Chapter 7. 앙상블 학습과 랜덤 포레스트¶
import os
import numpy as np
np.random.seed(42)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
matplotlib.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] = False
- 대중의 지혜wisdom of the crowd : 무작위로 선택된 수천 명의 사람에게 복잡한 질문을 하고 대답을 모은 것
- 앙상블 학습Ensemble Learing : 여러 개의 모델을 학습시켜 그 모델들의 예측결과들을 이용해 하나의 모델보다 더 나은 값을 예측하는 것
- 앙상블 : 일련의 예측기
- 앙상블 방법Ensemble method : 앙상블 학습 알고리즘
- 결정 트리의 앙상블 → 랜덤 포레스트Random Forest
7.1 투표 기반 분류기¶
- 직접 투표hard voting 분류기 : 다수결 투표로 클래스를 정하는 분류기
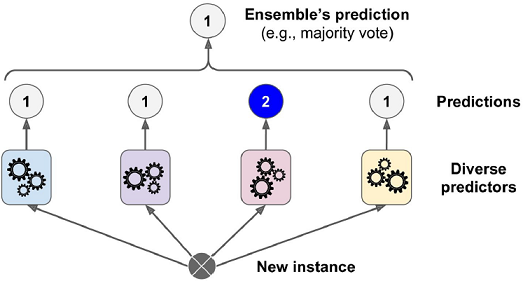
- 다수결 투표 분류기가 앙상블에 포함된 개별 분류기 중 가장 뛰어난 것보다도 정확도가 높을 경우가 많음
- 각 분류기가 약한 학습기weak learner(즉, 랜덤 추측보다 조금 더 높은 성능을 내는 분류기)일지라도 충분하게 많고 다양하다면 앙상블은 (높은 정확도를 내는) 강한 학습기strong learner가 될 수 있음
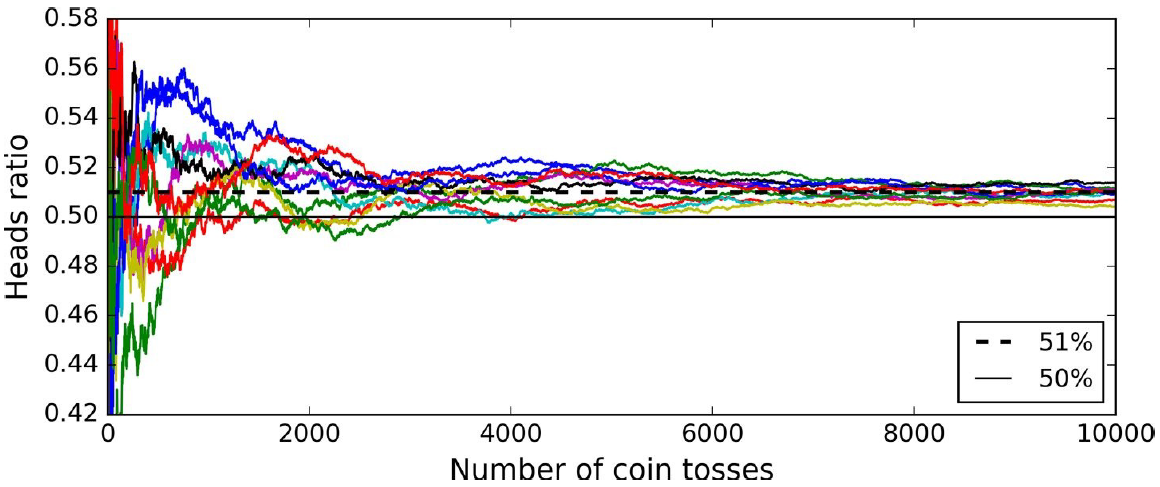
- 앙상블 방법은 예측기가 가능한 한 서로 독립적이고 오차에 상관관계가 없을 때 최고의 성능을 발휘함
- 다양한 분류기를 얻는 방법은 각기 다른 알고리즘으로 학습시키는 것
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
X_train.shape, y_train.shape
((375, 2), (375,))
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver='liblinear', random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma='auto', probability=True, random_state=42)
hard_voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
hard_voting_clf.fit(X_train, y_train)
VotingClassifier(estimators=[('lr', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=42, solver='liblinear',
tol=0.0001, verbose=0, warm_start=False)), ('rf', Rando...bf',
max_iter=-1, probability=True, random_state=42, shrinking=True,
tol=0.001, verbose=False))],
flatten_transform=None, n_jobs=None, voting='hard', weights=None)
soft_voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
soft_voting_clf.fit(X_train, y_train)
VotingClassifier(estimators=[('lr', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=42, solver='liblinear',
tol=0.0001, verbose=0, warm_start=False)), ('rf', Rando...bf',
max_iter=-1, probability=True, random_state=42, shrinking=True,
