Text Classification Using Topic Modelling¶
Topic modelling is a good intro to NLP.
Note that a lot of below is based on this article.
My intention with this is
- learn topic modelling
- learn spacy
As you will see (in earlier commits) the spacy part didn't pan out. It worked ok but the doc parsing was super slow for this volume. I'm not sure why that was, given I'd heard great things about it. I've tried to leave links on the previous commits to discussions around tuning spacy and some of the things I tried.
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import gensim
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from nltk.stem.porter import *
np.random.seed(42)
Load the dataset¶
We'll use a dataset of news articles grouped into 20 news categories - but just use 7 for this example. I've tried to pick groups that should have a decent seperation.
categories = [
'comp.windows.x',
'rec.autos',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.space',
'soc.religion.christian',
'talk.politics.guns'
]
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
newsgroups_test = fetch_20newsgroups(subset='test', categories=categories)
Lets looks at an example
print(newsgroups_train.data[6])
From: SHOE@PHYSICS.watstar.uwaterloo.ca (Mark Shoesmith)
Subject: Re: Let's talk sticks...
Lines: 35
Organization: University of Waterloo
In article <C50pt4.6CM@odin.corp.sgi.com> dptom@endor.corp.sgi.com (Tom Arnold) writes:
>Okay you hockey playing fans/finatics out there. I'm looking over the wide
>range of aluminum sticks for the first time. I've been playing with pieces
>of lumbar that seem to weigh alot and break after a few uses, so I'm
>thinking of changing to an aluminum shaft so when I break the blade all I
>have to do is change it. The problem is that there is such a wide reange of
>models and selections out there that I'm not certain which to consider. Can
>any of you post some of your suggestions and experiences with the aluminum
>sticks? What is the difference between models? What do you like/dislike about
>them? And, which brands are best?
>
>
I've had, and still have a few aluminum sticks. I got my first when I was 15
(a Christian), and broke the shaft halfway through the season, two years
later. I bought another (a Canadian) at the beginning of the next season,
and I still have it. I also have an Easton, that a friend was getting rid
off, after giving up the game. I find that Easton blades are easier to get,
but all brands of blades are pretty well interchangeable. Watch out for
dried up bits of firewood, that some stores pass off as blades. In my
experiences, the blades of an aluminum break more often than regular sticks,
but I've only ever broken one aluminum shaft.
I like aluminum sticks. The blades are quickly changed, even on the bench
if you have to. On the downside, the shaft won't break if you decide to
impale yourself on it :-)
Ciao,
Mark S.
"This is between me and the vegetable" - Rick Moranis in
Little Shop of Horrors
Mark Shoesmith
shoe@physics.watstar.uwaterloo.ca
target_newsgroup = newsgroups_test.target_names[newsgroups_train.target[6]]
print('Group: {}'.format(target_newsgroup))
Group: rec.sport.hockey
print(newsgroups_train.filenames.shape, newsgroups_train.target.shape)
(4122,) (4122,)
This should be enough rows normally. Though it is split over 7 categories which may not be enough.
Lets see how heavy each category is.
import collections
collections.Counter(newsgroups_train.target)
Counter({4: 593, 2: 597, 1: 594, 0: 593, 3: 600, 6: 546, 5: 599})
I could map the keys to the category names but you can see by eye that it is a really balanced dataset.
Data Preprocessing¶
We transform the data to basically optimise it so the ML algorithm recieves the strongest signal.
- Tokenization: Split the text into sentences and the sentences into words. Lowercase the words and remove punctuation.
- Words that have fewer than 3 characters are removed.
- Remove stopwords: such as the, is, at, which, and on.
- Lemmatize: Words in third person are changed to first person and verbs in past and future tenses are changed into present.
- Stemming: Words are reduced to their root form.
Lemmatizing is a mapping of the word to its base form i.e. went -> go.
Stemming is more of a function on the word such as removing the 'ing' from the end of words.
We do the lemmatizing and then stemming in the lemma may be a totally different spelt word (going -> go is similar but went -> go has a totally different spelling).
The stemming can often result in a 'invalid' word such as argue -> argu which the lemmatizing wouldn't accept.
stemmer = SnowballStemmer('english') # Porter2 stemmer
def lemmatize_stemming(text):
lemmatized = WordNetLemmatizer().lemmatize(text, pos='v')
return stemmer.stem(lemmatized)
def preprocess(text):
"""
Tokenise and lemmatize text
"""
result=[]
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return result
Check the output of the preprocessing
doc_sample = 'This disk has failed many times. I would like to get it replaced.'
