In this notebook, I want to wrap up some loose ends from last time.
The two cultures¶
This "debate" captures the tension between two approaches:
- modeling the underlying mechanism of a phenomena
- using machine learning to predict outputs (without necessarily understanding the mechanisms that create them)

I was part of a research project (in 2007) that involved manually coding each of the above reactions. We were determining if the final system could generate the same ouputs (in this case, levels in the blood of various substrates) as were observed in clinical studies.
The equation for each reaction could be quite complex:

This is an example of modeling the underlying mechanism, and is very different from a machine learning approach.
Source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2391141/
The most popular word in each state¶

A time to remove stop words
Factorization is analgous to matrix decomposition¶
With Integers¶
Multiplication: $$2 * 2 * 3 * 3 * 2 * 2 \rightarrow 144$$
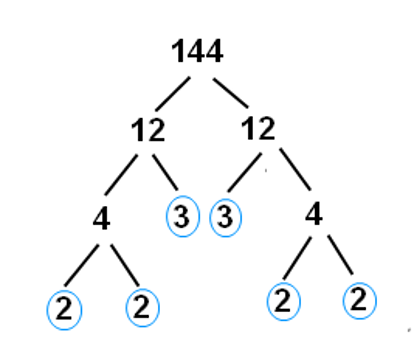
Factorization is the “opposite” of multiplication: $$144 \rightarrow 2 * 2 * 3 * 3 * 2 * 2$$
Here, the factors have the nice property of being prime.
Prime factorization is much harder than multiplication (which is good, because it’s the heart of encryption).
With Matrices¶
Matrix decompositions are a way of taking matrices apart (the "opposite" of matrix multiplication).
Similarly, we use matrix decompositions to come up with matrices with nice properties.

