Part 1: 鉄道路線図データをグラフとして解釈して可視化する¶
このノートブックの基本データは、全て駅データ.jpの無料版データを利用させていただきました。
<img src="http://www.ekidata.jp/img/220x70_b.gif" alt="駅データ" border="0">
はじめに¶
無償で入手できる鉄道関係のデータをマッピングするためのCytoscapeセッションファイルを作成するために行った、データの加工過程です。(効率性は無視してありますのでご了承下さい。)
詳細はこちらの記事をご覧ください。
ゴール¶
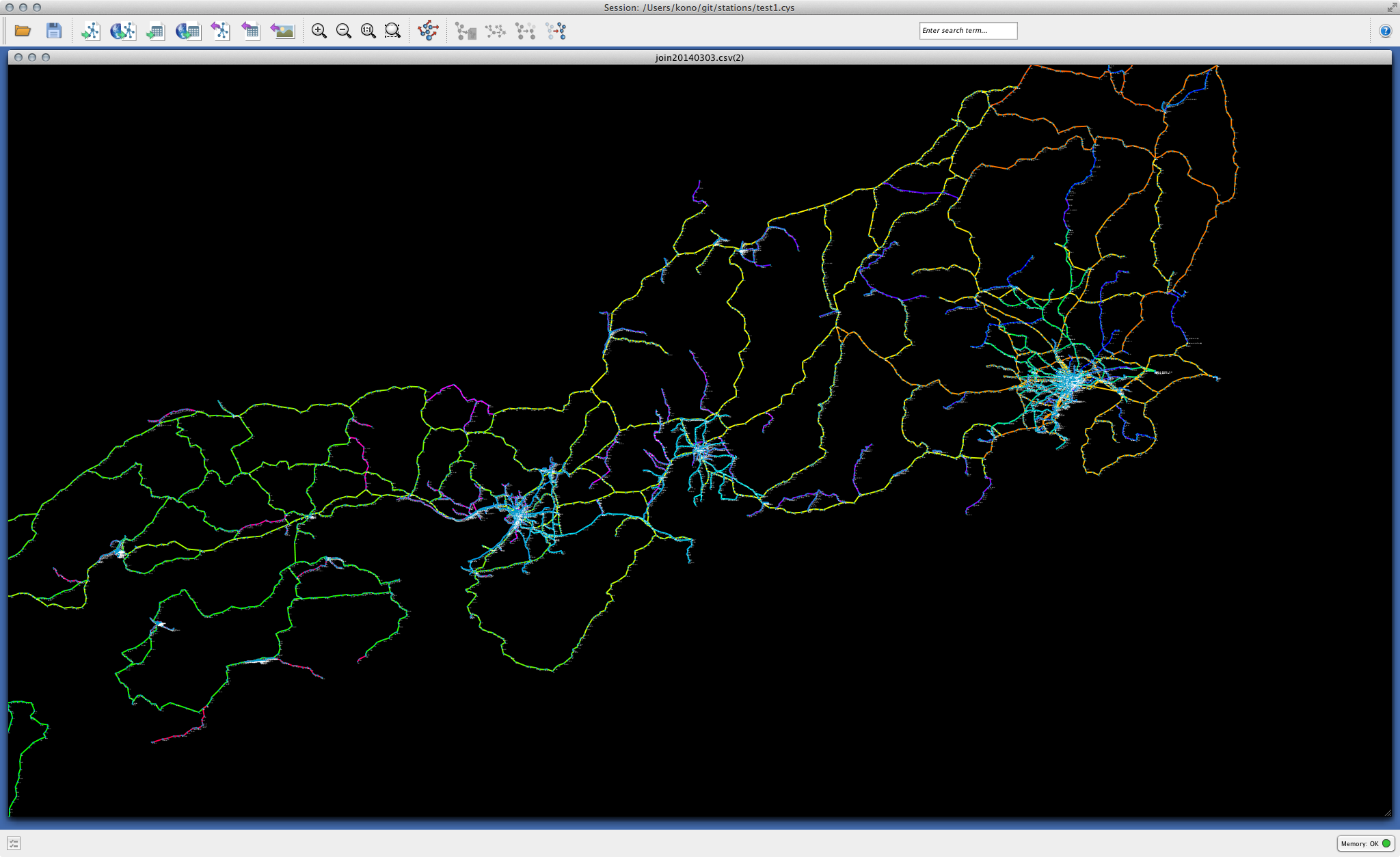
Cytoscape上利用できるグラフとしての白地図を作成する。
必要な知識¶
このサンプルを理解するのに必要な数学的知識はゼロです。基礎的なPythonとPandasの知識だけです。
アップデート情報¶
- 8/15/2014: 現在このノートはアップデート中です。随時修正を加えていきます。
実際のワークフロー¶
0. 必要なライブラリの読み込み¶
import pandas as pd
1. データの読み込み¶
まず、全てのデータをPandasのDataFrameに読み込みます。これは(現在の基準では)とても小さなデータセットなので、普通のラップトップでも全く問題ありません。すべての作業をメモリ上で行います。
# 駅に関するデータ
station_df = pd.read_csv('station20140303free.csv')
# 路線に関するデータ
connection_df = pd.read_csv('line20140303free.csv')
# 駅と駅の接続データ、つまりグラフ
graph_df = pd.read_csv('join20140303.csv')
# 鉄道会社のデータ
company_df = pd.read_csv('company20130120.csv')
# 県名と県IDのテーブル
pref_df = pd.read_csv('pref.csv')
# 路線名のリスト(後ほど使用)
line_names = connection_df[['line_cd', 'line_name']]
line_names.head()
| line_cd | line_name | |
|---|---|---|
| 0 | 1001 | 中央新幹線 |
| 1 | 1002 | 東海道新幹線 |
| 2 | 1003 | 山陽新幹線 |
| 3 | 1004 | 東北新幹線 |
| 4 | 1005 | 上越新幹線 |
5 rows × 2 columns
station_df.drop(['station_name_k', 'station_name_r', 'e_sort'], axis=1, inplace=True)
緯度と経度からCytoscapeの座標系に変換する¶
座標系の変換と言っても、特に複雑な計算は必要ありません。y軸の下が正の方向になっているので、それを修正し、あとは正しく表示されるようにスケーリングします。
SCALE_FACTOR = 10000
station_df['x'] = station_df['lon'] * SCALE_FACTOR
station_df['y'] = station_df['lat'] * (-SCALE_FACTOR)
県名のデータフレームと駅情報の統合¶
シンプルなマージを行い、県IDを県名に変換します
# 人間にとって読みやすいように、県のIDを県名に変換する
merged_stations = pd.merge(pref_df, station_df, on = 'pref_cd')
# 路線名も人が読めるものにする
merged_stations = pd.merge(merged_stations, line_names, on='line_cd')
# 必要の無くなったカラムを除去
merged_stations.drop(['pref_cd', 'line_cd'], axis=1, inplace=True)
merged_stations.head()
| pref_name | station_cd | station_g_cd | station_name | post | add | lon | lat | open_ymd | close_ymd | e_status | x | y | line_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 北海道 | 1110101 | 1110101 | 函館 | 040-0063 | 北海道函館市若松町12-13 | 140.726413 | 41.773709 | 1902-12-10 | NaN | 0 | 1407264.13 | -417737.09 | JR函館本線(函館~長万部) |
