![]()

This is the official YOLOv5 🚀 notebook by Ultralytics, and is freely available for redistribution under the GPL-3.0 license. For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!
Setup¶
Clone repo, install dependencies and check PyTorch and GPU.
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
import torch
from yolov5 import utils
display = utils.notebook_init() # checks
YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB) Setup complete ✅
1. Inference¶
detect.py runs YOLOv5 inference on a variety of sources, downloading models automatically from the latest YOLOv5 release, and saving results to runs/detect. Example inference sources are:
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images
display.Image(filename='runs/detect/exp/zidane.jpg', width=600)
detect: weights=['yolov5s.pt'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB) Fusing layers... Model Summary: 213 layers, 7225885 parameters, 0 gradients image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.007s) image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.007s) Speed: 0.5ms pre-process, 6.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640) Results saved to runs/detect/exp

2. Validate¶
Validate a model's accuracy on COCO val or test-dev datasets. Models are downloaded automatically from the latest YOLOv5 release. To show results by class use the --verbose flag. Note that pycocotools metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation.
COCO val¶
Download COCO val 2017 dataset (1GB - 5000 images), and test model accuracy.
# Download COCO val
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip
0%| | 0.00/780M [00:00<?, ?B/s]
# Run YOLOv5x on COCO val
!python val.py --weights yolov5x.pt --data coco.yaml --img 640 --iou 0.65 --half
val: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB) Downloading https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5x.pt to yolov5x.pt... 100% 166M/166M [00:03<00:00, 54.1MB/s] Fusing layers... Model Summary: 444 layers, 86705005 parameters, 0 gradients val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2636.64it/s] val: New cache created: ../datasets/coco/val2017.cache Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [01:12<00:00, 2.17it/s] all 5000 36335 0.729 0.63 0.683 0.496 Speed: 0.1ms pre-process, 4.9ms inference, 1.9ms NMS per image at shape (32, 3, 640, 640) Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json... loading annotations into memory... Done (t=0.46s) creating index... index created! Loading and preparing results... DONE (t=5.15s) creating index... index created! Running per image evaluation... Evaluate annotation type *bbox* DONE (t=90.39s). Accumulating evaluation results... DONE (t=14.54s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.507 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.689 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.552 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.345 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.559 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.652 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.381 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.630 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.682 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.732 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.829 Results saved to runs/val/exp
COCO test¶
Download COCO test2017 dataset (7GB - 40,000 images), to test model accuracy on test-dev set (20,000 images, no labels). Results are saved to a *.json file which should be zipped and submitted to the evaluation server at https://competitions.codalab.org/competitions/20794.
# Download COCO test-dev2017
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017labels.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip
!f="test2017.zip" && curl http://images.cocodataset.org/zips/$f -o $f && unzip -q $f -d ../datasets/coco/images
# Run YOLOv5x on COCO test
!python val.py --weights yolov5x.pt --data coco.yaml --img 640 --iou 0.65 --half --task test
3. Train¶
Train a YOLOv5s model on the COCO128 dataset with --data coco128.yaml, starting from pretrained --weights yolov5s.pt, or from randomly initialized --weights '' --cfg yolov5s.yaml.
- Pretrained Models are downloaded
automatically from the latest YOLOv5 release
- Datasets available for autodownload include: COCO, COCO128, VOC, Argoverse, VisDrone, GlobalWheat, xView, Objects365, SKU-110K.
- Training Results are saved to
runs/train/with incrementing run directories, i.e.runs/train/exp2,runs/train/exp3etc.
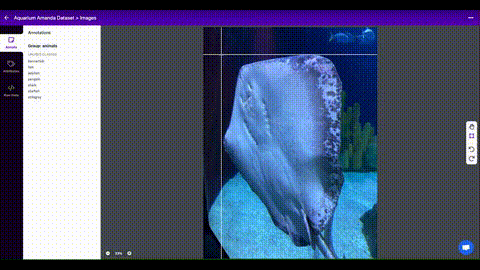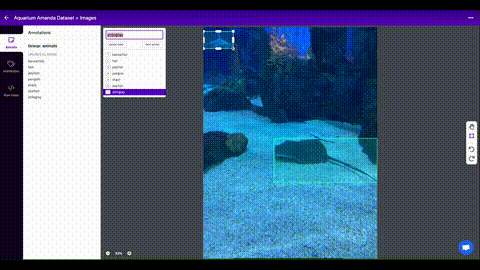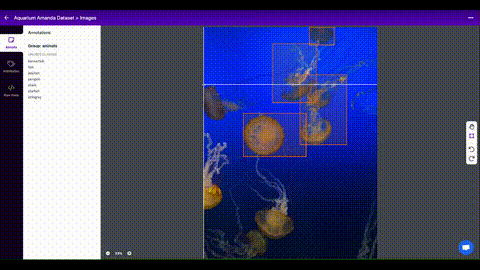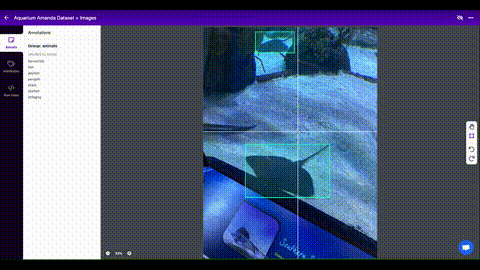
Train on Custom Data with Roboflow 🌟 NEW¶
Roboflow enables you to easily organize, label, and prepare a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the roboflow pip package.
- Custom Training Example: https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/
- Custom Training Notebook:

# Tensorboard (optional)
%load_ext tensorboard
%tensorboard --logdir runs/train
# Weights & Biases (optional)
%pip install -q wandb
import wandb
wandb.login()
# Train YOLOv5s on COCO128 for 3 epochs
!python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
train: weights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data/hyps/hyp.scratch.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, adam=False, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, patience=100, freeze=0, save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest github: up to date with https://github.com/ultralytics/yolov5 ✅ YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB) hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0 Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs (RECOMMENDED) TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/ from n params module arguments 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 2 115712 models.common.C3 [128, 128, 2] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 3 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 1182720 models.common.C3 [512, 512, 1] 9 -1 1 656896 models.common.SPPF [512, 512, 5] 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 6] 1 0 models.common.Concat [1] 13 -1 1 361984 models.common.C3 [512, 256, 1, False] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 16 [-1, 4] 1 0 models.common.Concat [1] 17 -1 1 90880 models.common.C3 [256, 128, 1, False] 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 296448 models.common.C3 [256, 256, 1, False] 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] 24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]] Model Summary: 270 layers, 7235389 parameters, 7235389 gradients, 16.5 GFLOPs Transferred 349/349 items from yolov5s.pt Scaled weight_decay = 0.0005 optimizer: SGD with parameter groups 57 weight, 60 weight (no decay), 60 bias albumentations: version 1.0.3 required by YOLOv5, but version 0.1.12 is currently installed train: Scanning '../datasets/coco128/labels/train2017.cache' images and labels... 128 found, 0 missing, 2 empty, 0 corrupted: 100% 128/128 [00:00<?, ?it/s] train: Caching images (0.1GB ram): 100% 128/128 [00:00<00:00, 296.04it/s] val: Scanning '../datasets/coco128/labels/train2017.cache' images and labels... 128 found, 0 missing, 2 empty, 0 corrupted: 100% 128/128 [00:00<?, ?it/s] val: Caching images (0.1GB ram): 100% 128/128 [00:01<00:00, 121.58it/s] Plotting labels... autoanchor: Analyzing anchors... anchors/target = 4.27, Best Possible Recall (BPR) = 0.9935 Image sizes 640 train, 640 val Using 2 dataloader workers Logging results to runs/train/exp Starting training for 3 epochs... Epoch gpu_mem box obj cls labels img_size 0/2 3.62G 0.04621 0.0711 0.02112 203 640: 100% 8/8 [00:04<00:00, 1.99it/s] Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:00<00:00, 4.37it/s] all 128 929 0.655 0.547 0.622 0.41 Epoch gpu_mem box obj cls labels img_size 1/2 5.31G 0.04564 0.06898 0.02116 143 640: 100% 8/8 [00:01<00:00, 4.77it/s] Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:00<00:00, 4.27it/s] all 128 929 0.68 0.554 0.632 0.419 Epoch gpu_mem box obj cls labels img_size 2/2 5.31G 0.04487 0.06883 0.01998 253 640: 100% 8/8 [00:01<00:00, 4.91it/s] Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:00<00:00, 4.30it/s] all 128 929 0.71 0.544 0.629 0.423 3 epochs completed in 0.003 hours. Optimizer stripped from