Creating your own dataset from Google Images¶
by: Francisco Ingham and Jeremy Howard. Inspired by Adrian Rosebrock
In this tutorial we will see how to easily create an image dataset through Google Images. Note: You will have to repeat these steps for any new category you want to Google (e.g once for dogs and once for cats).
from fastai.vision import *
Get a list of URLs¶
Search and scroll¶
Go to Google Images and search for the images you are interested in. The more specific you are in your Google Search, the better the results and the less manual pruning you will have to do.
Scroll down until you've seen all the images you want to download, or until you see a button that says 'Show more results'. All the images you scrolled past are now available to download. To get more, click on the button, and continue scrolling. The maximum number of images Google Images shows is 700.
It is a good idea to put things you want to exclude into the search query, for instance if you are searching for the Eurasian wolf, "canis lupus lupus", it might be a good idea to exclude other variants:
"canis lupus lupus" -dog -arctos -familiaris -baileyi -occidentalis
You can also limit your results to show only photos by clicking on Tools and selecting Photos from the Type dropdown.
Download into file¶
Now you must run some Javascript code in your browser which will save the URLs of all the images you want for you dataset.
In Google Chrome press CtrlShiftj on Windows/Linux and CmdOptj on macOS, and a small window the javascript 'Console' will appear. In Firefox press CtrlShiftk on Windows/Linux or CmdOptk on macOS. That is where you will paste the JavaScript commands.
You will need to get the urls of each of the images. Before running the following commands, you may want to disable ad blocking extensions (uBlock, AdBlockPlus etc.) in Chrome. Otherwise the window.open() command doesn't work. Then you can run the following commands:
urls=Array.from(document.querySelectorAll('.rg_i')).map(el=> el.hasAttribute('data-src')?el.getAttribute('data-src'):el.getAttribute('data-iurl'));
window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));
Create directory and upload urls file into your server¶
Choose an appropriate name for your labeled images. You can run these steps multiple times to create different labels.
folder = 'black'
file = 'urls_black.csv'
folder = 'teddys'
file = 'urls_teddys.csv'
folder = 'grizzly'
file = 'urls_grizzly.csv'
You will need to run this cell once per each category.
path = Path('data/bears')
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
path.ls()
[PosixPath('data/bears/urls_teddy.csv'),
PosixPath('data/bears/black'),
PosixPath('data/bears/urls_grizzly.csv'),
PosixPath('data/bears/urls_black.csv')]
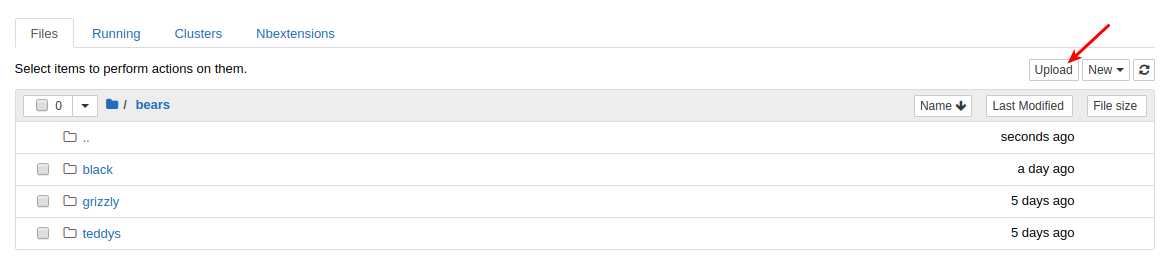
Finally, upload your urls file. You just need to press 'Upload' in your working directory and select your file, then click 'Upload' for each of the displayed files.
Download images¶
Now you will need to download your images from their respective urls.
fast.ai has a function that allows you to do just that. You just have to specify the urls filename as well as the destination folder and this function will download and save all images that can be opened. If they have some problem in being opened, they will not be saved.
Let's download our images! Notice you can choose a maximum number of images to be downloaded. In this case we will not download all the urls.
