10, 20, 300, 4]])
a
C:\Users\gilbut\anaconda3\lib\site-packages\ipykernel_launcher.py:1: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray """Entry point for launching an IPython kernel.
Out[13]:
array([list([1, 2, 3]), list([10, 20, 300, 4])], dtype=object)
12.5.2 arange 함수¶
In [51]:
import numpy as np
a = np.arange(1, 1000001) # 100만개 항목으로 구성된 배열 생성
12.5.3 linspace 함수¶
In [57]:
import numpy as np
a = np.linspace(0, 1.0, num=5)
a
Out[57]:
array([0. , 0.25, 0.5 , 0.75, 1. ])
In [58]:
import numpy as np
a = np.linspace(0, 1.0, num=5, endpoint=False)
a
Out[58]:
array([0. , 0.2, 0.4, 0.6, 0.8])
In [16]:
a = np.linspace(0, 1.0, num=6)
a
Out[16]:
array([0. , 0.2, 0.4, 0.6, 0.8, 1. ])
In [54]:
a = np.linspace(1, 5, num=5, dtype=np.int16)
a
Out[54]:
array([1, 2, 3, 4, 5], dtype=int16)
In [55]:
a = np.linspace(0, 1.0, num=6, dtype=np.int16)
a
Out[55]:
array([0, 0, 0, 0, 0, 1], dtype=int16)
12.5.4 empty 함수¶
- https://numpy.org/doc/stable/reference/generated/numpy.empty.html
- 초기화되지 않은 (결국 쓰레기값을 지닌) ndarray 생성
In [18]:
import numpy as np
a = np.empty((2, 2), dtype='int16')
a
Out[18]:
array([[ 0, 0],
[ 0, 16368]], dtype=int16)
In [19]:
a = np.empty((3, 2), dtype='float32')
a
Out[19]:
array([[3.3454865e+31, 8.6880505e-43],
[0.0000000e+00, 0.0000000e+00],
[1.8367379e-40, nan]], dtype=float32)
In [37]:
a = np.eye(N=4, dtype='int')
a
Out[37]:
array([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
In [38]:
a = np.eye(N=6)
a
Out[38]:
array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.]])
In [39]:
import numpy as np
a = np.ones(shape=(3, 3))
a
Out[39]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
In [41]:
a = np.ones(shape=(2, 2, 3), dtype=np.int16)
a
Out[41]:
array([[[1, 1, 1],
[1, 1, 1]],
[[1, 1, 1],
[1, 1, 1]]], dtype=int16)
In [42]:
a = np.ones(shape=6, dtype=np.bool)
a
Out[42]:
array([ True, True, True, True, True, True])
In [25]:
import numpy as np
a = np.zeros((3,3))
a
Out[25]:
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
In [26]:
a = np.zeros((2, 2, 3), dtype=np.int16)
a
Out[26]:
array([[[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0]]], dtype=int16)
In [27]:
a = np.zeros(5, dtype=np.bool)
a
Out[27]:
array([False, False, False, False, False])
In [28]:
import numpy as np
a = np.full((2, 2), 3.14)
a
Out[28]:
array([[3.14, 3.14],
[3.14, 3.14]])
In [29]:
a = np.full(8, 100)
a
Out[29]:
array([100, 100, 100, 100, 100, 100, 100, 100])
In [59]:
a = np.full(5,'ken')
a
Out[59]:
array(['ken', 'ken', 'ken', 'ken', 'ken'], dtype='<U3')
In [60]:
a[0] = 'tommy'
a[0]
Out[60]:
'tom'
In [61]:
a
Out[61]:
array(['tom', 'ken', 'ken', 'ken', 'ken'], dtype='<U3')
12.5.9 copy 함수¶
- ndarray의 copy에서는 깊은 복사와 얕은 복사가 동일. 즉 두 개의 구분이 필요없음
In [32]:
import numpy as np
b_arr = np.copy(a)
b_arr
Out[32]:
array(['tom', 'ken', 'ken', 'ken', 'ken'], dtype='<U3')
12.5.10 fromfunction 함수¶
- https://numpy.org/doc/stable/reference/generated/numpy.fromfunction.html?highlight=fromfunction#numpy.fromfunction
