import pandas
df = pandas.read_csv("survey-results.csv")
df
| PyHEP feedback: Atlantic: 15:00 CET, 06:00 PDT, 18:30 IST, 22:00 JST | PyHEP feedback: Pacific: 00:00 CET, 15:00 PDT, 03:30 IST, 07:00 JST | PyHEP feedback: Indian Ocean: 09:00 CET, 00:00 PDT, 12:30 IST, 16:00 JST | PyHEP feedback: How did you hear about this workshop? | PyHEP feedback: What are you hoping to learn from this workshop? | Professional life: What best describes your occupation? | Professional life: What best describes the stage of your professional career? | Professional life: If you're involved in computing, what do you do? | Professional life: If you write software, what is its lifespan and scope? | Professional life: Are you associated with one or more experimental or theoretical collaborations? (E.g. ATLAS, CMS, DUNE, USQCD...) | ... | Particle physics ecosystem: hepunits: https://github.com/scikit-hep/hepunits | Particle physics ecosystem: particle: https://github.com/scikit-hep/particle | Particle physics ecosystem: pyjet: https://github.com/scikit-hep/pyjet | Particle physics ecosystem: Astropy: https://www.astropy.org | Particle physics ecosystem: Geant4Py: https://nusoft.fnal.gov/larsoft/doxsvn/html/md_geant4.10.03.p03_environments_g4py_README.html | Particle physics ecosystem: luigi: https://luigi.readthedocs.io | Particle physics ecosystem: Rucio: https://rucio.readthedocs.io | Particle physics ecosystem: Gaudi: https://github.com/lgiordani/gaudi | Particle physics ecosystem: Condor: https://htcondor.readthedocs.io/en/latest/apis/python-bindings | Particle physics ecosystem: Do you regularly use any other packages that weren't listed here? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Great! | BAD | Acceptable | My physics collaboration's mailing list(s) | Machine learning/deep learning toolkits; Parti... | I research particle physics (experiment, theor... | Grad student involved in research | Studies that improve the quality of reconstruc... | Deployed widely | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | Acceptable | BAD | Great! | HSF mailing lists or announcements; Word of mo... | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Grad student involved in research | Studies that improve the quality of reconstruc... | Used in small group | NaN | ... | Don't know what it is | Don't know what it is | Don't know what it is | Don't know what it is | Don't know what it is | Don't know what it is | Don't know what it is | Through dependencies only | Through dependencies only | NaN |
| 2 | Great! | BAD | Acceptable | Word of mouth (in person, personal email, chat... | Particle physics analysis tools (other than RO... | I develop/maintain software | Grad student involved in research | Developing libraries for data analysts (i.e. "... | Deployed widely | NaN | ... | Never | Never | Never | Never | Never | Never | Never | Never | Never | NaN |
| 3 | Great! | NaN | NaN | My physics collaboration's mailing list(s) | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Grad student involved in research | Software the simulates physics (e.g. Monte Car... | Mostly use-once | NaN | ... | Never | Never | Never | Never | Never | Never | Never | Through dependencies only | Never | NaN |
| 4 | Great! | BAD | Acceptable | My physics collaboration's mailing list(s) | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Postdoc/fellow/temporary research position | NaN | Used in small group | CMS | ... | Don't know what it is | Don't know what it is | Don't know what it is | Don't know what it is | Never | Don't know what it is | Don't know what it is | Don't know what it is | Regularly | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 400 | NaN | NaN | Great! | My physics collaboration's mailing list(s) | Python fundamentals (how to program in Python)... | I research particle physics (experiment, theor... | Research or management at a laboratory/college... | Software that controls/reads data from an expe... | I don't write software | CMS | ... | Don't know what it is | Regularly | Regularly | Through dependencies only | Regularly | Through dependencies only | All the time | Through dependencies only | Through dependencies only | NO, |
| 401 | BAD | Acceptable | Great! | Word of mouth (in person, personal email, chat... | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Grad student involved in research | Statistical analysis of reconstructed physics ... | I don't write software | No | ... | NaN | NaN | NaN | NaN | Through dependencies only | NaN | NaN | NaN | NaN | NaN |
| 402 | NaN | NaN | Great! | HSF mailing lists or announcements; HSF/PyHEP ... | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Postdoc/fellow/temporary research position | Software that controls/reads data from an expe... | NaN | NaN | ... | Never | Never | Never | Never | Never | Never | Through dependencies only | Never | Through dependencies only | NaN |
| 403 | Acceptable | BAD | Acceptable | My physics collaboration's mailing list(s) | General-purpose data analysis toolkits; Machin... | I'm studying physics but not doing research | Undergraduate student | Software that controls/reads data from an expe... | Used in small group | CMS | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 404 | Acceptable | BAD | Great! | My physics collaboration's mailing list(s) | General-purpose data analysis toolkits; Machin... | I research particle physics (experiment, theor... | Postdoc/fellow/temporary research position | Software that controls/reads data from an expe... | NaN | CMS | ... | Never | Never | Never | Never | Never | Never | Never | Never | Regularly | NaN |
405 rows × 105 columns
df["Professional life: What best describes your occupation?"].value_counts(ascending=True).plot.barh();

df["Professional life: What best describes the stage of your professional career?"].value_counts(ascending=True).plot.barh();

languages = [
"C or C++",
"Python",
"Matlab",
"Javascript or other browser-based (e.g. TypeScript, CoffeeScript)",
"Verilog, VHDL, or other hardware description language",
"R",
"Java or other JVM-based (e.g. Kotlin, Scala, Clojure)",
"Perl",
"PHP",
"C#",
"Julia",
"Go",
"Swift",
"Rust",
"Ruby",
"Haskell",
"Raw assembly or machine code",
"Other, not listed above",
]
def explode(responses):
responses = [response.strip() for response in responses.split(";")]
return [1.0 if language in responses else 0.0 for language in languages]
exploded = df[["Computing and programming: Which of the following languages do you use regularly (i.e. more than 10% of your work)?"]].fillna("").applymap(explode)
indicator = pandas.DataFrame(exploded.iloc[:, 0].tolist(), columns=languages)
indicator.div(indicator.sum(axis=1), axis=0).sum(axis=0).iloc[::-1].plot.barh(figsize=(5, 7));

df[[
"Computing and programming: Do you *expect* to use Python more or less in the future (as a fraction of your programming time)?",
"Computing and programming: Do you *want* to use Python more or less in the future (as a fraction of your programming time)?"
]].apply(pandas.Series.value_counts).loc[["Less", "About the same", "More", "Don't know"]].plot.bar(rot=0).legend(bbox_to_anchor=(1.2, 0.5));

cols = {x: x.split(":")[1].strip() for x in df.columns if x.startswith("Python ecosystem:") and "?" not in x}
order = ((df[list(cols)] == "Don't know what it is") | (df[list(cols)] == "Never")).sum(axis=0).sort_values(ascending=False).index.tolist()
pkgs = df[order].rename(columns=cols).apply(pandas.Series.value_counts).T[[
"Don't know what it is", "Never", "Through dependencies only", "Regularly", "All the time"
]].fillna(0)
pkgs.insert(0, "No selection", pkgs.sum(axis=1).max() - pkgs.sum(axis=1))
pkgs.plot.barh(stacked=True, width=0.9, figsize=(20, 20), color=["#5e79e0", "#798bd1", "#992cc7", "#f5f518", "#ffa640", "#ff5a30"]).legend(bbox_to_anchor=(1.2, 0.5));

