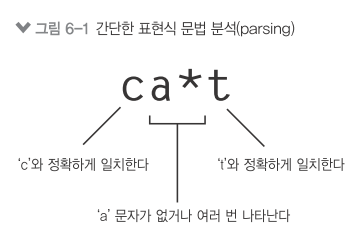
6 정규표현식, 파트 1¶
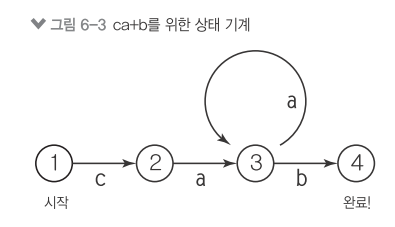
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.2 실제 예시: 전화 번호¶
6.1 정규표현식의 소개¶
6.2 실제 예시: 전화 번호¶
In [1]:
import re
pattern = r'\d\d\d-\d\d\d-\d\d\d\d'
s = input('Enter tel. number: ')
if re.match(pattern, s):
print('Number accepted.')
else:
print('Incorrect format.')
Enter tel. number: 222 222 2222 Incorrect format.
6.3 일치 패턴 정제하기¶
In [2]:
import re
pattern = r'\d\d\d[ -]\d\d\d[ -]\d\d\d\d$'
s = input('Enter tel. number: ')
if re.match(pattern, s):
print('Number accepted.')
else:
print('Incorrect format.')
Enter tel. number: 333 333 3333 Number accepted.
In [3]:
import re
pattern = r'\d\d\d[ -]\d\d\d[ -]\d\d\d\d'
s = input('Enter tel. number: ')
if re.fullmatch(pattern, s):
print('Number accepted.')
else:
print('Incorrect format.')
Enter tel. number: 111 111 1111 Number accepted.
In [4]:
import re
pattern = r'\d\d\d-\d\d-\d\d\d\d$'
s = input('Enter SSN: ')
if re.match(pattern, s):
print('Number accepted.')
else:
print('Incorrect format.')
Enter SSN: 111-11-1111 Number accepted.
6.4 정규 표현식 동작 방식: 컴파일 vs 실행¶


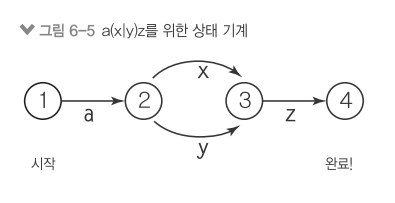
In [5]:
import re
reg1 = re.compile(r'ca*b$') # 패턴을 컴파일한다!
def test_item(s):
if re.match(reg1, s):
print(s, 'is a match.')
else:
print(s, 'is not a match!')
test_item('caab')
test_item('caaxxb')
caab is a match. caaxxb is not a match!
6.5 대소문자 무시하기, 그리고 다른 함수 플래그¶

In [6]:
if re.match('m*ack', 'Mack the Knife', re.IGNORECASE):
print ('Success.')
Success.
In [7]:
if re.match('m*ack', 'Mack the Knife', re.I):
print ('Success.')
Success.
In [8]:
if re.match('m*ack', 'Mack the Knife', re.I | re.DEBUG):
print ('Success.')
MAX_REPEAT 0 MAXREPEAT
LITERAL 109
LITERAL 97
LITERAL 99
LITERAL 107
0. INFO 4 0b0 3 MAXREPEAT (to 5)
5: REPEAT_ONE 6 0 MAXREPEAT (to 12)
9. LITERAL_UNI_IGNORE 0x6d ('m')
11. SUCCESS
12: LITERAL_UNI_IGNORE 0x61 ('a')
14. LITERAL_UNI_IGNORE 0x63 ('c')
16. LITERAL_UNI_IGNORE 0x6b ('k')
18. SUCCESS
Success.
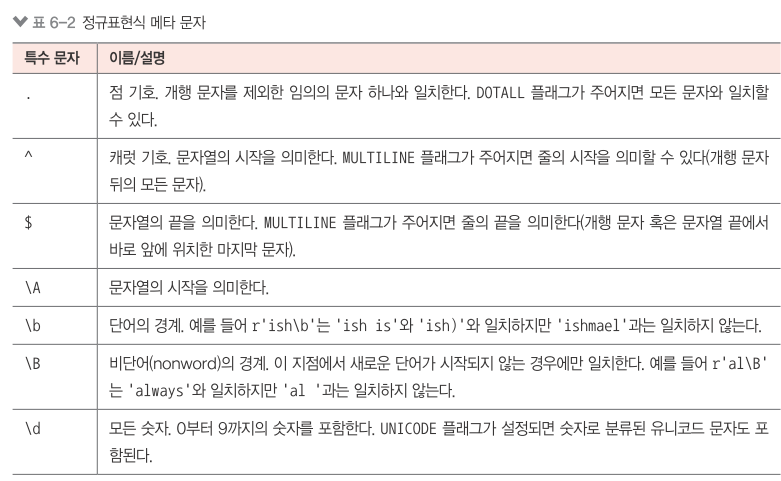

6.6.2 문자 집합¶
In [9]:
import re
if re.match(r'[+*^/-]', '^'):
print('Success!')
Success!
In [10]:
import re
if re.match(r'[^+*^/-]', '^'):
print('Success!')
6.6.3 패턴 수량자¶