What are the nice properties that matrices in an SVD decomposition have?
$$A = USV$$Some Linear Algebra Review¶
Matrix-vector multiplication¶
$Ax = b$ takes a linear combination of the columns of $A$, using coefficients $x$
Matrix-matrix multiplication¶
$A B = C$ each column of C is a linear combination of columns of A, where the coefficients come from the corresponding column of C
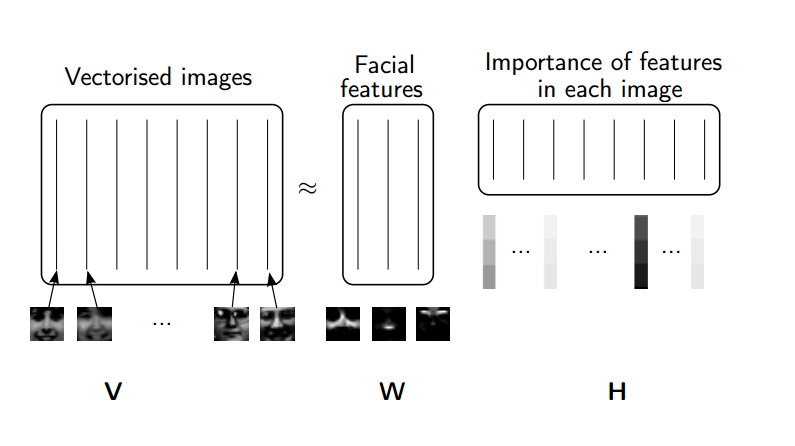
(source: NMF Tutorial)
Matrices as Transformations¶
The 3Blue 1Brown Essence of Linear Algebra videos are fantastic. They give a much more visual & geometric perspective on linear algreba than how it is typically taught. These videos are a great resource if you are a linear algebra beginner, or feel uncomfortable or rusty with the material.
Even if you are a linear algrebra pro, I still recommend these videos for a new perspective, and they are very well made.
from IPython.display import YouTubeVideo
YouTubeVideo("kYB8IZa5AuE")
British Literature SVD & NMF in Excel¶
Data was downloaded from here
The code below was used to create the matrices which are displayed in the SVD and NMF of British Literature excel workbook. The data is intended to be viewed in Excel, I've just included the code here for thoroughness.
Initializing, create document-term matrix¶
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn import decomposition
from glob import glob
import os
np.set_printoptions(suppress=True)
filenames = []
for folder in ["british-fiction-corpus"]: #, "french-plays", "hugo-les-misérables"]:
filenames.extend(glob("data/literature/" + folder + "/*.txt"))
len(filenames)
27
vectorizer = TfidfVectorizer(input='filename', stop_words='english')
dtm = vectorizer.fit_transform(filenames).toarray()
vocab = np.array(vectorizer.get_feature_names())
dtm.shape, len(vocab)
((27, 55035), 55035)
[f.split("/")[3] for f in filenames]
['Sterne_Tristram.txt', 'Austen_Pride.txt', 'Thackeray_Pendennis.txt', 'ABronte_Agnes.txt', 'Austen_Sense.txt', 'Thackeray_Vanity.txt', 'Trollope_Barchester.txt', 'Fielding_Tom.txt', 'Dickens_Bleak.txt', 'Eliot_Mill.txt', 'EBronte_Wuthering.txt', 'Eliot_Middlemarch.txt', 'Fielding_Joseph.txt', 'ABronte_Tenant.txt', 'Austen_Emma.txt', 'Trollope_Prime.txt', 'CBronte_Villette.txt', 'CBronte_Jane.txt', 'Richardson_Clarissa.txt', 'CBronte_Professor.txt', 'Dickens_Hard.txt', 'Eliot_Adam.txt', 'Dickens_David.txt', 'Trollope_Phineas.txt', 'Richardson_Pamela.txt', 'Sterne_Sentimental.txt', 'Thackeray_Barry.txt']
NMF¶
clf = decomposition.NMF(n_components=10, random_state=1)
W1 = clf.fit_transform(dtm)
H1 = clf.components_
num_top_words=8
def show_topics(a):
top_words = lambda t: [vocab[i] for i in np.argsort(t)[:-num_top_words-1:-1]]
topic_words = ([top_words(t) for t in a])
return [' '.join(t) for t in topic_words]
def get_all_topic_words(H):
top_indices = lambda t: {i for i in np.argsort(t)[:-num_top_words-1:-1]}
topic_indices = [top_indices(t) for t in H]
return sorted(set.union(*topic_indices))
ind = get_all_topic_words(H1)
vocab[ind]
array(['adams', 'allworthy', 'bounderby', 'brandon', 'catherine', 'cathy',
'corporal', 'crawley', 'darcy', 'dashwood', 'did', 'earnshaw',
'edgar', 'elinor', 'emma', 'father', 'ferrars', 'finn', 'glegg',
'good', 'gradgrind', 'hareton', 'heathcliff', 'jennings', 'jones',
'joseph', 'know', 'lady', 'laura', 'like', 'linton', 'little', 'll',
'lopez', 'louisa', 'lyndon', 'maggie', 'man', 'marianne', 'miss',
'mr', 'mrs', 'old', 'osborne', 'pendennis', 'philip', 'phineas',
'quoth', 'said', 'sissy', 'sophia', 'sparsit', 'stephen', 'thought',
'time', 'tis', 'toby', 'tom', 'trim', 'tulliver', 'uncle', 'wakem',
'wharton', 'willoughby'],
dtype='<U31')
show_topics(H1)
['mr said mrs miss emma darcy little know', 'said little like did time know thought good', 'adams jones said lady allworthy sophia joseph mr', 'elinor marianne dashwood jennings willoughby mrs brandon ferrars', 'maggie tulliver said tom glegg philip mr wakem', 'heathcliff linton hareton catherine earnshaw cathy edgar ll', 'toby said uncle father corporal quoth tis trim', 'phineas said mr lopez finn man wharton laura', 'said crawley lyndon pendennis old little osborne lady', 'bounderby gradgrind sparsit said mr sissy louisa stephen']
