Домашнее задание 3. Метод k ближайших соседей¶
import numpy as np
import pandas as pd
import scipy as sp
import matplotlib.pyplot as plt
%matplotlib inline
О библиотеках¶
В задачах 1 и 2 вам предстоит написать функции, аналоги которых есть в библиотеке scikit-learn (sklearn). Реализовывать различные методы машинного обучения «с нуля» очень полезно: способность реализовать какой-то метод самому — это главный критерий того, что вы понимаете, как он работает. В то же время, разбираться в существующих библиотеках тоже полезно — именно с ними вам придётся столкнуться в любой практической работе. Поэтому мы рекомендуем решить эти задачи двумя способами: вручную и с помощью sklearn. За оба положены баллы (хотя за sklearn поменьше, потому что это проще).
Задание 1 (4+1 баллов)¶
Вам предстоит реализовать две версии метода $k$ ближайших соседей (kNN) — обычный (который обсуждался на семинаре) и со взвешиванием.
В качестве метрики мы будем использовать $d_p(\cdot,\ \cdot)$ — расстояние Минковского порядка $p$.
Пусть нам нужно вычислить значение $y$ для некоторого $x_{new}$, наши данные заданы как $\{x_i, y_i\}_{i=1}^l$. Обычный метод $k$ ближайших соседей находит такие $i_1, \ldots, i_k$, что $\{x_{i_m}\}_{m=1}^k$ являются $k$ ближайшими соседями для точки $x_{new}$ (по выбранной метрике $d_p(\cdot,\ \cdot)$), и полагает, что значение нового объекта:
$$\widehat{y} = \underset{c \in C}{\mathrm{argmax}}\ \sum_{m=1}^k[y_{i_m} = c],$$где $C$ — множество классов, а $[y_{i_m}=c]$ — выражение, равное 1, если $y_{i_m}=c$, и 0 в противном случае. То есть $\widehat y$ — мода классов $k$ ближайших соседей. Модифицированный метод $k$ ближайших соседей, который вам предстоит реализовать, использует другую оценку:
$$\widehat y = \underset{c \in C}{\mathrm{argmax}} \sum_{i=1}^l w_{i}[y_i=c],$$где вес $w_i$ вычисляется следующим образом: $$ w_i = \cfrac{\exp(-d_p(x_{new}, x_i))}{\sum_{j=1}^l \exp(-d_p(x_{new}, x_j))} $$
Таким образом, модифицированный метод присваивает $i$-му объекту вес $w_{i}$, уменьшающийся с увеличением расстояния до $x_{new}$, вместо того чтобы присваивать $k$ ближайшим соседям вес $1$, а остальным $0$.
Ниже предоставлен шаблон функции для реализации метода, который возвращает предсказания для тестовой выборки, используя взвешенный или обычный kNN (с возможностью выбора порядка $p$ метрики расстояния). Код для обычного kNN можно взять из семинара; если вы не были на семинаре — придётся написать самостоятельно.
За решение задачи вручную (только с использованием numpy и scipy) можно получить до четырёх баллов. Полный балл за эту часть ставится в том случае, если решение не использует циклы. За решение с циклами можно получить не больше двух баллов из четырёх.
За решение задачи с помощью sklearn можно получить один балл.
Подсказка. Вам придётся вычислить расстояние Минковского между $x_{new}$ и каждой из точек $x_i$, $i=1,\ldots, l$. Существует библиотечная функция, которая позволяет это сделать быстро и без циклов. Вам нужно найти её и использовать.
Внимание! Вычисление весов $w_i$ исключительно через функции np.sum и np.exp может быть численно неустойчивым. Воспользуйтесь функцией scipy.special.softmax.
def knn_classifier(x_train, y_train, x_test, k=1, distance='euclid',
weight=True):
"""
x_train is np.array with shape (l, d) (matrix with l rows, d columns)
y_train is np.array with shape (l, ) (1-dimensional array with l elements)
x_test is np.array with shape (n, d) (matrix with n rows, d columns)
k is int (if weight is True, then the argument is ignored, else - number of neighbours)
distance is int (order p of Minkowski distance) or str: 'euclidian', 'cityblock' (you can implement more options)
weight is boolean, whether to use the weighted method or not
return y_test, np.array with shape (n, ) (1-dimensional array with n elements)
"""
### SOLUTION BEGIN
### SOLUTION END
Задание 2 (2 + 0.5 баллов)¶
На семинаре было рассказано про разные виды кросс-валидации. В этом задании вам предстоит реализовать собственноручно k-fold cross validation со стратификацией по параметру $y$ (целевой категориальной переменной).