cols = {x: x.split(":")[1].strip() for x in df.columns if x.startswith("Particle physics ecosystem:") and "?" not in x}
order = ((df[list(cols)] == "Don't know what it is") | (df[list(cols)] == "Never")).sum(axis=0).sort_values(ascending=False).index.tolist()
pkgs = df[order].rename(columns=cols).apply(pandas.Series.value_counts).T[[
"Don't know what it is", "Never", "Through dependencies only", "Regularly", "All the time"
]].fillna(0)
pkgs.insert(0, "No selection", pkgs.sum(axis=1).max() - pkgs.sum(axis=1))
pkgs.plot.barh(stacked=True, width=0.9, figsize=(20, 20), color=["#5e79e0", "#798bd1", "#992cc7", "#f5f518", "#ffa640", "#ff5a30"]).legend(bbox_to_anchor=(1.2, 0.5));

hopes = [
"Particle physics analysis tools (other than ROOT)",
"General-purpose data analysis toolkits",
"Machine learning/deep learning toolkits",
"Software engineering skills (beyond the fundamentals)",
"ROOT and PyROOT",
"Python fundamentals (how to program in Python)",
"Collaboration-specific topics",
"Other",
]
def explode(responses):
responses = [response.strip() for response in responses.split(";")]
return [1.0 if hope in responses else 0.0 for hope in hopes]
exploded = df[["PyHEP feedback: What are you hoping to learn from this workshop?"]].fillna("").applymap(explode)
indicator = pandas.DataFrame(exploded.iloc[:, 0].tolist(), columns=hopes)
indicator.div(indicator.sum(axis=1), axis=0).sum(axis=0).iloc[::-1].plot.barh(figsize=(5, 7));

Conclusions:¶
- You are mostly grad students and postdocs engaged in physics research.
- You use Python and C++ about equally, but want to use Python more.
- You are familiar with the major libraries of the Python world: NumPy, Matplotlib, machine learning.
- You are less familiar with Python libraries intended for physics analysis.
- But you want to learn.
So let's get started!
![]() is a pure-Python implementation of ROOT I/O.
is a pure-Python implementation of ROOT I/O.

![]() is a generalization of NumPy to data structures (such as jagged arrays).
is a generalization of NumPy to data structures (such as jagged arrays).

Interesting times!¶
We're in in the middle of a transition from Uproot 3.x → Uproot 4.x and Awkward 0.x → Awkward 1.x.
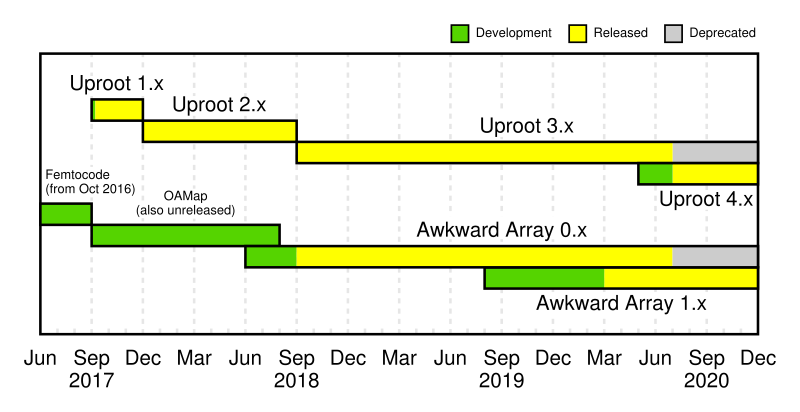
You can use both! Old and new versions are independently installable/importable.
| Now | Later this year | |
| Old versions | uproot, awkward | uproot3, awkward0 |
| New versions | uproot4, awkward1 | uproot, awkward |

What will this tutorial use?¶
New versions of both: Uproot 4 and Awkward 1. This tutorial is bleeding edge.
import uproot4
import awkward1 as ak
import numpy as np
In a nutshell¶
Uproot provides a short path from ROOT files to arrays.
np.array(uproot4.open("data/opendata_muons.root:Events/nMuon"))
array([2, 1, 2, ..., 2, 2, 2], dtype=uint32)
Let's break that down.
Exploring a file¶
root = uproot4.open("data/opendata_muons.root")
root
<ReadOnlyDirectory '/' at 0x7f2000010b50>
When you open a file, you get its root directory, which has the properties of a Python dict.
You can list its keys.
root.keys()
['Events;1']
You can get an item from it using square brackets.
root["Events"]
<TTree 'Events' (15 branches) at 0x7f200001c090>
(The ;1 wasn't necesssary—it's a "cycle number," which ROOT uses to distinguish objects in the same directory with the same name. If unspecified, you get the highest cycle number.)
from collections.abc import Mapping
isinstance(root, Mapping)
True
You can also get listings of objects by type.
root.classnames()
{'Events': 'TTree'}
Perhaps this file is more interesting:
nesteddirs = uproot4.open("data/nesteddirs.root")
nesteddirs.keys()
['one;1', 'one/two;1', 'one/two/tree;1', 'one/tree;1', 'three;1', 'three/tree;1']
nesteddirs["one/two"]
<ReadOnlyDirectory '/one/two' at 0x7f1ffffe4ed0>
nesteddirs["one/two"].keys()
['tree;1']
nesteddirs.classnames()
{'one': 'TDirectory',
'one/two': 'TDirectory',
'one/two/tree': 'TTree',
'one/tree': 'TTree',
'three': 'TDirectory',
'three/tree': 'TTree'}
At all levels, you can filter by name or type.
nesteddirs.keys(filter_classname="TTree")
['one/two/tree;1', 'one/tree;1', 'three/tree;1']
nesteddirs.classnames(filter_name="*t*")
{'one/two': 'TDirectory',
'one/two/tree': 'TTree',
'one/tree': 'TTree',
'three': 'TDirectory',
'three/tree': 'TTree'}
Histograms!¶
Uproot can read histograms (as well as most other ROOT objects), but it doesn't deal directly with them. The first thing that you do when extracting a histogram is to convert it to another library.
histograms = uproot4.open("data/hepdata-example.root")
histograms.classnames()
{'hpx': 'TH1F', 'hpxpy': 'TH2F', 'hprof': 'TProfile', 'ntuple': 'TNtuple'}
histograms["hpx"].to_boost()
Histogram(Regular(100, -4, 4, metadata={'@fUniqueID': 0, '@fBits': 50331648, 'fNdivisions': 510, 'fAxisColor': 1, 'fLabelColor': 1, 'fLabelFont': 42, 'fLabelOffset': 0.004999999888241291, 'fLabelSize': 0.03500000014901161, 'fTickLength': 0.029999999329447746, 'fTitleOffset': 1.0, 'fTitleSize': 0.03500000014901161, 'fTitleColor': 1, 'fTitleFont': 42, 'fNbins': 100, 'fXmin': -4.0, 'fXmax': 4.0, 'fFirst': 0, 'fLast': 0, 'fBits2': 0, 'fTimeDisplay': False, 'fTimeFormat': <TString '' at 0x7f1fffe86950>, 'name': 'xaxis', 'title': ''}), storage=Double()) # Sum: 74994.0 (75000.0 with flow)
This is a boost-histogram, a clean design of N-dimensional histograms in the Boost C++ library (with Python bindings). Boost-histogram focuses just on filling and manipulating (e.g. slicing) histograms.
But we want to plot it, right? There's another library, mplhep, which focuses just on plotting histograms in Matplotlib.
 |
 |
 |
import matplotlib.pyplot as plt
import mplhep
mplhep.histplot(histograms["hpx"].to_boost())
<matplotlib.axes._subplots.AxesSubplot at 0x7f1fc0fd9210>