| 1 | 北海道 | 1110102 | 1110102 | 五稜郭 | 041-0813 | 函館市亀田本町 | 140.733539 | 41.803557 | NaN | NaN | 0 | 1407335.39 | -418035.57 | JR函館本線(函館~長万部) |
| 2 | 北海道 | 1110103 | 1110103 | 桔梗 | 041-1210 | 北海道函館市桔梗3丁目41-36 | 140.722952 | 41.846457 | 1902-12-10 | NaN | 0 | 1407229.52 | -418464.57 | JR函館本線(函館~長万部) |
| 3 | 北海道 | 1110104 | 1110104 | 大中山 | 041-1121 | 亀田郡七飯町大字大中山 | 140.713580 | 41.864641 | NaN | NaN | 0 | 1407135.80 | -418646.41 | JR函館本線(函館~長万部) |
| 4 | 北海道 | 1110105 | 1110105 | 七飯 | 041-1111 | 亀田郡七飯町字本町 | 140.688556 | 41.886971 | NaN | NaN | 0 | 1406885.56 | -418869.71 | JR函館本線(函館~長万部) |
5 rows × 14 columns
# 必要ないカラムの削除
connection_df.drop(['line_color_c', 'line_color_t', 'line_type', 'e_sort'], axis=1, inplace=True)
connection_df.head(5)
| line_cd | company_cd | line_name | line_name_k | line_name_h | lon | lat | zoom | e_status | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1001 | 3 | 中央新幹線 | チュウオウシンカンセン | 中央新幹線 | 137.493896 | 35.411438 | 8 | 1 |
| 1 | 1002 | 3 | 東海道新幹線 | トウカイドウシンカンセン | 東海道新幹線 | 137.721489 | 35.144122 | 7 | 0 |
| 2 | 1003 | 4 | 山陽新幹線 | サンヨウシンカンセン | 山陽新幹線 | 133.147896 | 34.419338 | 7 | 0 |
| 3 | 1004 | 2 | 東北新幹線 | トウホクシンカンセン | 東北新幹線 | 140.763192 | 38.274267 | 7 | 0 |
| 4 | 1005 | 2 | 上越新幹線 | ジョウエツシンカンセン | 上越新幹線 | 139.121488 | 36.798565 | 8 | 0 |
5 rows × 9 columns
事業者情報と路線データのマージ¶
このマージによりテーブルが冗長になりますが、Cytoscape上で便利なので実行して新しいテーブルにします。
connection_final_df= pd.merge(connection_df, company_df, on='company_cd')
connection_final_df.drop(['e_sort'], axis=1, inplace=True)
connection_final_df.head()
| line_cd | company_cd | line_name | line_name_k | line_name_h | lon | lat | zoom | e_status_x | rr_cd | company_name | company_name_k | company_name_h | company_name_r | company_url | company_type | e_status_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1001 | 3 | 中央新幹線 | チュウオウシンカンセン | 中央新幹線 | 137.493896 | 35.411438 | 8 | 1 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 |
| 1 | 1002 | 3 | 東海道新幹線 | トウカイドウシンカンセン | 東海道新幹線 | 137.721489 | 35.144122 | 7 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 |