runs/train/exp/weights/last.pt, 14.9MB Optimizer stripped from runs/train/exp/weights/best.pt, 14.9MB Validating runs/train/exp/weights/best.pt... Fusing layers... Model Summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 4/4 [00:03<00:00, 1.04it/s] all 128 929 0.71 0.544 0.63 0.423 person 128 254 0.816 0.669 0.774 0.507 bicycle 128 6 0.799 0.667 0.614 0.371 car 128 46 0.803 0.355 0.486 0.209 motorcycle 128 5 0.704 0.6 0.791 0.583 airplane 128 6 1 0.795 0.995 0.717 bus 128 7 0.656 0.714 0.72 0.606 train 128 3 0.852 1 0.995 0.682 truck 128 12 0.521 0.25 0.395 0.215 boat 128 6 0.795 0.333 0.445 0.137 traffic light 128 14 0.576 0.143 0.24 0.161 stop sign 128 2 0.636 0.5 0.828 0.713 bench 128 9 0.972 0.444 0.575 0.25 bird 128 16 0.939 0.968 0.988 0.645 cat 128 4 0.984 0.75 0.822 0.694 dog 128 9 0.888 0.667 0.903 0.54 horse 128 2 0.689 1 0.995 0.697 elephant 128 17 0.96 0.882 0.943 0.681 bear 128 1 0.549 1 0.995 0.995 zebra 128 4 0.86 1 0.995 0.952 giraffe 128 9 0.822 0.778 0.905 0.57 backpack 128 6 1 0.309 0.457 0.195 umbrella 128 18 0.775 0.576 0.74 0.418 handbag 128 19 0.628 0.105 0.167 0.111 tie 128 7 0.96 0.571 0.701 0.441 suitcase 128 4 1 0.895 0.995 0.621 frisbee 128 5 0.641 0.8 0.798 0.664 skis 128 1 0.627 1 0.995 0.497 snowboard 128 7 0.988 0.714 0.768 0.556 sports ball 128 6 0.671 0.5 0.579 0.339 kite 128 10 0.631 0.515 0.598 0.221 baseball bat 128 4 0.47 0.456 0.277 0.137 baseball glove 128 7 0.459 0.429 0.334 0.182 skateboard 128 5 0.7 0.48 0.736 0.548 tennis racket 128 7 0.559 0.571 0.538 0.315 bottle 128 18 0.607 0.389 0.484 0.282 wine glass 128 16 0.722 0.812 0.82 0.385 cup 128 36 0.881 0.361 0.532 0.312 fork 128 6 0.384 0.167 0.239 0.191 knife 128 16 0.908 0.616 0.681 0.443 spoon 128 22 0.836 0.364 0.536 0.264 bowl 128 28 0.793 0.536 0.633 0.471 banana 128 1 0 0 0.142 0.0995 sandwich 128 2 0 0 0.0951 0.0717 orange 128 4 1 0 0.67 0.317 broccoli 128 11 0.345 0.182 0.283 0.243 carrot 128 24 0.688 0.459 0.612 0.402 hot dog 128 2 0.424 0.771 0.497 0.473 pizza 128 5 0.622 1 0.824 0.551 donut 128 14 0.703 1 0.952 0.853 cake 128 4 0.733 1 0.945 0.777 chair 128 35 0.512 0.486 0.488 0.222 couch 128 6 0.68 0.36 0.746 0.406 potted plant 128 14 0.797 0.714 0.808 0.482 bed 128 3 1 0 0.474 0.318 dining table 128 13 0.852 0.445 0.478 0.315 toilet 128 2 0.512 0.5 0.554 0.487 tv 128 2 0.754 1 0.995 0.895 laptop 128 3 1 0 0.39 0.147 mouse 128 2 1 0 0.0283 0.0226 remote 128 8 0.747 0.625 0.636 0.488 cell phone 128 8 0.555 0.166 0.417 0.222 microwave 128 3 0.417 1 0.995 0.732 oven 128 5 0.37 0.4 0.432 0.249 sink 128 6 0.356 0.167 0.269 0.149 refrigerator 128 5 0.705 0.8 0.814 0.45 book 128 29 0.628 0.138 0.298 0.136 clock 128 9 0.857 0.778 0.893 0.574 vase 128 2 0.242 1 0.663 0.622 scissors 128 1 1 0 0.0207 0.00207 teddy bear 128 21 0.847 0.381 0.622 0.345 toothbrush 128 5 0.99 0.6 0.662 0.45 Results saved to runs/train/exp
4. Visualize¶
Weights & Biases Logging 🌟 NEW¶
Weights & Biases (W&B) is now integrated with YOLOv5 for real-time visualization and cloud logging of training runs. This allows for better run comparison and introspection, as well improved visibility and collaboration for teams. To enable W&B pip install wandb, and then train normally (you will be guided through setup on first use).
During training you will see live updates at https://wandb.ai/home, and you can create and share detailed Reports of your results. For more information see the YOLOv5 Weights & Biases Tutorial.