W1.shape, H1[:, ind].shape
((27, 10), (10, 64))
Export to CSVs¶
from IPython.display import FileLink, FileLinks
np.savetxt("britlit_W.csv", W1, delimiter=",", fmt='%.14f')
FileLink('britlit_W.csv')
np.savetxt("britlit_H.csv", H1[:,ind], delimiter=",", fmt='%.14f')
FileLink('britlit_H.csv')
np.savetxt("britlit_raw.csv", dtm[:,ind], delimiter=",", fmt='%.14f')
FileLink('britlit_raw.csv')
[str(word) for word in vocab[ind]]
['adams', 'allworthy', 'bounderby', 'brandon', 'catherine', 'cathy', 'corporal', 'crawley', 'darcy', 'dashwood', 'did', 'earnshaw', 'edgar', 'elinor', 'emma', 'father', 'ferrars', 'finn', 'glegg', 'good', 'gradgrind', 'hareton', 'heathcliff', 'jennings', 'jones', 'joseph', 'know', 'lady', 'laura', 'like', 'linton', 'little', 'll', 'lopez', 'louisa', 'lyndon', 'maggie', 'man', 'marianne', 'miss', 'mr', 'mrs', 'old', 'osborne', 'pendennis', 'philip', 'phineas', 'quoth', 'said', 'sissy', 'sophia', 'sparsit', 'stephen', 'thought', 'time', 'tis', 'toby', 'tom', 'trim', 'tulliver', 'uncle', 'wakem', 'wharton', 'willoughby']
SVD¶
U, s, V = decomposition.randomized_svd(dtm, 10)
ind = get_all_topic_words(V)
len(ind)
52
vocab[ind]
array(['adams', 'allworthy', 'bounderby', 'bretton', 'catherine',
'crimsworth', 'darcy', 'dashwood', 'did', 'elinor', 'elton', 'emma',
'finn', 'fleur', 'glegg', 'good', 'gradgrind', 'hareton', 'hath',
'heathcliff', 'hunsden', 'jennings', 'jones', 'joseph', 'knightley',
'know', 'lady', 'linton', 'little', 'lopez', 'louisa', 'lydgate',
'madame', 'maggie', 'man', 'marianne', 'miss', 'monsieur', 'mr',
'mrs', 'pelet', 'philip', 'phineas', 'said', 'sissy', 'sophia',
'sparsit', 'toby', 'tom', 'tulliver', 'uncle', 'weston'],
dtype='<U31')
show_topics(H1)
['mr said mrs miss emma darcy little know', 'said little like did time know thought good', 'adams jones said lady allworthy sophia joseph mr', 'elinor marianne dashwood jennings willoughby mrs brandon ferrars', 'maggie tulliver said tom glegg philip mr wakem', 'heathcliff linton hareton catherine earnshaw cathy edgar ll', 'toby said uncle father corporal quoth tis trim', 'phineas said mr lopez finn man wharton laura', 'said crawley lyndon pendennis old little osborne lady', 'bounderby gradgrind sparsit said mr sissy louisa stephen']
np.savetxt("britlit_U.csv", U, delimiter=",", fmt='%.14f')
FileLink('britlit_U.csv')
np.savetxt("britlit_V.csv", V[:,ind], delimiter=",", fmt='%.14f')
FileLink('britlit_V.csv')
np.savetxt("britlit_raw_svd.csv", dtm[:,ind], delimiter=",", fmt='%.14f')
FileLink('britlit_raw_svd.csv')
np.savetxt("britlit_S.csv", np.diag(s), delimiter=",", fmt='%.14f')
FileLink('britlit_S.csv')
[str(word) for word in vocab[ind]]
['adams', 'allworthy', 'bounderby', 'bretton', 'catherine', 'crimsworth', 'darcy', 'dashwood', 'did', 'elinor', 'elton', 'emma', 'finn', 'fleur', 'glegg', 'good', 'gradgrind', 'hareton', 'hath', 'heathcliff', 'hunsden', 'jennings', 'jones', 'joseph', 'knightley', 'know', 'lady', 'linton', 'little', 'lopez', 'louisa', 'lydgate', 'madame', 'maggie', 'man', 'marianne', 'miss', 'monsieur', 'mr', 'mrs', 'pelet', 'philip', 'phineas', 'said', 'sissy', 'sophia', 'sparsit', 'toby', 'tom', 'tulliver', 'uncle', 'weston']
Randomized SVD offers a speed up¶

One way to address this is to use randomized SVD. In the below chart, the error is the difference between A - U * S * V, that is, what you've failed to capture in your decomposition:

For more on randomized SVD, check out my PyBay 2017 talk.
For significantly more on randomized SVD, check out the Computational Linear Algebra course.
Full vs Reduced SVD¶
Remember how we were calling np.linalg.svd(vectors, full_matrices=False)? We set full_matrices=False to calculate the reduced SVD. For the full SVD, both U and V are square matrices, where the extra columns in U form an orthonormal basis (but zero out when multiplied by extra rows of zeros in S).
Diagrams from Trefethen:

