from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
The raw code for this IPython notebook is by default hidden for easier reading.
To toggle on/off the raw code, click <a href="javascript:code_toggle()">here</a>.''')
OCDS for Infrastructure - Ukraine demonstrator¶
This notebook demonstrates the steps involved in developing a lightweight prototype to bring together structured data on infrastructure projects and contracting processes and explores the added value of using OCDS data in infrastructure monitoring.
The notebook is divided into the following sections:
- Summary of findings
- Part 1: Scraping projects data from the CoST Ukraine portal
- Part 2: Finding related contracting processes in the Prozorro OCDS export
- Part 3: Comparing data from CoST and Prozorro
Summary of findings¶
Availability of data¶
Projects
An export of structured data is not available from the front end of the CoST Ukraine portal, therefore a scraper script was written to extract projects data and store this in structured format.
Currently only data from the State Highways Agency is available on the CoST Ukraine portal.
Contracting processes
Structured data is available from the Prozorro platform via the following methods:
- An API which serves individual contracting processes in a format similar to OCDS
- Fortnightly bulk exports of OCDS format data, totaling c. 46gb per export
The most recent bulk export is dated 2018-04-20.
Finding related contracting processes¶
Currently the only public search interface available to the contracting data is in the Prozorro front end and there is no search API or interface to the bulk OCDS data to provide programmatic search of the data.
To reduce the number of manual steps in searching for and retrieving OCDS data from Prozorro the latest fortnightly bulk export was downloaded into an instance of the ocdsdata ETL tool so that the full dataset could be queried using PostgreSQL.
Using a sample of project titles from the CoST Ukraine portal and searching the tender/title and tender/description fields in the OCDS yielded the following results (number of relevant results shown in brackets):
| Search term | Project 1 | Project 2 | Project 3 | Project 4 | Project 5 |
|---|---|---|---|---|---|
| Project title | 1 (1) | 1 (1) | 1 (1) | 3 (3) | 0 (0) |
| Highway name | 14 (6) | 5 (3) | 3 (2) | 18 (8) | 73 (n/a) |
| Highway name and km marker | 6 (6) | 4 (3) | 2 (2) | 9 (8) | n/a |
Based on this sample, it seems that an automated search for the full project title is not sufficient to discover all related contracting processes and that searching for the highway name and km marker results in the best coverage and accuracy. As such two manual steps are required:
- Extract highway name and km marker from project title to use as search term (per project)
- Review tender title and description to determine whether the contracting process is related (per search result)
We also noted that:
- For 3 of the 5 projects, a Prozorro "announcement number" (ocid) was recorded in the CoST Portal
- For 4 of the 5 projects, the project title in the CoST Portal was an exact match for a construction contract in Prozorro
Suggesting that the list of projects in the CoST Ukraine portal may have been generated from Prozorro (e.g. by looking for tenders from the buyer with an item classification relating to construction).
Identifiers¶
Projects
Projects in the CoST Portal are not assigned an identifier. For the purposes of this analysis identifiers were constructed from the agency, region and foreign key extracted from the URL for the project, e.g.
portal.costukraine.org/UAD/POL/PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_TECH_DETAILS_handler&fk0=222*&master_viewmode=0
Contracting processes
Contracting processes in Prozorro are assigned an identifier (the ocid) however identifiers are not provided for the project a contracting process is associated with.
Some projects in the CoST Ukraine portal include a single ocid, which appears to be for the main construction contract associated with the project (check this).
Defining a project¶
The CoST Portal appears to list projects at the level of individual construction contracts.
When searching for related contracting processes we noted examples where there were several different construction contracts relating to a single highway, suggesting that there may be overarching projects of which the individual construction contracts form a part.
Tracking change¶
The OCDS Releases and Records model is designed to support disclosure of both individual updates about a contracting process (releases) and a summary of the latest state of the contracting process (records).
Currently, both the openprocurement API and the bulk OCDS export from Prozorro provide the latest state of the contracting process rather than a history of changes.
Prozorro functionality to publish individual releases to enable tracking change over the life of a process is in development.
There are two possible approaches to tracking change with the existing functionality, however there are obstacles to both of these:
Scrape the openprocurement API daily for specific contracting processes
- No search API is available, so requires first using either the Prozorro front end or ocdsdata ETL to find the relevant contracting processes.
- Results in non OCDS data.
Download and search historic bulk exports
- Contracting processes do not neccessarily appear in the same segment across exports, so the full export for each fortnight must be downloaded (c. 46GB per export)
- Exports are fortnightly so changes which occur more frequently than this may be missed
We weren't able to determine whether the release identifier is updated when the contracting process changes in either the API or bulk exports, so in either case it may be neccessary to compare all fields in the release to determine whether anything has changed.
Comparing project and contracting data¶
Comparing start and end dates¶
For each project:
- The end date listed in the CoST portal for the project matched the latest end date of the related contracts found in Prozorro.
- There was a related contract in Prozorro with a start date earlier than the start date listed in the project.
contracts_df.pivot_table(values='startDate', index=['project', 'projectStartDate'], aggfunc=np.min)
| startDate | ||
|---|---|---|
| project | projectStartDate | |
| UAD-DNE-40 | 18.04.2017 | 2017-02-09T00:00:00+02:00 |
| UAD-DNE-44 | 21.07.2017 | 2017-05-11T00:00:00+03:00 |
| UAD-POL-222 | 16.06.2017 | 2017-06-08T00:00:00+03:00 |
| UAD-SUM-173 | 12.10.2017 | 2016-09-21T18:00:00+00:00 |
contracts_df.pivot_table(values='endDate', index=['project', 'projectEndDate'], aggfunc=np.max)
| endDate | ||
|---|---|---|
| project | projectEndDate | |
| UAD-DNE-40 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
| UAD-DNE-44 | 31.12.2017 | 2017-12-31T00:00:00+02:00 |
| UAD-POL-222 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
| UAD-SUM-173 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
Understanding the project timeline¶
For each project we were able to identify design, construction and monitoring contracts and use the data from Prozorro to understand the project timeline, e.g.