proc = preprocess(doc_sample)
print(proc)
['disk', 'fail', 'time', 'like', 'replac']
Preprocess all the messages we have (in parallel)
import multiprocessing
pool = multiprocessing.Pool()
processed_docs = list(pool.map(preprocess, newsgroups_train.data))
print(processed_docs[:2])
[['rlennip', 'mach', 'robert', 'lennip', 'subject', 'planet', 'imag', 'orbit', 'ether', 'twist', 'newsread', 'version', 'organ', 'wilfrid', 'laurier', 'univers', 'line', 'real', 'life'], ['rdetweil', 'richard', 'detweil', 'subject', 'card', 'mail', 'list', 'distribut', 'organ', 'hewlett', 'packard', 'line', 'count', 'interest', 'cardin', 'mail', 'list', 'find', 'start', 'know', 'thank', 'dick', 'detweil', 'rdetweil', 'hpdmd']]
Create Bag of words¶
A dictionary is the number of times a word appears in the training set. A mapping between words and their integer ids.
dictionary = gensim.corpora.Dictionary(processed_docs)
for i in range(5):
print(i, dictionary[i])
0 ether 1 imag 2 laurier 3 lennip 4 life
Filter out tokens that appear in
- less than 15 documents or
- more than 10% of documents
- after (1) and (2), keep only the first 100k most frequent tokens
dictionary.filter_extremes(no_below=15, no_above=0.1, keep_n=100000)
Convert document (a list of words) into the bag-of-words format.
A list of (token_id, token_count) tuples
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
# i.e. the 3rd word from the 10th message
bow_doc_x = bow_corpus[10]
bow_word_x = 3
print('{} - {}'.format(
bow_doc_x[5],
dictionary[bow_doc_x[bow_word_x][0]]
))
(277, 1) - devic
Build the LDA Model¶
(Latent Dirichlet Allocation)
If observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word's presence is attributable to one of the document's topics
alpha and eta are hyperparameters that affect sparsity of the document-topic (theta) and topic-word (lambda) distributions. We will let these be the default values for now(default value is
1/num_topics)Alpha is the per document topic distribution.
- High alpha: Every document has a mixture of all topics(documents appear similar to each other).
- Low alpha: Every document has a mixture of very few topics
Eta is the per topic word distribution.
- High eta: Each topic has a mixture of most words(topics appear similar to each other).
- Low eta: Each topic has a mixture of few words.
lda_model = gensim.models.LdaMulticore(
bow_corpus,
num_topics=7,
id2word=dictionary,
passes=10,
workers=4)
Evaluate the model¶
lda_model.show_topics()
[(0, '0.019*"christian" + 0.008*"exist" + 0.007*"truth" + 0.005*"live" + 0.005*"life" + 0.005*"claim" + 0.005*"religion" + 0.005*"belief" + 0.004*"true" + 0.004*"absolut"'), (1, '0.010*"player" + 0.007*"season" + 0.006*"hockey" + 0.006*"score" + 0.004*"leagu" + 0.004*"goal" + 0.004*"basebal" + 0.004*"playoff" + 0.004*"defens" + 0.004*"second"'), (2, '0.014*"jesus" + 0.012*"church" + 0.007*"christ" + 0.006*"bibl" + 0.006*"christian" + 0.006*"hell" + 0.006*"faith" + 0.005*"cathol" + 0.005*"paul" + 0.005*"father"'), (3, '0.023*"window" + 0.011*"server" + 0.011*"widget" + 0.010*"file" + 0.010*"program" + 0.009*"motif" + 0.008*"applic" + 0.008*"display" + 0.008*"avail" + 0.007*"version"'), (4, '0.013*"file" + 0.009*"entri" + 0.009*"weapon" + 0.008*"gun" + 0.008*"firearm" + 0.006*"control" + 0.005*"crime" + 0.005*"govern" + 0.005*"output" + 0.005*"program"'), (5, '0.024*"space" + 0.014*"nasa" + 0.010*"orbit" + 0.009*"launch" + 0.006*"satellit" + 0.005*"mission" + 0.005*"earth" + 0.005*"data" + 0.004*"moon" + 0.004*"henri"'), (6, '0.008*"engin" + 0.007*"car" + 0.005*"price" + 0.005*"batf" + 0.005*"dealer" + 0.005*"drive" + 0.004*"compound" + 0.004*"scott" + 0.004*"buy" + 0.003*"children"')]
The show_topics shows what topics lda has found. You can see that the first is clearly about religion. The numbers show how much weight each word adds to a document being part of a topic. (TODO can you get negative numbers that are detrimental to classifying a topic?)
This is an unsupervised algorithm so it never sees that target field we have.
Baseball isn't seperately represented. It looks the the language used is very similar to baseball.
