from fastai.text import *
# Note: You need to run translation.ipynb nb before running this one to get the data set up
path = Config().data_path()/'giga-fren'
path.ls()
[PosixPath('/home/stas/.fastai/data/giga-fren/models'),
PosixPath('/home/stas/.fastai/data/giga-fren/giga-fren.release2.fixed.en'),
PosixPath('/home/stas/.fastai/data/giga-fren/giga-fren.release2.fixed.fr'),
PosixPath('/home/stas/.fastai/data/giga-fren/data_save.pkl'),
PosixPath('/home/stas/.fastai/data/giga-fren/cc.en.300.bin'),
PosixPath('/home/stas/.fastai/data/giga-fren/questions_easy.csv'),
PosixPath('/home/stas/.fastai/data/giga-fren/cc.fr.300.bin')]
Load data¶
We reuse the same functions as in the translation notebook to load our data.
def seq2seq_collate(samples:BatchSamples, pad_idx:int=1, pad_first:bool=True, backwards:bool=False) -> Tuple[LongTensor, LongTensor]:
"Function that collect samples and adds padding. Flips token order if needed"
samples = to_data(samples)
max_len_x,max_len_y = max([len(s[0]) for s in samples]),max([len(s[1]) for s in samples])
res_x = torch.zeros(len(samples), max_len_x).long() + pad_idx
res_y = torch.zeros(len(samples), max_len_y).long() + pad_idx
if backwards: pad_first = not pad_first
for i,s in enumerate(samples):
if pad_first:
res_x[i,-len(s[0]):],res_y[i,-len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])
else:
res_x[i,:len(s[0]):],res_y[i,:len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])
if backwards: res_x,res_y = res_x.flip(1),res_y.flip(1)
return res_x, res_y
class Seq2SeqDataBunch(TextDataBunch):
"Create a `TextDataBunch` suitable for training an RNN classifier."
@classmethod
def create(cls, train_ds, valid_ds, test_ds=None, path:PathOrStr='.', bs:int=32, val_bs:int=None, pad_idx=1,
pad_first=False, device:torch.device=None, no_check:bool=False, backwards:bool=False, **dl_kwargs) -> DataBunch:
"Function that transform the `datasets` in a `DataBunch` for classification. Passes `**dl_kwargs` on to `DataLoader()`"
datasets = cls._init_ds(train_ds, valid_ds, test_ds)
val_bs = ifnone(val_bs, bs)
collate_fn = partial(seq2seq_collate, pad_idx=pad_idx, pad_first=pad_first, backwards=backwards)
train_sampler = SortishSampler(datasets[0].x, key=lambda t: len(datasets[0][t][0].data), bs=bs//2)
train_dl = DataLoader(datasets[0], batch_size=bs, sampler=train_sampler, drop_last=True, **dl_kwargs)
dataloaders = [train_dl]
for ds in datasets[1:]:
lengths = [len(t) for t in ds.x.items]
sampler = SortSampler(ds.x, key=lengths.__getitem__)
dataloaders.append(DataLoader(ds, batch_size=val_bs, sampler=sampler, **dl_kwargs))
return cls(*dataloaders, path=path, device=device, collate_fn=collate_fn, no_check=no_check)
class Seq2SeqTextList(TextList):
_bunch = Seq2SeqDataBunch
_label_cls = TextList
Refer to the translation notebook for creation of 'questions_easy.csv'.
df = pd.read_csv(path/'questions_easy.csv')
src = Seq2SeqTextList.from_df(df, path = path, cols='fr').split_by_rand_pct().label_from_df(cols='en', label_cls=TextList)
np.percentile([len(o) for o in src.train.x.items] + [len(o) for o in src.valid.x.items], 90)
29.0
np.percentile([len(o) for o in src.train.y.items] + [len(o) for o in src.valid.y.items], 90)
26.0
As before, we remove questions with more than 30 tokens.
src = src.filter_by_func(lambda x,y: len(x) > 30 or len(y) > 30)
len(src.train) + len(src.valid)
47389
data = src.databunch()
data.save()
Can load from here when restarting.