- Construct an array by executing a function over each coordinate
- 좌표값이 함수에 들어가면서 값이 생성됨
In [14]:
import numpy as np
def simple(n):
return n + 1
a = np.fromfunction(function=simple, shape=(5,), dtype='int32')
a
Out[14]:
array([1, 2, 3, 4, 5], dtype=int32)
In [15]:
a = np.fromfunction(function=lambda n: n + 1, shape=(5,), dtype='int32')
a
Out[15]:
array([1, 2, 3, 4, 5], dtype=int32)
In [16]:
def add_it(r, c):
return r + c
a = np.fromfunction(function=add_it, shape=(3, 3), dtype='int32')
a
Out[16]:
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]], dtype=int32)
In [21]:
a = np.fromfunction(function=lambda r, c: r + c, shape=(3, 3), dtype='int')
a
Out[21]:
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
In [24]:
a = np.fromfunction(function=lambda _, r, c: r + c, shape=(2, 3, 3), dtype='int')
a
Out[24]:
array([[[0, 1, 2],
[1, 2, 3],
[2, 3, 4]],
[[0, 1, 2],
[1, 2, 3],
[2, 3, 4]]])

- 3D ndarray을 생성할 때, shape=(i, j, k)의 의미는 다음과 같은 x축, y축, z축에 대하여 (z축, y축, x축)으로 대응된다.


12.6 예시: 곱셈표 만들기¶
In [29]:
import numpy as np
def multy(r, c):
return (r + 1) * (c + 1)
a = np.fromfunction(function=multy, shape=(10, 10), dtype=np.int16)
print(a)
[[ 1 2 3 4 5 6 7 8 9 10] [ 2 4 6 8 10 12 14 16 18 20] [ 3 6 9 12 15 18 21 24 27 30] [ 4 8 12 16 20 24 28 32 36 40] [ 5 10 15 20 25 30 35 40 45 50] [ 6 12 18 24 30 36 42 48 54 60] [ 7 14 21 28 35 42 49 56 63 70] [ 8 16 24 32 40 48 56 64 72 80] [ 9 18 27 36 45 54 63 72 81 90] [ 10 20 30 40 50 60 70 80 90 100]]
In [30]:
a = np.fromfunction(function=lambda r, c: (r + 1) * (c + 1), shape=(10, 10), dtype=np.int16)
print(a)
[[ 1 2 3 4 5 6 7 8 9 10] [ 2 4 6 8 10 12 14 16 18 20] [ 3 6 9 12 15 18 21 24 27 30] [ 4 8 12 16 20 24 28 32 36 40] [ 5 10 15 20 25 30 35 40 45 50] [ 6 12 18 24 30 36 42 48 54 60] [ 7 14 21 28 35 42 49 56 63 70] [ 8 16 24 32 40 48 56 64 72 80] [ 9 18 27 36 45 54 63 72 81 90] [ 10 20 30 40 50 60 70 80 90 100]]
In [31]:
s = str(a)
s = s.replace('[', '')
s = s.replace(']', '')
s = ' ' + s
In [32]:
print(s)
1 2 3 4 5 6 7 8 9 10 2 4 6 8 10 12 14 16 18 20 3 6 9 12 15 18 21 24 27 30 4 8 12 16 20 24 28 32 36 40 5 10 15 20 25 30 35 40 45 50 6 12 18 24 30 36 42 48 54 60 7 14 21 28 35 42 49 56 63 70 8 16 24 32 40 48 56 64 72 80 9 18 27 36 45 54 63 72 81 90 10 20 30 40 50 60 70 80 90 100
12.7 numpy 배열의 배치 연산¶



In [33]:
import numpy as np
A = np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]])
A
Out[33]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [34]:
A = np.arange(16).reshape((4, 4))
A
Out[34]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
In [35]:
A = np.fromfunction(function=lambda r, c: r * 4 + c, shape=(4, 4))
A
Out[35]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]])
In [43]:
B = np.eye(4, dtype='int16')
print(B)
[[1 0 0 0] [0 1 0 0] [0 0 1 0] [0 0 0 1]]
In [44]:
C = A * 10
print(C)
[[ 0. 10. 20. 30.] [ 40. 50. 60. 70.] [ 80. 90. 100. 110.] [120. 130. 140. 150.]]
In [46]:
C = A * A
print(C)
[[ 0. 1. 4. 9.] [ 16. 25. 36. 49.] [ 64. 81. 100. 121.] [144. 169. 196. 225.]]
In [47]:
print(C.reshape((2, 8)))
[[ 0. 1. 4. 9. 16. 25. 36. 49.] [ 64. 81. 100. 121. 144. 169. 196. 225.]]
In [48]:
print(C)
[[ 0. 1. 4. 9.] [ 16. 25. 36. 49.] [ 64. 81. 100. 121.] [144. 169. 196. 225.]]
In [49]:
A
Out[49]:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]])
In [50]:
C = A * B
print(C)
[[ 0. 0. 0. 0.] [ 0. 5. 0. 0.] [ 0. 0. 10. 0.] [ 0. 0. 0. 15.]]
12.8 numpy의 조각을 정렬하기¶
In [51]:
A = np.arange(1, 11)
print(A)
[ 1 2 3 4 5 6 7 8 9 10]
In [52]:
print(A[2:5])
[3 4 5]
In [53]:
A[2:5] = 0
print(A)
[ 1 2 0 0 0 6 7 8 9 10]
In [54]:
A[2:5] += 100
print(A)
[ 1 2 100 100 100 6 7 8 9 10]
In [55]:
A = np.arange(1, 11)
A[2:5] *= [100, 200, 300]
A
Out[55]:
array([ 1, 2, 300, 800, 1500, 6, 7, 8, 9, 10])
In [56]:
A = np.arange(51)
print(A)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50]
In [57]:
A[1] = 0
A[2 * 2::2] = 0
print(A)
[ 0 0 2 3 0 5 0 7 0 9 0 11 0 13 0 15 0 17 0 19 0 21 0 23 0 25 0 27 0 29 0 31 0 33 0 35 0 37 0 39 0 41 0 43 0 45 0 47 0 49 0]
In [58]:
A[3 * 3::3] = 0
print(A)
[ 0 0 2 3 0 5 0 7 0 0 0 11 0 13 0 0 0 17 0 19 0 0 0 23 0 25 0 0 0 29 0 31 0 0 0 35 0 37 0 0 0 41 0 43 0 0 0 47 0 49 0]
In [59]:
A[5 * 5::5] = 0
A[7 * 7::7] = 0
print(A)
[ 0 0 2 3 0 5 0 7 0 0 0 11 0 13 0 0 0 17 0 19 0 0 0 23 0 0 0 0 0 29 0 31 0 0 0 0 0 37 0 0 0 41 0 43 0 0 0 47 0 0 0]
In [62]:
my_prime_list = [i for i in A if i > 0]
my_prime_list
Out[62]:
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
- Boolean Numpy Array
- 임의의 Numpy 배열 A의 인덱싱 연산에 활용되어 A 자체에 마스크(mask)로 적용
In [61]:
A > 0
Out[61]:
array([False, False, True, True, False, True, False, True, False,
False, False, True, False, True, False, False, False, True,
False, True, False, False, False, True, False, False, False,
False, False, True, False, True, False, False, False, False,
False, True, False, False, False, True, False, True, False,
False, False, True, False, False, False])
In [100]:
P = A[A > 0]
print(P)
[ 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47]
12.9 다차원 슬라이싱¶

In [63]:
A = np.arange(1, 17).reshape((4, 4))
print(A)
[[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12] [13 14 15 16]]
In [64]:
print(A[1:3])
[[ 5 6 7 8] [ 9 10 11 12]]
In [65]:
A[:, 1:3]
Out[65]:
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])
In [66]:
G = np.zeros((6, 6))
G[1:4, 2] = 1
print(G)
[[0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0.] [0. 0. 1. 0. 0. 0.] [0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0.]]