You will need to run this line once for every category.
classes = ['teddys','grizzly','black']
download_images(path/file, dest, max_pics=200)
Error https://npn-ndfapda.netdna-ssl.com/original/2X/9/973877494e28bd274c535610ffa8e262f7dcd0f2.jpeg HTTPSConnectionPool(host='npn-ndfapda.netdna-ssl.com', port=443): Max retries exceeded with url: /original/2X/9/973877494e28bd274c535610ffa8e262f7dcd0f2.jpeg (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7f2f7c168f60>: Failed to establish a new connection: [Errno -2] Name or service not known'))
# If you have problems download, try with `max_workers=0` to see exceptions:
download_images(path/file, dest, max_pics=20, max_workers=0)
Then we can remove any images that can't be opened:
for c in classes:
print(c)
verify_images(path/c, delete=True, max_size=500)
teddys
cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000073.jpg'> Image data/bears/teddys/00000106.gif has 1 instead of 3 channels Image data/bears/teddys/00000067.png has 4 instead of 3 channels Image data/bears/teddys/00000109.png has 4 instead of 3 channels cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000179.png'> Image data/bears/teddys/00000125.jpg has 1 instead of 3 channels Image data/bears/teddys/00000127.gif has 1 instead of 3 channels cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000012.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000145.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000165.jpg'> Image data/bears/teddys/00000193.gif has 1 instead of 3 channels cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000059.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000075.jpg'> Image data/bears/teddys/00000035.png has 4 instead of 3 channels Image data/bears/teddys/00000086.png has 4 instead of 3 channels cannot identify image file <_io.BufferedReader name='data/bears/teddys/00000177.jpg'> Image data/bears/teddys/00000110.png has 4 instead of 3 channels Image data/bears/teddys/00000099.gif has 1 instead of 3 channels Image data/bears/teddys/00000010.png has 4 instead of 3 channels grizzly
cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000116.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000178.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000119.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000082.png'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000108.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000019.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000132.jpg'> Image data/bears/grizzly/00000175.gif has 1 instead of 3 channels cannot identify image file <_io.BufferedReader name='data/bears/grizzly/00000122.jpg'> black
cannot identify image file <_io.BufferedReader name='data/bears/black/00000020.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000095.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000186.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000143.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000176.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000008.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000118.jpg'> cannot identify image file <_io.BufferedReader name='data/bears/black/00000135.jpg'>
View data¶
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
# If you already cleaned your data, run this cell instead of the one before
# np.random.seed(42)
# data = ImageDataBunch.from_csv(path, folder=".", valid_pct=0.2, csv_labels='cleaned.csv',
# ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
Good! Let's take a look at some of our pictures then.
data.classes
['black', 'grizzly', 'teddys']
data.show_batch(rows=3, figsize=(7,8))

data.classes, data.c, len(data.train_ds), len(data.valid_ds)
(['black', 'grizzly', 'teddys'], 3, 448, 111)
Train model¶
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.957604 | 0.199212 | 0.045045 |
| 2 | 0.556265 | 0.093994 | 0.036036 |
| 3 | 0.376028 | 0.082099 | 0.036036 |
| 4 | 0.273781 | 0.076548 | 0.027027 |
learn.save('stage-1')
learn.unfreeze()
learn.lr_find()
# If the plot is not showing try to give a start and end learning rate
# learn.lr_find(start_lr=1e-5, end_lr=1e-1)
learn.recorder.plot()
learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4))
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.046916 | 0.072489 | 0.027027 |
| 2 | 0.041749 | 0.070343 | 0.027027 |
learn.save('stage-2')
Interpretation¶
learn.load('stage-2');
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()

Cleaning Up¶
Some of our top losses aren't due to bad performance by our model. There are images in our data set that shouldn't be.
Using the ImageCleaner widget from fastai.widgets we can prune our top losses, removing photos that don't belong.
from fastai.widgets import *
First we need to get the file paths from our top_losses. We can do this with .from_toplosses. We then feed the top losses indexes and corresponding dataset to ImageCleaner.
Notice that the widget will not delete images directly from disk but it will create a new csv file cleaned.csv from where you can create a new ImageDataBunch with the corrected labels to continue training your model.
