Perceptron Learning in Python¶
(C) 2017-2024 by Damir Cavar
Download: This and various other Jupyter notebooks are available from my GitHub repo.
Prerequisites:
!pip install -U numpy
This is a tutorial related to the discussion of machine learning and NLP in the class Machine Learning for NLP: Deep Learning (Topics in Artificial Intelligence) taught at Indiana University in Spring 2018, and Fall 2023.
What is a Perceptron?¶
There are many online examples and tutorials on perceptrons and learning. Here is a list of some articles:
- Wikipedia on Perceptrons
- Jurafsky and Martin (ed. 3), Chapter 8
Example¶
This is an example that I have taken from a draft of the 3rd edition of Jurafsky and Martin, with slight modifications:
We import numpy and use its exp function. We could use the same function from the math module, or some other module like scipy. The sigmoid function is defined as in the textbook:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
Our example data, weights $w$, bias $b$, and input $x$ are defined as:
w = np.array([0.2, 0.3, 0.8])
b = 0.5
x = np.array([0.5, 0.6, 0.1])
Our neural unit would compute $z$ as the dot-product $w \cdot x$ and add the bias $b$ to it. The sigmoid function defined above will convert this $z$ value to the activation value $a$ of the unit:
z = w.dot(x) + b
print("z:", z)
print("a:", sigmoid(z))
z: 0.86 a: 0.7026606543447315
The XOR Problem¶
The power of neural units comes from combining them into larger networks. Minsky and Papert (1969): A single neural unit cannot compute the simple logical function XOR.
The task is to implement a simple perceptron to compute logical operations like AND, OR, and XOR.
- Input: $x_1$ and $x_2$
- Bias: $b = -1$ for AND; $b = 0$ for OR
- Weights: $w = [1, 1]$
with the following activation function:
$$ y = \begin{cases} \ 0 & \quad \text{if } w \cdot x + b \leq 0\\ \ 1 & \quad \text{if } w \cdot x + b > 0 \end{cases} $$We can define this threshold function in Python as:
def activation(z):
if z > 0:
return 1
return 0
For AND we could implement a perceptron as:
w = np.array([1, 1])
b = -1
x = np.array([0, 0])
print("0 AND 0:", activation(w.dot(x) + b))
x = np.array([1, 0])
print("1 AND 0:", activation(w.dot(x) + b))
x = np.array([0, 1])
print("0 AND 1:", activation(w.dot(x) + b))
x = np.array([1, 1])
print("1 AND 1:", activation(w.dot(x) + b))
0 AND 0: 0 1 AND 0: 0 0 AND 1: 0 1 AND 1: 1
For OR we could implement a perceptron as:
w = np.array([1, 1])
b = 0
x = np.array([0, 0])
print("0 OR 0:", activation(w.dot(x) + b))
x = np.array([1, 0])
print("1 OR 0:", activation(w.dot(x) + b))
x = np.array([0, 1])
print("0 OR 1:", activation(w.dot(x) + b))
x = np.array([1, 1])
print("1 OR 1:", activation(w.dot(x) + b))
0 OR 0: 0 1 OR 0: 1 0 OR 1: 1 1 OR 1: 1
With this narrow definition of a perceptron, it seems not possible to implement an XOR logic perceptron. The restriction is that there is a threshold function that is binary and piecewise linear.
As one student in my 2020 L645 class, Kazuki Yabe, points out, with a different activation function and a different weight vector, one unit can of course handle XOR. If we use the following activation function:
$$ y = \begin{cases} \ 0 & \quad \text{if } w \cdot x + b \neq 0.5\\ \ 1 & \quad \text{if } w \cdot x + b = 0.5 \end{cases} $$def bactivation(z):
if z == 0.5:
return 1
else: return 0
If we assume the weights to be set to 0.5 and the bias to 0, one unit can handle the XOR logic:
- Input: $x_1$ and $x_2$
- Bias: $b = 0$ for XOR
- Weights: $w = [0.5, 0.5]$
w = np.array([0.5, 0.5])
b = 0
x = np.array([0, 0])
print("0 OR 0:", bactivation(w.dot(x) + b))
x = np.array([1, 0])
print("1 OR 0:", bactivation(w.dot(x) + b))
x = np.array([0, 1])
print("0 OR 1:", bactivation(w.dot(x) + b))
x = np.array([1, 1])
print("1 OR 1:", bactivation(w.dot(x) + b))
0 OR 0: 0 1 OR 0: 1 0 OR 1: 1 1 OR 1: 0
This particular activation function is of course not differentiable, and it remains to be shown that the weights can be learned, but nevertheless, a single unit can be identified that solves the XOR problem.
The difference between Minsky and Papert's (1969) definition of a perceptron and this unit is that - as Julia Hockenmaier pointed out - a perceptron is defined to have a decision function that would be binary and piecewise linear. This means that the unit that solves the XOR problem is not compatible with the definition of perceptron as in Minsky and Papert (1969) (p.c. Julia Hockenmaier).
Tri-Perceptron XOR Solution¶
There is a proposed solution in Goodfellow et al. (2016) for the XOR problem, using a network with two layers of ReLU-based units.
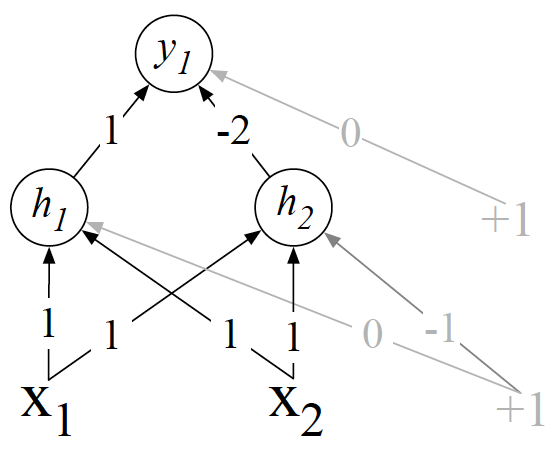
This two layer and three perceptron network solves the problem.
For more deiscussion on this problem, consult:
(C) 2017-2024 by Damir Cavar