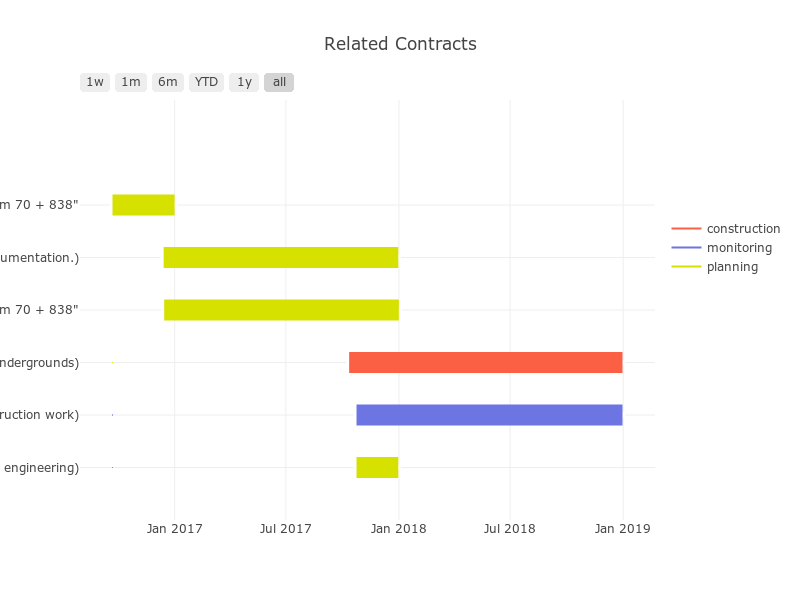
Comparing project value¶
For some projects the total value of contracts in Prozorro was greater than the total cost in the CoST Portal and for some projects is was less:
pd.options.display.float_format = '{:,}'.format
contracts_df.pivot_table(values='amount', index=['project','projectValue'], aggfunc=np.sum)
| amount | ||
|---|---|---|
| project | projectValue | |
| UAD-DNE-40 | 968,055,500.0 | 957,555,315.79 |
| UAD-DNE-44 | 203,382,619.0 | 204,569,982.24 |
| UAD-POL-222 | 575,109,925.0 | 576,803,727.92 |
| UAD-SUM-173 | 99,202,651.2 | 102,590,531.98 |
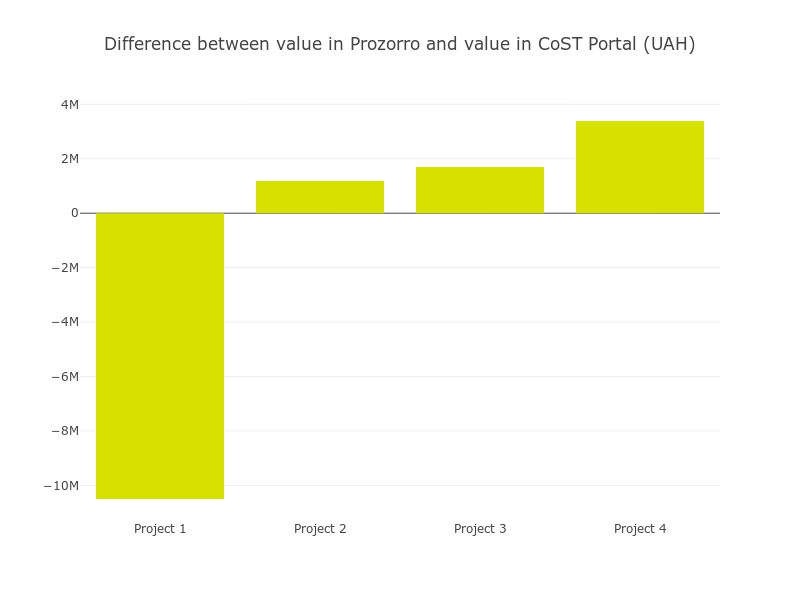
Understanding the split of project costs¶
Using the data from Prozorro we were able to understand the split of the total project cost across design, construction and monitoring contracts, e.g.
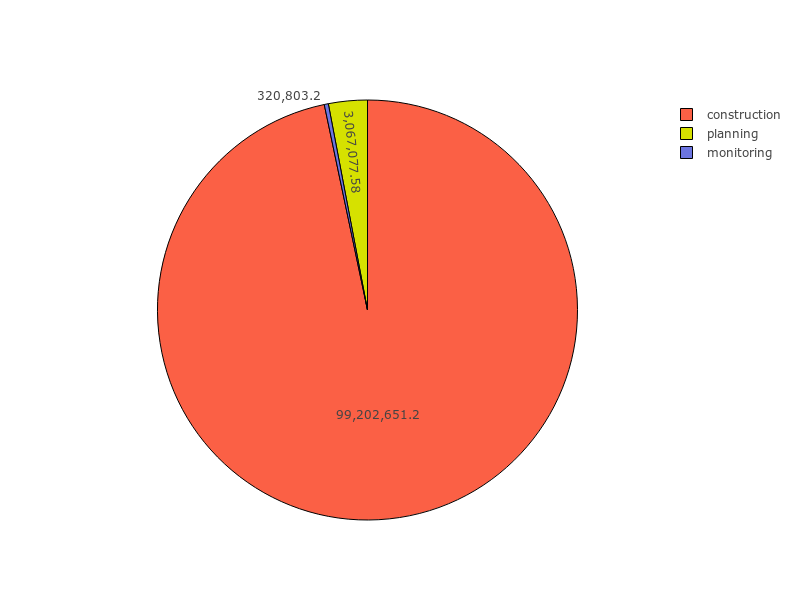
Conclusions¶
OCDS data can be used to:
- Discover contracts related to a project
- Understand the project timeline
- Understand the total cost of a project
The demonstrator suggests there is additional value in using OCDS data for infrastructure monitoring, for example, we found:
- Multiple design contracts for a single project, including intial design contracts for 'new construction' followed by further design contracts for 'reconstruction'
- Variances in the project values reported in the CoST portal and the total value of contracts in Prozorro
- Variances in the split of the total project value between design, construction and monitoring contracts
Part 1: Scraping data from CoST Ukraine portal¶
Navigate to the CoST Ukraine Portal
Note: Use Google Chrome with auto-translation enabled, unless you speak Ukrainian
Currently only projects of Ukravtodor, the State Highways Agency, are listed, so click the Ukravtodor logo.
Use the map to choose a region to see the projects list for, e.g. the Sumy region
Auto-translate doesn't work on the projects list page, so click "ТАБЛИЦІ" in the grey header bar to get a view which can be translated.