| 2 | 11402 | 3 | JR身延線 | ミノブセン | JR身延線 | 138.532397 | 35.392163 | 10 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 |
| 3 | 11411 | 3 | JR中央本線(名古屋~塩尻) | チュウオウホンセン | JR中央本線(名古屋~塩尻) | 137.468492 | 35.662471 | 9 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 |
| 4 | 11413 | 3 | JR飯田線(豊橋~天竜峡) | イイダセン | JR飯田線(豊橋~天竜峡) | 137.668949 | 35.125648 | 10 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 |
5 rows × 17 columns
駅の接続データを路線情報と統合する¶
この路線接続データには、駅に関する情報のないものが含まれています。それらをひと工夫して除去します。
# グラフと路線データをマージ
graph_new_df = pd.merge(connection_final_df, graph_df, on='line_cd')
# 全てのユニークな駅IDを駅のデータフレームから取り出す
all_stations = merged_stations['station_cd'].unique()
# グラフデータに含まれるユニークな駅IDを抽出
st1 = graph_new_df['station_cd1']
st2 = graph_new_df['station_cd2']
stations_in_graph = pd.concat([st1,st2]).unique()
# データのない駅をチェックする関数
def has_loc(station_id1, station_id2, all_stations):
if station_id1 in all_stations and station_id2 in all_stations:
return True
else:
return False
# その関数を渡してラムダ式として適用
graph_new_df['has_station_data'] = graph_new_df.apply(lambda row: has_loc(row['station_cd1'], row['station_cd2'], all_stations), axis=1)
# データのないエッジを除去する
graph_final_df = graph_new_df[graph_new_df['has_station_data'] == True]
graph_final_df.head(3)
| line_cd | company_cd | line_name | line_name_k | line_name_h | lon | lat | zoom | e_status_x | rr_cd | company_name | company_name_k | company_name_h | company_name_r | company_url | company_type | e_status_y | station_cd1 | station_cd2 | has_station_data | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 11402 | 3 | JR身延線 | ミノブセン | JR身延線 | 138.532397 | 35.392163 | 10 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 | 1140201 | 1140202 | True |
| 17 | 11402 | 3 | JR身延線 | ミノブセン | JR身延線 | 138.532397 | 35.392163 | 10 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 | 1140202 | 1140203 | True |
| 18 | 11402 | 3 | JR身延線 | ミノブセン | JR身延線 | 138.532397 | 35.392163 | 10 | 0 | 11 | JR東海 | ジェイアールトウカイ | 東海旅客鉄道株式会社 | JR東海 | http://jr-central.co.jp/ | 1 | 0 | 1140203 | 1140204 | True |
3 rows × 20 columns
3.データの書き出し¶
今回は基礎を学ぶために、ファイルベースでデータをやりとりします。以下のCSVファイルはCytoscapeに容易に読み込めます。