data = load_data(path)
data.show_batch()
| text | target |
|---|---|
| xxbos xxmaj quelles mesures le gouvernement a - t - il prises pour faire passer les ministères et organismes à risque élevé à une catégorie de risque plus faible ? | xxbos xxmaj what action has the xxmaj government taken to xxunk the " xxmaj medium to xxmaj high " risk departments and agencies to a lower risk category ? |
| xxbos xxmaj quels sont les rôles respectifs du personnel juridique et non juridique pour la définition du cadre de rédaction législative ainsi que durant le processus lui - même ? | xxbos xxmaj what are the appropriate roles of the legal and non - legal staff in setting the framework for the legislative drafting process and during the process itself ? |
| xxbos xxmaj comment nos chefs peuvent - ils espérer nous faire observer les règles et les politiques de notre organisation lorsqu’ils renoncent eux - mêmes à les faire respecter ? | xxbos xxmaj when our leaders choose not to enforce the regulations and policies of our organization , how can they expect us to follow them ? |
| xxbos xxmaj quel sera le sort réservé aux suppléments en vertu du projet de loi xxup c-51 , et le dosage fera - t - il l'objet d'une réglementation ? | xxbos xxmaj what is the future under xxmaj bill xxup c-51 for supplements and will there be regulated doses ? |
| xxbos xxmaj quelle serait aujourd'hui la prévalence du tabagisme si les manufacturiers de tabac canadiens n'avaient pas augmenté régulièrement le contenu en nicotine des cigarettes entre 1980 et 1995 ? | xxbos xxmaj what would the prevalence of smoking be today if the xxmaj canadian tobacco manufacturers had not regularly raised the nicotine content of cigarettes between 1980 and 1995 ? |
Transformer model¶
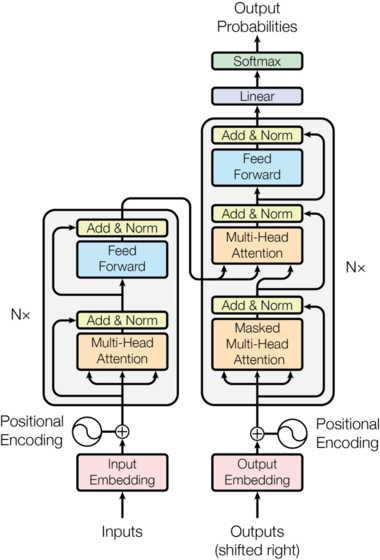
Shifting¶
We add a transform to the dataloader that shifts the targets right and adds a padding at the beginning.
def shift_tfm(b):
x,y = b
y = F.pad(y, (1, 0), value=1)
return [x,y[:,:-1]], y[:,1:]
data.add_tfm(shift_tfm)
Embeddings¶
The input and output embeddings are traditional PyTorch embeddings (and we can use pretrained vectors if we want to). The transformer model isn't a recurrent one, so it has no idea of the relative positions of the words. To help it with that, they had to the input embeddings a positional encoding which is cosine of a certain frequency:
class PositionalEncoding(nn.Module):
"Encode the position with a sinusoid."
def __init__(self, d:int):
super().__init__()
self.register_buffer('freq', 1 / (10000 ** (torch.arange(0., d, 2.)/d)))
def forward(self, pos:Tensor):
inp = torch.ger(pos, self.freq)
enc = torch.cat([inp.sin(), inp.cos()], dim=-1)
return enc
tst_encoding = PositionalEncoding(20)
res = tst_encoding(torch.arange(0,100).float())
_, ax = plt.subplots(1,1)
for i in range(1,5): ax.plot(res[:,i])
[<matplotlib.lines.Line2D at 0x7f9e60e41c18>]
[<matplotlib.lines.Line2D at 0x7f9e6202fc50>]
[<matplotlib.lines.Line2D at 0x7f9e62031080>]
[<matplotlib.lines.Line2D at 0x7f9e62031518>]

class TransformerEmbedding(nn.Module):
"Embedding + positional encoding + dropout"
def __init__(self, vocab_sz:int, emb_sz:int, inp_p:float=0.):
super().__init__()
self.emb_sz = emb_sz
self.embed = embedding(vocab_sz, emb_sz)
self.pos_enc = PositionalEncoding(emb_sz)
self.drop = nn.Dropout(inp_p)
def forward(self, inp):
pos = torch.arange(0, inp.size(1), device=inp.device).float()
return self.drop(self.embed(inp) * math.sqrt(self.emb_sz) + self.pos_enc(pos))
Feed forward¶
The feed forward cell is easy: it's just two linear layers with a skip connection and a LayerNorm.