tol=0.001, verbose=False))],
flatten_transform=None, n_jobs=None, voting='soft', weights=None)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, hard_voting_clf, soft_voting_clf):
clf.fit(X_train, y_train)
y_pred_voting = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred_voting))
LogisticRegression 0.864 RandomForestClassifier 0.872 SVC 0.888 VotingClassifier 0.896 VotingClassifier 0.912
- 간접 투표soft voting : 정확도가 높은 분류기에 더 높은 비중을 둚
7.2 배깅과 페이스팅¶
- 다양한 분류기를 만드는 방법
- 각기 다른 훈련 알고리즘을 사용
- ☞ 같은 알고리즘을 사용하지만 훈련 세트의 서브셋을 무작위로 구성
- 배깅bagging(bootstrap aggregating) : 훈련 세트에서 중복을 허용하여 샘플링하는 방식
- 페이스팅pasting : 훈련 세트에서 중복을 허용하지 않고 샘플링하는 방식
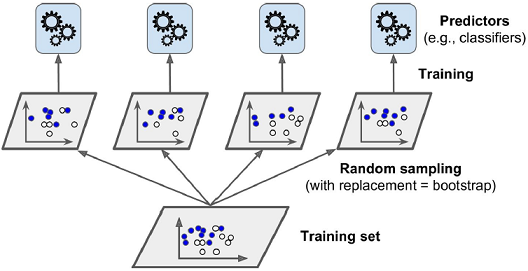
- 수집함수 : 모든 예측기의 예측을 모음
- 전형적인 분류 → 통계적 최빈값statistical mode(e.g. 직접 투표 분류기)
- 회귀 → 평균
- 개별 예측기는 원본 훈련 세트로 훈련시킨 것보다 훨씬 크게 편향되어 있지만 수집 함수를 통과하면 편향과 분산이 모두 감소
- 일반적으로 앙상블의 결과는 원본 데이터셋으로 하나의 예측기를 훈련시킬 때와 비교해 편향은 비슷하지만 분산은 줄어듦
7.2.1 사이킷런의 배깅과 페이스팅¶
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred_bag = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred_bag)
0.904
pas_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
max_samples=100, bootstrap=False, n_jobs=-1, random_state=42)
pas_clf.fit(X_train, y_train)
y_pred_pas = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred_pas)
0.904
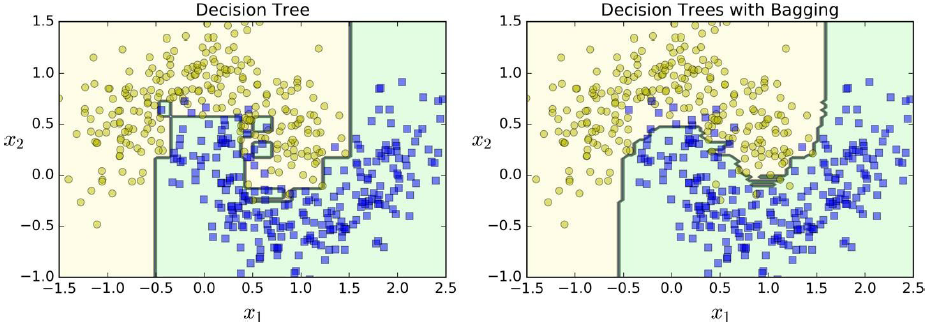
- 앙상블은 비슷한 편향에서 더 작은 분산을 만듦 - 훈련 세트의 오차 수가 거의 비슷하지만 결정 경계는 덜 불규칙
- 전반적으로 배깅이 더 나은 모델을 만들기 때문에 일반적으로 더 선호되지만 시간과 CPU 파워에 여유가 있다면 교차 검증으로 배깅과 페이스팅을 모두 평가해보는 것이 좋음
7.2.2 oob 평가¶
- oobout-of-bag 샘플 : 각 예측기에 선택되지 않은 훈련 샘플의 나머지
- 예측기마다 oob 샘플이 모두 다름
- 예측기가 훈련되는 동안에는 oob 샘플을 사용하지 않으므로 oob 샘플을 사용해 평가가 가능
- 앙상블의 평가는 각 예측기의 oob 평가를 평균
oob_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True, random_state=40)
oob_clf.fit(X_train, y_train)
oob_clf.oob_score_
0.9013333333333333
y_pred_oob = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred_oob)