However it has found 2 catagories for religion. I'm guessing Christians conversations have a decent split talking about solid entities like jesus and church, and then there are other conversations around spirituality and life in general.
categories_map = {
3: 'comp.windows.x',
6: 'rec.autos',
-1: 'rec.sport.baseball',
1: 'rec.sport.hockey',
5: 'sci.space',
2: 'soc.religion.christian',
0: 'soc.religion.christian',
4: 'talk.politics.guns'
}
Testing model on unseen document
num = 2
unseen_document = newsgroups_test.data[num]
print(unseen_document)
print(newsgroups_test.target_names[newsgroups_test.target[num]])
From: eggertj@moses.ll.mit.edu (Jim Eggert x6127 g41) Subject: Re: Robin Lane Fox's _The Unauthorized Version_? Reply-To: eggertj@ll.mit.edu Organization: MIT Lincoln Lab - Group 41 Lines: 19 In article <May.7.01.09.39.1993.14550@athos.rutgers.edu> iscleekk@nuscc.nus.sg (LEE KOK KIONG JAMES) writes: | mpaul@unl.edu (marxhausen paul) writes: | > My mom passed along a lengthy review she clipped regarding Robin Lane | > Fox's book _The Unauthorized Version: Truth and Fiction in the Bible_, |... | I've read the book. Some parts were quite typical regarding its | criticism of the bible as an inaccurate historical document, | alt.altheism, etc carries typical responses, but not as vociferous as | a.a. It does give an insight into how these historian (is he one... I | don't have any biodata on him) work. I've not been able to understand/ | appreciate some of the arguments, something like, it mentions certain | events, so it has to be after that event, and so on. Robin Lane Fox is a historian and a gardener. He has written several history books, perhaps a recent one you might remember is "The Search for Alexander". He has also written or edited several books on gardening. -- =Jim eggertj@ll.mit.edu (Jim Eggert) soc.religion.christian
The document is from the soc.religion.christian group. Pushing it through the model gives the estimations of which catagories LDA thinks the document belongs to.
# Data preprocessing step for the unseen document
bow_vector = dictionary.doc2bow(preprocess(unseen_document))
pred = sorted(lda_model[bow_vector], key=lambda tup: -1*tup[1])
print(pred)
[(0, 0.64716893), (3, 0.1975734), (1, 0.14305282)]
print('predicts {} with a probability of {:.2f}%'.format(categories_map[pred[0][0]], pred[0][1]*100))
predicts soc.religion.christian with a probability of 64.72%
Correctly classifies as religion. It also shows a 20% chance of being about windows and 14% about hockey.
This is a multiclass classification so rather than it being x% chance of the doc falling into a category, it is more like the document is covered by a number of categories with religion being the most covered.
Check Accuracy¶
We have a test dataset we can use to check the accuracy. We preprocess and pass the documents through the model and see how many match up to the true topic.
import multiprocessing
pool = multiprocessing.Pool()
test_processed_docs = list(pool.map(preprocess, newsgroups_test.data))
test_bow_corpus = [dictionary.doc2bow(doc) for doc in test_processed_docs]
Get the predicted values from the model
y_pred = []
for i, doc in enumerate(test_bow_corpus):
pred_all = sorted(lda_model[doc], key=lambda tup: -1*tup[1])
pred_cat = categories_map[pred_all[0][0]]
y_pred.append(newsgroups_test.target_names.index(pred_cat))
Get the ground truth values from the target field in the data
y_true = newsgroups_test.target
newsgroups_test.target_names
['comp.windows.x', 'rec.autos', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.space', 'soc.religion.christian', 'talk.politics.guns']
Accuracy is the proportion of correct predictions of the model
Accuracy = Number of correct predictions / Total number of predictions
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
0.6985052861830113
Accuracy is good for binary classification problems but less accurate in this case. It doesn't handle the belief in other topics that are covered in a document.
TODO: find a proper classification measure
Create a confusion matrix to show. This is a grid of the predicted values on the horizontal and the true values on the vertical
# creating a confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred)
Y_pred ->, y_true /
cm
array([[362, 11, 0, 8, 12, 2, 0],
[ 5, 317, 0, 33, 11, 27, 3],
[ 6, 8, 0, 356, 5, 18, 4],
[ 0, 7, 0, 382, 2, 6, 2],
[ 5, 13, 0, 3, 325, 25, 23],
[ 3, 3, 0, 3, 5, 381, 3],
[ 2, 174, 0, 5, 2, 32, 149]])
You can see that the diagonal has the high numbers, where the prediction was correct.
There are 174 messages where the model predicted hockey but the ground truth was cars. This could easily be where there is crossover with cars and sports.
People are discussing cars in the hockey newsgroup.
pyLDAvis¶
Interactive topic model visualization
This is a really good library for visuallising the topics and how the interact with each other. It sits ontop of the model and really pulls a ton of extra information out.