Note: You might need to open the "ТАБЛИЦІ" link in a new tab to get it to load
Choose the project which you want to scrape from the list, e.g. Reconstruction of the bridge crossing on the highway N-12 Sumy-Poltava km 70 + 838
Note: Use of Prozorro for above and below threshold procurement has only been mandatory since 1st August 2016, so try and find a project which starts after this date to give the best chance of finding related contracts
Set the following variables based on the URL of the project you selected:
#update with url segment for the public entity, e.g. UAD for State Highways Agency of Ukraine
publicEntity = "UAD"
#update with region for project, e.g. SUM for region, note for MFO projects the url construction is slightly different (see commented out html = line below)
region = "SUM"
#update with value of &fk0 parameter in URL of project you want to scrape - this identifies the project
foreignKey = "173"
#construct an identifier for saving data
projectID = publicEntity + "-" + region + "-" + foreignKey
Scrape data from CoST Portal¶
from requests import get
from bs4 import BeautifulSoup
import pprint
import json
import ipywidgets as widgets
#function to scrape content of main table
def scrape(url,output):
#get html and convert to nice object
html = get(url,stream=True).content
html = BeautifulSoup(html, "html.parser")
#get name of section we are scraping and create an object for it
section = html.body["id"]
output[section] = {}
main_table = html.find("div", class_="well")
if main_table != None:
for td in main_table.select("td"):
if "data-column-name" in td.attrs:
output[section][td["data-column-name"]] = td.text
return output
#get html of first page and convert to nice object
html = get("http://portal.costukraine.org/uad_mfo/PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_TECH_DETAILS_handler&fk0=" + foreignKey + "&master_viewmode=0",stream=True).content #use this line for MFO projects
#html = get("http://89.185.0.248:8888/"+publicEntity+"/"+region+"/PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_TECH_DETAILS_handler&fk0=" + foreignKey + "&master_viewmode=0",stream=True).content #use this line for all other projects
html = BeautifulSoup(html, "html.parser")
#set up array to store urls for each view of project
urls = []
#get urls of each page
navigation = html.find("ul", class_="nav nav-tabs grid-details-tabs")
for li in navigation.select("li"):
urls.append(li.a["href"])
#put amendments URL in separate variable (no data found for this page yet, so we don't do anything with this)
amendmentsURL = urls.pop()
#set up object for scraped data
project = {}
#scrape summary table (appears on each page, so only do this once)
project["summary"] = {}
summary_table = html.find("div", class_="grid grid-table grid-master js-grid")
for th in summary_table.select("th"):
project["summary"][th["data-name"]] = ""
for td in summary_table.select("td"):
if "data-column-name" in td.attrs:
project["summary"][td["data-column-name"]] = td.text
#scrape main table on each page
for url in urls:
print("scraping " + url)
project = scrape("http://portal.costukraine.org/uad_mfo/" + url, project) #use this line for MFO projects
#project = scrape("http://89.185.0.248:8888/"+publicEntity+"/"+region+"/" + url, project) #use this line for all other projects
print("done scraping")
data = {}
data = {"project": project}
scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_TECH_DETAILS_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_SUBJECTS_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_CUSTOMER_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_FINANCING_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_PROJECT_ORGANIZATION_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_CONTRACTOR_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_ENG_SUPERVIZORY_handler&fk0=3&master_viewmode=0 scraping PROJECTS.php?hname=dbo_PROJECTS_dbo_PROJECTS_TECH_SUPERVIZORY_handler&fk0=3&master_viewmode=0 done scraping
Translate scraped data¶
import copy
import os
from google.cloud import translate
#Set google cloud API credentials
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './ocds-f08bd860a3be.json'
#create a copy of the project from the Ukraine portal to translate
data["project_translated"] = copy.deepcopy(project)
# Instantiate translation client
translate_client = translate.Client()
target = 'en'
#translate project
project_translated = data["project_translated"]
for section in project_translated:
for key in project_translated[section]:
if type(project_translated[section][key]) == str:
text = project_translated[section][key]
translation = translate_client.translate(text, target_language = target)
if text != translation:
project_translated[section][key] = translation['translatedText']
Save data¶
import os
import json
if not os.path.exists("data"):
os.makedirs("data")
with open("data/" + projectID + ".json","w") as export:
json.dump(data,export,indent=2)
Part 2: Finding related contracts in Prozorro (using ocdsdata ETL tool)¶
Connect to ocdsdata instance¶
import getpass
import psycopg2
dbpassword = getpass.getpass("Enter database user password: ") #see /.pgpass file on server
# db connection config
conn = psycopg2.connect(
database = 'ocdsdata',
user = 'ocdsdata',
password = dbpassword,
host = '195.201.163.242',
port = '5432',
)
# clear db user password
dbpassword = ''
# create db cursor
cur = conn.cursor()
/home/ddewhurst/open_data_services/ocds/repositories/ocinfra.ocinfra_ukraine_demonstrator/.ve/lib/python3.5/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
Enter database user password: ········
Search for related contracting processes¶
import json
import copy
import os
from google.cloud import translate
from IPython.display import display
#Set google cloud API credentials
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/ddewhurst/open_data_services/ocds/repositories/ocinfra.ocinfra_ukraine_demonstrator/ocds-f08bd860a3be.json'
# Instantiate translation client
translate_client = translate.Client()
target = 'en'
#open project data
with open("data/"+projectID+".json") as file:
data = json.load(file)
#check if related contracting processes already exist and confirm overwrite
if "tenders" in data:
overwrite = input("Tenders data already exists for this project, overwrite? (y/n) ")
if overwrite == "y":
del(data["tenders"])
print("\n")
if "tenders" not in data:
#display project name in UK and EN and choose search terms
print("Project Title:")
print(data["project"]["summary"]["name"],"\n")
print("Project Title (translated):")
print(data["project_translated"]["summary"]["name"],"\n")
#prompt for search terms
searchInput = input("Enter pipe (|) delimited list of search terms from Ukrainian project title: ")
searchTerms = searchInput.split("|")
#construct SQL query
searchString = """
SELECT
data
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
"""
titleSearchString = """ AND (("""
descSearchString = """) OR ("""
for term in searchTerms:
titleSearchString = titleSearchString + "data -> 'tender' ->> 'title' LIKE '%" + term + "%'"
descSearchString = descSearchString + "data -> 'tender' ->> 'description' LIKE '%" + term + "%'"
if searchTerms.index(term) < len(searchTerms) - 1:
titleSearchString = titleSearchString + " AND "
descSearchString = descSearchString + " AND "
else:
descSearchString = descSearchString + "))"
searchString = searchString + titleSearchString + descSearchString
#search database and return results
print("\n","Searching...")