Ниже предоставлен шаблон функции, которая делит данные на $K$ частей («фолдов»), каждая из которых имеет то же (или максимально близкое) распределение классов (то есть значений переменной $y$), что и целый датасет. Она должна вернуть $K$-элементный список, каждый элемент которого является четырёхэлементным кортежем: (x_train, y_train, x_test, y_test), где x_test, y_test соответствует содержимому одного из фолдов, а x_train, y_train — всему остальному датасету. Если вы знаете, что такое генераторы, вместо того, чтобы возвращать $K$-элементный список, можете сделать соответствующий генератор.
Ниже есть код, который поможет вам себя проверить.
За решение задачи вручную ставится 2 балла максимум. В задаче можно использовать циклы, однако следует помнить, что циклы в питоне — медленные, и при любой возможности следует использовать векторизованные функции numpy. За неоптимальное использование циклов оценка может быть снижена.
За решение задачи с помощью sklearn ставится 0.5 балла.
def strat_kfold_gen(x, y, k):
'''
x is np.array with shape (l, d) (matrix with l rows, d columns)
y is np.array with shape (l, ) (1-dimensional array with l elements)
k is int, number of folds to split data
returns x_train, y_train, x_test, y_test
'''
### SOLUTION BEGIN
### SOLUTION END
# CHECK YOURSELF
x = np.random.normal(size=(171, 3))
y = np.hstack([np.ones(101), np.ones(50) * 2, np.ones(20) * 3])
np.random.shuffle(y)
K = 5
s = '\nClass distribution train/test:'
t = '1 - {:.3f}\t2 - {:.3f}\t3 - {:.3f}'
print(f'ALL, length={len(y)}',
s, '\n\tALL: ', t.format(*np.unique(y, return_counts=True)[1] / len(y)))
print('-'*70)
for i, (_, y_tr, _, y_t) in enumerate(strat_kfold_gen(x, y, K)):
print(f'FOLD #{i+1}, length={len(y_tr)}/{len(y_t)}',
s, '\n\tTRAIN: ', t.format(*np.unique(y_tr, return_counts=True)[1] / len(y_tr)),
'\n\tTEST: ', t.format(*np.unique(y_t, return_counts=True)[1] / len(y_t)))
ALL, length=171 Class distribution train/test: ALL: 1 - 0.591 2 - 0.292 3 - 0.117 ---------------------------------------------------------------------- FOLD #1, length=136/35 Class distribution train/test: TRAIN: 1 - 0.588 2 - 0.294 3 - 0.118 TEST: 1 - 0.600 2 - 0.286 3 - 0.114 FOLD #2, length=137/34 Class distribution train/test: TRAIN: 1 - 0.591 2 - 0.292 3 - 0.117 TEST: 1 - 0.588 2 - 0.294 3 - 0.118 FOLD #3, length=137/34 Class distribution train/test: TRAIN: 1 - 0.591 2 - 0.292 3 - 0.117 TEST: 1 - 0.588 2 - 0.294 3 - 0.118 FOLD #4, length=137/34 Class distribution train/test: TRAIN: 1 - 0.591 2 - 0.292 3 - 0.117 TEST: 1 - 0.588 2 - 0.294 3 - 0.118 FOLD #5, length=137/34 Class distribution train/test: TRAIN: 1 - 0.591 2 - 0.292 3 - 0.117 TEST: 1 - 0.588 2 - 0.294 3 - 0.118
Задание 3.1 (3 балла)¶
Теперь наконец применим наши две функции и посмотрим подробнее на результаты. Рассмотрим датасет Thyroid Gland, состоящий из результатов различных анализов, связанных со щитовидной железой пациентов. Целевой переменной является состояние щитовидной железы: нормальное, гипотиреоз или гипертиреоз.
1. (0.5 балла) Скачайте датасет (https://raw.githubusercontent.com/jbrownlee/Datasets/master/new-thyroid.csv) и ответьте на следующие вопросы. Сколько у датасета строк и столбцов? Целевая переменная записана последним столбцом. Какое у неё распределение? (Постройте подходящую картинку.)
Замечание. Функция pd.read_csv по умолчанию считает, что названия столбцов указаны в первой строке файла, но в файле по ссылке названия столбцов не указаны. Прочитайте в документации, как сделать так, чтобы pd.read_csv не воспринимала первую строчку файла как названия столбцов.