Note that running it freezes the python kernel as it launches a web server. (I've attached a screenshot)
# import pyLDAvis.gensim
# pyLDAvis.enable_notebook()
# prepared = pyLDAvis.gensim.prepare(lda_model, bow_corpus, dictionary)
# pyLDAvis.show(prepared)
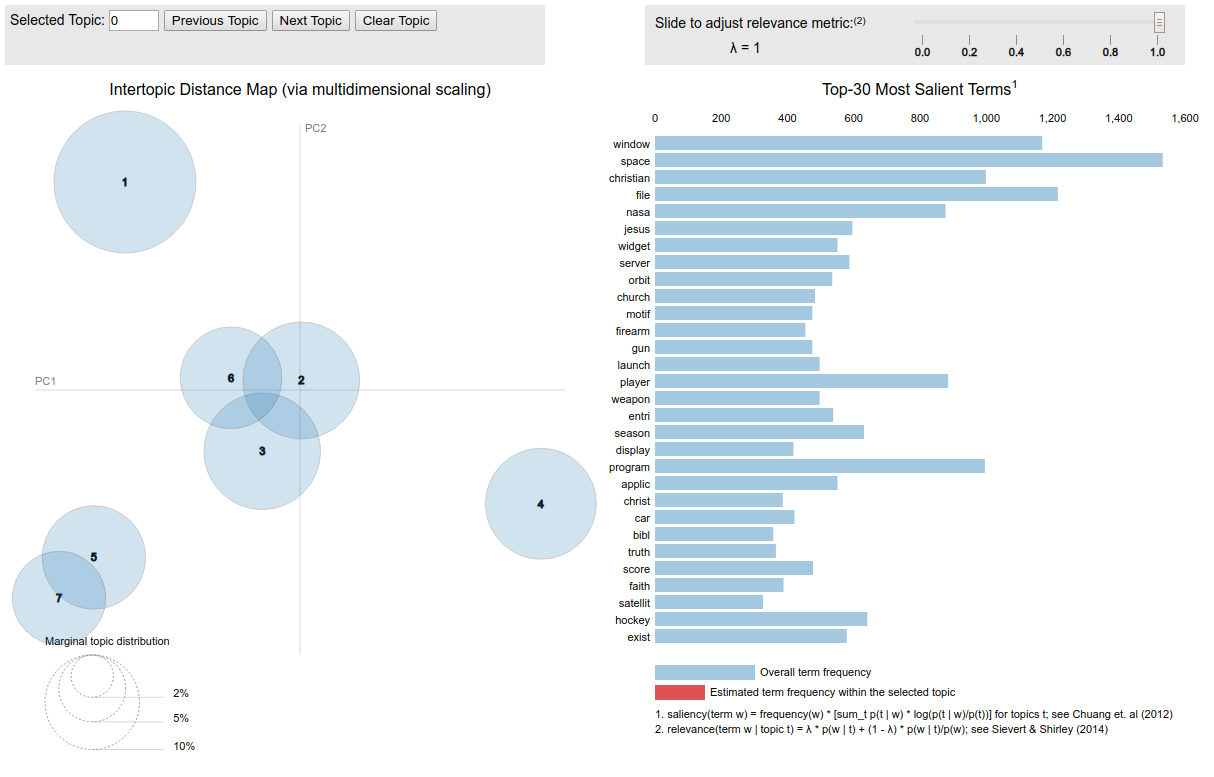
- You can see 1 top left is the sports topics, large because it contains both hockey and baseball in a single topic
- 2, 3 and 6 are cars space and guns with a margin of crossover
- 7 and 5 are the religion topics with large crossover. I would have expected more, though I guess at some point a large overlap becomes seen as a large topic.
- 4 windows is out on its own
Conclusion¶
This definately needs some tuning which I'll pick up in the future. Places for tuning are
- The Preprocessing
- Do we need both stemming and lemmatization
- Try a different stemmer. The SnowballStemmer is meant to strike a balance between being too aggressive or passive.
- Tune the LDA hyperparameters
- Alpha and eta. Also maybe the number of passes may produce different results
- Try a different model
- I see Non-negative matrix factorization being mentioned a lot
- RNN's are good at handling the abstract nature of language and they retain the sentence context. (Though last time I used an RNN I got better results with a non DL model)
Ultimately this is a multi class classification problem and I would expect to get better results using supervised learning algorithms. I was discussing this with someone and they mentioned using bigrams to handle the context that gets lost when using a bag of words. I would like to look into this, I thought about it later on and I'm hoping that using bigrams will give a sort of chain that the model can pick up on. i.e. Now we have A, B, C. With Bigrams we would have A, B, C and AB and BC, which give a sort of gives a relationship from A to C. I'm not sure if the model will pick that relationship up but bigrams will definately add a stronger signal for the model.