Цифровая обработка сигналов - Лекция 11¶
Тема: Применение банков фильтров в задачах аудиокодирования¶
Введение¶
Перед вами обучающий материал по основам цифровой обработки сигналов с использованием средств языка программирования Python. Предполагается, что читатель имеет базовые знания из области высшей математики, а также владеет языком Python и хотя бы поверхностно знает различные python-библиотеки - numpy/scipy, matplotlib и другие.
Для пользователей MATLAB / GNU Octave освоение материала с точки зрения программного кода не составит труда, поскольку основные функции и их атрибуты во многом идентичны и схожи с методами из python-библиотек.
Теоретический базис¶
Как правило, под понятием банк фильтров подразумевается ряд соединенных параллельно полосовых фильтров. Цель такой схемы состоит в том, чтобы выполнить разложение исходного сигнала на определенные, неповторяющиеся поддиапазоны частот (subbands).
Приведем пример:
- имеется аудиосигнал с частотой дискретизации 44,1 кГц,
- допустим, с помощью банка фильтров данный сигнал разделен на 1024 поддиапазона с равной шириной полосы,
- тогда нулевой поддиапазон будет содержать частотные составляющие от 0 до 21,53 Гц, первый поддиапазон - от 21,53 до 43,07 Гц, а поддиапазон под номером 1023 - от 22028,47 до 22050 Гц.
Фильтры, находящиеся в составе кодера, принято называть фильтрами разложения сигнала (analysis filter banks), а фильтры, находящиеся в декодере - фильтрами синтеза сигнала (synthesis filter banks).
Аналитически процесс фильтрации может быть выражен через процедуру свертки (convolution):
$$ y[n] = x[n]∗h[n]= \sum_{k=0}^n x[n−k]h[k] \tag{11.1} $$где $x[n]$ - это входной сигнал во временной области, $h[n]$ - импульсная характеристика фильтра, $y[n]$ - сигнал на выходе фильтра, $n$ - номер текущего отсчета.
В области DTFT операцию свертки заменит операция умножения:
$$ Y(\omega) = X(\omega)\cdot H(\omega) \tag{11.2}$$где $\omega = 2\pi \frac{f}{f_s}$ - это нормализованная угловая частота, при $f$ частоте в Герцах и частоте дискретизации $f_s$.
Чем больше фильтров будет содержаться в структуре банка, тем реже (плавнее) становится шаг перехода от частоты к частоте, а значит может быть проанализировано большее количество частотных изменений. Однако, слишком большое количество фильтров может привести к одной из разновидностей явления Гиббса - так называемому, эффекту пре-эхо.

Рис. 1. В рамках аудиокодировая эффект пре-эхо возникает обычно при обработке "перерходных" (transient) звуков: кастанеты, барабаны, клавишные. Причина: выбран слишком длинный фильтр (большое количество поддиапазонов). [3]
С точки зрения аудиокодирования по отношению к банкам фильтров, как правило, выдвигаются следующие требования [1, с. 1-2]:
- Хорошая разрешающая способность (достаточное количество поддиапазонов).
- Критическая дискретизация (critical sampling): количество отсчетов не должно увеличивается после примения банка.
- Идеальная реконструкция (perfect reconstruction) изначального сигнала: сигнал на выходе декодера должен быть тем же сигналом, что и на входе кодера (разве что, задержанным во времени $ \hat{x}[n] = x[n-d]$).
- Техническая реализуемость, эффективность реализации.
- Возможность переключения между количеством поддиапазонов (подавление эфекта пре-эхо).
Рассмотрим более детально некоторые из пунктов.
Критическая дискретизация (critical sampling)¶
Данный пункт проще всего рассмотреть на примере (рис. 2). Допустим, имеется банк фильтров, состоящий из $N = 1000$ полосовых фильтров; $\to$ на вход кодера поступают 10 тыс. отсчетов с частотой дискретизации 44.1кГц; $\to$ после применения фильтров (свертки) количество отсчетов возрастает прямопропорционально количеству фильтров до 10 млн.; $\to$ применяется дополнительная процедура понижения количества отсчетов (down-sampling) на стороне кодера и процедура их восстановления (up-sampling) на стороне декодера; $\to$ количество отсчетов снижается, что позволяет сохранить заданный битрейт; $\to$ частота дискретизации закономерно уменьшается до 44.1Гц.
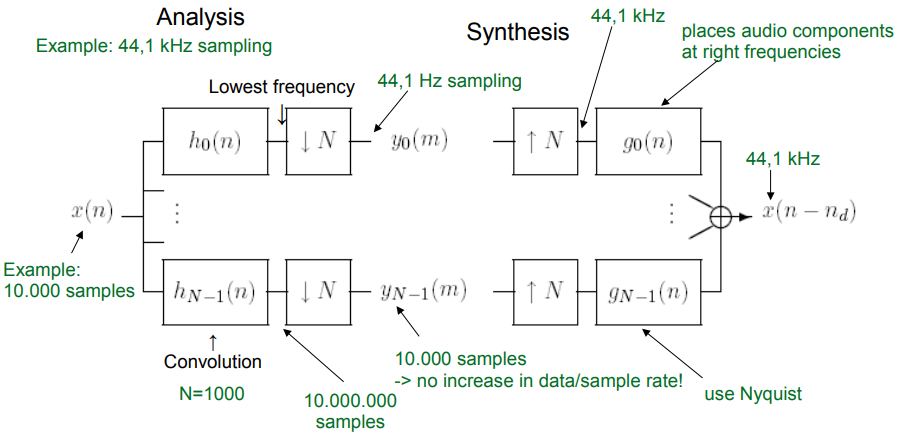
Рис. 2. Блок-схема прямой реализации* банков фильтров [2].*
Процедура понижения количества отсчетов представляет из себя обыкновенное прореживание: в каждом поддиапазоне исключается каждый кратный $N$ отсчет (рис. 3).

Рис. 3. Иллюстрация операции down-sampling [2].
На этапе декодера в пропущенные позиции добавляются нулевые значения (рис. 4).

Рис. 4. Иллюстрация операции up-sampling [2].
Преимуществом такой схемы очевидно является её простота. Однако, интереснее рассмотреть недостатки данного подхода.
Пример реализации данной схемы на языке Python можно найти в одном из репозиториев ТУ Ильменау по следующей ссылке.
Полифазное представление¶
Факт того, что операция понижения количества отсчетов следует не до, а после операции фильтрации, означает для прямой реализации излишние вычисления (то же самое на стороне декодера): все отсчеты участвуют в операции свертки, даже те, которые после будут удалены.
Решить данную проблему можно с помощью полифазного разложения входного сигнала: обрабатываться должны не копии одного и того же сигнала, а разные подпоследовательности, прореженные с определенным смещением во времени. Структурная схема такого подхода представлена на рисунке 5.

Рис. 5. Структурная схема полифазных банков фильтров [1, с. 37].
Отметим, что обозначение $z^{-1}$ следует понимать, как задержку операции понижения количества отсчетов (рис. 6):
- в самой нижней ветке останутся отсчеты с номерами 0, $N$, $2N$ и т.д.;
- во второй ветке отсчеты с номерами 1, $N+1$, $2N+1$ и т.д. и так до последней ветви.
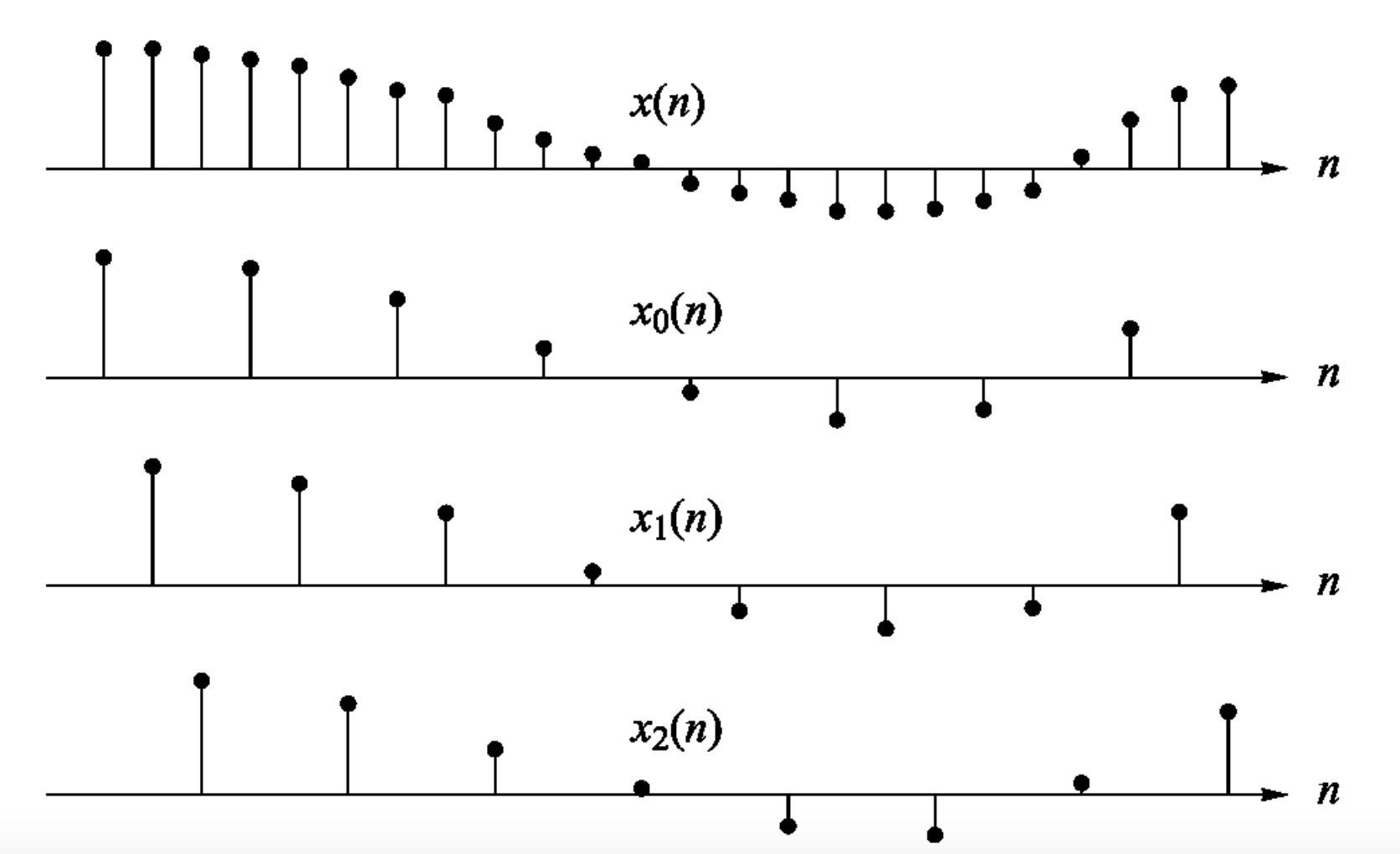
Рис. 6. Пример полифазного разложения для $N=3$ [4, с. 147].
Операцию, которая выражала бы одновременно и понижение количества отсчетов и фильтрацию удобно представлять через матричное умножение в z-области при $z = e^{j\omega}$:
$$ \underset{1\times N} {\mathbf{Y}(z)} = \underset{1\times N}{\mathbf{X}(z)} \cdot \underset{N\times N}{\mathbf{H}(z)} \tag{11.3}$$Вектор z-преобразований входного сигнала (вектор полиномов) выглядит следующим образом:
$$ \mathbf{X}(z) = \left[ X_0(z), X_1(z) ... X_{N-1}(z) \right] \tag{11.4}$$$$ X_i(z) = \sum_{m=0}^{N-1} x(mN + i) z^{-m}, \quad i=0,1,.. N-1 \tag{11.5}$$
где $N$ - это количество фильтров банка. Обратите внимание, что мы используем именно односторонние z-преобразования, в силу того, что реальные системы причинны.
Матрица односторонних z-преобразований коэффициентов фильтрации (матрица полиномов) может быть представлена как:
$$\mathbf{H}(z) = \left[ \mathbf{H}_0^T(z), \mathbf{H}_1^T(z) ... \mathbf{H}_{N-1}^T(z) \right] = \begin{bmatrix} H_{(N-1), 0} & H_{(N-1), 1} & ... & H_{(N-1), (N-1)}\\ H_{(N-2), 0} & H_{(N-2), 1} & ... & H_{(N-2), (N-1)} \\ . & . & & . \\ . & . & & .\\ . & . & & . \\ H_{0, 0} & H_{0, 1} & ... & H_{0, (N-1)} \end{bmatrix} \tag{11.6}$$$$ H_{n,k}(z) = \sum_{m=0}^{N-1} h_k(mN + n) z^{-m} \tag{11.7}$$где $n$ - это фаза, а $k$ - это номер поддиапазона.
Итак, кратко подытожим. Представление через z-преобразования:
- во-первых, позволяет разбить сигнал на последовательности с нужной задержкой,
- во-вторых заменяет операцию свертки на операцию матричного умножения, которая является более простым решением с точки зрения технической реализуемости.
Используя полифазное предсталение, рассмотрим следующий важный пункт проектирования банка фильтров - идеальную реконструкцию.
Идеальная реконструкция (perfect reconstruction)¶
Во-первых, повторим, что означает термин идеальная реконструкция: сигнал на выходе декодера $\hat{x}$ должен быть тем же сигналом, что и на входе кодера $x$ (разве что, задержанным во времени):
$$ \hat{x}[n] = x[n-d] \tag{11.8}$$В полифазном представлении сигнал на выходе декодера можно выразить следующим образом:
$$ \mathbf{\hat{X}}(z) = \mathbf{Y}(z) \cdot \mathbf{G}(z) = \mathbf{X}(z) \cdot \mathbf{H}(z) \cdot \mathbf{G}(z) \tag{11.9}$$где $\mathbf{G}(z)$ - это одностороннее z-преобразование коэффициентов фильтра синтеза.
Соответственно, для идеальной реконструкции достаточно, чтобы $\mathbf{G}(z) = z^{-d}\mathbf{H}^{-1}(z)$. Однако, так как матрицы $\mathbf{G}(z)$ и $\mathbf{H}(z)$ - это матрицы полиномов, нахождение для них обратных матриц - это, мягко говоря, не самая тривиальная задача.
Одним из самых простых методов для решения данной проблемы является подбор на роль матриц анализа и синтеза параунитарных (paraunitary) матриц [1, с. 40], подчиняющихся свойству:
$$ \mathbf{A^{-1}}(z) = \mathbf{A}^H(z^{-1}) \tag{11.10}$$где $H$ обозначает Эрмитово сопряжение.
Итак, матрицы анализа и синтеза в данном случае - это ни что иное, как транспонированные, комплексно сопряженые и развернутые во времени копии друг друга.
Техническая реализуемость, эффективность реализации¶
Названные выше принципы были положены в основу конкретных реализаци банков фильтров, таких как:
- Digital Cosine Transform (DCT) IV;
- Modified DCT (MDCT);
- Pseudo Quadradutre Mirror Filter (PQMF) и т.д.
и получили широкое распространение в рамках стандартов аудикодирования (MPEG 2 Layer 3 (MP3), AAC, семейство LossLess стандартов и т.д.).
Более подробные материалы по данной тематике с примерами на языке Python можно найти в репозиториях ТУ Ильменау (Германия), в стенах которого преподавал и сам Карлхайнц Брандербург - один из создателей стандарта MP3:
Литература¶
- Schuller, G., 2020. Filter Banks and Audio Coding: Compressing Audio Signals Using Python. Springer Nature.
- "Filter Banks I" by Prof. Dr. Gerald Schuller, Fraunhofer IDMT & Ilmenau University of Technology Ilmenau, Germany
- "Filter Banks III" by Prof. Dr. Gerald Schuller, Fraunhofer IDMT & Ilmenau University of Technology Ilmenau, Germany
- Signal Analysis: Wavelets, Filter Banks, Time-Frequency Transforms and Applications. Alfred Mertins. 1999 John Wiley & Sons Ltd