def feed_forward(d_model:int, d_ff:int, ff_p:float=0., double_drop:bool=True):
layers = [nn.Linear(d_model, d_ff), nn.ReLU()]
if double_drop: layers.append(nn.Dropout(ff_p))
return SequentialEx(*layers, nn.Linear(d_ff, d_model), nn.Dropout(ff_p), MergeLayer(), nn.LayerNorm(d_model))
Multi-head attention¶
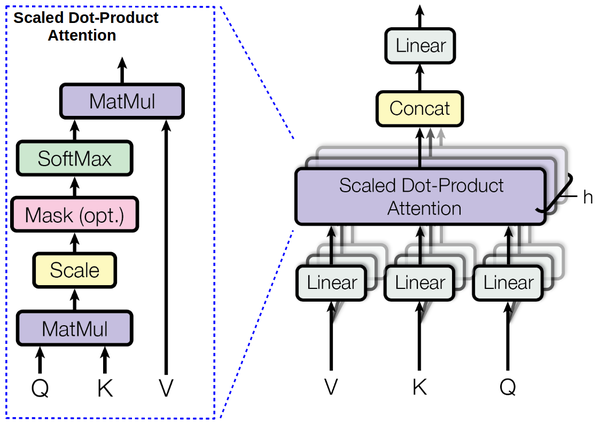
class MultiHeadAttention(nn.Module):
"MutiHeadAttention."
def __init__(self, n_heads:int, d_model:int, d_head:int=None, resid_p:float=0., attn_p:float=0., bias:bool=True,
scale:bool=True):
super().__init__()
d_head = ifnone(d_head, d_model//n_heads)
self.n_heads,self.d_head,self.scale = n_heads,d_head,scale
self.q_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.k_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.v_wgt = nn.Linear(d_model, n_heads * d_head, bias=bias)
self.out = nn.Linear(n_heads * d_head, d_model, bias=bias)
self.drop_att,self.drop_res = nn.Dropout(attn_p),nn.Dropout(resid_p)
self.ln = nn.LayerNorm(d_model)
def forward(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
return self.ln(q + self.drop_res(self.out(self._apply_attention(q, k, v, mask=mask))))
def _apply_attention(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
bs,seq_len = q.size(0),q.size(1)
wq,wk,wv = self.q_wgt(q),self.k_wgt(k),self.v_wgt(v)
wq,wk,wv = map(lambda x:x.view(bs, x.size(1), self.n_heads, self.d_head), (wq,wk,wv))
wq,wk,wv = wq.permute(0, 2, 1, 3),wk.permute(0, 2, 3, 1),wv.permute(0, 2, 1, 3)
attn_score = torch.matmul(wq, wk)
if self.scale: attn_score = attn_score.div_(self.d_head ** 0.5)
if mask is not None:
attn_score = attn_score.float().masked_fill(mask, -float('inf')).type_as(attn_score)
attn_prob = self.drop_att(F.softmax(attn_score, dim=-1))
attn_vec = torch.matmul(attn_prob, wv)
return attn_vec.permute(0, 2, 1, 3).contiguous().contiguous().view(bs, seq_len, -1)
def _attention_einsum(self, q:Tensor, k:Tensor, v:Tensor, mask:Tensor=None):
# Permute and matmul is a little bit faster but this implementation is more readable
bs,seq_len = q.size(0),q.size(1)
wq,wk,wv = self.q_wgt(q),self.k_wgt(k),self.v_wgt(v)
wq,wk,wv = map(lambda x:x.view(bs, x.size(1), self.n_heads, self.d_head), (wq,wk,wv))
attn_score = torch.einsum('bind,bjnd->bijn', (wq, wk))
if self.scale: attn_score = attn_score.mul_(1/(self.d_head ** 0.5))
if mask is not None:
attn_score = attn_score.float().masked_fill(mask, -float('inf')).type_as(attn_score)
attn_prob = self.drop_att(F.softmax(attn_score, dim=2))
attn_vec = torch.einsum('bijn,bjnd->bind', (attn_prob, wv))
return attn_vec.contiguous().view(bs, seq_len, -1)
Masking¶
The attention layer uses a mask to avoid paying attention to certain timesteps. The first thing is that we don't really want the network to pay attention to the padding, so we're going to mask it. The second thing is that since this model isn't recurrent, we need to mask (in the output) all the tokens we're not supposed to see yet (otherwise it would be cheating).