In [67]:
print(G[1:4, 1:4])
[[0. 1. 0.] [0. 1. 0.] [0. 1. 0.]]
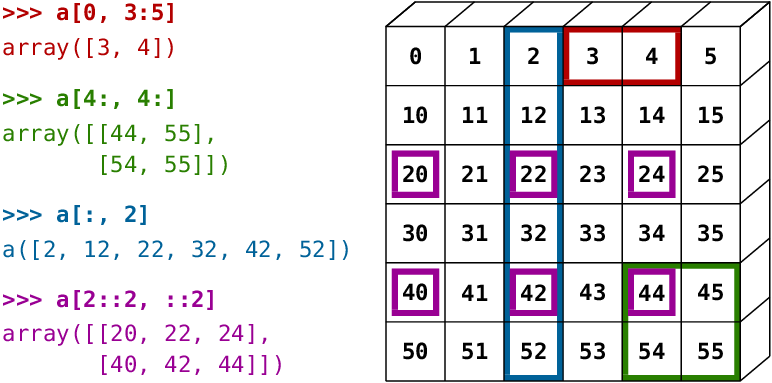
12.10 불리언 배열: 넘파이에 마스킹하기!¶
In [68]:
B = np.arange(1,10).reshape(3,3)
print(B)
[[1 2 3] [4 5 6] [7 8 9]]
In [69]:
B1 = B > 4
B1
Out[69]:
array([[False, False, False],
[False, True, True],
[ True, True, True]])
In [70]:
print(B * (B > 4))
[[0 0 0] [0 5 6] [7 8 9]]
In [71]:
print(B[B > 7])
[8 9]
In [72]:
print(B[B % 3 == 1])
[1 4 7]
In [79]:
B2 = (B > 2) & (B < 7) # "AND" 연산
print(B2)
[[False False True] [ True True True] [False False False]]
In [80]:
print(B)
[[1 2 3] [4 5 6] [7 8 9]]
In [77]:
print(B[B2])
[3 4 5 6]
In [84]:
B3 = B > 3
print(B3)
[[False False False] [ True True True] [ True True True]]
In [85]:
print(B[B3])
[4 5 6 7 8 9]
In [86]:
print(B[ (B == 1) | (B > 6)]) # ‘OR’ 연산자
[1 7 8 9]
12.11 numpy와 에라토스테네스의 체¶

In [114]:
def sieve(n):
b_list = [True] * (n + 1)
b_list[0:2] = [False, False] # 일반 파이썬 리스트에서 슬라이싱 할당은 동일 사이즈로만 가능
for i in range(2, n+1):
if b_list[i]:
for j in range(i*i, n+1, i):
b_list[j] = False
primes = [i for i in range(2, n+1) if b_list[i]]
return primes
In [115]:
sieve(50)
Out[115]:
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47]
In [116]:
import numpy as np
def np_sieve(n):
# B 생성, 모든 항목을 True로 설정한다.
B = np.ones(n + 1, dtype=np.bool)
B[0:2] = False
for i in range(2, n + 1):
if B[i]:
B[i*i: n+1: i] = False
return np.arange(n + 1)[B]
In [117]:
np_sieve(50)
Out[117]:
array([ 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47])
In [118]:
import time
- 1000까지 소수 검출 속도 비교
In [119]:
t1 = time.time() * 1000
sieve(1_000)
t2 = time.time() * 1000
print('sieve took', t2-t1, 'milliseconds.')
sieve took 0.22509765625 milliseconds.
In [120]:
t1 = time.time() * 1000
np_sieve(1_000)
t2 = time.time() * 1000
print('np_sieve took', t2-t1, 'milliseconds.')
np_sieve took 0.264892578125 milliseconds.
- 10000000 까지 소수 검출 속도 비교
In [121]:
t1 = time.time() * 1000
sieve(10_000_000)
t2 = time.time() * 1000
print('sieve took', t2-t1, 'milliseconds.')
sieve took 2546.77978515625 milliseconds.