graph_final_df.to_csv('graph_disconnected.csv')
merged_stations.to_csv('stations.csv')
# グループを抽出 (非効率なので当然ながら遅いけどシンプルなので)
groups = map(lambda x: merged_stations[merged_stations['station_g_cd'] == x], merged_stations['station_g_cd'].unique())
# 抽出のためのユーティリティ関数
def add_cl(df, edges):
group_members = df['station_cd']
processed = set([])
map(lambda station_id: add_edge(station_id, group_members, edges, processed), group_members)
def add_edge(current_station, stations, edges, processed):
for station in stations:
if station != current_station and station not in processed:
edges.append([station, 0, current_station])
processed.add(current_station)
# 新しいエッジを入れる入れ物
group_edges = []
map(lambda df: add_cl(df, group_edges) if len(df) != 1 else None, groups)
# 最終的にはデータフレームに
cliques_df = pd.DataFrame(group_edges, columns=['station_cd1', 'line_cd', 'station_cd2'])
# クリークのみをSIF形式のテーブルとして書き出してみます
cliques_df.to_csv('cliques.sif', sep=' ', index=False)
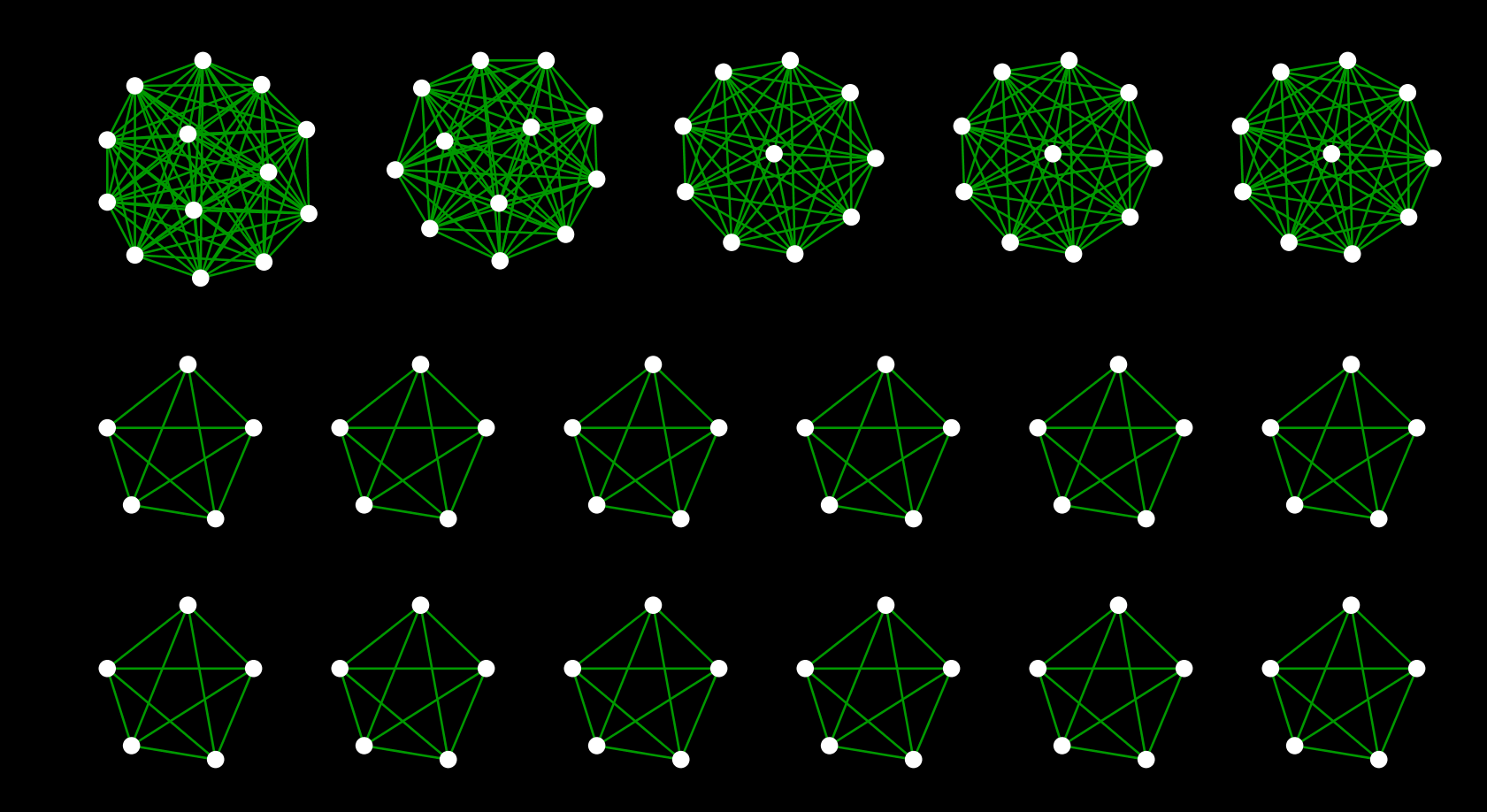
merged_graph = pd.concat([graph_final_df, cliques_df])
merged_graph.to_csv('graph_connected.csv')



公共データの掃除とマッピング¶
乗降客データはどこかにないかと探していたところ、それらしきものを発見したので使ってみます。
ソースはこちらです: http://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-S12.html
詳しいスペックはこちら
注意!¶
このデータ、実は壊れた状態で配布されています。こんな感じで簡単に修復できますが。
cat S12-13.xml | sed -e "s/ksj:ailroad/ksj:railroad/" > fixed.xml
XMLファイルを処理する¶
必要な部分を拾いだしてDataFrameにします。
(暫定版です。後ほど掃除します)
import xml.etree.ElementTree as ET
tree = ET.parse('fixed.xml')
root = tree.getroot()
PREFIX = '{http://nlftp.mlit.go.jp/ksj/schemas/ksj-app}'
passenger_array = []
entries = root.findall('./' + PREFIX + 'TheNumberofTheStationPassengersGettingonandoff')
# フィールド名の抽出
column_names = []
for col in entries[0]:
column_names.append(col.tag.split('}')[1])
# データを抽出する
for data in entries:
row=[]
for entry in data:
if(type(entry.text) is unicode):
row.append((entry.text).encode('utf-8'))
else:
row.append(entry.text)
passenger_array.append(row)
# データフレームへ
passenger_df = pd.DataFrame(passenger_array, columns=column_names)
# スペックシートから人力で人の読めるテーブルにする(ダメダメなやり方ですね...)
railroad_division = [
['普通鉄道 JR', '11'],
['普通鉄道', '12'],
['鋼索鉄道', '13'],