0.904
oob_clf.oob_decision_function_.shape # oob 평가가 예측한 각 훈련 샘플의 클래스 확률
(375, 2)
7.3 랜덤 패치와 랜덤 서브스페이스¶
- 특성 샘플링 - 더 다양한 예측기를 만들며 편향을 늘리는 대신 분산을 낮춤
- 이미지와 같은 매우 고차원의 데이터셋을 다룰 때 유용함
- 랜덤 패치 방식Random Patches method - 훈련 특성과 샘플을 모두 샘플링하는 방식
- 랜덤 서브스페이스 방식Random Subspaces method
- 훈련 샘플은 모두 사용 → bootstrap=False, max_samples=1.0
- 특성은 샘플링 → bootstrap_features=True, max_features<1.0
7.4 랜덤 포레스트¶
- 랜덤 포레스트는 일반적으로 배깅 또는 페이스팅을 적용한 결정 트리의 앙상블
- 전형적으로 max_samples를 훈련 세트의 크기로 지정
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
accuracy_score(y_test, y_pred_rf)
0.912
- 랜덤 포레스트는 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신, 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식으로 무작위성을 더 주입
→ 다시 한번 편향을 손해 보는 대신 분산을 낮추어 전체적으로 더 훌륭한 모델을 만듦
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16, random_state=42),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred_bag = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred_bag)
0.92
7.4.1 엑스트라 트리¶
- 익스트림 랜덤 트리Extremly Randomized Trees 앙상블(또는 줄여서 엑스트라 트리Extra-Trees) : 극단적으로 무작위한 트리의 랜덤 포레스트
- 여기서도 역시 편향이 늘어나지만 대신 분산을 낮춤
- 모든 노드에서 특성마다 가장 최적의 임곗값을 찾는 것이 트리 알고리즘에서 가장 시간이 많이 소요되는 작업 중 하나이므로 일반적인 랜덤 포레스트보다 엑스트라 트리가 훨씬 빠름
from sklearn.ensemble import ExtraTreesClassifier
ext_clf = ExtraTreesClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1, random_state=42)
ext_clf.fit(X_train, y_train)
y_pred_ext = ext_clf.predict(X_test)
accuracy_score(y_test, y_pred_ext)
0.912
- RandomForestClassifier와 ExtraTreesClassifier 중 뭐가 더 나을지 예단하기 어려우므로, 일반적으로 둘 다 시도해보고 교차 검증으로 비교해보는 것이 유일한 방법
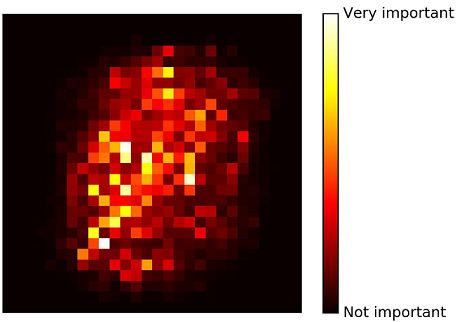
7.4.2 특성 중요도¶
- 랜덤 포레스트는 특성을 선택해야 할 때 어떤 특성이 중요한지 빠르게 확인할 수 있어 편리함
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1, random_state=42)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)
sepal length (cm) 0.11249225099876374 sepal width (cm) 0.023119288282510326 petal length (cm) 0.44103046436395765 petal width (cm) 0.4233579963547681