In [122]:
t1 = time.time() * 1000
np_sieve(10_000_000)
t2 = time.time() * 1000
print('np_sieve took', t2-t1, 'milliseconds.')
np_sieve took 896.49658203125 milliseconds.
12.12 numpy 통계 구하기 – 표준 편차¶

In [6]:
import numpy as np
import numpy.random as ran
A = ran.rand(10)
print(A)
print(A.shape)
[0.33973737 0.16864527 0.39474274 0.42710631 0.86438432 0.67152607 0.00672403 0.1244622 0.13069404 0.80049644] (10,)
In [7]:
A = ran.rand(3, 3)
print(A)
print(A.shape)
[[0.90879311 0.61971292 0.16838488] [0.10881478 0.69499699 0.07213863] [0.57432973 0.93496149 0.17358513]] (3, 3)
In [8]:
A = ran.rand(3, 3, 3)
print(A)
print(A.shape)
[[[0.47952324 0.50679153 0.38142121] [0.18419655 0.98121221 0.35026395] [0.66970099 0.80612869 0.46596528]] [[0.41454809 0.39191325 0.52940041] [0.23523159 0.26554211 0.40562865] [0.14930301 0.94267647 0.96713257]] [[0.42923939 0.36459349 0.31501216] [0.36935727 0.25893938 0.42838482] [0.23286462 0.98129982 0.1953949 ]]] (3, 3, 3)
In [9]:
import numpy as np
import numpy.random as ran
A = ran.random(100_000)
np.mean(A)
Out[9]:
0.5018404494269068
In [10]:
np.sum(A)
Out[10]:
50184.04494269068
In [11]:
np.median(A)
Out[11]:
0.5033012753071466
In [12]:
np.std(A)
Out[12]:
0.28889654605996534
In [13]:
A = ran.rand(3, 3, 3)
print(A)
print(A.shape)
print(np.mean(A))
print(np.sum(A))
print(np.median(A))
print(np.std(A))
[[[0.37179968 0.04861112 0.75513961] [0.87322301 0.3392253 0.51569713] [0.17456649 0.37514481 0.04819507]] [[0.35481209 0.3042816 0.71001006] [0.58083898 0.88110883 0.56928942] [0.41816889 0.92267971 0.56071293]] [[0.22542938 0.57968216 0.08112255] [0.77211739 0.54911936 0.86319039] [0.86337074 0.45191001 0.4027625 ]]] (3, 3, 3) 0.5034151561065233 13.59220921487613 0.5156971294015305 0.2606589044496662
In [113]:
import numpy as np
import time
import numpy.random as ran
def get_std1(ls):
t1 = time.time()
m = sum(ls)/len(ls)
ls2 = [(i - m) ** 2 for i in ls]
sd = (sum(ls2)/len(ls2)) ** .5
t2 = time.time()
print('Python took', t2-t1)
def get_std2(A):
t1 = time.time()
A2 = (A - np.mean(A)) ** 2
result = (np.mean(A2)) ** .5
t2 = time.time()
print('Numpy took', t2-t1)
def get_std3(A):
t1 = time.time()
result = np.std(A)
t2 = time.time()
print('np.std took', t2-t1)
A = ran.rand(1_000_000)
get_std1(A)
get_std2(A)
get_std3(A)
Python took 0.42522501945495605 Numpy took 0.002130746841430664 np.std took 0.005688905715942383
12.13 numpy 행과 열 가져오기¶
numpy.random.randint¶
- https://numpy.org/doc/stable/reference/random/generated/numpy.random.randint.html
- Return random integers from low (inclusive) to high (exclusive).