['懸垂式鉄道', '14'],
['跨座式鉄道', '15'],
['案内軌条式鉄道','16'],
['無軌条鉄道', '17'],
['軌道', '21'],
['懸垂式モノレール', '22'],
['跨座式モノレール', '23'],
['案内軌条式', '24'],
['浮上式', '25']
]
railroad_company_classification = [
['JR新幹線', '1'],
['JR在来線', '2'],
['公営鉄道', '3'],
['民営鉄道', '4'],
['第三セクター', '5']
]
rd_df = pd.DataFrame(railroad_division, columns=['rail_type', 'railroadDivision'])
company_type_df = pd.DataFrame(railroad_company_classification, columns=['company_type', 'railroadCompanyClassification'])
passenger_df.to_csv('passenger_original.csv')
passenger_df.head()
| station | stationName | administrationCompany | routeName | railroadDivision | railroadCompanyClassification | duplicate2011 | dataEorN2011 | remarks2011 | passengers2011 | duplicate2012 | dataEorN2012 | remarks2012 | passengers2012 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | 二月田 | 九州旅客鉄道 | 指宿枕崎線 | 11 | 2 | 1 | 3 | None | 0 | 1 | 3 | None | 0 |
| 1 | None | 古島 | 沖縄都市モノレール | 沖縄都市モノレール線 | 23 | 5 | 1 | 1 | None | 3907 | 1 | 1 | None | 3980 |
| 2 | None | お台場海浜公園 | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 1 | 1 | None | 14612 | 1 | 1 | None | 16130 |
| 3 | None | 船の科学館 | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 1 | 1 | None | 3767 | 1 | 1 | None | 3235 |
| 4 | None | テレコムセンター | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 1 | 1 | None | 12112 | 1 | 1 | None | 12775 |
5 rows × 14 columns
乗降客数などがちゃんとテーブル化されているのがわかります。ちなみにこの乗降客数は、一日あたりの平均値だそうです。
データ内容の検討¶
さて、これでとりあえず機械に読み込ませやすい形式にはなりましたが、さらなる利用をするために、どのように使うかを検討する必要があります。データの構造を見てみましょう。

ここで注目すべきは__重複コード__と言う項目です。どうやら、必ずしも駅ごとのデータがとれているわけではなく、データによっては他の駅の統計に合算されていたり、欠損値も存在するようです。更に調べると、他の駅に合算されている場合、合算先の駅は備考欄にIDで指定してあるわけではなく、人間用の文章で記述してあります。具体的には、こんな感じです:
remarks = pd.Series(passenger_df['remarks2011'].unique())
remarks[:10]
0 None 1 東日本旅客鉄道、花輪線を含む 2 長野電鉄、屋代線を含む 3 東日本旅客鉄道、小海線を含む 4 東武鉄道、桐生線を含む 5 天竜浜名湖鉄道、天竜浜名湖線を含む 6 東京都、1号線浅草線を含む 7 芝山鉄道、芝山鉄道線を含む 8 新京成電鉄、新京成線を含む 9 北総鉄道、北総線を含む dtype: object
これだと、機械的に合算内容を把握するのはとても面倒です。かと言って、現在のデータフレーム全部を単純に駅名でマッピングしても、合算の方法などによって可視化の結果が左右されてしまいます。
抜粋版のデータを作る¶
このように単純なマッピングではうまくいきそうにないので、抜粋版を作り、それでどのような感じになるか確かめる、と言う方針で行きます。つまり、簡単に正確なデータが手に入るものだけを利用します。作業としては、__dataEorNカラムのみを利用しデータが存在するものを取り出す__と言う単純なフィルタリングです。