def get_padding_mask(inp, pad_idx:int=1):
return None
return (inp == pad_idx)[:,None,:,None]
def get_output_mask(inp, pad_idx:int=1):
return torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None].byte()
return ((inp == pad_idx)[:,None,:,None].long() + torch.triu(inp.new_ones(inp.size(1),inp.size(1)), diagonal=1)[None,None] != 0)
Example of mask for the future tokens:
torch.triu(torch.ones(10,10), diagonal=1).byte()
tensor([[0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.uint8)
Encoder and decoder blocks¶
We are now ready to regroup these layers in the blocks we add in the model picture:
class EncoderBlock(nn.Module):
"Encoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads:int, d_model:int, d_head:int, d_inner:int, resid_p:float=0., attn_p:float=0., ff_p:float=0.,
bias:bool=True, scale:bool=True, double_drop:bool=True):
super().__init__()
self.mha = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=ff_p, double_drop=double_drop)
def forward(self, x:Tensor, mask:Tensor=None): return self.ff(self.mha(x, x, x, mask=mask))
class DecoderBlock(nn.Module):
"Decoder block of a Transformer model."
#Can't use Sequential directly cause more than one input...
def __init__(self, n_heads:int, d_model:int, d_head:int, d_inner:int, resid_p:float=0., attn_p:float=0., ff_p:float=0.,
bias:bool=True, scale:bool=True, double_drop:bool=True):
super().__init__()
self.mha1 = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.mha2 = MultiHeadAttention(n_heads, d_model, d_head, resid_p=resid_p, attn_p=attn_p, bias=bias, scale=scale)
self.ff = feed_forward(d_model, d_inner, ff_p=ff_p, double_drop=double_drop)
def forward(self, x:Tensor, enc:Tensor, mask_in:Tensor=None, mask_out:Tensor=None):
y = self.mha1(x, x, x, mask_out)
return self.ff(self.mha2(y, enc, enc, mask=mask_in))
The whole model¶
class Transformer(nn.Module):
"Transformer model"
def __init__(self, inp_vsz:int, out_vsz:int, n_layers:int=6, n_heads:int=8, d_model:int=256, d_head:int=32,
d_inner:int=1024, inp_p:float=0.1, resid_p:float=0.1, attn_p:float=0.1, ff_p:float=0.1, bias:bool=True,
scale:bool=True, double_drop:bool=True, pad_idx:int=1):
super().__init__()
self.enc_emb = TransformerEmbedding(inp_vsz, d_model, inp_p)
self.dec_emb = TransformerEmbedding(out_vsz, d_model, 0.)