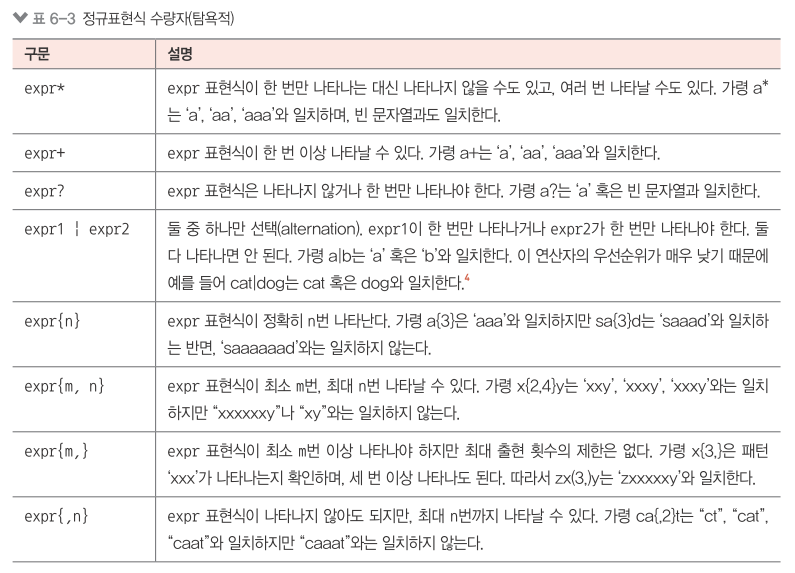

6.6.4 역추적, 탐욕적 수량자와 게으른 수량자¶
In [11]:
import re
pat = r'c.*t'
if re.match(pat, 'cat'):
print('Success!')
Success!
In [12]:
import re
pat1 = r'(\w|[@#$%^&*!]){8,}$'
pat2 = r'.*\d'
pat3 = r'.*[a-zA-Z]'
pat4 = r'.*[@#$%^$*]'
def verify_passwd(s):
b = (re.match(pat1, s) and re.match(pat2, s) and
re.match(pat3, s) and re.match(pat4, s))
return bool(b)
6.7 정규표현식 실습 예시¶
6.8 일치 객체 사용하기¶

In [13]:
import re
pat = r'(a+)(b+)(c+)'
m = re.match(pat, 'abbcccee')
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.group(3))
abbccc a bb ccc
In [14]:
import re
pat = r'(a+)(b+)(c+)'
m = re.match(pat, 'abbcccee')
for i in range(m.lastindex + 1):
print(i, '. ', m.group(i), sep='')
0. abbccc 1. a 2. bb 3. ccc
6.9 패턴에 맞는 문자열 검색하기¶
In [15]:
import re
m = re.search(r'\d{2,}', '1 set of 23 owls, 999 doves.')
print('"', m.group(), '" found at ', m.span(), sep='')
"23" found at (9, 11)
6.10 반복하여 검색하기 (findall)¶
In [16]:
import re
s = '1 set of 23 owls, 999 doves.'
print(re.findall(r'\d+', s))
['1', '23', '999']
In [17]:
import re
s = 'What is 1,000.5 times 3 times 2,000?'
print(re.findall(r'\d[0-9,.]*', s))
['1,000.5', '3', '2,000']
In [18]:
s = 'I do not use sophisticated, multisyllabic words!'
print(re.findall(r'\w{6,}', s))
['sophisticated', 'multisyllabic']
In [19]:
import re
s = '12 15+3 100-*'
print(re.findall(r'[+*/-]|\w+', s))
['12', '15', '+', '3', '100', '-', '*']
6.11 'findall' 메서드와 그룹핑 문제¶
In [20]:
pat = r'\d{1,3}(,\d{3})*(\.\d*)?'
print(re.findall(pat, '12,000 monkeys and 55.5 cats.'))
[(',000', ''), ('', '.5')]
In [21]:
pat = r'(\d{1,3}(,\d{3})*(\.\d*)?)'
lst = re.findall(pat, '12,000 monkeys on 55.5 cats.')
for item in lst:
print(item[0])
12,000 55.5
6.12 반복 패턴 검색하기¶
In [22]:
import re
s = 'The cow jumped over the the moon.'
m = re.search(r'(\w+) \1', s)
print(m.group(), '...found at', m.span())
the the ...found at (20, 27)
In [23]:
s = 'The United States of of America.'
m = re.search(r'(\w+) \1', s)
print(m.group(), '...found at', m.span())
of of ...found at (18, 23)
In [24]:
s = 'The the cow jumped over the the moon.'
m = re.search(r'(\w+) \1', s, flags=re.I)
print(m.group(), '...found at', m.span())
The the ...found at (0, 7)
6.13 텍스트 교체하기¶
In [25]:
import re
s = 'Get me a new dog to befriend my dog.'
s2 = re.sub('dog', 'cat', s)
print(s2)
Get me a new cat to befriend my cat.
In [26]:
s = 'The the cow jumped over over the moon.'
s2 = re.sub(r'(\w+) \1', r'\1', s, flags=re.I)
print(s2)
The cow jumped over the moon.
In [ ]: