自回归模型¶
原理讲解¶
到目前为止,我们强调的是以回归模型来推断因果关系。如果从一个客户的角度仅关心某变量(比如股价)的未来值,则可以用该变量的过去值来预测其未来值(因为时间序列一般存在自相关),这种模型被称为“单变量时间序列”。此时,可以不必理会因果关系,只考虑相关关系即可。比如,看到街上有人带伞,可以预测今天要下雨,但行人带伞并不导致下雨。对于样本数据 y1,y2,…yT,最简单的预测方法为一阶自回归 AR(1):
yt=β0+β1yt−1+εt(t=2,⋯,T)其中,扰动项 εt 为白噪声,满足零期望 E(εt)=0,同方差 Var(εt)=σ2ε,且无自相关 Cov(εt,εs)=0,t≠s。假设|β1|<1,则 {yt}为渐近独立的平稳过程。由于 yt−1 依赖于 {εt−1,…ε1},而 εt 与 {εt−1,…ε1} 不相关,故 yt−1 与 εt 不相关,因此用OLS估计方程(1)是一致的。然而,使用 OLS 只能用观测值 t=2,…,T 进行回归,将损失一个样本容量。
为了提高估计效率,考虑最大似然估计。为此,进一步假设 εt 为独立同分布,且服从正态分布 N(0,σ2ε)。由于 yt 为平稳过程,其期望与方差均不随时间而变。对方程(1)两边同时取期望可得
E(y)=β0+β1E(y)经移项整理可知,{yt} 的无条件期望为 β01−β1。对方程(1)两边同时取方差可得
Var(y)=β21Var(y)+σ2ε故 yt 的无条件方差为 σ2ε1−β21。因此,y1 服从正态分布 N(β01−β1,σ2ε1−β21),其(无条件)密度函数为
fy1(y1)=1√2πσ2ε/(1−β21)exp{−[y1−(β0/(1−β1))]22σ2ε/(1−β21)}在给定 y1 的条件下,y2 的条件分布为 y2|y1∼N(β0+β1y1,σ2ε),其条件密度为
fy2|x1(y2|y1)=1√2πσ2εexp{−(y2−β0−β1y1)22σ2ε}则 y1 与 y2 的联合分布密度为
fy1,y2(y1,y2)=fy1(y1)fy2|y1(y2|y1)依此类推得 yt|yt−1∼N(β0+β1yt−1,σ2ε),t=2,⋯,T,写出整个样本数据 {y1,y2,⋯,yT} 的联合概率密度(即似然函数)为
fγ1,…,yT(y1,⋯,yT)=fy1(y1)T∏t=2fy1|yt−1(yt|yt−1)取对数可得对数似然函数:
lnL(β0,β1,σ2ε;y1,⋯,yT)=lnfy1(y1)+T∑t=2lnfy1|yt−1(yt|yt−1)代入 fy1(y1) 与 fy1|yt−1(yt|yt−1) 的表达式可得
lnL=−12ln2π−12ln[σ2ε/(1−β21)]−[y1−(β0/(1−β1))]22σ2ε/(1−β21)−T−12ln2π−T−12lnσ2ε−T∑t=2(yt−β0−β1yt−1)22σ2ε寻找最优参数 (β0,β1,σ2ε),使得 lnL 最大化,这个估计量被称为“精确最大似然估计量”。由于 lnL 为 (β0,β1,σ2ε))的非线性函数,故需要使用迭代法进行数值计算。
如果样本容量 T 较大,则第一个观测值对似然函数的贡献较小,可以忽略。此时,相当于考虑在第一个观测值 y1 给定的情况下,{y2,⋯,yT} 的条件分布,则对数似然函数简化为
lnL=−T−12ln2π−T−12lnσ2ε−T∑t=2(yt−β0−β1yt−1)22σ2ε最大化上式所得到的估计量称为“条件最大似然估计量”( conditional MLE)。
更一般地,可以考虑 p 阶自回归模型,记为 AR(p):
yt=β0+β1yt−1+⋯+βpyy−p+εt对 AR(p) 的估计与 AR(1) 类似。在使用“条件 MLE”时,考虑在给定 {y1,⋯,yp} 的情况下,{yp+1,⋯,yT} 的条件分布。由于条件 MLE 等价于 OLS,而后者并不依赖于正态性假定,故条件 MLE 的一致性也不依赖于正态性假定。
然而,通常我们并不知道滞后期 p。因此,如何估计 ˆp 在实践中有着重要的意义。
估计滞后期 p 有两种方法:
- 由大到小的序贯 t 规则
- 使用信息准则:AIC、BIC 准则等
在实践中,可以结合以上两种方法来确定 ˆp。如果二者不一致,为了保守起见(即尽量避免遗漏变量偏差),可取二者滞后阶数的大者。
最大似然估计原理¶
如果回归模型存在非线性,可能不方便使用 OLS,这时常常采用最大似然估计法(MLE)或非线性最小二乘法(NLS)。
假设随机向量 y 的概率密度函数为 f(y;θ),其中 θ 为 K 维未知参数向量,通过抽取随机样本 y1,⋯,yn 来估计 θ。假设y1,⋯,yn 为独立同分布(iid),则样本数据的联合密度函数为 f(y1;θ)f(y2;θ)⋯f(yn;θ)。
在抽样之前,y1,⋯,yn 被视为随机向量。抽样之后,y1,⋯,yn 就有了特定的样本值。因此,可以将样本的联合密度函数视为在 y1,⋯,yn 给定的情况下,未知参数 θ 的函数。定义“似然函数”(likelihood function)为
L(θ;y1,⋯,yn)=n∏i=1f(yi;θ)由此可知,似然函数与联合密度函数完全相等,只是 θ 与 y1,⋯,yn 的角色互换,即把 θ 作为自变量,而视 y1,⋯,yn 为已给定的。为了运算方便,常把似然函数取对数,将乘积的形式转化为求和的形式
lnL(θ;y1,⋯,yn)=n∑i=1lnf(yi;θ)“最大似然估计法"(Maximum Likelihood Estimation,简记 MLE 或 ML)来源于一个简单而深刻的思想:给定样本取值后,该样本最有可能来自参数 θ 为何值的总体。换言之,寻找 ˆθML,使得观测到样本数据的可能性最大,即最大化对数似然函数(loglikelihoodfunction):
maxθ∈ΘlnL(θ;y)在数学上,常把最大似然估计量 ˆθML 写为
ˆθML≡argmaxlnL(θ;y)其中,“argmax"(即argument of the maximum)表示能使 lnL(y;θ) 最大化的 θ 取值。假设存在唯一内点解,则该无约束极值问题的一阶条件为
s(θ;y)≡∂lnL(θ;y)∂θ≡(∂lnL(θ;y)∂θ1⋮∂lnL(θ;y)∂θK)=0原理实现¶
import numpy as np
import pandas as pd
import statsmodels.api as sm
data = pd.read_excel('../数据/上证指数与沪深300.xlsx')
def ARxx(X, P):
"""
获取自回归的估计向量
X - 输入数据,列向量
P - AR 阶数,标量
"""
N = len(X)
ARx = pd.DataFrame()
for m in range(1,P+1):
ARx.insert(m-1, f'var_{m}', list(X[P-m:N-m]))
ARy = list(X[P:N])
return ARy, ARx
y, X = ARxx(data['sz'], 1)
X = sm.add_constant(X)
mod = sm.OLS(y, X)
res = mod.fit()
res.summary()
| Dep. Variable: | y | R-squared: | 0.979 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.979 |
| Method: | Least Squares | F-statistic: | 2.126e+04 |
| Date: | Fri, 29 May 2020 | Prob (F-statistic): | 0.00 |
| Time: | 21:02:41 | Log-Likelihood: | -2286.7 |
| No. Observations: | 459 | AIC: | 4577. |
| Df Residuals: | 457 | BIC: | 4586. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 39.1999 | 19.891 | 1.971 | 0.049 | 0.111 | 78.288 |
| var_1 | 0.9863 | 0.007 | 145.803 | 0.000 | 0.973 | 1.000 |
| Omnibus: | 50.265 | Durbin-Watson: | 1.999 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 186.067 |
| Skew: | -0.417 | Prob(JB): | 3.94e-41 |
| Kurtosis: | 6.006 | Cond. No. | 3.55e+04 |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.55e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
statsmodels 库实现¶
详情请参考:AutoReg 模型
from statsmodels.tsa.ar_model import AutoReg
import pandas as pd
data = pd.read_excel('../数据/上证指数与沪深300.xlsx')
res = AutoReg(data['sz'], lags=1).fit()
res.summary()
| Dep. Variable: | sz | No. Observations: | 460 |
|---|---|---|---|
| Model: | AutoReg(1) | Log Likelihood | -2286.658 |
| Method: | Conditional MLE | S.D. of innovations | 35.265 |
| Date: | Fri, 29 May 2020 | AIC | 7.139 |
| Time: | 21:02:41 | BIC | 7.166 |
| Sample: | 1 | HQIC | 7.149 |
| 460 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| intercept | 39.1999 | 19.847 | 1.975 | 0.048 | 0.300 | 78.100 |
| sz.L1 | 0.9863 | 0.007 | 146.121 | 0.000 | 0.973 | 1.000 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0139 | +0.0000j | 1.0139 | 0.0000 |
matlab实现¶
使用 OLS 估计代码¶
ARxx.m
function [ARy,ARx] = ARxx(X,P)
% 获取自回归的估计向量
% X - 输入数据,列向量
% P - AR 阶数,标量
N = length(X);
ARx = zeros(N-P,P+1);
ARx(:,1) = ones(N-P,1); %常数项
for m = 1:P
ARx(:,m+1) = X(P-m+1:N-m,1); %P-m+1 = N-m-(N-P)+1
end
ARy = X(P+1:N,1);
% % 1.载入数据
% data = xlsread('../数据/上证指数与沪深300.xlsx');
% f1 = data(:,2);
%
% % 2.估计自回归模型f1 = c + f1(-1) + f1(-2)
% [ARy,ARx] = ARxx(f1,2);
% beta = regress(ARy,ARx);
%
% % 3.计算各滞后阶AIC值,选取最优滞后阶数(最大阶数为6)
% T = length(f1);
% AR_AIC = zeros(6,1);
% for p = 1:6
% [ARy,ARx] = ARxx(f1,p);
% beta = regress(ARy,ARx);
% y_hat = ARx*beta;
% resid = ARy - y_hat;
% AR_AIC(p) = log(resid'*resid/T)+2*(p+1)/T;
% end
%
% % 4.找到最小的AIC值所对应的阶数
% Best_p = find(AR_AIC == min(AR_AIC));
% [ARy,ARx] = ARxx(f1,Best_p);
% beta = regress(ARy,ARx);
fminsearch 函数(最大似然估计)¶
使用¶
fminsearch 函数用来求解多维无约束的线性优化问题,用 derivative-free 的方法找到多变量无约束函数的最小值
语法:
x = fminsearch(fun,x0)
x = fminsearch(fun,x0,options)
[x,fval] = fminsearch(...)
[x,fval,exitflag] = fminsearch(...)
[x,fval,exitflag,output] = fminsearch(...)
解释:
fminsearch 能够从一个初始值开始,找到一个标量函数的最小值。通常被称为无约束非线性优化
x = fminsearch(fun,x0) 从 x0 开始,找到函数 fun 中的局部最小值 x,x0 可以是标量,向量,矩阵。fun 是一个函数句柄
x = fminsearch(fun,x0,options) 以优化参数指定的结构最小化函数,可以用 optimset 函数定义这些参数。(见 matlab help)
[x,fval] = fminsearch(...)返回在结果 x 出的目标函数的函数值
[x,fval,exitflag] = fminsearch(...) 返回 exitflag 值来表示 fminsearch 退出的条件:
- 1--函数找到结果 x
- 0--函数最大功能评价次数达到,或者是迭代次数达到
- -1--算法由外部函数结束
[x,fval,exitflag,output] = fminsearch(...) 返回一个结构输出 output,包含最优化函数的信息:
- output.algorithm 使用的优化算法
- output.funcCount 函式计算次数
- output.iterations 迭代次数
- output.message 退出信息
优化参数选项options¶
可以通过 optimset 函数设置或改变这些参数。其中有的参数适用于所有的优化算法,有的则只适用于大型优化问题,另外一些则只适用于中型问题。
首先描述适用于大型问题的选项。这仅仅是一个参考,因为使用大型问题算法有一些条件。对于 fminunc(fminsearch)函数来说,必须提供梯度信息。
LargeScale – 当设为'on'时使用大型算法,若设为'off'则使用中型问题的算法。
适用于大型和中型算法的参数:
Diagnostics – 打印最小化函数的诊断信息。
Display – 显示水平。选择'off',不显示输出;选择'iter',显示每一步迭代过程的输出;选择'final',显示最终结果。打印最小化函数的诊断信息。
GradObj – 用户定义的目标函数的梯度。对于大型问题此参数是必选的,对于中型问题则是可选项。
MaxFunEvals – 函数评价的最大次数。
MaxIter – 最大允许迭代次数。
TolFun – 函数值的终止容限。
TolX – x 处的终止容限。
只用于大型算法的参数:
Hessian – 用户定义的目标函数的 Hessian 矩阵。
HessPattern –用于有限差分的 Hessian 矩阵的稀疏形式。若不方便求 fun 函数的稀疏 Hessian 矩阵 H,可以通过用梯度的有限差分获得的 H 的稀疏结构(如非零值的位置等)来得到近似的 Hessian 矩阵 H。若连矩阵的稀疏结构都不知道,则可以将 HessPattern 设为密集矩阵,在每一次迭代过程中,都将进行密集矩阵的有限差分近似(这是缺省设置)。这将非常麻烦,所以花一些力气得到 Hessian 矩阵的稀疏结构还是值得的。
MaxPCGIter – PCG 迭代的最大次数。
PrecondBandWidth – PCG 前处理的上带宽,缺省时为零。对于有些问题,增加带宽可以减少迭代次数。
TolPCG – PCG 迭代的终止容限。
TypicalX – 典型 x 值。
只用于中型算法的参数:
DerivativeCheck – 对用户提供的导数和有限差分求出的导数进行对比。
DiffMaxChange – 变量有限差分梯度的最大变化。
DiffMinChange - 变量有限差分梯度的最小变化。
LineSearchType – 一维搜索算法的选择。
exitflag:描述退出条件
- exitflag>0 表示目标函数收敛于解 x 处。
- exitflag=0 表示已经达到函数评价或迭代的最大次数。
- exitflag<0 表示目标函数不收敛。
output:该参数包含下列优化信息:
- output.iterations – 迭代次数。
- output.algorithm – 所采用的算法。
- output.funcCount – 函数评价次数。
- output.cgiterations – PCG 迭代次数(只适用于大型规划问题)。
- output.stepsize – 最终步长的大小(只用于中型问题)。
- output.firstorderopt – 一阶优化的度量:解 x 处梯度的范数。
fminunc(fminsearch)为中型优化算法的搜索方向提供了 4 中算法,由 options 中的参数 HessUpdate 控制
- HessUpdate=‘bfgs’(默认值),为拟牛顿的 BFGS 法
- HessUpdate='dfp'为拟牛顿 DFP 法
- HessUpdate=‘steepdesc’最速下降法
fminunc(fminsearch)中为中型优化算法的步长一维搜索提供了两种算法,由 options 中参数 LineSearchType 控制
- LineSearchType='quadcubic'混合的二次和三次多项式插值
- LineSearchType=‘cubicpoly’三次多项式插值
使用 fminunc 和 fminsearch 都可能会得到局部最优解。
fminsearch函数的缺陷¶
- 依赖于初值
- 不同目标函数需要选择不同的算法
- 仅是局部最优算法,并不是全局最优
- 迭代法与解析解的速度不是一个量级
fminsearch函数实例¶
1. 求解 z=(x+1)2+(y−1)2 的最小值
三维图像显示:
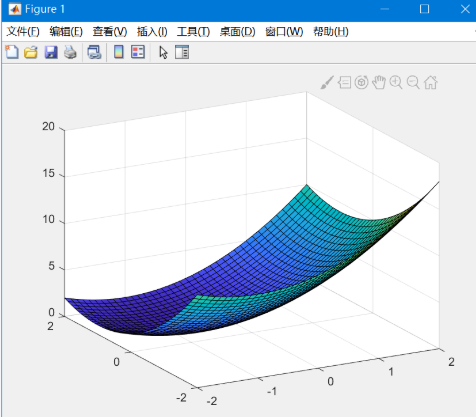
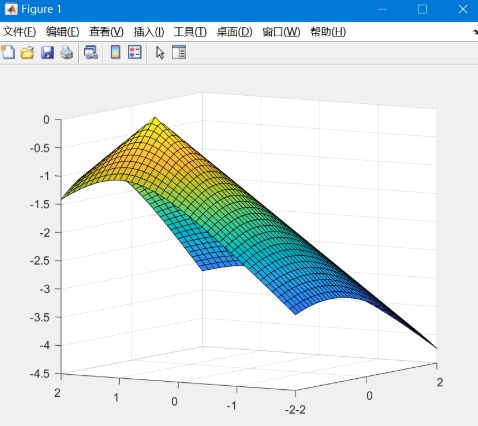
可能不太好从图像里看出极值,这里再举一个例子:
z=−√(x+1)2+(y−1)2 三维图
% 1.编写目标函数
function z = ObjectFunction(Beta)
z = (Beta(1)+1)^2 + (Beta(2)-1)^2;
% 2.初始参数设定
maxsize = 2000; % 生成均匀随机数的个数(用于赋初值)
REP = 100; % 若发散则继续进行迭代的次数
nInitialVectors = [maxsize, 2]; % 生成随机数向量
MaxFunEvals = 5000; % 函数评价的最大次数
MaxIter = 5000; % 允许迭代的最大次数
options = optimset('LargeScale', 'off','HessUpdate', 'dfp','MaxFunEvals', ...