7.5 부스팅¶
- 부스팅boosting(원래는 가설 부스팅hypothesis boosting이라 불림) - 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법
7.5.1 아다부스트¶
- 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높이는 방식
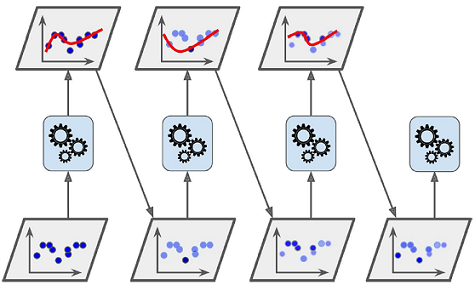

- 모든 예측기가 훈련을 마치면 배깅이나 페이스팅과 비슷한 방식으로 예측을 만듦
- 전반적인 정확도에 따라 예측기마다 다른 가중치가 적용됨

- 각 샘플 가중치 $w^{(i)}$는 초기에 $1 \over m$로 초기화됨
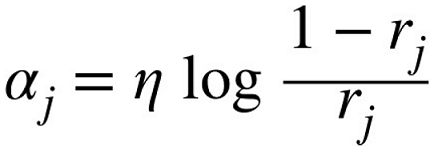
- $\eta$ : 학습률 파라미터(기본값은 1)
- 예측기가 정확할수록 예측기의 가중치가 더 높아짐
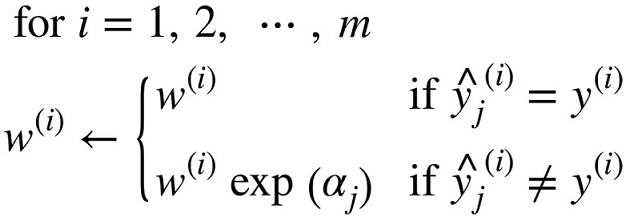
- 잘못 분류된 샘플의 가중치가 증가됨
▣ 아다부스트의 전체 과정¶
- 예측기가 학습되고, 샘플의 가중치가 적용된 예측기의 에러율을 계산
- 예측기의 에러율로 예측기의 가중치를 계산
- 모든 샘플의 가중치를 업데이트하고 정규화
- 업데이트하고 정규화된 새로운 샘플로 새로운 예측기를 학습
※ 지정된 예측기 수에 도달하거나 완벽한 예측기가 만들어지면 중지됨

- $N$은 예측기의 수
- 예측기의 가중치 합이 가장 큰 클래스가 예측 결과가 됨
- 사이킷런은 SAMME라는 아다부스트의 다중 클래스 버전을 사용
- 클래스가 두 개 뿐일 때는 SAMME가 아다부스트와 동일
- 예측기가 클래스의 확률을 추정할 수 있다면(즉, predict_proba() 메서드가 있다면) 사이킷런은 SAMME.R이라는 변종을 사용
- SAMME.R은 예측값 대신 클래스 확률에 기반하며 일반적으로 성능이 더 좋음
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
AdaBoostClassifier(algorithm='SAMME.R',
base_estimator=DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best'),
learning_rate=0.5, n_estimators=200, random_state=42)
- 여기에서 사용하는 결정 트리는 max_depth=1로, 결정 노드 하나와 리프 노드 두 개로 이루어진 트리
- 이 트리가 AdaBoostClassifier의 기본 추정기
7.5.2 그래디언트 부스팅¶
- Gradient Boosting : 아다부스트처럼 반복마다 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔여 오차residual error에 새로운 예측기를 학습시킴
- Gradient Tree Boosting or Gradient Boosted Regression Tree(GBRT) : 결정 트리를 기반 예측기로 사용
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=42, splitter='best')
# 잔여 오차
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=42, splitter='best')
# 잔여 오차
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=42, splitter='best')
X_new = np.array([[0.8]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
y_pred
array([0.75026781])