self.encoder = nn.ModuleList([EncoderBlock(n_heads, d_model, d_head, d_inner, resid_p, attn_p,
ff_p, bias, scale, double_drop) for _ in range(n_layers)])
self.decoder = nn.ModuleList([DecoderBlock(n_heads, d_model, d_head, d_inner, resid_p, attn_p,
ff_p, bias, scale, double_drop) for _ in range(n_layers)])
self.out = nn.Linear(d_model, out_vsz)
self.out.weight = self.dec_emb.embed.weight
self.pad_idx = pad_idx
def forward(self, inp, out):
mask_in = get_padding_mask(inp, self.pad_idx)
mask_out = get_output_mask (out, self.pad_idx)
enc,out = self.enc_emb(inp),self.dec_emb(out)
for enc_block in self.encoder: enc = enc_block(enc, mask_in)
for dec_block in self.decoder: out = dec_block(out, enc, mask_in, mask_out)
return self.out(out)
Bleu metric (see dedicated notebook)¶
class NGram():
def __init__(self, ngram, max_n=5000): self.ngram,self.max_n = ngram,max_n
def __eq__(self, other):
if len(self.ngram) != len(other.ngram): return False
return np.all(np.array(self.ngram) == np.array(other.ngram))
def __hash__(self): return int(sum([o * self.max_n**i for i,o in enumerate(self.ngram)]))
def get_grams(x, n, max_n=5000):
return x if n==1 else [NGram(x[i:i+n], max_n=max_n) for i in range(len(x)-n+1)]
def get_correct_ngrams(pred, targ, n, max_n=5000):
pred_grams,targ_grams = get_grams(pred, n, max_n=max_n),get_grams(targ, n, max_n=max_n)
pred_cnt,targ_cnt = Counter(pred_grams),Counter(targ_grams)
return sum([min(c, targ_cnt[g]) for g,c in pred_cnt.items()]),len(pred_grams)
class CorpusBLEU(Callback):
def __init__(self, vocab_sz):
self.vocab_sz = vocab_sz
self.name = 'bleu'
def on_epoch_begin(self, **kwargs):
self.pred_len,self.targ_len,self.corrects,self.counts = 0,0,[0]*4,[0]*4
def on_batch_end(self, last_output, last_target, **kwargs):
last_output = last_output.argmax(dim=-1)
for pred,targ in zip(last_output.cpu().numpy(),last_target.cpu().numpy()):
self.pred_len += len(pred)
self.targ_len += len(targ)
for i in range(4):
c,t = get_correct_ngrams(pred, targ, i+1, max_n=self.vocab_sz)
self.corrects[i] += c
self.counts[i] += t
def on_epoch_end(self, last_metrics, **kwargs):
precs = [c/t for c,t in zip(self.corrects,self.counts)]
len_penalty = exp(1 - self.targ_len/self.pred_len) if self.pred_len < self.targ_len else 1
bleu = len_penalty * ((precs[0]*precs[1]*precs[2]*precs[3]) ** 0.25)
return add_metrics(last_metrics, bleu)
Training¶
model = Transformer(len(data.train_ds.x.vocab.itos), len(data.train_ds.y.vocab.itos), d_model=256)
learn = Learner(data, model, metrics=[accuracy, CorpusBLEU(len(data.train_ds.y.vocab.itos))],
loss_func = CrossEntropyFlat())
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()

learn.fit_one_cycle(8, 5e-4, div_factor=5)
| epoch | train_loss | valid_loss | accuracy | bleu | time |
|---|---|---|---|---|---|
| 0 | 2.432767 | 2.478084 | 0.618113 | 0.460726 | 01:03 |
| 1 | 1.959129 | 1.978793 | 0.686264 | 0.505202 | 01:06 |
| 2 | 1.536871 | 1.656002 | 0.723556 | 0.543357 | 01:07 |
| 3 | 1.371858 | 1.453879 | 0.749335 | 0.570762 | 01:07 |
| 4 | 1.113087 | 1.345275 | 0.764912 | 0.590188 | 01:07 |
| 5 | 0.970879 | 1.287549 | 0.774231 | 0.602932 | 01:06 |
| 6 | 0.852550 | 1.280241 | 0.778895 | 0.609807 | 01:07 |
| 7 | 0.771543 | 1.282661 | 0.779013 | 0.610055 | 01:08 |
def get_predictions(learn, ds_type=DatasetType.Valid):
learn.model.eval()
inputs, targets, outputs = [],[],[]
with torch.no_grad():
for xb,yb in progress_bar(learn.dl(ds_type)):
out = learn.model(*xb)
for x,y,z in zip(xb[0],xb[1],out):
inputs.append(learn.data.train_ds.x.reconstruct(x))
targets.append(learn.data.train_ds.y.reconstruct(y))
outputs.append(learn.data.train_ds.y.reconstruct(z.argmax(1)))
return inputs, targets, outputs