# YOUR CODE
2. (2 балла) Примените ваш kNN-алгоритм для предсказания значения целевой переменной, используя кросс-валидацию на 3 фолдах. (Вам нужно изготовить из датафрейма массивы numpy x и y, которые можно скормить функциям, написанным в задачах 1 и 2. Чтобы получить массив из датафрейма можно использовать свойство .values.) Перебирая значения параметра $k$ — количества ближайших соседей — от 0 до 20 нарисуйте два графика зависимости качества предсказания (будем использовать accuracy) от $k$ — один для обучающей и один для тестовой выборок. Можно рисовать отдельную линию на графике для каждого фолда, либо рисовать их среднее±разброс. Значение p в метрике Минковского выберете на свой вкус.
# YOUR CODE
Как зависит качество от значения $k$ для каждой выборки? Как выбрать оптимальное значение?
Ваш ответ: ...
3. (0.5 балла) Попробуйте улучшить качество модели, отмасштабировав данные таким образом, чтобы разброс значений всех переменных был примерно одинаковым (способ скейлинга на ваш выбор, см. модуль sklearn-preprocessing).
# YOUR CODE
Какие изменения в качестве произошли?
Ваш ответ: ...
### SOLUTION
Наша итоговая цель в этом задании — нарисовать объекты датасета на плоскости и посмотреть, как алгоритм делит плоскость на классы и как это влияет на результаты на тестовой выборке. Кроме этого мы рассмотрим разные параметры алгоритма. Первая проблема состоит в том, что в датасете больше двух признаков — непонятно, как объекты изображать на плоскости. Обычно в такой ситуации используются методы снижения размерности (например, PCA), но мы про них ещё не говорили, поэтому воспользуемся другим подходом: попробуем выделить среди признаков те, которые (по одиночке) дают максимум информации о значении целевой переменной (это называется univariate feature selection).
2. (0.5 балла) Функция sklearn.feature_selection.mutual_info_classif находит взаимную информацию между целевой переменной и каждым из признаков. Чем больше взаимная информация, тем больше знание одной переменной сообщает нам о возможных значениях другой переменной. С помощью этой функции выберите два признака, которые имеют максимальную взаимную информацию с целевой переменной. Создайте из них numpy-массив $X$ и создайте массив $y$ со значениями целевой переменной. После чего разделите данные на обучающую и тестовую выборки в соотношении 2:1, воспользовавшись вашей функцией strat_kfold_gen и взяв только один элемент из возвращённого списка (или генератора).
# YOUR CODE
В следующем задании вопользуйтесь примерами из интернета ([1], [2], [3] и т.д. на ваш выбор), чтобы построить график следующего типа. Каждая точка плоскости (decision boundaries) покрашена в свой цвет в зависимости от того, какое предсказание сделает алгоритм для этой точки, а объекты раскрашены в тот цвет, какой у них истинный $y$.
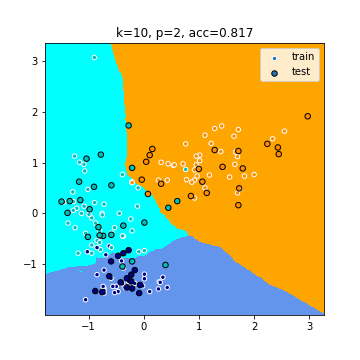
3. (2 балла) Переберите $M$ значений параметра $k$ (можете добавить значение 0 как индикатор использования взвешенного kNN), $L$ значений параметра $p$ (порядок расстояния Минковского) и постройте сетку $L \times M$ графиков типа выше. ($M$ и $L$ — небольшие целые числа, больше 3.)
На графиках должны быть:
- подпись: набор параметров и качество (accuracy) до третьего знака после запятой;
- окрашенные в цвет истинного класса точки обучающей и тестовой выборки
- сделайте маркеры обучающей и тестовой выборок различными (например, треугольники и кружочки/черная и белая обводка/маленький и большой размер);
- границы принятия решений (decision boundaries) на основе обученного (на обучающей выборке) алгоритма kNN;
- общее название сетки графиков, где в том числе указаны номера признаков, выбранные в предыдущем пункте.
# YOUR CODE
У какого набора параметров получилось лучшее качество?
Объясните как параметры влияют на decision boundaries.
Ваш ответ: ...