passenger_df['is_complete'] = passenger_df.apply(
lambda row: True if row['dataEorN2011'] == '1' and row['dataEorN2012'] == '1' and row['duplicate2011'] == '1' and row['duplicate2012'] == '1' and row['remarks2011'] == None and row['remarks2012'] == None else False, axis=1)
passenger_filtered = passenger_df[passenger_df['is_complete']]
# 要らなくなった情報を除去
passenger_filtered.drop(['is_complete', 'station', 'duplicate2011', 'duplicate2012', 'remarks2011', 'remarks2012', 'dataEorN2011', 'dataEorN2012'], axis=1, inplace=True)
passenger_filtered.head()
-c:6: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame
| stationName | administrationCompany | routeName | railroadDivision | railroadCompanyClassification | passengers2011 | passengers2012 | |
|---|---|---|---|---|---|---|---|
| 1 | 古島 | 沖縄都市モノレール | 沖縄都市モノレール線 | 23 | 5 | 3907 | 3980 |
| 2 | お台場海浜公園 | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 14612 | 16130 |
| 3 | 船の科学館 | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 3767 | 3235 |
| 4 | テレコムセンター | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 12112 | 12775 |
| 5 | 汐留 | ゆりかもめ | 東京臨海新交通臨海線 | 24 | 5 | 6841 | 7617 |
5 rows × 7 columns
temp_df = pd.merge(passenger_filtered, rd_df, on='railroadDivision')
passenger_final_df = pd.merge(temp_df, company_type_df, on='railroadCompanyClassification')
# 必要なくなったカラムを消去
passenger_final_df.drop(['railroadDivision', 'railroadCompanyClassification'], axis=1, inplace=True)
passenger_final_df.to_csv('passenger_final.csv')
passenger_final_df[4000:4010]
| stationName | administrationCompany | routeName | passengers2011 | passengers2012 | rail_type | company_type | |
|---|---|---|---|---|---|---|---|
| 4000 | 南栄 | 豊橋鉄道 | 渥美線 | 3435 | 3422 | 普通鉄道 | 民営鉄道 |
| 4001 | 老津 | 豊橋鉄道 | 渥美線 | 747 | 729 | 普通鉄道 | 民営鉄道 |
| 4002 | 愛知大学前 | 豊橋鉄道 | 渥美線 | 6391 | 4281 | 普通鉄道 | 民営鉄道 |
| 4003 | 三河田原 | 豊橋鉄道 | 渥美線 | 2921 | 3003 | 普通鉄道 | 民営鉄道 |
| 4004 | 大清水 | 豊橋鉄道 | 渥美線 | 2940 | 3004 | 普通鉄道 | 民営鉄道 |
| 4005 | 高師 | 豊橋鉄道 | 渥美線 | 2607 | 2687 | 普通鉄道 | 民営鉄道 |
| 4006 | 芦原 | 豊橋鉄道 | 渥美線 | 580 | 621 | 普通鉄道 | 民営鉄道 |