MaxFunEvals, 'display', 'on', 'MaxIter', MaxIter, 'TolFun', 1e-6, 'TolX', 1e-6,'TolCon',10^-12);
% 3.寻找最优初值
initialTargetVectors = unifrnd(-5,5, nInitialVectors);
RQfval = zeros(nInitialVectors(1), 1);
for i = 1:nInitialVectors(1)
RQfval(i) = ObjectFunction(initialTargetVectors(i,:));
end
Results = [RQfval, initialTargetVectors];
SortedResults = sortrows(Results,1);
BestInitialCond = SortedResults(1,2: size(Results,2));
% 4.迭代求出最优估计值Beta
[Beta, fval exitflag] = fminsearch(' ObjectFunction ', BestInitialCond);
for it = 1:REP
if exitflag == 1, break, end
[Beta, fval exitflag] = fminsearch(' ObjectFunction ', BestInitialCond);
end
if exitflag~=1, warning('警告:迭代并没有完成'), end
2. 求解 lnL=−12ln2π−12ln[σ2ε/(1−β21)]−[y1−(β0/(1−β1))]22σ2ε/(1−β21)−T−12ln2π−T−12lnσ2ε−∑Tt=2(yt−β0−β1yt−1)22σ2ε 的最大值
%导入数据
data = xlsread('../数据/上证指数与沪深300.xlsx');
f1 = data(:,2);
% 1.编写目标函数
function lnL = ARlnL(Beta,Y)
%Beta(1) = Beta0 ;Beta(2) = Beta1 ;Beta(3) = siga ;
T = length(Y);
lnL1 = -0.5*log(2*pi)-0.5*log(Beta(3)^2/(1-Beta(2)^2))-(Y(1)-(Beta(1)/(1-Beta(2))))^2/(2*Beta(3)^2/(1-Beta(2)^2))-0.5*log(2*pi)*(T-1)-0.5*(T-1)*log(Beta(3)^2);
for i = 2:T
lnL2(i) = (Y(i)- Beta(1)-Beta(2)*Y(i-1))^2;
end
lnL = lnL1-0.5*sum(lnL2)/Beta(3)^2;
lnL = -lnL;
% 2.初始参数设定
maxsize = 2000; % 生成均匀随机数的个数(用于赋初值)
REP = 100; % 若发散则继续进行迭代的次数
nInitialVectors = [maxsize, 3]; % 生成随机数向量
MaxFunEvals = 5000; % 函数评价的最大次数
MaxIter = 5000; % 允许迭代的最大次数
options = optimset('LargeScale', 'off','HessUpdate', 'dfp','MaxFunEvals', ...
MaxFunEvals, 'display', 'on', 'MaxIter', MaxIter, 'TolFun', 1e-6, 'TolX', 1e-6,'TolCon',10^-12);
% 3.寻找最优初值
initialTargetVectors = unifrnd(-1,1, nInitialVectors);
RQfval = zeros(nInitialVectors(1), 1);
for i = 1:nInitialVectors(1)
RQfval(i) = ARlnL (initialTargetVectors(i,:), f1);
end
Results = [RQfval, initialTargetVectors];
SortedResults = sortrows(Results,1);
BestInitialCond = SortedResults(1,2: size(Results,2));
% 4.迭代求出最优估计值Beta
[Beta, fval exitflag] = fminsearch(' ARlnL ', BestInitialCond,options,f1);
for it = 1:REP
if exitflag == 1, break, end
[Beta, fval exitflag] = fminsearch(' ARlnL ', BestInitialCond,options,f1);
end
if exitflag~=1, warning('警告:迭代并没有完成'), end
最终结果为:
| c | AR(1) | sigma |
|---|---|---|
| 38.11 | 1.00 | 35.96 |