Local Logging¶
All results are logged by default to runs/train, with a new experiment directory created for each new training as runs/train/exp2, runs/train/exp3, etc. View train and val jpgs to see mosaics, labels, predictions and augmentation effects. Note an Ultralytics Mosaic Dataloader is used for training (shown below), which combines 4 images into 1 mosaic during training.

train_batch0.jpg shows train batch 0 mosaics and labels

test_batch0_labels.jpg shows val batch 0 labels

test_batch0_pred.jpg shows val batch 0 predictions
Training results are automatically logged to Tensorboard and CSV as results.csv, which is plotted as results.png (below) after training completes. You can also plot any results.csv file manually:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'

Environments¶
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab and Kaggle notebooks with free GPU:

- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status¶
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), testing (val.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
Appendix¶
Optional extras below. Unit tests validate repo functionality and should be run on any PRs submitted.
# Reproduce
for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':
!python val.py --weights {x}.pt --data coco.yaml --img 640 --task speed # speed
!python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP
# PyTorch Hub
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
dir = 'https://ultralytics.com/images/'
imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images
# Inference
results = model(imgs)
results.print() # or .show(), .save()
# CI Checks
%%shell
export PYTHONPATH="$PWD" # to run *.py. files in subdirectories
rm -rf runs # remove runs/
for m in yolov5n; do # models
python train.py --img 64 --batch 32 --weights $m.pt --epochs 1 --device 0 # train pretrained
python train.py --img 64 --batch 32 --weights '' --cfg $m.yaml --epochs 1 --device 0 # train scratch
for d in 0 cpu; do # devices
python val.py --weights $m.pt --device $d # val official
python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom
python detect.py --weights $m.pt --device $d # detect official
python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom
done
python hubconf.py # hub
python models/yolo.py --cfg $m.yaml # build PyTorch model
python models/tf.py --weights $m.pt # build TensorFlow model
python export.py --img 64 --batch 1 --weights $m.pt --include torchscript onnx # export
done
# Profile
from utils.torch_utils import profile
m1 = lambda x: x * torch.sigmoid(x)
m2 = torch.nn.SiLU()
results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)
# Evolve
!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve
!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)
# VOC
for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)
!python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}
# TensorRT
# https://developer.nvidia.com/nvidia-tensorrt-download
!lsb_release -a # check system
%ls /usr/local | grep cuda # check CUDA
!wget https://ultralytics.com/assets/TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # download
![ -d /content/TensorRT-8.2.0.6/ ] || tar -C /content/ -zxf ./TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # unzip
%pip list | grep tensorrt || pip install /content/TensorRT-8.2.0.6/python/tensorrt-8.2.0.6-cp37-none-linux_x86_64.whl # install
%env LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:/content/cuda-11.1/lib64:/content/TensorRT-8.2.0.6/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 # add to path
!python export.py --weights yolov5s.pt --include engine --imgsz 640 640 --device 0
!python detect.py --weights yolov5s.engine --imgsz 640 640 --device 0