inputs, targets, outputs = get_predictions(learn)
inputs[10],targets[10],outputs[10]
(Text xxbos xxmaj comment cela a - t - il pu se produire et pourquoi n'y a - t - il pas de mécanismes en place pour empêcher cette situation ?, Text xxbos xxmaj why was this allowed to happen and why are n't there any mechanisms in place to prevent this ?, Text xxbos xxmaj why did this happening to take and why is there there no measures not this to prevent this situation)
inputs[700],targets[700],outputs[700]
(Text xxbos xxmaj qu’advient - il lorsque les attentes sont xxunk et même xxunk ou qu’elles incitent l’organisation à xxunk de ses activités de base ?, Text xxbos xxmaj what happens when expectations are diverse and even xxunk , or take the organization away from its core business ?, Text xxbos xxmaj what happens when expectations are xxunk and their even or or they - organization 's from its core activities activities)
inputs[701],targets[701],outputs[701]
(Text xxbos xxmaj quelles mesures sont prises par les autorités sanitaires provinciales et locales pour assurer la sécurité du public lorsque des insecticides sont utilisés ?, Text xxbos xxmaj what steps do provincial / local health authorities take to ensure public safety when pesticides are used ?, Text xxbos xxmaj what measures are provincial and local health authorities have to ensure the safety and xxunk are used ?)
inputs[2500],targets[2500],outputs[2500]
(Text xxbos xxmaj quand les restrictions à la propriété concernant les xxunk aux postes terrestres seront - elles xxunk ?, Text xxbos xxmaj when will land xxmaj border store restrictions on ownership be lifted ?, Text xxbos xxmaj when will the restrictions property xxmaj restrictions be the of xxunk ?)
inputs[4002],targets[4002],outputs[4002]
(Text xxbos xxmaj qu’est - ce qu’une résolution du conseil de bande ( xxup xxunk ) ?, Text xxbos xxmaj what is a xxmaj band xxmaj council xxmaj resolution ( xxup xxunk ) ?, Text xxbos xxmaj what is a xxmaj band xxmaj board xxmaj agreement ? xxup xxunk ) ?)
Label smoothing¶
They point out in the paper that using label smoothing helped getting a better BLEU/accuracy, even if it made the loss worse.
model = Transformer(len(data.train_ds.x.vocab.itos), len(data.train_ds.y.vocab.itos), d_model=256)
learn = Learner(data, model, metrics=[accuracy, CorpusBLEU(len(data.train_ds.y.vocab.itos))],
loss_func=FlattenedLoss(LabelSmoothingCrossEntropy, axis=-1))
learn.fit_one_cycle(8, 5e-4, div_factor=5)
| epoch | train_loss | valid_loss | accuracy | bleu | time |
|---|---|---|---|---|---|
| 0 | 3.288097 | 3.361678 | 0.620848 | 0.462028 | 01:07 |
| 1 | 2.866131 | 2.932534 | 0.690689 | 0.508931 | 01:08 |
| 2 | 2.617174 | 2.686622 | 0.720212 | 0.535796 | 01:07 |
| 3 | 2.396165 | 2.509400 | 0.750236 | 0.572231 | 01:07 |
| 4 | 2.234806 | 2.415202 | 0.764170 | 0.590421 | 01:07 |
| 5 | 2.094995 | 2.375675 | 0.773611 | 0.601696 | 01:07 |
| 6 | 1.979516 | 2.361270 | 0.778426 | 0.607941 | 01:07 |
| 7 | 1.968844 | 2.363652 | 0.778740 | 0.608949 | 01:07 |
learn.fit_one_cycle(8, 5e-4, div_factor=5)
| epoch | train_loss | valid_loss | accuracy | bleu | time |
|---|---|---|---|---|---|
| 0 | 2.005607 | 2.370556 | 0.776371 | 0.606602 | 01:07 |
| 1 | 2.039403 | 2.376988 | 0.773496 | 0.602594 | 01:08 |
| 2 | 1.998095 | 2.364960 | 0.776239 | 0.606155 | 01:07 |
| 3 | 1.948557 | 2.333933 | 0.783300 | 0.617531 | 01:07 |
| 4 | 1.846455 | 2.334134 | 0.787573 | 0.623490 | 01:07 |
| 5 | 1.729133 | 2.339518 | 0.792536 | 0.632397 | 01:07 |
| 6 | 1.623762 | 2.345591 | 0.794781 | 0.636248 | 01:08 |
| 7 | 1.599179 | 2.351281 | 0.794569 | 0.636407 | 01:08 |
print("Quels sont les atouts particuliers du Canada en recherche sur l'obésité sur la scène internationale ?")