plt.style.use(mplhep.style.CMS)
mplhep.histplot(histograms["hpx"].to_boost())
mplhep.cms.label()

plt.style.use(mplhep.style.ATLAS)
mplhep.histplot(histograms["hpx"].to_boost())
mplhep.atlas.label()

mplhep.hist2dplot(histograms["hpxpy"].to_boost());

histograms["hpx"].to_hist().plot();

histograms["hpxpy"].to_hist().plot();

histograms["hpxpy"].to_hist().plot2d_full();

from uncertainties import unumpy as unp
def pdf(x, a=1/np.sqrt(2*np.pi), x0=0, sigma=1, offset=0):
exp = unp.exp if a.dtype == np.dtype("O") else np.exp
return a * exp(-(x-x0)**2/(2*sigma**2)) + offset
histograms["hpx"].to_hist().plot_pull(pdf);

See the hist examples on how to do this more beautifully/elegantly.
Exploring a TTree¶

It's generally useful to first look at a TTree with show.
tree = root["Events"]
tree.show()
name | typename | interpretation
---------------------+----------------------+-----------------------------------
run | int32_t | AsDtype('>i4')
luminosityBlock | uint32_t | AsDtype('>u4')
event | uint64_t | AsDtype('>u8')
PV_npvs | int32_t | AsDtype('>i4')
PV_x | float | AsDtype('>f4')
PV_y | float | AsDtype('>f4')
PV_z | float | AsDtype('>f4')
nMuon | uint32_t | AsDtype('>u4')
Muon_pt | float[] | AsJagged(AsDtype('>f4'))
Muon_eta | float[] | AsJagged(AsDtype('>f4'))
Muon_phi | float[] | AsJagged(AsDtype('>f4'))
Muon_mass | float[] | AsJagged(AsDtype('>f4'))
Muon_charge | int32_t[] | AsJagged(AsDtype('>i4'))
Muon_pfRelIso04_all | float[] | AsJagged(AsDtype('>f4'))
Muon_tightId | bool[] | AsJagged(AsDtype('bool'))
These are all the branches of the TTree with the type name of the branch (if Uproot can determine it) and its interpretation as an array (if possible).
TTrees also have a dict-like interface.
tree.keys()
['run', 'luminosityBlock', 'event', 'PV_npvs', 'PV_x', 'PV_y', 'PV_z', 'nMuon', 'Muon_pt', 'Muon_eta', 'Muon_phi', 'Muon_mass', 'Muon_charge', 'Muon_pfRelIso04_all', 'Muon_tightId']
tree.items()
[('run', <TBranch 'run' at 0x7f200001c810>),
('luminosityBlock', <TBranch 'luminosityBlock' at 0x7f200001c510>),
('event', <TBranch 'event' at 0x7f200001cd90>),
('PV_npvs', <TBranch 'PV_npvs' at 0x7f200001c550>),
('PV_x', <TBranch 'PV_x' at 0x7f2000010050>),
('PV_y', <TBranch 'PV_y' at 0x7f20000c6950>),
('PV_z', <TBranch 'PV_z' at 0x7f1fffe12810>),
('nMuon', <TBranch 'nMuon' at 0x7f2000034350>),
('Muon_pt', <TBranch 'Muon_pt' at 0x7f2000034d10>),
('Muon_eta', <TBranch 'Muon_eta' at 0x7f2000083e50>),
('Muon_phi', <TBranch 'Muon_phi' at 0x7f200005d4d0>),
('Muon_mass', <TBranch 'Muon_mass' at 0x7f200005db10>),
('Muon_charge', <TBranch 'Muon_charge' at 0x7f200005df10>),
('Muon_pfRelIso04_all', <TBranch 'Muon_pfRelIso04_all' at 0x7f20000402d0>),
('Muon_tightId', <TBranch 'Muon_tightId' at 0x7f20000401d0>)]
tree.typenames()
{'run': 'int32_t',
'luminosityBlock': 'uint32_t',
'event': 'uint64_t',
'PV_npvs': 'int32_t',
'PV_x': 'float',
'PV_y': 'float',
'PV_z': 'float',
'nMuon': 'uint32_t',
'Muon_pt': 'float[]',
'Muon_eta': 'float[]',
'Muon_phi': 'float[]',
'Muon_mass': 'float[]',
'Muon_charge': 'int32_t[]',
'Muon_pfRelIso04_all': 'float[]',
'Muon_tightId': 'bool[]'}
isinstance(tree, Mapping)
True
tree.keys(filter_name="Muon_*")
['Muon_pt', 'Muon_eta', 'Muon_phi', 'Muon_mass', 'Muon_charge', 'Muon_pfRelIso04_all', 'Muon_tightId']
tree.keys(filter_typename="float[]")
['Muon_pt', 'Muon_eta', 'Muon_phi', 'Muon_mass', 'Muon_pfRelIso04_all']
tree.keys(filter_branch=lambda branch: not isinstance(branch.interpretation, uproot4.AsJagged))
['run', 'luminosityBlock', 'event', 'PV_npvs', 'PV_x', 'PV_y', 'PV_z', 'nMuon']
Turning branches into arrays¶
If a branch has a known interpretation, you can call array on it to get an array.
tree["Muon_pt"].array()
<Array [[52, 42.9], [5.02, ... [18.3, 9.72]] type='1000000 * var * float32'>
First thing to notice: this is not a NumPy array. It's because the data have different numbers of values in each element (a jagged array).
tree["Muon_pt"].array()[:20].tolist()
[[52.00833511352539, 42.85704040527344], [5.019948482513428], [15.967432022094727, 12.481289863586426], [53.42825698852539, 38.43761444091797], [7.178549766540527, 5.597340106964111], [47.27000427246094, 39.6187858581543], [5.050840377807617, 16.29404067993164], [17.36166763305664, 26.066043853759766], [42.84968566894531, 74.1303482055664], [33.52196502685547, 21.316774368286133], [13.822826385498047, 27.89041519165039], [12.187352180480957], [24.41823387145996, 3.560229778289795, 28.34453010559082], [22.598438262939453, 9.5486421585083], [12.511752128601074, 11.833377838134766, 45.572383880615234], [35.032833099365234, 36.92668533325195], [39.79318618774414, 39.22704315185547], [42.45128631591797, 45.18961715698242], [17.6611270904541, 7.474045753479004], [6.152662754058838]]
We can (in Uproot 4) force it to be a NumPy array, but it isn't pretty:
tree["Muon_pt"].array(library="np")[:20]
array([array([52.008335, 42.85704 ], dtype=float32),
array([5.0199485], dtype=float32),
array([15.967432, 12.48129 ], dtype=float32),
array([53.428257, 38.437614], dtype=float32),
array([7.17855, 5.59734], dtype=float32),
array([47.270004, 39.618786], dtype=float32),
array([ 5.0508404, 16.29404 ], dtype=float32),
array([17.361668, 26.066044], dtype=float32),
array([42.849686, 74.13035 ], dtype=float32),
array([33.521965, 21.316774], dtype=float32),
array([13.822826, 27.890415], dtype=float32),
array([12.187352], dtype=float32),
array([24.418234 , 3.5602298, 28.34453 ], dtype=float32),
array([22.598438, 9.548642], dtype=float32),
array([12.511752, 11.833378, 45.572384], dtype=float32),
array([35.032833, 36.926685], dtype=float32),
array([39.793186, 39.227043], dtype=float32),
array([42.451286, 45.189617], dtype=float32),
array([17.661127 , 7.4740458], dtype=float32),
array([6.1526628], dtype=float32)], dtype=object)
The data type (dtype) of this NumPy array is object, meaning that each element it contains is a Python object, namely another NumPy array.
The default is for all arrays to be Awkward arrays, but you can override this by specifying library.
The difference is that Awkward arrays interpret nested lists as a second dimension, whereas NumPy object arrays do not:
awkward_array = tree["Muon_pt"].array(library="ak")
numpy_array = tree["Muon_pt"].array(library="np")
# from the first 20 events, get the first item
awkward_array[:20, 0]
<Array [52, 5.02, 16, ... 42.5, 17.7, 6.15] type='20 * float32'>
# doesn't work with NumPy object arrays because contents are not guaranteed to be arrays
numpy_array[:20, 0]
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-48-daec92a4662c> in <module> 1 # doesn't work with NumPy object arrays because contents are not guaranteed to be arrays ----> 2 numpy_array[:20, 0] IndexError: too many indices for array
Another valid library is Pandas. Pandas has its own way of describing variable length structures (MultiIndex).
tree["Muon_pt"].array(library="pd")
entry subentry
0 0 52.008335
1 42.857040
1 0 5.019948
2 0 15.967432
1 12.481290
...
999997 1 3.336458
999998 0 4.999241
1 14.161738
999999 0 18.304218
1 9.717607
Length: 2366345, dtype: float32
In the original one-liner, we used colon (:) to separate a file path/URL from an object path to get to the branch:
uproot4.open("data/opendata_muons.root:Events/nMuon")
<TBranch 'nMuon' at 0x7f1f8c690fd0>
And "cast" the branch as a NumPy array, which is the same as calling array with library="np".
np.array(uproot4.open("data/opendata_muons.root:Events/nMuon"))
array([2, 1, 2, ..., 2, 2, 2], dtype=uint32)
This can be useful if you're passing the branch to a library that expects an array. (Warning: only do this with non-jagged arrays!)
import matplotlib.pyplot as plt
plt.hist(uproot4.open("data/opendata_muons.root:Events/nMuon"), bins=11, range=(-0.5, 10.5));