cur.execute("rollback")
cur.execute(searchString)
allTenders = []
relatedTenders = []
for result in cur.fetchall():
allTenders.append(result[0])
print("Found ",len(allTenders)," contracting process(es)\n")
#translate tender title & description
for tender in allTenders:
print("OCID: ",tender["ocid"])
if "title" in tender["tender"]:
text = tender["tender"]["title"]
translation = translate_client.translate(text, target_language = "en")
tender["tender"]["title_en"] = translation["translatedText"]
print("Title: ",tender["tender"]["title_en"])
if "description" in tender["tender"]:
text = tender["tender"]["description"]
translation = translate_client.translate(text, target_language = "en")
tender["tender"]["description_en"] = translation["translatedText"]
print("Description",tender["tender"]["description_en"],"\n")
#prompt to confirm tender is related and categorise as planning, contstruction or monitoring
if input("Is this tender related to the project? (y/n): ") == "y":
relatedTenders.append(tender)
tenderType = input("Is this a (p)lanning, (c)onstruction or (m)onitoring tender?: ")
tender["ocinfra"] = {}
if tenderType == "p":
tender["ocinfra"]["type"] = "planning"
elif tenderType == "c":
tender["ocinfra"]["type"] = "construction"
elif tenderType == "m":
tender["ocinfra"]["type"] = "monitoring"
else:
print("ERROR")
print("\n")
#save data
data["tenders"] = relatedTenders
with open("data/"+projectID+".json","w") as file:
json.dump(data,file,indent=2)
print("done")
Tenders data already exists for this project, overwrite? (y/n) y Project Title: Будівництво обходів трьох населених пунктів на автомобільній дорозі М-03 Київ-Харків-Довжанський: с.Покровська Багачка, с.Красногорівка, м.Полтава (Ічерга). Project Title (translated): Construction of detours of three settlements on the motorway M-03 Kiev-Kharkiv-Dovzhansky: p.Pokrovskaya Bagachka, s.Krasnogorovka, Poltava (Icherga). Enter pipe (|) delimited list of search terms from Ukrainian project title: М-03 Київ-Харків-Довжанський|Будівництво обходів Searching... Found 0 contracting process(es) done
Part 3: Compare data in Prozorro to data in CoST Ukraine Portal¶
Load data on contracts¶
import numpy as np
import pandas as pd
import json
import glob
paths = glob.glob("data/*.json")
contracts = []
for path in paths:
if "translated" not in path:
with open(path) as file:
data = json.load(file)
for tender in data["tenders"]:
if "contracts" in tender:
for contract in tender["contracts"]:
contracts.append({
"project": path.split("/")[-1].split(".")[-2],
"projectStartDate": data["project"]["summary"]["term_start"],
"projectEndDate": data["project"]["summary"]["term_end"],
"projectValue": data["project"]["summary"]["total_cost"],
"ocid": tender["ocid"],
"title_en": tender["tender"]["title_en"],
"type": tender["ocinfra"]["type"],
"contractID": contract["contractID"],
"status": contract["status"],
"startDate": contract["period"]["startDate"],
"endDate": contract["period"]["endDate"],
"amount": contract["value"]["amount"]
})
if contract["value"]["currency"] != "UAH":
print("Warning: Multiple currencies")
contracts_df = pd.DataFrame(contracts)
contracts_df = contracts_df[["project","projectStartDate","projectEndDate","projectValue","ocid","type","title_en","contractID","status","startDate","endDate","amount"]]
contracts_df['projectValue'] = contracts_df['projectValue'].str.replace(' ', '')
contracts_df['projectValue'] = pd.to_numeric(contracts_df['projectValue'])
Compare start dates¶
contracts_df.pivot_table(values='startDate', index=['project', 'projectStartDate'], aggfunc=np.min)
| startDate | ||
|---|---|---|
| project | projectStartDate | |
| UAD-DNE-40 | 18.04.2017 | 2017-02-09T00:00:00+02:00 |
| UAD-DNE-44 | 21.07.2017 | 2017-05-11T00:00:00+03:00 |
| UAD-POL-222 | 16.06.2017 | 2017-06-08T00:00:00+03:00 |
| UAD-POL-222_translated | 16.06.2017 | 2017-06-08T00:00:00+03:00 |
| UAD-SUM-173 | 12.10.2017 | 2016-09-21T18:00:00+00:00 |
Compare end dates¶
contracts_df.pivot_table(values='endDate', index=['project', 'projectEndDate'], aggfunc=np.max)
| endDate | ||
|---|---|---|
| project | projectEndDate | |
| UAD-DNE-40 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
| UAD-DNE-44 | 31.12.2017 | 2017-12-31T00:00:00+02:00 |
| UAD-POL-222 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
| UAD-POL-222_translated | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
| UAD-SUM-173 | 31.12.2018 | 2018-12-31T00:00:00+02:00 |
Visualise start and end dates¶
import plotly
import plotly.figure_factory as ff
from copy import copy
plotly.offline.init_notebook_mode()
# generate gantt chart for each project
gantt_charts = {}
for project in contracts_df["project"].unique():
# create dataframe with correct structure for gantt chart
gantt_charts[project] = {}
gantt_df = contracts_df.rename(index=str, columns={"title_en":"Task", "startDate":"Start","endDate":"Finish"})
gantt_df = gantt_df.loc[gantt_df["project"] == project]
gantt_charts[project]["data"] = copy(gantt_df)
# set colours for contract types
colors= {}
if "planning" in gantt_df["type"].unique():
colors["planning"] = "#d6e100"
if "construction" in gantt_df["type"].unique():
colors["construction"] = "#fb6045"
if "monitoring" in gantt_df["type"].unique():
colors["monitoring"] = "#6c75e1"
gantt_df = gantt_df.sort_values(by="Start",ascending=False)
# create gantt chart
gantt_charts[project]["chart"] = ff.create_gantt(
gantt_df,
colors=colors,
index_col='type',
#reverse_colors=True,
show_colorbar=True,
showgrid_x=True,
showgrid_y=True,
title="Related Contracts"
)
# plot example gantt chart and save image for display in summary
plotly.offline.iplot(gantt_charts[projectID]["chart"], image="png", filename="relatedContracts")
Compare project values¶
pd.options.display.float_format = '{:,}'.format
contracts_df.pivot_table(values='amount', index=['project', 'projectValue'], aggfunc=np.sum)
| amount | ||
|---|---|---|
| project | projectValue | |
| UAD-DNE-40 | 968,055,500.0 | 957,555,315.79 |
| UAD-DNE-44 | 203,382,619.0 | 204,569,982.24 |
| UAD-POL-222 | 575,109,925.0 | 576,803,727.92 |
| UAD-SUM-173 | 99,202,651.2 | 102,590,531.98 |
Visualise project value differences¶
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode()
# set number formatting
pd.options.display.float_format = '{:,}'.format
# calculate sum of contract values for each project
value_pivot = contracts_df.pivot_table(values='amount', index=['project','projectValue'], aggfunc=np.sum)
# create list of values for chart
values = []
for index, row in value_pivot.iterrows():
values.append(row['amount']-index[1])
# set chart properties
trace1 = go.Bar(