from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=0.1, random_state=42)
gbrt.fit(X, y)
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=3, n_iter_no_change=None, presort='auto',
random_state=42, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
- learning_rate : 각 트리의 기여 정도
- learning_rate를 0.1처럼 낮게 설정하면 앙상블을 훈련 세트에 학습시키기 위해 많은 트리가 필요하지만 일반적으로 예측의 성능은 좋아짐
→ 축소shrinkage라고 부르는 규제 방법

- 최적의 트리 수를 찾는 방법 → 조기 종료 기법
- staged_predict() : 훈련의 각 단계에서 앙상블에 의해 만들어진 예측기를 순회하는 반복자iterator를 반환
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=49)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120, random_state=42)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors)
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators, random_state=42)
gbrt_best.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=55, n_iter_no_change=None, presort='auto',
random_state=42, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)

- 많은 수의 트리를 먼저 훈련시키고 최적의 수를 찾기 위해 다시 살펴보는 대신 실제로 훈련을 중지하는 방법으로 조기 종료를 구현할 수 있음
- warm_start=True로 설정하면 사이킷런이 fit() 메서드가 호출될 때 기존 트리를 유지하고 훈련을 추가할 수 있도록 해줌
gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True, random_state=42)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break # 조기 종료
gbrt.n_estimators
61
- 연속해서 다섯 번의 반복 동안 검증 오차가 향상되지 않으면 훈련을 멈춤
- 확률적 그래디언트 부스팅Stochastic Gradient Boosting
- subsample=0.25 → 각 트리는 무작위로 선택된 25%의 훈련 샘플로 학습됨
- 마찬가지로 편향이 높아지는 대신 분산이 낮아짐
- 훈련 속도를 상당히 높임
sto_gbrt = GradientBoostingRegressor(subsample=0.25, max_depth=2, n_estimators=3, learning_rate=0.1)
sto_gbrt.fit(X, y)
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.1, loss='ls', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=3, n_iter_no_change=None, presort='auto',
random_state=None, subsample=0.25, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
7.6 스태킹¶
- 스태킹stacking의 기본 아이디어 : 앙상블에 속한 모든 예측기의 예측을 취합하는 간단한 함수(직접 투표 같은)를 사용하는 대신 취합하는 모델을 훈련시킬 수 없을까?