Pluralization¶
If you look carefully, you'll notice that there's an array function and an arrays function. The latter gets multiple arrays.
# NumPy arrays in a dict
pv_numpy = tree.arrays(filter_name="PV_*", library="np")
pv_numpy
{'PV_npvs': array([ 1, 1, 1, ..., 12, 20, 9], dtype=int32),
'PV_x': array([0.0722459 , 0.0722459 , 0.0722459 , ..., 0.07219489, 0.07082949,
0.06881613], dtype=float32),
'PV_y': array([0.06209353, 0.06209353, 0.06209353, ..., 0.06237721, 0.06023057,
0.06337257], dtype=float32),
'PV_z': array([-0.0280992 , -0.0280992 , -0.0280992 , ..., 1.5894414 ,
0.87497556, -0.6417597 ], dtype=float32)}
# Awkward record-array
pv_awkward = tree.arrays(filter_name="PV_*", library="ak")
pv_awkward
<Array [{PV_npvs: 1, ... PV_z: -0.642}] type='1000000 * {"PV_npvs": int32, "PV_x...'>
# Pandas DataFrame (as opposed to Series for a single array)
pv_pandas = tree.arrays(filter_name="PV_*", library="pd")
pv_pandas
| PV_npvs | PV_x | PV_y | PV_z | |
|---|---|---|---|---|
| 0 | 1 | 0.072246 | 0.062094 | -0.028099 |
| 1 | 1 | 0.072246 | 0.062094 | -0.028099 |
| 2 | 1 | 0.072246 | 0.062094 | -0.028099 |
| 3 | 1 | 0.072246 | 0.062094 | -0.028099 |
| 4 | 1 | 0.072246 | 0.062094 | -0.028099 |
| ... | ... | ... | ... | ... |
| 999995 | 11 | 0.072857 | 0.059204 | -0.903353 |
| 999996 | 16 | 0.073376 | 0.060643 | 0.519306 |
| 999997 | 12 | 0.072195 | 0.062377 | 1.589441 |
| 999998 | 20 | 0.070829 | 0.060231 | 0.874976 |
| 999999 | 9 | 0.068816 | 0.063373 | -0.641760 |
1000000 rows × 4 columns
All of these are "packages" of arrays that you might use in your analysis.
pv_numpy["PV_x"]
array([0.0722459 , 0.0722459 , 0.0722459 , ..., 0.07219489, 0.07082949,
0.06881613], dtype=float32)
pv_awkward["PV_x"]
<Array [0.0722, 0.0722, ... 0.0708, 0.0688] type='1000000 * float32'>
pv_awkward.PV_x
<Array [0.0722, 0.0722, ... 0.0708, 0.0688] type='1000000 * float32'>
pv_pandas["PV_x"]
0 0.072246
1 0.072246
2 0.072246
3 0.072246
4 0.072246
...
999995 0.072857
999996 0.073376
999997 0.072195
999998 0.070829
999999 0.068816
Name: PV_x, Length: 1000000, dtype: float32
pv_pandas.PV_x
0 0.072246
1 0.072246
2 0.072246
3 0.072246
4 0.072246
...
999995 0.072857
999996 0.073376
999997 0.072195
999998 0.070829
999999 0.068816
Name: PV_x, Length: 1000000, dtype: float32
Above, we used filter_name to select branches that match a pattern. We can also request specific branches:
tree.arrays(["PV_x", "PV_y", "PV_z"])
<Array [{PV_x: 0.0722, ... PV_z: -0.642}] type='1000000 * {"PV_x": float32, "PV_...'>
Or do calculations. (This feature exists for TTree aliases, which can be formulas.)
tree.arrays("PV", aliases={"PV": "sqrt(PV_x**2 + PV_y**2 + PV_z**2)"})
<Array [{PV: 0.0993}, ... {PV: 0.649}] type='1000000 * {"PV": float32}'>
tree.arrays("PV", cut="sqrt(PV_x**2 + PV_y**2) < 0.1", aliases={"PV": "sqrt(PV_x**2 + PV_y**2 + PV_z**2)"})
<Array [{PV: 0.0993}, ... {PV: 0.649}] type='954099 * {"PV": float32}'>
all_in_memory = uproot4.concatenate("data/uproot-sample-*.root:sample", ["i4", "ai8", "Af8", "str"])
all_in_memory
<Array [{i4: -15, ai8: [, ... str: 'hey-29'}] type='420 * {"i4": int64, "ai8": 3...'>
all_in_memory.i4
<Array [-15, -14, -13, -12, ... 11, 12, 13, 14] type='420 * int64'>
all_in_memory.ai8
<Array [[-14, -13, -12], ... [15, 16, 17]] type='420 * 3 * int64'>
all_in_memory.Af8
<Array [[], [-15], ... 10, 11.1, 12.2, 13.3]] type='420 * var * float64'>
all_in_memory.str
<Array ['hey-0', 'hey-1', ... 'hey-29'] type='420 * string'>
But, often enough, you don't have enough memory. What then?
Laziness¶
One option is to open them as lazy arrays, which opens the files (to get the number of events in each), but doesn't read the data until you use it.
not_in_memory_yet = uproot4.lazy("data/uproot-sample-*.root:sample")
not_in_memory_yet
<Array [{n: 0, b: True, ... str: 'hey-29'}] type='420 * {"n": int32, "b": bool, ...'>
"If it's not in memory, how can I see the values?"
Only the parts of the files (branches and batches of events) that are visible are read. In the above, n and b from the first file and str from the last file must have been read.
Let's get the Af8 field:
not_in_memory_yet.Af8
<Array [[], [-15], ... 10, 11.1, 12.2, 13.3]] type='420 * var * float64'>
Again, this only read from the first and last files to show the first and last values.
A mathematical operation would cause them all to be read in.
not_in_memory_yet.Af8 + 100
<Array [[], [85], ... [110, 111, 112, 113]] type='420 * var * float64'>
Controlling the lazy cache¶
After (part of) a lazy array has been read, how long does it stay in memory? Is it constantly being re-read every time we do a calculation?
By default, a 100 MB cache is associated with the lazy array, but we can provide our own if we want a bigger or smaller one.
cache = uproot4.LRUArrayCache("1 GB")
not_in_memory_yet = uproot4.lazy("data/uproot-sample-*.root:sample", array_cache=cache)
cache
<LRUArrayCache (0/1073741824 bytes full) at 0x7f1f8c5ce890>
not_in_memory_yet
<Array [{n: 0, b: True, ... str: 'hey-29'}] type='420 * {"n": int32, "b": bool, ...'>
cache
<LRUArrayCache (1386/1073741824 bytes full) at 0x7f1f8c5ce890>
not_in_memory_yet + 100
<Array [{n: 100, b: 101, ab: [, ... 150, 157]}] type='420 * {"n": int32, "b": in...'>
cache
<LRUArrayCache (154084/1073741824 bytes full) at 0x7f1f8c5ce890>
What's more, we can clear it when we need to.
cache.clear()
cache
<LRUArrayCache (0/1073741824 bytes full) at 0x7f1f8c5ce890>
Iteration¶
But often, that's still not enough control.
We don't read arrays into memory for the fun of it, we do it to perform calculations, and lazy arrays don't control which parts of which arrays are in memory during a calculation.