x=["Project 1","Project 2", "Project 3", "Project 4"],
y=values,
name='Difference',
marker=dict(
color='#d6e100'
)
)
data = [trace1]
layout = go.Layout(
title='Difference between value in Prozorro and value in CoST Portal (UAH)'
)
# plot chart and save image for display in summary
fig = go.Figure(data=data, layout=layout)
plotly.offline.iplot(fig, filename='valueDifferences', image='png')
Visualise value by contract type¶
import plotly
import plotly.graph_objs as go
plotly.offline.init_notebook_mode()
# create pie chart of contract value by type for each project
pie_charts = {}
for project in contracts_df["project"].unique():
pie_charts[project] = {}
# create dataframe with correct structure for pie chart
pie_df = contracts_df.loc[contracts_df["project"] == project]
# set colours, values and labels for pie chart
colors= []
values = []
labels = []
if "planning" in pie_df["type"].unique():
colors.append("#d6e100")
values.append(pie_df[pie_df["type"] == "planning"]["amount"].sum())
labels.append("planning")
if "construction" in pie_df["type"].unique():
colors.append("#fb6045")
values.append(pie_df[pie_df["type"] == "construction"]["amount"].sum())
labels.append("construction")
if "monitoring" in pie_df["type"].unique():
colors.append("#6c75e1")
values.append(pie_df[pie_df["type"] == "monitoring"]["amount"].sum())
labels.append("monitoring")
labels = ['planning','construction','monitoring']
# create pie chart
pie_charts[project] = go.Pie(
labels=labels,
values=values,
hoverinfo='label+percent',
textinfo='value',
name="pie",
#layout = {"title":"Global Emissions 1990-2011"},
marker=dict(
colors=colors,
line=dict(color='#000000', width=1)
)
)
# display example pie chart and save image to display in summary
plotly.offline.iplot([pie_charts[projectID]], filename='valuePie', image='png')
Assess CoST IDS coverage¶
Based on CoST IDS 'Table 1. Project and Contract Data for proactive disclosure'
Note: Some elements of 'Table 2. Project and Contract information for disclosure upon request' are included in the Prozorro data
There are some discrepancies between the following versions of the CoST IDS published on the CoST website:
Version A includes 'Last updated' and 'Project reference number' elements which are not present in Version B.
Version A combines 'Contract start date' and 'Contract duration' into a single element, they are separate in Version B
Version A includes a duplicate element 'Variation to contract price' which there is only a single instance of Version B, whilst Version B includes 'Escalation to contract price' which is not present in Version A.
For the purposes of this analysis we have used Version A and added the two additional elements from version B.
import pandas as pd
import qgrid
import json
mapping_df = pd.read_csv("cost_mapping.csv")
for col in ['prozorro_mapping','prozorro_example','cost_mapping','cost_example','notes']:
mapping_df[col] = mapping_df[col].astype('str')
mapping_df = mapping_df.set_index("id")
mapping_df
| object | phase | data | prozorro_mapping | prozorro_example | cost_mapping | cost_example | notes | |
|---|---|---|---|---|---|---|---|---|
| id | ||||||||
| P0 | Project | Project identification | Project reference number | Project identifiers were not included in eithe... | ||||
| P1 | Project | Project identification | Project owner | organization | "organization": "SAD in Poltava region" | The owner of the project could be inferred fro... | ||
| P2 | Project | Project identification | Sector, subsector | Differs from item classification in Prozorro (... | ||||
| P3 | Project | Project identification | Project name | name | "name": "Construction of overpass and transpor... | Project name may appear in tender/title or ten... | ||
| P4 | Project | Project identification | Project Location | tender/items/deliveryAddress | "deliveryAddress": { ... | Delivery address from the main construction co... | ||
| P5 | Project | Project identification | Purpose | Definition requires clarification | ||||
| P6 | Project | Project identification | Project description | Project description may appear in tender/descr... | ||||
| P7 | Project | Project preparation | Project scope (main output) | Definition requires clarification | ||||
| P8 | Project | Project preparation | Environmental impact | |||||
| P9 | Project | Project preparation | Land and settlement impact | |||||
| P10 | Project | Project preparation | Contact details | Definition requires clarification, contact det... | ||||
| P11 | Project | Project preparation | Funding sources | |||||
| P12 | Project | Project preparation | Project Budget | |||||
| P13 | Project | Project preparation | Project budget approval date | |||||
| P14 | Project | Project completion | Project status (current) | |||||
| P15 | Project | Project completion | Completion cost (projected) | total_cost | "total_cost": "575 109 925.00" | The projected completion cost could be calcula... | ||
| P16 | Project | Project completion | Completion date (projected) | term_end | "term_end": "31.12.2018" | The projected completion date for the project ... | ||
| P17 | Project | Project completion | Scope at completion (projected) | |||||
| P18 | Project | Project completion | Reasons for project changes | |||||
| P19 | Project | Project completion | Reference to audit and evaluation reports | |||||
| C1 | Contract | Procurement | Procuring entity | tender/procuringEntity | "procuringEntity": { "additi... | Recommend mapping to whole object to capture b... | ||
| C2 | Contract | Procurement | Procuring entity contact details | tender/procuringEntity/contactPoint | "contactPoint": { "email... | |||
| C3 | Contract | Procurement | Contract administration entity | |||||
| C5 | Contract | Procurement | Procurement process | tender/procurementMethod,tender/procurementMet... | "procurementMethod": "open","procurementMethod... | Definition requires clarification | ||
| C6 | Contract | Procurement | Contract type | Definition requires clarification | ||||
| C4 | Contract | Procurement | Contract status (current) | Prozorro includes a contracts/status field how... | ||||
| C7 | Contract | Procurement | Number of firms tendering | tender/numberOfTenderers | "numberOfTenderers": 4 | Prozorro also includes the name, address, iden... | ||
| C8 | Contract | Procurement | Cost estimate | tender/value | "value": { "amount": 5780000... | tender/value is the estimated cost at the time... | ||
| C9 | Contract | Procurement | Contract title | tender/title | "title": "Construction of overpass and transpo... | The contract object in Prozorro does not inclu... | ||