| 4007 | 新豊橋 | 豊橋鉄道 | 渥美線 | 18298 | 16482 | 普通鉄道 | 民営鉄道 |
| 4008 | 豊島 | 豊橋鉄道 | 渥美線 | 471 | 453 | 普通鉄道 | 民営鉄道 |
| 4009 | 四十万 | 北陸鉄道 | 石川線 | 222 | 225 | 普通鉄道 | 民営鉄道 |
10 rows × 7 columns
結果の検討¶
かなり人間に読めるようになってきました。でも微妙に気持ち悪い値が入っています。
passenger_final_df[passenger_final_df['stationName'] == '南阿蘇白川水源']
| stationName | administrationCompany | routeName | passengers2011 | passengers2012 | rail_type | company_type | |
|---|---|---|---|---|---|---|---|
| 942 | 南阿蘇白川水源 | 南阿蘇鉄道 | 高森線 | 1 | 24 | 普通鉄道 | 第三セクター |
1 rows × 7 columns
一日の乗降客が一人ってありえるのでしょうか?駅の情報を見てみます

南阿蘇白川水源駅
- 2011年(平成23年)6月 阿蘇白川 - 見晴台間に白川水源の最寄となる新駅設置を発表。
- 2012年(平成24年)3月17日 - 開業。
- 2012年(平成24年)7月22日 - 駅舎完成[3]。
- 備考: 無人駅
開業前のデータがあるのは謎ですが、数字的にはありえそうです(試験走行時の統計?)。今回はたまたまこういった値を発見しましたが、実際には目視でこういったことをするのは困難です。だからこそ可視化という手法が生きてくるのですが。
なぜわざわざ人間の読める非効率的なデータに変換するのか?¶
これは機械にとってはメリットがないのですが、可視化を考えた時、数字などにエンコードされた情報は直接ラベル等として使用するのは使い勝手が悪いので、データのサイズが小さい場合は、効率性よりも実用性を重視して、このような変換を予め行っておくことで可視化の段階での複雑な操作を避ける事が出来ます。
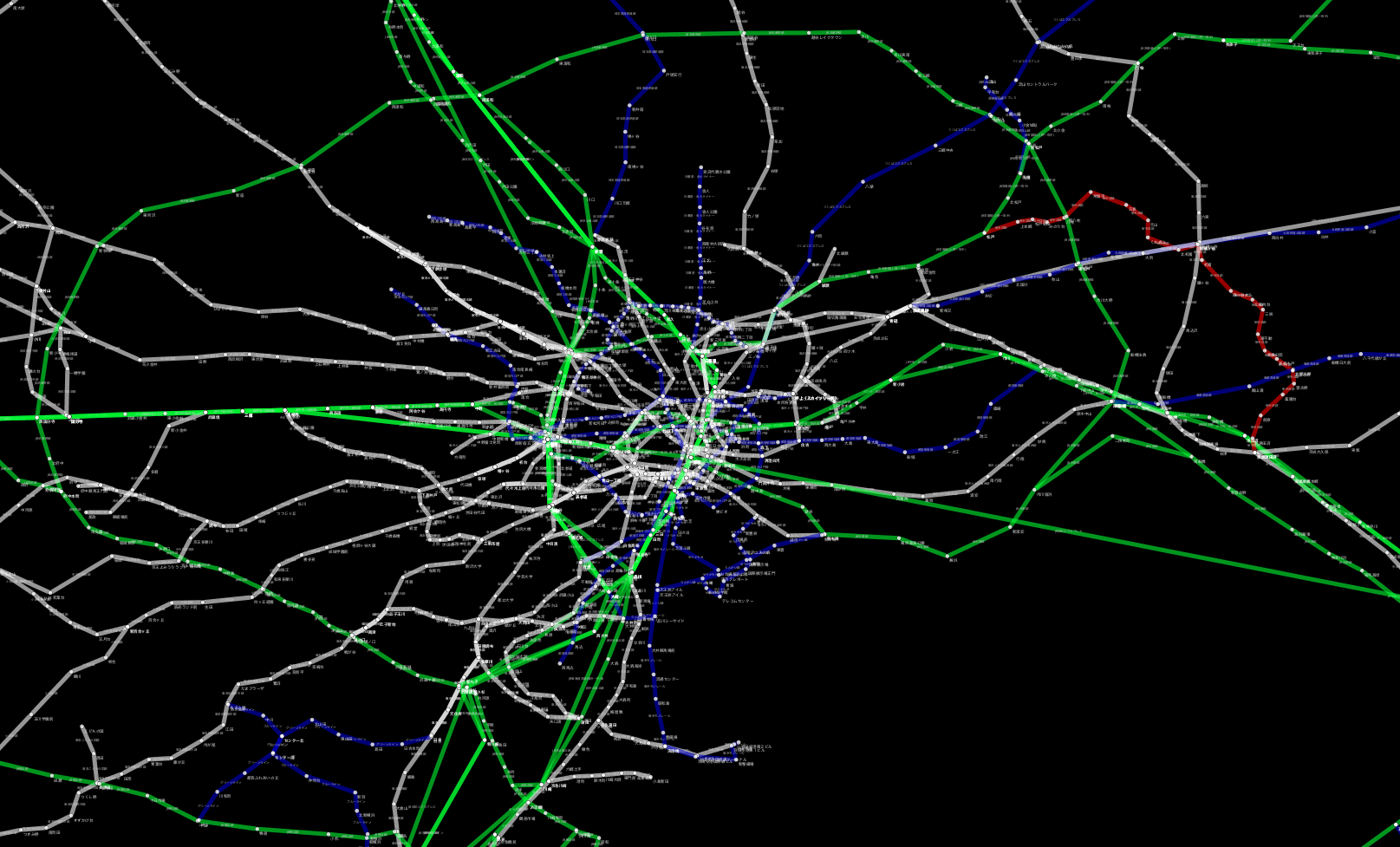
実際にマッピング¶
欲しかったのは、駅名と乗降客のシンプルなテーブルでしたが、かなりの回り道になってしまいました。ここからは実際にCytoscapeで可視化してみましょう。
東京メトロを題材としたマッピング¶
ここで東京メトロの乗降客を路線グラフ上で視覚的に把握してみようと思います。ところが、現時点で路線名のマップは行えません、なぜなら、一方は「__東京メトロ__」、もう一方は「__東京地下鉄__」と異なる名称を使っているからです。という訳で切り出し、変換、マージです。
tokyo_metro = passenger_final_df[passenger_final_df['administrationCompany'] == '東京地下鉄']
def create_line_name(company, line):
prefix = company.replace('地下鉄', 'メトロ')
suffix = line.split('線')[1]
return prefix + suffix + '線'
tokyo_metro['line_name'] = tokyo_metro.apply(lambda row: create_line_name(row['administrationCompany'], row['routeName']), axis=1)
tokyo_metro['station_name'] = tokyo_metro['stationName']
merged = pd.merge(merged_stations, tokyo_metro, on=['station_name', 'line_name'])
データタイプの変更¶
数字として扱わなければいけないものを文字列として読み込んでいるのを忘れていました。変換しましょう。
merged['passengers2012'] = merged['passengers2012'].astype(int)
merged['passengers2011'] = merged['passengers2011'].astype(int)
# 乗降客トップ10の駅を表示して、妥当性を検討する
sorted_df = merged.sort_index(by='passengers2012', ascending=False)
sorted_df[['station_name', 'line_name', 'passengers2012']][:10]
| station_name | line_name | passengers2012 | |
|---|---|---|---|
| 57 | 池袋 | 東京メトロ丸ノ内線 | 483952 |
| 64 | 大手町 | 東京メトロ丸ノ内線 | 277336 |
| 27 | 西船橋 | 東京メトロ東西線 | 274785 |
| 90 | 銀座 | 東京メトロ日比谷線 | 245548 |
| 56 | 渋谷 | 東京メトロ銀座線 | 226644 |
| 50 | 新橋 | 東京メトロ銀座線 | 223335 |
| 69 | 新宿 | 東京メトロ丸ノ内線 | 220154 |
| 82 | 上野 | 東京メトロ日比谷線 | 212509 |
| 29 | 高田馬場 | 東京メトロ東西線 | 186629 |
| 32 | 飯田橋 | 東京メトロ東西線 | 169830 |
10 rows × 3 columns
だいたい想像と一致しますね。無論、これは駅ごとのデータのみを抽出したものですから、巨大駅として複数の路線を合算した場合は、当然新宿とかがトップに来ると思いますが、地下鉄のひと駅当たりだとこんな感じで間違いなさそうです。
# 結果の書き出し
merged.to_csv('metro_data_table.csv')
スクレイピング: Webページの加工による路線ごとの色データ抽出¶
せっかくなので、このデータにもう一仕事してみましょう。路線ごとの色はラインカラーと呼ばれて、駅に掲示してある路線図などでお馴染みですね。残念ながら機械が読みやすいようなデータは見つからなかったのですが、Wikipediaにはちゃんとありました。
これをCytoscapeで使える形に加工しましょう。この作業は_スクレイピング_と呼ばれ、できれば避けたいイヤな作業なのですが、機械が理解できるWebがもっと充実するまで、仕方がないオーバーヘッドだと思って諦めましょう。
以下、正確さにも欠ける適当な処理ですが、とりあえず大方の情報は拾えます。路線名からRGBの文字列へ変換します。
from lxml.html import parse
from urllib2 import urlopen
page = parse(urlopen('http://ja.wikipedia.org/wiki/%E6%97%A5%E6%9C%AC%E3%81%AE%E9%89%84%E9%81%93%E3%83%A9%E3%82%A4%E3%83%B3%E3%82%AB%E3%83%A9%E3%83%BC%E4%B8%80%E8%A6%A7'))
doc = page.getroot()
table_rows = doc.findall('.//tr')
color_list = []
for row in table_rows:
line_name = None
line_color = None
row_data = row.findall('.//%s' % 'td')
for val in row_data:
style = val.get('style')
for child in val:
if child.tag is 'a':
line_name = child.get('title')
if style is not None:
line_color = style
if line_name is not None and line_color is not None:
new_color = line_color.split(';')[0].replace('background:', '')
color_list.append([line_name.encode('utf-8'), new_color.encode('utf-8')])
# データフレームに。
color_df = pd.DataFrame(color_list, columns=['line_name', 'line_color'])
# CSVとして書き出し
color_df.to_csv('line_colors.csv')
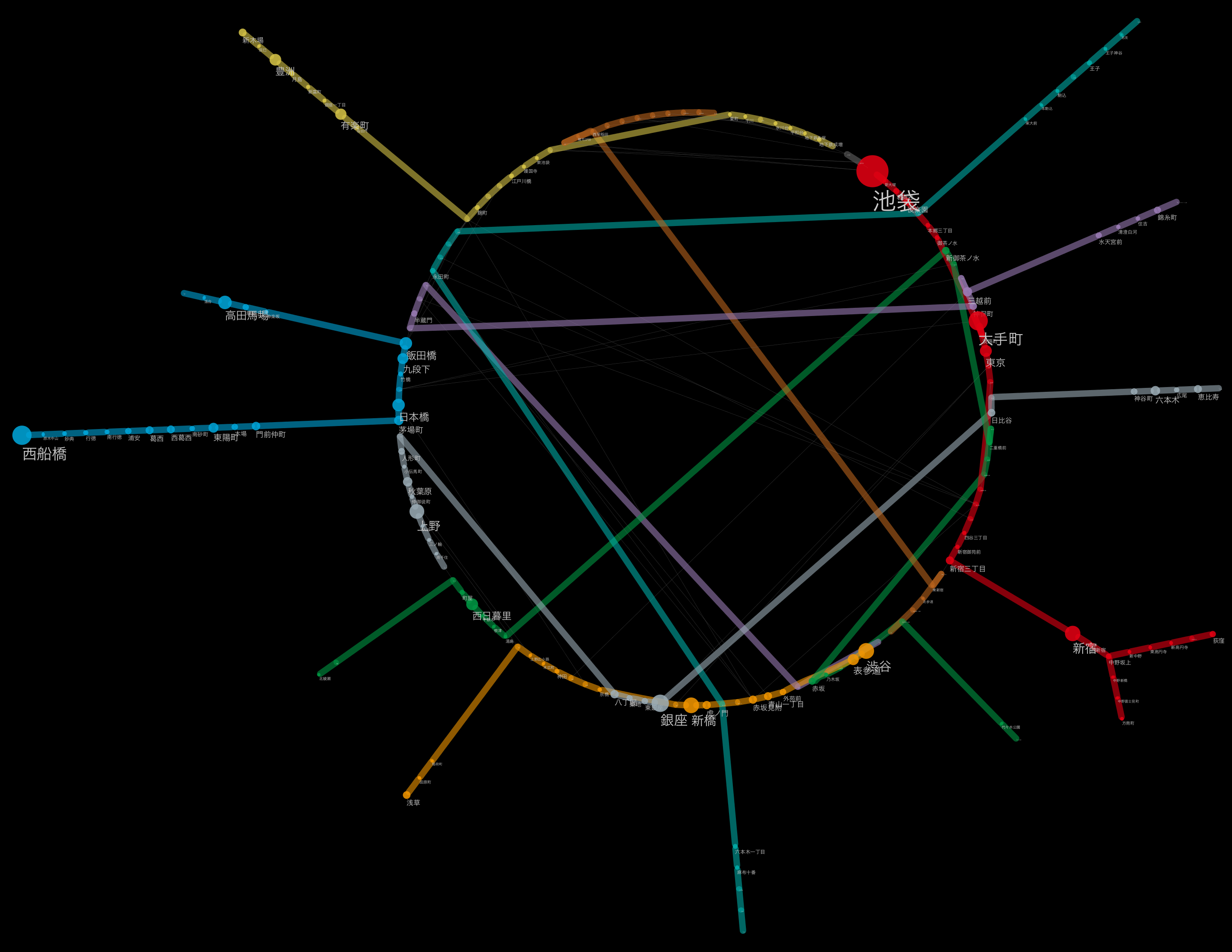
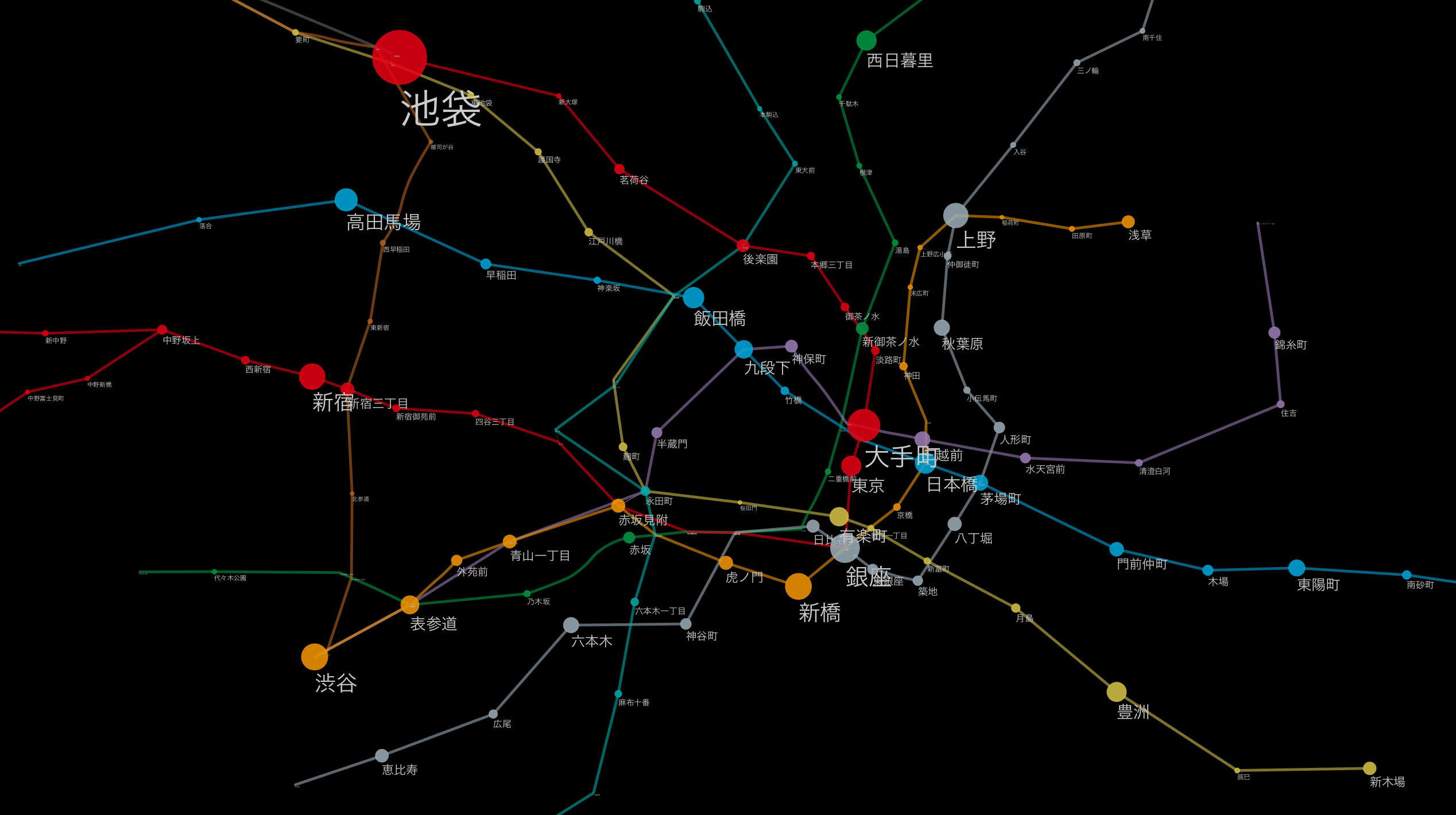
まとめ¶
このように、実際のデータ前処理はとても地道でつまらない作業が多いのも事実です。配布元がシンプルかつ正確に機械可読なデータを配布してくれればほとんどの問題は解決するのですが...
愚痴を言ってても始まらないので、在野の個人開発者や民間企業でも気軽に利用できる形でのデータの公開への提言をまとめて、公的機関に働きかけると言う活動もありかな、と思います。この記事をお読みの皆さんのように、実際にデータを使う人々の具体的指摘があったほうが、公開する側もやりやすいと思いますので。こういった話題に興味のある方は、ぜひ以下のグループに参加してみてください。
- Data Visualization Japan (Facebookグループです)