- 블렌더blender 또는 메타 학습기meta learner가 예측들을 입력으로 받아 최종 예측을 함
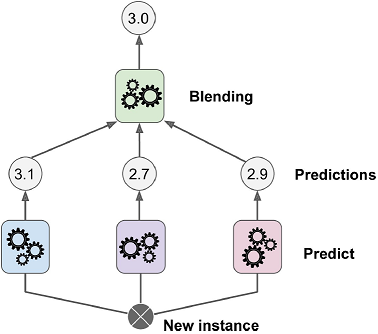
- 블렌딩blending : 홀드 아웃hold-out 세트를 사용
- 스태킹stacking : 아웃 오브 폴드out-of-fold 예측(k-겹 교차 검증에서 검증 폴드의 결과를 모두 모은 것)
- 많은 사람이 두 용어를 같은 의미로 사용

▣ 블렌더 학습 과정¶
- 훈련 세트를 두 개의 서브셋으로 나눔
- 첫 번째 서브셋으로 예측기들을 훈련
- 이 (첫 번째 레이어의) 예측기들로 두 번째 서브셋(홀드 아웃 세트)에 대한 예측을 만듦
- (타깃값은 그대로 쓰고) 이 예측값들을 새 훈련 세트(3차원)로 하여 블렌더를 학습

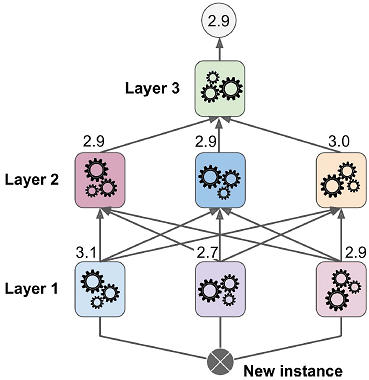
▣ 멀티(3)레이어 블렌더 학습 과정¶
- 훈련 세트를 세 개의 서브셋으로 나눔
- 첫 번째 서브셋으로 예측기들을 훈련 → 첫 번째 레이어
- 첫 번째 레이어의 예측기들로 두 번째 서브셋에 대한 예측을 만듦
- 이 예측값들을 새 훈련 세트로 하여 예측기들을 훈련 → 두 번째 레이어
- 두 번째 레이어의 예측기들로 세 번째 서브셋에 대한 예측을 만듦
- 이 예측값들을 새 훈련 세트로 하여 블렌더를 학습
7.7 연습문제¶
1. 정확히 같은 훈련 데이터로 다섯 개의 다른 모델을 훈련시켜서 모두 95% 정확도를 얻었다면 이 모델들을 연결하여 더 좋은 결과를 얻을 수 있을까요? 가능하다면 어떻게 해야 할까요? 그렇지 않다면 왜일까요?¶
☞ 다섯 개의 모델을 훈련시켰고 모두 95%의 정확도를 달성했다면 이들을 연결하여 투표 앙상블을 만들어 더 나은 결과를 기대할 수 있습니다. 만약 모델이 서로 다르다면 (예를 들면 SVM 분류기, 결정 트리 분류기, 로지스틱 회귀 분류기 등) 훨씬 좋습니다. 만약 다른 훈련 샘플에서 훈련되었다면 더더욱 좋습니다(이것이 배깅과 페이스팅 앙상블의 핵심입니다). 하지만 그렇지 않더라도 모델이 서로 많이 다르면 여전히 좋은 결과를 냅니다.
2. 직접 투표와 간접 투표 분류기 사이의 차이점은 무엇일까요?¶
☞ 직접 투표 분류기는 앙상블에 있는 각 분류기의 선택을 카운트해서 가장 많은 투표를 얻은 클래스를 선택합니다. 간접 투표 분류기는 각 클래스의 평균적인 확률 추정값을 계산해서 가장 높은 확률을 가진 클래스를 고릅니다. 이 방식은 신뢰가 높은 투표에 더 가중치를 주고 종종 더 나은 성능을 냅니다. 하지만 앙상블에 있는 모든 분류기가 클래스 확률을 추정할 수 있어야 사용할 수 있습니다(예를 들어 사이킷런의 SVM 분류기는 probability=True로 지정해야 합니다).
3. 배깅 앙상블의 훈련을 여러 대의 서버에 분산시켜 속도를 높일 수 있을까요? 페이스팅 앙상블, 부스팅 앙상블, 랜덤 포레스트, 스태킹 앙상블의 경우는 어떨까요?¶
☞ 배깅 앙상블의 각 예측기는 독립적이므로 여러 대의 서버에 분산하여 앙상블의 훈련 속도를 높일 수 있습니다. 페이스팅 앙상블과 랜덤 포레스트도 같은 이유로 동일합니다. 그러나 부스팅 앙상블의 예측기는 이전 예측기를 기반으로 만들어지므로 훈련이 순차적이어야 하고 여러 대의 서버에 분산해서 얻을 수 있는 이득이 없습니다. 스태킹 앙상블의 경우 한 층의 모든 예측기가 각각 독립적이므로 여러 대의 서버에서 병렬로 훈련될 수 있습니다. 그러나 한 층에 있는 예측기들은 이전 층의 예측기들이 훈련된 후에 훈련될 수 있습니다.
4. oob 평가의 장점은 무엇인가요?¶
☞ oob 평가를 사용하면 배깅 앙상블의 각 예측기가 훈련에 포함되지 않은(즉, 따로 떼어놓은) 샘플을 사용해 평가됩니다. 이는 추가적인 검증 세트가 없어도 편향되지 않게 앙상블을 평가하도록 도와줍니다. 그러므로 훈련에 더 많은 샘플을 사용할 수 있어서 앙상블의 성능은 조금 더 향상될 것입니다.