| C10 | Contract | Procurement | Contract firm(s) | awards/suppliers | "suppliers": [ { ... | |||
| C11 | Contract | Procurement | Contract price | contracts/values | "value": { "amount": 575... | |||
| C12 | Contract | Procurement | Contract scope of work | contracts/documents | "documents": [ { ... | A scope or description for the contract isn't ... | ||
| C13 | Contract | Procurement | Contract start date and duration | contracts/period | "period": { "endDate": "... | |||
| C14 | Contract | Implementation | Variation to contract price | Our understanding is that information in Prozo... | ||||
| C15 | Contract | Implementation | Escalation of contract price | Our understanding is that information in Prozo... | ||||
| C16 | Contract | Implementation | Variation to contract duration | Our understanding is that information in Prozo... | ||||
| C17 | Contract | Implementation | Variation to contract scope | Our understanding is that information in Prozo... | ||||
| C18 | Contract | Implementation | Reasons for price changes | Our understanding is that information in Prozo... | ||||
| C19 | Contract | Implementation | Reasons for scope and duration changes | Our understanding is that information in Prozo... |
Appendix 1: Creating a versioned release¶
The Prozorro dataset provides compiled releases (i.e. the last known state of a contracting process) rather than a change history, so in this section we attempt to reconstruct a change history from previous bulk OCDS downloads from Prozorro
Get list of package uris we are interested in:
cur.execute("""
SELECT
data.data ->> 'ocid' as ocid,
package_data.data ->> 'uri' as package_uri
FROM ((
package_data
JOIN
release
ON
package_data.id = release.package_data_id
)
JOIN
data
ON
data.id = release.data_id
)
WHERE
data.data ->> 'ocid' LIKE 'ocds-be6bcu%'
AND
data.data -> 'tender' ->> 'title' LIKE '%Н-12 Суми-Полтава%'
AND
data.data -> 'tender' ->> 'title' LIKE '%838%'
""")
printResults(cur)
ocid package_uri ------ -------------
Above query is broken, so manual copy and paste of results from pgadmin:
"ocds-be6bcu-UA-2017-06-22-000543-b" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000054.json"
"ocds-be6bcu-UA-2017-10-24-000672-a" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000042.json"
"ocds-be6bcu-UA-2017-08-18-000844-c" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000161.json"
"ocds-be6bcu-UA-2016-08-22-000314-b" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000086.json"
"ocds-be6bcu-UA-2016-12-14-000431-a" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000392.json"
"ocds-be6bcu-UA-2017-10-24-000686-a" "http://ocds.prozorro.openprocurement.io/merged_with_extensions_2018-04-20/release-0000429.json"
Get the ocid of the biggest contract:
contracts_df[contracts_df['amount']==contracts_df['amount'].max()]['ocid'][0]
'ocds-be6bcu-UA-2017-06-22-000543-b'
Download historical packages for the biggest contract, dating back to before the tender.period.startDate:
from datetime import datetime, timedelta
import ipywidgets as widgets
dates = []
date = datetime.strptime("2018-04-20","%Y-%m-%d")
while date > datetime.strptime("2017-06-01","%Y-%m-%d"):
date = date - timedelta(days=7)
dates.append(datetime.strftime(date,"%Y-%m-%d"))
progress = widgets.FloatProgress(
min=0,
max=10.0,
step=0.1,
description='Downloading:',
bar_style='info',
orientation='horizontal'
)
import requests
from IPython.display import display
for date in dates:
link = "http://ocds.prozorro.openprocurement.io/merged_with_extensions_" + date + "/release-0000054.json"
file_name = "packages/release-0000054_" + date + ".json"
progress.value = 0
with open(file_name, "wb") as f:
print("Downloading %s" % file_name)
response = requests.get(link, stream=True)
total_length = response.headers.get('content-length')
if total_length is None: # no content length header
print("no content length header")
f.write(response.content)
else:
progress.max = int(total_length)
display(progress)
for data in response.iter_content(chunk_size=4096):
f.write(data)
progress.value += len(data)
Downloading packages/release-0000054_2018-04-13.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=103119101.0)
Downloading packages/release-0000054_2018-04-06.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=106824214.0)
Downloading packages/release-0000054_2018-03-30.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=112747162.0)
Downloading packages/release-0000054_2018-03-23.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=107905082.0)
Downloading packages/release-0000054_2018-03-16.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=101410162.0)
Downloading packages/release-0000054_2018-03-09.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=105871337.0)
Downloading packages/release-0000054_2018-03-02.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=108025409.0)
Downloading packages/release-0000054_2018-02-23.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=105660149.0)
Downloading packages/release-0000054_2018-02-16.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=104189085.0)
Downloading packages/release-0000054_2018-02-09.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=102377447.0)
Downloading packages/release-0000054_2018-02-02.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=101725350.0)
Downloading packages/release-0000054_2018-01-26.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=111157440.0)
Downloading packages/release-0000054_2018-01-19.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=99870098.0)
Downloading packages/release-0000054_2018-01-12.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=102351391.0)
Downloading packages/release-0000054_2018-01-05.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-12-29.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-12-22.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-12-15.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-12-08.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-12-01.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-11-24.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-11-17.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-11-10.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-11-03.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-10-27.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-10-20.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=106365281.0)
Downloading packages/release-0000054_2017-10-13.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=54955577.0)
Downloading packages/release-0000054_2017-10-06.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=55340212.0)