In [16]:
import numpy as np
import numpy.random as ran
A = ran.randint(low=1, high=20, size=(3, 4))
print(A)
[[16 9 16 19] [18 18 3 11] [14 18 17 3]]
In [17]:
np.mean(A)
Out[17]:
13.5
In [18]:
np.sum(A)
Out[18]:
162
In [19]:
np.std(A) # 표준 편차
Out[19]:
5.5
In [20]:
B = np.fromfunction(lambda r,c: c, (4, 5), dtype=np.int32)
print(B)
[[0 1 2 3 4] [0 1 2 3 4] [0 1 2 3 4] [0 1 2 3 4]]
- sum() & axis



- Axis or axes along which a sum is performed.
In [21]:
np.sum(B, axis=0) # 행 기준 합계 --> 각 열의 합계 --> 연산 결과 벡터 내 원소 개수는 열의 개수와 동일
Out[21]:
array([ 0, 4, 8, 12, 16])
In [22]:
np.sum(B, axis=1) # 열 기준 합계 --> 각 행의 합계 --> 연산 결과 벡터 내 원소 개수는 행의 개수와 동일
Out[22]:
array([10, 10, 10, 10])
- 2차원 배열에 1차원 배열을 새로운 열(column)로 붙이기
- np.c_
In [141]:
B
Out[141]:
array([[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]], dtype=int32)
In [38]:
B_sum_col = np.sum(B, axis=1)
B_sum_col
Out[38]:
array([10, 10, 10, 10])
In [39]:
print(B.shape, B_sum_col.shape)
(4, 5) (4,)
In [40]:
B1 = np.c_[B, B_sum_col]
print(B1)
[[ 0 1 2 3 4 10] [ 0 1 2 3 4 10] [ 0 1 2 3 4 10] [ 0 1 2 3 4 10]]
- 2차원 배열에 1차원 배열을 새로운 행(row)으로 붙이기
- np.r_
In [41]:
B_sum_row = np.sum(B1, axis=0)
B_sum_row
Out[41]:
array([ 0, 4, 8, 12, 16, 40])
In [42]:
print(B1.shape, B_sum_row.shape)
(4, 6) (6,)
In [43]:
B2 = np.r_[B1, [B_sum_row]]
print(B2)
[[ 0 1 2 3 4 10] [ 0 1 2 3 4 10] [ 0 1 2 3 4 10] [ 0 1 2 3 4 10] [ 0 4 8 12 16 40]]
In [46]:
def spreadsheet(A):
AC = np.sum(A, axis=1)
A2 = np.c_[A, AC]
AR = np.sum(A2, axis=0)
return np.r_[A2, [AR]]
In [47]:
arr = np.arange(15).reshape(3, 5)
print(arr)
[[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]]
In [48]:
print(spreadsheet(arr))
[[ 0 1 2 3 4 10] [ 5 6 7 8 9 35] [ 10 11 12 13 14 60] [ 15 18 21 24 27 105]]
- hstack, vstack
In [57]:
B, B.shape
Out[57]:
(array([[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]], dtype=int32),
(4, 5))
In [58]:
B_sum_col = np.sum(B, axis=1)
B_sum_col
Out[58]:
array([10, 10, 10, 10])
In [59]:
B.shape, B_sum_col.shape
Out[59]:
((4, 5), (4,))
In [60]:
B_sum_col = np.expand_dims(B_sum_col, axis=1)
In [61]:
B.shape, B_sum_col.shape
Out[61]:
((4, 5), (4, 1))
In [62]:
B1 = np.hstack([B, B_sum_col])
B1, B1.shape
Out[62]:
(array([[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10]]),
(4, 6))

In [63]:
B_sum_row = np.sum(B1, axis=0)
B_sum_row
Out[63]:
array([ 0, 4, 8, 12, 16, 40])
In [64]:
B1.shape, B_sum_row.shape
Out[64]:
((4, 6), (6,))
In [65]:
B_sum_row = np.expand_dims(B_sum_row, axis=0)
In [66]:
B1.shape, B_sum_row.shape
Out[66]:
((4, 6), (1, 6))
In [68]:
B2 = np.vstack([B1, B_sum_row])
B2, B2.shape
Out[68]:
(array([[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10],
[ 0, 1, 2, 3, 4, 10],
[ 0, 4, 8, 12, 16, 40]]),
(5, 6))