5. 무엇이 엑스트라 트리를 일반 랜덤 포레스트보다 더 무작위하게 만드나요? 추가적인 무작위성이 어떻게 도움이 될까요? 엑스트라 트리는 일반 랜덤 포레스트보다 느릴까요, 빠를까요?¶
☞ 랜덤 포레스트에서 트리가 성장할 때 각 노드에서 특성의 일부를 무작위로 선택해 분할에 사용합니다. 엑스트라 트리에서도 이는 마찬가지지만 한 단계 더 나아가서 일반 결정 트리처럼 가능한 최선의 임계점을 찾는 것이 아니라 각 특성에 대해 랜덤한 임계점을 사용합니다. 이 추가적인 무작위성은 규제처럼 작동합니다. 즉, 랜덤 포레스트가 훈련 데이터에 과대적합되었다면 엑스트라 트리는 그렇지 않을 것입니다. 또한 엑스트라 트리는 가능한 최선의 임계점을 찾지 않기 때문에 랜덤 포레스트보다 훨씬 빠르게 훈련됩니다. 그러나 예측을 할 때는 랜덤 포레스트보다 더 빠르지도 느리지도 않습니다.
6. 아다부스트 앙상블이 훈련 데이터에 과소적합되었다면 어떤 매개변수를 어떻게 바꾸어야 할까요?¶
☞ 아다부스트 앙상블이 훈련 데이터에 과소적합되었다면 예측기 수를 증가시키거나 기반 예측기의 규제 하이퍼파라미터를 감소시켜 볼 수 있습니다. 또한 학습률을 약간 증가시켜 볼 수 있습니다.
7. 그래디언트 부스팅 앙상블이 훈련 데이터에 과대적합되었다면 학습률을 높여야 할까요, 낮춰야 할까요?¶
☞ 그래디언트 부스팅 앙상블이 훈련 세트에 과대적합되었다면 학습률을 감소시켜야 합니다. (예측기 수가 너무 많으면) 알맞은 개수를 찾기 위해 조기 종료 기법을 사용할 수 있습니다.
8. (3장에서 소개한) MNIST 데이터를 불러들여 훈련 세트, 검증 세트, 테스트 테스로 나눕니다(예를 들면 훈련에 40,000개 샘플, 검증에 10,000개 샘플, 테스트에 10,000개 샘플). 그런 다음 랜덤 포레스트 분류기, 엑스트라 트리 븐류기, SVM 같은 여러 종류의 분류기를 훈련시킵니다. 그리고 검증 세트에서 개개의 분류기보다 더 높은 성능을 내도록 이들을 간접 또는 직접 투표 분류기를 사용하는 앙상블로 연결해보세요. 앙상블을 얻고 나면 테스트 세트로 확인해보세요. 개개의 분류기와 비교해서 성능이 얼마나 향상되나요?¶
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
C:\Users\link\Anaconda3\envs\mlbook\lib\site-packages\sklearn\utils\deprecation.py:77: DeprecationWarning: Function fetch_mldata is deprecated; fetch_mldata was deprecated in version 0.20 and will be removed in version 0.22 warnings.warn(msg, category=DeprecationWarning) C:\Users\link\Anaconda3\envs\mlbook\lib\site-packages\sklearn\utils\deprecation.py:77: DeprecationWarning: Function mldata_filename is deprecated; mldata_filename was deprecated in version 0.20 and will be removed in version 0.22 warnings.warn(msg, category=DeprecationWarning)
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(mnist.data, mnist.target, test_size=10000, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=10000, random_state=42)
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.svm import LinearSVC
from sklearn.neural_network import MLPClassifier
random_forest_clf = RandomForestClassifier(n_estimators=10, random_state=42)
extra_trees_clf = ExtraTreesClassifier(n_estimators=10, random_state=42)
svm_clf = LinearSVC(max_iter=10000, random_state=42)
mlp_clf = MLPClassifier(random_state=42)
estimators = [random_forest_clf, extra_trees_clf, svm_clf, mlp_clf]
for estimator in estimators:
print("훈련 예측기: ", estimator)
estimator.fit(X_train, y_train)
훈련 예측기: RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False)
훈련 예측기: ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False)
훈련 예측기: LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=10000,
multi_class='ovr', penalty='l2', random_state=42, tol=0.0001,
verbose=0)
C:\Users\link\Anaconda3\envs\mlbook\lib\site-packages\sklearn\svm\base.py:922: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations. "the number of iterations.", ConvergenceWarning)
훈련 예측기: MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=42, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
[estimator.score(X_val, y_val) for estimator in estimators]
[0.9467, 0.9512, 0.8648, 0.9618]
from sklearn.ensemble import VotingClassifier
named_estimators = [
("random_forest_clf", random_forest_clf),
("extra_trees_clf", extra_trees_clf),