In order to clean the entire set of images, we need to create a new dataset without the split. The video lecture demostrated the use of the ds_type param which no longer has any effect. See the thread for more details.
db = (ImageList.from_folder(path)
.split_none()
.label_from_folder()
.transform(get_transforms(), size=224)
.databunch()
)
# If you already cleaned your data using indexes from `from_toplosses`,
# run this cell instead of the one before to proceed with removing duplicates.
# Otherwise all the results of the previous step would be overwritten by
# the new run of `ImageCleaner`.
# db = (ImageList.from_csv(path, 'cleaned.csv', folder='.')
# .split_none()
# .label_from_df()
# .transform(get_transforms(), size=224)
# .databunch()
# )
Then we create a new learner to use our new databunch with all the images.
learn_cln = cnn_learner(db, models.resnet34, metrics=error_rate)
learn_cln.load('stage-2');
ds, idxs = DatasetFormatter().from_toplosses(learn_cln)
Make sure you're running this notebook in Jupyter Notebook, not Jupyter Lab. That is accessible via /tree, not /lab. Running the ImageCleaner widget in Jupyter Lab is not currently supported.
# Don't run this in google colab or any other instances running jupyter lab.
# If you do run this on Jupyter Lab, you need to restart your runtime and
# runtime state including all local variables will be lost.
ImageCleaner(ds, idxs, path)
'No images to show :)'
If the code above does not show any GUI(contains images and buttons) rendered by widgets but only text output, that may caused by the configuration problem of ipywidgets. Try the solution in this link to solve it.
Flag photos for deletion by clicking 'Delete'. Then click 'Next Batch' to delete flagged photos and keep the rest in that row. ImageCleaner will show you a new row of images until there are no more to show. In this case, the widget will show you images until there are none left from top_losses.ImageCleaner(ds, idxs)
You can also find duplicates in your dataset and delete them! To do this, you need to run .from_similars to get the potential duplicates' ids and then run ImageCleaner with duplicates=True. The API works in a similar way as with misclassified images: just choose the ones you want to delete and click 'Next Batch' until there are no more images left.
Make sure to recreate the databunch and learn_cln from the cleaned.csv file. Otherwise the file would be overwritten from scratch, losing all the results from cleaning the data from toplosses.
ds, idxs = DatasetFormatter().from_similars(learn_cln)
Getting activations...
Computing similarities...
ImageCleaner(ds, idxs, path, duplicates=True)
'No images to show :)'
Remember to recreate your ImageDataBunch from your cleaned.csv to include the changes you made in your data!
Putting your model in production¶
First thing first, let's export the content of our Learner object for production:
learn.export()
This will create a file named 'export.pkl' in the directory where we were working that contains everything we need to deploy our model (the model, the weights but also some metadata like the classes or the transforms/normalization used).
You probably want to use CPU for inference, except at massive scale (and you almost certainly don't need to train in real-time). If you don't have a GPU that happens automatically. You can test your model on CPU like so:
defaults.device = torch.device('cpu')
img = open_image(path/'black'/'00000021.jpg')
img

We create our Learner in production enviromnent like this, just make sure that path contains the file 'export.pkl' from before.
learn = load_learner(path)
pred_class,pred_idx,outputs = learn.predict(img)
pred_class.obj
Category black
So you might create a route something like this (thanks to Simon Willison for the structure of this code):
@app.route("/classify-url", methods=["GET"])
async def classify_url(request):
bytes = await get_bytes(request.query_params["url"])
img = open_image(BytesIO(bytes))
_,_,losses = learner.predict(img)
return JSONResponse({
"predictions": sorted(
zip(cat_learner.data.classes, map(float, losses)),
key=lambda p: p[1],
reverse=True
)
})
(This example is for the Starlette web app toolkit.)
Things that can go wrong¶
- Most of the time things will train fine with the defaults
- There's not much you really need to tune (despite what you've heard!)
- Most likely are
- Learning rate
- Number of epochs
Learning rate (LR) too high¶
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(1, max_lr=0.5)
Total time: 00:13 epoch train_loss valid_loss error_rate 1 12.220007 1144188288.000000 0.765957 (00:13)
Learning rate (LR) too low¶
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
Previously we had this result:
Total time: 00:57
epoch train_loss valid_loss error_rate
1 1.030236 0.179226 0.028369 (00:14)
2 0.561508 0.055464 0.014184 (00:13)
3 0.396103 0.053801 0.014184 (00:13)
4 0.316883 0.050197 0.021277 (00:15)
learn.fit_one_cycle(5, max_lr=1e-5)
Total time: 01:07 epoch train_loss valid_loss error_rate 1 1.349151 1.062807 0.609929 (00:13) 2 1.373262 1.045115 0.546099 (00:13) 3 1.346169 1.006288 0.468085 (00:13) 4 1.334486 0.978713 0.453901 (00:13) 5 1.320978 0.978108 0.446809 (00:13)
learn.recorder.plot_losses()

As well as taking a really long time, it's getting too many looks at each image, so may overfit.
Too few epochs¶
learn = cnn_learner(data, models.resnet34, metrics=error_rate, pretrained=False)
learn.fit_one_cycle(1)
Total time: 00:14 epoch train_loss valid_loss error_rate 1 0.602823 0.119616 0.049645 (00:14)
Too many epochs¶
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.9, bs=32,
ds_tfms=get_transforms(do_flip=False, max_rotate=0, max_zoom=1, max_lighting=0, max_warp=0
),size=224, num_workers=4).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=error_rate, ps=0, wd=0)
learn.unfreeze()
learn.fit_one_cycle(40, slice(1e-6,1e-4))
Total time: 06:39 epoch train_loss valid_loss error_rate 1 1.513021 1.041628 0.507326 (00:13) 2 1.290093 0.994758 0.443223 (00:09) 3 1.185764 0.936145 0.410256 (00:09) 4 1.117229 0.838402 0.322344 (00:09) 5 1.022635 0.734872 0.252747 (00:09) 6 0.951374 0.627288 0.192308 (00:10) 7 0.916111 0.558621 0.184982 (00:09) 8 0.839068 0.503755 0.177656 (00:09) 9 0.749610 0.433475 0.144689 (00:09) 10 0.678583 0.367560 0.124542 (00:09) 11 0.615280 0.327029 0.100733 (00:10) 12 0.558776 0.298989 0.095238 (00:09) 13 0.518109 0.266998 0.084249 (00:09) 14 0.476290 0.257858 0.084249 (00:09) 15 0.436865 0.227299 0.067766 (00:09) 16 0.457189 0.236593 0.078755 (00:10) 17 0.420905 0.240185 0.080586 (00:10) 18 0.395686 0.255465 0.082418 (00:09) 19 0.373232 0.263469 0.080586 (00:09) 20 0.348988 0.258300 0.080586 (00:10) 21 0.324616 0.261346 0.080586 (00:09) 22 0.311310 0.236431 0.071429 (00:09) 23 0.328342 0.245841 0.069597 (00:10) 24 0.306411 0.235111 0.064103 (00:10) 25 0.289134 0.227465 0.069597 (00:09) 26 0.284814 0.226022 0.064103 (00:09) 27 0.268398 0.222791 0.067766 (00:09) 28 0.255431 0.227751 0.073260 (00:10) 29 0.240742 0.235949 0.071429 (00:09) 30 0.227140 0.225221 0.075092 (00:09) 31 0.213877 0.214789 0.069597 (00:09) 32 0.201631 0.209382 0.062271 (00:10) 33 0.189988 0.210684 0.065934 (00:09) 34 0.181293 0.214666 0.073260 (00:09) 35 0.184095 0.222575 0.073260 (00:09) 36 0.194615 0.229198 0.076923 (00:10) 37 0.186165 0.218206 0.075092 (00:09) 38 0.176623 0.207198 0.062271 (00:10) 39 0.166854 0.207256 0.065934 (00:10) 40 0.162692 0.206044 0.062271 (00:09)