print("What are Specific strengths canada strengths in obesity - ? are up canada ? from international international stage ?")
print("Quelles sont les répercussions politiques à long terme de cette révolution scientifique mondiale ?")
print("What are the long the long - term policies implications of this global scientific ? ?")
Quels sont les atouts particuliers du Canada en recherche sur l'obésité sur la scène internationale ? What are Specific strengths canada strengths in obesity - ? are up canada ? from international international stage ? Quelles sont les répercussions politiques à long terme de cette révolution scientifique mondiale ? What are the long the long - term policies implications of this global scientific ? ?
inputs[10],targets[10],outputs[10]
(Text xxbos xxmaj comment cela a - t - il pu se produire et pourquoi n'y a - t - il pas de mécanismes en place pour empêcher cette situation ?, Text xxbos xxmaj why was this allowed to happen and why are n't there any mechanisms in place to prevent this ?, Text xxbos xxmaj why did this happening to take and why is there there no measures not this to prevent this situation)
inputs[700],targets[700],outputs[700]
(Text xxbos xxmaj qu’advient - il lorsque les attentes sont xxunk et même xxunk ou qu’elles incitent l’organisation à xxunk de ses activités de base ?, Text xxbos xxmaj what happens when expectations are diverse and even xxunk , or take the organization away from its core business ?, Text xxbos xxmaj what happens when expectations are xxunk and their even or or they - organization 's from its core activities activities)
inputs[701],targets[701],outputs[701]
(Text xxbos xxmaj quelles mesures sont prises par les autorités sanitaires provinciales et locales pour assurer la sécurité du public lorsque des insecticides sont utilisés ?, Text xxbos xxmaj what steps do provincial / local health authorities take to ensure public safety when pesticides are used ?, Text xxbos xxmaj what measures are provincial and local health authorities have to ensure the safety and xxunk are used ?)
inputs[4001],targets[4001],outputs[4001]
(Text xxbos xxmaj qui a dit qu'un xxmaj xxunk xxmaj xxunk ne xxunk que des armes ?, Text xxbos xxmaj who said a xxmaj xxunk xxmaj tech would have to work on weapons ?, Text xxbos xxmaj who said xxmaj xxmaj xxunk xxmaj xxunk xxunk not not xxunk in weapons ?)
Test leakage¶
If we change a token in the targets at position n, it shouldn't impact the predictions before that.
learn.model.eval();
xb,yb = data.one_batch(cpu=False)
inp1,out1 = xb[0][:1],xb[1][:1]
inp2,out2 = inp1.clone(),out1.clone()
out2[0,15] = 10
y1 = learn.model(inp1, out1)
y2 = learn.model(inp2, out2)
(y1[0,:15] - y2[0,:15]).abs().mean()
tensor(0., device='cuda:0', grad_fn=<MeanBackward0>)