("svm_clf", svm_clf),
("mlp_clf", mlp_clf),
]
voting_clf = VotingClassifier(named_estimators)
voting_clf.fit(X_train, y_train)
C:\Users\link\Anaconda3\envs\mlbook\lib\site-packages\sklearn\svm\base.py:922: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations. "the number of iterations.", ConvergenceWarning)
VotingClassifier(estimators=[('random_forest_clf', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
...=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False))],
flatten_transform=None, n_jobs=None, voting='hard', weights=None)
voting_clf.score(X_val, y_val)
0.9634
[estimator.score(X_val, y_val) for estimator in voting_clf.estimators_]
[0.9467, 0.9512, 0.8648, 0.9618]
voting_clf.set_params(svm_clf=None)
VotingClassifier(estimators=[('random_forest_clf', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
...=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False))],
flatten_transform=None, n_jobs=None, voting='hard', weights=None)
voting_clf.estimators
[('random_forest_clf',
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False)),
('extra_trees_clf',
ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False)),
('svm_clf', None),
('mlp_clf',
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=42, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False))]
voting_clf.estimators_
[RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False),
ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=42, verbose=0, warm_start=False),
LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=10000,
multi_class='ovr', penalty='l2', random_state=42, tol=0.0001,
verbose=0),
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=42, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)]
del voting_clf.estimators_[2]
voting_clf.score(X_val, y_val)
0.9679
voting_clf.voting = "soft"
voting_clf.score(X_val, y_val)
0.9716
voting_clf.score(X_test, y_test)
0.9683
[estimator.score(X_test, y_test) for estimator in voting_clf.estimators_]
[0.9434, 0.9444, 0.9615]
9. 이전 연습문제의 각 분류기를 실행해서 검증 세트에서 예측을 만들고 그 결과로 새로운 훈련 세트를 만들어보세요. 각 훈련 샘플은 하나의 이미지에 대한 전체 분류기의 예측을 담은 벡터고 타깃은 이미지의 클래스입니다. 새로운 훈련 세트에 분류기 하나를 훈련시켜보세요. 방금 블렌더를 훈련시켰습니다. 그리고 이 분류기를 모아서 스태킹 앙상블을 구성했습니다. 이제 테스트 세트에 앙상블을 평가해보세요. 테스트 세트의 각 이미지에 대해 모든 분류기로 예측을 만들고 앙상블의 예측 결과를 만들기 위해 블렌더에 그 예측을 주입합니다. 앞서 만든 투표 분류기와 비교하면 어떤가요?¶
X_val_predictions = np.empty((len(X_val), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_val_predictions[:, index] = estimator.predict(X_val)
X_val_predictions
array([[2., 2., 2., 2.],
[7., 7., 7., 7.],
[4., 4., 4., 4.],
...,
[4., 4., 4., 4.],
[9., 9., 9., 9.],
[4., 4., 4., 4.]], dtype=float32)
rnd_forest_blender = RandomForestClassifier(n_estimators=200, oob_score=True, random_state=42)
rnd_forest_blender.fit(X_val_predictions, y_val)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200, n_jobs=None,
oob_score=True, random_state=42, verbose=0, warm_start=False)
rnd_forest_blender.oob_score_
0.9672
X_test_predictions = np.empty((len(X_test), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_test_predictions[:, index] = estimator.predict(X_test)
y_pred = rnd_forest_blender.predict(X_test_predictions)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
0.9624