If you're worried about memory, the safest thing to do is to iterate over the data.
for arrays in uproot4.iterate("data/uproot-sample-*.root:sample", ["i4", "Af8"]):
print(arrays["i4"] + arrays["Af8"])
[[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]] [[], [-29], [-28, -26.9], [-27, -25.9, ... [23, 24.1, 25.2], [24, 25.1, 26.2, 27.3]]
This iteration is not one event at a time. (This set of TTrees has 420 entries.) It's a chunk of events at a time.
In each step, a chunk of events for all specified arrays (["i4", "Af8"]) is read. You do your calculation, move on to the next step, and all the previous arrays are dropped. (Only TBasket data carries over if event steps don't line up with TBasket boundaries—a low-level detail.)
Weird objects¶
Although Uproot is primarily for TTrees with simple types, it is possible to read some complex types.
weird = uproot4.open("data/uproot-stl_containers.root:tree")
weird.show()
name | typename | interpretation
---------------------+----------------------+-----------------------------------
string | std::string | AsStrings()
tstring | TString | AsStrings()
vector_int32 | std::vector<int32_t> | AsJagged(AsDtype('>i4'), header_by
vector_string | std::vector<std::str | AsObjects(AsVector(True, AsString(
vector_tstring | std::vector<TString> | AsObjects(AsVector(True, AsString(
vector_vector_int32 | std::vector<std::vec | AsObjects(AsVector(True, AsVector(
vector_vector_string | std::vector<std::vec | AsObjects(AsVector(True, AsVector(
vector_vector_tstrin | std::vector<std::vec | AsObjects(AsVector(True, AsVector(
vector_set_int32 | std::vector<std::set | AsObjects(AsVector(True, AsSet(Fal
vector_set_string | std::vector<std::set | AsObjects(AsVector(True, AsSet(Fal
set_int32 | std::set<int32_t> | AsObjects(AsSet(True, dtype('>i4')
set_string | std::set<std::string | AsObjects(AsSet(True, AsString(Fal
map_int32_int16 | std::map<int32_t, in | AsObjects(AsMap(True, dtype('>i4')
map_int32_vector_int | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_int32_vector_str | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_int32_set_int16 | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_int32_set_string | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_string_int16 | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_string_vector_in | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_string_vector_st | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_string_set_int16 | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_string_set_strin | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_int32_vector_vec | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_int32_vector_set | std::map<int32_t, st | AsObjects(AsMap(True, dtype('>i4')
map_string_string | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
map_string_tstring | std::map<std::string | AsObjects(AsMap(True, AsString(Tru
np.array(weird["map_string_vector_string"])
array([<STLMap {'one': ['one']} at 0x7f1fcb8f8890>,
<STLMap {'one': ['one'], 'two': ['one', 'two']} at 0x7f1fcb73a390>,
<STLMap {'one': ['one'], ..., 'two': ['one', 'two']} at 0x7f1fcb7439d0>,
<STLMap {'four': ['one', 'two', 'three', 'four'], ...} at 0x7f1fcb743e90>,
<STLMap {'five': ['one', 'two', 'three', 'four', 'five'], ...} at 0x7f1fcb748550>],
dtype=object)
HZZ = uproot4.open("data/uproot-HZZ-objects.root:events")
HZZ.show()
name | typename | interpretation
---------------------+----------------------+-----------------------------------
jetp4 | std::vector<TLorentz | AsJagged(AsStridedObjects(Model_TL
jetbtag | std::vector<float> | AsJagged(AsDtype('>f4'), header_by
jetid | std::vector<bool> | AsJagged(AsDtype('bool'), header_b
muonp4 | std::vector<TLorentz | AsJagged(AsStridedObjects(Model_TL
muonq | std::vector<int32_t> | AsJagged(AsDtype('>i4'), header_by
muoniso | std::vector<float> | AsJagged(AsDtype('>f4'), header_by
electronp4 | std::vector<TLorentz | AsJagged(AsStridedObjects(Model_TL
electronq | std::vector<int32_t> | AsJagged(AsDtype('>i4'), header_by
electroniso | std::vector<float> | AsJagged(AsDtype('>f4'), header_by
photonp4 | std::vector<TLorentz | AsJagged(AsStridedObjects(Model_TL
photoniso | std::vector<float> | AsJagged(AsDtype('>f4'), header_by
MET | TVector2 | AsStridedObjects(Model_TVector2_v3
MC_bquarkhadronic | TVector3 | AsStridedObjects(Model_TVector3_v3
MC_bquarkleptonic | TVector3 | AsStridedObjects(Model_TVector3_v3
MC_wdecayb | TVector3 | AsStridedObjects(Model_TVector3_v3
MC_wdecaybbar | TVector3 | AsStridedObjects(Model_TVector3_v3
MC_lepton | TVector3 | AsStridedObjects(Model_TVector3_v3
MC_leptonpdgid | int32_t | AsDtype('>i4')
MC_neutrino | TVector3 | AsStridedObjects(Model_TVector3_v3
num_primaryvertex | int32_t | AsDtype('>i4')
trigger_isomu24 | bool | AsDtype('bool')
eventweight | float | AsDtype('>f4')
HZZ["muonp4"].array(library="pd")
| fP | fE | ||||
|---|---|---|---|---|---|
| fX | fY | fZ | |||
| entry | subentry | ||||
| 0 | 0 | -52.899456 | -11.654672 | -8.160793 | 54.779499 |
| 1 | 37.737782 | 0.693474 | -11.307582 | 39.401695 | |
| 1 | 0 | -0.816459 | -24.404259 | 20.199968 | 31.690445 |
| 2 | 0 | 48.987831 | -21.723139 | 11.168285 | 54.739788 |
| 1 | 0.827567 | 29.800508 | 36.965191 | 47.488857 | |
| ... | ... | ... | ... | ... | ... |
| 2416 | 0 | -39.285824 | -14.607491 | 61.715790 | 74.602982 |
| 2417 | 0 | 35.067146 | -14.150043 | 160.817917 | 165.203949 |
| 2418 | 0 | -29.756786 | -15.303859 | -52.663750 | 62.395161 |
| 2419 | 0 | 1.141870 | 63.609570 | 162.176315 | 174.208633 |
| 2420 | 0 | 23.913206 | -35.665077 | 54.719437 | 69.556213 |
3825 rows × 4 columns
Sometimes, errors that people report as "Uproot can't read type X" don't have anything to do with type X.