Downloading packages/release-0000054_2017-09-29.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=53099417.0)
Downloading packages/release-0000054_2017-09-22.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-09-15.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=105998048.0)
Downloading packages/release-0000054_2017-09-08.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=116270598.0)
Downloading packages/release-0000054_2017-09-01.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-08-25.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-08-18.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=52089030.0)
Downloading packages/release-0000054_2017-08-11.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=117947469.0)
Downloading packages/release-0000054_2017-08-04.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-07-28.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=50869727.0)
Downloading packages/release-0000054_2017-07-21.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-07-14.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=95.0)
Downloading packages/release-0000054_2017-07-07.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=111018535.0)
Downloading packages/release-0000054_2017-06-30.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=106951321.0)
Downloading packages/release-0000054_2017-06-23.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=115060229.0)
Downloading packages/release-0000054_2017-06-16.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=116402054.0)
Downloading packages/release-0000054_2017-06-09.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=109039645.0)
Downloading packages/release-0000054_2017-06-02.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=105778793.0)
Downloading packages/release-0000054_2017-05-26.json
FloatProgress(value=0.0, bar_style='info', description='Downloading:', max=111417821.0)
import glob
import json
packagelist = glob.glob("packages/*")
releases = []
for package in packagelist:
print("processing: ", package)
with open(package) as file:
try:
package_json = json.load(file)
print("package contains ", len(package_json["releases"]), " releases")
for release in package_json["releases"]:
if "d64bd98f2e35428b93f958b421f55356" in release["id"]:
print(release["id"])
releases.append(release)
except ValueError:
print("Loading JSON failed for: ", package)b
processing: packages/release-0000054_2017-06-23.json package contains 4096 releases processing: packages/release-0000054_2018-03-02.json package contains 4096 releases processing: packages/release-0000054_2017-10-20.json package contains 4096 releases processing: packages/release-0000054_2017-11-03.json Loading JSON failed for: packages/release-0000054_2017-11-03.json processing: packages/release-0000054_2017-09-08.json package contains 4100 releases processing: packages/release-0000054_2017-12-15.json Loading JSON failed for: packages/release-0000054_2017-12-15.json processing: packages/release-0000054_2017-12-22.json Loading JSON failed for: packages/release-0000054_2017-12-22.json processing: packages/release-0000054_2017-06-02.json package contains 4096 releases processing: packages/release-0000054_2017-12-01.json Loading JSON failed for: packages/release-0000054_2017-12-01.json processing: packages/release-0000054_2018-04-06.json package contains 4096 releases processing: packages/release-0000054_2018-02-09.json package contains 4096 releases processing: packages/release-0000054_2017-08-25.json Loading JSON failed for: packages/release-0000054_2017-08-25.json processing: packages/release-0000054_2017-09-15.json package contains 4098 releases processing: packages/release-0000054_2017-05-26.json package contains 4096 releases processing: packages/release-0000054_2017-09-01.json Loading JSON failed for: packages/release-0000054_2017-09-01.json processing: packages/release-0000054_2017-10-27.json Loading JSON failed for: packages/release-0000054_2017-10-27.json processing: packages/release-0000054_2017-06-30.json package contains 4096 releases processing: packages/release-0000054_2017-06-16.json package contains 4096 releases processing: packages/release-0000054_2017-12-08.json Loading JSON failed for: packages/release-0000054_2017-12-08.json processing: packages/release-0000054_2017-10-06.json package contains 2048 releases processing: packages/release-0000054_2018-04-13.json package contains 4096 releases processing: packages/release-0000054_2018-02-23.json package contains 4096 releases processing: packages/release-0000054_2017-09-22.json Loading JSON failed for: packages/release-0000054_2017-09-22.json processing: packages/release-0000054_2017-08-18.json package contains 2048 releases processing: packages/release-0000054_2018-02-02.json package contains 4096 releases processing: packages/release-0000054_2018-03-16.json package contains 4096 releases processing: packages/release-0000054_2017-07-28.json package contains 2048 releases processing: packages/release-0000054_2018-03-30.json package contains 4096 releases processing: packages/release-0000054_2018-03-09.json package contains 4096 releases processing: packages/release-0000054_2017-09-29.json package contains 2049 releases processing: packages/release-0000054_2017-12-29.json Loading JSON failed for: packages/release-0000054_2017-12-29.json processing: packages/release-0000054_2018-01-26.json package contains 4096 releases processing: packages/release-0000054_2018-01-12.json package contains 4096 releases processing: packages/release-0000054_2017-07-14.json Loading JSON failed for: packages/release-0000054_2017-07-14.json processing: packages/release-0000054_2017-11-10.json Loading JSON failed for: packages/release-0000054_2017-11-10.json processing: packages/release-0000054_2018-01-19.json package contains 4096 releases processing: packages/release-0000054_2018-02-16.json package contains 4096 releases processing: packages/release-0000054_2017-11-24.json Loading JSON failed for: packages/release-0000054_2017-11-24.json processing: packages/release-0000054_2017-11-17.json Loading JSON failed for: packages/release-0000054_2017-11-17.json processing: packages/release-0000054_2018-01-05.json Loading JSON failed for: packages/release-0000054_2018-01-05.json processing: packages/release-0000054_2017-06-09.json package contains 4096 releases processing: packages/release-0000054_2018-03-23.json package contains 4096 releases processing: packages/release-0000054_2017-10-13.json package contains 2048 releases processing: packages/release-0000054_2017-08-11.json package contains 4096 releases processing: packages/release-0000054_2017-07-07.json package contains 4096 releases processing: packages/release-0000054_2017-07-21.json Loading JSON failed for: packages/release-0000054_2017-07-21.json processing: packages/release-0000054_2017-08-04.json Loading JSON failed for: packages/release-0000054_2017-08-04.json
No matching releases were found, suggesting that releases are not located in a consistent segment of the bulk download across dates, therefore constructing a history of changes would involve downloading all segments for all bulk releases (c. 46GB data for every two weeks)
Appendix 2: Exploring the Prozorro dataset¶
cur.execute("""
SELECT
COUNT(id) as release_count,
COUNT(DISTINCT data ->> 'ocid') as ocid_count
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
""")
printResults(cur)
release_count ocid_count
--------------- ------------
1892352 1892352
One release per ocid
Releases by tag¶
cur.execute("""
SELECT
COUNT(id) as release_count,
data ->> 'tag' as tag
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
GROUP BY
tag
""")
printResults(cur)
release_count tag
--------------- --------------------------------------
230269 ["tender"]
13203 ["tender", "award"]
61133 ["tender", "award", "bid"]
1004187 ["tender", "award", "contract"]
546471 ["tender", "award", "contract", "bid"]
37089 ["tender", "bid"]
Results suggest that releases and records model is not fully implemented -> expected to see similar numbers of tender and award releases
Search for the name of the highway (Н-12 Суми-Полтава)
cur.execute("""
SELECT
COUNT(id) as release_count,
COUNT(DISTINCT data ->> 'ocid') as ocid_count
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
AND
data -> 'tender' ->> 'title' LIKE '%Н-12 Суми-Полтава%'
""")
printResults(cur)
release_count ocid_count
--------------- ------------
14 14
Refine search by km marker
cur.execute("""
SELECT
COUNT(id) as release_count,
COUNT(DISTINCT data ->> 'ocid') as ocid_count
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
AND
data -> 'tender' ->> 'title' LIKE '%Н-12 Суми-Полтава%'
AND
data -> 'tender' ->> 'title' LIKE '%838%'
""")
printResults(cur)
release_count ocid_count
--------------- ------------
6 6
Check how many different ocids there are for the project and what tags
cur.execute("""
SELECT
COUNT(id) as release_count,
data ->> 'ocid' as ocid,
data ->> 'tag' as tag
FROM
data
WHERE
data ->> 'ocid' LIKE 'ocds-be6bcu%'
AND
data -> 'tender' ->> 'title' LIKE '%Н-12 Суми-Полтава%'
AND
data -> 'tender' ->> 'title' LIKE '%838%'
GROUP BY
ocid,
tag
""")
printResults(cur)
release_count ocid tag
--------------- ---------------------------------- --------------------------------------
1 ocds-be6bcu-UA-2016-08-22-000314-b ["tender", "award", "contract", "bid"]
1 ocds-be6bcu-UA-2016-12-14-000431-a ["tender", "award", "contract"]
1 ocds-be6bcu-UA-2017-06-22-000543-b ["tender", "award", "contract", "bid"]
1 ocds-be6bcu-UA-2017-08-18-000844-c ["tender", "award", "contract"]
1 ocds-be6bcu-UA-2017-10-24-000672-a ["tender", "award", "contract"]
1 ocds-be6bcu-UA-2017-10-24-000686-a ["tender", "award", "contract"]
Appendix 3: Finding related contracts in Prozorro (front end search / openprocurement API)¶
Using untranslated name of the project, search the Prozorro front end for related tenders.
Example¶
The name of our project:
Reconstruction of the bridge crossing on the highway N-12 Sumy-Poltava km 70 + 838
Was translated from:
Реконструкція мостового переходу на автомобільній дорозі Н-12 Суми-Полтава км 70+838
Searching for the name of the highway (Н-12 Суми-Полтава) returns 67 results. Manually reviewing the results to identify those relating to the bridge at km 70 +838 results in 6 contracts:
https://prozorro.gov.ua/tender/UA-2017-10-24-000686-a (ecd7008713ce40898a0b8a9e725cd75a)
https://prozorro.gov.ua/tender/UA-2017-10-24-000672-a (1711f9b90d7244d68aa47d02f538e0f9)
https://prozorro.gov.ua/tender/UA-2017-06-22-000543-b (1dc0ebaf0c3e4330bf242a91f39579e9)
https://prozorro.gov.ua/tender/UA-2017-08-18-000844-c (58c516cadcfe4767852e94d63860aed6)
https://prozorro.gov.ua/tender/UA-2016-12-14-000431-a (d87604c7236a43a09b5ec4249cc5cb84)
https://prozorro.gov.ua/tender/UA-2016-08-22-000314-b (2f5da1f7f080416e91b3fd655abffc85)
The individual tender view in the Prozorro front end includes the identifier needed to retrieve the related record from the openprocurementapi (shown in brackets above)
Populate the following array with the tender identifiers you found in the previous step:
identifiers = ["ecd7008713ce40898a0b8a9e725cd75a","1711f9b90d7244d68aa47d02f538e0f9","1dc0ebaf0c3e4330bf242a91f39579e9","58c516cadcfe4767852e94d63860aed6","d87604c7236a43a09b5ec4249cc5cb84","2f5da1f7f080416e91b3fd655abffc85"]
Run the following script to download the data from the openprocurement API:
import urllib
data["tenders"] = []
for identifier in identifiers:
with urllib.request.urlopen("https://public.api.openprocurement.org/api/2/tenders/" + identifier) as url:
response = json.loads(url.read().decode())
data["tenders"].append(response["data"])
#save results to file
with open("data_" + publicEntity + "_" + region + "_" + foreignKey + ".json", "w") as output:
json.dump(data, output, indent = 4, ensure_ascii=False)
Appendix 4: Initial mapping / fields for comparison¶
The following table provides a high level mapping of the fields in the CoST Ukraine to fields in OCDS, to identify opportunities to compare data from CoST Ukraine and Prozorro:
| Section | Field | Example | Related OCDS field(s) | Notes |
|---|---|---|---|---|
| Summary | term_end |
31.12.2018 | contract/period/endDate |
|
| Summary | term_start |
12.10.2017 | contract/period/startDate |
|
| Summary | total_cost |
99 202 651.20 | contract/value/amount |
|
| Summary | customer |
Sumymostobud LLC | awards/suppliers/name |
|
| TECH_DETAILS | left_cost |
99 202 651.20 | Cost remaining? Matches total_cost in summary section | |
| SUBJECTS | prognose cost |
99202651.20 | Expected cost? Matches total_cost in summary section | |
| SUBJECTS | decision_date |
12.10.2017 | awards/suppliers/date |
|
| CONTRACTOR | costs |
99 202 651.20 | awards/amount |
Matches total_cost in summary section |
| CONTRACTOR | org_name |
Sumymostobud LLC | awards/suppliers/name |
|
| CONTRACTOR | announce_place |
Prozor | Notice location | |
| CONTRACTOR | terms |
31.12.2018 | contract.period.endDate |
|
| CONTRACTOR | announce_date |
22.06.2017 | tender date? | |
| CONTRACTOR | start_date |
12.10.2017 | contract/period/startDate |
|
| CONTRACTOR | announce_num |
UA-2017-06-22-000543-b | ocid |
|
| FINANCING | state_budget |
19 667 768.40 | budget.amount |