To help zero in on actual deserialization errors, a lot more diagnostic information has been included. In Uproot 4, this is what a deserialization error looks like (encountered last Thursday):
TH1F version 2 as <dynamic>.Model_TH1F_v2 (939 bytes)
TH1 version 7 as <dynamic>.Model_TH1_v7 (893 bytes)
(base): <TNamed 'cutflow' title='dijethad' at 0x7fafb4505f90>
(base): <TAttLine (version 2) at 0x7fafb4506350>
(base): <TAttFill (version 2) at 0x7fafb4506390>
(base): <TAttMarker (version 2) at 0x7fafb4506310>
fNcells: 9
TAxis version 9 as <dynamic>.Model_TAxis_v9 (417 bytes)
(base): <TNamed 'xaxis' at 0x7fafb4506890>
(base): <TAttAxis (version 4) at 0x7fafb4506950>
fNbins: 7
fXmin: 0.0
fXmax: 7.0
fXbins: <TArrayD [] at 0x7fafb4506910>
fFirst: 0
fLast: 0
fBits2: 4
fTimeDisplay: False
fTimeFormat: <TString '' at 0x7fafb44dc1d0>
THashList version 5 as <dynamic>.Model_THashList_v0 (294 bytes)
TList version 1 as uproot4.models.TList.Model_TList (? bytes)
(base): <TObject None None at 0x7fafb4506fd0>
fName: ''
fSize: 475136
attempting to get bytes 1851028560:1851028561
outside expected range 0:939 for this Chunk
in file /home/pivarski/miniconda3/lib/python3.7/site-packages/skhep_testdata/data/uproot-issue33.root
in object /cutflow
The values get wonky in the THashList (fSize: 475136), which led directly to the issue.
To split or not to split¶
"Splitting branches" is a technical detail in ROOT, but very important in Uproot, since Uproot views branches as arrays.
Here is an "unsplit" file:
unsplit = uproot4.open("data/uproot-small-evnt-tree-nosplit.root:tree")
unsplit.show()
name | typename | interpretation ---------------------+----------------------+----------------------------------- evt | Event | AsObjects(Model_Event)
And here is a "split" file:
split = uproot4.open("data/uproot-small-evnt-tree-fullsplit.root:tree")
split.show()
name | typename | interpretation
---------------------+----------------------+-----------------------------------
evt | Event | AsObjects(Model_Event)
evt/Beg | TString | AsStrings()
evt/I16 | int16_t | AsDtype('>i2')
evt/I32 | int32_t | AsDtype('>i4')
evt/I64 | int64_t | AsDtype('>i8')
evt/U16 | uint16_t | AsDtype('>u2')
evt/U32 | uint32_t | AsDtype('>u4')
evt/U64 | uint64_t | AsDtype('>u8')
evt/F32 | float | AsDtype('>f4')
evt/F64 | double | AsDtype('>f8')
evt/Str | TString | AsStrings()
evt/P3 | unknown | None
evt/P3/P3.Px | int32_t | AsDtype('>i4')
evt/P3/P3.Py | double | AsDtype('>f8')
evt/P3/P3.Pz | int32_t | AsDtype('>i4')
evt/ArrayI16[10] | int16_t[10] | AsDtype("('>i2', (10,))")
evt/ArrayI32[10] | int32_t[10] | AsDtype("('>i4', (10,))")
evt/ArrayI64[10] | int64_t[10] | AsDtype("('>i8', (10,))")
evt/ArrayU16[10] | uint16_t[10] | AsDtype("('>u2', (10,))")
evt/ArrayU32[10] | uint32_t[10] | AsDtype("('>u4', (10,))")
evt/ArrayU64[10] | uint64_t[10] | AsDtype("('>u8', (10,))")
evt/ArrayF32[10] | float[10] | AsDtype("('>f4', (10,))")
evt/ArrayF64[10] | double[10] | AsDtype("('>f8', (10,))")
evt/N | uint32_t | AsDtype('>u4')
evt/SliceI16 | int16_t* | AsJagged(AsDtype('>i2'), header_by
evt/SliceI32 | int32_t* | AsJagged(AsDtype('>i4'), header_by
evt/SliceI64 | int64_t* | AsJagged(AsDtype('>i8'), header_by
evt/SliceU16 | uint16_t* | AsJagged(AsDtype('>u2'), header_by
evt/SliceU32 | uint32_t* | AsJagged(AsDtype('>u4'), header_by
evt/SliceU64 | uint64_t* | AsJagged(AsDtype('>u8'), header_by
evt/SliceF32 | float* | AsJagged(AsDtype('>f4'), header_by
evt/SliceF64 | double* | AsJagged(AsDtype('>f8'), header_by
evt/StdStr | std::string | AsStrings(header_bytes=6)
evt/StlVecI16 | std::vector<int16_t> | AsJagged(AsDtype('>i2'), header_by
evt/StlVecI32 | std::vector<int32_t> | AsJagged(AsDtype('>i4'), header_by
evt/StlVecI64 | std::vector<int64_t> | AsJagged(AsDtype('>i8'), header_by
evt/StlVecU16 | std::vector<uint16_t | AsJagged(AsDtype('>u2'), header_by
evt/StlVecU32 | std::vector<uint32_t | AsJagged(AsDtype('>u4'), header_by
evt/StlVecU64 | std::vector<uint64_t | AsJagged(AsDtype('>u8'), header_by
evt/StlVecF32 | std::vector<float> | AsJagged(AsDtype('>f4'), header_by
evt/StlVecF64 | std::vector<double> | AsJagged(AsDtype('>f8'), header_by
evt/StlVecStr | std::vector<std::str | AsObjects(AsVector(True, AsString(
evt/End | TString | AsStrings()
It's the same data, and they look the same in ROOT. But since a branch is a unit of what can be read into an array, we have to read whole objects or nothing.
unsplit["evt"].array()
<Array [{ArrayF32: [0, 0, ... U64: 99}] type='100 * Event["ArrayF32": 10 * float...'>
But with the split file, we can choose which parts to read.
split.arrays(["P3.Px", "P3.Py", "P3.Pz"])
<Array [{P3.Px: -1, P3.Py: 0, ... P3.Pz: 98}] type='100 * {"P3.Px": int32, "P3.P...'>
If there are any types in an unsplit object that Uproot can't deserialize, Uproot won't be able to read any of its data.
If there are any types in a split object that Uproot can't deserialize, Uproot will be able to read everything else.
Also, split objects are usually faster to read, even if you read everything.
Split your data whenever possible!
Writing to ROOT files¶
Uproot 4 cannot write to ROOT files yet: see Uproot 3 documentation.
Some caveats, though:
- Writing ROOT files with Uproot will always be minimal: histograms and only basic types in TTrees.
- You won't be able to update an existing file, only make new files.
- It won't be as fast as writing with ROOT.
The issues involved in writing an established format are considerably different from reading. If anyone thinks they can do better, they're welcome to try!
Why do we need our own array library? It's a long story, but if you're interested, I presented it to non-physicists here:

Let's take another look at the muon data.
tree = uproot4.open("data/opendata_muons.root:Events")
tree.show()
name | typename | interpretation
---------------------+----------------------+-----------------------------------
run | int32_t | AsDtype('>i4')
luminosityBlock | uint32_t | AsDtype('>u4')
event | uint64_t | AsDtype('>u8')
PV_npvs | int32_t | AsDtype('>i4')
PV_x | float | AsDtype('>f4')
PV_y | float | AsDtype('>f4')
PV_z | float | AsDtype('>f4')
nMuon | uint32_t | AsDtype('>u4')
Muon_pt | float[] | AsJagged(AsDtype('>f4'))
Muon_eta | float[] | AsJagged(AsDtype('>f4'))
Muon_phi | float[] | AsJagged(AsDtype('>f4'))
Muon_mass | float[] | AsJagged(AsDtype('>f4'))
Muon_charge | int32_t[] | AsJagged(AsDtype('>i4'))
Muon_pfRelIso04_all | float[] | AsJagged(AsDtype('>f4'))
Muon_tightId | bool[] | AsJagged(AsDtype('bool'))
We've already seen that it's "awkward" to deal with the jagged arrays in NumPy. However, they look and feel like records if "zipped" into an Awkward array.
events = tree.arrays(library="ak", how="zip")
events
<Array [{run: 194778, ... ] type='1000000 * {"run": int32, "luminosityBlock": ui...'>
The data type encapsulates the structure of the events.
ak.type(events)
1000000 * {"run": int32, "luminosityBlock": uint32, "event": uint64, "PV_npvs": int32, "PV_x": float32, "PV_y": float32, "PV_z": float32, "nMuon": uint32, "Muon": var * {"pt": float32, "eta": float32, "phi": float32, "mass": float32, "charge": int32, "pfRelIso04_all": float32, "tightId": bool}}
1000000 * means that there are a million events, "Muon": var * means that the contents of the "Muon" field are jagged: there's a variable number of them per event.
We could look at a few of these as Python lists and dicts.
ak.to_list(events[:3])
[{'run': 194778,
'luminosityBlock': 51,
'event': 12887941,
'PV_npvs': 1,
'PV_x': 0.07224589586257935,
'PV_y': 0.06209353357553482,
'PV_z': -0.02809920161962509,
'nMuon': 2,
'Muon': [{'pt': 52.00833511352539,
'eta': 1.2523202896118164,
'phi': 0.8424168229103088,
'mass': 0.10565836727619171,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False},
{'pt': 42.85704040527344,
'eta': 1.6531223058700562,
'phi': -2.154824733734131,
'mass': 0.10565836727619171,
'charge': -1,
'pfRelIso04_all': -999.0,
'tightId': False}]},
{'run': 194778,
'luminosityBlock': 51,
'event': 12963969,
'PV_npvs': 1,
'PV_x': 0.07224589586257935,
'PV_y': 0.06209353357553482,
'PV_z': -0.02809920161962509,
'nMuon': 1,
'Muon': [{'pt': 5.019948482513428,
'eta': 2.1219534873962402,
'phi': 1.7212640047073364,
'mass': 0.10565836727619171,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False}]},
{'run': 194778,
'luminosityBlock': 51,
'event': 13227276,
'PV_npvs': 1,
'PV_x': 0.07224589586257935,
'PV_y': 0.06209353357553482,
'PV_z': -0.02809920161962509,
'nMuon': 2,
'Muon': [{'pt': 15.967432022094727,
'eta': -1.241450548171997,
'phi': -2.8183231353759766,
'mass': 0.10565836727619171,
'charge': -1,
'pfRelIso04_all': -999.0,
'tightId': False},
{'pt': 12.481289863586426,
'eta': -0.7956085205078125,
'phi': -1.5160582065582275,
'mass': 0.10565836727619171,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False}]}]
But the data are not actually arranged as objects in memory; each field ("pt", "eta", "phi", etc.) is in an array by itself.
This means that structure-changing things like pulling out the kinematics are not expensive computations. (That is, they do not scale with the size of the dataset.)
You can project out and remix them without penalty.
events["Muon", ["pt", "eta", "phi"]]
<Array [[{pt: 52, eta: 1.25, ... phi: -3.01}]] type='1000000 * var * {"pt": floa...'>
ak.type(events["Muon", ["pt", "eta", "phi"]])
1000000 * var * {"pt": float32, "eta": float32, "phi": float32}
events["Muon", "pz"] = events["Muon", "pt"] * np.sinh(events["Muon", "eta"])
ak.type(events.Muon)
1000000 * var * {"pt": float32, "eta": float32, "phi": float32, "mass": float32, "charge": int32, "pfRelIso04_all": float32, "tightId": bool, "pz": float32}
events.Muon.pz
<Array [[83.5, 108], ... [71.7, 19.1]] type='1000000 * var * float32'>
Since nearly all of you are familiar with NumPy, slicing arrays with boolean arrays is probably familiar to you.
What's new is that the boolean arrays can now be jagged to slice jagged arrays (i.e. cut particles).
events.Muon.pt > 20
<Array [[True, True], ... [False, False]] type='1000000 * var * bool'>
events.Muon[events.Muon.pt > 20]
<Array [[{pt: 52, eta: 1.25, ... [], []] type='1000000 * var * {"pt": float32, "...'>
ak.any(events.Muon.pt > 20, axis=1)
<Array [True, False, False, ... False, False] type='1000000 * bool'>
events.Muon[ak.any(events.Muon.pt > 20, axis=1)]
<Array [[{pt: 52, eta: 1.25, ... pz: -5.76}]] type='384536 * var * {"pt": float3...'>
Awkward analysis¶
Several new operations are needed when arrays can have arbitrary data structures, so the Awkward Array library is best seen as a collection of functions acting on ak.Array (the array type).
Probably the most important of these is ak.num, which tells us the number of elements in each nested list.
ak.num(events.Muon)
<Array [2, 1, 2, 2, 2, 2, ... 4, 2, 2, 2, 2, 2] type='1000000 * int64'>
That's how many muons there are in each event.
This becomes necessary if we ever try to select the first (and second, etc.) element in each event. Some events might not have any.
events.Muon[:, 0]
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-107-74aedcb9e3df> in <module> ----> 1 events.Muon[:, 0] ~/miniconda3/lib/python3.7/site-packages/awkward1/highlevel.py in __getitem__(self, where) 855 have the same dimension as the array being indexed. 856 """ --> 857 return awkward1._util.wrap(self._layout[where], self._behavior) 858 859 def __setitem__(self, where, what): ValueError: in ListArray64 attempting to get 0, index out of range
So we use ak.num to slice the first dimension.
events.Muon[ak.num(events.Muon) > 0, 0]
<Array [{pt: 52, eta: 1.25, ... pz: 71.7}] type='969031 * {"pt": float32, "eta":...'>
Masking vs cutting¶
In the nearly two years that physicists have been doing analyses with Awkward Arrays, they've found that cuts are difficult to accumulate. If the first cut changes the length of the array from 1000000 to 969031, boolean arrays that could be applied to the first array can't be applied to the second array.
In practice, they've taken a logical-and of all cuts and apply them at the end, but we can do better: we can mask, rather than cut.
events.Muon.mask[events.Muon.pt > 20]
<Array [[{pt: 52, eta: 1.25, ... [None, None]] type='1000000 * var * ?{"pt": flo...'>
One of the new types that Awkward Array introduces is the "option type," which allows some values to be None. (It's a ? in the type specification.)
Making regular arrays¶
If you're feeding your data into a machine learning pipeline, you might need the jaggedness to go away. There are functions for padding jagged arrays (with None) so that they reach a desired length (and replacing None with a preferred value): ak.pad_none (and ak.fill_none).
ak.pad_none(events.Muon.pt, 3, clip=True)
<Array [[52, 42.9, None, ... 18.3, 9.72, None]] type='1000000 * 3 * ?float32'>
ak.fill_none(ak.pad_none(events.Muon.pt, 3, clip=True), 0)
<Array [[52, 42.9, 0], ... [18.3, 9.72, 0]] type='1000000 * 3 * float64'>
When you're plotting something, you usually want to flatten the jaggedness.
plt.hist(ak.flatten(events.Muon.pt), bins=120, range=(0, 60));

Awkward combinatorics¶
We often want to find pairs of particles with some invariant mass. To do that, we need combinatoric functions like ak.cartesian and ak.combinations.
| Cartesian product (per event) | n-choose-k combinations (per event) |
 |  |
muon_pairs = ak.combinations(events.Muon, 2)
muon_pairs
<Array [[({pt: 52, eta: 1.25, ... pz: 19.1})]] type='1000000 * var * ({"pt": flo...'>
m1, m2 = ak.unzip(muon_pairs)
m1, m2
(<Array [[{pt: 52, eta: 1.25, ... pz: 71.7}]] type='1000000 * var * {"pt": float3...'>,
<Array [[{pt: 42.9, eta: 1.65, ... pz: 19.1}]] type='1000000 * var * {"pt": floa...'>)
masses = np.sqrt(2*m1.pt*m2.pt*(np.cosh(m1.eta - m2.eta) - np.cos(m1.phi - m2.phi)))
masses
<Array [[96.1], [], [18.3, ... [17.9], [14.6]] type='1000000 * var * float32'>
plt.hist(ak.flatten(masses), bins=80, range=(70, 110));

plt.hist(ak.flatten(masses), bins=240, range=(0, 12))
plt.yscale("log")


The NumPy-like expressions for combinatorics look weird. It's fine for simple things when you get the hang of it, but really complex or performance-critical array expressions can be hard to write.
Numba lets you write Python for loops, but then it compiles them as though they were C functions.
Only a subset of Python and NumPy are accepted by its compiler, but Awkward Arrays are included.
import numba as nb
@nb.jit
def find_energetic_muon(events):
for event in events:
for muon in event.Muon:
if muon.pt > 100000:
return muon
return None
find_energetic_muon(events).tolist()
{'pt': 124582.25,
'eta': 1.2202473878860474,
'phi': 1.9215593338012695,
'mass': 0.1056494414806366,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False,
'pz': 192658.265625}
Or better yet,
@nb.jit
def find_energetic_muons_event(events):
for i in range(len(events)):
for muon in events[i].Muon:
if muon.pt > 100000:
return i
return -1
find_energetic_muons_event(events)
7400
events[7400].tolist()
{'run': 194120,
'luminosityBlock': 267,
'event': 200402745,
'PV_npvs': 6,
'PV_x': 0.07382062822580338,
'PV_y': 0.06162504851818085,
'PV_z': 2.451892137527466,
'nMuon': 4,
'Muon': [{'pt': 23.145275115966797,
'eta': -1.4625529050827026,
'phi': -0.7058165669441223,
'mass': 0.10565836727619171,
'charge': 1,
'pfRelIso04_all': 2.859344959259033,
'tightId': True,
'pz': -47.2779541015625},
{'pt': 37.34275436401367,
'eta': 1.2313216924667358,
'phi': 1.9259896278381348,
'mass': 0.10565836727619171,
'charge': -1,
'pfRelIso04_all': 1.151142954826355,
'tightId': True,
'pz': 58.51325225830078},
{'pt': 12.710587501525879,
'eta': -1.3235374689102173,
'phi': -0.615562379360199,
'mass': 0.10565836727619171,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False,
'pz': -22.183122634887695},
{'pt': 124582.25,
'eta': 1.2202473878860474,
'phi': 1.9215593338012695,
'mass': 0.1056494414806366,
'charge': 1,
'pfRelIso04_all': -999.0,
'tightId': False,
'pz': 192658.265625}]}
The invariant mass calculation looks more conventional this way, though it is more verbose, too. You also need two passes to allocate an array of the right size.
@nb.jit
def invariant_mass(events):
num_pairs = 0
for event in events:
num_pairs += max(0, len(event.Muon) * (len(event.Muon) - 1) // 2)
out = np.empty(num_pairs, np.float64)
num_pairs = 0
for event in events:
for i in range(len(event.Muon)):
for j in range(i + 1, len(event.Muon)):
m1 = event.Muon[i]
m2 = event.Muon[j]
out[num_pairs] = np.sqrt(2*m1.pt*m2.pt*(np.cosh(m1.eta - m2.eta) - np.cos(m1.phi - m2.phi)))
num_pairs += 1
return out
masses = invariant_mass(events)
plt.hist(masses, bins=80, range=(70, 110));
plt.hist(masses, bins=240, range=(0, 12))
plt.yscale("log")
The important point is that you don't have to choose between Awkward combinatorics and Numba. You can pass the same data structures through ak.this and ak.that functions as you can pass into Numba-compiled functions.
- Awkward's array-at-a-time functions are best for interactive exploration. It can be hard to express deeply nested loops with ak.cartesian and ak.combinations.
- Numba's just-in-time compilation is best for tricky algorithms and high performance. It can be hard to satisfy Numba's type constraints and stay within the supported Python subset and NumPy subset.
Use them both in your data analysis! Use Numba to make indexes to slice Awkward arrays; use Awkward to prepare structures for Numba.
(I haven't even mentioned the fact that Awkward Arrays are accessible from C++ and will soon run on GPUs.)